---
tags: linux2022
---
# K08: ktcp
contributed by < `eric88525` >
## :checkered_flag: 自我檢查清單
- [x] 參照 [Linux 核心模組掛載機制](https://hackmd.io/@sysprog/linux-kernel-module),解釋 `$ sudo insmod khttpd.ko port=1999` 這命令是如何讓 `port=1999` 傳遞到核心,作為核心模組初始化的參數呢?
> 過程中也會參照到 [你所不知道的 C 語言:連結器和執行檔資訊](https://hackmd.io/@sysprog/c-linker-loader)
- [ ] 參照 [CS:APP 第 11 章](https://hackmd.io/s/ByPlLNaTG),給定的 kHTTPd 和書中的 web 伺服器有哪些流程是一致?又有什麼是你認為 kHTTPd 可改進的部分?
- [x] `htstress.c` 用到 [epoll](http://man7.org/linux/man-pages/man7/epoll.7.html) 系統呼叫,其作用為何?這樣的 HTTP 效能分析工具原理為何?
- [x] 給定的 `kecho` 已使用 CMWQ,請陳述其優勢和用法
- [x] 核心文件 [Concurrency Managed Workqueue (cmwq)](https://www.kernel.org/doc/html/latest/core-api/workqueue.html) 提到 "The original create_`*`workqueue() functions are deprecated and scheduled for removal",請參閱 Linux 核心的 git log (不要用 Google 搜尋!),揣摩 Linux 核心開發者的考量
- [x] 解釋 `user-echo-server` 運作原理,特別是 [epoll](http://man7.org/linux/man-pages/man7/epoll.7.html) 系統呼叫的使用
- [x] 是否理解 `bench` 原理,能否比較 `kecho` 和 `user-echo-server` 表現?佐以製圖
- [x] 解釋 `drop-tcp-socket` 核心模組運作原理。`TIME-WAIT` sockets 又是什麼?
# Linux 核心模組參數傳遞
> 參照 [Linux 核心模組掛載機制](https://hackmd.io/@sysprog/linux-kernel-module),解釋 `$ sudo insmod khttpd.ko port=1999` 這命令是如何讓 `port=1999` 傳遞到核心,作為核心模組初始化的參數呢?
> 內容參考 [KYG-yaya573142](https://hackmd.io/@KYWeng/H1OBDQdKL)
如果要在 insmod 時候初始化 module parameters,可以在 insmod 最後加入多個 `變數名稱=值`來初始化。
```c
insmod hellop howmany=10 whom="Mom"
```
使用的前提是在 module 需要先註冊好這些變數,而 module_param 是定義在 `moduleparam.h` 內的 macro
```c
static char *whom = "world";
static int howmany = 1;
module_param(howmany, int, S_IRUGO);
module_param(whom, charp, S_IRUGO);
```
[linux v5.17.9 的巨集定義 ](https://elixir.bootlin.com/linux/latest/source/include/linux/moduleparam.h#L126):
根據註解
+ name: 要註冊的變數
+ type: 參數型態 (byte, hexint, short, ushort, int, uint, long, ulong, charp, bool, invbool)
+ perm: 在 sysfs 的權限
展開後會執行:
1. module_param 先透過 `param_check_##type` 檢查變數型態
2. `module_param_cb` 註冊變數
3. `__MODULE_PARM_TYPE` 註冊核心模組資訊,如同註冊`MODULE_LICENSE`、`MODULE_DESCRIPTION` 一樣
```c
#define module_param(name, type, perm) \
module_param_named(name, name, type, perm)
#define module_param_named(name, value, type, perm) \
param_check_##type(name, &(value)); \
module_param_cb(name, ¶m_ops_##type, &value, perm); \
__MODULE_PARM_TYPE(name, #type)
```
### Step1. 變數型態檢查(以 short 為例)
+ `__always_unused` 為告訴編譯器這段不會有其他程式用到,抑制相關警告訊息
```c
#define param_check_short(name, p) __param_check(name, p, short)
#define __param_check(name, p, type) \
static inline type __always_unused *__check_##name(void) { return(p); }
```
### Step2. 註冊變數
+ 從第 9 行開始初始化一個 `kernel_param` 的 struct
```c=
#define module_param_cb(name, ops, arg, perm) \
__module_param_call(MODULE_PARAM_PREFIX, name, ops, arg, perm, -1, 0)
/* This is the fundamental function for registering boot/module
parameters. */
#define __module_param_call(prefix, name, ops, arg, perm, level, flags) \
/* Default value instead of permissions? */ \
static const char __param_str_##name[] = prefix #name; \
static struct kernel_param __moduleparam_const __param_##name \
__used __section("__param") \
__aligned(__alignof__(struct kernel_param)) \
= { __param_str_##name, THIS_MODULE, ops, \
VERIFY_OCTAL_PERMISSIONS(perm), level, flags, { arg } }
```
kernel_param 的結構如下
```c
// at include/linux/moduleparam.h
struct kernel_param {
const char *name; // __param_str_port
struct module *mod; // THIS_MODULE
const struct kernel_param_ops *ops; //
const u16 perm;
s8 level;
u8 flags;
union {
void *arg;
const struct kparam_string *str;
const struct kparam_array *arr;
};
};
```
### Step3. 註冊到模組資訊
〈[Linux 核心模組運作原理](https://hackmd.io/@sysprog/linux-kernel-module)〉有說明
```c
#define __MODULE_PARM_TYPE(name, _type) \
__MODULE_INFO(parmtype, name##type, #name ":" _type)
```
`__MODULE_INFO` 展開後
1. 為輸入產生一個不重複的名字
2. 透過 __attribute__ 告訴編譯器放在 .modinfo 區塊
3. unused 為沒任何程式用到,不須警告
4. aligned = 1
```c
// include/linux/moduleparam.h:
#define __MODULE_INFO(tag, name, info) \
static const char __UNIQUE_ID(name)[] \
__used __section(".modinfo") __aligned(1) \
= __MODULE_INFO_PREFIX __stringify(tag) "=" info
```
註冊 port 變數 `module_param(port, ushort, S_IRUGO)` 展開為
```c
// static const char 獨一無二的變數[] = "tag=info"
static const char 獨一無二的變數[] = "parmtype=port:ushort"
```
執行 `objdump -s khttpd.ko` 後,可以在 .modinfo 區塊看到 `parmtype=port:ushort`
```
Contents of section .modinfo:
0000 76657273 696f6e3d 302e3100 64657363 version=0.1.desc
0010 72697074 696f6e3d 696e2d6b 65726e65 ription=in-kerne
0020 6c204854 54502064 61656d6f 6e006175 l HTTP daemon.au
0030 74686f72 3d4e6174 696f6e61 6c204368 thor=National Ch
0040 656e6720 4b756e67 20556e69 76657273 eng Kung Univers
0050 6974792c 20546169 77616e00 6c696365 ity, Taiwan.lice
0060 6e73653d 4475616c 204d4954 2f47504c nse=Dual MIT/GPL
0070 00706172 6d747970 653d6261 636b6c6f .parmtype=backlo
0080 673a7573 686f7274 00706172 6d747970 g:ushort.parmtyp
0090 653d706f 72743a75 73686f72 74007372 e=port:ushort.sr
00a0 63766572 73696f6e 3d324434 35363136 cversion=2D45616
00b0 39433933 35313738 31443331 33323334 9C9351781D313234
00c0 00646570 656e6473 3d007265 74706f6c .depends=.retpol
00d0 696e653d 59006e61 6d653d6b 68747470 ine=Y.name=khttp
00e0 64007665 726d6167 69633d35 2e31312e d.vermagic=5.11.
00f0 302d3431 2d67656e 65726963 20534d50 0-41-generic SMP
0100 206d6f64 5f756e6c 6f616420 6d6f6476 mod_unload modv
0110 65727369 6f6e7320 00 ersions .
```
當我們實際執行 `sudo strace insmod khttpd.ko port=1999 apple=131 `,可以看到使用到 `finit_module` system call,而我們傳入的多個變數字串,中間用一個空格分開
```c
finit_module(3, "port=1999 apple=131", 0) = -1 EEXIST (File exists)
```
### finit_module
實際的執行由 load_module 完成
:::spoiler finit_module
```c
// kernel/module.c
SYSCALL_DEFINE3(finit_module, int, fd, const char __user *, uargs, int, flags)
{
struct load_info info = { };
void *buf = NULL;
int len;
int err;
err = may_init_module();
if (err)
return err;
pr_debug("finit_module: fd=%d, uargs=%p, flags=%i\n", fd, uargs, flags);
if (flags & ~(MODULE_INIT_IGNORE_MODVERSIONS
|MODULE_INIT_IGNORE_VERMAGIC
|MODULE_INIT_COMPRESSED_FILE))
return -EINVAL;
len = kernel_read_file_from_fd(fd, 0, &buf, INT_MAX, NULL,
READING_MODULE);
if (len < 0)
return len;
if (flags & MODULE_INIT_COMPRESSED_FILE) {
err = module_decompress(&info, buf, len);
vfree(buf); /* compressed data is no longer needed */
if (err)
return err;
} else {
info.hdr = buf;
info.len = len;
}
return load_module(&info, uargs, flags);
}
```
:::
### load_module
1. 把傳入的 args 複製到 mod->args
2. 傳入 parse_args
:::spoiler load_module
```c
// kernel/module.c
/*
* Allocate and load the module: note that size of section 0 is always
* zero, and we rely on this for optional sections.
*/
static int load_module(struct load_info *info, const char __user *uargs,
int flags)
{
struct module *mod;
long err = 0;
char *after_dashes;
...
/* Now copy in args */
mod->args = strndup_user(uargs, ~0UL >> 1);
if (IS_ERR(mod->args)) {
err = PTR_ERR(mod->args);
goto free_arch_cleanup;
}
init_build_id(mod, info);
dynamic_debug_setup(mod, info->debug, info->num_debug);
...
/* Module is ready to execute: parsing args may do that. */
after_dashes = parse_args(mod->name, mod->args, mod->kp, mod->num_kp,
-32768, 32767, mod,
unknown_module_param_cb);
if (IS_ERR(after_dashes)) {
err = PTR_ERR(after_dashes);
goto coming_cleanup;
} else if (after_dashes) {
pr_warn("%s: parameters '%s' after `--' ignored\n",
mod->name, after_dashes);
}
...
return err;
}
```
:::
### parse_args
1. 在第25行 `args = next_arg(args, ¶m, &val)` 將字串分析,存到 param 和 val
2. 第30行 `ret = parse_one(param, val, doing, params, num,..)` 將初始化的數值,指派到 `const struct kernel_param *params` 內
:::spoiler parse_args
```c=
// kernel/params.c
/* Args looks like "foo=bar,bar2 baz=fuz wiz". */
char *parse_args(const char *doing,
char *args,
const struct kernel_param *params,
unsigned num,
s16 min_level,
s16 max_level,
void *arg,
int (*unknown)(char *param, char *val,
const char *doing, void *arg))
{
char *param, *val, *err = NULL;
/* Chew leading spaces */
args = skip_spaces(args);
if (*args)
pr_debug("doing %s, parsing ARGS: '%s'\n", doing, args);
while (*args) {
int ret;
int irq_was_disabled;
args = next_arg(args, ¶m, &val);
/* Stop at -- */
if (!val && strcmp(param, "--") == 0)
return err ?: args;
irq_was_disabled = irqs_disabled();
ret = parse_one(param, val, doing, params, num,
min_level, max_level, arg, unknown);
if (irq_was_disabled && !irqs_disabled())
pr_warn("%s: option '%s' enabled irq's!\n",
doing, param);
switch (ret) {
case 0:
continue;
case -ENOENT:
pr_err("%s: Unknown parameter `%s'\n", doing, param);
break;
case -ENOSPC:
pr_err("%s: `%s' too large for parameter `%s'\n",
doing, val ?: "", param);
break;
default:
pr_err("%s: `%s' invalid for parameter `%s'\n",
doing, val ?: "", param);
break;
}
err = ERR_PTR(ret);
}
return err;
}
```
:::
### parse_one
for loop 會去檢查此變數是否存在,如果存在則指派數值
```c
static int parse_one(char *param,
char *val,
const char *doing,
const struct kernel_param *params,
unsigned num_params,
s16 min_level,
s16 max_level,
void *arg,
int (*handle_unknown)(char *param, char *val,
const char *doing, void *arg))
{
unsigned int i;
int err;
/* Find parameter */
for (i = 0; i < num_params; i++) {
if (parameq(param, params[i].name)) {
if (params[i].level < min_level
|| params[i].level > max_level)
return 0;
/* No one handled NULL, so do it here. */
if (!val &&
!(params[i].ops->flags & KERNEL_PARAM_OPS_FL_NOARG))
return -EINVAL;
pr_debug("handling %s with %p\n", param,
params[i].ops->set);
kernel_param_lock(params[i].mod);
if (param_check_unsafe(¶ms[i]))
err = params[i].ops->set(val, ¶ms[i]);
else
err = -EPERM;
kernel_param_unlock(params[i].mod);
return err;
}
}
if (handle_unknown) {
pr_debug("doing %s: %s='%s'\n", doing, param, val);
return handle_unknown(param, val, doing, arg);
}
pr_debug("Unknown argument '%s'\n", param);
return -ENOENT;
}
```
---
# HTTP 伺服器處理流程
> 參照 CS:APP 第 11 章,給定的 kHTTPd 和書中的 web 伺服器有哪些流程是一致?又有什麼是你認為 kHTTPd 可改進的部分?
>
[csapp:11 筆記](https://hackmd.io/@eric88525/csapp-11)
課程介紹的 web server

以下為書中示範的 server 程式碼,可以看到都是在 user space 中執行
:::spoiler server code
```c
/*
* echoserveri.c - An iterative echo server
*/
#include "csapp.h"
/*
* echo - read and echo text lines until client closes connection
*/
void echo(int connfd)
{
size_t n;
char buf[MAXLINE];
rio_t rio;
Rio_readinitb(&rio, connfd);
while((n = Rio_readlineb(&rio, buf, MAXLINE)) != 0) { //line:netp:echo:eof
printf("server received %d bytes\n", (int)n);
Rio_writen(connfd, buf, n);
}
}
int main(int argc, char **argv)
{
int listenfd, connfd;
socklen_t clientlen;
struct sockaddr_storage clientaddr; /* Enough space for any address */ //line:netp:echoserveri:sockaddrstorage
char client_hostname[MAXLINE], client_port[MAXLINE];
if (argc != 2) {
fprintf(stderr, "usage: %s <port>\n", argv[0]);
exit(0);
}
listenfd = Open_listenfd(argv[1]);
while (1) {
clientlen = sizeof(struct sockaddr_storage);
connfd = Accept(listenfd, (SA *)&clientaddr, &clientlen);
Getnameinfo((SA *) &clientaddr, clientlen, client_hostname, MAXLINE,
client_port, MAXLINE, 0);
printf("Connected to (%s, %s)\n", client_hostname, client_port);
echo(connfd);
Close(connfd);
}
exit(0);
}
```
:::
khttp 則是一個 kernel module,有些函式跟 user space 用法不同
| user | kernel |
| -------- | -------- |
| socket | sock_create|
|bind|kernel_bind|
|listen|kernel_listen|
|accept|kernel_accept|
```graphviz
digraph{
node [shape=box];
khttp_init-> http_server_daemon [label="kthread_run"];
http_server_daemon->http_server_worker [label="kthread_run"];
rankdir="LR";
}
```
## khttp_init
負責 socket 建立 / bind / listen,類似 `open_listenfd`
+ sock_create
+ kernel_bind
+ kernel_listen
## http_server_daemon
負責接收連線( kernel_accept ),執行 http_server_worker
命名方面 **daemon** 在電腦術語中代表後台程式
> In multitasking computer operating systems, a daemon is a computer program that runs as a background process, rather than being under the direct control of an interactive user
## http_server_worker
執行主要任務
## kHTTPd 改進
參考 [KYG-yaya573142](https://hackmd.io/@KYWeng/H1OBDQdKL) 的報告,由於 request->request_url 為 `char [128]`,因此要先計算串接後字串長度避免 core dump。
```c
static int http_parser_callback_request_url(http_parser *parser,
const char *p,
size_t len)
{
struct http_request *request = parser->data;
size_t old_len = strlen(request->request_url);
if ((old_len + len) > 127) {
pr_err("url error: url truncated!\n");
len = 127 - old_len;
}
strncat(request->request_url, p, len);
return 0;
}
```
:::warning
應描述針對 kHTTPd 的缺失,並擬定改進方案。上述的記憶體管理只是冰山一角,還有好多要改進!
:notes: jserv
:::
---
# epoll 系統呼叫
> htstress.c 用到 epoll 系統呼叫,其作用為何?這樣的 HTTP 效能分析工具原理為何?
在閱讀多方教材後,整理出 [epoll 筆記](https://hackmd.io/@eric88525/epoll-intro)
epoll 的好處在於:
+ 可以同時監控許多 fd,不像 select 有所限制
+ 透過紅黑樹結構新增/查找 fd ,I/O 效率不像是 **poll** 會隨著 fd 增加而下降
+ epoll 複雜度分為 epoll_wait 和 epoll_ctl
+ epoll_wait 只負責取出 ready list,而 ready list 平時是由 epoll instance 來維護,因此複雜度為 $O(1)$
+ epoll_ctl 負責新增刪除修改監控的 fd,由於內部資料結構是紅黑樹,複雜度為 $O(logn)$
用在 htstress.c 程式能大幅減少輪詢時間,減少 IO 時間
## 在 htstress 內的使用情況:
**main**
1. parse arguments
2. 建立 num_threads 個 thread,每個 thread 執行 worker()
3. 輸出結果
**worker**
1. 建立 epoll 物件
2. 建立 concurrency 個連線(每個連線都是一個 fd ),並用 epoll 物件來監管這些 fd
3. 重複迴圈執行 `epoll_wait` ,當有 fd 在 ready list 時,檢查每一個fd 的狀態,執行對應動作
+ `EPOLLOUT`: The associated file is available for write(2) operations.
+ `EPOLLIN`: The associated file is available for read(2) operations.
4. 所有連線結束,結束 worker
---
# CMWQ
> 給定的 kecho 已使用 CMWQ,請陳述其優勢和用法
先定義一些名詞
+ work 要被執行的任務(例如某個 function)
+ worker 執行任務的單位
傳統的 multi thread 和 single thread 的缺點
+ 發布任務和執行任務的是同一個 cpu ,這會造成其他 cpu 在空等
+ 如果有兩個 work A 和 B,B 需要 A 先完成,這兩者都被安排到同一個 worker ,並且 B 先被執行,就會發生 **deadlock**
CMWQ 提出了 **worker pool** 的概念,讓任務發佈者跟執行者不一定要相同 cpu
概念如下圖所示
+ 當有 work 需要被執行,會先丟到 workqueue 內,再由 pwq 來自動分配要由哪個 worker_pool 來執行。

## worker
執行 work 的單位叫做 worker,worker 的集合形成 worker_pool。
worker_pool 分兩種
+ **normal worker_pool**
+ 默認情況下 work 都是在這處理
+ 每個 cpu 有兩個 normal worker_pool,一個普通優先級別,另一個高優先級別
+ **unbound worker_pool**
+ 顧名思義,worker_pool 可以調動多個 cpu 上的 worker,具體數量為動態決定
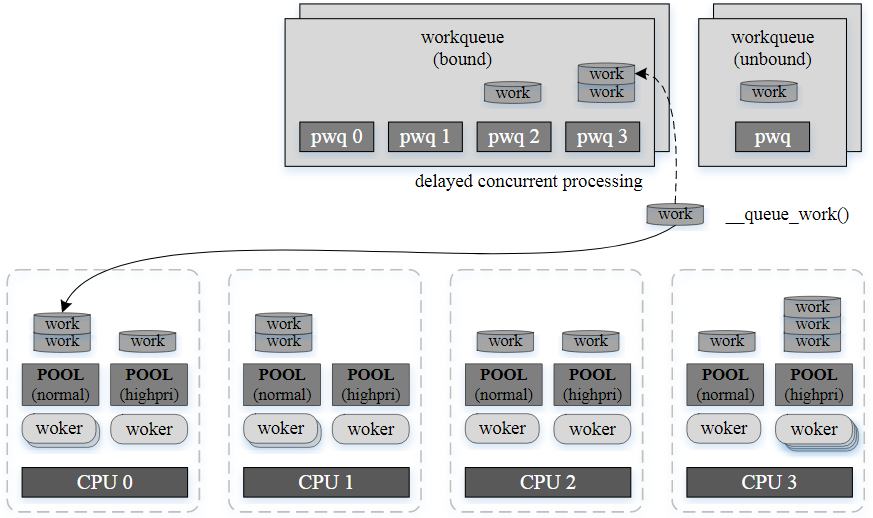
我們可透過以下命令來查看 cpu 的 worker pool
第一行中的 `kworker/0:0H` 格式為 `kworker/{cpu}:{id}{'H' 表示高優先級別}`
```c
$ ps -ef |grep kworker
root 6 2 0 五 07 ? 00:00:00 [kworker/0:0H-events_highpri]
root 22 2 0 五 07 ? 00:00:00 [kworker/1:0H-events_highpri]
root 28 2 0 五 07 ? 00:00:00 [kworker/2:0H-events_highpri]
root 34 2 0 五 07 ? 00:00:00 [kworker/3:0H-events_highpri]
.
.
.
root 2704538 2 0 06:34 ? 00:00:00 [kworker/1:2-events]
root 2705564 2 0 06:51 ? 00:00:00 [kworker/u64:0-events_unbound]
root 2705764 2 0 06:57 ? 00:00:00 [kworker/3:1-events]
root 2706456 2 0 07:16 ? 00:00:00 [kworker/u64:3-ext4-rsv-conversion]
```
## work
work 存在於 workque 內的格式為 `work_struct`,除了任務本身還記載了其他資訊
```c
struct work_struct {
struct list_head entry; // 掛載於 workqueue 的節點
work_func_t func; // 要執行的任務
atomic_long_t data; // 如下圖
};
```

## workqueue
```c
struct workqueue_attrs {
int nice;
cpumask_var_t cpumask;
bool no_numa;
};
```
## 在 kecho 的使用
```graphviz
digraph{
node [shape=box]
work_queue [shape=box3d]
socket [shape=oval]
socket->create_work [label="accept"]
create_work->work_queue [label="queue_work"]
alloc_workqueue->work_queue [label="create"]
rankdir="LR"
}
```
### alloc_workqueue
在第 71 行使用到了 `alloc_workqueue` 來分配一個 workque,此程式 (kecho) 預設 workque 為 unbound。前面提到的 unbound workque 可以透過 flag = `WQ_UNBOUND` 來設定
```c
/**
* alloc_workqueue - allocate a workqueue
* @fmt: printf format for the name of the workqueue
* @flags: WQ_* flags
* @max_active: max in-flight work items, 0 for default
* @args...: args for @fmt
*
* Allocate a workqueue with the specified parameters. For detailed
* information on WQ_* flags, please refer to Documentation/workqueue.txt.
*
* The __lock_name macro dance is to guarantee that single lock_class_key
* doesn't end up with different namesm, which isn't allowed by lockdep.
*
* RETURNS:
* Pointer to the allocated workqueue on success, %NULL on failure.
*/
#define alloc_workqueue(fmt, flags, max_active, args...)
```
:::spoiler kecho_mod.c
```c=42
struct workqueue_struct *kecho_wq;
static int kecho_init_module(void)
{
int error = open_listen(&listen_sock);
if (error < 0) {
printk(KERN_ERR MODULE_NAME ": listen socket open error\n");
return error;
}
param.listen_sock = listen_sock;
/*
* Create a dedicated workqueue instead of using system_wq
* since the task could be a CPU-intensive work item
* if its lifetime of connection is too long, e.g., using
* `telnet` to communicate with kecho. Flag WQ_UNBOUND
* fits this scenario. Note that the trade-off of this
* flag is cache locality.
*
* You can specify module parameter "bench=1" if you won't
* use telnet-like program to interact with the module.
* This earns you better cache locality than using default
* flag, `WQ_UNBOUND`. Note that your machine may going
* unstable if you use telnet-like program along with
* module parameter "bench=1" to interact with the module.
* Since without `WQ_UNBOUND` flag specified, a
* long-running task may delay other tasks in the kernel.
*/
kecho_wq = alloc_workqueue(MODULE_NAME, bench ? 0 : WQ_UNBOUND, 0);
echo_server = kthread_run(echo_server_daemon, ¶m, MODULE_NAME);
if (IS_ERR(echo_server)) {
printk(KERN_ERR MODULE_NAME ": cannot start server daemon\n");
close_listen(listen_sock);
}
return 0;
}
```
:::
在 `kecho_mod.c` ,我們已經建立好了名為 `kecho_wq` 的 workque,接下來要把任務加入到 workque 內執行,步驟為
1. 把任務包成 work_struct 結構
2. 加入 workque
我們自定義的函式 `create_work` ,把 accept 後的 socket 轉成 `struct kecho`
```c
/* echo_server.h */
struct kecho {
struct socket *sock;
struct list_head list;
struct work_struct kecho_work; // 透過 INIT_WORK 來和 echo_server_worker 綁定
};
```
最後回傳 `&kecho->kecho_work`,在 160 行的 `queue_work` 加入 work queue 中來執行。
:::spoiler echo_server.c
```c=100
static struct work_struct *create_work(struct socket *sk)
{
struct kecho *work;
if (!(work = kmalloc(sizeof(struct kecho), GFP_KERNEL)))
return NULL;
work->sock = sk;
INIT_WORK(&work->kecho_work, echo_server_worker);
list_add(&work->list, &daemon.worker);
return &work->kecho_work;
}
/* it would be better if we do this dynamically */
static void free_work(void)
{
struct kecho *l, *tar;
/* cppcheck-suppress uninitvar */
list_for_each_entry_safe (tar, l, &daemon.worker, list) {
kernel_sock_shutdown(tar->sock, SHUT_RDWR);
flush_work(&tar->kecho_work);
sock_release(tar->sock);
kfree(tar);
}
}
int echo_server_daemon(void *arg)
{
struct echo_server_param *param = arg;
struct socket *sock;
struct work_struct *work;
allow_signal(SIGKILL);
allow_signal(SIGTERM);
INIT_LIST_HEAD(&daemon.worker);
while (!kthread_should_stop()) {
/* using blocking I/O */
int error = kernel_accept(param->listen_sock, &sock, 0);
if (error < 0) {
if (signal_pending(current))
break;
printk(KERN_ERR MODULE_NAME ": socket accept error = %d\n", error);
continue;
}
if (unlikely(!(work = create_work(sock)))) {
printk(KERN_ERR MODULE_NAME
": create work error, connection closed\n");
kernel_sock_shutdown(sock, SHUT_RDWR);
sock_release(sock);
continue;
}
/* start server worker */
queue_work(kecho_wq, work);
}
printk(MODULE_NAME ": daemon shutdown in progress...\n");
daemon.is_stopped = true;
free_work();
return 0;
}
```
:::
### echo_server_worker
要執行的 work,socket 資訊需先由 `container_of` 巨集來取得
```c
static void echo_server_worker(struct work_struct *work)
{
struct kecho *worker = container_of(work, struct kecho, kecho_work);
unsigned char *buf;
buf = kzalloc(BUF_SIZE, GFP_KERNEL);
if (!buf) {
printk(KERN_ERR MODULE_NAME ": kmalloc error....\n");
return;
}
while (!daemon.is_stopped) {
int res = get_request(worker->sock, buf, BUF_SIZE - 1);
if (res <= 0) {
if (res) {
printk(KERN_ERR MODULE_NAME ": get request error = %d\n", res);
}
break;
}
res = send_request(worker->sock, buf, res);
if (res < 0) {
printk(KERN_ERR MODULE_NAME ": send request error = %d\n", res);
break;
}
memset(buf, 0, res);
}
kernel_sock_shutdown(worker->sock, SHUT_RDWR);
kfree(buf);
}
```
## 資料來源
> [Concurrency Managed Workqueue (cmwq)](https://www.kernel.org/doc/html/v4.10/core-api/workqueue.html)
> [Linux 中的 workqueue 機制 [一]](https://zhuanlan.zhihu.com/p/91106844)
> [Linux 中的 workqueue 機制 [二]
> ](https://zhuanlan.zhihu.com/p/94561631)[講解 Linux Workqueue 原理](https://blog.csdn.net/weixin_38387929/article/details/118185914)
# alloc_workqueue 的更動
> 核心文件 Concurrency Managed Workqueue (cmwq) 提到 “The original create_*workqueue() functions are deprecated and scheduled for removal”,請參閱 Linux 核心的 git log (不要用 Google 搜尋!),揣摩 Linux 核心開發者的考量
檢視了 workqueue.h 的 commit 紀錄,找到相關 [commit](https://git.kernel.org/pub/scm/linux/kernel/git/stable/linux.git/commit/include/linux/workqueue.h?id=d320c03830b17af64e4547075003b1eeb274bc6c)
commit log
> This patch makes changes to make new workqueue features available to
its users.
> * Now that workqueue is more featureful, there should be a public
workqueue creation function which takes paramters to control them.
Rename __create_workqueue() to alloc_workqueue() and make 0
max_active mean WQ_DFL_ACTIVE. In the long run, all
create_workqueue_*() will be converted over to alloc_workqueue().
> * To further unify access interface, rename keventd_wq to system_wq
and export it.
> * Add system_long_wq and system_nrt_wq. The former is to host long
running works separately (so that flush_scheduled_work() dosen't
take so long) and the latter guarantees any queued work item is
never executed in parallel by multiple CPUs. These will be used by
future patches to update workqueue users.
本次 commit 更動的地方只有重新命名而已
從說明得知隨著 workqueue 功能越來越多,應該有個 public creation function 給一般的 user 使用。
因此重新命名為 `alloc_workqueue()` ,而不是以 __ 開頭的 `__create_workqueue` 命名。
---
# user-echo-server 運作原理
> 解釋 user-echo-server 運作原理,特別是 epoll 系統呼叫的使用
epoll 詳細原理和用法在這篇 [epoll 筆記](https://hackmd.io/@eric88525/epoll-intro)
以下為 user-echo-server 的程式碼
+ 在進入第 50 行的無限迴圈以前,準備好
+ 可供連線的 socket `listener`
+ 可監管 EPOLL_SIZE 個 fd 的 epoll 物件 `epoll_fd`
+ 用來儲存目前連線 client 的 client_list_t `cllist`
+ 在 44 行指定要觀察 `EPOLLIN` 和 `EPOLLET` 事件, `EPOLLIN` 對應的是有資料可讀取(有新的連線),`EPOLLET` 指的是希望用 edge-trigger 觸發
+ 無限迴圈重複執行 `epoll_wait` 來檢查有沒有 event 發生,事件的來源有兩種
+ 由 listener 而來,代表有新的 client 連上了 socket
+ accept 接收連線,產生 client fd
+ 透過 epoll_ctl 註冊 client fd 到 epoll 物件
+ 如果是已經建立過的連線,執行 `handle_message_from_client` 來處理
+ 如果 client 傳送的訊息長度為 0,關閉 client 並移出 cllist
+ 反之則印出 client 傳來的訊息0
```c=
int main(void)
{
static struct epoll_event events[EPOLL_SIZE];
struct sockaddr_in addr = {
.sin_family = PF_INET,
.sin_port = htons(SERVER_PORT),
.sin_addr.s_addr = htonl(INADDR_ANY),
};
socklen_t socklen = sizeof(addr);
client_list_t *list = NULL;
int listener;
if ((listener = socket(PF_INET, SOCK_STREAM, 0)) < 0)
server_err("Fail to create socket", &list);
printf("Main listener (fd=%d) was created.\n", listener);
if (setnonblock(listener) == -1)
server_err("Fail to set nonblocking", &list);
if (bind(listener, (struct sockaddr *) &addr, sizeof(addr)) < 0)
server_err("Fail to bind", &list);
printf("Listener was binded to %s\n", inet_ntoa(addr.sin_addr));
/*
* the backlog, which is "128" here, is also the default attribute of
* "/proc/sys/net/core/somaxconn" before Linux 5.4.
*
* specifying the backlog greater than "somaxconn" will be truncated
* to the maximum attribute of "somaxconn" silently. But you can also
* adjust "somaxconn" by using command:
*
* $ sudo sysctl net.core.somaxconn=<value>
*
* For details, please refer to:
*
* http://man7.org/linux/man-pages/man2/listen.2.html
*/
if (listen(listener, 128) < 0)
server_err("Fail to listen", &list);
int epoll_fd;
if ((epoll_fd = epoll_create(EPOLL_SIZE)) < 0)
server_err("Fail to create epoll", &list);
static struct epoll_event ev = {.events = EPOLLIN | EPOLLET};
ev.data.fd = listener;
if (epoll_ctl(epoll_fd, EPOLL_CTL_ADD, listener, &ev) < 0)
server_err("Fail to control epoll", &list);
printf("Listener (fd=%d) was added to epoll.\n", epoll_fd);
while (1) {
struct sockaddr_in client_addr;
int epoll_events_count;
if ((epoll_events_count = epoll_wait(epoll_fd, events, EPOLL_SIZE,
EPOLL_RUN_TIMEOUT)) < 0)
server_err("Fail to wait epoll", &list);
printf("epoll event count: %d\n", epoll_events_count);
clock_t start_time = clock();
for (int i = 0; i < epoll_events_count; i++) {
/* EPOLLIN event for listener (new client connection) */
if (events[i].data.fd == listener) {
int client;
while (
(client = accept(listener, (struct sockaddr *) &client_addr,
&socklen)) > 0) {
printf("Connection from %s:%d, socket assigned: %d\n",
inet_ntoa(client_addr.sin_addr),
ntohs(client_addr.sin_port), client);
setnonblock(client);
ev.data.fd = client;
if (epoll_ctl(epoll_fd, EPOLL_CTL_ADD, client, &ev) < 0)
server_err("Fail to control epoll", &list);
push_back_client(&list, client,
inet_ntoa(client_addr.sin_addr));
printf(
"Add new client (fd=%d) and size of client_list is "
"%d\n",
client, size_list(list));
}
if (errno != EWOULDBLOCK)
server_err("Fail to accept", &list);
} else {
/* EPOLLIN event for others (new incoming message from client)
*/
if (handle_message_from_client(events[i].data.fd, &list) < 0)
server_err("Handle message from client", &list);
}
}
printf("Statistics: %d event(s) handled at: %.6f second(s)\n",
epoll_events_count,
(double) (clock() - start_time) / CLOCKS_PER_SEC);
}
close(listener);
close(epoll_fd);
exit(0);
}
```
---
# bench 原理
> 是否理解 bench 原理,能否比較 kecho 和 user-echo-server 表現?佐以製圖
bench 程式目的: 建立 MAX_THREAD 個連線來向 server 發送訊息,並把每個連線所用的時間存在 `time_res` 陣列內,每個連線都會測試 BENCH_COUNT 次後取平均
pthread_cond_broadcast(&worker_wait);
+ 用於喚醒所有被 worker_wait block 的 thread
pthread_cond_wait(&worker_wait, &worker_lock)
+ 釋放 worker_lock,接著把 worker_wait 上鎖,並等待 worker_wait 解鎖
pthread_mutex_lock
+ mutex_lock
bench_worker 流程如下:
1. 在 bench() 主程式建立 MAX_THREAD 個 thread 來執行 bench_worker
2. 每個 thread:
1. 在第 9 行檢查有沒有準備好 MAX_THREAD 個 thread,有的話呼叫 `pthread_cond_broadcast` 來釋放 worker_wait
2. 如果沒有準備好 MAX_THREAD 個 thread,pthread_cond_wait 先釋放 worker_lock,把 worker_wait 上鎖,並且去等待其他 thread 呼叫 `pthread_cond_broadcast` 來解鎖
3. 在 19 行,由於 pthread_cond_wait 結束後又會拿回 worker_lock ,因此需要再解鎖一次
4. 連上 server ,記錄訊息傳送與接收時間,在寫入時間時用 `res_lock` 來確保寫入不受干擾
```c=
static void *bench_worker(__attribute__((unused)))
{
int sock_fd;
char dummy[MAX_MSG_LEN];
struct timeval start, end;
/* wait until all workers created */
pthread_mutex_lock(&worker_lock);
if (++n_retry == MAX_THREAD) {
pthread_cond_broadcast(&worker_wait);
} else {
while (n_retry < MAX_THREAD) {
if (pthread_cond_wait(&worker_wait, &worker_lock)) {
puts("pthread_cond_wait failed");
exit(-1);
}
}
}
pthread_mutex_unlock(&worker_lock);
/* all workers are ready, let's start bombing the server */
sock_fd = socket(AF_INET, SOCK_STREAM, 0);
if (sock_fd == -1) {
perror("socket");
exit(-1);
}
struct sockaddr_in info = {
.sin_family = PF_INET,
.sin_addr.s_addr = inet_addr(TARGET_HOST),
.sin_port = htons(TARGET_PORT),
};
if (connect(sock_fd, (struct sockaddr *) &info, sizeof(info)) == -1) {
perror("connect");
exit(-1);
}
gettimeofday(&start, NULL);
send(sock_fd, msg_dum, strlen(msg_dum), 0);
recv(sock_fd, dummy, MAX_MSG_LEN, 0);
gettimeofday(&end, NULL);
shutdown(sock_fd, SHUT_RDWR);
close(sock_fd);
if (strncmp(msg_dum, dummy, strlen(msg_dum))) {
puts("echo message validation failed");
exit(-1);
}
pthread_mutex_lock(&res_lock);
time_res[idx++] += time_diff_us(&start, &end);
pthread_mutex_unlock(&res_lock);
pthread_exit(NULL);
}
```
## user-echo-server
在移除 print 之前的測試

移除 print 後少了許多干擾,測試結果平滑了許多

## kecho
kecho 由於是在 kernel 層面,且有加入 cmwq 來加速,執行時間差異巨大

---
# drop-tcp-socket 核心模組運作原理
> 解釋 drop-tcp-socket 核心模組運作原理。TIME-WAIT sockets 又是什麼?
## TIME-WAIT 機制
以下為關閉 TCP 連線的狀態圖
| 狀態 | 動作 |
| -------- | -------- |
| FIN-WAIT-1 | 主動端呼叫 close() 終止連線,向被動端發送 `FIN` 封包並等待 `ACK` |
|CLOSE-WAIT| 被動端接收到`FIN` 後發送 `ACK` 回應,進入 CLOSE_WAIT 狀態。此時只能發送而不能接收,直到把剩下的訊息發送完才關閉連線 |
|FIN-WAIT-2|等待對方的 `FIN` 封包,此時可接收資料,不能發送資料|
|LAST-ACK|剩餘資料傳送完後向主動端發送 `FIN`|
|CLOSED| 真正關閉連線|
|TIME_WAIT|主動端接收到 LAST_ACK 發送來的 `FIN` 後,發送 `ACK` 來告知被動端可以 CLOSE。但`ACK` 不一定會成功送達,如果傳送失敗被動端會再次發送一次`FIN`,TIME_WAIT 是為了確保對方再次發送 `FIN` 時能接收的到。TIME_WAIT 等待時間為 2個 MSL (Maximum Segment Lifetime),MSL 為 TCP 所允許最大 segment 存活的時間。 |

## 需要 TIME_WAIT 的原因
從上圖可知,TIME_WAIT 只有在主動要求關閉連線的一方才會出現。
+ TIME_WAIT 機制能避免延遲的封包被同一個 socket 使用
+ 例如 Receiver 遲遲沒有收到 ACK,Receiver 仍然認為連線沒中斷,Initiator 這時就不能建立新的連線
+ 保證 receiver 能接收到最後一次 ACK
## 如果 TIME_WAIT 太多
如果 server 作為主動關閉方,當關閉多個連線後會有許多 TIME_WAIT 累積在 server 內,當 server 有最大連線數量時這些 TIME_WAIT 會**佔據一部分的連線數量**,進而影響效能。
## 查詢 TIME_WAIT 的方法
在執行 user-echo-server (port=12345) 後建立 3 個連線並關閉,輸入以下命令就能看到正在 TIME_WAIT 的 server port 和 user port
```c
$ netstat -n | grep WAIT | grep 12345
tcp 0 0 127.0.0.1:51496 127.0.0.1:12345 TIME_WAIT
tcp 0 0 127.0.0.1:51494 127.0.0.1:12345 TIME_WAIT
tcp 0 0 127.0.0.1:51498 127.0.0.1:12345 TIME_WAIT
```
## drop-tcp-socket 核心模組運作原理
module 使用方式為對 **/proc/net/drop_tcp_sock** 寫入,特別的是路徑位於 `/proc/net`
```c
// drop 單一個 TIME_WAIT
echo "127.0.0.1:51484 127.0.0.1:12345" | sudo tee /proc/net/drop_tcp_sock
// drop 多個 TIME_WAIT
$ netstat -n | grep WAIT | grep 12345 | awk '{print $4" "$5}' | sudo tee /proc/net/drop_tcp_sock
```
### network namespace
在 module 初始化 drop_tcp_init 時, 呼叫`register_pernet_subsys(&droptcp_pernet_ops)`
註冊了 **network device** 在 **network namespace** `/proc/net` 底下
> 節錄自 Linux Kernel Networking: Implementation and Theory By Rami Rosen
> p.416
> A **network namespace** is logically another copy of the network stack, with its own network devices, routing tables,neighbouring tables, netfilter tables, network sockets, network procfs entries, network sysfs entries, and other network resources. A practical feature of network namespaces is that network applications running in a given namespace (let’s say ns1) will first look for configuration files under /etc/netns/ns1, and only afterward under /etc. So, for example, if you created a namespace called ns1 and you have created /etc/netns/ns1/hosts, every userspace application that tries to access the hosts file will first access /etc/netns/ns1/hosts and only then (if the entry being looked for does not exist) will it read /etc/hosts. This feature is implemented using bind mounts and is available only for network namespaces created with the ip netns add command.
network namespace object 是由 **net structure** 定義
結構內的屬性描述了此 namespace 在哪以及名稱等相關資訊
```c
struct net {
...
/* user_ns represents the user namespace that
* created the network namespace
*/
struct user_namespace *user_ns;
/* proc_inum is the unique proc inode number
* associated to the network namespace
*/
unsigned int porc_inum;
/* proc_net represents the network namespace procfs entry
* (/proc/net) as each network namespace maintains its own
* procfs entry.
*/
struct proc_dir_entry *proc_net;
/* count is the network namespace reference counter */
atomic_t count;
...
/* gen (an instance of the net_generic
* structure, defined in include/net/netns/generic.h) is
* a set of generic pointers on structures
* describing a network namespace context
* of optional subsystems
*/
struct net_generic __rcu *gen;
};
(include/net/netspace.h)
```
如要建立的 network device 有特定的資料,則需傳入 struct pernet_operations 來初始化,此結構定義了
+ init: 初始化執行的 function
+ exit: cleanup 執行的 function
+ id: 用以識別 private data 的 id
+ size: 每個 namespace 有時會需要一些 private data,此參數為 private data 的大小
在初始化 network device 時呼叫 `proc_create_data`,在 /proc/net 下建立了名為 `drop_tcp_sock` 的 procfs 實體,指定其 file_operations (open/write/release 行為) 為 `droptcp_proc_fops` ,並傳入 network device 的 private data
```c
// 獨立 process 的名稱
#define DROPTCP_PDE_NAME "drop_tcp_sock"
struct droptcp_data {
uint32_t len;
uint32_t avail;
char data[0];
};
// network device 的私有資料
struct droptcp_pernet {
struct net *net;
struct proc_dir_entry *pde;
};
struct droptcp_inet {
char ipv6 : 1;
const char *p;
uint16_t port;
uint32_t addr[4];
};
...
static int droptcp_pernet_init(struct net *net)
{
// 指向 network device 的 private data
struct droptcp_pernet *dt = net_generic(net, droptcp_pernet_id);
dt->net = net;
// 建立 procfs 實體 (network device) 在 net->proc_net (/proc/net) 下,名為 DROPTCP_PDE_NAME
dt->pde = proc_create_data(DROPTCP_PDE_NAME, 0600, net->proc_net,
&droptcp_proc_fops, dt);
return !dt->pde;
}
static void droptcp_pernet_exit(struct net *net)
{
// 指向 network device 的 private data
struct droptcp_pernet *dt = net_generic(net, droptcp_pernet_id);
BUG_ON(!dt->pde);
// 移除 procfs 實體
remove_proc_entry(DROPTCP_PDE_NAME, net->proc_net);
}
// 建立 network device 的參數
static struct pernet_operations droptcp_pernet_ops = {
.init = droptcp_pernet_init,
.exit = droptcp_pernet_exit,
.id = &droptcp_pernet_id, // 用以識別 namespace 下的 device
.size = sizeof(struct droptcp_pernet) // 分配空間給 device 的資料
};
static int drop_tcp_init(void)
{
int res = register_pernet_subsys(&droptcp_pernet_ops);
if (res)
return res;
return 0;
}
static void drop_tcp_exit(void)
{
unregister_pernet_subsys(&droptcp_pernet_ops);
}
module_init(drop_tcp_init);
module_exit(drop_tcp_exit);
```
一個 namespace 下可有許多 device,id 可用來識別 namespace 下的特定 device
network device 的私有資料可透過 `void *net_generic(const struct net *net, unsigned int id)` 來取得,此函式回傳指向 net->gen[id] 的指標。
```c
/*
* Generic net pointers are to be used by modules to put some private
* stuff on the struct net without explicit struct net modification
*
* The rules are simple:
* 1. set pernet_operations->id. After register_pernet_device you
* will have the id of your private pointer.
* 2. set pernet_operations->size to have the code allocate and free
* a private structure pointed to from struct net.
* 3. do not change this pointer while the net is alive;
* 4. do not try to have any private reference on the net_generic object.
*
* After accomplishing all of the above, the private pointer can be
* accessed with the net_generic() call.
*/
struct net_generic {
union {
struct {
unsigned int len;
struct rcu_head rcu;
} s;
void *ptr[0];
};
};
static inline void *net_generic(const struct net *net, unsigned int id)
{
struct net_generic *ng;
void *ptr;
rcu_read_lock();
ng = rcu_dereference(net->gen);
// net->gen 儲存 namespace 下 device 的資料
ptr = ng->ptr[id];
rcu_read_unlock();
return ptr;
}
(/include/net/netns/generic.h)
```
藉由以下命令來驗證 `/proc/net/drop_tcp_sock` 存在
```shell
# before insmod
$ ls /proc/net | grep drop_tcp_sock
# after insmod
$ sudo insmod drop-tcp-socket.ko
$ ls /proc/net | grep drop_tcp_sock
drop_tcp_sock
```
### device file operation
在建立 `/proc/net/drop_tcp_sock` 實體時,有指定其 file operation 為 droptcp_proc_fops,因此在 open、write、release 時會執行指定的函式
**droptcp_proc_open**
+ 分配 PAGE_SIZE 大小的記憶體空間給 file->private_data
+ 用 avail 紀錄能實際使用多少空間
**droptcp_proc_write**
+ 從 user space 拷貝字串到 kernel space,儲存在 file->private_data->data
**droptcp_proc_release**
+ 呼叫 `droptcp_process` 來釋放 socket
+ 釋放 file->private_data 空間
```c
static int droptcp_proc_open(struct inode *inode, struct file *file)
{
// 為 device 的私有資料分配記憶體空間
struct droptcp_data *d = kzalloc(PAGE_SIZE, GFP_KERNEL);
if (!d)
return -ENOMEM;
// avail 表示有多少空間能使用
d->avail = PAGE_SIZE - (sizeof(*d) + 1);
// 指派 file->private_data 為剛剛分配的空間
file->private_data = d;
return 0;
}
static ssize_t droptcp_proc_write(struct file *file,
const char __user *buf,
size_t size,
loff_t *pos)
{
struct droptcp_data *d = file->private_data;
// 檢查 d 已經寫入的長度 (len) 加上新輸入的資料長度 (size) 是否超過 d->avail
if (d->len + size > d->avail) {
// 計算需要多少個 PAGE_SIZE 空間
size_t new_avail = d->avail + roundup(size, PAGE_SIZE);
// dnew 指向更更大的空間,其內容和 d 相同,並釋放 d 指向的舊空間
struct droptcp_data *dnew =
krealloc(d, new_avail + (sizeof(*d) + 1), GFP_KERNEL);
// 錯誤檢查
if (!dnew) {
kfree(d), file->private_data = NULL;
return -ENOMEM;
}
// 讓 d 重新指向新空間
(d = dnew)->avail = new_avail;
file->private_data = d;
}
// 拷貝使用者寫入的資料到 kernel
if (copy_from_user(d->data + d->len, buf, size))
return -EFAULT;
d->data[(d->len += size)] = 0;
return size;
}
/*
* 此時的 file->private_data 已經有了使用者寫入的字串
* 在 release 時執行 droptcp_process 來 drop 掉 socket
*/
static int droptcp_proc_release(struct inode *inode, struct file *file)
{
struct droptcp_data *d = file->private_data;
if (d) {
droptcp_process(PDE_DATA(file_inode(file)), d);
kfree(d), file->private_data = NULL;
}
return 0;
}
#ifdef HAVE_PROC_OPS
static const struct proc_ops droptcp_proc_fops = {
.proc_open = droptcp_proc_open,
.proc_write = droptcp_proc_write,
.proc_release = droptcp_proc_release,
};
#else
static const struct file_operations droptcp_proc_fops = {
.owner = THIS_MODULE,
.open = droptcp_proc_open,
.write = droptcp_proc_write,
.release = droptcp_proc_release,
};
#endif
```
## droptcp_process
負責釋放 tcp socket,由 `droptcp_proc_release` 呼叫
1. 分析 user 寫入的字串,得到 source 和 destination socket 字串
3. 呼叫 droptcp_pton 來將字串的 socket,轉換成 binary 的 socket 形式
4. 呼叫 droptcp_drop ,傳入 source 和 destination socket 資訊,釋放 server 內對應的 socket
+ 正在 time_wait 的 socket 需要用 inet_twsk_deschedule_put 來釋放
```c
struct droptcp_inet {
char ipv6 : 1;
const char *p;
uint16_t port;
uint32_t addr[4];
};
static void droptcp_drop(struct net *net,
const struct droptcp_inet *src,
const struct droptcp_inet *dst)
{
struct sock *sk;
if (!src->ipv6) {
// 找到 socket(ipv4)
sk = inet_lookup(net, &tcp_hashinfo, NULL, 0, (__be32) dst->addr[0],
htons(dst->port), (__be32) src->addr[0],
htons(src->port), 0);
if (!sk)
return;
} else {
// 找到 socket(ipv6)
sk = inet6_lookup(net, &tcp_hashinfo, NULL, 0,
(const struct in6_addr *) dst->addr, htons(dst->port),
(const struct in6_addr *) src->addr, htons(src->port),
0);
if (!sk)
return;
}
printk("Drop socket:%p (%s -> %s) state %d\n", sk, src->p, dst->p,
sk->sk_state);
if (sk->sk_state == TCP_TIME_WAIT) {
/* This is for handling early-kills of TIME_WAIT sockets.
* Warning : consume reference.
* Caller should not access tw anymore.
*/
inet_twsk_deschedule_put(inet_twsk(sk));
} else {
// 把 tcp 連線設為 close
tcp_done(sk);
/* Ungrab socket and destroy it, if it was the last reference. */
sock_put(sk);
}
}
static int droptcp_pton(struct droptcp_inet *in)
{
char *p, *end;
// 將字串格式的 ipv4 位址轉換到 binary representation,儲存在 in->addr
if (in4_pton(in->p, -1, (void *) in->addr, -1, (const char **) &end)) {
in->ipv6 = 0;
// 將字串格式的 ipv6 位址轉換到 binary representation,儲存在 in->addr
} else if (in6_pton(in->p, -1, (void *) in->addr, -1,
(const char **) &end)) {
in->ipv6 = 1;
} else
return -EINVAL;
p = (end += 1);
while (*p && isdigit(*p))
p++;
*p = 0;
// 將 string 轉成 unsigned long 寫入 n->port ,成功則 return 0
return kstrtou16(end, 10, &in->port);
}
static void droptcp_process(struct droptcp_pernet *dt, struct droptcp_data *d)
{
// 取得 user 寫入的字串
char *p = d->data;
// 儲存 source 端和 destination 的 socket 資訊
struct droptcp_inet src, dst;
while (*p && p < d->data + d->len) {
// 略過開頭的空白
while (*p && isspace(*p))
p++;
if (!*p) /* skip spaces */
return;
// 儲存 source 端 ip
src.p = p;
while (*p && !isspace(*p))
p++;
if (!*p) /* skip non-spaces */
return;
while (*p && isspace(*p))
p++;
if (!*p) /* skip spaces */
return;
// 儲存 destination 端 ip
dst.p = p;
while (*p && !isspace(*p))
p++;
if (!*p) /* skip non-spaces */
return;
// 把字串格式的位址 binary 形式,如轉換失敗或是通訊協定不同則退出
if ((droptcp_pton(&src) || droptcp_pton(&dst)) ||
(src.ipv6 != dst.ipv6))
break;
// 執行 drop
droptcp_drop(dt->net, &src, &dst), p++;
}
}
```
參考資料
> [TIME_WAIT and its design implications for protocols and scalable client server systems](http://www.serverframework.com/asynchronousevents/2011/01/time-wait-and-its-design-implications-for-protocols-and-scalable-servers.html)
> [Linux Kernel Networking Implementation and Theory](https://link.springer.com/book/10.1007/978-1-4302-6197-1)