Memory management
===
記憶體是 Kernel 裡最複雜的一個章節,就讓我們一起體會他的奧妙
前面的介紹著重在 physical memory 是如何管理,後面則是 virtual kernel memory space 的記憶體管理,virtual user space 會在另外的章節提到
# NUMA
首先, memory 有分為 uniform memory access(UMA) 跟 non-uniform memory access(NUMA)兩種
UMA: 每個 processor accesses memory 的速度都是一樣的
NUMA: 每個 processor accesses memory 的速度不一樣,local 的比較快,以下圖為例
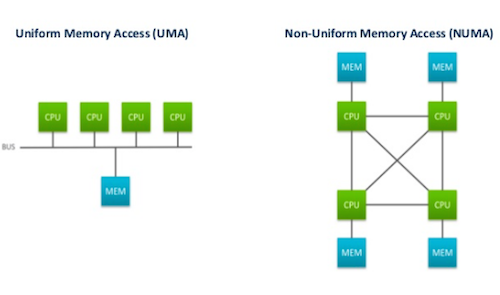圖[1]
# Node
根據圖[1],把每個 memory 當成一個 node,這樣 UMA 只有一個 node,但是 NUMA 有四個
# Zone
# Node and Zone Initialization
## build_zonelists()
當我們 allocate memory,首先要先找 node,然後找 zone,最後透過 buddy system 找到 page。
node 透過 `NODE_DATA(nid)` 可以得知,那怎麼找到特定的 zone?
首先,Zone 分為以下的 type
```c=
enum zone_type {
#ifdef CONFIG_ZONE_DMA
ZONE_DMA,
#endif
#ifdef CONFIG_ZONE_DMA32
ZONE_DMA32,
#endif
ZONE_NORMAL,
#ifdef CONFIG_HIGHMEM
ZONE_HIGHMEM,
#endif
ZONE_MOVABLE,
MAX_NR_ZONES
};
```
每個 type 都會建立一個 `struct zone`,在 allocate memory 的時候,需要先知道我們想要的 memory type 是哪一種,然後就去對應的 zone 裡面開始找,找的時候要有個順序對照,要是在第一個 zone 找不到,還可以去下個 zone 找,這個順序就存在每個 `struct zone` 的 `zonelist->zones`裡面,`build_zonelists`會為所有的 zone 建立這個順序
Example
---
假設系統有 4 個 nodes ,分別叫做 A, B, C, D, zone_type 則有 highmem, normal, dma 三個 types
那麼以下是 node C 裡各別 zone 的 `zonelist->zones`
highmem:
| C2 | C1 | C0 | D2 | D1 | D0 | A2 | A1 | A0 | B2 | B1 | B0 | NULL |
| -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | ---- |
normal:
| C1 | C0 | D1 | D0 | A1 | A0 | B1 | B0 | NULL |
| -- | -- | -- | -- | -- | -- | -- | -- | ---- |
DMA:
| C0 | D0 | A0 | B0 | NULL |
| -- | -- | -- | -- | ---- |
# slab
kmem_cache_create 並不會建立 slab,只會建立一個 cache 的空殼,array_cache 裡也沒有可以用的 object!
## kmalloc
一開始用了 `__builtin_constant_p` 檢查`size`是不是 constant,是的話透過 MACRO 計算需要的 size,接著呼叫 `kmem_cache_alloc`,不是的話就呼叫 `__kmalloc`,最後還是會做一樣的檢查,不過是透過迴圈
`size`是 constant 時:
```c=
static inline void *kmalloc(size_t size, gfp_t flags)
{
if (__builtin_constant_p(size)) {
int i = 0;
#define CACHE(x) \
if (size <= x) \
goto found; \
else \
i++;
#include "kmalloc_sizes.h"
#undef CACHE
return kmem_cache_alloc(malloc_sizes[i].cs_cachep, flags);
}
```
`size`不是 constant 時:
```c=
static inline struct kmem_cache *__find_general_cachep(size_t size,
gfp_t gfpflags)
{
struct cache_sizes *csizep = malloc_sizes;
...
while (size > csizep->cs_size)
csizep++;
...
}
```
雖然都做一樣的事情,但是一個是在 compiler time 做檢查,令一個是在 execution time
# 有趣的程式碼
## Division of Address Space
`inline function` compiler 可以做最佳化,以以下例子為例
```c=
static __always_inline unsigned long fix_to_virt(const unsigned int idx) {
if (idx >= __end_of_fixed_addresses)
__this_fixmap_does_not_exist();
return __fix_to_virt(idx);
}
```
最佳化後 `if` branch 會被拿掉,因為全部都是 `constant`
virtual address space 可以先分為兩大類:
- kernel address
- user address
| kernel space |
| ------------ |
| user space |
其中 `kernel address`再分兩種
- kernel logical address
這塊空間是透過 direct mapping,而且是 contiguous,適用 DMA
如果 physical memory 少於1G,那麼全部的 `kernel address` 都是 `kernel logical address`,大於 1G 的話,就會有 `kernel virtual address`
- kernel virtual address
這就不是 contiguous
一般而言, kernel space 和 user space 的比例是 1:3,也有 2:2 的,像是手機,原因是 camera 需要大塊的 buffer
# 問題
## void pointer arithmetics
in slab.c
```c=
static struct slab *alloc_slabmgmt(struct kmem_cache *cachep, void *objp,
int colour_off, gfp_t local_flags,
int nodeid)
{
...
slabp = objp + colour_off;
...
}
```
void pointer `objp` does add arithmetic!
Is this correct?
## functions who invokes cache_estimate
呼叫 `cache_estimate` 的 function,都會檢查 `num`,如果 num == 0 就繼續呼叫,但是在 `cache_estimate` 裡面一定會給 num 一個值,不可能是 0,表示 order 0 的時候就會結束迴圈,這樣何必寫一個迴圈呢?程式碼如下
```c=
static void cache_estimate(unsigned long gfporder, size_t buffer_size,
size_t align, int flags, size_t *left_over,
unsigned int *num);
void __init kmem_cache_init(void) {
...
for (order = 0; order < MAX_ORDER; order++) {
cache_estimate(order, cache_cache.buffer_size,
cache_line_size(), 0, &left_over, &cache_cache.num);
if (cache_cache.num)
break;
}
...
}
```
# Reference
[1] https://www.motioncontroltips.com/wp-content/uploads/2018/04/NUMA-Architecture.png