# Langchain
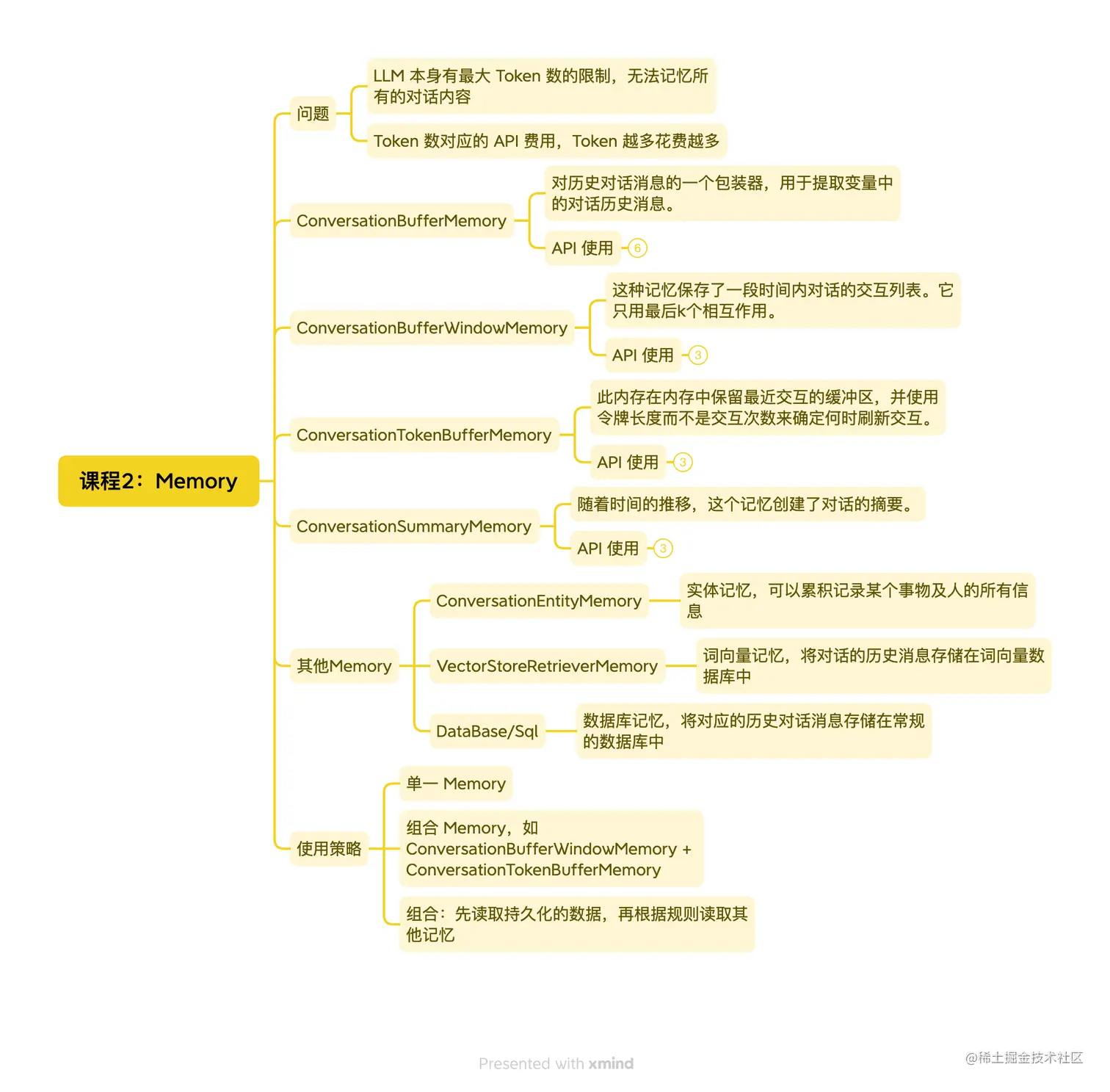
## Conversation & Memory
### ConversationBufferMemory
可以記錄所有對話並傳遞至下一次對話中

### ConversationSummaryMemory
會將對話紀錄總結後傳遞至下一次對話中

### ConversationBufferWindowMemory
可以將指定次數的最新對話傳遞至下一次對話中
`# We set a low k=2, to only keep the last 2 interactions in memory
window_memory = ConversationBufferWindowMemory(k=2)
`
### ConversationSummaryBufferMemory
"It keeps a buffer of recent interactions in memory, but rather than just completely flushing old interactions it compiles them into a summary and uses both"
### Conversation Knowledge Graph : ConversationKGMemory
將對話中的重要資料透過知識圖譜的方式進行儲存,並傳遞至下一次對話中

### Entity Memory
Entity memory remembers given facts about specific entities in a conversation. It extracts information on entities (using an LLM) and builds up its knowledge about that entity over time (also using an LLM).
實體記憶,可以累積紀錄某個人事物的實體訊息:每次與LM溝通時會抓取該input的entity,並累積儲存進Entity的memory中。

picture from https://juejin.cn/post/7243252896392839225
## PAL
### PAL : Program-aided Language
透過prompt先產生python function,再執行該function取得回應後回傳

## Summarization: load_summarize_chain
### Doc 處理方法
#### 1. Stuff
#### 適用於很多小文檔,將所有doc及Prompt一次全部丟入LM

#### 2. Refine
#### Refine 文檔鏈透過循環輸入文件並迭代更新其答案來建立回應。對於每個文檔,它將所有非文檔輸入、當前文檔和最新的中間答案傳遞給 LLM 鏈以獲得新答案。

#### 3. Map Reduce
#### MapReduce 是一種分散式計算框架,用於處理大規模資料集的並行計算。它包含兩個主要步驟:Map 和 Reduce。Map 步驟將輸入資料集映射到中間結果,然後 Reduce 步驟將中間結果進一步整合為最終結果。MapReduce 的設計目的是有效處理大數據,並實現分散式計算的高效性。

#### 4. Map Rerank
#### MapRerank 是一種搜尋引擎優化技術,用於改善搜索結果的排序和排名。它基於傳統的搜索引擎模型,但對搜索結果進行了後續處理和重新排名,以提供更精確和相關的搜索結果。MapRerank 通常利用機器學習、自然語言處理和用戶行為分析等技術來改進搜索結果的質量和用戶體驗。

### Splitting and summarizing in a single chain
#### For convenience, we can wrap both the text splitting of our long document and summarizing in a single `AnalyzeDocumentsChain`, 此功能簡單快速,一個function包到好

### LLMSummarizationCheckerChain
#### 此為一種特定方法,將已知knowledge取得摘要或是重點後再次向LLM確認其正確性,若有錯誤則透過LLM進行修改。
## Agents
### 可以定義各種"代理人(工具)"來回答特定類型的問題
## Safety
### Constitutional chain: https://python.langchain.com/docs/guides/safety/constitutional_chain
#### 可以將LM的response再次放入constitutional chain,即可套用自定義的principle來修正response,給出預期的回覆。ex: 修正不符合道德規範的言論、回覆合理合法的回應。
## Caching
### Embeddings can be stored or temporarily cached to avoid needing to recompute them.
https://python.langchain.com/docs/modules/data_connection/text_embedding/caching_embeddings
## VectorStore in Retrieval
https://python.langchain.com/docs/modules/data_connection/vectorstores/
#### 儲存和搜尋非結構化資料的最常見方法之一是嵌入它並儲存產生的embedding vectors,然後在查詢時嵌入非結構化查詢並檢索與嵌入查詢「最相似」的embedding vectors。向量儲存負責儲存嵌入資料並為您執行向量搜尋。
#### tools:
1. Chroma
2. FAISS
3. Lance

### Asynchronous operations
#### Qdrant: 為一種可於**local端架設**的向量資料庫(https://qdrant.tech/),可以將向量存進去Qdrant,過程中會有IO操作,可以透過fastapi來達成異步操作。
## Tools
### Custom tools:
#### 可以自定義tools(for specific question)來供LM使用
https://python.langchain.com/docs/modules/agents/tools/custom_tools
https://youtu.be/biS8G8x8DdA?si=84ByXBQ9elItpo_T
### Retrieval QA Over Multiple Files with ChromaDB