# Memory Allocation
###### tags: `sysprog`
[討論區連結](https://gitter.im/embedded2015/guts-general)
:::info
主講人: [jserv](http://wiki.csie.ncku.edu.tw/User/jserv) / 課程討論區: [2016 年系統軟體課程](https://www.facebook.com/groups/system.software2016/)
:mega: 返回「[嵌入式作業系統設計與實作](http://wiki.csie.ncku.edu.tw/sysprog/schedule)」課程進度表
:::
- [ ] [雜記: What a C Programmer Should Know About Memory](http://wen00072.github.io/blog/2015/08/08/notes-what-a-c-programmer-should-know-about-memory/)
**動態記憶體分配對Realtime System的影響**
* 一般DSA(Dynamic storage allocation)演算法針對平均執行時˙間做優化,WCET(worst-case execution time)可能很差
* Realtime tasks通常執行時間長(比起non-realtime tasks),fragmentation會對其造成更大的影響
**Glibc malloc()分配記憶體的方式**
* keywords: anonymous memory, break point, buddy memory allocation
* 參考文件: [glibc 記憶體管理行為](http://reborn2266.blogspot.tw/2011/11/linux-user-space.html), Linux system programming Ch.8
* Glibc有兩種分配記憶體方式,依照malloc()記憶體需求參數的大小決定使用哪種(default threshold = 128 KB,可調整)
1. 分配heap上面的空間(使用`brk()`或`sbrk()`) => small allocations
2. 分配anonymous memory(使用`mmap()`) => large allocations
* 相較於file mapping而言,anonymous memory是指沒有對應檔案系統的記憶體區塊,如process的heap和stack
* [memory mapped page and anonymous page](http://stackoverflow.com/questions/13024087/what-are-memory-mapped-page-and-anonymous-page) , [Anonymous Memory](http://flylib.com/books/en/2.830.1.111/1/)
* Heap的結束位址(頂端)稱作break point,可利用`brk()`或`sbrk()`系統呼叫,改變此位址來擴展或縮減heap的大小
* 若heap頂端記憶體空間被分配出去,即使低於它位址的記憶體空間已經被釋放,系統也無法透過`brk()`調整heap size,造成**internal fragmentation**,影響效能
* 若heap頂端為空,且heap size比起其中已被分配的記憶體量大出許多的時候,glibc才會去縮減heap的空間
**membroker**
* 程序彼此合作,透過membroker調節記憶體空間的機制
* membroker記錄了所有client process、每個client已分配的memory大小,以及剩餘的的記憶體總量(global quota),client可以向membroker要求分配記憶體
* 兩種clients
* Simple : 可以request memory與return quota (free)
* Bidirectional : 可以接受membroker的give back請求,釋放自己的quota
* give back可分normal或urgent
* client可能以free cache、garbage collection的方式回應give back
* 兩種request quota
* Low urgency (REQUEST)
* 會等待membroker送normal give back,但無法取得多餘quota時不會block
* 可能會allocate比request更少的memory
* High urgency (RESERVE)
* 送reserve(urgent) give back,無法取得多餘quota時會block
* 若成功,一定會allocate request的量
**System-wide Memory Management for Linux Embedded Systems**
What is anonymous memory?
* buddy memory allocation scheme
brk() is bad for other realtime threads
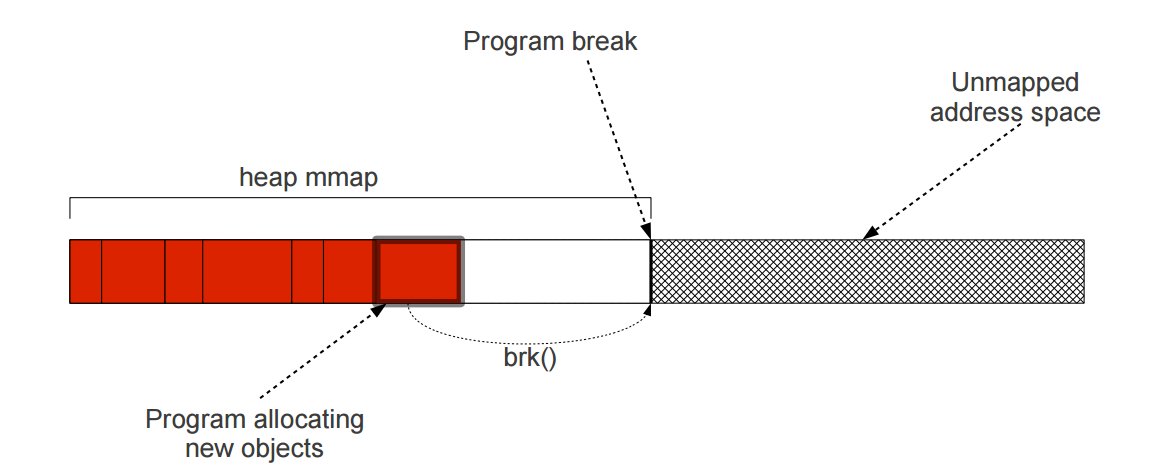
`down_write(current->mm->**mmap_sem**)` 會造成indefinite waiting
Glibc cannot shrink heap until highest allocated object is freed
[VMA](http://www.jollen.org/blog/2007/01/linux_virtual_memory_areas_vma.html)
常用的動態記憶體分配演算法
* Sequential fit(First fit)
* 在free list(list of free block)上依序找尋第一個出現的合適空間,複雜度為O(n)
* free blocks排列的方式會有不同的效果
* 增進locality of reference
* Increasing size(best fit)
* Decreasing size(worst fit)
* Segregated Free Lists
* 基於每個程序的memory request通常只有幾種固定的block size,使用array of blocks儲存多個free lists,每個free list中的block size不同
* Buddy System
* Segregated Free Lists演算法的變形,在記憶體的分割和合併上較有效率
* 分配出去的記憶體區塊大小被限定,通常是最小單位 * k,k通常是2的指數或是費式數列元素
* 會產生很多internal fragmentation
* Indexed Fit
* 採取其他資料結構(例如binary tree)儲存free block資訊(大小、位置等)以改善list在搜尋上的缺點
* Bitmap Fit
* 使用[bitmap](https://www.wikiwand.com/en/Bitmap_index)做為free blocks的索引,佔用空間小(通常為32 bits),可減少cache miss,降低response time
**[TLSF(Two Level Segregated Fit)](http://www.gii.upv.es/tlsf/files/ecrts04_tlsf.pdf)**
* _[Dynamic Storage Allocation� A Survey and Critical Review](http://www.cs.northwestern.edu/~pdinda/icsclass/doc/dsa.pdf) 這篇論文整理了1961-1995關於記憶體分配的研究_
* 結合Segregated Free Lists和Bitmap Fit
* TLSF讓動態記憶體的分配和回收(allocation & deallocation)複雜度能達到Θ(1),同時也減少fragmentation的大小
* 特性
* immediate coalescing
* Good-fit strategy
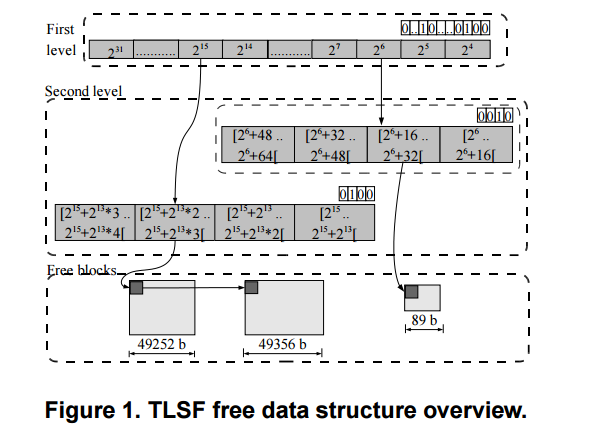
The first-level array divides free blocks in classes that are a power of two apart (16, 32, 64, 128, etc.); and the second-level sub-divides each first-level class linearly.
* [An Improvement of TLSF Algorithm](https://people.kth.se/~roand/tlsf.pdf)
* [TLSF代碼分析](http://blog.csdn.net/william198757/article/details/51452514)
* [tlsf-bsd](https://github.com/jserv/tlsf-bsd): 重新實做的 TLSF,BSD 授權 (而非原本的 GPL)
**TLSF特性的比較**
**dlmalloc / ptmalloc2**
* immediate coalescing
* 在ptmalloc中,fast bin是不立即合併的,此可以增加tiny request的處理速度,省下分割block的時間。TLSF立即合併可減少fragmentation,但降低效能。
* size streagy
* 在ptmalloc中,不同size使用不同的結構,fast與small bin在有block時速度快;但large包含segregated best fit與sorting,可能無法保證worst case。ptmalloc考慮到large request通常並不多,為在有限的free list下減少fragmentation而設計。TLSF則為了保證worst case並降低複雜度而使用相同策略。
* block header
* 兩者的block基本上相同,皆包含size、free list pointer與previous block。但在TLSF中previous block使用pointer而非size,且不會被用於data。
* free list
* ptmalloc使用segregated free lists,並在512bytes以下的bin間距採最小間距,但在large block的覆蓋率相對較小(故需要sort & find)。TLSF為了能使large block保持O(1),故採用現今的雙層結構,增加bin的數量,並利用bitmap降低搜尋所需時間(clz),但在small block則較慢(雙層reference、需要分割)。
* 在[An Improvement of TLSF Algorithm](https://people.kth.se/~roand/tlsf.pdf)中,作者提議在small block也使用最小間距。
* last remainder / unsorted
* 為ptmalloc為利用caching / 提高平均效率所設計,TLSF沒有類似功能。
* ptmalloc不適合real time之處
* 在malloc中,若small /fast沒有exact fit,或large request,ptmalloc會進入consolidate fastbin -> unsorted bin loop -> find best fit的過程,其worst case是無法保證的。
**scalloc**
* O(1) allocation
* 兩者皆有segregated的特性,並皆不包含seearch best fit的成份。TLSF miss時,往上找good fit,並使用clz等加速;scalloc在沒有hot與reusable時,進span-pool找新span,在span-pool miss時,需要loop span-pool。兩者的list大小皆不變,故皆為O(1),worst case則推估為TLSF較佳。
* memory assumption
* TLSF可以在沒有MMU、paging的環境下使用,在有的情況下則可memlock以減少latency。scalloc依賴demand paging運作,幾乎所有的fragmentation都由paging處理。
**Understanding glibc malloc (ptmalloc2)**
**Memory request size**
* 大request(>= 512 bytes) : 使用best-fit的策略,在一個range(bin)的list中尋找
* 小request(<= 64 bytes) : caching allocation,保留一系列固定大小區塊的list以利迅速回收再使用
* 在兩者之間 : 試著結合兩種方法,有每個size的list(小的特性),也有合併(coalesce)機制、double linked list(大)
* 極大的request(>= 128KB by default) : 直接使用mmap(),讓memory management解決
**arena and thread**
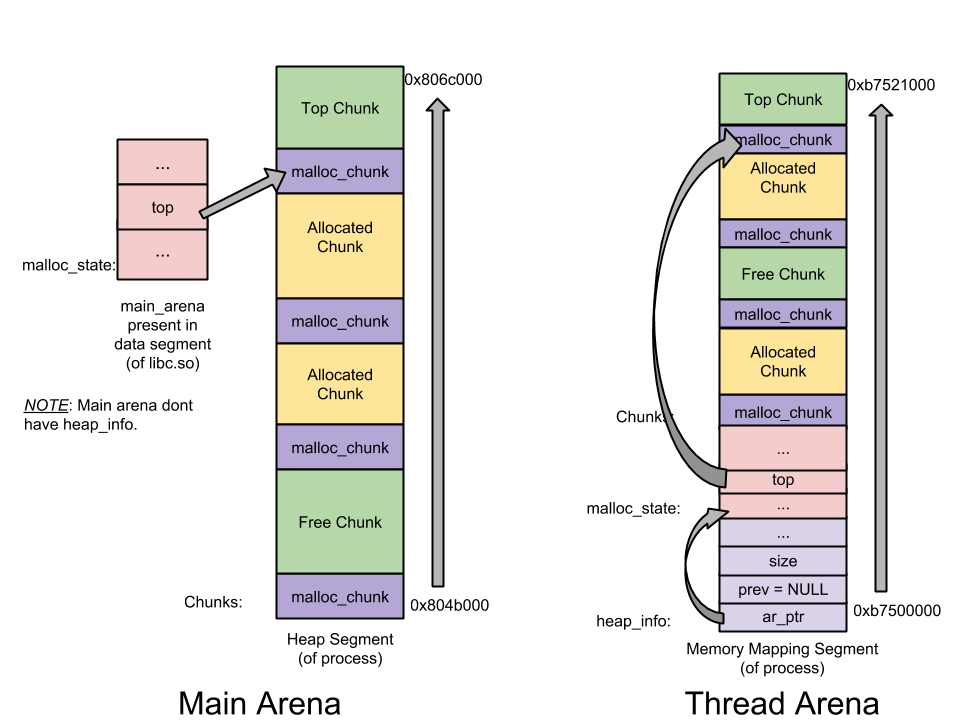
arena即為malloc從系統取得的連續記憶體區域,分為main arena與thread arena兩種。
* main arena : 空間不足時,使用brk()延展空間,預設一次132kb
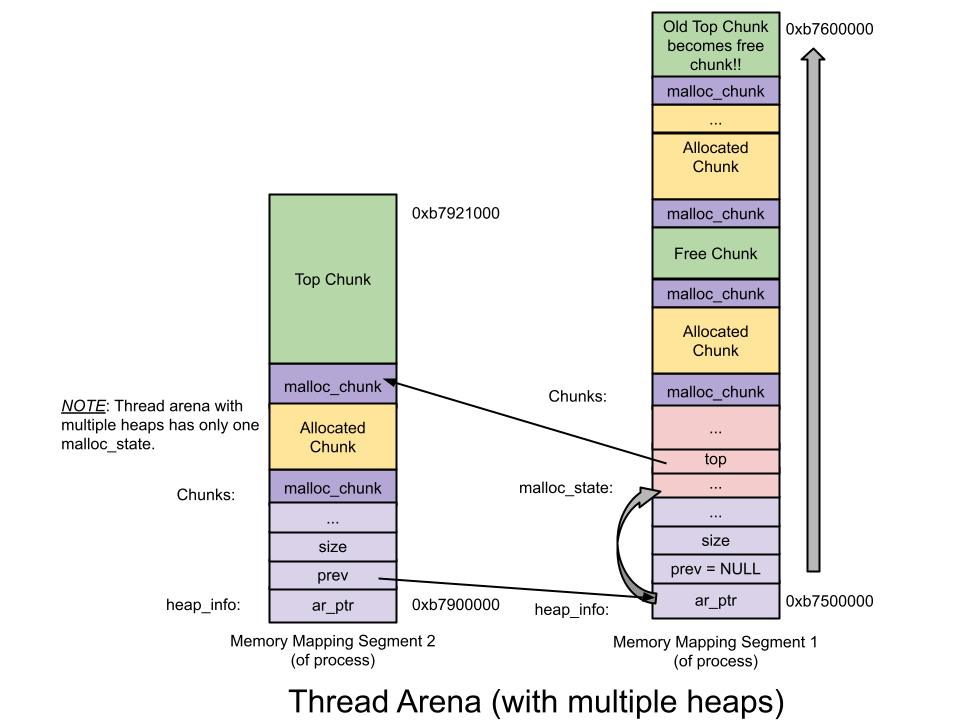
* thread arena : 使用mmap()取得新記憶體,預設map 1mb,分配給heap 132kb,尚未分配給heap的空間設定為不可讀寫,1 mb使用完後會再map一個1 mb的新heap
每個thread在呼叫malloc()時會分配到一個arena,在開始時thread與arena是一對一的(per-thread arena),但arena的總數有限制,超過時threads會開始共用arena:
* 32 bit : 2 * number of cores
* 64 bit : 8 * number of cores
此設計是為了減少多threads記憶體浪費,但也因此glibc malloc**不是lockless allocator**,對於有許多threads的server端程式來說,很有可能影響效能
* [github mysql switch to TCmalloc](https://github.com/blog/1422-tcmalloc-and-mysql) 可能跟這個問題有關
www.google.com.tw/?gws_rd=ssl
**Heap data structures**
* **[malloc_state](https://github.com/sploitfun/lsploits/blob/master/glibc/malloc/malloc.c#L1671) (Arena Header)** : 每個arena一個。紀錄arena的資訊,包含bins (free list), top chunk, last remainder chunk等等allocation/free需要的資訊。其中main arena的header在data segment(static),thread的在heap中
* **[heap_info](https://github.com/sploitfun/lsploits/blob/master/glibc/malloc/arena.c#L59) (Heap Header)** : 在thread arena中,每個arena可能有超過一個heap。紀錄前一個heap、所屬的arena、已使用/未使用的size
* **[malloc_chunk](https://github.com/sploitfun/lsploits/blob/master/glibc/malloc/malloc.c#L1108) (Chunk Header)** : 一個heap被分為許多區段,稱為chunk,是user data儲存的地方,又依使用狀態分為free與allocated。紀錄chunk本身的size與型態
_Main arena vs Thread arena :_
_multiple heap Thread arena :_
**Chunks**
* 可用來分配或正在使用中的記憶體區塊,分為allocated與free
* chunk的大小在32bit下最小16 bytes,對齊8 bytes;64bit下最小32 bytes,對齊16 bytes
* 需要至少4個word作為free chunk時的field
_Allocated chunk :_

* [prev_size](https://github.com/sploitfun/lsploits/blob/master/glibc/malloc/malloc.c#L1110) : 如果前一個chunk是free chunk,包含前一個chunk的size,若是allocated,則包含user data
* [size](https://github.com/sploitfun/lsploits/blob/master/glibc/malloc/malloc.c#L1111) : 此chunk的大小,最後3bit作為flag使用
* [PREV_INUSE](https://github.com/sploitfun/lsploits/blob/master/glibc/malloc/malloc.c#L1267) (P) : 前一個chunk是allocated
* [IS_MMAPPED](https://github.com/sploitfun/lsploits/blob/master/glibc/malloc/malloc.c#L1274) (M) : 是mmap取得的獨立區塊
* [NON_MAIN_ARENA](https://github.com/sploitfun/lsploits/blob/master/glibc/malloc/malloc.c#L1283) (N) : chunk是thread arena的一部分
_Free Chunk _:
.png)
* [prev_size](https://github.com/sploitfun/lsploits/blob/master/glibc/malloc/malloc.c#L1110) : 因兩個free chunk會合併,只會出現在fast bin的情況下
* fast bin的chunk在free時不會做合併,只有在malloc步驟中的consolidate fastbin(fast /small bin miss)才會合併
* 下一個chunk的PREV_INUSE flag平時是不set的
* [fd](https://github.com/sploitfun/lsploits/blob/master/glibc/malloc/malloc.c#L1113)(Forward pointer) : 指向在同一個bin中的下一個chunk
* [bk](https://github.com/sploitfun/lsploits/blob/master/glibc/malloc/malloc.c#L1114)(Backward pointer) : 指向在同一個bin中的上一個chunk
**Bins**
bins是紀錄free chunks的資料結構(freelist),依據其大小和特性分成4種 :
(以下的數值為32bit系統,64bit *2)
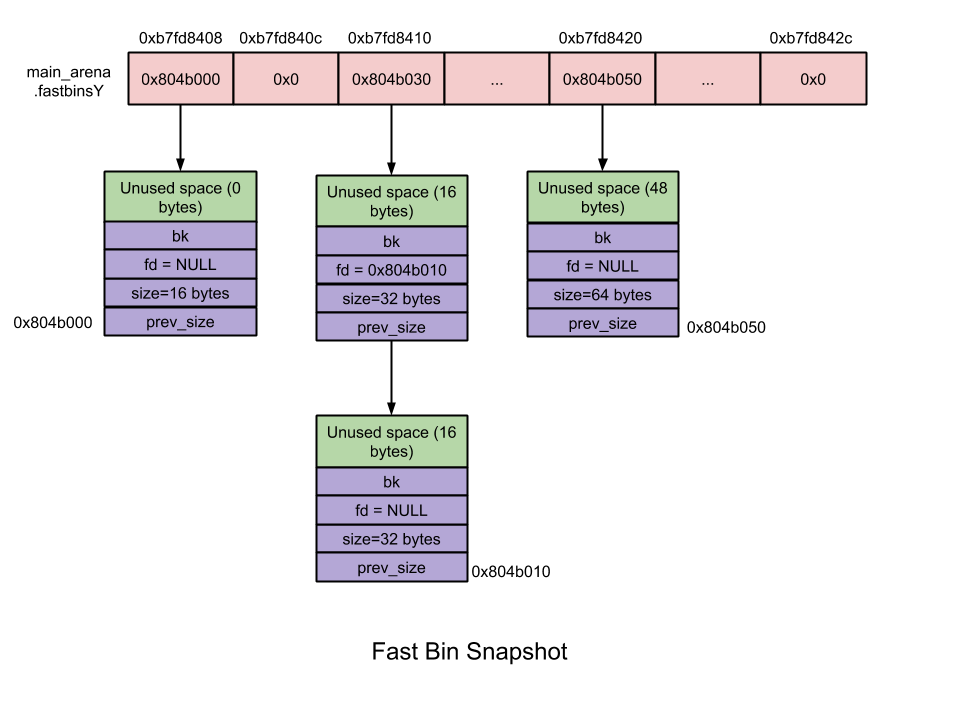
_Fast Bin _:
* 10個bin
* 使用linled lisk,malloc時allocate最後一項(pop from top)
* chunk大小在16~最大80(可設定,預設64)byte之間
* size : 每個bin差8 bytes
* 不執行合併 : 在free時不會清除下一個chunk的PREV_INUSE flag
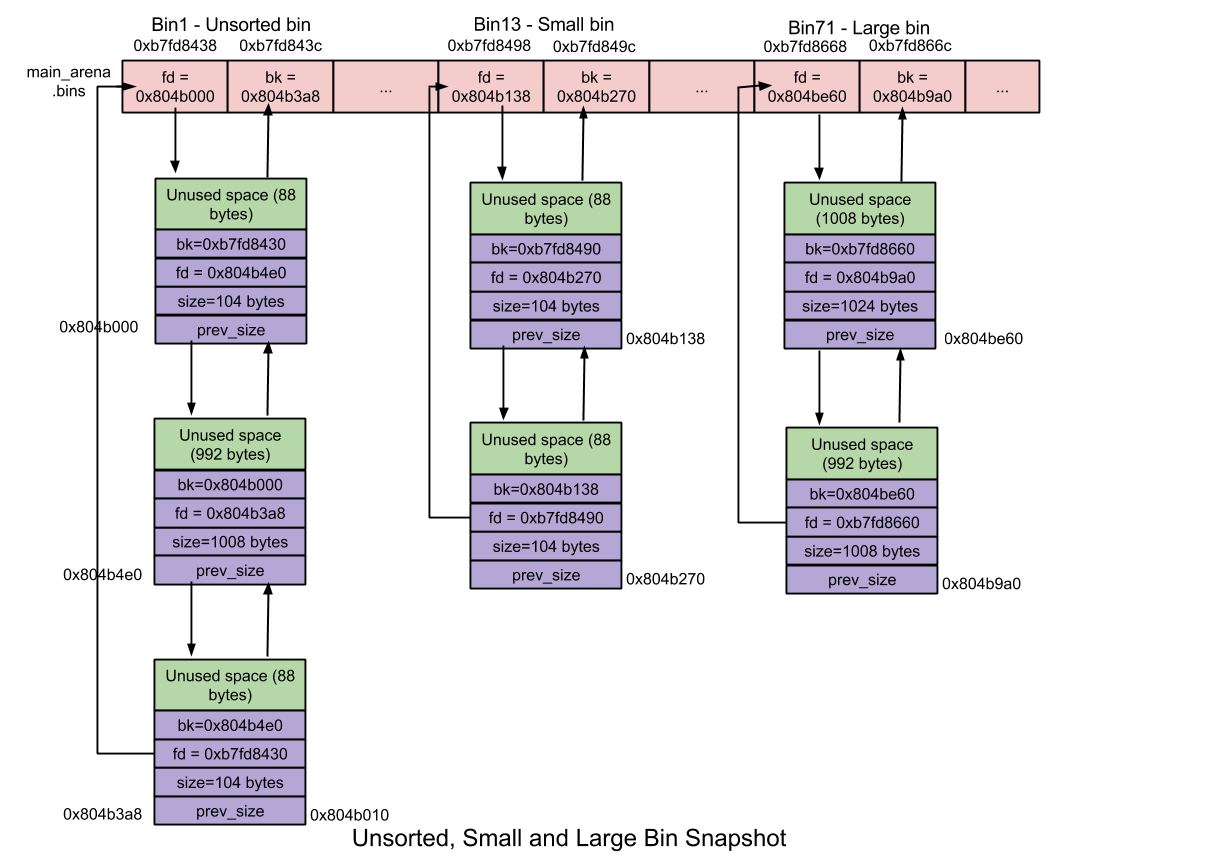
_Unsorted Bin _:
* 最近free的small / large chunk,不分大小
* 重複使用chunks以加速allocation
_Small Bin _:
* chunk < 512 bytes
* 62個bin
* size : 每個bin差8 bytes
* 合併 : 兩個相鄰的free chunk合併,減少fragmentation(但較耗時)
_Large Bin _:
* chunk >= 512 bytes
* 63個bin
* size : 每個bin差距不同
* 前32個bin差64 bytes (n=1)
* 再2^(6-n)個bin差8^(n+1) bytes
* n=6 : 1個bin 262144 bytes
* 剩最後一個bin存放所有更大的chunk
* bin裡的chunk依大小排序(因size差距不再是最小單位),allocate時需搜尋最適大小
**Top chunk**
在arena邊界的chunk,若所有bin皆無法allocate則由這裡取得,若仍不夠則用brk / mmap延展
**Last Remainder Chunk**
最近一次分割的large chunk,被用來滿足small request所剩下的部分
**malloc流程**
* 調整malloc size : 加上overhead並對齊,若<32byte(64bit最小size,4 pointers)則補上
* 檢查fastbin : 若對應bin size有符合chunk即return chunk
* 檢查smallbin : 若對應bin size有符合chunk即return chunk
* 合併(consolidate) fastbin : (若size符合large bin或前項失敗)呼叫malloc_consolidate進行fastbin的合併(取消下一chunk的PREV_INUSE),並將合併的bin歸入unsorted
* 處理unsorted bin :
* 若unsorted bin中只有last_remainder且大小足夠,分割last_remainder並return chunk。剩下的空間則成為新的last_remainder
* loop每個unsorted bin chunk,若大小剛好則return,否則將此chunk放至對1應size的bin中。此過程直到unsorted bin為空或loop 10000次為止
* 在small / large bin找best fit,若成功則return分割的chunk,剩下的放入unsorted bin(成為last_remainder);若無,則繼續loop unsorted bin,直到其為空
* 使用top chunk : 分割top chunk,若size不夠則合併fastbin,若仍不夠則system call
**free流程**
* 檢查 : 檢查pointer位址、alignment、flag等等,以確認是可free的memory
* 合併(consolidate)
* fastbin size : 不進行合併
* 其他 :
* 檢查前一chunk,若未使用則合併
* 檢查後一chunk,若是top chunk則整塊併入top chunk,若否但未使用,則合併
* 將合併結果放入unsorted bin
* ref : [allocation過程](http://brieflyx.me/2016/heap/glibc-heap/)
* **glibc malloc allocation informations**
* [mallinfo](http://man7.org/linux/man-pages/man3/mallinfo.3.html) - obtain memory allocation information
* [malloc_stats](http://man7.org/linux/man-pages/man3/malloc_stats.3.html) - print memory allocation statistics
* [malloc_info](http://man7.org/linux/man-pages/man3/malloc_info.3.html) - export malloc state to a stream
簡單測試 : malloc(40 * sizeof(int));
* malloc_stats()
* Arena 0:
* system bytes = 135168
* in use bytes = 176
* Total (incl. mmap):
* system bytes = 135168
* in use bytes = 176
* max mmap regions = 0
* max mmap bytes = 0
* mallinfo() [example](http://man7.org/linux/man-pages/man3/mallinfo.3.html#EXAMPLE)
* Total non-mmapped bytes (arena): 135168
* # of free chunks (ordblks): 1
* # of free fastbin blocks (smblks): 0
* # of mapped regions (hblks): 0
* Bytes in mapped regions (hblkhd): 0
* Max. total allocated space (usmblks): 0
* Free bytes held in fastbins (fsmblks): 0
* Total allocated space (uordblks): 176
* Total free space (fordblks): 134992
* Topmost releasable block (keepcost): 134992
* malloc_info(int _options_, FILE *_stream_)
* <total type="fast" count="0" size="0"/>
* <total type="rest" count="0" size="0"/>
* <system type="current" size="135168"/>
* <system type="max" size="135168"/>
* <aspace type="total" size="135168"/>
* <aspace type="mprotect" size="135168"/>
* </heap>
* <total type="fast" count="0" size="0"/>
* <total type="rest" count="0" size="0"/>
* <total type="mmap" count="0" size="0"/>
* <system type="current" size="135168"/>
* <system type="max" size="135168"/>
* <aspace type="total" size="135168"/>
* <aspace type="mprotect" size="135168"/>
* </malloc>
**Introduction to Scalloc**
**簡介**
scalloc的設計強調在concurrent環境下的表現,尤其是在thread / core增加時的performance (secaling),並且保持一定的記憶體效率。其設計仰賴64-bit的記憶體空間與linux demand paging的特性,包含了 :
* virtual span作為在virtual address space上分配記憶體的單位 (大小皆相同)
* 強調concurrent資料結構的global back end
* constant-time allocation、並積極回收記憶體的per-thread front end
**Real Spans & Virtual Spans**
span是allocator用來分配記憶體的概念單位,scalloc使用雙層(real & virtual) span作為分割記憶體的單位。記憶體區段(arena)先分割成virtual span,其內再分成real span,於real span內進行allocation。
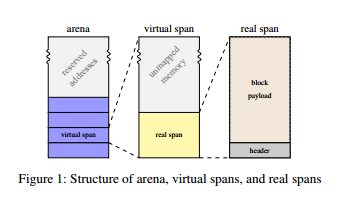
_Real span & size class_
每個real span內依size class被分為相同大小的blocks,real span有29種size class,但real span本身只有9種大小。size class 1-16分別為16bytes至256bytes,每個class相差16bytes(與tcmalloc相同),它們的real span皆有相同的size;17-29分別為512bytes至2MB,每個class相差2倍。>1MB的allocation則直接以mmap處理。
_Virtual span_
在scalloc初始化時,會進行一次32TB的mmap,此區段稱為arena,其空間被分成以2MB size , 2MB aligned的區塊,即為virtual span。每個使用中的virtual span包含一個real span,virtual span的size class即為該real span的size class,通常real span的size會比virtual span小許多。virtual span有以下特性 :
* real span以外的記憶體不會產生physical fragmentation,因其不被使用也不被mapped(由於demand paging)。
* size class不論大小可採取統一標準處理
* arena記憶體只進行一次(初始化)mmap,不用進行額外的system call
當virtual span清空後,會放入free list(即span pool),為限制physical fragmentation,若real span大於一定大小,會以madvise釋放空間。
* addressable memory : 一個2MB的virtual span最小只會有16KB real span,故整個32TB空間addressable的最小只有(2^45 / 2^21)=256GB
* 可以看出scalloc的設計假設virtual address近乎無限,若在32bit架構下只有(4GB / 128)=32MB
* Backend: Span-Pool
span-pool是一個global資料結構,由stack-like pools的array組成,array以size class為單位。stack-like pools在單thread情形下即為stack。
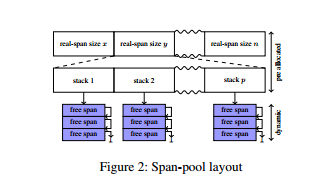
size class的分割以pre-allocated array的index達成,每個entry內又有一個pre-allocated array(pool array),其entry內含lock-free的Treiber stack,index則為執行時的core number。Treiber stack由元素的singly linked list組成,push與pop以對top pointer的atomic compare-and-swap實作。為避免ABA問題,實作中使用包含在top pointer中的16-bit ABA counter。
以下是Span-pool的pseudo code :

_put_
thread會先取得real-span index與core index並放入對應的pool : 在放入之前,若其real-span size > MADVISE_THRESHOLD,則用madvise釋放記憶體。MADVISE_THRESHOLD預設為32KB,即size class增加方式的分界(512bytes)的real-span size。
_get_
先試由所屬real-span / core index取得span(fast path);若失敗,則搜尋整個pool,試取得空span;若仍失敗,由arena取得新的virtual span。
**Frontend: Allocation and Deallocation**
span可以有幾種不同的狀態 :
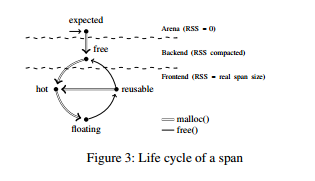
span可以是以下其中之一 : expected, free, hot, floating, reusable。
* expected : 仍在arena,不占任何實體記憶體的狀態
* free : 在span-pool中等待使用的狀態
其他3種狀態皆在frontend,且span此時有所屬的span size
* hot : 正在用來malloc的span,在local buffer內每size class一個
* floating : 內含free block在reusability threshold以下者
* reusable : 內含free block在reusability threshold以上,可以在hot填滿時替換
每個span在frontend時,都會被分配到一個local-allocation buffer (LAB),LAB可以調整為thread-local(TLAB)或core-local(CLAB)模式,分別由每thread / core擁有一個。 LAB內包含每size class一個的hot span,與一些也以size class分類的reusable span。
span內的free若是其他thread進行的稱為remote free,自身thread進行的為local free。malloc皆是由local hot span進行。針對remote free的fragmentation問題,scalloc使用兩個free list將local與remote free分開處理。
_Allocation_
* thread先嘗試LAB的hot span,在對應hot span內的local free list取得block (fast path)。
* 若沒有對應的hot span : 試由resuable span取得新的hot span;若仍失敗,由span-pool取得。
* 若有hot span但local free list為空 : 若remote free list相對reusability threshold有一定比值,thread將所有remote block移至local,並進行fast patch;若沒有,同上一點方式取得新hot span。
* 將remote block移至local的條件判斷為減少lock的效能考量
_Deallocation_
* returned block放入free list,若span在LAB則local,非則remote。
* 若span floating,檢查是否達到reusability threshold,若是則改變狀態為reusable並放入LAB的reusable set。
* 若span reusable,檢查span是否為空,若是則為free,並移入span-pool
**Operation Complexity**
_allocation_
只考慮hot span且不進行任何cleanup,在沒有contention的情形下 :
* 有hot span,進行allocation : constant-time
* 取得reusable span : constant-time
有contention情形下,因同步進行的deallocation,可能需要考慮1個以上的reusable span,但至少有1個thread可以以constant-time執行
_deallocation_
只考慮block所在的span :
* 插入至local free list為constant-time
* remote free list為constant-time modulo synchronization(remote free list為lock-free)
* 不太清楚remote的constant-time modulo synchronization所指為何
* 推測是至少有1個thread可以以constant-time進行?
* span改為reusable為constant-time modulo synchronization (放入reusable set為lock-based)
_Span-pool_
為constant-time modulo synchronization (span-pool整體為lock-free)
**Implementation Details**
_Real Span_
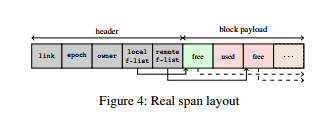
* link : 在span-pool或set內時,用來link其他span
* epoch : 用以紀錄span的life cycle狀態。word的上部用來紀錄states,下半為一個[ABA counter](https://en.wikipedia.org/wiki/ABA_problem),因free block + state轉換並非atomic。若沒有ABA counter :
<table style="font-size: 13px;">
<tbody>
<tr>
<td class="added" style="border: 1px solid rgb(153, 153, 153); min-width: 50px; height: 22px; line-height: 16px; padding-right: 4px; padding-left: 4px;">thread A</td>
<td class="added" style="border: 1px solid rgb(153, 153, 153); min-width: 50px; height: 22px; line-height: 16px; padding-right: 4px; padding-left: 4px;">thread B</td>
<td class="added" style="border: 1px solid rgb(153, 153, 153); min-width: 50px; height: 22px; line-height: 16px; padding-right: 4px; padding-left: 4px;"></td>
</tr>
<tr>
<td class="added" style="border: 1px solid rgb(153, 153, 153); min-width: 50px; height: 22px; line-height: 16px; padding-right: 4px; padding-left: 4px;">old = epoch</td>
<td class="added" style="border: 1px solid rgb(153, 153, 153); min-width: 50px; height: 22px; line-height: 16px; padding-right: 4px; padding-left: 4px;"></td>
<td class="added" style="border: 1px solid rgb(153, 153, 153); min-width: 50px; height: 22px; line-height: 16px; padding-right: 4px; padding-left: 4px;"></td>
</tr>
<tr>
<td class="added" style="border: 1px solid rgb(153, 153, 153); min-width: 50px; height: 22px; line-height: 16px; padding-right: 4px; padding-left: 4px;">free(last block)</td>
<td class="added" style="border: 1px solid rgb(153, 153, 153); min-width: 50px; height: 22px; line-height: 16px; padding-right: 4px; padding-left: 4px;"></td>
<td class="added" style="border: 1px solid rgb(153, 153, 153); min-width: 50px; height: 22px; line-height: 16px; padding-right: 4px; padding-left: 4px;">span現在是empty but reusable ,A準備mark free</td>
</tr>
<tr>
<td class="added" style="border: 1px solid rgb(153, 153, 153); min-width: 50px; height: 22px; line-height: 16px; padding-right: 4px; padding-left: 4px;"></td>
<td class="added" style="border: 1px solid rgb(153, 153, 153); min-width: 50px; height: 22px; line-height: 16px; padding-right: 4px; padding-left: 4px;">get reusable span -> hot</td>
<td class="added" style="border: 1px solid rgb(153, 153, 153); min-width: 50px; height: 22px; line-height: 16px; padding-right: 4px; padding-left: 4px;"></td>
</tr>
<tr>
<td class="added" style="border: 1px solid rgb(153, 153, 153); min-width: 50px; height: 22px; line-height: 16px; padding-right: 4px; padding-left: 4px;"></td>
<td class="added" style="border: 1px solid rgb(153, 153, 153); min-width: 50px; height: 22px; line-height: 16px; padding-right: 4px; padding-left: 4px;">hot->floating->reusable</td>
<td class="added" style="border: 1px solid rgb(153, 153, 153); min-width: 50px; height: 22px; line-height: 16px; padding-right: 4px; padding-left: 4px;">span現在是reusable (not empty)</td>
</tr>
<tr>
<td class="added" style="border: 1px solid rgb(153, 153, 153); min-width: 50px; height: 22px; line-height: 16px; padding-right: 4px; padding-left: 4px;">compare-and-swap(epoch,old,FREE)</td>
<td class="added" style="border: 1px solid rgb(153, 153, 153); min-width: 50px; height: 22px; line-height: 16px; padding-right: 4px; padding-left: 4px;"></td>
<td class="added" style="border: 1px solid rgb(153, 153, 153); min-width: 50px; height: 22px; line-height: 16px; padding-right: 4px; padding-left: 4px;">雖然span內還有block ,但因epoch == old (reusable) ,span被mark free</td>
</tr>
</tbody>
</table>
* Owner : 一個identifier (16 bits)用來分別owning LAB + reference (48 bits)指向該LAB,整個word可以以compare-and-swap atomic更新。當使用LAB的最後一個thread結束,owner會被設為TERMINATED,等到下次LAB重新使用時,owner會有新的identifier,但reference不變(仍是同一個LAB)。
* Remote f-list : 實作一個[Treiber stack](https://en.wikipedia.org/wiki/Treiber_Stack),並同時記錄top pointer與block count (放在同一個word)。若要get所有block,只需要將top改為NULL (atomic),此動作同時set block count=0。
_Auxiliary structures and methods_

* get_lab : 利用owner field取得對應LAB。
* is_oprhan : 檢查該span所屬的LAB,其對應thread是否全部結束。
* try_mark_* : 嘗試對epoch進行compare-and-swap,同時更改ABA counter (atomic)。
* try_refill_from_remotes : 若remote free list大於一定數量(相對於reusability threshold),將所有block移至local。
* try_adopt : 更改is_oprhan span的owner (atomic)。
* Set : 用來維持reusable span的紀錄
* constant time的put ,get ,remove。
* open / close用以防止put ,get沒有owner的set (owner==TERMINATED)。
* 考慮到contention頻率不高,使用lock-based deque。
_Frontend_

* get_span : 由span-pool或reusable set取得span。
* 分別代表free -> hot / reusable -> hot。
* allocate : 由hot span取得block。
* 若沒有,先試由remote free list取得新的block (try_refill_from_remotes)
* 若仍無block,將hot span改為floating,並取得新span (get_span)
* deallocate : free block並檢查狀態轉換
* 由於free + state非atomic,epoch被紀錄以待稍後compare-and-set使用。
* 將block放入對應free list。
* free block > reusability threshold,轉換至reusable,使用old_owner防止放入沒有owner或其他owner的LAB。
* span全空,轉換至free (compete : get_span的try_mark_reusable)。
_Thread Termination_
由於LAB沒有對所有span的reference (例如floating span),要找出orphaned,必須比較span的owner與LAB的owner,兩者不同或owner==TERMINATED皆是orphaned span。orphaned皆為floating,於deallocate時由新的LAB adopt。
* terminate :
* close所有reusable set,並將所有span轉至floating。
* compete : reusable -> floating 對 reusable -> free
* LAB被設為TERMINATED,使原floating span的owner與LAB不同。
_Handling Large Objects_
大於1M直接使用mmap。
[Scalloc design decisions](https://paper.dropbox.com/doc/Scalloc-Design-Decisions-nzdAAqUSuRaWQQKg5xGxJ)
**fragmentation testing**
**主要策略**
* 直接測**fragmentation**
* fragmentation = (free - freemax) / free ; 0 if free = 0
測量最大可用的block(freemax)相對於所有可用空間(free)的比率,freemax相對越小就表示連續的的block越小,即fragmentation 變大。
* ptmalloc2 mallinfo : 沒有抓最大可用block的機制,測量可能有困難
* 從**utilization**的結果觀察
* memory utilization = active memory / used
* or used memory over time
* ref : [](https://www.facebook.com/notes/facebook-engineering/scalable-memory-allocation-using-jemalloc/480222803919/)[https://www.facebook.com/notes/facebook-engineering/scalable-memory-allocation-using-jemalloc/480222803919/](https://www.facebook.com/notes/facebook-engineering/scalable-memory-allocation-using-jemalloc/480222803919/)
allocated相對於總記憶體使用的比率,剩下的空間即是浪費掉的空間,可能的來源有overhead、fragmentation等。
fragmentation 可能造成新的allocation無法使用已經free的記憶體,造成總使用空間增加,utilization下降。 若一個process的memory utilization因為fragmentation持續降低,最後可能因為使用空間太大而OOM。
* ptmalloc2 mallinfo : 可以用(uordblks / arena)來測,或直接看arena隨時間的變化
**實例 (paper)**
* [facebook-jemalloc](https://www.facebook.com/notes/facebook-engineering/scalable-memory-allocation-using-jemalloc/480222803919/) : 看 active memory vs RAM usage 長時間比率穩定度(fragmentation 不造成RAM無限消耗)
* **[OOPSLA15-Scalloc](http://www.cs.uni-salzburg.at/~ck/content/publications/conferences/OOPSLA15-Scalloc.pdf)** : 測量memory consumption時使用Resident Set Size(RSS) sample的平均值,sample rate隨使用的benchmark而不同 (每個benchmark+thread數為一個資料點)
* [Scalable Memory Allocation](http://cs.nyu.edu/~lerner/spring12/Preso05-MemAlloc.pdf) : max heap use in benchmark (只有一個值)
* **[Small Block Sizes in rt Embedded Systems](http://jultika.oulu.fi/files/nbnfioulu-201302081026.pdf)** : max allocated live memory vs max used memory(原理與facebook類似), 利用在allocator內加code的方式(**instrumentation**),maximum以**最高address**計算,並加入implementation overhead的觀察(未詳細說明)。比較4個benchmark pattern,隨allocation / free做graph (profiling)。
* **[The Memory Fragmentation Problem: Solved?](http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.97.5185&rep=rep1&type=pdf)** : 提到四種數值化模式 :
<table style="font-size: 13px;">
<tbody>
<tr>
<td class="added" style="border: 1px solid rgb(153, 153, 153); min-width: 50px; height: 22px; line-height: 16px; padding-right: 4px; padding-left: 4px;"></td>
<td class="added" style="border: 1px solid rgb(153, 153, 153); min-width: 50px; height: 22px; line-height: 16px; padding-right: 4px; padding-left: 4px;">vs</td>
<td class="added" style="border: 1px solid rgb(153, 153, 153); min-width: 50px; height: 22px; line-height: 16px; padding-right: 4px; padding-left: 4px;">at (time point)</td>
<td class="added" style="border: 1px solid rgb(153, 153, 153); min-width: 50px; height: 22px; line-height: 16px; padding-right: 4px; padding-left: 4px;">缺點</td>
</tr>
<tr>
<td class="added" style="border: 1px solid rgb(153, 153, 153); min-width: 50px; height: 22px; line-height: 16px; padding-right: 4px; padding-left: 4px;">used</td>
<td class="added" style="border: 1px solid rgb(153, 153, 153); min-width: 50px; height: 22px; line-height: 16px; padding-right: 4px; padding-left: 4px;">requesed</td>
<td class="added" style="border: 1px solid rgb(153, 153, 153); min-width: 50px; height: 22px; line-height: 16px; padding-right: 4px; padding-left: 4px;">across all point in time (average)</td>
<td class="added" style="border: 1px solid rgb(153, 153, 153); min-width: 50px; height: 22px; line-height: 16px; padding-right: 4px; padding-left: 4px;">看不到spike</td>
</tr>
<tr>
<td class="added" style="border: 1px solid rgb(153, 153, 153); min-width: 50px; height: 22px; line-height: 16px; padding-right: 4px; padding-left: 4px;">used</td>
<td class="added" style="border: 1px solid rgb(153, 153, 153); min-width: 50px; height: 22px; line-height: 16px; padding-right: 4px; padding-left: 4px;">max requesed</td>
<td class="added" style="border: 1px solid rgb(153, 153, 153); min-width: 50px; height: 22px; line-height: 16px; padding-right: 4px; padding-left: 4px;">max live(requesed) memory</td>
<td class="added" style="border: 1px solid rgb(153, 153, 153); min-width: 50px; height: 22px; line-height: 16px; padding-right: 4px; padding-left: 4px;">fragmentation可能還會成長</td>
</tr>
<tr>
<td class="added" style="border: 1px solid rgb(153, 153, 153); min-width: 50px; height: 22px; line-height: 16px; padding-right: 4px; padding-left: 4px;">max used</td>
<td class="added" style="border: 1px solid rgb(153, 153, 153); min-width: 50px; height: 22px; line-height: 16px; padding-right: 4px; padding-left: 4px;">requesed</td>
<td class="added" style="border: 1px solid rgb(153, 153, 153); min-width: 50px; height: 22px; line-height: 16px; padding-right: 4px; padding-left: 4px;">max memory usage</td>
<td class="added" style="border: 1px solid rgb(153, 153, 153); min-width: 50px; height: 22px; line-height: 16px; padding-right: 4px; padding-left: 4px;">可能有極高的fragmentation</td>
</tr>
<tr>
<td class="added" style="border: 1px solid rgb(153, 153, 153); min-width: 50px; height: 22px; line-height: 16px; padding-right: 4px; padding-left: 4px;">max used</td>
<td class="added" style="border: 1px solid rgb(153, 153, 153); min-width: 50px; height: 22px; line-height: 16px; padding-right: 4px; padding-left: 4px;">max requesed</td>
<td class="added" style="border: 1px solid rgb(153, 153, 153); min-width: 50px; height: 22px; line-height: 16px; padding-right: 4px; padding-left: 4px;">not same point in time</td>
<td class="added" style="border: 1px solid rgb(153, 153, 153); min-width: 50px; height: 22px; line-height: 16px; padding-right: 4px; padding-left: 4px;">可能低估</td>
</tr>
</tbody>
</table>
* 考慮到implementation overhead,在malloc時的size內減去(ex : malloc(20) , overhead=4 改成malloc(16))。
* used memory使用**system call**追蹤,因allocator只能以page為單位請求記憶體,觀察會有誤差。
更清楚的解釋上述四種數值化模式 [](https://paper.dropbox.com/doc/Fragmentation-4v9zRLIanLfNw1BoiZ0VH)[https://paper.dropbox.com/doc/Fragmentation-4v9zRLIanLfNw1BoiZ0VH](https://paper.dropbox.com/doc/Fragmentation-4v9zRLIanLfNw1BoiZ0VH)
* **[Hoard](https://people.cs.umass.edu/~emery/pubs/berger-asplos2000.pdf)** : Multithreaded問題 : 因一般的profiling + lock會造成allocation無法平行執行(serialized behavior),hoard使用per-thread在malloc/free時紀錄(+timestamp),記錄在事先準備的mapped memory,最後在整理成檔案。(但記錄方式沒有詳細說明)
* [SSMalloc](https://apsys2012.kaist.ac.kr/media/papers/apsys2012-final27.pdf) : peak physical memory footprint
**實驗考量**
* implementation overhead
* 考慮到實驗的目的是避免OOM和提高space efficiency,overhead也會影響這兩項的結果,故我認為應該可以只看總消耗量,而不必分開overhead與fragmentation。(還可以減少所需的工作量)
* Resident Set Size
* 實驗平台要求real-time,且盡量減少(或說沒有)swap,且Resident受系統的其他部分影響(由系統管理),故我認為測驗應該基於real(virtual) size,尤其在有swap的情形下,swap in/out會造成程式失去real-time特性。
* 測量方式
* 由於實驗包含如tlsf等不會自動map memory(paging)的allocator,故無法由系統判別消耗的RAM數量(利用如ps等),測量需要在allocator本身的code裡進行。
**(可能的)測量方法**
* 取得total size
* allocator內包含自我測試function(如ptmalloc2)
* 在profiling時,使用自帶的mallinfo()等取得total size
* no auto paging(如tlsf)
* 在allocator內加入紀錄top address的code,由top address - base address得到total size。
* with auto paging
* 在allocator內加入紀錄total mapped memory的code,並以此為total size。
* 測量時間點
* 在profiling時,於每次malloc / free前後,並應該與timing / preformance實驗分開做(加入的code可能影響preformance)。
* Multithread test
* 理論上,total size應該以per-thread的方式記錄,但實際運作方式可能依allocator的不同而改變,方法應允許malloc/free可以(嘗試)平行執行。
**Memory allocator研究 - jemalloc**
設計上重視cache locality勝於減少working set pages使用數目,減少記憶體的使用量可以達到此目的;因為temporal locality通常也意味著spatial locality,所以也盡可能分配連續的記憶體
(同樣地)提到false cache sharing對效能的衝擊
## 實驗重現與驗證
**ROBUST MEMORY MANAGEMENT USING REAL TIME CONCEPTS **
* 仰賴RTOS µC/OS-II將記憶體切成固定大小的區塊
**Understanding glibc malloc**
* 實驗內容為觀察per thread arena的分配情形,接著以code tracing的方式分析glibc malloc(ptmalloc)的行為
* 在每個thread執行第一次malloc的時候,似乎會直接分配一塊很大的head memory(稱作per thread arena)。例如在本實驗中只要求1kB的空間,卻給了132kB
* 若在multithread application中對每個thread都分配一個arena,對記憶體衝擊會很大,因此per-thread arena限制arena的上限數目(2 * number of cores in 32-bit system, 8 * number of cores in 64-bit system)
## 實驗設計
* 實驗用到的程式碼放在這
[](https://github.com/jacky6016/malloc-benchmark)[https://github.com/jacky6016/malloc-benchmark](https://github.com/jacky6016/malloc-benchmark)
* Performance index
* alloc/dealloc WCET
* fragmentation空間
* scalability
* 情境
* 必須要製造worse-case scenario (每種演算法的worst case scenario可能不同)
**實驗測量方向**
* space efficiency & avoid OOM
* (peak) allocated memory vs total used pages
* real-time
* max(worst case) allocation & dealloc time
* performance / throughput
* average time
* allocation time 與 allocated / freed space 的對應比較?
* memory profiling
---------------------------------------------------------------------------------------------------------------------------------------------
* [Tips of malloc & free Making your own malloc library for troubleshooting](http://elinux.org/images/b/b5/Elc2013_Kobayashi.pdf) 重點摘錄
* 目標 easy to modify,use this only for the debugee process
* You can see memory map of ` cat /proc/self/maps `
* __malloc_hook is not thread safe
* Use probability distribution generate 10000 or more random variables( these random variable are allocated size patterns, and it will follow the distribution).
* [Random number generation](http://heather.cs.ucdavis.edu/~matloff/SimCourse/PLN/RandNumGen.pdf)
* 先用[exponential distribution](https://en.wikipedia.org/wiki/Exponential_distribution)產生random number, 程式裡的mean_size = 1 / lambda
* memory random size generator finish, Please [follow](https://github.com/ldotrg/memory_size_generator) (5/20 done)
* 這支程式還有支援gamma, normal, Erlang 等分配,可以改CODE試試
* random.c是用moment generating function 去刻出來的code
* 下一步是把產生的radom size餵 給malloc_count 去測試
* [](https://github.com/whosyourdadd/RandMalloc/blob/master/MemSize_Generator/main.cc)[https://github.com/whosyourdadd/RandMalloc/blob/master/MemSize_Generator/main.cc](https://github.com/whosyourdadd/RandMalloc/blob/master/MemSize_Generator/main.cc)
* 應該要先討論畫什麼圖表(i.e 想要看到什麼樣的分析圖),x軸和y軸要放什麼,這樣才知道如何設計實驗流程,才有辦法數學分析,最後再導入網路應用的packet size pattern。
* lwip memory allocate [mem.c](https://github.com/tabascoeye/lwip/blob/master/src/core/mem.c).
-------------------------------------------------------------------------------------------------------------------------------------------------
## Buddy System
[ [source](https://embedded2016.hackpad.com/-IoT-OS-HyperC-j1Y2KKWoTAh) ]
[Buddy System](https://en.wikipedia.org/wiki/Buddy_memory_allocation) 是種記憶體配置 (memory allocator) 演算法,先將記憶體分成很多size,最小的單位即是一個 page,這個方式會減少 external fragmentation,因為這個機制就是典型的你有多大就放再那一個適合大小櫃子裡,再來還是會有internal fragmentation 的問題,因位我們已經把一個基本單位規定成一個 Page ,而假如一個 Page 是 64K,那麼假如只要儲存一個52K的東西,那麼就會有12K是空的,這個的好處就是可以分的很清楚,哪個page是誰的,就我認知,解決external fragment會是比較好的選擇,因位假如發生的話單位都是以page來算,internal 可能是用byte來算的。
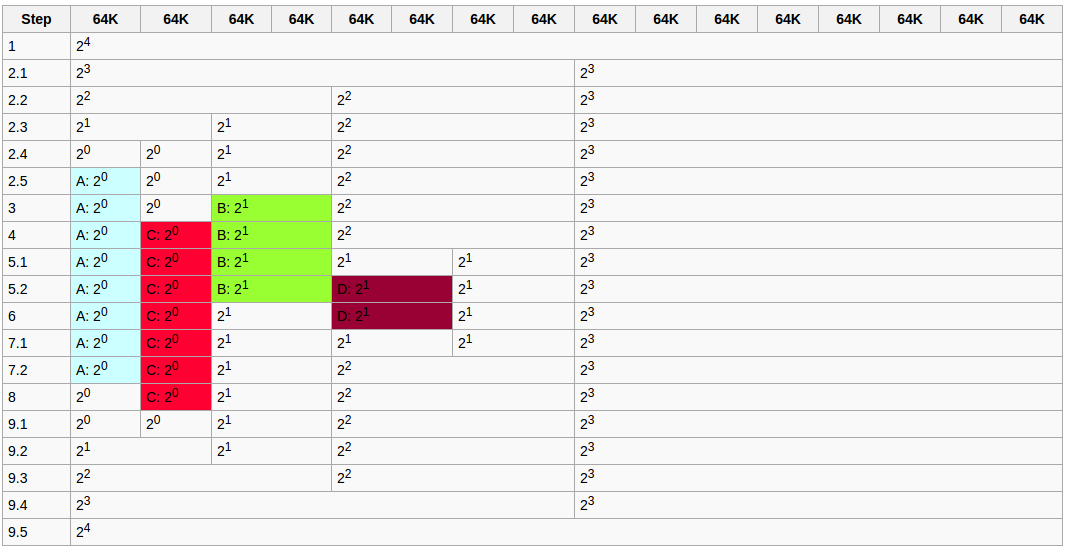
實例解釋:
現在我們有4個東西要儲存 A , B , C , D, 首先我們第一個要儲存的是 A,而A是佔了 64KB的空間(也可能是基本單位 page size),所以我們開始作對折的動作,`step 1` 開始,`step 2.1` 開始做第一次對折,發現空間還是大於他很多,所以我又再切`step 2.2`,一直切到`step 2.5` 才終於剛剛好放下,再來是放 B ,他佔了 2*64KB,然後我發現我剛好有對的地方所以直接放下去`step 3` ,再來換C,而C的流程跟B一樣,就是D了,他佔了 2*64KB,但觀察`step 4`和‵`step 5.1` 其實是沒有剛好放的下D的空間,所以他又再切它,最後這些A B C D 總有用完的時候,就可以將他回收成原本的memory樣式 `step 9.1`開始。
## Benchmarking
* 由 University of Salzburg, Austria 發展的 [scalloc](http://scalloc.cs.uni-salzburg.at/) 提供了若干組 memory allocator 的 benchmark suite: **[scalloc-artifact](https://github.com/cksystemsgroup/scalloc-artifact)**
* 編譯與測試
* git clone [](https://github.com/cksystemsgroup/scalloc-artifact.git)[https://github.com/cksystemsgroup/scalloc-artifact.git](https://github.com/cksystemsgroup/scalloc-artifact.git)
* cd scalloc-artifact
* export BASE_PATH=`pwd`
* tools/make_deps.sh
* tools/create_env.sh
* 找了一圈才發現scalloc-artifact提供的benchmark tools已經是最完整的
[Scalloc-artifact test suite測試數據](https://paper.dropbox.com/doc/Scalloc-artifact-test-suite-YTEv5m9emT1fyPiZOBxEL)
## MADVISE
重現 [note-about-madvise](http://ytliu.info/blog/2014/05/27/note-about-madvice/) 部落格文章上,測試madvise的程式碼。並且在進行修改之後,開了一個新專案放到github上面,照著README操作就可以重現該篇文章上使用madvise帶來效能上的改進。
[](https://github.com/enginec/madviseBench)[https://github.com/enginec/madviseBench](https://github.com/enginec/madviseBench)
* test mmap without madvice
* This file has 1073741824 bytesread without madvise: 4140 ms
* test mmap with madvice
* This file has 1073741824 bytesread with madvise: 3865 ms
* test mmap without madvice again
* This file has 1073741824 bytesread without madvise: 4176 ms
* test mmap with madvice again
* This file has 1073741824 bytesread with madvise: 3872 ms
* ====== test end ======
## 分析Memory Usage Pattern製作benchmark
目前我的想法是透過分析一個程式的memory usage pattern,例如可能是頻繁的小區塊分配與釋放、或是每次索取的記憶體大小差異g很大等,產生對應的benchmark,之後就可以利用這個benchmark來比較不同memory allocator的效能差異。
原本的想法是參考malloc_count,透過動態連結malloc到測試程式,得知每次malloc呼叫大小和順序,並用這個資料去產生benchmark。
但這種作法的盲點在,假設我們要分析的程式是multi-threaded,那麼光是紀錄每次呼叫malloc的大小和順序是不夠的。我們必須要能夠模擬出每個thread使用malloc/free的大小和時間點,用於建立對應的benchmark,再拿這個benchmark去測試各種malloc實作才有意義。因為有些malloc實作支援multithread,要這樣做才能真正測出各種malloc實作的差異。
目前下幾個關鍵字搜尋,找到兩個商用軟體好像能分析thread等級的memory usage情況。
* [C++ Memory Validator](https://www.softwareverify.com/cpp-memory.php)
* [Intel Vtune Amplifier](https://software.intel.com/en-us/intel-vtune-amplifier-xe)
## intersec 記憶體系列文章
* [Memory – Part 1: Memory Types](https://techtalk.intersec.com/2013/07/memory-part-1-memory-types/)
* [Memory – Part 2: Understanding Process memory](https://techtalk.intersec.com/2013/07/memory-part-2-understanding-process-memory/)
* [Memory – Part 3: Managing memory](https://techtalk.intersec.com/2013/08/memory-part-3-managing-memory/)
* [Memory – Part 4: Intersec’s custom allocators](https://techtalk.intersec.com/2013/10/memory-part-4-intersecs-custom-allocators/)
* [Memory – Part 5: Debugging Tools](https://techtalk.intersec.com/2013/12/memory-part-5-debugging-tools/)
* [Memory – Part 6: Optimizing the FIFO and Stack allocators](https://techtalk.intersec.com/2014/09/memory-part-6-optimizing-the-fifo-and-stack-allocators/)
## Reference
* [Memory Management Reference](http://www.memorymanagement.org/)**:** a resource for programmers and computer scientists interested in [memory management](http://www.memorymanagement.org/glossary/m.html#term-memory-management) and [garbage collection](http://www.memorymanagement.org/glossary/g.html#term-garbage-collection).
* [Robust Memory Management using Real Time Concepts](http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.682.3406&rep=rep1&type=pdf)
* 重現實驗
* 將來不見得要重新實作,可能只需要做修改/調整參數
* [SuperMalloc: A Super Fast Multithreaded malloc() for 64-bit Machines](http://conf.researchr.org/event/ismm-2015/ismm-2015-papers-supermalloc-a-super-fast-multithreaded-malloc-for-64-bit-machines)
* Xenomai 3 內建 TLSF: [lib/boilerplate/tlsf/tlsf.c](http://git.xenomai.org/xenomai-3.git/tree/lib/boilerplate/tlsf/tlsf.c)
* [reddit: Github got 30% better performance using TCMalloc with MySQL](https://www.reddit.com/r/programming/comments/18zija/github_got_30_better_performance_using_tcmalloc/)
* [Understanding glibc malloc](https://sploitfun.wordpress.com/2015/02/10/understanding-glibc-malloc/)
* 注意細節 : lock(smp environment) , memory leak , fragmention / buddy system實作
* [A Malloc Tutorial](http://www.inf.udec.cl/~leo/Malloc_tutorial.pdf)
* [Cache Coherence](https://www.wikiwand.com/en/Cache_coherence)
* [Memory barrier](https://www.wikiwand.com/en/Memory_barrier)
* [Memory Pool 的 設計哲學和無痛運用](http://jjhou.boolan.com/programmer-13-memory-pool.pdf)
* [TLSF: a New Dynamic Memory Allocator for Real-Time Systems](http://www.gii.upv.es/tlsf/files/ecrts04_tlsf.pdf)
* 這篇使用的硬體沒有MMU
* [How Memory Allocation Affects Performance in Multithreaded Programs](http://www.oracle.com/technetwork/articles/servers-storage-dev/mem-alloc-1557798.html)
* [Apache madvise experiment](http://people.apache.org/~gbowyer/madvise-perf/)
* [jeMalloc](http://people.freebsd.org/~jasone/jemalloc/bsdcan2006/jemalloc.pdf)
* [History of Memory Models - MIT open course](https://www.youtube.com/watch?v=3e1ZF1L1VhY&feature=youtu.be&list=PLUl4u3cNGP61hsJNdULdudlRL493b-XZf)
* [A Study on Dynamic Memory Allocation Mechanisms for Small Block Sizes in Real-Time Embedded Systems](http://jultika.oulu.fi/files/nbnfioulu-201302081026.pdf) (2012)
* [CAMA: Cache-Aware Memory Allocation for WCET Analysis](http://www.rw.cdl.uni-saarland.de/~jherter/papers/camaecrts08.pdf)
* [Dynamic Memory Management for Embedded Real-Time Systems](http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.102.74&rep=rep1&type=pdf)
* [Super Allocator](https://eci.exascale-tech.com/wiki/images/8/8c/OCR_memory_hierarchy_allocation_system_-_intel.pdf) for Open Collaborative/Community Runtime (OCR)
* [OCR git repositories](https://xstack.exascale-tech.com/wiki/index.php/Main_Page)
* [Open Community Runtime](https://01.org/open-community-runtime) at 01.org
* creating a runtime framework that explores new programming methods for machines with high core count. The initial focus is on HPC applications. Its goal is to create a framework and reference implementation to help developers explore programming methods to improve the power efficiency, programability, and reliability of HPC applications while maintaining app performance.
* [Fast, Multicore-Scalable, Low-Fragmentation Memory Allocation through Large Virtual Memory and Global Data Structures](http://www.cs.uni-salzburg.at/~ck/content/publications/conferences/OOPSLA15-Scalloc.pdf)
## Implementations & Tools
**Implementations**
* Linaro 蒐集的 [notes and ideas on improving glibc malloc performance](https://wiki.linaro.org/WorkingGroups/ToolChain/LibraryPerformance/GlibcPerformance/GlibcMalloc)
* [cortex-malloc](https://git.linaro.org/toolchain/cortex-malloc.git)
* [small - a collection of Specialized Memory ALLocators for small allocations](https://github.com/tarantool/small)
* [mallocMC: Memory Allocator for Many Core Architectures](https://github.com/ComputationalRadiationPhysics/mallocMC)
* [scalloc: A Fast, Multicore-Scalable, Low-Memory-Overhead Allocator](http://scalloc.cs.uni-salzburg.at/)
* [SSMalloc](http://ipads.se.sjtu.edu.cn/doku.php?id=pub:projects:ssmalloc): A Low-latency, Locality-conscious Memory Allocator with Stable Performance Scalability
* [lockfree-malloc](https://github.com/Begun/lockfree-malloc) : The world’s first Web-scale memory allocator
* [memory_library](https://github.com/rampantpixels/memory_lib): Lock-free memory allocator (C11)
* [fc_malloc](https://github.com/bytemaster/fc_malloc): Lock-Free, Wait-Free, CAS-free, thread-safe, memory allocator.
* [wfmalloc](https://github.com/ashish-17/wfmalloc): Wait-Free dynamic memory allocator.
* [Adaptive allocators](http://www.ercoppa.org/malloc/) (BSA)
* [DieHard](https://github.com/emeryberger/DieHard): An error-resistant memory allocator
**Benchmarks**
* [malloc-survey](https://github.com/r-lyeh/malloc-survey): 包含大量的實做測試與比較
* [Concurrent Memory Allocator Benchmarks](https://github.com/aysylu/malloc/tree/master/benchmarks)
* [Memory Fragmentation/Malloc Benchmark](https://github.com/jffrosen/fragbench)
* [malloc_count](https://github.com/bingmann/malloc_count): Method to measure the amount of allocated memory of a program at run-time.
* [Benchmarking memory allocators](https://www.google.com.tw/url?sa=t&rct=j&q=&esrc=s&source=web&cd=7&cad=rja&uact=8&ved=0ahUKEwjLrLSDyvzMAhVEkJQKHdncCsYQFghHMAY&url=http%3A%2F%2Fwww.helsinki.fi%2F~joorava%2Fmemory%2F&usg=AFQjCNELj9rKm6jjBMd5YS7WAaRX4-Juhg&sig2=z-QFyzYRqcnVz20Cg7hsXg)
* [malloc() Performance in a Multithreaded Linux Environment](http://www.citi.umich.edu/techreports/reports/citi-tr-00-5.pdf) [投影片](http://people.freebsd.org/~jasone/jemalloc/bsdcan2006/BSDcan2006_slides.pdf)
* [scalloc-artifact](https://github.com/cksystemsgroup/scalloc-artifact), [[scalloc source](https://github.com/cksystemsgroup/scalloc.git)]
* [memory allocation for long-running server applications](http://delivery.acm.org/10.1145/290000/286880/p176-larson.pdf?ip=140.112.48.70&id=286880&acc=ACTIVE%20SERVICE&key=AF37130DAFA4998B%2EEE7BEA59C98A8EF6%2E4D4702B0C3E38B35%2E4D4702B0C3E38B35&CFID=788282193&CFTOKEN=37630263&__acm__=1465030145_2745fab37af59fa32f3393b95059b369)
* [wfmalloc-test-framework](https://github.com/ashish-17/wfmalloc-test-framework): Testing framework for wfmalloc benchmarking
* [custom-memory-allocator](https://github.com/ashish-17/custom-memory-allocator): Create a custom memory allocator and compare it with existing ones
* [Test harness for malloc](https://blogs.oracle.com/rweisner/entry/test_harness_for_malloc)
**Tools**
* [LibMallocTrace](https://github.com/timm-allman/LibMallocTrace): A simple library that traces all malloc/free and mmap/munmap calls.