[toc]
# Aztec Network Operational Resilience
The Aztec network is an L2 network using a zero-knowledge Rollup (zkRollup) to the Ethereum network as its L1. Aztec Network's speciality lies in being able to roll up both public and private transactions. This analysis will look at the operational resilience of the Aztec network in the context of three particular outcomes:
- Soft finality of the Aztec network
- Disaster recovery of the Aztec network
- Sensitivity of the Aztec network to block reorganization
Where applicable, potential effects of the two sequencer decentralization proposals on these aspects of operational resilience will be compared and contrasted, Fernet ([Aztec, 2023a](https://hackmd.io/0FwyoEjKSUiHQsmowXnJPw)) and B52 ([Aztec, 2023b](https://hackmd.io/VIeqkDnMScG1B-DIVIyPLg)).
## Soft finality of the Aztec network
Aztec's reliance on an L1 to secure it's network needs to be reflected in:
- *Aztec protocol should measure time in L1 block time.*
The duration of phase intervals should be specified in numbers of L1 blocks. Doing so provides pacing for Aztec that naturally accounts for stress on the L1 network. In several instances, times are given in seconds. Best case, these representations of world time are only informal, i.e. non-normative. Worst case, representations of world time become part of the sequencing protocol.
- *Aztec protocol should maintain a minimum L1 block separation between its blocks.*
Aztec should maintain a notion of a "safe block height" for its L1 chain. Aztec rollups should be spaced at least the safe block height apart. Under optimal conditions, the Ethereum blockchain's second latest epoch is finalized by the Casper FFG protocol with the finalized checkpoint block moving forward approximately every 6 minutes and maintaining a minimum finalized block height for the chain of between 64 and 96 blocks.
- *Aztec protocol should operate synchronously to its L1.*
Aztec should limit the number of work-in-progress (WIP) blocks to one. Work on a new block should start only after all information necessary to select the winning proposal and finalize it (on the L1) is incorporated into the L1 blockchain at a minimum block height of the safe block height. The reason for this precaution is that the Aztec protocol does not maintain logs in a decentralized, secure way, that could be used to recreate its network state following a corrupting event such as an L1 block reorganization. Therefore, Aztec is reliant on its L1 to secure finalized transaction order once Aztec begins work on a new block. Without developing a decentralized means of storing protocol logs, raising the WIP limit to more than one means that Aztec must accept the use of a centralized log systems for disaster recovery. While this would still be an improvement over reliance on centralized sequencing, it is suboptimal with regards to the goal of decentralization of the protocol.
> [name=David Sisson]TODO:
> - Define hard and soft Aztec finality based on the above.
> - Write a lead-in paragraph to disaster recovery topic.
### Effect of Sequencer Decentralization on Soft Finality
## Disaster Recovery of the Aztec network
The effect of network failure on data processing systems and how to build systems that are resilient in the face of such failures is well studied. Eric Brewer proposed the CAP Theorem in 1998 ([Brewer, 1998](https://web.archive.org/web/20080625005132/http://www.ccs.neu.edu/groups/IEEE/ind-acad/brewer/index.htm)), which poses a trilemma among Consistency, Availability and network partition tolerance in any shared data system. Given that network partition is always a risk, a data system distributed across a network must choose between maintaining availability or maintaining consistency. In 2011, Nathan Marz proposed Lambda Architecture as a "way to beat" the CAP theorem ([Martz, 2011](http://nathanmarz.com/blog/how-to-beat-the-cap-theorem.html)), which uses parallel stream and batch processing subsystems to achieve real-time availability from the streaming subsystem and eventual consistency from the batch subsystem. While Lambda doesn't really beat CAP, it does place its consideration at a good spot architecturally --- namely at the platform level rather than the application level. Three years later, Jay Kreps described the kappa architecture that had many of the properties of lambda architecture with regards to the CAP Theorem, but was a pure streaming solution alleviating the need for the complexities of running parallel streaming and batch subsystems ([Kreps, 2014](http://radar.oreilly.com/2014/07/questioning-the-lambda-architecture.html)).
The common thread running through these architectures is the presence of an immutable copy of logs that enable distributed data reprocessing to recover from failures. By definition, Aztec's L1 - the Ethereum network - contains such an immutable copy of Aztec's logs as recently as the last finalized epoch. That leaves the intervals between the last finalized epoch and the current safe block and between the current safe block and the current head block as gaps in immutable log storage.
### Effect of Sequencer Decentralization on Disaster Recovery
## Sensitivity of the Aztec Network to Reorganization
Relying on the Ethereum copy of Aztec logs between the last finalized epoch and the current safe block may be considered a reasonable risk. If this is not the case, then secondary log storage will be required. Such storage could be provided through a centralized mechanism, such as a private data store probably hosted in a similar way to Aztec's current hosting of centralized sequencing. Alternatively, short-lived distributed ledgers could be used to store these logs. A new distributed ledger could be triggered by Casper FFG finalization, with the newly finalized Ethereum checkpoint providing the basis for its genesis block.
Additionally, this redundant store of logs not yet included in finalized blocks provides a means to detect reorganizations in this theoretically vulnerable part of the Ethereum blockchain. Being able to detect reorganizations is a necessary precursor to developing a recovery mechanism. Such a mechanism could be investigated further if it is of interest.
### Effect of Sequencer Decentralization on Reorganization Sensitivity
## Vulnerability of the Aztec Network to Denial of Service Attacks
An actor can exercise its affordances to clog or otherwise prevent other actors from using the system. This topic is deprecated from consideration with regard to operational resilience of the Aztec network. If a denial of service attack results in a chain halt, then the means of recovery has already been discussed in the disaster recovery topic. In addition, the existence of an ability to recover from disaster also opens up the tactic of halting and restarting the network to potentially defend against a denial of service attack. This tactic could be investigated further if it is of interest.
### Effect of Sequencer Decentralization on Denial of Service Vulnerability
No relevance seen at this time.
# References and Notes
[Reasonably Likely Ethereum Attack Vulnerabilities](https://ethereum.org/en/developers/docs/consensus-mechanisms/pos/attack-and-defense/)
> ...all small-stake attacks are subtle variations on two types of validator misbehavior: under-activity (failing to attest/propose or doing so late) or over-activity (proposing/attesting too many times in a slot). In their most vanilla forms these actions are easily handled by the fork-choice algorithm and incentive layer
> [name=David Sisson] TODO: Soften recommendations to Aztec based on 2023-08-22 call:
> - Use Ethereum block-time as Aztec real-time
> - Create a policy that defines Ethereum Safe Block in the context of Aztec.
> - Create a policy that sets roll-up maximum work-in-progress (WIP)
> -
# Appendix 1: Finality in Gasper --- Ethereum's Proof of Stake Consensus Protocol
Finality in a blockchain refers to the block height at which an actor using the blockchain can be confident that a given order of blocks will not change. In transitioning from Proof of Work (PoW) to Proof of Stake (PoS), the Ethereum Network changed how the network reaches consensus on adding blocks to the canonical chain. In doing so, Ethereum also changed how finality is reached.
Under PoW, miners use the computing power of their node to compete to produce the next block in the chain competing blocks represent forks in the canonical chain. Difficulty of the PoW task is adjusted so that on average a miner would mine a block about every 15 seconds. When the Ethereum network operated under PoW, it reached consensus on which fork would be the canonical blockchain by using Nakamoto consensus, which is a longest chain model, as its fork choice rule ([Wood, 2022](https://ethereum.github.io/yellowpaper/paper.pdf)).
The specifics of Ethereum's PoS protocol are quite complicated. Reasonably accessible explanatory posts can be found at the following links:
- https://ethos.dev/beacon-chain
- https://www.youtube.com/watch?v=5gfNUVmX3Es
The key elements with regard to this analysis follow. With PoS, a validator must stake 32 ETH to participate in the creation of new blocks. One validator is randomly selected to propose a new block for a 12 second slot. Other validators are chosen to attest to (vote for) the proposals. The Ethereum network reaches consensus on its canonical blockchain based on block proposals and attestations using the Gasper protocol. Gasper combines two consensus operations. One, Latest Message-Driven Greedy Heaviest Observed SubTree (LMD GHOST), is a fork choice rule that is a variant of the longest chain model ([Buterin, etal., 2020](https://arxiv.org/pdf/2003.03052.pdf)). The other, Casper the Friendly Finality Gadget (Casper-FFG), is a practical Byzantine Fault Tolerant (pBFT) model ([Buterin & Griffith, 2019](https://arxiv.org/pdf/1710.09437.pdf); [Castro & Liskov, 1999](https://pmg.csail.mit.edu/papers/osdi99.pdf)). Being a longest chain model, LMD GHOST provides probabilistic finality similar to PoW's Nakamoto consensus. Casper-FFG operates in concert with LMD GHOST to provide absolute finality at boundaries between 32 slot epics. (See [Gauba, 2018](https://medium.com/mechanism-labs/finality-in-blockchain-consensus-d1f83c120a9a) for a discussion of probablistic and absolute finality.)
In longest chain models, finality is defined probabilistically. In the case of Nakamoto consensus, the more blocks between a given block and the head block, the more work is required to affect a reorganization, and therefore, the lower the probability of a reorg. Under PoS, finality is defined economically. The more blocks between a given block and the head block, the more staked ether (ETH) is at risk to slashing to affect a reorganization.
The following figure illustrates what Gasper's happy-path consensus looks like. Be aware that there is no guarantee that there will be a block proposed for every slot, or that at the start of each epoch the prior checkpoint will be justified.

## Definitions of Terms
### Head Block
The head block is the block most recently added to the chain. In any decentralized consensus protocol, consistency is eventual. So, the head block is never known with certainty. On Ethereum, the head node is identified by LMD GHOST attestations by pre-selected committees of validators assigned to each slot. The attestation committee of a slot cannot include the block proposer of that slot. Each attestation is a vote for a block to fill a slot paired with the parent of that block in the view of the attestor. The clocked nature of provides 12 seconds for consensus to be reached. However, unpredictable conditions can render this time insufficient --- such as validator unresponsiveness, network transmission delays, and the presence of "bad validators" ([Parkes, 2012](http://arxiv.org/abs/2102.02247)).
### Justified Block
The first block in an epoch is called a checkpoint block. It is also known as the Epoch Boundary Block (EBB). This analysis will use the former term. Under optimal network conditions, the checkpoint block fills Slot 0. Checkpoint blocks anchor the canonical chain through Caper FFG attestations. All validators qualify to make Casper FFG attestations. Each attestation is a vote for the checkpoint block of the current epoch paired with the prior checkpoint block in the view of the each validator. The current checkpoint block is referred to as the target; the prior check point block is referred to as the source. If a checkpoint pair receives a stake weighted sum of these attestations that account for $\frac{2}{3}$^rds^ of the total amount of ETH staked by active validators, then Casper FFG marks the source checkpoint block justified.
### Finalized Block
When the checkpoint blocks of two consecutive epochs fulfill the criteria of being marked justified, Casper FFG marks the earlier checkpoint of the pair finalized.
### Inactivity Leak Condition
In order to constrain finality failure, post merge Ethereum adds a third consensus rule, the inactivity leak ([Edgington, 2023, Sect. 2.8.6](https://eth2book.info/capella/part2/incentives/inactivity/)). The inactivity leak condition is triggered if Casper FFG cannot finalize a new checkpoint in four consecutive epochs.
### Safe Block
While Gasper cannot provide head block finality, one can define a block that will not revert under a set of reasonable assumptions ([Asgaonkar, 2023](https://www.adiasg.me/confirmation-rule-for-ethereum/)). Such a block is generally referred to as a safe block. Under normal mainnet conditions, Asgaonkar and collaborators. estimate that as safe block can be confirmed within one minute, or at a block height of 5.
The reasonable assumptions of normal mainnet conditions listed by Asgaonkar and collaborators are:
> - The votes cast by honest validators in any particular slot are received by all validators by the end of that slot, i.e., the network is synchronous with latency < 8 seconds.
> - The adversary controls less than $\frac{1}{3}$^rd^ of the network, i.e., adversarial fraction $\beta \leq \frac{1}{3}$.
# Appendix 2: [Shared State model of Kappa architecture](https://nexocode.com/blog/posts/data-stream-processing-challenges/)
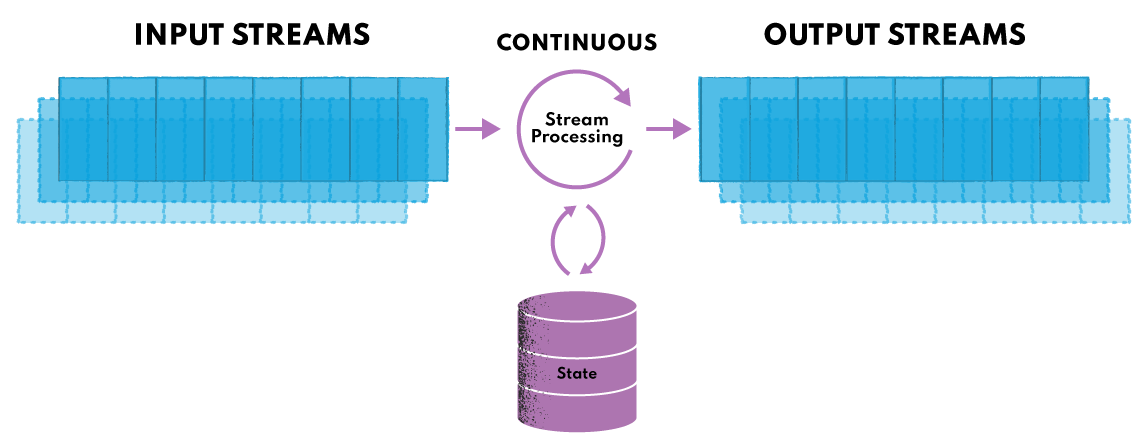
Complex system architecture requires Monitoring and Management tooling.
Fault tolerance through replication and logging
Managing delays (Producer performance degradation):
- Watermarking --- timestamp indicating the delay after which the item will be dropped
- Buffering --- store items that can't be processed without a delayed item
- Windowing --- essentially a fixed length buffer
Managing backpressure (Consumer performance degradation):
- Buffering producer output
- Adaptive consumer scaling
- Stream partitioning
- Drop incoming data items
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet