# Exploring Contract Deployment Design in Ethereum Layer-2 Solutions
> How SmartContract ByteCode published on Data Availability layer in Ethereum Rollups
## Introduction
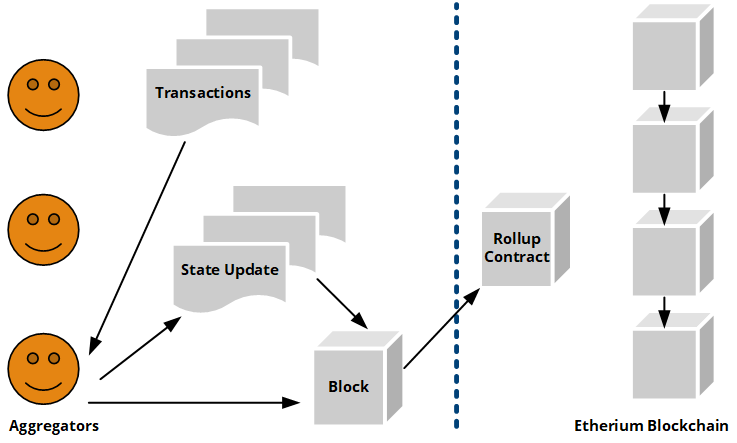
In the ever-evolving landscape of Ethereum's blockchain, scalability remains a paramount challenge, prompting the development of sophisticated solutions known as rollups. These innovative mechanisms enhance Ethereum's capacity by batching numerous transactions off-chain and subsequently validating their integrity on Layer 1. This article presupposes that readers possess a high-level understanding of rollups and their operational dynamics, focusing on their pivotal role as a scaling solution.
At the heart of rollup technology lie **two fundamental challenges**:
* validating the authenticity of data published (new L2 state)
* determining the optimal location for this data's publication.
These issues are critical in ensuring the seamless operation of rollups, alongside addressing the intricacies of bridging and communication between Layer 1 and Layer 2 (L1<->L2).
This blog post aims to delve into the **data availability mechanisms** within the context of rollups, particularly examining how they manage the publication and verification of smart contract source codes or **bytecodes deployed on them**.
[diagram source](https://blockchain-academy.hs-mittweida.de/2021/10/ethereum-scaling-keys-zk-rollups-and-optimistic-rollups/)
## Classifying Rollups
transaction compressed based rollup => send tx to zero address for deploying
state-diff based rollup => Declare on L1 => Deploy on L2
---
**Another reason why solutions like zkSync and StarkNet opt for a two-step contract deployment process is due to their use of native account abstraction. This approach allows them to save significant space. Instead of storing bytecode for each account separately, they publish the code once for the account abstraction, and then all accounts simply reference it. This method is efficient because it avoids the redundancy of storing identical code multiple times, streamlining the storage process on the blockchain.**
---
### Scroll
fully compatible with mainnet -> send init code to zero address and send tx data to l1 as data availability
scroll sends tx summary to L1 for DA
Scroll provides data availability for its L2 smart contract source code by ensuring that all executed transactions are recorded on-chain. This approach allows anyone monitoring the contract to know the correct state of the rollup chain. The system's architecture includes several smart contracts that play crucial roles in this process
> SELFDESTRUCT selfdestruct Disabled. If the opcode is encountered, the transaction will be reverted.2
one of the reason for disabling self destruct is their approach
Additional Fields
We added two fields in the current StateAccount object: PoseidonCodehash and CodeSize.
```
type StateAccount struct {
Nonce uint64
Balance *big.Int
Root common.Hash // merkle root of the storage trie
KeccakCodeHash []byte // still the Keccak codehash
// added fields
PoseidonCodeHash []byte // the Poseidon codehash
CodeSize uint64
}
```
CodeHash
Related to this, we maintain two types of codehash for each contract bytecode: Keccak hash and Poseidon hash.
KeccakCodeHash is kept to maintain compatibility for EXTCODEHASH. PoseidonCodeHash is used for verifying the correctness of bytecodes loaded in the zkEVM, where Poseidon hashing is far more efficient.
This document describes zkTrie, a sparse binary Merkle Patricia Trie used to store key-value pairs efficiently. It explains the tree structure, construction, node hashing, and tree operations, including insertion and deletion.
Scroll is a general-purpose ZK rollup that uses the EVM for off-chain computations. Scroll’s execution layer functions similarly to Ethereum’s - transactions are batched into blocks, and then the blocks are executed according to the EVM specs (we actually use a slightly modified version of Geth). This means that users can interact with Scroll in the same way that they would interact with Ethereum. It also means that developers can develop on top of Scroll just as they would develop on top of Ethereum.
Transaction Batching
In Scroll, the transactions are batched in multiple tiers.

A group of ordered transactions are packed into a block.
A series of contiguous blocks are grouped into a chunk. The chunk is the base unit for proof generation of the zkEVM circuit.
A series of contiguous chunks are grouped into a batch. The batch is the base unit for data commitment and proof verification on the L1. The proof for a batch, or a batch proof, is an aggregated proof of the chunk proofs in this batch.
The goal for this multi-layer batching schema is to reduce the gas cost of onchain data commitment and proof verification. This approach increases the granularity of the rollup units on L1 while takes the fixed circuit capacity into consideration. As a result, batching reduces the data to be stored in the contract and amortizes the proof verification cost to more L2 transactions.
Once a chunk is created, a corresponding chunk proving task will be generated and sent to a zkEVM prover. Upon the creation of a new batch, two subsequent actions occur: (a) the rollup node commits the transaction data and block information from this batch to the L1 contract, and (b) a batch proving task to aggregate chunk proofs is dispatched to an aggregator prover. The standards for proposing a chunk and a batch are detailed in the Rollup Node.
### Polygon ZKEvm
Ethereum Equivalence: Polygon zkEVM aims to provide full EVM equivalence, ensuring that most Ethereum smart contracts, wallets, tools, and infrastructure work seamlessly on the zkEVM layer. This compatibility means that developers do not need to rewrite or adjust their code, offering a near-identical experience to Ethereum L1 with significant scalability improvements
polygon in this section is so much similar to scroll because the polygon zkevm project is evm equivilent not just compatible. and in the pure evm contract deployment shouldbe the same.
All of the data needed for proof construction is published on chain. Unlike most ZK rollups transactions are posted instead of state diffs
One of the differences between Polygon zkEVM and Ethereum is in the way their states are recorded. Ethereum uses Patricia Merkle tries while Polygon zkEVM uses Sparse Merkle trees (SMTs). The Concepts section therefore discusses how SMTs are constructed and the operations executable on the SMTs. These are Create, Read, Update and Delete, or simply CRUD.
### Starknet
Declare on L1 => Deploy on L2
https://docs.starknet.io/documentation/architecture_and_concepts/Smart_Contracts/contract-classes/
https://docs.openzeppelin.com/contracts-cairo/0.6.1/udc
https://l2beat.com/scaling/projects/starknet
https://docs.starknet.io/documentation/architecture_and_concepts/Smart_Contracts/contract-classes/
The state commitment scheme uses a binary Merkle-Patricia trie with the Pedersen hash function.
### Zksync Era
Declare on L1 => Deploy on L2
https://docs.zksync.io/build/developer-reference/contract-deployment.html
https://web.archive.org/web/20240117035043/https://blog.quarkslab.com/zksync-transaction-workflow.html
https://docs.zksync.io/build/developer-reference/contract-deployment.html
### Arbitrum
same -> transaction to zero address
### Optimism
same -> transaction to zero address