# AIPC Newcomer's Guide (WIP)
總之就是關於組裝 AI 入門電腦的建議。
> 組裝電腦一定有風險,顯卡投資有賺有賠,申購前應詳閱公開說明書
## Glossary
ISA: Instruction Set Architecture
SD: Stable Diffusion
SDXL: Stable Diffusion XL
LLM: Large Language Model
VRAM: GPU 的 RAM
## OS 考量
通常使用 Ubuntu 是問題最少的(通常,不一定如此),根據喜好使用 Debian 或 Arch Linux 也沒什麼問題,只要能從套件庫安裝目標顯卡的驅動都可以用。反正現代大多數 ML 相關東西都跑在 Python venv 或 conda 裡面,並不會用到系統安裝的 Runtime。
> 用什麼都好,但最好別用 Windows,你也不想訓練到一半強制重開機自動更新對吧?
## 硬體考量
### CPU & RAM:
由於大多數時候實際計算都在 GPU 上面進行,CPU 效能不是非常重要,但 PCI-E Lane 以及 RAM 要能擴充到夠用,建議單核心效能至少要比 AMD Ryzen 5 2400G 快(約 2000 Passmark 分)。單核心效能很多狀況下比多核心效能更重要,因為大多數 Python 寫的東西都在主執行緒 poll GPU,如果單核心效能不足,會沒辦法用滿 GPU。
如果是跑 LLM 遇到 GPU VRAM 不夠,只能 offload 部分 model layer 的時候,就會需要多核心效能夠快且 RAM 通道數量夠多的 CPU,最經濟的選擇通常就是 E5-2697Av4 + X99 平臺以及 4 通道 DDR4。
SD1.5 至少需要 16GiB 左右 RAM 才夠用,SDXL 則是 32GiB 左右。
跑 LLM 最好都要有 32GiB 以上的 RAM(至少要能完整塞下目標 LLM 模型)。
### GPU:
首先因為計算時可能會有 thrashing 的狀況,建議最好要有額外的亮機卡或使用 CPU 內顯輸出,這樣計算時不影響系統 GUI 順暢度。此外也能避免 GUI 佔用 VRAM 導致不穩定。
在一臺主機裏面裝兩張或以上的顯卡時,普通軸向風扇的顯卡散熱很容易有嚴重瓶頸,尤其是三卡槽厚度顯卡下方有另外一張顯卡的情況,很容易讓進風量不足,顯卡過熱。因此如果一開始就能預見未來可能擴充更多顯卡,可以考慮渦輪(離心扇)卡。即使這些渦輪卡本身散熱並不怎麼好而且吵,它們全功率運作時也比較不容易互相影響,可以在高密度環境下保證所有卡都能正常散熱。(補充教材: [CaptiveAire: Fan Fundamentals - From The Wright Brothers To Today (YouTube, 48:24)](https://www.youtube.com/watch?v=vF72pOHc1zY))
由於 NVIDIA 擁有 Tensor Core 的消費級 GPU 只有 RTX20 / 30 / 40 系或以後的 GPU,而且 NVIDIA 給 VRAM 跟我掏錢時一樣摳門,因此大 VRAM 的卡都不怎麼便宜。16GiB VRAM 以上最便宜的選擇只有沒 Tensor Core 的 Tesla P40 與 P100。如果要有 Tensor Core,最便宜的選擇會變成 RTX4060Ti 16G。要是把標準放低一點,12G 也有 RTX3060 12G 可以選,不過礦卡多,而且效能普通。
針對 LLM 時,如果不在乎單次執行的速度受影響,可以把 model 分散在不同張卡上面,有時候這樣組建成本比較低一點。
> 要是 VRAM 也能像普通 DIMM 一樣擴充就好了
另外,各種 GPU 規格都可以上 [TechPowerUp GPU Database](https://www.techpowerup.com/gpu-specs/) 查詢
#### NVIDIA:
年代、架構名稱與產品名稱對照表(僅列出 CUDA 12.x 支援 GPU 系列)
| 年代 | 架構名稱 | CUDA | 消費級產品名稱 | 工作站級產品名稱 | 伺服器級產品名稱 |
|:----- | ------------ | ----:|:------------------------------------ |:------------------------------ |:------------------------------- |
| 2014 | Maxwell | 5.x | GTX900 系列 (如 GTX980) | Quadro M 系列 | Tesla M 系列 (如 M40) |
| 2016 | Pascal | 6.x | GTX1000 系列 (如 GTX1080Ti, GTX1660) | Quadro P 系列 | Tesla P 系列 (如 P4, P40, P100) |
| 2018 | Volta | 7.0 | Titan V | Quardo GV100 | Tesla V 系列(如 V100) |
| 2018 | Turing | 7.x | RTX20 系 (如 RTX2080Ti, Titan RTX) | Quadro RTX 系列 (如 RTX 6000) | T 系列 (如 T4, T40) |
| 2020 | Ampere | 8.6 | RTX30 系列 (如 RTX3090) | RTX A 系列 (如 RTX A4000) | A 系列 (如 A2, A10, A100) |
| 2022 | Ada Lovelace | 8.9 | RTX40 系列 (如 RTX4090) | RTX Ada 系列 (如 RTX 6000 Ada) | Ada 系列 (如 L4, L40) |
| 2024 | Hopper | 9.0 | 無 | 無 | Hopper 系列 (如 H100) |
| 2024+ | Blackwell | 12.0 | RTX50 系列(如 RTX5090) | RTX Pro Blackwell | Blackwell 系列 (如 B200) |
* Volta 以及它以後的架構都有 Tensor Core,除了 GTX1600 系列是 Turing 但閹割掉 Tensor Core
* 從 Turing 開始,GPU 內多了一個 GSP core,Linux 上的 nvidia-open 驅動只支援有 GSP 的顯卡
* 現在幾乎沒有任何理由購入 Maxwell 時代的 GPU
* Ampere 以及它以後的架構才有 BF16 格式可以用,Ada 開始才有原生 FP8
* Ada Lovelace 這代的能耗比強很多,4070 和 3080 的效能差不多,但功耗只有 2/3,如果功耗是個考量而且不缺錢,可以考慮
#### AMD:
AMD 的部分文檔不清不楚,但基本上 RX6000 系列以後的卡都還有 ROCm 支援。不過 AMD 卡要到的 RX7000 系列 (RDNA3) 才開始擁有類似 Tensor Core 的 WMMA (Wave Matrix Multiply Accumulate) 功能,因此 RX6000 與 RX5000 的 PyTorch 效能都很糟糕。AMD 的單位 VRAM 雖然不像 NVIDIA 那樣貴,但 AMD ROCm 部分情境的 VRAM 使用效率很差,因此 VRAM 部分的表現並沒有比較好。
#### VRAM,很多 VRAM,更多 VRAM,最好是超大 VRAM!!
許多大型模型(如 SD, SDXL, LLaMA 7B,或是 Mixtral 8x7B)都需要很大量的 RAM,其中各種大語言模型 (LLM) 最需要大量 VRAM,現在能用 8GiB 左右的 VRAM 跑 7B 參數量的 LLM 其實是因為進行了量化,其中最流行的是 4bit 量化,需要的 VRAM 只要 FP16 的 ¼,但如果需要針對模型進行微調(Fine-tune)或訓練時,需要的 VRAM 會比推理時高很多,因此 VRAM 絕對是越大越好,但是 GPU VRAM 不像 CPU 這邊的 RAM 可以自己擴充,因此需要花更多心力去挑選 GPU 型號。
> 大 VRAM、高效能、低價格,你只能三選二
### 主機板:
能有兩個或以上的 PCI-E x16 插槽最好,或者如果支援 PCI-E x16 拆分成 x4+x4+x4+x4 搞多卡也會很有幫助。GPU 計算通常不像普通玩遊戲時那樣需要 PCI-E 頻寬,很多時候 PCI-E 3.0 x4 就夠用了(但是載入模型或交換資料時會比較慢),狀況允許時 PCI-E x16 會是最好的。
但是跑 LLM 只有部分 layer 在 GPU 中的時候很需要 PCI-E 頻寬,所以有 LLM 需求的話最好還是 x16。
### 電源:
不要想說買大瓦數用不到,看新硬體手癢買下去之後一定會用到的,最好一開始直接上 850W ~ 1000W,才不會因為電源不夠力,又買一顆新的。
> 雙卡?三卡!整機滿載功耗直上 1500W!
### 儲存:
如果能弄出超大容量的 NVMe 當然最好,不過因為大多數模型載入/儲存都是順序存取,使用 HDD 除了慢一點沒什麼問題。而且只會讀取,不會寫入。如果真的有需要儲存非常多模型,使用 SMR HDD 也是合理的。
## 各家 GPU Compute Stack 現況
### NVIDIA CUDA:
目前的行業標準,各大 ML 框架只要能用 GPU 大概都用它。
在 Stable Diffusion 中由於 xformers 函式庫只支援它,因此又快又省 VRAM。但是就算沒開 xformers,CUDA 的 VRAM 使用量仍舊比 ROCm HIP 低。
> Absolutely Proprietary
### AMD ROCm HIP:
AMD 模仿 CUDA API 設計出來的玩意,在消費級設備上介於能用和不能用之間,由於 AMD 這邊沒有搞出 IR,GPU Code 必須針對每個想要支援的 GPU ISA 重新編譯,非常刺激。除此之外,一樣是跑 SD,在 AMD 上面的 VRAM 使用量就總是 NVIDIA CUDA 那邊的兩倍或以上。AMD 還說 ROCm 跨平台,NVIDIA GPU 也能用。~~(但我不覺得會有人腦袋撞到放著 CUDA 不用)~~
AMD ROCm 在 Stable Diffusion 上面表現很差,在 llama.cpp 這邊則是一般。
### Intel oneAPI / OpenVINO:
Intel 自己生出來的解決方案,支援它的東西暫時還不夠多。
### OpenCL/SYCL:
其實每一家 GPU 廠商的 Compute Stack 通常都支援 OpenCL,但現在 ML 不流行它,因為搞起來很麻煩(不像 CUDA 那樣是 single-source,即使是最簡單的小程式也必須手動進行很多底層操作才能初始化設備),而且 OpenCL 規範也老了,不方便運用現在 GPU 中各種加速單元。
SYCL 則是太新了,而且和 OpenCL 一樣每個廠商要提供自己的實做,又因為大家現在都抱著 CUDA(除了 Intel 在推廣 SYCL),因此沒什麼人用。
## Tensor Core 的重要性:
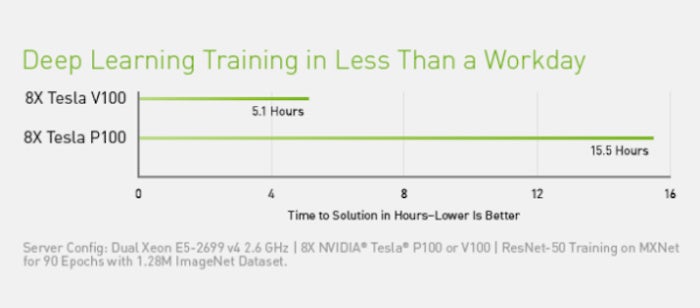
> Rule of Thumb: 如果這張卡在 2018 以後推出,那它應該就有 Tensor Core
Tensor Core 是一種針對 ML 矩陣操作進行加速的特殊專用,它還可以大幅加速各種混合精度操作,讓訓練/推理速度更快。擁有 Tensor Core 的顯卡即使 MD5 Hashrate 差不多,也會有更快的 ML 計算速度。NVIDIA 在 2018 推出第一款擁有 Tensor Core 的 Server GPU: V100 之後,從 RTX20 系卡開始,消費級顯示卡上也包含了 Tensor Core。
AMD 的消費級卡要到 2022 年推出的 RX7000 系列上面才開始擁有類似的 WMMA 加速功能,但是效能依舊不太行,加上 VRAM 使用效率不好,大多數用途還是 NVIDIA 最吃香。
## 各種 GPU 們
| 測試過 | 顯卡 | 相對效能 | VRAM (GiB) | 參考價格 (USD) | 備註 |
| ------ | --------------------- | -------- | ----------:| --------------:| ------ |
| ✅ | AMD Radeon 780M | ★☆☆☆☆ | 8 | -- | |
| ✅ | AMD RX590 | ★☆☆☆☆ | 8 | 70 | #3 |
| ✅ | AMD RX6500XT | ★☆☆☆☆ | 4 | 80 | #3 |
| ✅ | AMD RX6600XT | ★☆☆☆☆ | 8 | 100 | #3 |
| ✅ | NVIDIA Tesla P4 | ★☆☆☆☆ | 8 | 50 | #2 |
| ✅ | NVIDIA Tesla P40 | ★☆☆☆☆ | 24 | 120 | #2 |
| ❌ | NVIDIA Tesla P100 | ★☆☆☆☆ | 16 | 130 | #2 |
| ✅ | NVIDIA T4 | ★★☆☆☆ | 16 | 700# | #1 |
| ✅ | AMD RX6800 | ★★☆☆☆ | 16 | 300+ | |
| ✅ | AMD RX6700XT | ★★☆☆☆ | 12 | 250+ | |
| ✅ | Intel Arc A750 | ★★★☆☆ | 8 | 200@ | WIP #5 |
| ❌ | Intel Arc A770 | ★★★☆☆ | 16 | 330@ | #5 |
| ✅ | NVIDIA RTX3060 12G | ★★★☆☆ | 12 | 200 | |
| ✅ | NVIDIA RTX3070M 16G | ★★★☆☆ | 16 | 250 | #4 #7 |
| ✅ | NVIDIA RTX3060 Ti | ★★★☆☆ | 8 | 250 | |
| ❌ | NVIDIA Tesla V100 | ★★★☆☆ | 16 | 700 | |
| ✅ | NVIDIA RTX2080 Ti 22G | ★★★☆☆ | 22 | 330 | #4 |
| ❌ | NVIDIA RTX A4000 | ★★★☆☆ | 16 | 700 | |
| ✅ | NVIDIA RTX4060Ti 16G | ★★★☆☆ | 16 | 500@ | #6 |
| ❌ | NVIDIA L4 | ★★★★☆ | 24 | 2500+ | |
| ✅ | NVIDIA RTX4070 | ★★★★☆ | 12 | 600+ | |
| ✅ | NVIDIA RTX3080 | ★★★★☆ | 10 | 330+ | |
| ✅ | NVIDIA RTX3080 20G | ★★★★☆ | 20 | 400+ | #4 |
| ✅ | NVIDIA RTX3080Ti | ★★★★☆ | 12 | 400+ | |
| ✅ | NVIDIA RTX3090 | ★★★★☆ | 24 | 700+ | |
| ✅ | NVIDIA RTX3090Ti | ★★★★☆ | 24 | 800+ | |
| ✅ | NVIDIA RTX4080 | ★★★★☆ | 16 | 833+ | |
| ❌ | NVIDIA L40 | ★★★★★ | 48 | 10000+ | |
| ✅ | NVIDIA RTX6000 Ada | ★★★★★ | 48 | 10000+ | |
| ✅ | NVIDIA RTX4090 | ★★★★★ | 24 | 2000# | |
| ❌ | NVIDIA RTX4090 48G | ★★★★★ | 48 | 3000# | #4 |
價格標示:+ 表示以上,# 表示根據不同區域,價格差很大,@ 表示全新價格
備註:
1. T4 價格高,跑 SD 發揮不出理論 FP16 效能,優勢只有省電以及 VRAM 夠大
2. Pascal 是老架構,沒有 Tensor Core,沒辦法高效率進行混合精度計算,P4 和 P40 甚至沒有 FP16
3. 頭殼被門夾到才會買這種卡
4. 魔改卡,穩定性取決於人品
5. Intel Arc 在 Linux 上暫時沒看法看溫度/功耗,且環境設定起來比 NVIDIA/AMD 都困難
6. NVIDIA RTX4060Ti 的 VRAM 頻寬被砍得很慘,這點要注意
7. RTX3070M 16G 魔改卡直接裝 550 系列 nvidia-open 驅動就能使用
### 觀察到的有趣現象:
1. Tesla T4 開 xformers 後算圖速度和 RX6800 差不多,此時 T4 只有 ⅓ 功耗
2. 3060Ti/3080 等 30 系卡插在 PCI-E 3.0 x1 會讓 nv_queue 卡住 Kernel
3. Tesla P40 算圖速度大約是 3080 的 1/5
4. 4070 算圖速度和 3080 幾乎不分上下
5. 4090 SDXL 算圖速度是 4070 的兩倍以上
6. RTX3080Ti 把功耗從 350W 降到 250W (-28.6%) 只會損失 12% 效能,此時能耗比趨近於 RTX4070
7. RTX3090Ti 把功耗從 480W 降到 350W (-27%) 只會損失大約 10% 效能
## 效能測試方案:
FP32, FP16, INT32 Peak Performance:
* [mixbench](https://github.com/ekondis/mixbench)
* [clpeak](https://github.com/krrishnarraj/clpeak/)
General Compute Performance:
* [hashcat](https://github.com/hashcat/hashcat): various hash
* [blender benchmark](https://opendata.blender.org/): 3D render
* [FluidX3D](https://github.com/ProjectPhysX/FluidX3D): open-source high-performance fluild simulation
GPU Mining:
* Cryptonote-based coin mining: [xmrig](https://github.com/xmrig/xmrig)
* Ethereum Classic (ETC) mining: SRBMiner-Multi, lolminer, t-rex
ML Inference:
* [llama.cpp](https://github.com/ggerganov/llama.cpp) (mainly INT4 / INT8)
* [vLLM](https://github.com/vllm-project/vllm) (mainly INT4 / INT8)
* [SGLang](https://github.com/sgl-project/sglang) (mainly INT4 / INT8)
* [whisper.cpp](https://huggingface.co/ggerganov/whisper.cpp) (mainly INT8)
* [stable-diffusion-webui-forge](https://github.com/lllyasviel/stable-diffusion-webui-forge) (autocast FP16/BF16)
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui) (INT4/INT8/FP16)
ML Training:
* [LoRA_Easy_Training_Scripts](https://github.com/derrian-distro/LoRA_Easy_Training_Scripts) (FP16/BF16/FP32)
* [sd-scripts](https://github.com/kohya-ss/sd-scripts) (FP16/BF16/FP32)
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui) (INT4/INT8/FP16)
## Basic Benchmark Results:
| 顯卡 | 相對效能 | VRAM GiB | MD5 | 7B LLM | Haven |
|:--------------------- |:-------- | --------:| -------:| ------:| --------:|
| AMD Radeon 780M | ★☆☆☆☆ | 4 | 7GH/s | 16t/s | 282H/s |
| AMD RX590 | ★☆☆☆☆ | 8 | 14GH/s | 16t/s | 941H/s |
| AMD RX6500XT | ★☆☆☆☆ | 4 | 14GH/s | N/A | 431H/s |
| AMD RX6600XT | ★☆☆☆☆ | 8 | 25GH/s | 42t/s | 831H/s |
| NVIDIA Tesla P4 | ★☆☆☆☆ | 8 | 15GH/s | 15t/s | 446H/s |
| NVIDIA Tesla P40 | ★☆☆☆☆ | 24 | 31GH/s | 20t/s | 854H/s |
| NVIDIA Tesla P100 | ★☆☆☆☆ | 16 | 27GH/s | ?? | ?? |
| NVIDIA T4 | ★★☆☆☆ | 16 | 20GH/s | ~20t/s | ?? |
| AMD RX6800 | ★★☆☆☆ | 16 | 40GH/s | 61t/s | ~1900H/s |
| AMD RX6700XT | ★★☆☆☆ | 12 | 32GH/s | 44t/s | 1421H/s |
| Intel Arc A750 | ★★★☆☆ | 8 | 32GH/s | N/A | ~800H/s |
| Intel Arc A770 | ★★★☆☆ | 16 | 33GH/s | ?? | ?? |
| NVIDIA RTX3060 12G | ★★★☆☆ | 12 | 24GH/s | ?? | ?? |
| NVIDIA RTX3060 Ti | ★★★☆☆ | 8 | 32GH/s | N/A | ~1500H/s |
| NVIDIA RTX3070M 16G | ★★★☆☆ | 16 | 34GH/s | 73t/s | 1488H/s |
| NVIDIA Tesla V100 | ★★★☆☆ | 16 | 55GH/s | ?? | ?? |
| NVIDIA RTX2080 Ti 22G | ★★★☆☆ | 22 | 49GH/s | 93t/s | 1116H/s |
| NVIDIA RTX A4000 | ★★★☆☆ | 16 | 35GH/s | ?? | ?? |
| NVIDIA RTX4060Ti 16G | ★★★☆☆ | 16 | 41GH/s | 55t/s | ?? |
| NVIDIA L4 | ★★★★☆ | 24 | 40GH/s | ?? | ?? |
| NVIDIA RTX4070 | ★★★★☆ | 12 | 57GH/s | 89t/s | 1700H/s |
| NVIDIA RTX3080 | ★★★★☆ | 10 | 59GH/s | 103t/s | 2100H/s |
| NVIDIA RTX3080 Ti | ★★★★☆ | 12 | 67GH/s | 135t/s | 2600H/s |
| NVIDIA RTX3090 | ★★★★☆ | 24 | 66GH/s | ?? | ?? |
| NVIDIA RTX3090 Ti | ★★★★☆ | 24 | 79GH/s | 140t/s | 2856H/s |
| NVIDIA RTX4080 | ★★★★☆ | 16 | 91GH/s | 100t/s | 1888H/s |
| NVIDIA L40 | ★★★★★ | 48 | 124GH/s | ?? | ?? |
| NVIDIA RTX6000 Ada | ★★★★★ | 48 | 125GH/s | ?? | ?? |
| NVIDIA RTX4090 | ★★★★★ | 24 | 150GH/s | ?? | 3426H/s |
(7B LLM 分數大致與 VRAM 頻寬呈正比)
Mixbench results (CPU & GPU): [NeoChen1024/mixbench-results](https://github.com/NeoChen1024/mixbench-results/)
Blender Benchmark Open Data: [opendata.blender.org](https://opendata.blender.org/)
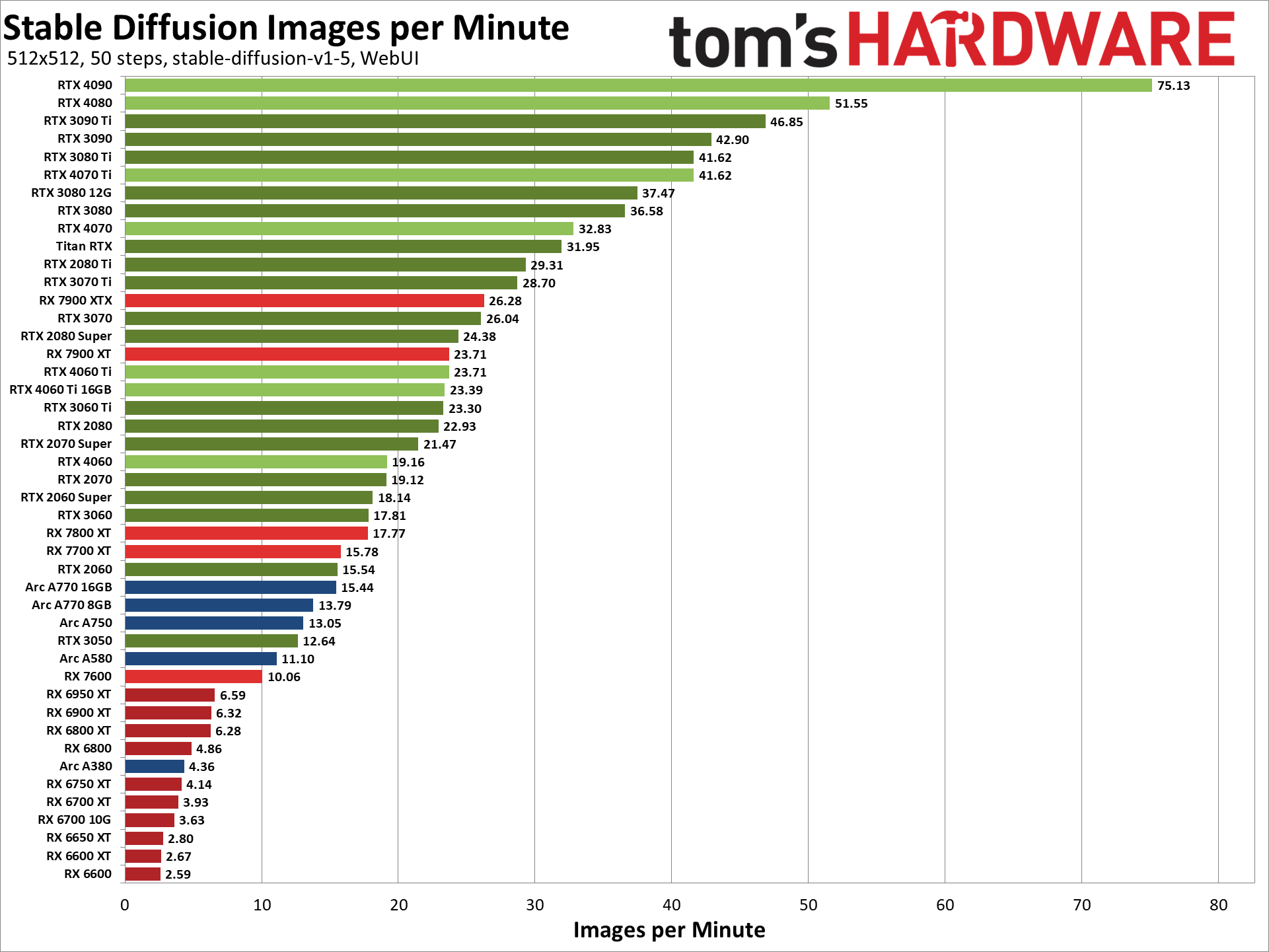
### Tom's Hardware Stable Diffusion Benchmark (Consumer-Grade Cards Only):
## 參考配置
根據幾種常見用途,推薦下面幾種搭配:
### SD1.5 / SDXL:
CPU 部分隨意,只要如前面提到的,有合理效能即可。
GPU 部分即使是訓練 SDXL Lora,unet-only 的狀況下使用 BF16 精度訓練只需要 12G VRAM 就夠了,此時 RTX3060 12G 就是個很好的入門選擇,但如果想要追求更高算圖速度,可以考慮 3080 / 3080Ti。
### LLM:
執行太大的模型時都有可能因為沒辦法把所有 layer 都放到 VRAM 裡面,這時候 CPU 效能就會比較重要,所以 AMD Ryzen 5 5600X 或是更高效能的 CPU 都是很好的選擇。
至於 GPU 部分由於單使用者狀況下只要有 10t/s 左右的計算速度都可以提供良好聊天體驗,像是 NVIDIA Tesla P40 這種 VRAM 特別大的卡就很適合拿來跑 LLM。如果覺得 P40 架構太古老,也可以考慮 2x RTX3060 12G 之類的組合。假設預算上並沒有任何限制,直接買 3090 (24G),甚至是 2x 3090 也是不錯的選擇。
此外,因為 LLM 推理計算大多數時候瓶頸都在 VRAM 頻寬,如果搞 batched inference 同時處理多個 request 效率會更好,因此如果有需求,VRAM 最好遠大於 LLM 模型本身。
## 我的配置

### 我的主機:
<iframe height=768px src="https://docs.google.com/spreadsheets/d/e/2PACX-1vRCU4kCPukHpLbe86QpOg5pR0gGB6-KmkEhZ8dWGpMcbcCfuCkVbyrV4TNVBj2TUREvcWKlKovG6SNR/pubhtml?gid=914867685&single=true&widget=true&headers=false"></iframe>
### 第二主機:

<iframe height=768px src="https://docs.google.com/spreadsheets/d/e/2PACX-1vRCU4kCPukHpLbe86QpOg5pR0gGB6-KmkEhZ8dWGpMcbcCfuCkVbyrV4TNVBj2TUREvcWKlKovG6SNR/pubhtml?gid=978595277&single=true&widget=true&headers=false"></iframe>