# Related Works for ScrapeRise
## 1) Scrapy
#### URL:
https://scrapy.org/
#### Scrapy GitHub Repository:
[https://github.com/scrapy/scrapy]
#### Company Name:
Scraping Hub Company
[https://medium.com/geekculture/lets-discover-the-wonderful-world-of-scrapy-scraping-with-ac9571338e2e]
#### Release Year:
September 2009
[https://medium.com/geekculture/lets-discover-the-wonderful-world-of-scrapy-scraping-with-ac9571338e2e]
#### Description:
- Scrapy is an open source **==python framework==** for web scraping to extract the data from websites by building custom **spiders** that define how a certain site or a group of sites will be and how to extract structured data from their pages. As well as it can use **proxy API**.
[https://scrapy.org/]
[https://docs.scrapy.org/en/latest/topics/spiders.html]
[https://www.zenrows.com/blog/scrapy-proxy]
scrapedmd.io/_uploads/r1_xSK71p.png)
#### Features:
- Selecting and extracting data from HTML/XML sources using **XPath** and **extended CSS selectors**, with helper methods to extract using regular expressions.
- Using an interactive shell console (IPython aware) for **trying out** the XPath and CSS expressions to scrape data, very useful when writing or debugging your spiders.
- Exporting data in **multiple formats** (JSON, CSV, XML) and storing them in multiple backends (FTP, S3, local filesystem).
- Robust encoding supportting and **auto-detection**, for dealing with non-standard , foreign and broken encoding declarations.
- Strong extensibility supporting, allowing you to plug in your own functionality using signals and a well-defined API (middlewares, extensions, and pipelines).
[https://docs.scrapy.org/en/latest/intro/overview.html]
#### Photo:

[https://scrapeops.io/assets/images/tut-5-7-0158f534ab7c38ecf54b6e2aca0c2bc6.png]
******************************
## 2) WebHarvy
#### URL:
https://www.webharvy.com/
#### Company Name:
WebHarvy
[https://www.predictiveanalyticstoday.com/webharvy/]
#### Release Year:
March 23, 2021
[https://www.webharvy.com/blog/category/release-update/]
#### Description:
- WebHarvy is a **==C# web scraping software application==** that can automatically scrape Text, Images, URLs & Emails from websites by using **proxy** servers or solve the CAPTCHA manually.
[https://www.predictiveanalyticstoday.com/webharvy/]
[https://www.g2.com/products/webharvy/reviews]
[https://www.webharvy.com/tour6.html]
[https://www.predictiveanalyticstoday.com/webharvy/]
[https://www.webharvy.com/articles/sites-requiring-login.html]
#### Features:
- Exporting scraped data to files(Excel, XML, CSV, JSON or TSV) or to SQL databases(Microsoft SQL Server, Oracle, MySQL and PostgreSQL).And it can integrate with other applications using the API.
- Providing Point-and-Click Interface that can help to navigate through websites and select the data you want to extract by **clicking** on the elements.
- Providing Automatic Pattern Detection on web pages to ease the scraping on multiple pages with **similar** structures. It intelligently identifies data elements such as URLs, images, text, prices, and more.
- Supporting advanced scraping techniques like **pagination handling**, **form filling**, **interacting with JavaScript-based elements** on websites, and handling **AJAX** requests.
[https://stackdiary.com/web-scraping-tools-and-apps/]
#### Photo:

[https://a.fsdn.com/con/app/proj/webharvy.s/screenshots/3-5acb26ee.PNG/1000/auto/1]
******************************
## 3) Mozenda:
#### URL:
https://www.mozenda.com/
#### Company Name:
Mozenda, Inc.
#### Release Year:
Mozenda was founded in 2007.
[https://www.mozenda.com/2018-mozenda-year-in-review/]
#### Description:
Mozenda is a web scraping **==tool==** that allows users to view, organize and run reports on data collected from websites, it’s automatically detects information organized in lists on user-specified web pages and allows users to build agents to collect this data by using **proxy API**.
<!-- build using mix programming languges(Python, JavaScript, Java, .NET (C#), SQL, HTML/CSS, Web Technologies (HTTP, REST, AJAX)) -->
#### Features:
- Offering a point-and-click interface to create Web Scraping events from any website in no time.
- Request blocking features and job sequencers to harvest web data in real-time.
- Providing the best customer support and in-class account management
- Collecting and publishing data to preferred BI tools or databases.
[https://hevodata.com/learn/web-scraping-tools/#Mozenda]
[https://www.proxyrack.com/blog/what-is-mozenda/]
#### Photo:
https://www.mozenda.com/new-feature-release-do-more-with-your-data/

*********************************
## 4) ParseHub:
#### URLs:
(https://www.parsehub.com/)
#### Company Name:
Developed by ParseHub Inc.
(https://www.parsehub.com/)
#### Release Year:
Available for web scraping since at least 2016.
(https://www.parsehub.com/)
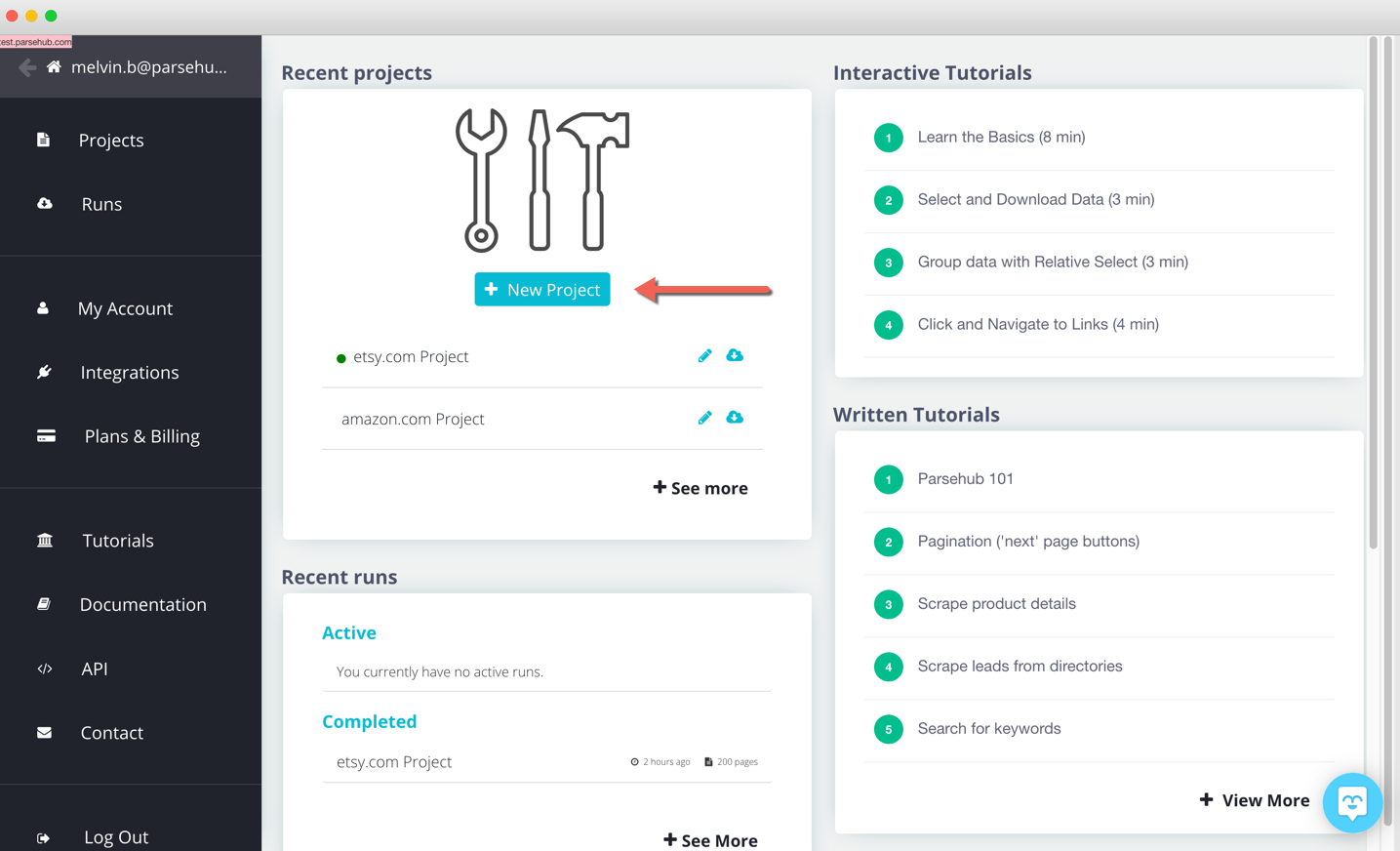
#### Description:
ParseHub is a user-friendly JavaScript web scraping **==tool==** that can be **extract data** from dynamic websites especially from e-commerce websites **using AJAX or JavaScript**. As well as it can use **proxy API**.
[https://www.parsehub.com/]
[https://stackdiary.com/web-scraping-tools-and-apps/#:~:text=Key%20Features%20of%20ParseHub&text=You%20can%20easily%20navigate%20through,run%20automatically%20at%20specified%20intervals]
[https://help.parsehub.com/hc/en-us/articles/115001324853-Adding-Custom-Proxies-to-ParseHub-for-all-Paid-Plans-]
#### Features:
- Selecting and extracting product information, prices, and more.
- Providing a visual web scraping tool with a point-and-click interface.
- Allowing users to create scraping projects without coding.
- Supporting scraping data from dynamic websites.
- Allowing data export in various formats, including CSV and JSON.
- Providing scheduling and automation features.
(https://www.parsehub.com/)
#### Photo:
*********************************
## 5) Import.io
#### URL:
https://www.import.io/
#### Company Name:
Import.io
[https://www.crunchbase.com/organization/importio]
#### Release Year:
2012
[https://www.parsehub.com/blog/parsehub-vs-import-io-which-alternative-is-better-for-web-scraping/]
#### Description:
- Import.io is a **==python web-based platform[API]==** <<https://www.g2.com/products/import-io-2017-12-19/reviews>> designed to allow users to easily extract web data for their analytics, big data, data visualization, machine learning or artificial intelligence projects by using **proxy** server, it can't solve the CAPTCH<<https://www.octoparse.com/blog/octoparse-vs-importio-comparison-which-is-best-for-web-scraping>>.
- Use **XPath**, **Click and point** for select element.<<https://www.loginworks.com/blogs/who-wins-the-war-octoparse-vs-import-io/>>
[https://www.g2.com/products/import-io-2017-12-19/reviews]
#### Features:
- Using auto-Extraction by **capturing** information and **converting** it to the **structured data set**(CSV, JSON, API, Google Sheets).<<https://www.octoparse.com/blog/octoparse-vs-importio-comparison-which-is-best-for-web-scraping>>
- Captureing only the **complex content** of a web page that you want to scrape.<<https://www.loginworks.com/blogs/who-wins-the-war-octoparse-vs-import-io/>>
- Using authentication that works with the login and password details.<<https://www.loginworks.com/blogs/who-wins-the-war-octoparse-vs-import-io/>>
- Creating automatic crystal report and content crystal reports.<<https://www.loginworks.com/blogs/who-wins-the-war-octoparse-vs-import-io/>>
- Using a Saas platform to store the extracted data in the database.<<https://www.loginworks.com/blogs/who-wins-the-war-octoparse-vs-import-io/>>
[https://www.loginworks.com/blogs/who-wins-the-war-octoparse-vs-import-io/]
[https://www.octoparse.com/blog/octoparse-vs-importio-comparison-which-is-best-for-web-scraping]
[https://medium.com/@wrekindata/how-to-use-import-io-to-scrape-data-from-amazon-5558b5a833e9]
[https://stackoverflow.com/questions/28902213/accessing-import-io-api-through-a-proxy-server]
#### Photo:
[https://docs.import.io/reference/dashboard/]
*********************************
## 6) Puppeteer:
#### URLs:
(https://pptr.dev/)
#### Company Name:
Developed by Google.
#### Release Year:
Introduced in 2017.
(https://pptr.dev/)
#### Description:
Puppeteer is a **==Node.js library==** for web scraping and browser automation. It can handle websites that employ **anti-scraping measures** using **proxy** servers for enhanced anonymity and IP management.
[https://pptr.dev/]
[https://www.browserstack.com/guide/puppeteer-proxy]
#### Features:
- Automating headless Chrome or Chromium browsers.
- Supporting web scraping, automation, and taking screenshots of web pages.
- Providing a high-level API for controlling browser actions.
- Useful for complex web interactions and dynamic content scraping.
- Cross-platform compatibility.
(https://pptr.dev/)
(https://github.com/CheshireCaat/puppeteer-with-fingerprints?gclid=CjwKCAjwsKqoBhBPEiwALrrqiOkx7aCJjQfhfvE_jBwJ8eBH4NlxOaxexA_uaI1rcXzmFtUNxNDNYRoCSlUQAvD_BwE)
#### Photo:

*********************************
## 7) Content Grabber:
#### URL:
[https://contentgrabber.com/Manual/understanding_the_concept.htm]
#### Company Name:
Content Grabber is developed by Sequentum, a software company specializing in web data extraction solutions.
[https://alternativeto.net/software/content-grabber/about/]
#### Release Year:
Content Grabber was first released in May 15, 2015.
[https://content-grabber1.software.informer.com/versions/]
#### Description:
- Content Grabber is a Web Scraping and Web automation **==tool==** that can extract content from almost any website and save it as structured data in a format of your choice, including Excel reports, XML, CSV and most databases by using a **proxy API**.
[https://alternativeto.net/software/content-grabber/about/]
#### Features:
- Fast web data extraction compared to a lot of its competitors.
- Allowing building web apps with the dedicated API with the ability to execute web data directly from the website.
- Scheduling it to scrape information from the web automatically.
- Offering a wide variety of formats for the extracted data like CSV, JSON, etc.
[https://hevodata.com/learn/web-scraping-tools/#:~:text=Key%20Features%20of%20Content%20Grabber&text=Allows%20you%20to%20build%20web%20apps%20with%20the%20dedicated%20API,like%20CSV%2C%20JSON%2C%20etc]
[http://webdata-scraping.com/web-scraping-using-content-grabber-api]
#### Photo:

[https://contentgrabber.com/Manual/understanding_the_concept.htm]
*********************************
## 8) Beautiful Soup:
#### URLs:
(https://www.crummy.com/software/BeautifulSoup/)
#### Company Name:
Beautiful Soup is an open-source project with contributions from various developers in the Python community.
(https://www.crummy.com/software/BeautifulSoup/)
#### Release Year:
It doesn't have a specific release year as a software application would. Instead, it is continually updated and maintained as part of the Python library ecosystem.
(https://www.crummy.com/software/BeautifulSoup/)
#### Description:
Beautiful Soup is a **==Python library==** to extract data from HTML and XML documents, making it easier to scrape data from web pages by simplifying document structure navigation. It **doesn't** handle HTTP requests or manage issues like **CAPTCHAs** or **proxy** rotation. You may need to use **additional libraries** or **tools** for these purposes, depending on your web scraping project.
(https://www.crummy.com/software/BeautifulSoup/)
(https://brightdata.com/blog/proxy-101/proxy-with-python-requests)
#### Features:
- Python library for parsing HTML and XML documents.
- Providing easy navigation and search of document structures.
- Ideal for extracting data from web pages when used in combination with other libraries like Requests.
- Allowing manipulation of parsed data.
(https://www.crummy.com/software/BeautifulSoup/)
(https://stackoverflow.com/questions/45533571/webpage-values-are-missing-while-scraping-data-using-beautifulsoup-python-3-6)
#### Photo:

*********************************
## 9) Octoparse:
https://www.octoparse.com/blog/octoparse-vs-importio-comparison-which-is-best-for-web-scraping
#### URLs:
(https://www.octoparse.com/)
#### Company Name:
Developed by Octopus Data Inc.
(https://www.octoparse.com/)
#### Release Year:
Available since 2013.
(https://www.octoparse.com/)
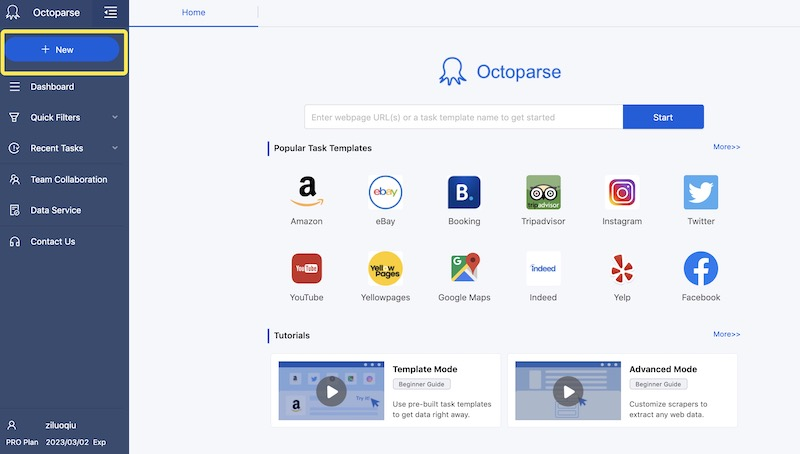
#### Description:
Octoparse is a web scraping **==tool==** for extracting data from **e-commerce websites**.It scrapes product details, images, and more by using **proxy** servers and solve CAPTCH automatically.
And it can supports advanced scraping techniques, such as **interacting** with **JavaScript-based elements** on websites, handling **AJAX requests**.
(https://www.octoparse.com/)
(https://helpcenter.octoparse.com/en/articles/6470932-set-up-ip-proxies)
#### Features:
- Providing user-friendly interface.
- No coding required, point-and-click operation.
- Enabling extraction from various websites.
- Exporting data to multiple formats(Excel, JSON, database, etc.) or to local database.
- Scheduling scraping and cloud service.(https://www.octoparse.com/)
#### Photo:
*********************************
## 10) Selenium with Browser Automation:
#### URLs:
(https://www.selenium.dev/)
#### Company Name:
Selenium is an **open-source project** with contributions from individuals and organizations.
#### Release Year:
First introduced in 2004.
(https://www.selenium.dev/)
### Description:
Selenium is a versatile **==tool==** for browser automation and web scraping. It can **handle anti-scraping measures** by simulating user interactions in a web browser. As well as it's using **proxy** servers for IP rotation and anonymity. For websites with CAPTCHAs, you may need to **implement** CAPTCHA solving mechanisms.
(https://www.selenium.dev/)
(https://www.browserstack.com/guide/set-proxy-in-selenium)
#### Features:
- Cross-browser automation framework for web testing and scraping.
- Supporting multiple programming languages (Java, Python, C#, etc.).
- Providing WebDriver for browser automation.
- Suitable for automating complex web interactions.
[https://www.selenium.dev/documentation/]
#### Photo:

*********************************
## 11) Scraper API:
#### URL:
https://dashboard.scraperapi.com/
#### Company Name:
ScraperAPI, Inc.
#### Release Year:
ScraperAPI was released in 2020.
https://www.prnewswire.com/news-releases/fe-international-advises-scraperapi-in-acquisition-by-saasgroup-301111971.html
#### Description:
- Scraper API is a Web Scraping **==tool==** that helps you to manage proxies, browsers and CAPTCHAs so you can get the HTML from any web page by making an API call. As well as it can use **proxy API**.
[https://popupsmart.com/blog/web-scraping-tools#13scraperapi]
#### Features:
- Extracting data from HTML, PDF files, documents, and images.
- Providing a reliable and efficient way to extract data from websites without having to worry about managing proxies or dealing with captchas.
- Handling proxy rotation, browsers, and CAPTCHAs so developers can scrape any page with a single API call.
[https://hevodata.com/learn/web-scraping-tools/#ScraperAPI]
[https://popupsmart.com/blog/web-scraping-tools#13scraperapi]
#### Photo:

https://www.webscrapingapi.com/serp-scraping-api-starting-guide
******************************
 Sign in with Wallet
Sign in with Wallet







