# Deep Clustering
###### tags: `nicholas` `clustering`
## Unsupervised learning
I want to use unsupervised learning to try to understand what is going on inside neural networks. In particular I mean mapping activation patterns (which exist in some weird incomprehensible space) to a space with human understandable structure.
:heavy_check_mark: Avoids ELK-style Goodhearting by a powerful reporter (this is why we use linear probes which are intentionally weak)
:heavy_check_mark: Extracts features without relying on us to provide them (we may find things we weren't expecting to find)
:heavy_check_mark: Helps protect us from confirmation bias
:x: Methods are brittle to assumptions about the structure of the data
:x: A failure to find features doesn't prove they aren't there
### Examples:
- Principle Component Analysis (PCA)
- Autoencoders
- K-means clustering
- [Expectation Maximization](https://en.wikipedia.org/wiki/Expectation%E2%80%93maximization_algorithm) (GMM)
- Hierarchical clusterign
## What is Deep Clustering?
[Original paper](https://openaccess.thecvf.com/content_ECCV_2018/papers/Mathilde_Caron_Deep_Clustering_for_ECCV_2018_paper.pdf) by Facebook AI Research
### Method:
Iteratively repeat the following:
1. Pass input data through a NN and produce feature vectors
2. Cluster the feature vectors and generate "pseudo labels" for each data point
3. Train the NN to predict the pseudo labels

### Main Findings
1. Their network, despite receiving no human generated labels, found human interpretable features. (This is evidence in favor of the Natural Abstraction Hypothesis):

2. The features found by Deep Clustering could be used by supervised learning algorithms (transfer learning), and were better than the features found by other supervised learning algorithms.
### Intuition for why this works
From the original paper:
> a multilayerperceptron classifier on top of the last convolutional layer of a random AlexNet achieves 12% in accuracy on ImageNet while the chance is at 0.1% [(source)](https://arxiv.org/pdf/1603.09246.pdf)
This means that the output from the last convolution of the random AlexNet still preserves a significant amount of structure, which K-means can exploit to produce clusters which are not entirely random. The clusters are still mostly random, but the little bit of structure can be bootstrapped to provide a training signal which leads to features which can be used to more cleanly separate the data into distinct categories.
In theory, there are arbitrarily many sets of features which allow us to cleanly separate the data. The network, however, has implicit prior over the kinds of features it learns, and it seems that this prior can lead to human interpretable features.
The reason this works, in my opinion, is that the Natural Abstraction Hypothesis is true.
## Interpretability
The problem with applying unsupervised methods to activation patterns in a NN is that it's a really high dimensional space, and we don't really know what structure data within that space will have. Applying brittle methods which make incorrect assumptions about that structure will likely be suboptimal. For example, K-means is notorious for failing to model irregular datasets:
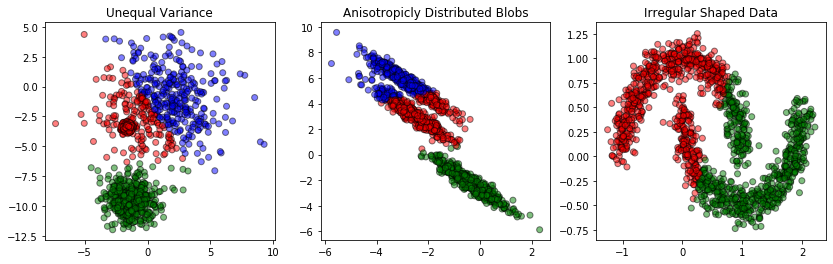
[(Image source)](https://zerowithdot.com/mistakes-with-k-means-clustering/)
Each unsupervised method must make some assumptions, or have some prior, over the kind of structure it is meant to extract. Different methods make different assumptions, and it takes a lot of experience and practice to know which method to apply in which situation.
The advantage of Deep Clustering is that we can **use a NN's own simplicity prior**, instead of a prior handcrafted by humans, to try to extract features from an activaiton pattern. An activation pattern is a type of data produced by one part of a NN with the purpose of being useful to another part of a NN. It seems natural to expect that the simplicity prior of the NN we intend to study may be very similar to the simplicity prior of a NN we intend to use as an unsupervised reporter.
More broadly, I'd like to explore any and all unsupervised methods (not just Deep Clustering) which use the simplicity prior of a NN rather than handcrafted assumptions, and use them to produce powerful unsupervised reporters which are immune to Goodhearting.
## Other methods
### Local Aggregation
This method is similar to Deep Clustering, but claims to be more flexible and efficient. (I don't 100% understand how it works yet, here is their [paper](https://openaccess.thecvf.com/content_ICCV_2019/papers/Zhuang_Local_Aggregation_for_Unsupervised_Learning_of_Visual_Embeddings_ICCV_2019_paper.pdf) and [code](https://github.com/neuroailab/LocalAggregation).)

They also find that they can use the features as a pretraining step for supervised learning tasks, and claim to outperform Deep Clustering. They also find that they can use the features generated to do KNN classification.