---
tags: linux2022, linux
---
# 2022q1 Homework6 (ktcp)
contributed by < [Julian-Chu](https://github.com/Julian-Chu) >
> [K08: ktcp](https://hackmd.io/@sysprog/linux2022-ktcp)
## 自我檢查清單
### 參照 [Linux 核心模組掛載機制](https://hackmd.io/@sysprog/linux-kernel-module),解釋 `$ sudo insmod khttpd.ko port=1999` 這命令是如何讓 port=1999 傳遞到核心,作為核心模組初始化的參數呢?
首先會看到 main.c 裡面對 port 參數進行宣告跟初始化
```c
static ushort port = DEFAULT_PORT;
module_param(port, ushort, S_IRUGO);
```
`module_param` 的細節可以閱讀 [Linux 核心模組掛載機制](https://hackmd.io/@sysprog/linux-kernel-module) 或是展開以下的程式碼
:::spoiler linux/moduleparam.h
```c
#define module_param(name, type, perm) \
module_param_named(name, name, type, perm)
#define module_param_named(name, value, type, perm) \
param_check_##type(name, &(value)); \
module_param_cb(name, ¶m_ops_##type, &value, perm); \
__MODULE_PARM_TYPE(name, #type)
/**
* module_param_cb - general callback for a module/cmdline parameter
* @name: a valid C identifier which is the parameter name.
* @ops: the set & get operations for this parameter.
* @arg: args for @ops
* @perm: visibility in sysfs.
*
* The ops can have NULL set or get functions.
*/
#define module_param_cb(name, ops, arg, perm) \
__module_param_call(MODULE_PARAM_PREFIX, name, ops, arg, perm, -1, 0)
#define __MODULE_PARM_TYPE(name, _type) \
__MODULE_INFO(parmtype, name##type, #name ":" _type)
#define __MODULE_INFO(tag, name, info) \
static const char __UNIQUE_ID(name)[] \
__used __section(".modinfo") __aligned(1) \
= __MODULE_INFO_PREFIX __stringify(tag) "=" info
```
:::
\
巨集完全展開後如下:
```c
static inline unsigned short __always_unused *__check_port(void)
{
return (&(port));
};
static const char __param_str_port[] = KBUILD_MODNAME
"."
"port";
static struct kernel_param const __param_port __used __section("__param")
__aligned(__alignof__(struct kernel_param)) = {
__param_str_port,
THIS_MODULE,
¶m_ops_ushort,
VERIFY_OCTAL_PERMISSIONS(S_IRUGO),
-1,
0,
{&port}};
static const char __UNIQUE_ID(porttype)[]__used __section(".modinfo")__aligned(1)=KBUILD_MODNAME "." __stringify(parmtype)"=" "port" ":" "ushort"
```
在 ELF __param section 宣告型態為 kernel_param 的變數, 同時也在 .modinfo section 加入 `parmtyp=port:ushort` 的資訊
利用 objdump 可以看到不只是 port 還有 backlog 也是列在其中
```shell
$ objdump -s khttpd.ko
...
Contents of section .modinfo:
0000 76657273 696f6e3d 302e3100 64657363 version=0.1.desc
0010 72697074 696f6e3d 696e2d6b 65726e65 ription=in-kerne
0020 6c204854 54502064 61656d6f 6e006175 l HTTP daemon.au
0030 74686f72 3d4e6174 696f6e61 6c204368 thor=National Ch
0040 656e6720 4b756e67 20556e69 76657273 eng Kung Univers
0050 6974792c 20546169 77616e00 6c696365 ity, Taiwan.lice
0060 6e73653d 4475616c 204d4954 2f47504c nse=Dual MIT/GPL
0070 00706172 6d747970 653d6261 636b6c6f .parmtype=backlo
0080 673a7573 686f7274 00706172 6d747970 g:ushort.parmtyp
0090 653d706f 72743a75 73686f72 74007372 e=port:ushort.sr
00a0 63766572 73696f6e 3d414445 31304544 cversion=ADE10ED
00b0 37313234 43443046 30313133 35363438 7124CD0F01135648
00c0 00646570 656e6473 3d007265 74706f6c .depends=.retpol
00d0 696e653d 59006e61 6d653d6b 68747470 ine=Y.name=khttp
00e0 64007665 726d6167 69633d35 2e342e30 d.vermagic=5.4.0
00f0 2d313034 2d67656e 65726963 20534d50 -104-generic SMP
0100 206d6f64 5f756e6c 6f616420 6d6f6476 mod_unload modv
0110 65727369 6f6e7320 00 ersions .
```
接著觀察 `load_module`
```c
https://elixir.bootlin.com/linux/v5.10.4/source/kernel/module.c#L3832
/* Allocate and load the module: note that size of section 0 is always
zero, and we rely on this for optional sections. */
static int load_module(struct load_info *info, const char __user *uargs,
int flags)
{
struct module *mod;
long err = 0;
char *after_dashes;
err = elf_header_check(info);
...
// 從 elf 資訊讀入 info
// ELF header (Ehdr)
// Section header (Shdr)
err = setup_load_info(info, flags);
...
err = rewrite_section_headers(info, flags);
...
/* Check module struct version now, before we try to use module. */
if (!check_modstruct_version(info, info->mod)) {
err = -ENOEXEC;
goto free_copy;
}
// 利用 info 產生 mod
/* Figure out module layout, and allocate all the memory. */
mod = layout_and_allocate(info, flags);
...
audit_log_kern_module(mod->name);
/* Reserve our place in the list. */
err = add_unformed_module(mod);
...
/* To avoid stressing percpu allocator, do this once we're unique. */
err = percpu_modalloc(mod, info);
/* Now module is in final location, initialize linked lists, etc. */
err = module_unload_init(mod);
...
init_param_lock(mod);
// 從 elf 的 section 讀入資料
// kernel params 也在這個方法讀入
/* Now we've got everything in the final locations, we can
* find optional sections. */
err = find_module_sections(mod, info);
...
err = check_module_license_and_versions(mod);
...
/* Set up MODINFO_ATTR fields */
setup_modinfo(mod, info);
/* Fix up syms, so that st_value is a pointer to location. */
err = simplify_symbols(mod, info);
...
err = apply_relocations(mod, info);
...
err = post_relocation(mod, info);
...
flush_module_icache(mod);
/* Now copy in args */
mod->args = strndup_user(uargs, ~0UL >> 1);
...
dynamic_debug_setup(mod, info->debug, info->num_debug);
/* Ftrace init must be called in the MODULE_STATE_UNFORMED state */
ftrace_module_init(mod);
/* Finally it's fully formed, ready to start executing. */
err = complete_formation(mod, info);
...
err = prepare_coming_module(mod);
...
// 在這步針對 kernel param 跟 args 做比對, 有比對成功就將 kernel param 的值更新
/* Module is ready to execute: parsing args may do that. */
after_dashes = parse_args(mod->name, mod->args, mod->kp, mod->num_kp,
-32768, 32767, mod,
unknown_module_param_cb);
if (IS_ERR(after_dashes)) {
err = PTR_ERR(after_dashes);
goto coming_cleanup;
} else if (after_dashes) {
pr_warn("%s: parameters '%s' after `--' ignored\n",
mod->name, after_dashes);
}
/* Link in to sysfs. */
err = mod_sysfs_setup(mod, info, mod->kp, mod->num_kp);
...
/* Get rid of temporary copy. */
free_copy(info);
/* Done! */
trace_module_load(mod);
return do_init_module(mod);
...
}
```
:::spoiler parse_args
```c
https://elixir.bootlin.com/linux/v5.10.4/source/kernel/params.c#L161
/* Args looks like "foo=bar,bar2 baz=fuz wiz". */
char *parse_args(const char *doing,
char *args,
const struct kernel_param *params,
unsigned num,
s16 min_level,
s16 max_level,
void *arg,
int (*unknown)(char *param, char *val,
const char *doing, void *arg))
{
char *param, *val, *err = NULL;
/* Chew leading spaces */
args = skip_spaces(args);
if (*args)
pr_debug("doing %s, parsing ARGS: '%s'\n", doing, args);
while (*args) {
int ret;
int irq_was_disabled;
args = next_arg(args, ¶m, &val);
/* Stop at -- */
if (!val && strcmp(param, "--") == 0)
return err ?: args;
irq_was_disabled = irqs_disabled();
ret = parse_one(param, val, doing, params, num,
min_level, max_level, arg, unknown);
if (irq_was_disabled && !irqs_disabled())
pr_warn("%s: option '%s' enabled irq's!\n",
doing, param);
switch (ret) {
case 0:
continue;
case -ENOENT:
pr_err("%s: Unknown parameter `%s'\n", doing, param);
break;
case -ENOSPC:
pr_err("%s: `%s' too large for parameter `%s'\n",
doing, val ?: "", param);
break;
default:
pr_err("%s: `%s' invalid for parameter `%s'\n",
doing, val ?: "", param);
break;
}
err = ERR_PTR(ret);
}
return err;
}
static int parse_one(char *param,
char *val,
const char *doing,
const struct kernel_param *params,
unsigned num_params,
s16 min_level,
s16 max_level,
void *arg,
int (*handle_unknown)(char *param, char *val,
const char *doing, void *arg))
{
unsigned int i;
int err;
/* Find parameter */
for (i = 0; i < num_params; i++) {
if (parameq(param, params[i].name)) {
if (params[i].level < min_level
|| params[i].level > max_level)
return 0;
/* No one handled NULL, so do it here. */
if (!val &&
!(params[i].ops->flags & KERNEL_PARAM_OPS_FL_NOARG))
return -EINVAL;
pr_debug("handling %s with %p\n", param,
params[i].ops->set);
kernel_param_lock(params[i].mod);
if (param_check_unsafe(¶ms[i]))
err = params[i].ops->set(val, ¶ms[i]);
else
err = -EPERM;
kernel_param_unlock(params[i].mod);
return err;
}
}
if (handle_unknown) {
pr_debug("doing %s: %s='%s'\n", doing, param, val);
return handle_unknown(param, val, doing, arg);
}
pr_debug("Unknown argument '%s'\n", param);
return -ENOENT;
}
```
:::
\
簡略流程如下:
`module_param` 將相關的參數放入到 ELF 的 __param section -> 讀取 ELF `__param` section, 取得 module 的 kernel param -> 與 args 做比對, 更新數值
---
### 參照 [CS:APP 第 11 章](https://hackmd.io/s/ByPlLNaTG) ,給定的 kHTTPd 和書中的 web 伺服器有哪些流程是一致?又有什麼是你認為 kHTTPd 可改進的部分?

khttpd 的主要流程如下
```c
khttpd_init
-> open_listen_socket
-> kernel_bind
-> kernel_listen
-> kthread_run(http_server_daemon)
-> http_server_daemon
-> kernel_accept
-> http_server_worker
// RECV_BUFFER_SIZE = 4096
-> http_server_recv
-> kernel_recvmsg (size 4096)
-> http_parser_execute
-> http_parser_callback_message_complete
-> http_server_response
-> http_server_send
-> kernel_sendmsg
khttpd_exit
-> kthread_stop(http_server)
-> close_listen_socket
```
比對 CS:APP 主要的流程 socket -> bind -> listen -> accept 看起來是一致的, 只是使用的 API 不同。
改進:針對每一個 request 都需要新建一個 kthread 的成本可能太大, 也許可以嘗試 worker pool
```c
int kernel_accept(struct socket * sock, struct socket ** newsock, int flags)
Returns 0 or an error.
int accept(int sockfd, struct sockaddr *restrict addr, socklen_t *restrict addrlen);
On success, these system calls return a file descriptor for the
accepted socket (a nonnegative integer). On error, -1 is
returned, errno is set to indicate the error, and addrlen is left unchanged.
```
:::warning
Q: kernel network 相關的 api 都是直接使用 socket, 並沒有提到 file descriptor, 為什麼會有這種區別?
> 這是 Linux 沒有貫徹 UNIX 設計哲學 "Everything is a file" 的案例:network device 是過於特別,以至於既非 character device 也非 block device,要用完全不同的方式來存取。
> :notes: jserv
:::
---
### `htstress.c` 用到 [epoll](https://man7.org/linux/man-pages/man7/epoll.7.html) 系統呼叫,其作用為何?這樣的 HTTP 效能分析工具原理為何?
main function 主要處理初始化參數、新建 worker(pthread)、印出結果。
可以看到許多的參數可以選擇
```c
int main(int argc, char *argv[])
{
// init signal handler
// init socket
// parse args
// parse URL
// prepare request buffer
...
/* run test */
for (int n = 0; n < num_threads - 1; ++n)
pthread_create(&useless_thread, 0, &worker, 0);
worker(0);
// print result
....
}
```
epoll 主要使用在 worker 跟 init_conn 之中。 而 epoll 本身是用以監聽 file descriptor,在 htstress 中,主要用以監聽 socket FD 然後根據不同的事件像是 EPOLLIN、 EPOLLOUT 來作相對應的處理 request 和 response。 簡略的處理流程如下圖:

:::spoiler worker and init_conn 程式碼
```c
struct econn {
int fd;
size_t offs;
int flags;
};
static void *worker(void *arg)
{
int ret, nevts;
struct epoll_event evts[MAX_EVENTS];
char inbuf[INBUFSIZE];
struct econn ecs[concurrency], *ec;
(void) arg;
int efd = epoll_create(concurrency);
...
// each worker has concurrency conns
for (int n = 0; n < concurrency; ++n)
init_conn(efd, ecs + n);
for (;;) {
do {
nevts = epoll_wait(efd, evts, sizeof(evts) / sizeof(evts[0]), -1);
} while (!exit_i && nevts < 0 && errno == EINTR);
...
for (int n = 0; n < nevts; ++n) {
ec = (struct econn *) evts[n].data.ptr;
....
if (evts[n].events & EPOLLERR) {...}
if (evts[n].events & EPOLLHUP) {...}
if (evts[n].events & EPOLLOUT) {
ret = send(ec->fd, outbuf + ec->offs, outbufsize - ec->offs, 0);
...
if (ret > 0) {
if (debug & HTTP_REQUEST_DEBUG)
// 2: stderr
write(2, outbuf + ec->offs, outbufsize - ec->offs);
ec->offs += ret;
/* write done? schedule read */
if (ec->offs == outbufsize) {
evts[n].events = EPOLLIN;
evts[n].data.ptr = ec;
ec->offs = 0;
if (epoll_ctl(efd, EPOLL_CTL_MOD, ec->fd, evts + n)) {...}
}
}
} else if (evts[n].events & EPOLLIN) {
for (;;) {
ret = recv(ec->fd, inbuf, sizeof(inbuf), 0);
...
}
if (!ret) {
close(ec->fd);
...
init_conn(efd, ec);
}
}
}
}
}
static void init_conn(int efd, struct econn *ec)
{
int ret;
ec->fd = socket(sss.ss_family, SOCK_STREAM, 0);
ec->offs = 0;
ec->flags = 0;
if (ec->fd == -1) {
perror("socket() failed");
exit(1);
}
// manipulate fd, F_SETFL: set file status flags.
/*
If the O_NONBLOCK flag is not enabled, then the
system call is blocked until the lock is removed or converted to
a mode that is compatible with the access. If the O_NONBLOCK
flag is enabled, then the system call fails with the error
EAGAIN.
*/
fcntl(ec->fd, F_SETFL, O_NONBLOCK);
do {
// not accept(server), so no connfd.
// If the connection or binding succeeds, zero is returned. On
// error, -1 is returned, and errno is set to indicate the error.
ret = connect(ec->fd, (struct sockaddr *) &sss, sssln);
} while (ret && errno == EAGAIN);
if (ret && errno != EINPROGRESS) {
perror("connect() failed");
exit(1);
}
struct epoll_event evt = {
.events = EPOLLOUT, .data.ptr = ec,
};
// add econn->fd into epoll fd
if (epoll_ctl(efd, EPOLL_CTL_ADD, ec->fd, &evt)) {
perror("epoll_ctl");
exit(1);
}
}
```
:::
\
這樣的性能測試工具主要需要考量的點如下:
- high throughput 短時間內可以發出大量的 request,
- low latency: 發出 request 到可以處理 response 完的時間要短於 server 回傳 response 的時間點
- 可以提供各種參數調整測試工具在不同電腦的性能
- 因為是由 client 做的短時間的測試, 可以盡可能使用 CPU 資源
- 穩定: 重複測試下的結果浮動不大
:::success
思考:
* htstress 的 epoll 程式碼中, 使用 level trigger 而不是 edge trigger, 性能考量應該是 ET 較佳,但查看 wrk 的程式碼也是使用 LT, client 的考量是否與 server 不同, 或是性能測試工具需求的不同?
:::
目前的推論是使用場景不同,考慮到 ET 只有在狀態變化的狀態下才會觸發, 所以 ET 的優勢在於可以減少 epoll_wait 的返回 fd, 對 epoll_wait 迴圈的性能有所提升, 對 epoll_ctl 的呼叫就會變少,但並非時間複雜度上像是 O(n) -> O(log n)的變化,只是單純 n 的減少。此外 ET 也會比 LT 少掉 EPOLLIN/EPOLLOUT 的切換。
但是除了 epoll loop 本身外還需要考慮另一方面, 由於 ET 觸發一次後需要等到資料清空後才能在觸發, 所以拿到 fd 後就必需一口氣把 buffer 上的資料處理完, 單執行緒不需長時間等待資料的情況跟 LT 相近, 需要等待資料的情況可能會有重複嘗試讀取或是阻塞的情況在單一 fd 上, 多執行緒且採用 reactor pattern 的情況, 將讀寫的任務分配到其他執行緒上, 採用 ET 可以得到較為高效的 event loop。
回到 htstress 的情況, 單執行緒設計加上只有監聽 256 個事件,配合 LT 已經可以滿足性能需求, 程式碼實作上也較為簡單,沒有採用 ET 的必要性
:::success
* 爲何同一個 socket fd 需要更動 EPOLLOUT -> EPOLLIN, 同時監聽是否對性能有影響?
:::
在Level trigger 模式下,EPOLLOUT 會持續觸發,需要變更監聽的事件才能避免這個問題
:::success
* htsress 的 send(EPOLLOUT) 與 recv(EPOLLIN) 處理方式的不同? send 需要靠 epoll loop 完成資料的分段寫入, 但 read 卻可以一次把資料讀完?
:::
read 讀出的 buffer 不會被儲存在 econn 上帶到下一個 epoll , 為了辨別 4xx 和 5xx 最簡單的方式就是在同一個 epoll 迴圈內讀完 buffer 後辨別,不需要額外的儲存空間
:::spoiler send and recv
```c
if (evts[n].events & EPOLLOUT) {
ret = send(ec->fd, outbuf + ec->offs, outbufsize - ec->offs, 0);
if (ret == -1 && errno != EAGAIN) {
/* TODO: something better than this */
perror("send");
exit(1);
}
if (ret > 0) {
if (debug & HTTP_REQUEST_DEBUG)
// 2: stderr
write(2, outbuf + ec->offs, outbufsize - ec->offs);
ec->offs += ret;
/* write done? schedule read */
if (ec->offs == outbufsize) {
evts[n].events = EPOLLIN;
evts[n].data.ptr = ec;
ec->offs = 0;
if (epoll_ctl(efd, EPOLL_CTL_MOD, ec->fd, evts + n)) {
perror("epoll_ctl");
exit(1);
}
}
}
} else if (evts[n].events & EPOLLIN) {
for (;;) {
ret = recv(ec->fd, inbuf, sizeof(inbuf), 0);
if (ret == -1 && errno != EAGAIN) {
perror("recv");
exit(1);
}
if (ret <= 0)
break;
if (ec->offs <= 9 && ec->offs + ret > 10) {
char c = inbuf[9 - ec->offs];
if (c == '4' || c == '5')
ec->flags |= BAD_REQUEST;
}
if (debug & HTTP_RESPONSE_DEBUG)
write(2, inbuf, ret);
ec->offs += ret;
}
if (!ret) {
close(ec->fd);
int m = atomic_fetch_add(&num_requests, 1);
if (max_requests && (m + 1 > (int) max_requests))
atomic_fetch_sub(&num_requests, 1);
else if (ec->flags & BAD_REQUEST)
atomic_fetch_add(&bad_requests, 1);
else
atomic_fetch_add(&good_requests, 1);
if (max_requests && (m + 1 >= (int) max_requests)) {
end_time();
return NULL;
}
if (ticks && m % ticks == 0)
printf("%d requests\n", m);
init_conn(efd, ec);
}
}
```
:::
---
### 給定的 `kecho` 已使用 CMWQ,請陳述其優勢和用法
優勢:
解耦 kthread(work thread) 與 work queue, 開發者可以依據不同的設定建立需要 workqueue, 簡化開發流程, 大多數的場景都不需考慮自行管理 kthread(work thread) 或是自行開發 work queue 導致不必要的 context switch 和 dead locking 的風險.
用法:
- 利用 alloc_workqueue 根據需求新建 workqueue
- queue_work 將 work_struct 放入 workqueue
- destroy_workqueue
---
### 核心文件 [Concurrency Managed Workqueue (cmwq)](https://www.kernel.org/doc/html/latest/core-api/workqueue.html) 提到 “The original create_*workqueue() functions are deprecated and scheduled for removal”,請參閱 Linux 核心的 git log (不要用 Google 搜尋!),揣摩 Linux 核心開發者的考量
根據 [git log](https://github.com/torvalds/linux/commit/d320c03830b17af64e4547075003b1eeb274bc6c) 的紀錄當時是將 `__create_workqueue` 更名爲 `alloc_workqueue` 但參數在當時並沒有更動,而在[現行版本](https://github.com/torvalds/linux/blob/master/include/linux/workqueue.h#L403)可看到
`create_workqueue`
`create_freezeable_workqueue`
`create_singlethread_workqueue`
時至今日仍然沒有移除。
猜想:核心開發者提供一個 public 的 API 可以讓使用者做細節跟客製化的控制, 但是已經有許多的地方仍然使用舊有的 API,全部都一口氣修改可能會造成許多問題,所以能做的就是保持現有 API 的狀況下,鼓勵開發者使用新的 API, 提供一個過渡期讓開發者可以修改現有的程式碼, 而不會造成太大的衝擊
> There are two worker-pools, one for normal work items and the other for high priority ones, for each possible CPU and some extra worker-pools to serve work items queued on unbound workqueues - the number of these backing pools is dynamic.
>
>Subsystems and drivers can create and queue work items through special workqueue API functions as they see fit. They can influence some aspects of the way the work items are executed by setting flags on the workqueue they are putting the work item on. These flags include things like CPU locality, concurrency limits, priority and more. To get a detailed overview refer to the API description of alloc_workqueue() below.
>
>When a work item is queued to a workqueue, the target worker-pool is determined according to the queue parameters and workqueue attributes and appended on the shared worklist of the worker-pool. For example, unless specifically overridden, a work item of a bound workqueue will be queued on the worklist of either normal or highpri worker-pool that is associated to the CPU the issuer is running on.
---
### 解釋 `user-echo-server` 運作原理,特別是 `epoll` 系統呼叫的使用
user-echo-server 的主要流程與 CS:APP 的 echo server 類似, 加上 epoll 用來處理多個連線
```c
// client 主要用來記錄 conn fd 跟對應的 address, 用於 log
// 利用 singly linked list 增刪查
typedef struct client_list_s {
int client;
char *addr;
struct client_list_s *next;
} client_list_t;
```
epoll 系統呼叫主要用於監聽 listenfd 與 connfd
大致流程如下
```c
// 新建 epollfd
epoll_create(EPOLL_SIZE)
// 將 listenfd(設爲 O_NONBLOCKING) 加入 epollfd 中,設定為監聽 EPOLLIN 跟 Edge trigger
-> epoll_ctl(epoll_fd, EPOLL_CTL_ADD, listener, &ev)
// 監聽 listenfd(此時尚未有 connfd)
-> epoll_wait(epoll_fd, events, EPOLL_SIZE, EPOLL_RUN_TIMEOUT)
// - listenfd ready
// - accept 創建 connfd,
// - 把ev.data.fd 設定成 connfd
// 把 connfd(設爲 O_NONBLOCKING) 加入 epoll 監聽 EPOLLIN 跟 Edge trigger
-> epoll_ctl(epoll_fd, EPOLL_CTL_ADD, client, &ev)
// 監聽 listenfd 和 connfd
-> epoll_wait(epoll_fd, events, EPOLL_SIZE, EPOLL_RUN_TIMEOUT)
// 情況 1: conn fd ready
// rev message and close connfd
-> handle_message_from_client(events[i].data.fd, &list)
// 情況 2: 重複上面新建 connfd 並加入 epoll 的流程
```
---
### 是否理解 bench 原理,能否比較 `kecho` 和 `user-echo-server` 表現?佐以製圖
bench 的主要原理涵蓋在 `bench` 和 `bench_worker` 兩個函式中, 對比 htstress 在固定數量的 worker 中使用 epoll 內處理所有連線, bench 針對每一個連線都會使用新建一個 pthread 來處理相關的連線與請求
```c
static void bench(void)
{
// 執行 BENCH_COUNT 次數的測試
for (int i = 0; i < BENCH_COUNT; i++) {
ready = false;
// 每次的測試新建 MAX_THREAD 個 pthread
for (int i = 0; i < MAX_THREAD; i++) {
if (pthread_create(&pt[i], NULL, bench_worker, NULL)) {
puts("thread creation failed");
exit(-1);
}
}
// 更改 ready 狀態前加鎖, 若此時還有 pthread 新建中則會阻塞在此, 等待所有 pthread 新建完成, 但有此行程式碼比 pthread 先拿到鎖的風險?
pthread_mutex_lock(&worker_lock);
ready = true;
// 廣播對所有被 worker_wait 阻塞的 pthread 繼續動作
/* all workers are ready, let's start bombing kecho */
pthread_cond_broadcast(&worker_wait);
pthread_mutex_unlock(&worker_lock);
/* waiting for all workers to finish the measurement */
for (int x = 0; x < MAX_THREAD; x++)
pthread_join(pt[x], NULL);
idx = 0;
}
for (int i = 0; i < MAX_THREAD; i++)
fprintf(bench_fd, "%d %ld\n", i, time_res[i] /= BENCH_COUNT);
}
static void *bench_worker(__attribute__((unused)))
{
int sock_fd;
char dummy[MAX_MSG_LEN];
struct timeval start, end;
// 上鎖確保此時 ready 不會被更動
/* wait until all workers created */
pthread_mutex_lock(&worker_lock);
while (!ready)
// 阻塞等到廣播後繼續流程
if (pthread_cond_wait(&worker_wait, &worker_lock)) {
puts("pthread_cond_wait failed");
exit(-1);
}
pthread_mutex_unlock(&worker_lock);
sock_fd = socket(AF_INET, SOCK_STREAM, 0);
if (sock_fd == -1) {
perror("socket");
exit(-1);
}
struct sockaddr_in info = {
.sin_family = PF_INET,
.sin_addr.s_addr = inet_addr(TARGET_HOST),
.sin_port = htons(TARGET_PORT),
};
if (connect(sock_fd, (struct sockaddr *) &info, sizeof(info)) == -1) {
perror("connect");
exit(-1);
}
gettimeofday(&start, NULL);
send(sock_fd, msg_dum, strlen(msg_dum), 0);
recv(sock_fd, dummy, MAX_MSG_LEN, 0);
gettimeofday(&end, NULL);
shutdown(sock_fd, SHUT_RDWR);
close(sock_fd);
if (strncmp(msg_dum, dummy, strlen(msg_dum))) {
puts("echo message validation failed");
exit(-1);
}
pthread_mutex_lock(&res_lock);
time_res[idx++] += time_diff_us(&start, &end);
pthread_mutex_unlock(&res_lock);
pthread_exit(NULL);
}
```
#### 比較
CMWQ實作

尚未綁定 CPU

```shell
isolcpus=0
taskset -c 0 ./user-echo-server
```

- user-echo-server 比較綁定 CPU 與否的結果, 明顯頻繁切換 CPU 的成本不低
- 嘗試切回使用 kthread 實作的 kecho, 不過 bench 遇到問題,所以參照 [kecho pull request #1](https://github.com/sysprog21/kecho/pull/1#issue-569377988) 的圖表作為比較, 在給定 `1000 threads` 的條件下 kthread 實作與 user-echo-server 都會有隨著 thread 上升性能下滑的趨勢, 性能中間的落差可能爲 user space 與 kernel space 之間資料拷貝的成本
kthread 實作

- 比較 kthread 與 cmwq 的性能差異, kthread 實作版本會對每一個 conn socket 新建一個 kthread, 相較於 cmwq 複用綁定 CPU 的 worker kthread, 會額外增加 kthread 的新建、排程、銷燬、以及 context switch 的成本
- 增加 bench 設定 thread 的數量到 10000,cmwq 的性能仍穩定
```shell
#define MAX_THREAD 10000
$ sudo sysctl net.core.somaxconn=10000
$ sudo sysctl net.ipv4.tcp_max_syn_backlog=10000
$ ulimit -u unlimited
$ sudo insmod kecho.ko backlog=10000
```

---
### 解釋 `drop-tcp-socket` 核心模組運作原理。`TIME-WAIT sockets` 又是什麼
#### 嘗試解釋 `drop-tcp-socket` 核心模組運作原理
- 模組載入,取得 namespace specific data,
- `echo "127.0.0.1:36986 127.0.0.1:12345" | sudo tee /proc/net/drop_tcp_sock`
- open: 初始化 file
- write:
把 "127.0.0.1:36986 127.0.0.1:12345" 寫入 network device
- release:
-> droptcp_process : 根據寫入的字串解析出 socket 的 source(IP+Port) 跟 destination(IP+Port)
-> droptcp_drop : 根據解析出的 source 與 destination 查表該 network namespace 下的 socket,如果狀態是 TIME_WAIT 就呼叫 `inet_twsk_deschedule_put` 殺掉 socket
```c
// 定義 proc file 的操作 ps: Linux 5.6 以前的版本會使用 file_operations
static const struct proc_ops droptcp_proc_fops = {
.proc_open = droptcp_proc_open,
.proc_write = droptcp_proc_write,
.proc_release = droptcp_proc_release,
};
// 設定 per network subsystem 的 callback 來新建或清理 proc file(/proc/net/drop_tcp_sock)
// Some network devices and some network subsystems should have
// network namespaces specific data.
// In order to enable this, a structure named pernet_operations was added;
// this structure includes an init and exit callback
static struct pernet_operations droptcp_pernet_ops = {
.init = droptcp_pernet_init,
.exit = droptcp_pernet_exit,
.id = &droptcp_pernet_id,
.size = sizeof(struct droptcp_pernet),
};
module_init:
drop_tcp_init
// Network subsystems that need network-namespace-specific data should call
// register_pernet_subsys() when the subsystem is initialized
-> register_pernet_subsys(&droptcp_pernet_ops)
// 執行 per network namespace operation 的初始化
-> droptcp_pernet_init
// 取得 namespace
-> net_generic
// 新建 proc/net/drop_tcp_sock
-> proc_create_data(DROPTCP_PDE_NAME, 0600, net->proc_net,
&droptcp_proc_fops, dt);
-> droptcp_pernet_exit
-> net_generic
-> remove_proc_entry(DROPTCP_PDE_NAME, net->proc_net);
module_exit:
drop_tcp_exit
// Network subsystems that need network-namespace-specific data should call
// register_pernet_subsys() when the subsystem is initialized and
// unregister_pernet_subsys() when the subsystem is removed
->unregister_pernet_subsys(&droptcp_pernet_ops);
```
```c
///drop-tcp-socket.c
// The Network Namespace Object (struct net): https://elixir.bootlin.com/linux/latest/source/include/net/net_namespace.h
static int droptcp_pernet_init(struct net *net)
{
// (an instance of the net_generic structure, defined in include/net/netns/generic.h) is a set of generic pointers on structures describing a network namespace context of optional
subsystems.
struct droptcp_pernet *dt = net_generic(net, droptcp_pernet_id);
dt->net = net;
dt->pde = proc_create_data(DROPTCP_PDE_NAME, 0600, net->proc_net,
&droptcp_proc_fops, dt);
return !dt->pde;
}
// 傳入參數 (要新建 proc file, file mode, 上一層的 proc file, )
extern struct proc_dir_entry *proc_create_data(const char *, umode_t,
struct proc_dir_entry *,
const struct proc_ops *,
void *);
```
以下兩個函式根據給定 network namespace 的資訊回傳 socket
```c
// 根據給定的資訊(IPv4) 查詢 socket
// include/net/inet_hashtables.h
static inline struct sock *inet_lookup(struct net *net,
struct inet_hashinfo *hashinfo,
struct sk_buff *skb, int doff,
const __be32 saddr, const __be16 sport,
const __be32 daddr, const __be16 dport,
const int dif)
{
struct sock *sk;
bool refcounted;
sk = __inet_lookup(net, hashinfo, skb, doff, saddr, sport, daddr,
dport, dif, 0, &refcounted);
if (sk && !refcounted && !refcount_inc_not_zero(&sk->sk_refcnt))
sk = NULL;
return sk;
}
// 根據給定的資訊(IPv6) 查詢 socket
// include/net/inet6_hashtables.h
struct sock *inet6_lookup(struct net *net, struct inet_hashinfo *hashinfo,
struct sk_buff *skb, int doff,
const struct in6_addr *saddr, const __be16 sport,
const struct in6_addr *daddr, const __be16 dport,
const int dif);
int inet6_hash(struct sock *sk);
#endif /* IS_ENABLED(CONFIG_IPV6) */
#define INET6_MATCH(__sk, __net, __saddr, __daddr, __ports, __dif, __sdif) \
(((__sk)->sk_portpair == (__ports)) && \
((__sk)->sk_family == AF_INET6) && \
ipv6_addr_equal(&(__sk)->sk_v6_daddr, (__saddr)) && \
ipv6_addr_equal(&(__sk)->sk_v6_rcv_saddr, (__daddr)) && \
(((__sk)->sk_bound_dev_if == (__dif)) || \
((__sk)->sk_bound_dev_if == (__sdif))) && \
net_eq(sock_net(__sk), (__net)))
#endif /* _INET6_HASHTABLES_H */
```
:::spoiler net_namespace.h
```c
struct pernet_operations {
struct list_head list;
/*
* Below methods are called without any exclusive locks.
* More than one net may be constructed and destructed
* in parallel on several cpus. Every pernet_operations
* have to keep in mind all other pernet_operations and
* to introduce a locking, if they share common resources.
*
* The only time they are called with exclusive lock is
* from register_pernet_subsys(), unregister_pernet_subsys()
* register_pernet_device() and unregister_pernet_device().
*
* Exit methods using blocking RCU primitives, such as
* synchronize_rcu(), should be implemented via exit_batch.
* Then, destruction of a group of net requires single
* synchronize_rcu() related to these pernet_operations,
* instead of separate synchronize_rcu() for every net.
* Please, avoid synchronize_rcu() at all, where it's possible.
*
* Note that a combination of pre_exit() and exit() can
* be used, since a synchronize_rcu() is guaranteed between
* the calls.
*/
int (*init)(struct net *net);
void (*pre_exit)(struct net *net);
void (*exit)(struct net *net);
void (*exit_batch)(struct list_head *net_exit_list);
unsigned int *id;
size_t size;
};
/**
* register_pernet_subsys - register a network namespace subsystem
* @ops: pernet operations structure for the subsystem
*
* Register a subsystem which has init and exit functions
* that are called when network namespaces are created and
* destroyed respectively.
*
* When registered all network namespace init functions are
* called for every existing network namespace. Allowing kernel
* modules to have a race free view of the set of network namespaces.
*
* When a new network namespace is created all of the init
* methods are called in the order in which they were registered.
*
* When a network namespace is destroyed all of the exit methods
* are called in the reverse of the order with which they were
* registered.
*/
int register_pernet_subsys(struct pernet_operations *ops)
{
int error;
mutex_lock(&net_mutex);
error = register_pernet_operations(first_device, ops);
mutex_unlock(&net_mutex);
return error;
}
/**
* register_pernet_device - register a network namespace device
* @ops: pernet operations structure for the subsystem
*
* Register a device which has init and exit functions
* that are called when network namespaces are created and
* destroyed respectively.
*
* When registered all network namespace init functions are
* called for every existing network namespace. Allowing kernel
* modules to have a race free view of the set of network namespaces.
*
* When a new network namespace is created all of the init
* methods are called in the order in which they were registered.
*
* When a network namespace is destroyed all of the exit methods
* are called in the reverse of the order with which they were
* registered.
*/
int register_pernet_device(struct pernet_operations *ops)
{
int error;
mutex_lock(&net_mutex);
error = register_pernet_operations(&pernet_list, ops);
if (!error && (first_device == &pernet_list))
first_device = &ops->list;
mutex_unlock(&net_mutex);
return error;
}
```
:::
:::spoiler inet_twsk_deschedule_put
```c
/* These are always called from BH context. See callers in
* tcp_input.c to verify this.
*/
/* This is for handling early-kills of TIME_WAIT sockets.
* Warning : consume reference.
* Caller should not access tw anymore.
*/
void inet_twsk_deschedule_put(struct inet_timewait_sock *tw)
{
if (del_timer_sync(&tw->tw_timer))
inet_twsk_kill(tw);
inet_twsk_put(tw);
}
```
:::
有兩種 droptcp_proc_fops 的原因是因為 linux 5.6 起提供針對 proc file 提供了 proc_ops structure, 之前使用的 file_operations 提供了對於 VFS 不必要的方法([LKMPG: 7.1 The proc Structure](https://sysprog21.github.io/lkmpg/#the-proc-file-system))
:::info
register_pernet_subsys vs register_pernet_device:
:::
```c
/*
* Use these carefully. If you implement a network device and it
* needs per network namespace operations use device pernet operations,
* otherwise use pernet subsys operations.
*
* Network interfaces need to be removed from a dying netns _before_
* subsys notifiers can be called, as most of the network code cleanup
* (which is done from subsys notifiers) runs with the assumption that
* dev_remove_pack has been called so no new packets will arrive during
* and after the cleanup functions have been called. dev_remove_pack
* is not per namespace so instead the guarantee of no more packets
* arriving in a network namespace is provided by ensuring that all
* network devices and all sockets have left the network namespace
* before the cleanup methods are called.
*
* For the longest time the ipv4 icmp code was registered as a pernet
* device which caused kernel oops, and panics during network
* namespace cleanup. So please don't get this wrong.
*/
int register_pernet_subsys(struct pernet_operations *);
void unregister_pernet_subsys(struct pernet_operations *);
int register_pernet_device(struct pernet_operations *);
void unregister_pernet_device(struct pernet_operations *);
```
references:
- LKMPG
- Linux Kernel Networking - Implementation and Theory
> The /proc File System
>
>In Linux, there is an additional mechanism for the kernel and kernel modules to send information to processes — the /proc file system. Originally designed to allow easy access to information about processes (hence the name), it is now used by every bit of the kernel which has something interesting to report, such as /proc/modules which provides the list of modules and /proc/meminfo which gathers memory usage statistics.
>
>The method to use the proc file system is very similar to the one used with device drivers — a structure is created with all the information needed for the /proc file, including pointers to any handler functions (in our case there is only one, the one called when somebody attempts to read from the /proc file). Then, init_module registers the structure with the kernel and cleanup_module unregisters it.
>
>Normal file systems are located on a disk, rather than just in memory (which is where /proc is), and in that case the index-node (inode for short) number is a pointer to a disk location where the file’s inode is located. The inode contains information about the file, for example the file’s permissions, together with a pointer to the disk location or locations where the file’s data can be found.
#### TIME_WAIT socket
- 四次握手, 等待被關閉方收到 ACK 訊息, 否則需保持可接收 FIN 訊息的狀態・ 確保該次連線關閉可以新建連線
- 需等 2 MSL 確保沒新資料
- 主動關閉連線方才有
- 單一機器 socket(port) 數有上限, 太多 TiME_WAIT sockets 會導致無法建立新連線
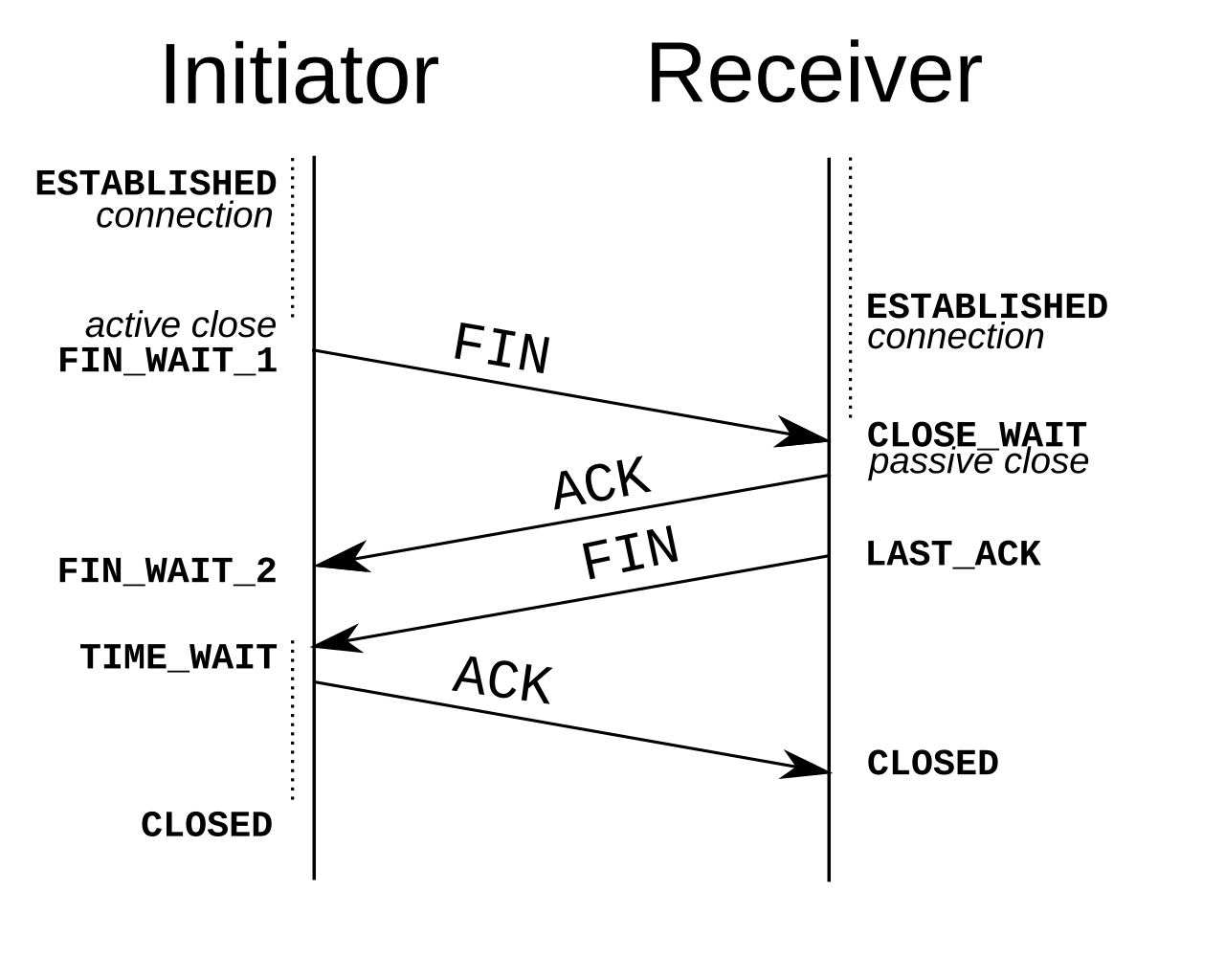
(source: wiki)
---
## kecho
:::info
使用 telnet 傳遞字串長度超過 4095 會 cut off, 仍找不到原因..
:::
### 若使用者層級的程式頻繁傳遞過長的字串給 kecho 核心模組,會發生什麼事?
利用 bench 傳遞 4096 的字串給 kecho
```shell
[10391.537307] kecho: get request =
[10391.537308] kecho: start send request.
[10391.537309] systemd-journald[301]: /dev/kmsg buffer overrun, some messages lost.
[10391.537309] kecho: recv length = 4095
[10391.537310] kecho: recv length = 0
[10391.537315] kecho: start send request.
[10391.537318] kecho: get request =
[10391.537319] kecho: recv length = -104
[10391.537323] kecho: get request error = -104
```
bench 的執行時間明顯以倍數增加, 電腦的負載提高非常明顯
值得注意的訊息:(待研究)
- `/dev/kmsg buffer overrun, some messages lost.`
- printk 使用 ring buffer, 一次寫入的長度大於 ring buffer 的容量就會造成 message lost
- log_buf_len, CONFIG_LOG_BUF_SHIFT
- `-104 #errorno`
### 參照 [kecho pull request #1](https://github.com/sysprog21/kecho/pull/1),嘗試比較 kthread 為基礎的實作和 CMWQ,指出兩者效能的落差並解釋
### 如果使用者層級的程式建立與 kecho 核心模組的連線後,就長期等待,會導致什麼問題?
會產生不必要的的長期資源佔用:
- kthread
- memory
- socket fd
### 研讀 [Linux Applications Performance: Introduction](https://unixism.net/2019/04/linux-applications-performance-introduction/),嘗試將上述實作列入考量,比較多種 TCP 伺服器實作手法的效能表現
#### forking vs threaded vs preforked vs prethreaded
比對這四組,可以發現一些有趣的現象
- process 的新建和銷燬成本遠大於 thread (forking vs threaded)
- process 跟 thread 預先建立後重複使用的情況下,在 2500 concurrency 之前差異並不大,側面可以印證 thread 在 linux 下跟 process 是一樣的東西,但是共用資源程度的不同還是對高性能上還是會造成影響
#### prethreaded, poll, epoll
- poll 在 concurrency 少的情況跟 epoll 性能幾乎一樣, 但是略爲可以觀察到會隨 concurrency 數量(conn fd)的上升導致下降($log n$ vs $n$ 在 $n$ 小的時候差異不巨大)
- prethreaded 在 2500 到 8000 優於 epoll, 但是 epoll 在 12000 以上的情況,性能下降少很多優於 prethreaded
- prethreaded 在 12000 的性能劇烈下降的原因是? 排程器?
## khttpd
在 GitHub 上 fork khttpd,目標是提供檔案存取功能和修正 khttpd 的執行時期缺失。過程中應一併完成以下:
### 指出 kHTTPd 實作的缺失 (特別是安全疑慮) 並予以改正
####
issue
- 每次 accept 都會新建 kthread(使用 cmwq 解決)
- 對處理 request 的 kthread 沒有 kthread_stop 的機制(使用 cmwq 解決)
- buf 在 keep alive 情況下的複用沒有被 reset
- 額外的 CRLF
##### - buf 在 keep alive 情況下的複用沒有被 reset
```c=
static int http_server_worker(void *arg){
...
while (!kthread_should_stop()) {
int ret = http_server_recv(socket, buf, RECV_BUFFER_SIZE - 1);
if (ret <= 0) {
if (ret)
pr_err("recv error: %d\n", ret);
break;
}
printk("buf: %s", buf);
http_parser_execute(&parser, &setting, buf, ret);
if (request.complete && !http_should_keep_alive(&parser))
break;
}
...
}
```
在 line 10 把 buf 印出來
然後利用 telnet 來測試
```shell
$ telnet 127.0.0.1 1999
Trying 127.0.0.1...
Connected to 127.0.0.1.
Escape character is '^]'.
GET / HTTP/1.1
TEST:99999999999999999999999
TEST2:888888888
HTTP/1.1 200 OK
Server: khttpd
Content-Type: text/plain
Content-Length: 12
Connection: Keep-Alive
Hello World!
```
```shell
$dmesg
[12435.167760] buf: GET / HTTP/1.1
[12444.041610] buf: TEST:99999999999999999999999
[12450.698731] buf: TEST2:888888888
99999999999
[12451.226849] buf:
ST2:888888888
99999999999
[12451.226855] khttpd: requested_url = /
```
利用 telnet 發出 head, 可以看到第一個 TEST head 的資料留存在 buf 中在讀取 TEST2 head 的時候被印出, 可能會導致 parse 結果不正確
修正:
```c=
while (!kthread_should_stop()) {
memset(buf, 0, RECV_BUFFER_SIZE);
int ret = http_server_recv(socket, buf, RECV_BUFFER_SIZE - 1);
if (ret <= 0) {
if (ret)
pr_err("recv error: %d\n", ret);
break;
}
printk("buf: %s", buf);
http_parser_execute(&parser, &setting, buf, ret);
if (request.complete && !http_should_keep_alive(&parser))
break;
}
```
加入 line 3 , 清空 buf
結果正常
```shell
[12919.404475] buf: GET / HTTP/1.1
[12933.382912] buf: TEST:99999999999999999999999
[12939.895957] buf: TEST2:888888888
[12940.431934] buf:
```
##### - 額外的 CRLF
使用 go 內建的 http client 作測試的時候發現的問題
```go
package main
import (
"io"
"io/ioutil"
"net/http"
)
func main() {
client := &http.Client{}
for i := 0; i < 5; i++ {
req, err := http.NewRequest("GET", "http://127.0.0.1:1999", nil)
if err != nil {
panic(err)
}
//req.Header.Set("Connection", "close")
res, err := client.Do(req)
if err != nil {
panic(err)
}
io.Copy(ioutil.Discard, res.Body)
res.Body.Close()
}
}
```
會出現警告訊息
```shell
$ go run main.go
2022/05/27 00:30:43 Unsolicited response received on idle HTTP channel starting with "\r\n"; err=<nil>
2022/05/27 00:30:43 Unsolicited response received on idle HTTP channel starting with "\r\n"; err=<nil>
2022/05/27 00:30:43 Unsolicited response received on idle HTTP channel starting with "\r\n"; err=<nil>
2022/05/27 00:30:43 Unsolicited response received on idle HTTP channel starting with "\r\n"; err=<nil>
2022/05/27 00:30:43 Unsolicited response received on idle HTTP channel starting with "\r\n"; err=<nil>
```
查閱 [RFC-2616](https://www.w3.org/Protocols/rfc2616/rfc2616-sec4.html)
發現 message body 的結尾沒有規定需要 CRLF
且有以下的敘述
>Certain buggy HTTP/1.0 client implementations generate extra CRLF's after a POST request. To restate what is explicitly forbidden by the BNF, an HTTP/1.1 client MUST NOT preface or follow a request with an extra CRLF.
移除 `HTTP_RESPONSE_200_KEEPALIVE_DUMMY` 的 `CRLF` 後, 沒有出現警告訊息
todo: go http client 有內建連接池可以複用 connection, 但是這個例子沒有生效, 待研究
#### 釐清 ret 0 誤解
stream socket 的 kernel_recvmsg, recvmsg在 blocking 模式下, 沒有資料可讀的情況阻塞, 而不是回傳 0, 在 blocking 和 nonblocking 的情況下回傳 0 都代表連線被關閉。
datagram sockets 的情況是有可能回傳資料爲 0
> These calls return the number of bytes received, or -1 if an error occurred. In the event of an error, errno is set to indicate the error.
>
> When a stream socket peer has performed an orderly shutdown, the return value will be 0 (the traditional "end-of-file" return).
>
> Datagram sockets in various domains (e.g., the UNIX and Internet domains) permit zero-length datagrams. When such a datagram is received, the return value is 0.
> The value 0 may also be returned if the requested number of bytes to receive from a stream socket was 0.
read: 0 代表 EOF
> On success, the number of bytes read is returned (zero indicates end of file)
### 引入 Concurrency Managed Workqueue (cmwq),改寫 kHTTPd,分析效能表現和提出改進方案,可參考 kecho
kthread 版本,200000 requests
```shell
$./htstress 127.0.0.1:1999 -n 200000
0 requests
20000 requests
40000 requests
60000 requests
80000 requests
100000 requests
120000 requests
140000 requests
160000 requests
180000 requests
requests: 200000
good requests: 200000 [100%]
bad requests: 0 [0%]
socker errors: 0 [0%]
seconds: 10.961
requests/sec: 18246.747
```
### 實作 HTTP 1.1 keep-alive,並提供基本的 directory listing 功能可由 Linux 核心模組的參數指定 WWWROOT,例如 httpd
#### command to list connections
netstat -atn | grep 1999
```shell
tcp 0 0 0.0.0.0:1999 0.0.0.0:* LISTEN
```
目前只有 LISTEN 的socket
#### 錯誤的 curl 測試方式
查看程式碼與使用 curl 測試, 看訊息貌似 HTTP 1.1 keep-alive 在當前版本已實作
```shell
$ curl 127.0.0.1:1999 -v
* Trying 127.0.0.1:1999...
* TCP_NODELAY set
* Connected to 127.0.0.1 (127.0.0.1) port 1999 (#0)
> GET / HTTP/1.1
> Host: 127.0.0.1:1999
> User-Agent: curl/7.68.0
> Accept: */*
>
* Mark bundle as not supporting multiuse
< HTTP/1.1 200 OK
< Server: khttpd
< Content-Type: text/plain
< Content-Length: 12
< Connection: Keep-Alive
<
* Excess found in a read: excess = 2, size = 12, maxdownload = 12, bytecount = 0
* Connection #0 to host 127.0.0.1 left intact
Hello World!
$ curl 127.0.0.1:1999 -v -H "Connection: close"
* Trying 127.0.0.1:1999...
* TCP_NODELAY set
* Connected to 127.0.0.1 (127.0.0.1) port 1999 (#0)
> GET / HTTP/1.1
> Host: 127.0.0.1:1999
> User-Agent: curl/7.68.0
> Accept: */*
> Connection: close
>
* Mark bundle as not supporting multiuse
< HTTP/1.1 200 OK
< Server: khttpd
< Content-Type: text/plain
< Content-Length: 12
< Connection: Close
<
* Excess found in a read: excess = 2, size = 12, maxdownload = 12, bytecount = 0
* Closing connection 0
Hello World!
```
上述的錯誤在於 curl 兩次會分別開啓新的連線,所以上述的訊息雖然是正確, 但是測試方式不對
```shell=
tcp 0 0 0.0.0.0:1999 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.1:49836 127.0.0.1:1999 TIME_WAIT
tcp 0 0 127.0.0.1:49838 127.0.0.1:1999 TIME_WAIT
```
#### 使用 curl 測試 keep alive
```shell=
$ curl 127.0.0.1:1999 127.0.0.1:1999 -v
* Trying 127.0.0.1:1999...
* TCP_NODELAY set
* Connected to 127.0.0.1 (127.0.0.1) port 1999 (#0)
> GET / HTTP/1.1
> Host: 127.0.0.1:1999
> User-Agent: curl/7.68.0
> Accept: */*
>
* Mark bundle as not supporting multiuse
< HTTP/1.1 200 OK
< Server: khttpd
< Content-Type: text/plain
< Content-Length: 12
< Connection: Keep-Alive
<
* Excess found in a read: excess = 2, size = 12, maxdownload = 12, bytecount = 0
* Connection #0 to host 127.0.0.1 left intact
Hello World!* Found bundle for host 127.0.0.1: 0x557db15e9030 [serially]
* Can not multiplex, even if we wanted to!
* Re-using existing connection! (#0) with host 127.0.0.1
* Connected to 127.0.0.1 (127.0.0.1) port 1999 (#0)
> GET / HTTP/1.1
> Host: 127.0.0.1:1999
> User-Agent: curl/7.68.0
> Accept: */*
>
* Mark bundle as not supporting multiuse
< HTTP/1.1 200 OK
< Server: khttpd
< Content-Type: text/plain
< Content-Length: 12
< Connection: Keep-Alive
<
* Excess found in a read: excess = 2, size = 12, maxdownload = 12, bytecount = 0
* Connection #0 to host 127.0.0.1 left intact
Hello World!
```
可以看到 `Re-using existing connection! (#0) with host 127.0.0.1` ,
連線有被重複使用
```shell
tcp 0 0 0.0.0.0:1999 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.1:49840 127.0.0.1:1999 TIME_WAIT
```
#### 測試較長時間的 keep alive
利用 curl 測試爲短時間的連續測試
改寫 htstress.c 成[client.c](https://github.com/Julian-Chu/khttpd/blob/fix/client.c) 變成單一執行緒, 每秒發送一次 request 持續 20s
```shell=
$./client.c
count: 1
count: 2
count: 3
count: 4
count: 5
count: 6
count: 7
count: 8
count: 9
count: 10
count: 11
count: 12
count: 13
count: 14
count: 15
count: 16
count: 17
count: 18
count: 19
count: 20
```
可以看到連線重複使用
```shell
tcp 0 0 0.0.0.0:1999 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.1:49868 127.0.0.1:1999 TIME_WAIT
```
#### 使用 telnet 測試
```shell
$ telnet 127.0.0.1 1999
Trying 127.0.0.1...
Connected to 127.0.0.1.
Escape character is '^]'.
GET / HTTP/1.1
HTTP/1.1 200 OK
Server: khttpd
Content-Type: text/plain
Content-Length: 12
Connection: Keep-Alive
Hello World!
GET / HTTP/1.1
HTTP/1.1 200 OK
Server: khttpd
Content-Type: text/plain
Content-Length: 12
Connection: Keep-Alive
Hello World!
```
```shell
tcp 0 0 0.0.0.0:1999 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.1:1999 127.0.0.1:49948 ESTABLISHED
tcp 0 0 127.0.0.1:49948 127.0.0.1:1999 ESTABLISHED
```
---
tool:
`ps auxf | grep khttpd`
`sudo netstat -tnope | grep keepalive`
`sudo netstat -tnope | grep 1999`
`netstat -atn | grep 1999`
> The normal Unix close function is also used to close a socket and terminate a TCP connection.
The default action of close with a TCP socket is to mark the socket as closed and return to the process immediately. The socket descriptor is no longer usable by the process: It cannot be used as an argument to read or write. But, TCP will try to send any data that is already queued to be sent to the other end, and after this occurs, the normal TCP connection termination sequence takes place
釐清誤解,之前誤以為每個 request 都需要經過 accept, 但實際上 accept 只處理 connection request, 當連線建立後未終止前, accept 不會回傳同樣的 socket(因為是資料傳輸的 request 並非 connect request), 直到 close 會關閉 socket 同時中斷連線後, accpet 才會接收同一客戶端來的 connection request
#### note:
>pthread_detatch()
>which tells the operating system that it can free this thread’s resources without another thread having to call pthread_join() to collect details about this thread’s termination. This is much like how the parent process needs to call wait()
>man pthread_detach
> The pthread_detach() function marks the thread identified by
thread as detached. When a detached thread terminates, its
resources are automatically released back to the system without
the need for another thread to join with the terminated thread.
>
>Attempting to detach an already detached thread results in unspecified behavior.
>
>Once a thread has been detached, it can't be joined with pthread_join(3) or be made joinable again.
> Either pthread_join(3) or pthread_detach() should be called for
each thread that an application creates, so that system resources
for the thread can be released. (But note that the resources of
any threads for which one of these actions has not been done will
be freed when the process terminates.)
>The Thundering Herd
> a problem in computer science when many processes, all waiting for the same event are woken up by the operating system. A good example is our pre-forked server in which there are several child processes all blocked on the same socket in accept(). This problem occurs when the part of the kernel that wakes up all processes or threads leaves it to another part of the kernel, the scheduler, to figure out which process or thread will actually get to run, while all others go back to blocking. When the number of processes/threads increases, this determination wastes CPU cycles every time an event that potentially turns processes or threads runnable occurs. While this problem doesn’t seem to affect Linux anymore
[Serializing accept(), AKA Thundering Herd, AKA the Zeeg Problem](https://uwsgi-docs.readthedocs.io/en/latest/articles/SerializingAccept.html)
---
## note
>INADDR_ANY
>
>This is an IP address that is used when we don't want to bind a socket to any specific IP. Basically, while implementing communication, we need to bind our socket to an IP address. When we don't know the IP address of our machine, we can use the special IP address INADDR_ANY. It allows our server to receive packets that have been targeted by any of the interfaces.
### cmwq
https://www.kernel.org/doc/html/v4.10/core-api/workqueue.html
https://lwn.net/Articles/355700/
https://lwn.net/Articles/393171/
https://lwn.net/Articles/394084/
https://events.static.linuxfound.org/sites/events/files/slides/Async%20execution%20with%20wqs.pdf
### epoll
https://eklitzke.org/blocking-io-nonblocking-io-and-epoll
> man epoll_ctl
>
> EPOLLIN The associated file is available for read(2) operations.
> EPOLLOUT The associated file is available for write(2) operations.
[c10k](http://www.kegel.com/c10k.html)
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet