---
title: Synthetic Data for Text Localisation in Natural Images
tags: 論文共筆
---
# Synthetic Data for Text Localisation in Natural Images
`Ankush Gupta et al. 2016 CVPR`
## 時空背景
Text Spotting: 電腦視覺中,處理在自然場景中閱讀文字問題
Intro 提到此時的 SOTA 是 [這篇](https://hackmd.io/s_gEOu6XR8qUks-sabb9WQ) (同一個Group自己講的, 自行判斷~)
:::success
SOTA 的問題
:::
**正確切割成為辨識正確率的瓶頸**
正確切割的文字圖片的 **Accuracy** 達到98%, 但 end2end 的 **F-measure** 只有69%, 主因是有許多錯誤切割的區域, 會造成辨識上困難
參見附圖 🤣
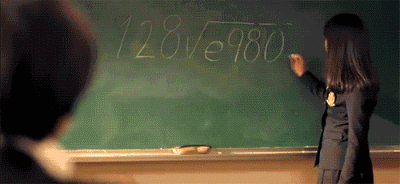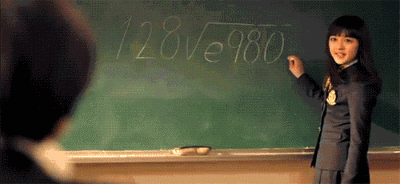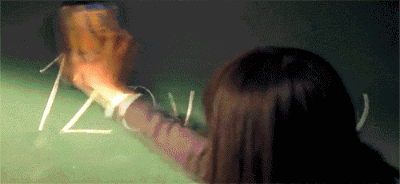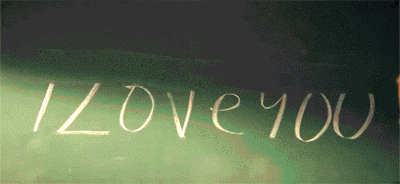
**速度太慢**
因為用了很多傳統方法加上 [R-CNN](https://arxiv.org/abs/1311.2524) ,(光是看到用第一版本的 R-CNN大概就知道在普通等級的硬體上絕對不會是即時偵測XD, 不過畢竟其有時空背景上的限制)
:::success
本篇貢獻
:::
**Generating Engine**
其實 [前一篇](https://hackmd.io/s_gEOu6XR8qUks-sabb9WQ) 就有提到用合成的方式做數據,但並不自然, 這一篇特別介紹生成引擎並提供 [github](https://github.com/ankush-me/SynthText) ,用現成的**深度學習**與**切割**方法來對齊文字, 讓文字自然的融入自然場景照片中
**Fully-convolutional regression network(FCRN)**
此時 ,物件偵測的時空背景是 [Yolov1](https://arxiv.org/abs/1506.02640) 出一年左右, [SSD](https://arxiv.org/abs/1512.02325) 剛出不到半年, [Yolov2](https://arxiv.org/abs/1612.08242)未出。
另外, `E Shelhamer` 的 [FCN](https://arxiv.org/abs/1605.06211) 已出
作者使用了一個類似全卷積的 YOLO 架構,加上convolutional regressor, 做出文字框與文字的預測。
## 方法
:::success
Generating Engine
:::
**文字與圖像的來源**
第一步當然是要先取出要合成的 **Text** 跟 **Image**
Text 的來源是 [Newsgroups20 datasets](https://blog.csdn.net/imstudying/article/details/77876159), 這裡取三種 1.Words 2.Lines (up to 3 lines) 3.Paragraphs (up to 7 lines)。(這個數據集內有英文,符號,數字,標點)
Image 的來源則是 [Google Image Search](https://images.google.com/), 這裡取了 objects/scenes, indoors/outdoors, natural/artificial, 共八千張圖。 特別需要注意的是,為了標注嚴謹, 圖片上不能本來就有其他字樣(例如路標),所以在搜尋時就不會用 "street-sign" , "menu" 這類關鍵字, 為求嚴謹,還有再經過人工檢查,刪去本來就有字樣的圖片。
**如下圖就是標注不嚴謹的例子**
([SVT dataset](http://www.iapr-tc11.org/mediawiki/index.php/The_Street_View_Text_Dataset))

可以看到內有許多文字沒被標注出來
**Segmentation**
再來就進入怎麼對齊文字的方法論了
首先是切割, 基於一個假設: 文字必然是出現在某個特殊區塊內(特別的紋理和顏色), 於是用了 [gPb-UCM contour hieranchies](https://www2.eecs.berkeley.edu/Research/Projects/CS/vision/grouping/papers/amfm_pami2010.pdf), [efficient graph-cut inplementation](https://www2.eecs.berkeley.edu/Research/Projects/CS/vision/grouping/papers/apbmm_cvpr2014.pdf) 來決定區域
**如下圖,左邊有區域限制,右邊沒限制**

**Geometry Estimation**
決定區域之後,再來就是要根據幾何構造將文字貼上去
通常文字會在區域的表面,為了估計出類似效果,會根據**估計**出來的**局部區域法線**來將文字投影上去 (perspectively transformed)
1. **法線估計**是用一個 CNN 先對上述切出來的 RGB 圖像區域做深度估計, 用法線來產生一個 fronto-parallel region
2. 接著創造一個平面 (planar facets) 用 [RANSAC](https://zh.wikipedia.org/zh-tw/%E9%9A%A8%E6%A9%9F%E6%8A%BD%E6%A8%A3%E4%B8%80%E8%87%B4) 來擬合這個 fronto-parallel region
3. 最後,將文字對齊長邊(平面的寬)
4. 當然,還要刪掉文本重疊的部份,如果多文本要疊在重複的區域,要刪除。
被決定的區域如果有以下情形還是會被刪掉
1.太小
2.極端的長寬比
3.法線與視角垂直
4.紋理太多(紋理強度用RGB影像的三階導數算)
:::success
Fully-Convolution Regression Network
:::
$x\,代表一張圖作為輸入$
$($c$,p)\,為輸出,$c代表信心值,pose$\,p=(x-u,\,y-v,\,w,\,h)$
$u,v\,代表特徵圖上一格的中心點$
因為原圖共經過四次 downsampling, 一格Feature channel$\;\phi_{uv}^f$代表 $4\times 4$個 pixels
接著對每格$\;\phi_{uv}^f\,$再經過$\,7\times 5\times 5\,$的卷積核做出7個值的預測 pose$\,p=(x-u,\,y-v,\,w,\,h,\,\cos\theta,\,\sin\theta)$
```graphviz
digraph structs {
node[shape=Mrecord]
K[label="{FCRN \n(Input 224 x 224 x 3 )|{kernel|Output}|{CR 64 x 5 x 5|224 x 224 x 64}|{MP 2x2 |112 x 112 x64}|{CR 128 x 5 x 5|112 x 112 x 128}|{MP 2x2|56 x 56 x 128}|{CR 128 x 3 x 3|56 x 56 x 128}|{CR 128 x 3 x 3|56 x 56 x 128}|{MP 2x2|28 x 28 x 128}|{CR 256 x 3 x 3|28 x 28 x 256}|{CR 256 x 3 x 3|28 x 28 x 256}|{MP 2x2|14 x 14 x 256}|{CR 512 x 3 x 3|14 x 14 x 512}|{CR 512 x 3 x 3|14 x 14 x 512}|{CR 512 x 5 x 5|14 x 14 x 512}}"]
}
```
$CR: Convolution Filters + ReLu$ (卷積都有經過 Zero padding)
$MP: MaxPooling$
```graphviz
digraph structs {
rankdir=LR
node[shape=Mrecord]
struct1 [label=" { Feature maps}|{14 x 14 x 512}"];
struct2 [label=" { 1 個卷積核 }|{5 x 5 x 512}|{s1 p1}"];
struct3 [label=" { 6 個卷積核 }|{<f0>5 x 5 x 512}|{s1 p1}"];
struct4 [label=" { box 的座標 }|{<f0>6 x 14 x 14 }"];
struct5 [label=" { box 的信心值 }|{<f0>1 x 14 x 14 }"];
struct1-> struct2:f1->struct5:f [arrowhead = vee]
struct1:f -> struct3:<f0> ->struct4:f [arrowhead = vee]
}
```
## 參考
[Reading text in the wild with convolutional neural networks](https://arxiv.org/abs/1412.1842)
[Synthetic Data for Text Localisation in Natural Images
Supplementary Material](http://www.robots.ox.ac.uk/~vgg/data/scenetext/gupta16_supplement.pdf)
[CSDN](https://blog.csdn.net/u010167269/article/details/52389676)
[SynthText dataset](https://www.robots.ox.ac.uk/~vgg/data/scenetext/)
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet