# A Constrained Long-form Question Answering (LFQA) Model on eli5_category
A final project of *ANLY-580: NLP for Data Analytics* at Georgetown University.
Presented by:
- Jingsong Gao, jg2109@georgetown.edu
- Qinren Zhou, qz142@georgetown.edu
- Rui Qiu, rq47@georgetown.edu

> Credit: [Darren Lebeuf](http://landoflebeef.com/blog/2013/4/24/bert-and-bart)
## 1. Introduction
The search engines nowadays enable us to ask any questions as a search query. However, when it comes to a scientific question, the answer to that question could be either not accurate enough or too specialized to understand. For instance, to fully apprehend a Wikipedia page, one might need much prior knowledge in a particular area.
Prior research on long-form question answering aims to fix this issue. [ELI5: Long Form Question Answering](https://ai.facebook.com/blog/longform-qa/) by Facebook (2019) and [Hurdles to Progress in Long-form Question Answering](https://arxiv.org/abs/2103.06332) by Google (2021) are two representative papers in this area. Facebook created the ELI5 dataset and used the ROUGE-L metric to evaluate the long-form answers in their paper, which the dataset and metric widely used in later research. However, Google’s paper pointed out that the dataset has severe train/validation overlapping and the metric showing a lack of distinction between random answers and gold answers.
Therefore, instead of training models on a dataset with potential issues and gaining higher grades using an invalid metric, our project will focus on recreating a categorized ELI5 dataset and proposing more discriminatory metrics for this LFQA task.
## 2. Dataset
### 2.1 Source
The subreddit [r/explainlikeim5](https://www.reddit.com/r/explainlikeimfive/) (ELI5) from Reddit is a worthy training dataset. Users in this subreddit are known for their objective, thorough and intuitive explanations of various questions. ELI5 is appealing because answers are supposed to be entirely self-contained and thus rely less on pre-existing knowledge of the world and use more straightforward language that is easier to model.
### 2.2 Facebook's `ELI5`
The [ELI5 dataset](https://huggingface.co/datasets/eli5) created by Facebook contains more than 270,000 posts in the subreddit from 2012 to 2019, and each post consists of a scientific question and some easy-to-understand answers.
### 2.3 Issues of Uncategorized Data
In Google AI Blog's post [Progress and Challenges in Long-Form Open-Domain Question Answering](https://ai.googleblog.com/2021/03/progress-and-challenges-in-long-form.html), researchers addressed three concerning trends in the progress of building a more sensible model:
1. Many held-out questions are paraphrased in the training set. This is caused by the fact that even though the subreddit /r/explainlikeim5 is clearly against repeated questions, it is simply unavoidable.
2. ROGUE metric is not always a good evaluation standard. This one is actually not related to the uncategorized characteristic of the data, but we will mention it again in the later section.
3. The third issue comes as the byproduct of previous two. If we set an answer conditionally generated on random documents, instead of relevant documents, it still can provide a "correct" and factual answer. And at the same time, the longer answer has a higher ROGUE-L score.
We aim to tackle the **first issue** our categorized version of data.
### 2.4 Our `ELI5_Category`
So the main question here is: **Why categorize the data?**
Recall the overlapping issue we metioned earlier. The most straightforward solution to this is to figure out why the overlapping occurs, then we can purposefully resolve it.
With the introduction of the thread tagging system in 2017, the questions that appeared in the subreddit are more organized in such a manner. As a result, if we take a random sample collections of questions as the training set, and the sample size is large enough, it barely impossible to neglect the fact some questions would be repetitive or overlapping.
In order to control the overlapping, [Hurdles to Progress in Long-form Question Answering](https://arxiv.org/abs/2103.06332) offers two specific solutions:
1. Automatically retrieving paraphrases and then running human validation to eliminate them.
2. Holding out entire genres or domains to reduce the possibility of overlap — for example, keeping Q/A on Sports only in the held-out sets.
Therefore, we built our abridged but categorized version of the ELI5 dataset using posts in the subreddit from 2017 to 2021, which named as [ELI5_Category](https://huggingface.co/datasets/jsgao/eli5_category). Our dataset contains more than **100,000 questions and 220,000 answers**.
The dataset is split into 1 training set, 2 validation sets, and 1 test set according to the category. The number of questions contain in each set is listed below.
| | Train | Valid | Valid2 |Test |
| ----- | ------ | ----- | ---- | ---- |
| `Biology` | 32769 | | | |
| `Chemistry` | 6633 | | | |
| `Culture` | | 5446 | | |
| `Earth Science` | 677 | | | |
| `Economics` | 5901 | | | |
| `Engineering` | | | | 5411 |
| `Mathematics` | 1912 | | | |
| `Other` | 19312 | | | |
| `Physics` | 10196 | | | |
| `Psychology` | 338 | | | |
| `Technology` | 14034 | | | |
| `Repost` | | | 2375 | |
| **Total** | 91772 | 5446 | 2375 | 5411 |
Some simple aggregations on the ELI5 data will reveal that:
| `category` | `mean_top_score` | `mean_all_score` | `mean_answer_num` |
|:--------------- | ----------------:| ----------------:| -----------------:|
| 1 Biology | 205. | 114. | 2.37 |
| 2 Chemistry | 197. | 114. | 2.15 |
| 3 Earth Science | 170. | 81.9 | 2.54 |
| 4 Economics | 141. | 75.3 | 2.84 |
| 5 Mathematics | 209. | 108. | 2.66 |
| 6 Other | 133. | 72.1 | 2.62 |
| 7 Physics | 136. | 78.4 | 2.24 |
| 8 Psychology | 159. | 78.4 | 2.60 |
| 9 Technology | 169. | 91.7 | 2.43 |
| 10 Culture | 162. | 79.7 | 3.14 |
| 11 Repost | 281. | 158. | 2.56 |
| 12 Engineering | 179. | 92.5 | 2.58 |
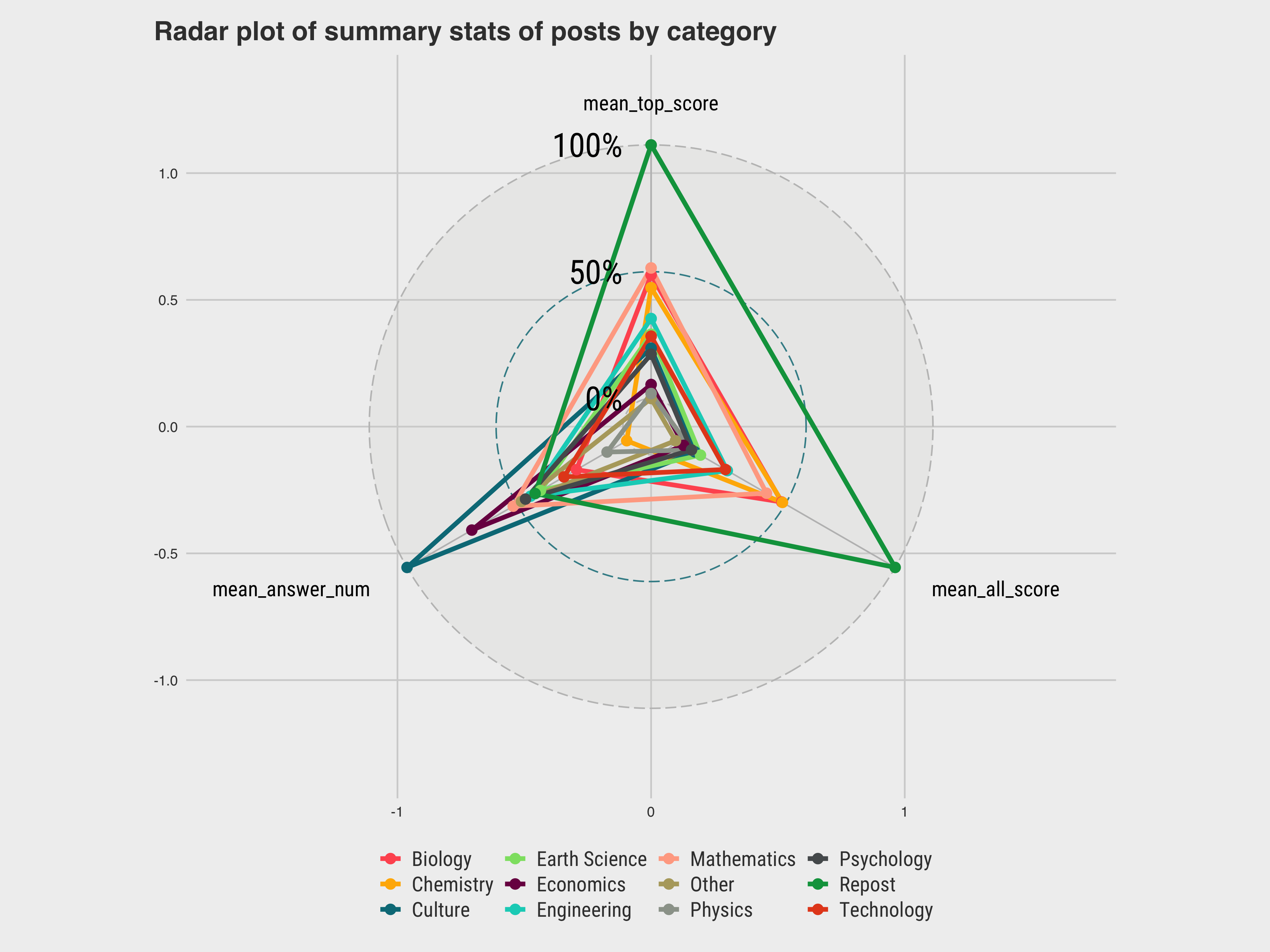
- Why reposts have higer scores:
- Posts with more reposts tend to contain trending topics, which means users are more motivated to answer.
- Higher scores of reposts can come from higher correctness of the solution, that's also why those questions are frequently reposted.
- Reposts are not classified by category intentionally, indicating that using the reposts as training set may lead to overlapping problems.
### 2.5 Ground Truth
Since answers are generated based on pre-existing knowledges, the model need to find supporting documents for questions first. Here, we use the [wiki_snippets(wiki40b_en_100_0)](https://huggingface.co/datasets/wiki_snippets) dataset as the ground truth to support the model answering those questions. This wikipedia dataset contains more than 17,500,000 snippets from Wikipedia.
## 3. Model
### 3.1 Two-stage Model Structure

> Credit: [Yacine Jernite](https://yjernite.github.io/lfqa.html)
Our LFQA model has a two-stage model structure: `Retriever-Generator`. First, document retriever model selects a set of Wikipedia passages that relevant to the input questions as supporting documents. Then, the answer generator model takes the concatenation of the input question and supporting documents as input and writes the answer.
### 3.2 Retrierver: BERT + Faiss

> Credit: [Yacine Jernite](https://yjernite.github.io/lfqa.html)
The retriever model is based on a pretrained BERT-like structure, but with an additional linear layer that projects the BERT output down to 128 dimensions embeddings. The projection layer is finetuned using QA pairs in training set to minimize the dot-product between question embedding and answer embedding.

> Credit: [Yacine Jernite](https://yjernite.github.io/lfqa.html)
To find the best relevant supporting documents, we do a Approximate Nearest Neighbor search with all Wikipedia passages' embedding vectors. The ANN search is accelerated by pre-clustering Wikipedia embeddings using Facebook's [faiss](https://ai.facebook.com/tools/faiss/) library.
### 3.3 Generator: BART

> Credit: [Papers with Code](https://paperswithcode.com/method/bart)
BART is a denoising autoencoder for pretraining sequence-to-sequence models. It is trained by (1) corrupting text with an arbitrary noising function, and (2) learning a model to reconstruct the original text. It uses a standard seq2seq/NMT architecture with a bidirectional encoder (like BERT) and a left-to-right decoder (like GPT). In our work, we input the question and supporting documents to the BART model and use model outputs as answers.
## 4. Results
### 4.1 Model Training
#### 4.1.1 Retrierver
A pretrained [BERT(google/bert_uncased_L-8_H-768_A-12](https://huggingface.co/google/bert_uncased_L-8_H-768_A-12)) model is fine-tuned on the training set for 10 epochs.
> GPU: **RTX 2080S**, epoch: **26 min**, total: **4.5 hours**, checkpoint size: **930 MB**
The 128-dimensional embeddings of training/validation sets and all wiki_snippets are calculated and saved to binary files.
> GPU: **RTX 2080S**, training/validation sets: **4 hours**, wiki_snippets: **11 hours**
The top 10 related snippets are then retrieved as supporting documents using pre-calculated embeddings. Due to large memory requirement, this step is performed on a intel i7-9700K CPU with 48 GB DDR4 memory which takes **5 minutes**.
#### 4.1.2 Generator
A pretained [BART(bart-base)](https://huggingface.co/facebook/bart-base) model is fine-tuned on **all answers** in the training set with pre-retrieved supporting documents for 3 epochs. Due to large memory requirement, this step is performed on Google Colab with Colab Pro.
> GPU: **Colab Pro**, epoch: **4.5 hours**, total: **14 hours**, checkpoint size: **1.55 GB**
Since [BART(bart-large)](https://huggingface.co/facebook/bart-large) model contains 2.8x parameters (400M vs 140M) comparing to bart-base. We expected to get more reasonable outputs from that model. Therefore, two subsets of training set are used to fine-tune for 10 epochs: (1) 6633 questions and their **1st answers** in **Chemistry** category; (2) first 6633 questions and their **1st answers** from training set in **multiple** categories.
> GPU: **Colab Pro**, epoch: **28 min**, total: **5 hours**, checkpoint size: **4.54 GB**
### 4.2 Model Comparison
#### 4.2.1 The Absence of ROGUE Metric
As mentioned earlier, the ROGUE metric used in the evaluation of the model performance is problematic as it gives higher score to some seemingly nonsense generated answers while underestimating the top answers.
To make our life easier, we decide to evaluate the performance of a model based on our intuitive judgement.
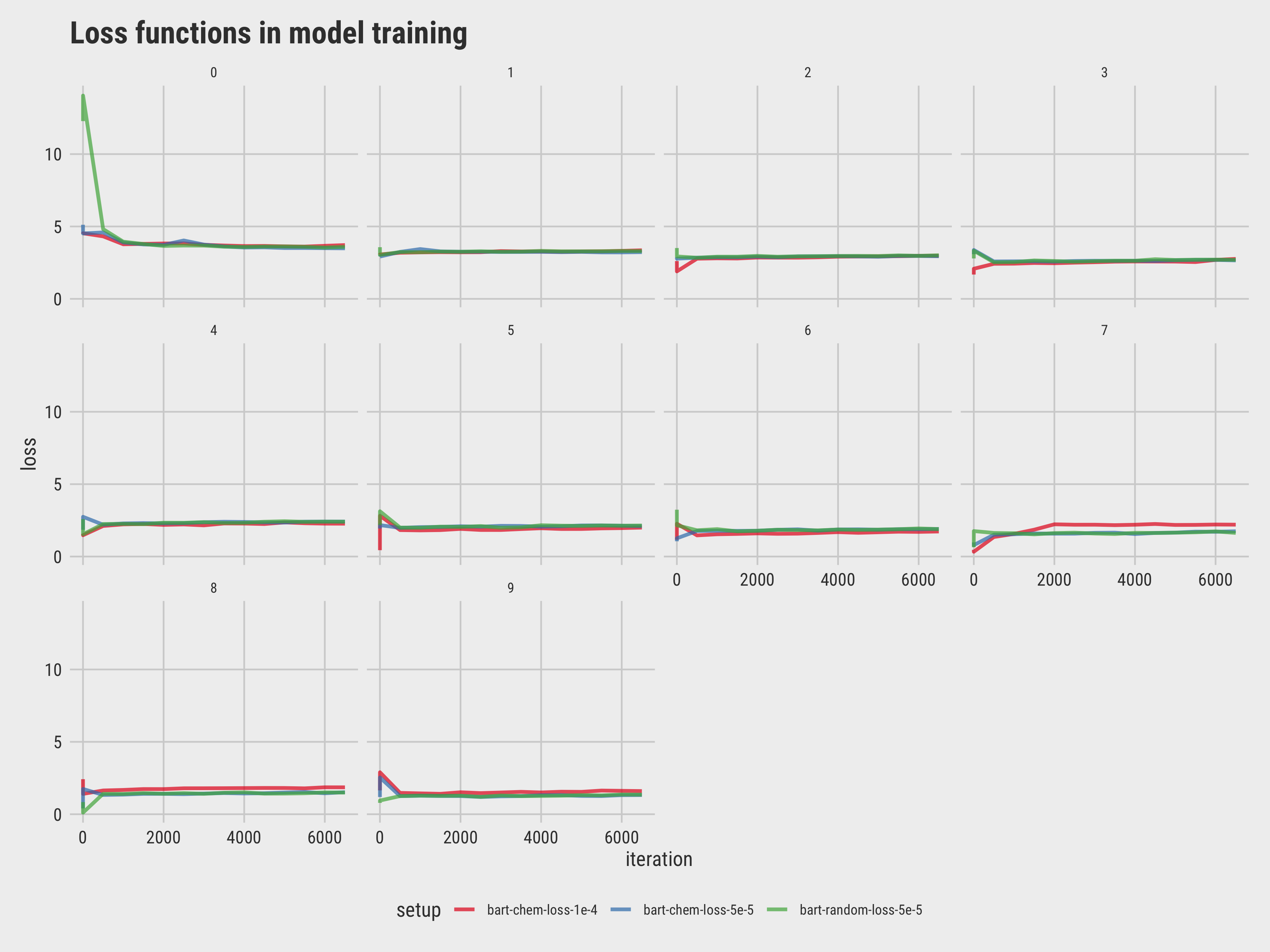
#### 4.2.2 Learning Rate Tuning
Note that changing settings of the retriever model requires us to re-calculate the 128d embeddings and re-train the generator model, so tuning of model settings are only performed on the generator model.
| model | dataset | size | learning rate | epochs | note |
| -------- | -------- | ------ | -------- | ----- | ----- |
| bart-base | full eli5c | 224088 | $2\times10^{-4}$ | 3 | success |
| bart-large | chemistry | 6633 | $2\times10^{-4}$ | 3 | fail at epoch0 |
| bart-large | chemistry | 6633 | $2\times10^{-3}$ | 10 | fail at epoch0 |
| bart-large | chemistry | 6633 | $2\times10^{-4}$ | 10 | fail at epoch0 |
| bart-large | chemistry | 6633 | $1\times10^{-4}$ | 10 | success until epoch9 |
| bart-large | chemistry | 6633 | $5\times10^{-5}$ | 10 | success |
| bart-large | random | 6633 | $1\times10^{-4}$ | 10 | fail at epoch0 |
| bart-large | random | 6633 | $5\times10^{-5}$ | 10 | success |
> We didn't capture the interim model training outputs of "failed" or overfitted models.
#### 4.2.3 Sample QAs
> [eli5c_reddit_test📊](https://docs.google.com/spreadsheets/d/1mJ2yCqXloo1ZbvOjOVjNDbyq_734XcfmZ7zRMeVnh5Y/edit?usp=sharing) (Sample answers from various models.)
## 5. Limitations and Reflections
- Due to the limitation of computational power, we cannot train the model with **both enough epochs and enough categories coverage.** So we either pick a smaller subset to run more epochs, or train the model on the complete dataset but with a few epochs. In contrast, Facebook's trial was conducted on **4 GPUs with 3 epochs (18 hours per epoch).**
- However, our selected models seem to have a decent performance with less training time and data.
- It's hard to measure how our model performs after all. No scientific evaluation metrics are involved. A possible solution is to use crowdsourcing human evaluation to grade the generated answers by correctness and some other linguistic dimensions. Again, this could be both time-consuming since the evaluators need extended time to learn some facts about the question themselves if they are no experts in those areas.
## 6. Demo Showcase
As proposed in the proposal, a prototype of open-ended question-answering website is hosted as a deliverable. The model behind it is `bart-large(dataset: random6633, learning rate: 5e-5)`, which has been uploaded to HuggingFace [jsgao/bart-eli5c](https://huggingface.co/jsgao/bart-eli5c). Although the model was trained with a small subset of the entire QA dataset, it actually delivers some seemingly meaningful answers.
**[Interactive Demo](http://eli5c.jsgao.me/)** (deployed on personal PC, if not work, try the [backup video demo📼](https://youtu.be/XGEBU51gr00).)
> - [GitHub Repository🐱](https://github.com/rexarski/ANLY580-final-project)
> - [Colab Playground🧪](https://drive.google.com/drive/folders/0APh2KjbUaOpxUk9PVA) (Need GU email or permission to access.).
> - [Working notebook📙](https://colab.research.google.com/drive/1NkD-meVW6U2I3WTETAER1LZ7G8db6L1D).
> - [jsgao/eli5_category📚](https://huggingface.co/datasets/jsgao/eli5_category)
***
## References
- [Introducing long-form question answering](https://ai.facebook.com/blog/longform-qa/)
- [Explain Anything Like I'm Five: A Model for Open Domain Long Form Question Answering](https://yjernite.github.io/lfqa.html)
- [ELI5](https://facebookresearch.github.io/ELI5/index.html)
- [GitHub repository](https://github.com/facebookresearch/ELI5)
- [Paper](https://research.fb.com/wp-content/uploads/2019/07/ELI5-Long-Form-Question-Answering.pdf)
- [Progress and Challenges in Long-Form Open-Domain Question Answering](https://ai.googleblog.com/2021/03/progress-and-challenges-in-long-form.html)
- [Hurdles to Progress in Long-form Question Answering](https://arxiv.org/abs/2103.06332)
- [wiki40b](https://huggingface.co/datasets/wiki40b), clean-up text for 40+ Wikipedia languages editions of pages correspond to entities.
 Sign in with Wallet
Sign in with Wallet







