# 2021q1 Homework3 (quiz3)
contributed by < [`linD026`](https://github.com/linD026) >
###### tags: `linux2021`
> [2021 年第 3 週隨堂測驗題目](https://hackmd.io/@sysprog/linux2021-quiz3)
> [folly::FBString](https://github.com/facebook/folly/blob/master/folly/docs/FBString.md)
---
## 0 進度
- [x] 1 解釋程式碼運作原理與改進
- [ ] NULL
- [x] 2 提供字串複製 ( CoW ) 實作
- [ ] NULL
- [x] 3 實驗 - 字串空間效率最佳化
- [ ] NULL
- [x] 4 整合 - 字串空間最佳化
- [ ] 多執行緒下的保證
- [x] 5 Linux 核心 內部實例
- [ ] mm_struct, address_space, page 之間的關係要在釐清
- [ ] CoW 在 page 的實作
- [ ] 各步驟說明要完善
---
## 1 解釋程式碼運作原理與改進
### 結構定義
* 小字串: 字串長度不超過 15 , 儲存於 stack 。
* 長度為 15 減去以 4 個 bit 方式儲存的 `space_left` 表示。
* 字串儲存於 15 位元組的 `filler` 字元陣列中。
* 中字串: 字串長度介於 16 至 `LARGE_STRING_LEN` (此為 256 ), 儲存於 heap。
* 使用 `data` 指標提取字串。
* 長度以 `size` 表示。最大長度以被分配的 bit 多寡決定。此為 54 bits 共 $2^{54} - 1$ 最大長度。
* 分配的空間大小以 `capacity` 表示。應須涵蓋到 `size` 所能表示的範圍,因此以二的次方來儲存。在此 6 bits 來表示,共 $2^{6} - 1$ 。
* 在最後 4 個 bit 中儲存了判斷是否為指標(是否為小字串)、大字串等,各為 1 bit 的標示。
* `is_ptr` 、 `is_large_string` 、 `flag2` 、 `flag3`
* 大字串: 字串長度超過 `LARGE_STRING_LEN`,儲存於 heap。
* 使用 CoW 作最佳化。
* 基本資訊與中字串一致。
* 但在提取字串的指標上和中字串不同,其在原先指標的前 4 個 byte 的位置儲存了 `int` 型態的 `refcnt` ( `reference count` ),因此在存取字串時須注意。
```cpp
typedef union {
char data[16];
// stack and flags
struct {
uint8_t filler[15],
space_left : 4,
/* if it is on heap, set 1 */
is_ptr : 1, is_large_string : 1, flag2 : 1, flag3 : 1;
};
/* heap allocated */
struct {
char *ptr;
/* supports strings up to 2^MAX_STR_LEN_BITS - 1 bytes */
size_t size : MAX_STR_LEN_BITS,
/* capacity is always a power of 2 (unsigned)-1 */
capacity : 6;
/* the last 4 bits are important flags */
};
} xs;
```
```graphviz
digraph table {
graph [rankdir = TD]
node [shape = record]
small_byte [label = "{4 bits|space_left}|{4 bits|{is_ptr|is_large_string|flag2|flag3}}"]
small [label = "{memory|small}|{15 bytes|filler}|{1 byte|<in>}"]
small:in -> small_byte
}
```
```graphviz
digraph table {
graph [rankdir = TD]
node [shape = record]
medium [label = "{memory|medium}|{8 bytes|data}|{4 bytes|}| {4 bytes|<in>}"]
medium_byte [label = "{54 bits| size}|{6 bits| capacity}|{4 bits|<in>}"]
small_byte [label = "{4 bits|{is_ptr|is_large_string|flag2|flag3}}"]
// medium_byte -> medium:in
medium:in -> medium_byte
// small_byte -> medium_byte:in
medium_byte:in -> small_byte
}
```
```graphviz
digraph table {
graph [rankdir = TD]
node [shape = record]
large [label = "{memory|large}|{4 bytes|refcnt}|{8 bytes| pointer}| {4 bytes|<in>}"]
medium_byte [label = "{54 bits| size}|{6 bits| capacity}|{4 bits|<in>}"]
small_byte [label = "{4 bits|{is_ptr|is_large_string|flag2|flag3}}"]
large:in -> medium_byte
medium_byte:in -> small_byte
}
```
* 取得資訊的函式
* 下列函式皆為提取該字串的資訊。
* 可以看到 `xs_capacity` 在提取時是以 2 的冪 (利用對 `1` 作位元偏移)。
```cpp
static inline bool xs_is_ptr(const xs *x) { return x->is_ptr; }
static inline bool xs_is_large_string(const xs *x) {
return x->is_large_string;
}
static inline size_t xs_size(const xs *x) {
return xs_is_ptr(x) ? x->size : 15 - x->space_left;
}
static inline size_t xs_capacity(const xs *x) {
return xs_is_ptr(x) ? ((size_t)1 << x->capacity) - 1 : 15;
}
static inline char *xs_data(const xs *x) {
if (!xs_is_ptr(x))
return (char *)x->data;
if (xs_is_large_string(x))
return (char *)(x->ptr + 4);
return (char *)x->ptr;
}
```
* refcnt - 大字串的 CoW
```cpp
static inline void xs_set_refcnt(const xs *x, int val) {
*((int *)((size_t)x->ptr)) = val;
}
static inline void xs_inc_refcnt(const xs *x) {
if (xs_is_large_string(x))
++(*(int *)((size_t)x->ptr));
}
static inline int xs_dec_refcnt(const xs *x) {
if (!xs_is_large_string(x))
return 0;
return --(*(int *)((size_t)x->ptr));
}
static inline int xs_get_refcnt(const xs *x) {
if (!xs_is_large_string(x))
return 0;
return *(int *)((size_t)x->ptr);
}
```
* ilog2
* 利用 [`__builtin_clz`](https://gcc.gnu.org/onlinedocs/gcc/Other-Builtins.html) 取得該數的 `the number of leading 0-bits` 並減去 32 (視型態此為 `uint32_t` ) 取得該數的左邊算起來第一個 1 的位數後減 1 。
* 例子:
* $7_{10} = 0000 0000 0000 0111_2$
$32 -29 = 3$
$3 - 1 = 2$ 等於 $2^2 = 4$
* $9_{10} = 0000 0000 0000 1001_2$
$32 - 28 = 4$
$4 - 1 = 3$ 等於 $2^3 = 8$
```cpp
/* lowerbound (floor log2) */
static inline int ilog2(uint32_t n) { return 32 - __builtin_clz(n) - 1; }
```
* xs_allocate_data
* 依照字串的資訊分配適當的記憶體,利用` bool reallocate` 來判斷是擴充還是分配新的記憶體空間。
* 如果 `len` 符合大字串,則可以看到在分配時跳過了前四個 byte 。
```cpp
static void xs_allocate_data(xs *x, size_t len, bool reallocate)
{
/* Medium string */
if (len < LARGE_STRING_LEN) {
x->ptr = reallocate ? realloc(x->ptr, (size_t) 1 << x->capacity)
: malloc((size_t) 1 << x->capacity);
return;
}
/* Large string */
x->is_large_string = 1;
/* The extra 4 bytes are used to store the reference count */
x->ptr = reallocate ? realloc(x->ptr, (size_t)(1 << x->capacity) + 4)
: malloc((size_t)(1 << x->capacity) + 4);
xs_set_refcnt(x, 1);
}
```
* xs_new
* `const void *p` 為要儲存的字串。
* ```cpp
#define xs_literal_empty() \
(xs) { .space_left = 15 }
```
* 記憶體分配可以分成在 stack 或 heap 兩種,中字串與大字串的區隔則在 `xs_allocate_data` 裡決定。
```cpp
xs *xs_new(xs *x, const void *p)
{
*x = xs_literal_empty();
size_t len = strlen(p) + 1;
if (len > 16) {
x->capacity = ilog2(len) + 1;
x->size = len - 1;
x->is_ptr = true;
xs_allocate_data(x, x->size, 0);
memcpy(xs_data(x), p, len);
} else {
memcpy(x->data, p, len);
x->space_left = 15 - (len - 1);
}
return x;
}
```
* xs_tmp
* [`_Static_assert`](https://en.cppreference.com/w/c/language/_Static_assert) 是 C11 新增的檢測方式,在編譯時期檢測錯誤。
> The constant expression is evaluated **at compile time** and **compared to zero**. If it compares equal to zero, a compile-time error occurs and the compiler must display message (if provided) as part of the error message (except that characters not in basic source character set aren't required to be displayed).
Otherwise, if expression does not equal zero, nothing happens; no code is emitted.
```cpp
#define xs_tmp(x) \
((void)((struct { \
_Static_assert(sizeof(x) <= MAX_STR_LEN, "it is too big"); \
int dummy; \
}){1}), \
xs_new(&xs_literal_empty(), x))
```
:::warning
//TODO 為什麼是這寫法 `((void) (struct{_Static_assert(); int dummy;}){1}), function())`
:::
* xs_cow_lazy_copy
* 此函式以名稱來看是在 CoW 時的複製。
* 一般來說, lazy copy 是指當 B 物件複製 A 物件的資料時,B 物件所擁有的資料是直接指向 A 原資料。當作更改時,再獨立複製出來。
* 此` char **data` 為要複製的資料,複製至 `xs *x` 並讓 `data` 指向複製的內容。
```cpp
static bool xs_cow_lazy_copy(xs *x, char **data)
{
if (xs_get_refcnt(x) <= 1)
return false;
/* Lazy copy */
xs_dec_refcnt(x);
xs_allocate_data(x, x->size, 0);
if (data) {
memcpy(xs_data(x), *data, x->size);
/* Update the newly allocated pointer */
*data = xs_data(x);
}
return true;
}
```
* 例子:
* pointer 指向資料來源 A 所擁有的資料
```graphviz
digraph main{
node [shape = record]
A [label = "xs A | <data> string A"]
pointer [label = "pointer"]
pointer -> A:data
}
```
* 配置記憶體給 B 作存放複製的資料
* 把 pointer 指向的資料複製進 B
```graphviz
digraph main{
node [shape = record]
subgraph cluster_1 {
label = "pointer"
data [label = "string A"]
}
B [label = "xs B | <data> allocated"]
data -> B:data[label = " copy"]
}
```
* 複製完後,讓 pointer 重新指向複製的資料。
```graphviz
digraph main{
node [shape = record]
subgraph cluster_1 {
label = "pointer"
data [label = "string A (copy)"]
}
B [label = "xs B | <data> string A (copy)"]
B:data -> data[label = " assign"]
}
```
* 但這沒有滿足所要的 lazy copy ,亦即複製時是 shadow copy。
* 此函式的作用只有分配記憶體並複製以即使 `char **data` 所擁有的指標指向複製的資料而已。
* 因此可以改成不以字串獨立出 `xs` 結構作操作,而是直接以原始資料與複製目的地作操作。
* 而且原始資料的 reference count 在複製時也增加,以紀錄有多少物件共通使用此資料。
* 在這裡我也 `xs` 結構所沒使用到的 `flag2` 改成 `sharing` ,紀錄複製物件所使用的資料不是自己的。
* 而 `flag3` 則是改成 `source` 來紀錄來源物件的資料是有被其他物件使用到。
```cpp
bool xs_cow_copy(xs *dest, xs *src) {
if (xs_is_ptr(src) && xs_is_large_string(src)) {
if (!dest->sharing)
xs_free(dest);
memcpy(dest, src, sizeof(xs));
dest->sharing = true;
xs_set_refcnt(dest, 1);
xs_inc_refcnt(src);
return true;
}
return false;
}
```
* xs_concat
* 此函式在字串串接,以目標物件目前所擁有的記憶體大小作區分。
* 若是最後大小小於等於 `capacity` 直接複製,再判斷是否是大字串還是小字串來作字串長度的處理。
* 若是大於則重新分配。
```cpp
xs *xs_concat(xs *string, const xs *prefix, const xs *suffix)
{
size_t pres = xs_size(prefix), sufs = xs_size(suffix),
size = xs_size(string), capacity = xs_capacity(string);
char *pre = xs_data(prefix), *suf = xs_data(suffix),
*data = xs_data(string);
xs_cow_lazy_copy(string, &data);
if (size + pres + sufs <= capacity) {
memmove(data + pres, data, size);
memcpy(data, pre, pres);
memcpy(data + pres + size, suf, sufs + 1);
if (xs_is_ptr(string))
string->size = size + pres + sufs;
else
string->space_left = 15 - (size + pres + sufs);
} else {
xs tmps = xs_literal_empty();
xs_grow(&tmps, size + pres + sufs);
char *tmpdata = xs_data(&tmps);
memcpy(tmpdata + pres, data, size);
memcpy(tmpdata, pre, pres);
memcpy(tmpdata + pres + size, suf, sufs + 1);
xs_free(string);
*string = tmps;
string->size = size + pres + sufs;
}
return string;
}
```
* `xs_cow_lazy_copy` 是多餘的。
* xs_trim
* 此函式最主要的地方是在如何紀錄要消除的字元以及如何檢測。
* 在此,是以字元本身的 bit 數來判斷。
* 例如紀錄字元 `A` ($65_{10}$ or $100 0001_2$) :
* set_bit: mask[65/8] = mask[65/8] | 1 << 65 % 8
* set_bit: mask[0100 0001 >> 3] = 0000 0000 | 0000 0001 << (0100 0001 & 0000 0111)
* set_bit: mask[8] = 0000 0010
* 接下來在 檢測時 (check_bit) 逆向執行此操作來看有沒有符合:
* 例子 `A` ($65_{10}$ or $100 0001_2$) :
* check_bit: mask[8] = 0000 0010
* !(0000 0010 & 0000 0001 << 1) 為否( !(true) ),跳過此字元。
* 例子 `B` ($66_{10}$ or $100 0010_2$) :
* !(0000 0010 & 0000 0001 << 2) 為是( !(false) ),中止。
* 最後頭尾都做一遍,便達到此目的。
* 關於記憶體操作則是設 `orig` 紀錄原先指標的位置。
* 再利用 `dataptr` 和 `slen` 指向剩下所需的字串與其長度。
* 最後,把剩下所需的字串位移到 `orig` 即完成。
```cpp
xs *xs_trim(xs *x, const char *trimset)
{
if (!trimset[0])
return x;
char *dataptr = xs_data(x), *orig = dataptr;
if (xs_cow_lazy_copy(x, &dataptr))
orig = dataptr;
/* similar to strspn/strpbrk but it operates on binary data */
uint8_t mask[32] = {0};
#define check_bit(byte) (mask[(uint8_t) byte / 8] & 1 << (uint8_t) byte % 8)
#define set_bit(byte) (mask[(uint8_t) byte / 8] |= 1 << (uint8_t) byte % 8)
size_t i, slen = xs_size(x), trimlen = strlen(trimset);
for (i = 0; i < trimlen; i++)
set_bit(trimset[i]);
for (i = 0; i < slen; i++)
if (!check_bit(dataptr[i]))
break;
for (; slen > 0; slen--)
if (!check_bit(dataptr[slen - 1]))
break;
dataptr += i;
slen -= i;
/* reserved space as a buffer on the heap.
* Do not reallocate immediately. Instead, reuse it as possible.
* Do not shrink to in place if < 16 bytes.
*/
memmove(orig, dataptr, slen);
/* do not dirty memory unless it is needed */
if (orig[slen])
orig[slen] = 0;
if (xs_is_ptr(x))
x->size = slen;
else
x->space_left = 15 - slen;
return x;
#undef check_bit
#undef set_bit
}
```
* 此函式可以在 `byte / 8` 和 `byte % 8` 時改進成 `byte >> 3` 和 `byte & 7` 。
* 且 `xs_cow_lazy_copy` 是多餘的。
:::info
Reference
* [DCL03-C. Use a static assertion to test the value of a constant expression](https://wiki.sei.cmu.edu/confluence/display/c/DCL03-C.+Use+a+static+assertion+to+test+the+value+of+a+constant+expression)
* [cppreferenc.com - _Static_assert](https://en.cppreference.com/w/c/language/_Static_assert)
:::
---
## 2 提供字串複製 (CoW) 實作
我針對 copy on write 設定兩個參數其一為 `sharing` 表示字串是不是共通的亦即別人的,另一個是 `source` 表示是否為來源字串。
在對字串進行操作時若是 CoW 則使用 `xs_cow_write_trim` 和 `xs_cow_write_concat` 兩個 marco 來處理。
缺點是對複製字串進行操作時須知道他的來源字串為何,才可對來源作 `xs_dec_refcnt` 等操作。
```cpp
bool xs_cow_copy(xs *dest, xs *src) {
if (xs_is_ptr(src) && xs_is_large_string(src)) {
if (!dest->sharing)
xs_free(dest);
memcpy(dest, src, sizeof(xs));
dest->sharing = true;
xs_set_refcnt(dest, 1);
xs_inc_refcnt(src);
return true;
}
return false;
}
void __xs_cow_write(xs *dest, xs *src) {
if (!xs_is_ptr(dest) && !xs_is_ptr(src) && !strncmp(xs_data(dest), xs_data(src), xs_size(src)))
return;
dest->sharing = false;
char *temp = xs_data(dest);
xs_allocate_data(dest, dest->size, 0);
memcpy(xs_data(dest), temp, xs_size(dest));
xs_dec_refcnt(src);
if (xs_get_refcnt(src) < 1)
xs_free(src);
else if (xs_get_refcnt(src) == 1)
src->source = false;
}
#define xs_cow_write_trim(cpy, trimeset, src) \
do { \
__xs_cow_write(cpy, src); \
xs_trim(cpy, trimeset); \
} while (0)
#define xs_cow_write_concat(cpy, prefix, suffix, src) \
do { \
__xs_cow_write(cpy, src); \
xs_concat(cpy, prefix, suffix); \
} while (0)
```
```cpp
xs *xs_new(xs *x, const void *p)
{
*x = xs_literal_empty();
size_t len = strlen(p) + 1;
if (len > 16) {
x->capacity = ilog2(len) + 1;
x->size = len - 1;
x->is_ptr = true;
x->sharing = false;
x->source = false;
xs_allocate_data(x, x->size, 0);
memcpy(xs_data(x), p, len);
} else {
memcpy(x->data, p, len);
x->space_left = 15 - (len - 1);
}
return x;
}
```
:::info
Reference
* [wikipedia - Reference counting](https://en.wikipedia.org/wiki/Reference_counting)
* [wikipedia - Copy-on-write](https://en.wikipedia.org/wiki/Copy-on-write#In_software)
* [wikipedia - Object copying](https://en.wikipedia.org/wiki/Object_copying#Lazy_copy)
* [stackoverflow - why lazy copy when we have deep copy and shallow copy?](https://stackoverflow.com/questions/7698312/why-lazy-copy-when-we-have-deep-copy-and-shallow-copy)
:::
## 3 實驗 : 字串空間效率最佳化
> 完整[程式碼](https://github.com/linD026/linux2021_homework_quiz3_xs/blob/main/xs.c)。
### 實驗一 : 記憶體空間
* 設字串長度為 261,分別比較 `malloc` 和 `xs_new` 後在進行複製的差異。
* `malloc` 以在建議一個指標 `malloc` 後再 `memcpy` ,`xs` 的複製以 `xs_cow_copy` 為主。
* 可以看到兩者不是差很多,都介於 512 大小。
* malloc 還可以理解,但 xs 結構卻也是 512 這就有點驚訝了。
* 後來仔細檢查後發現,在 `xs_new` 裡的記憶體配置是以 2 的冪來估算 (capacity)。因此 $261 > 256 = 2^8$ 是不夠,會以$261 < 512 = 2^9$ 來分配。
* 這優點在於當要使用更多記憶體可以不用再 `realloc` ,缺點是不需要多的記憶體每次**還是會給你多一倍的空間**,導致**會有相等大小的記憶體沒被使用到**。
```shell
--------------------------------------------------------------------------------
Command: ./malloc_heap
Massif arguments: (none)
ms_print arguments: massif.out.23213
--------------------------------------------------------------------------------
n time(i) total(B) useful-heap(B) extra-heap(B) stacks(B)
--------------------------------------------------------------------------------
0 0 0 0 0 0
1 141,867 280 261 19 0
2 141,956 304 269 35 0
--------------------------------------------------------------------------------
Command: ./xs_heap
Massif arguments: (none)
ms_print arguments: massif.out.23338
--------------------------------------------------------------------------------
n time(i) total(B) useful-heap(B) extra-heap(B) stacks(B)
--------------------------------------------------------------------------------
0 0 0 0 0 0
1 142,054 536 516 20 0
```
* 根據老師所說
> 因此還需要設計 reclaim
* 設計了能夠調整記憶體大小的函式。並且把目前可以以 `reference count` 取代的 `source` 改成 `reclaim` 。
* 當 `xs *x` 的字串儲存結構為指標且不是 `CoW` 的 `shadow copy` 則可以進行調整成適當大小的空間。
* 在測試時,發現調整過的大字串的記憶體大小確實縮小成符合自身的 `264` ,但**多餘的記憶體 `272` 並沒有馬上被釋放**,而是先放在 `extra-heap` 之中。
* 之後修改函式讓其調整回原先記憶體大小,可以看到當有需要的時候會直接從中 (`extra-heap`) 拿取。
```cpp
void xs_reclaim_data(xs *x, bool fixed) {
if (!xs_is_ptr(x) || x->sharing)
return;
if (fixed) {
if (xs_is_large_string(x))
x->ptr = realloc(x->ptr, x->size + 4);
else
x->ptr = realloc(x->ptr, x->size);
x->reclaim = true;
} else {
if (xs_is_large_string(x))
x->ptr = realloc(x->ptr, (size_t)(1 << x->capacity) + 4);
else
x->ptr = realloc(x->ptr, (size_t)(1 << x->capacity));
x->reclaim = false;
}
}
// xs_reclaim_data(&string, 1);
// xs_reclaim_data(&string, 0);
```
```shell
--------------------------------------------------------------------------------
n time(i) total(B) useful-heap(B) extra-heap(B) stacks(B)
--------------------------------------------------------------------------------
1 142,468 536 516 20 0
2 142,692 536 516 20 0
3 142,692 536 264 272 0
4 142,800 536 516 20 0
```
### 實驗二 : 小字串 的 locality of reference
> 完整[程式碼](https://github.com/linD026/linux2021_homework_quiz3_xs/blob/main/main.c)以及[分析報告](https://github.com/linD026/linux2021_homework_quiz3_xs/blob/main/perf.txt)。
* 測試小字串儲存在 `stack` (`opt_store`) 和 `heap` (`normal_store`) 之中,所呈現的效能差異。
* 為了模擬字串操作對記憶體的使用,在測試時 `stack` 和 `heap` 都會進行以下操作:
```cpp
// step one, create small string
// step two, create midium string
// step three, create large string
// step four, print midium string
// step five, copy large string
// step six, print small string
// step seven, print large string
```
* 關於各字串內容:
```cpp
// len 261
#define large_string "aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa"
// len 18
#define midium_string "aaaaaaaaaaaaaaaaa"
// len 9
#define small_string "aaaaaaaa"
#define NUM 1024
```
* 第一次測試時,只有對小字串作一次存取兩者差異不會很大。
* 初步猜測是因為記憶體使用率不高,`stack` 和 `heap` 的字串都可以直接儲存在 `cache` 裡。
```shell
Performance counter stats for './opt_store' (100000 runs):
2047 cache-misses # 4.317 % of all cache refs ( +- 0.27% )
4,7416 cache-references ( +- 0.01% )
71,3257 instructions # 0.85 insn per cycle ( +- 0.07% )
83,5205 cycles ( +- 0.04% )
47,7950 ref-cycles ( +- 0.05% )
0 mem-loads ( +- 4.84% )
8,6014 mem-stores ( +- 0.00% )
0.00034325 +- 0.00000775 seconds time elapsed ( +- 2.26% )
----------------------------------------------------------------------------------------
Performance counter stats for './normal_store' (100000 runs):
2172 cache-misses # 4.597 % of all cache refs ( +- 0.26% )
4,7256 cache-references ( +- 0.01% )
71,2467 instructions # 0.85 insn per cycle ( +- 0.00% )
83,3951 cycles ( +- 0.02% )
47,6457 ref-cycles ( +- 0.04% )
0 mem-loads ( +- 4.68% )
8,5965 mem-stores ( +- 0.00% )
0.000328804 +- 0.000000150 seconds time elapsed ( +- 0.05% )
```
* 如果細部檢測 `L1` 是可以明顯到看兩著並無太大落差:
```shell
Performance counter stats for './opt_store' (100 runs):
19,4656 L1-dcache-loads ( +- 0.12% )
1,4042 L1-dcache-load-misses # 7.21% of all L1-dcache hits ( +- 0.24% )
8,6271 L1-dcache-stores ( +- 0.11% )
0.00032419 +- 0.00000350 seconds time elapsed ( +- 1.08% )
----------------------------------------------------------------------------------------
Performance counter stats for './normal_store' (100 runs):
19,4097 L1-dcache-loads ( +- 0.12% )
1,4054 L1-dcache-load-misses # 7.24% of all L1-dcache hits ( +- 0.22% )
8,6072 L1-dcache-stores ( +- 0.12% )
0.00042350 +- 0.00000292 seconds time elapsed ( +- 0.69% )
```
* 後來改了小字串的儲存結構,從單一字串變為 `NUM` 大小的字串陣列,分別是:
`char *small[NUM] = {0};` 和 `xs small[NUM];`
* 而在 `print` 出小字串的步驟,則選擇陣列的 `NUM/2` 小字串。
* 會這樣做是因為要讓記憶體使用率提昇,讓儲存在 `stack` 和 `heap` 所擁有的特徵提高。
* 更改過後,可以看到 `L1` 確實有差異性了:
```shell
array 1024
Performance counter stats for './opt_store_arr' (100 runs):
23,3280 L1-dcache-loads ( +- 0.11% )
1,4786 L1-dcache-load-misses # 6.34% of all L1-dcache hits ( +- 0.18% )
10,6816 L1-dcache-stores ( +- 0.10% )
0.00034444 +- 0.00000345 seconds time elapsed ( +- 1.00% )
----------------------------------------------------------------------------------------
Performance counter stats for './normal_store_arr' (100 runs):
25,8083 L1-dcache-loads ( +- 0.12% )
1,5460 L1-dcache-load-misses # 5.99% of all L1-dcache hits ( +- 0.21% )
12,9397 L1-dcache-stores ( +- 0.11% )
0.00035670 +- 0.00000351 seconds time elapsed ( +- 0.98% )
```
```shell
array 1024 -O0
Performance counter stats for './opt_store_arr' (100000 runs):
2303 cache-misses # 4.654 % of all cache refs ( +- 0.28% ) (96.63%)
4,9472 cache-references ( +- 0.01% )
84,9043 instructions # 0.93 insn per cycle ( +- 0.06% )
91,1753 cycles ( +- 0.04% )
52,0356 ref-cycles ( +- 0.05% )
0 mem-loads ( +- 4.81% )
10,6827 mem-stores ( +- 0.00% )
<not counted> L1-dcache-loads ( +- 1.29% ) (3.37%)
<not counted> L1-dcache-load-misses (0.00%)
<not counted> L1-dcache-stores (0.00%)
0.000352127 +- 0.000000180 seconds time elapsed ( +- 0.05% )
----------------------------------------------------------------------------------------
Performance counter stats for './normal_store_arr' (100000 runs):
2343 cache-misses # 4.673 % of all cache refs ( +- 0.28% ) (96.37%)
5,0143 cache-references ( +- 0.01% )
99,9849 instructions # 1.03 insn per cycle ( +- 0.00% )
97,0846 cycles ( +- 0.02% )
55,8482 ref-cycles ( +- 0.05% )
0 mem-loads ( +- 4.86% )
12,9219 mem-stores ( +- 0.00% )
<not counted> L1-dcache-loads ( +- 1.21% ) (3.63%)
<not counted> L1-dcache-load-misses (0.00%)
<not counted> L1-dcache-stores (0.00%)
0.000371690 +- 0.000000226 seconds time elapsed ( +- 0.06% )
```
* 只是更改儲存位置卻可以明顯看出在 `cache-misses`, `cache-references`, `instructions、cycles`, `ref-cycles` ,存放於 `stack` 的實作都比在 `heap` 好。
* 關於此差距,從 [locality of reference](https://en.wikipedia.org/wiki/Locality_of_reference) 的 `Spatial locality` 可以看出,在使用儲存位置較相近資料時有較好的表現。
### 延伸探討
> 以下若非特別聲明皆引自 [stackoverflow - Is accessing data in the heap faster than from the stack?
](https://stackoverflow.com/questions/24057331/is-accessing-data-in-the-heap-faster-than-from-the-stack)
#### stack
##### Allocation and deallocation
* 編譯時期編譯器已把資料和函式一併建構。
> For stack-based data, **the stack-pointer-register-relative address can also be calculated and hardcoded at compile time.** Then the stack-pointer-register may be adjusted by the total size of function arguments, local variables, return addresses and saved CPU registers as the function is entered and returns (i.e. at runtime). Adding more stack-based variables will just change the total size used to adjust the stack-pointer-register, rather than having an increasingly detrimental effect.
##### Layout and Access
* 連續記憶體配置。
> Because the absolute virtual address, or a segment- or stack-pointer-register-relative address can be calculated at compile time for global and stack based data, runtime access is very fast.
>
> If successive lines of your source code list global variables, they'll be arranged in adjacent memory locations (albeit with possible padding for alignment purposes). The same is true for stack-based variables listed in the same function.
* 各執行緒可以有自己的 `stack` (跟執行的函式有關),亦即儲存於自己的 `stack` 的資料只有自己可以讀取。
#### heap
##### Allocation and deallocation
* 執行時期才配置。
* 在資料儲存時如果當下 heap memory 分配不夠,會需要系統呼叫如 sbrk mmap 等巷系統要求更多記憶體。
* 儲存於 heap 的資料並不保證每個位置都會是連續的,這取決於作業系統的實作,也因此在存取時的花費會高於 stack 。
> For heap-based data, a runtime heap allocation library must consult and update its internal data structures to track which parts of the block(s) aka pool(s) of heap memory it manages are associated with specific pointers the library has provided to the application, until the application frees or deletes the memory. If there is insufficient virtual address space for heap memory, it may need to call an OS function like `sbrk` to request more memory (Linux may also call `mmap` to create backing memory for large memory requests, then unmap that memory on `free`/`delete`).
##### Layout and Access
* 讀取資料時,指標以及資料本身都要在 cache 裡,且兩者通常會是不連續位置。
* 不連續記憶體以及間接存取皆會使 cache misses 上升。
> For the heap access, both the pointer and the heap memory must be in registers for the data to be accessible (so there's more demand on CPU caches, and at scale - more cache misses/faulting overheads).
>
> With heap hosted data, the program has to access the data via a runtime-determined pointer holding the virtual memory address on the heap, sometimes with an offset from the pointer to a specific data member applied at runtime. That may take a little longer on some architectures.
* 多執行緒下,儲存於 heap 的資料各執行緒都可以看到。
#### 總結
> 
> [geeksforgeeks.org](https://www.geeksforgeeks.org/stack-vs-heap-memory-allocation/)
資料存放於 stack 和 heap 的成本在配置記憶體、存取與儲存形式都有很大的落差。
其中,維護儲存於不連續記憶體( heap )的成本,確實高於 stack 。
關於相關詳細比較,那篇 stackoverflow 的下方也有人提及兩者效能表現比較的文章:
> [Stack allocation vs heap allocation – performance benchmark](https://publicwork.wordpress.com/2019/06/27/stack-allocation-vs-heap-allocation-performance-benchmark/)
> 
:::info
Reference
* [wikipedia - Locality of reference : Spatial and temporal locality usage](https://en.wikipedia.org/wiki/Locality_of_reference#Spatial_and_temporal_locality_usage)
* [stackoverflow - How does Linux perf calculate the cache-references and cache-misses events](https://stackoverflow.com/questions/55035313/how-does-linux-perf-calculate-the-cache-references-and-cache-misses-events)
* [brendangregg.com - perf examples](http://www.brendangregg.com/perf.html)
* [easyperf.net - Performance analysis vocabulary.](https://easyperf.net/blog/2018/09/04/Performance-Analysis-Vocabulary)
* [pcsuggest.com - 4 ways to disable NMI watchdog in Linux](https://www.pcsuggest.com/disable-nmi-watchdog-linux/)
* [HackMD - perf 原理和實務](https://hackmd.io/@sysprog/gnu-linux-dev/https%3A%2F%2Fhackmd.io%2Fs%2FB11109rdg)
* [geeksforgeeks.org - Stack vs Heap Memory Allocation](https://www.geeksforgeeks.org/stack-vs-heap-memory-allocation/)
* [stackoverflow - Is accessing data in the heap faster than from the stack?](https://stackoverflow.com/questions/24057331/is-accessing-data-in-the-heap-faster-than-from-the-stack)
* [publicwork.wordpress.com - Stack allocation vs heap allocation – performance benchmark](https://publicwork.wordpress.com/2019/06/27/stack-allocation-vs-heap-allocation-performance-benchmark/)
* [stackoverflow - Dynamic allocation store data in random location in the heap?](https://stackoverflow.com/questions/55194751/dynamic-allocation-store-data-in-random-location-in-the-heap)
* [medium.com - Understanding Memory Layout](https://medium.com/@shoheiyokoyama/understanding-memory-layout-4ef452c2e709)
* [www.cs.princeton.edu - Memory Management - Jennifer Rexford](https://www.cs.princeton.edu/courses/archive/spr11/cos217/lectures/18MemoryMgmt.pdf)
:::
## 4 整合 - 字串空間最佳化
整合第二周的 `string interning` 和第三周的`xs` 。
* `hash table` 管理的節點結構更改:
```cpp
struct __cstr_node {
xs str;
uint32_t hash_size;
struct __cstr_node *next;
};
```
* 小字串直接建立。但當使用長度達到中字串以及大字串時,放入至 `hash table` 裡控管。
* `cstr_interning` 會回傳 `hash table` 中紀錄的節點所擁有的 `xs` 。
* `xs_new` 則是將其複製。
* 此函式的功能不再只是建立字串,而是在中字串以及大字串的範圍下建立 `hash table` 的資料。
```cpp
xs *xs_new(xs *x, const void *p) {
size_t len = strlen(p) + 1;
if (len > 16) {
xs *temp = cstr_interning((char *)p, len - 1, hash_blob((char *)p, len - 1));
memcpy(x, temp, sizeof(xs));
} else {
*x = xs_literal_empty();
memcpy(x->data, p, len);
x->space_left = 15 - (len - 1);
}
return x;
}
```
* 在 `interning` ,新建的節點操作是建立後,再對記憶體 `reclaim` 成適當大小。
* 當然也可以直接分配適當大小的記憶體,在此我先活用現有的函式。
```cpp=113
n = &si->pool->node[si->index++];
n->hash_size = hash;
n->str = xs_literal_empty();
n->str.capacity = ilog2(sz) + 1;
n->str.size = sz;
n->str.is_ptr = true;
n->str.sharing = false;
n->str.reclaim = false;
xs_allocate_data(&n->str, n->str.size, 0);
memcpy(xs_data(&n->str), cstr, sz + 1);
xs_reclaim_data(&n->str, 1);
n->str.sharing = true;
n->next = si->hash[index];
si->hash[index] = n;
```
* 關於字串操作,中字串以及大字串所有的資訊除了字串本身是指向 `hash table` 的資料,其他都是副本,因此在操作的前置動作只須對指標以及原先資料的 `reference count` 作處理就行。
* 操作結束後,透過 `xs_new` 來建立 `hash table` 裡資料,原先物件則釋放掉。
* 最後是包裝成 `marco` :
```cpp
#define xs_cow_write_trim(cpy, trimeset) \
do { \
__xs_cow_write(cpy); \
xs_trim(cpy, trimeset); \
__xs_cow_write_end(cpy); \
} while (0)
```
```cpp
void __xs_cow_write(xs *dest) {
if (!xs_is_ptr(dest) && !dest->sharing)
return;
CSTR_LOCK();
xs *src =
interning(&__cstr_ctx, xs_data(dest), xs_size(dest), hash_blob(xs_data(dest), xs_size(dest)));
xs_dec_refcnt(src);
if (xs_get_refcnt(src) < 0)
xs_set_refcnt(src, 0);
CSTR_UNLOCK();
dest->sharing = false;
char *temp = xs_data(dest);
xs_allocate_data(dest, dest->size, 0);
memcpy(xs_data(dest), temp, xs_size(dest));
}
void __xs_cow_write_end(xs *dest) {
xs tmp;
xs_new(&tmp, xs_data(dest));
dest->sharing = false;
xs_set_refcnt(dest, 0);
xs_free(dest);
memcpy(dest, &tmp, sizeof(xs));
}
```
* **需注意幾點**
* `hash table` 的資料不會被刪除。
* 讀取 `hash table` 資料:
* 如果是要副本須透過 `xs_new` 。
* 如果是 `hash table` 裡的原始資料則為 `cstr_interning` 。
* 中大字串一定要藉由包裝過的 marco 如 `xs_cow_write_trim` 來操作。
* 並沒有限制 `xs_trim` 等直接操作,因此小字串直接操作即可。
* 小字串在 `xs_concat` 成長為中大字串時,會自動寫入 `hash table` ,並且使用者拿到的 `xs` 會是副本。
* 如果 `xs` 的物件利用 `xs_grow` 擴大記憶體,則物件不會紀錄至 `hash table` 。
* 最後,我也保留了原先 CoW 操作的函式:
```cpp
xs *xs_new_self(xs *x, const void *p);
bool xs_cow_copy_self(xs *dest, xs *src);
void __xs_cow_write_self(xs *dest, xs *src);
xs *xs_concat_self(xs *string, const xs *prefix, const xs *suffix);
```
* 因此 `xs_tmp` 可以改成 `xs_new_self` 的建立,如果想要自己釋放掉且不想被儲存的話。
```cpp
#define xs_tmp_self(x) \
((void)((struct { \
_Static_assert(sizeof(x) <= MAX_STR_LEN, "it is too big"); \
int dummy; \
}){1}), \
xs_new_self(&xs_literal_empty(), x))
```
> 完整程式碼: [linD026](https://github.com/linD026/linux2021_homework_quiz3_xstring)
---
## 5 Linux 核心 內部實例
### fork
* 實作手法為 copy on write 。
> DESCRIPTION
> fork() creates a new process by duplicating the calling process. The new process is referred to as the child process. The calling process is referred to as the parent process.
>
> The child process and the parent process run in separate memory spaces. At the time of fork() both memory spaces have the same content. Memory writes, file mappings ([mmap(2)](https://man7.org/linux/man-pages/man2/mmap.2.html)), and unmappings ([munmap(2)](https://man7.org/linux/man-pages/man2/munmap.2.html)) performed by one of the processes do not affect the other.
> [UNIX 作業系統 fork/exec 系統呼叫的前世今生](https://hackmd.io/@sysprog/unix-fork-exec)
* 有趣的是 fork 的 CoW 操作需要 [MMU](http://www.cs.unc.edu/~porter/courses/cse306/s16/lab2.html) 的幫助。因此在如 [uclinux](http://wiki.csie.ncku.edu.tw/embedded/uclinux) 等架構下,沒辦法使用 fork 而是需要 **vfork** 來操作。
* 在下方引述資料可以看到,因為 vfork 的實作, child 對記憶體的改變也會在 parent 顯現。
> With vfork(), the parent process is suspended, and the child process uses the address space of the parent. Beacuse vfork() does not use copy-on-write, if the child process changes any pages of the parent's address space, the altered pages will be visible to the parent once it resumes.
> 引自:[Operating System Concepts 10th Edition Asia Edition - page 400](https://www.wiley.com/en-sg/Operating+System+Concepts%2C+10th+Edition%2C+Asia+Edition-p-9781119586166)
>
> Historic description
> Under Linux, fork(2) is implemented using copy-on-write pages, so the only penalty incurred by fork(2) is the time and memory required to duplicate the parent's page tables, and to create a unique task structure for the child. However, in the bad old days a fork(2) would require making a complete copy of the caller's data space, often needlessly, since usually immediately afterward an exec(3) is done. Thus, for greater efficiency, BSD introduced the vfork() system call, which did not fully copy the address space of the parent process, but borrowed the parent's memory and thread of control until a call to execve(2) or an exit occurred. The parent process was suspended while the child was using its resources. The use of vfork() was tricky: for example, not modifying data in the parent process depended on knowing which variables were held in a register.
> 引自: **Linux Programmer's Manual - vfork()**
:::info
Reference
* [成大資工wiki - uclinux](http://wiki.csie.ncku.edu.tw/embedded/uclinux)
* [cs.unc.edu - CSE 306: Lab 2: Copy-on-Write Fork](http://www.cs.unc.edu/~porter/courses/cse306/s16/lab2.html)
* [Operating System Concepts 10th Edition Asia Edition - page 400](https://www.wiley.com/en-sg/Operating+System+Concepts%2C+10th+Edition%2C+Asia+Edition-p-9781119586166)
相關閱讀
* [geeksforgeeks.org - Difference between fork() and vfork()](https://www.geeksforgeeks.org/difference-between-fork-and-vfork/)
:::
### page
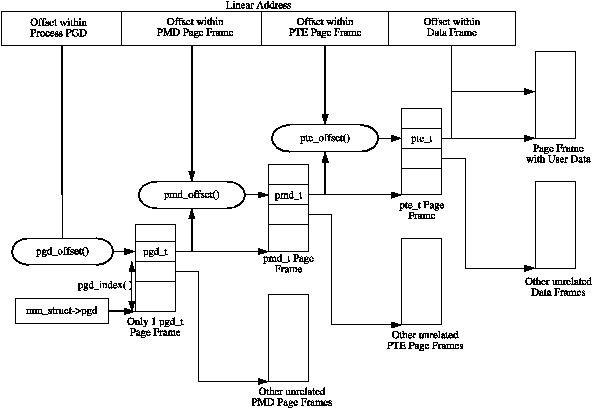
一個 process 對一塊 page 讀取時,根據不同硬體架構會有特定的 page table 來讀取。
> **Each process a pointer (mm_struct→pgd) to its own Page Global Directory (PGD) which is a physical page frame. This frame contains an array of type pgd_t which is an architecture specific type defined in <asm/page.h>. The page tables are loaded differently depending on the architecture.** On the x86, the process page table is loaded by copying mm_struct→pgd into the cr3 register which has the side effect of flushing the TLB. In fact this is how the function __flush_tlb() is implemented in the architecture dependent code.
> 
> [kernel.org - Chapter 3 Page Table Management](https://www.kernel.org/doc/gorman/html/understand/understand006.html)
而當多個 process 共用一個 page frame 時,則會採用 CoW :
> 
> [Operating system support in distributed system](https://www.slideshare.net/ishapadhy/operating-system-support-in-distributed-system)
> > 此投影片主要講 threads in distributed system
#### 硬體架構
* [linux kernel source tree - root/arch/x86/include/asm/page.h](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/arch/x86/include/asm/page.h?h=v5.12-rc4)
```cpp
#ifndef __pa
#define __pa(x) __phys_addr((unsigned long)(x))
#endif
#ifndef __va
#define __va(x) ((void *)((unsigned long)(x)+PAGE_OFFSET))
#endif
```
* [linux kernel source tree - root/include/asm-generic/page.h](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/include/asm-generic/page.h?h=v5.12-rc4)
* 在 `generic page.h` 的註解可以看到,這用於` NOMMU architectures` 。
```cpp
/*
* Generic page.h implementation, for NOMMU architectures.
* This provides the dummy definitions for the memory management.
*/
```
#### 實作層級
* [linux kernel source tree - root/include/linux/pgtable.h](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/include/linux/pgtable.h?h=v5.12-rc4)
* [linux kernel source tree - root/include/linux/pagemap.h](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/include/linux/pagemap.h?h=v5.12-rc4)
* [linux kernel source tree - root/arch/x86/include/asm/io.h](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/arch/x86/include/asm/io.h?h=v5.12-rc4#n116)
```cpp
/**
* virt_to_phys - map virtual addresses to physical
* @address: address to remap
*
* The returned physical address is the physical (CPU) mapping for
* the memory address given. It is only valid to use this function on
* addresses directly mapped or allocated via kmalloc.
*
* This function does not give bus mappings for DMA transfers. In
* almost all conceivable cases a device driver should not be using
* this function
*/
static inline phys_addr_t virt_to_phys(volatile void *address)
{
return __pa(address);
}
#define virt_to_phys virt_to_phys
/**
* phys_to_virt - map physical address to virtual
* @address: address to remap
*
* The returned virtual address is a current CPU mapping for
* the memory address given. It is only valid to use this function on
* addresses that have a kernel mapping
*
* This function does not handle bus mappings for DMA transfers. In
* almost all conceivable cases a device driver should not be using
* this function
*/
static inline void *phys_to_virt(phys_addr_t address)
{
return __va(address);
}
#define phys_to_virt phys_to_virt
```
* [linux kernel source tree - root/mm/filemap.c](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/mm/filemap.c?h=v5.12-rc4#n71)
#### sharing page table
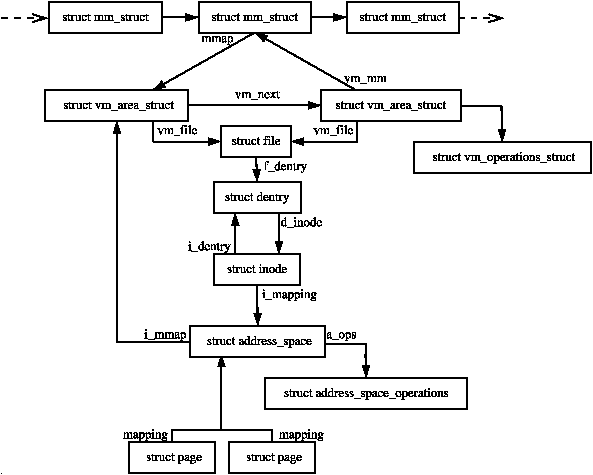
##### `mm_struct`
* 每個 user-address-space 都有一個。
* 記錄所有記憶體相關資訊,不管是本身記錄或是間接紀錄( pointer )。
##### `vm_area_struct` / vmas
* 每個相同檔案的 backing, permissions, and sharing characteristics 的記憶體區塊都有一個。
* 必要時可做分離與合併。
* 與 mm_struct 連結,且有排序:
> There is a single chain of vmas attached to the mm_struct that describes the entire address space, sorted by address. This chain also can be collected into a tree for faster lookup.
* 紀錄:
* same characteristics
* starting and ending virtual addresses of the range
* file and offset into it if it is file-backed
* set of flags
* shared or private
* writeable
##### The page table
* 分三個層級:
* the page directory ( pgd )
* the page middle directory ( pmd )
* the page table entries ( pte )
* Each level is an array of entries contained within a single physical page
##### `address_space`
> address_space structure is the anchor for all mappings related to the file object. It contains links to every vma mapping this file, as well as links to every physical page containing data from the file.
> The only vmas not attached to an address_space are the ones describing the stack and the ones describing the bss space for the application and each shared library. These are called the ’anonymous’ vmas and are backed directly by swap space.
##### `page`
> All physical pages in the system have a structure that contains all the metadata associated with the page.
* [bootlin.com - /include/linux/mm_types.h](https://elixir.bootlin.com/linux/v4.6/source/include/linux/mm_types.h#L31)
```cpp
/*
* Each physical page in the system has a struct page associated with
* it to keep track of whatever it is we are using the page for at the
* moment. Note that we have no way to track which tasks are using
* a page, though if it is a pagecache page, rmap structures can tell us
* who is mapping it.
*
* The objects in struct page are organized in double word blocks in
* order to allows us to use atomic double word operations on portions
* of struct page. That is currently only used by slub but the arrangement
* allows the use of atomic double word operations on the flags/mapping
* and lru list pointers also.
*/
```
##### mapping
* `mmap` 分配一段記憶體空間,此空間以新的或是改寫過的 vma 表示,跟 task 的 `mm_struct` 和 `address_space` 相連。
* `mmap` 呼叫時 The page table 並沒有操作。
##### lock
* 有三個 lock
* `a read/write semaphore` - `mm_struct`
* `page_table_lock` - `mm_struct`
* `i_shared_lock` ( `i_shared_sem` ) - `address_space`
* sharing PTE Page
* page_table_lock 沒辦法完全保護
* pte_chains ([在 2004 被移除](https://lwn.net/Articles/80868/))
* pte_page_lock 保護
* 也就是說, page_table_lock 只保護到找到想要的 pte page ,之後由 pte_page_lock 保護。
```cpp
/*
* A file's MAP_PRIVATE vma can be in both i_mmap tree and anon_vma
* list, after a COW of one of the file pages. A MAP_SHARED vma
* can only be in the i_mmap tree. An anonymous MAP_PRIVATE, stack
* or brk vma (with NULL file) can only be in an anon_vma list.
*/
struct list_head anon_vma_chain; /* Serialized by mmap_sem &
* page_table_lock */
struct anon_vma *anon_vma; /* Serialized by page_table_lock */
```
> [bootlin.com - /include/linux/mm_types.h](https://elixir.bootlin.com/linux/v4.6/source/include/linux/mm_types.h#L335)
> 
> [kernel.org - Chapter 4 Process Address Space](https://www.kernel.org/doc/gorman/html/understand/understand007.html)
:::warning
然而**上述資料有點舊**,跟現況不太符合。
> [Sharing Page Tables in the Linux Kernel - Dave McCracken IBM Linux Technology Center Austin, TX - 2003](https://www.kernel.org/doc/ols/2003/ols2003-pages-315-320.pdf)
關於 pte_chain 的演進:
> ```
> Process scan
> pte_chain
> Object-based rmap with anon_vma
> Improve anon_vma with anon_vma_chain
> Replace same_anon_vma linked list with an interval tree
> Reuse anon_vma
> ```
> [匿名反向映射的前世今生](https://richardweiyang-2.gitbook.io/kernel-exploring/00-index/01-anon_rmap_history)
**因此,又找了這份投影片來解析 `struct page` 在 CoW 下得操作:**
> [cs.columbia.edu - W4118: Linux memory management](https://www.cs.columbia.edu/~junfeng/13fa-w4118/lectures/l20-adv-mm.pdf)
:::
#### vma
> vma 的整體結構圖
> 
>
> 
>
> 
>
> 
> vma 資料搜尋
> 
>
> 
##### page
> > `struct page` 簡述
> 
> 
> 
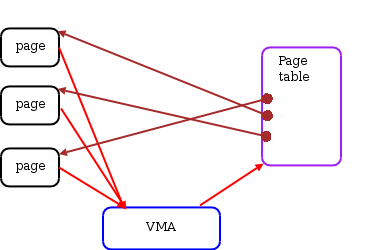
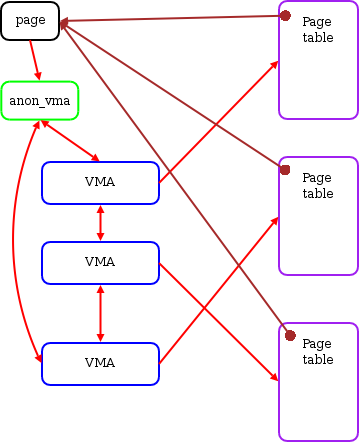
> `anon_vma` 管理 CoW 的 page
> 
> 1. `anon_vma` in action
> 
> 2. `anon_vma` in action
> 
>
> [kernel.org - mm Concepts overview](https://www.kernel.org/doc/html/latest/admin-guide/mm/concepts.html#anonymous-memory)
> **The anonymous memory or anonymous mappings represent memory that is not backed by a filesystem.** Such mappings are implicitly created for program’s stack and heap or by explicit calls to mmap(2) system call.
> Usually, the anonymous mappings only define virtual memory areas that the program is allowed to access. **The read accesses will result in creation of a page table entry that references a special physical page filled with zeroes.** When the program performs a write, a regular physical page will be allocated to hold the written data. The page will be marked dirty and if the kernel decides to repurpose it, the dirty page will be swapped out.
>
> [linux man page - mmap](https://man7.org/linux/man-pages/man2/mmap.2.html)
> 
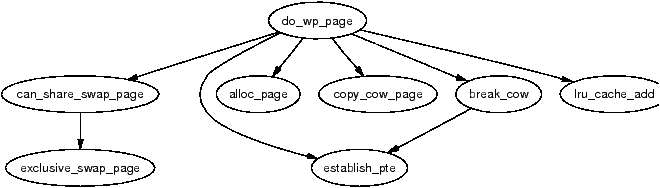
> > page 在 CoW 的操作。
> 
> [kernel.org - Chapter 4 Process Address Space](https://www.kernel.org/doc/gorman/html/understand/understand007.html)
* [bootlin.com - /mm/memory.c - do_wp_page](https://elixir.bootlin.com/linux/v4.6/source/mm/memory.c#L2345)
* 以假設有保護的情況下,進行 CoW
* mark dirty bit
```cpp
/*
* This routine handles present pages, when users try to write
* to a shared page. It is done by copying the page to a new address
* and decrementing the shared-page counter for the old page.
*
* Note that this routine assumes that the protection checks have been
* done by the caller (the low-level page fault routine in most cases).
* Thus we can safely just mark it writable once we've done any necessary
* COW.
*
* We also mark the page dirty at this point even though the page will
* change only once the write actually happens. This avoids a few races,
* and potentially makes it more efficient.
*
* We enter with non-exclusive mmap_sem (to exclude vma changes,
* but allow concurrent faults), with pte both mapped and locked.
* We return with mmap_sem still held, but pte unmapped and unlocked.
*/
```
* 要進行 CoW 的 `old_page` 會先處理 anonymous pages 狀態
```cpp
/*
* Take out anonymous pages first, anonymous shared vmas are
* not dirty accountable.
*/
```
* 複製過後的資料會被移入至 `anon_vma` ,以確保在尋找資料時不會找到 parent 或 siblings
```cpp
/*
* The page is all ours. Move it to
* our anon_vma so the rmap code will
* not search our parent or siblings.
* Protected against the rmap code by
* the page lock.
*/
```
* 如果不是 anonymous page 則會:
```cpp
/*
* Ok, we need to copy. Oh, well..
*/
get_page(old_page);
pte_unmap_unlock(page_table, ptl);
return wp_page_copy(mm, vma, address, page_table, pmd,
orig_pte, old_page);
```
#### 總結
* 一個 `mm_struct` 結構控管多個 `vm_area_struct` , 而其中 `vm_area_struct` 又以資料結構來儲存。( `rbtree` )。
* `vm_area_struct` 的 mapping 可以是 Anonymous mapping 。
* Anonymous mapping 包含了 CoW pages 。
* `vm_area_struct` 再藉由多個資料結構如 `struct inode struct` , `address_space mapping` (priorty tree - `i_mmap`, radix tree - `page_tree`) 等至 struct page 。
* 而 `pages` 的儲存結構為 radix tree 保存於 `address_space` 。(如果要直接對 page 操作的話,方便反向尋找)
* 之後藉由 `do_cp_page` 等函式,搭配 lock 去做 CoW 處理。 ([/mm/memory.c](https://elixir.bootlin.com/linux/v4.6/source/mm/memory.c#L2664))
* 操作完後,有一個分支是執行 `establish_pte` ,建立 page table entry 來提升效率。
> 註:現今實作又改了:
>```cpp
>/**
> * struct address_space - Contents of a cacheable, mappable object.
> * @host: Owner, either the inode or the block_device.
> * @i_pages: Cached pages.
> * @gfp_mask: Memory allocation flags to use for allocating pages.
> * @i_mmap_writable: Number of VM_SHARED mappings.
> * @nr_thps: Number of THPs in the pagecache (non-shmem only).
> * @i_mmap: Tree of private and shared mappings.
> * @i_mmap_rwsem: Protects @i_mmap and @i_mmap_writable.
> * @nrpages: Number of page entries, protected by the i_pages lock.
> * @nrexceptional: Shadow or DAX entries, protected by the i_pages lock.
> * @writeback_index: Writeback starts here.
> * @a_ops: Methods.
> * @flags: Error bits and flags (AS_*).
> * @wb_err: The most recent error which has occurred.
> * @private_lock: For use by the owner of the address_space.
> * @private_list: For use by the owner of the address_space.
> * @private_data: For use by the owner of the address_space.
> */
>struct address_space {
> struct inode *host;
> struct xarray i_pages;
> gfp_t gfp_mask;
> atomic_t i_mmap_writable;
>#ifdef CONFIG_READ_ONLY_THP_FOR_FS
> /* number of thp, only for non-shmem files */
> atomic_t nr_thps;
>#endif
> struct rb_root_cached i_mmap;
> struct rw_semaphore i_mmap_rwsem;
> unsigned long nrpages;
> unsigned long nrexceptional;
> pgoff_t writeback_index;
> const struct address_space_operations *a_ops;
> unsigned long flags;
> errseq_t wb_err;
> spinlock_t private_lock;
> struct list_head private_list;
> void *private_data;
>} __attribute__((aligned(sizeof(long)))) __randomize_layout;
>```
> > [linux kernel 5.11.10](https://elixir.bootlin.com/linux/latest/source/include/linux/fs.h#L451)
* **xarray** ( replace radix tree )
* [lwn.net - The Xarray data structure](https://lwn.net/Articles/745073/)
> The kernel's radix tree is, he said, a great data structure, but it has far fewer users than one might expect. Instead, various kernel subsystems have implemented their own data structures to solve the same problems. He tried to fix that by converting some of those subsystems and found that the task was quite a bit harder than it should be. The problem, he concluded, is that the API for radix trees is bad; it doesn't fit the actual use cases in the kernel.
* radix tree 的概念沒有變,但從 tree 改成 array (an automatically resizing array)
* `unsigned long` 的 array of pointer
* 更改的原因是因為儲存結構以及相關操作的函式太過模糊。
> Part of the issue is that the "tree" terminology is confusing in this case. A radix tree isn't really like the classic trees that one finds in data-structure texts. Addition of an item to a tree has been called "insertion" for decades, for example, but an "insert" doesn't really describe what happens with a radix tree, especially if an item with the given key is already present there. Radix trees also support concepts like "exception entries" that users find scary just because of the naming that was used.
:::info
延伸閱讀
* [Linux 核心設計: RCU 同步機制](https://hackmd.io/@sysprog/linux-rcu?type=view)
:::
最後,實作一直在改進,周遭資訊卻很難跟上。 (譬如 struct address_space 中看起來取代 radix tree 的 [xarray](https://www.mdeditor.tw/pl/pNmC/zh-tw) 沒多少資訊)
光是要找到正確的資訊就好困難。
雖然可以從現今程式碼著手,但在沒整體架構的演進與變化脈絡的知識,真的會看不太懂。
:::info
Reference
* [Operating system support in distributed system](https://www.slideshare.net/ishapadhy/operating-system-support-in-distributed-system)
* [kernel.org - Chapter 3 Page Table Management](https://www.kernel.org/doc/gorman/html/understand/understand006.html)
* [kernel.org - Chapter 4 Process Address Space](https://www.kernel.org/doc/gorman/html/understand/understand007.html)
* [lwn.net - kernel development - Fixing up the shared page table patch](https://lwn.net/Articles/18654/)
* [從 radix tree 到 xarray](https://www.mdeditor.tw/pl/pNmC/zh-tw)
* [lwn.net - rmap 9 remove pte_chains](https://lwn.net/Articles/80868/)
* [cs.columbia.edu - W4118: Linux memory management](https://www.cs.columbia.edu/~junfeng/13fa-w4118/lectures/l20-adv-mm.pdf)
* [匿名反向映射的前世今生](https://richardweiyang-2.gitbook.io/kernel-exploring/00-index/01-anon_rmap_history)
* [static.lwn.net Kernel development - January 24, 2002](https://static.lwn.net/2002/0124/kernel.php3)
* [The Priority Search Tree](https://www.halolinux.us/kernel-architecture/the-priority-search-tree.html)
* [lwn.net - A multi-order radix tree](https://lwn.net/Articles/688130/)
* [Page Cache](http://books.gigatux.nl/mirror/kerneldevelopment/0672327201/ch15lev1sec1.html)
* [lwn.net - Maintainer activity per subsystem](https://lwn.net/Articles/842419/)
* [lwn.net - Fixing up the shared page table patch
](https://lwn.net/Articles/18980/)
* [Sharing Page Tables in the Linux Kernel - Dave McCracken IBM Linux Technology Center Austin, TX - 2003](https://www.kernel.org/doc/ols/2003/ols2003-pages-315-320.pdf)
* [lwn.net - Virtual Memory II: the return of objrmap](https://lwn.net/Articles/75198/)
* [stackoverflow - What are memory mapped page and anonymous page?
](https://stackoverflow.com/questions/13024087/what-are-memory-mapped-page-and-anonymous-page)
相關閱讀 (有訂閱 lwn.net 可以看)
* [**Patching until the COWs come home (part 1)**](https://lwn.net/Articles/849638/)
([Kernel] Posted Mar 22, 2021 16:52 UTC (Mon) by corbet)
The kernel's memory-management subsystem is built upon many concepts, one of which is called "copy on write", or "COW". The idea behind COW is conceptually simple, but its details are tricky and its past is troublesome. Any change to its implementation can have unexpected consequences and cause subt [...]
* [**Patching until the COWs come home (part 2)**](https://lwn.net/Articles/849876/)
([Kernel] Posted Mar 25, 2021 16:30 UTC (Thu) by corbet)
Part 1 of this series described the copy-on-write (COW) mechanism used to avoid unnecessary copying of pages in memory, then went into the details of a bug in that mechanism that could result in the disclosure of sensitive data. A patch written by Linus Torvalds and merged for the 5.8 kernel appear [...]
:::
### btrfs
// TODO
[btrfs wiki](https://btrfs.wiki.kernel.org/index.php/Main_Page)
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet