# 考研筆記 - 計算機組織 (大碩張凡)
###### tags: `考研` `計算機組織`
###### 撰寫時間 : 2022/10/29 ~ 2022/12/30
## ch1 計算機語言
### 綱要
- ISA = 指令集 + 根據指令集所制定硬體的規範,是製造計算機的抽象規範
- RISC與CISC不同指令集類型的區別
- 硬體介紹 - 記憶體是用來儲存正在執行中的程式
- 記憶體的addressing, alignment, endianness規則
- 硬體介紹 - 暫存器是存於CPU的記憶元件,由於量少所以可以提供高速存取
- 5個記憶體的區塊 - stack, heap, satic, code, reserved
- 32個一般目的暫存器(GPR)、3個特殊目的暫存器(SPR)
- fp和sp永遠指向正在執行的procedure frame的頭和尾
- C語言compilation步驟與loader的6大執行步驟
- Java的interpretation步驟
- 指令分為3大類 - data transfer, operation, flow control
- 算數運算指令 - add, sub
- data transfer指令 - load, store
- 基底/位移定址模式(base or displacement addressing)
- lh,lhu指令區別 - sign extension
- intra program的flow control指令 - branch, jump
- 使用beq, bne, slt等指令造出以上虛擬指令blt, bgt, ble, bge
- 基本區塊(basic block)是編譯程式執行最佳化的最基本單位
- 邏輯運算指令(and / or / nor / xor)
- mask用and特性實踐;set用or特性實踐
- 用nor取代沒有的not指令
- 運算指令對應的立即版本指令
- 32-bit常數載入暫存器使用lui加上ori指令
- 根據指令參與運算的元素不同,分為R-type, I-type, J-type
- 組合語言翻譯機器語言3個步驟
- branch目的位置 = program counter值 + 4 * 16-bit address
- jump去頭4個bit(一個程式侷限在256M區塊),去尾2個bit(alignment)
- 程式呼叫的6大步驟
- caller與callee利用argument與values for results暫存器傳遞data
- caller有責任存argument與temp暫存器,callee有責任存save與ra暫存器
- 遞迴呼叫的C語言轉組語的組譯步驟
- 定址模式說明指令如何取得運算元或是指令如何計算跳躍目的位置
- 不同型態的指令集
- 指令集的4大設計原則
---
### ISA
<br>
如上圖所示,計算機組織這門學問探討軟體與硬體的交界處那2層,如何藉由control unit, datapath(前兩者合稱processor), memory, I/O device這些由數位邏輯電路所建構的計算機架構,要能夠執行指令集中的每一道指令,也就是軟體裡面最硬的、硬體裡面最軟的部分。
- 計算機的命令(commands)在高階語言稱為敘述(statements),在低階語言稱為指令(instructions),一個高階語言可以對應到多個低階語言的指令。
- **指令是CPU可以執行的最基本運算,一部計算機所可以執行指令的集合稱為指令集(instructions set)**,這堂課要教是MIPS R2000這個指令集。通常單一指令的功能都很簡單,因為簡單的指令,計算機硬體實踐較容易,越簡單的硬體架構,效能會越好。
- **ISA = 指令集 + 根據指令集所制定硬體的規範,是製造計算機的抽象規範**,根據這個抽象規範,我們可以使用不同造計算機的方式,不管使用哪種造計算機的方式,造出來的計算機彼此相容的(compatible),可以執行相同的machine language。
- **word = CPU一次可以處理的資料量**,一個word可以是16 bits、32 bits、64 bits等,如果一個CPU可以處理的字組的大小為32 bits,則稱此CPU為32 bits的CPU,而根據MIPS R2000所造出來的CPU也是32 bits的CPU。
- 指令集分為精簡指令集(RISC)與複雜指令集(CISC),1980年代以前主流使用CISC,代表的有intel x86、AMD Opteron,第一個原因是那時compiler效率太差,因此程序員都是直接寫assembly language,由於assembly language是人寫的,就必須使用功能強大的assembly language,**以減輕程序員編程的負擔**,第二個原因是早期程式容量需要小於記憶體容量,計算機才能執行,但記憶體價格又十分昂貴,因此需要**較少行的指令以減省記憶體容量**。
- 但隨著記憶體價格降低;compiler效率變好,而RISC由於指令較少,compiler也比較好優化;RISC比CISC更好做pipeline,因此1980年代以後,就由CISC轉為RISC,代表的有MIPS、ARM、RISC-V。
前面提及ISA = 指令集 + 根據指令集所制定硬體的規範,這些硬體包括4類 - 記憶體、暫存器、指令格式、定址模式,接下來會依序介紹
---
### 記憶體(memory)
1. **功能**<br>
用來儲存正在執行中的程式,包含資料(data)與程式碼(code)。
2. **架構/地址/容量**<br>
一個位址(address)指到1個位元組(byte)資料,稱為byte addressing 。實務上多數的資料項目使用較大的字組(words)做為基本存取單位,稱為word addressing。如果我們使用32 bits來表記憶體的位址.則此記憶體容量最大可為2^32^位元組。
3. **R/W operation**<br>
32-bit的CPU代表一次會連續抓4個byte的資料,若有讀取,會藉由address line傳遞要讀取記憶體的地址,再將read enable的control line拉高,最後就會以data line傳回資料給CPU的register。
4. **alignment**<br>
MIPS任意指令都是32個bit,要把資料放到memory裡面一定會跨4個位置,而第一個位置規定是4的整數倍。
5. **byte-order / endianness**<br>
**Big Endian**是指資料放進記憶體中的時候,**最高位的位元組(MSB)會放在最低的記憶體位址上**,MIPS屬於Big Endian;而Little Endian則是剛好相反,它會把最高位的位元組(MSB)放在最高的記憶體位址上,Intel x86屬於Little Endian。
---
### 暫存器(register)
1. MIPS R2000的主處理器,只能處理整數運算,因此需要有另外2種協同處理器(coprocessor),分別為處理浮點數運算與處理exception(程式執行到一半出錯)、interrupt(I/O設備出錯)。
2. 當程式使用比CPU暫存器還多的變數,compiler會把最常用的變數放在暫存器,其餘放在記憶體,稱為**溢出暫存器(spilling register)**,並**利用load與store指令,在暫存器與記憶體間傳送資料**。
3. 暫存器如果數量過多,CPU解碼器越複雜,解碼時間拉長,clock cycle time拉長,頻率就降低,就會降低CPU的執行效率。
4. MIPS R2000的主處理器有個32個32-bit的一般目的暫存器(GPR)、3個32-bit的特殊目的暫存器(SPR)。
5. 特殊目的暫存器(SPR) - 有3種<br>
1. **程式計數器(program counter, PC)**- 儲存下一個要被執行指令所在的記憶體位置。
2. **Hi, Lo** - 儲存乘法運算後的高位元32 bit與低位元32 bit或是除法運算後的餘數與商數部分。
6. 一般目的的暫存器(GPR) - 分5大類,寫assembly code時可使用name或是number表示都可。
| Type | Number | Name | Usage |
| ------------------- | ----------- | ----------- | ----------------------- |
| Assembler Related | $1 | \$at | Preserved for Assembler |
| OS Related | \$26 - \$27 | \$k0, \$k1 | Preserved for OS |
| Constants | \$0 | \$zero | Constant zero |
| Variables/Constants | \$8 - \$15 | \$t0 - \$t7 | Temporaries |
| Variables/Constants | \$24 - \$25 | \$t8, \$t9 | More temporaries |
| Variables/Constants | \$16 - \$23 | \$s0 - \$s7 | Save |
| Procedure Call | \$4 - \$7 | \$a0 - \$a3 | Arguments(引數) |
| Procedure Call | \$2 - \$3 | \$v0, \$v1 | Values for results |
| Procedure Call | \$31 | \$ra | Return address |
| Memory Management | \$28 | \$gp | Global pointer |
| Memory Management | \$29 | \$sp | Stack pointer |
| Memory Management | \$30 | \$fp | Frame pointer |
1. \$at保留給編譯器用與\$k0 - \$k1保留給OS用,程序員不要用。
2. 常數0暫存器 - 因為0常用(例 : 大於0小於0,與0做比較),因此CPU運算時直接從register調用時,就不需要再從memory將數字為0的資料load進register,硬體上直接把32bit通通接地(hardwired to zero)。
3. temp暫存器 - 存放運算的中間結果。
4. save暫存器 - 被呼叫程式(callee)在使用\$s0-\$s7存他自己的變數之前,先把他將要破壞s開頭的暫存器存到memory裡面。而當被呼叫程式(callee)執行完畢後、要跳回caller前,要從memory還原出原本的變數。**MIPS規定callee有責任存和還原他要用的s開頭的暫存器。**
5. arguments /values for results暫存器 - 在run time時,OS要先檢查memory占用的狀況,找memory哪一個連續、足夠大的空間,把程式塞進去,所以在runtime時,caller和callee會被放到memory的哪裡都是未知的,只有OS才知道,因此caller不會看到callee,callee也不會看到caller,**但兩者程式都是能看得到硬體的,所以必須要有硬體(暫存器)當作引數傳遞的媒介**,caller的argument要傳給callee的parameter,就需要\$a0 - \$a3;而同理callee要把回傳值給caller時,就需要\$v0 - \$v1。若互相要傳的引數超過暫存器時,就存到memory裡面,caller和callee就需要互相商量好。
6. return address暫存器 - caller跳到callee時,要先要跳之前的地址存到\$ra,並跳至callee,等到callee執行完後,就會讀取\$ra,回去執行caller的程式。
7. 欲了解剩下3種暫存器,須先了解記憶體管理
---
### 記憶體管理
當OS把程式call到memory裡面後,分為5個記憶體的區塊 - stack, heap, static, code, reserved。
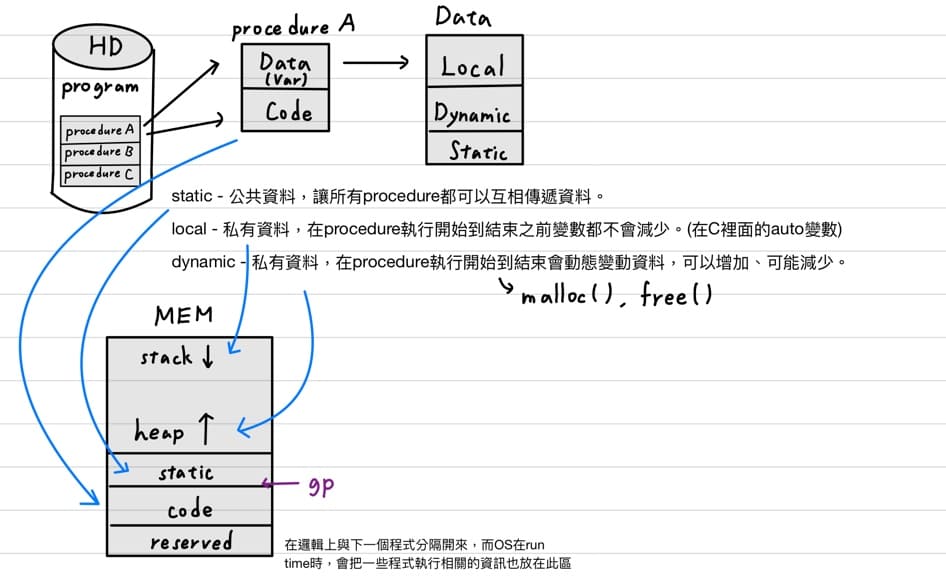<br>
1. **stack區** - 放置local變數,雖然在procedure執行開始到結束之前local變數都不會減少,但會隨著**副程式呼叫**而增減,成長方向為由上往下。
2. **heap區** - 放置dynamic變數,在procedure執行開始到結束會動態變動資料而增減。
3. **static區** - 放置static變數,在程式執行過程中大小不會改變,static變數讓所有procedure都可以互相傳遞資料。
4. **code區** - 存放程式執行的指令。
5. **reserved區** - 在邏輯上與下一個程式分隔開來,而OS在run time時,會把一些程式執行相關的資訊也放在此區。
stack是一種memory讀取的結構,規則為first in, last out,當一個procedure在執行時會把他自己的local變數放到stack裡面,而**一個procedure的local變數在stack中的集合,稱為procedure frame / activation record**。
隨著副程式呼叫stack區會往下成長,每一次呼叫都會產生一層procedure frame ,**fp和sp永遠指向正在執行的procedure frame的頭和尾**。而程式執行時只會fp和sp之間讀取變數,避免程式在呼叫來呼叫去誤用到別人的local變數。
大部分的指令集都只有sp,而沒有fp,但MIPS有別於其他指令集有fp,這是因為正在執行的procedure時,**local變數放到stack的時間是不確定的**,因此sp的值會變動,而fp都是固定的,因此**fp較適合作為參考點**。
1. global pointer暫存器 - 指向靜態變數第一個變數的位置,協助我們存取靜態區任意位置的變數資料。
2. frame pointer暫存器 - 指向正在執行procedure(stack最頂端的procedure)第一個變數的位置。
3. stack pointer暫存器 - 指向正在執行procedure(stack最頂端的procedure)最後一個變數的位置,也就是整個stack最頂端的位置。
---
### C語言compilation步驟與loader的6大執行步驟
<br>
人透過高階語言寫程式,透過compiler轉為低階的assembly language,但是assembly language一樣是由英文數字組成,機器看不懂;所以就需要assembler轉為機器看得懂0101的machine language;由於各自的procedure可以各自compile, assemble,因此會產生數個machine language,以及呼叫用到library的machine language,就需要linker把這個program相關的machine language去merge起來一個大的檔案,為可執行檔;當使用者執行這個可執行檔,OS會派出另一個系統程式稱為loader,load會執行6個步驟
1. loader讀取可執行檔的檔頭,檢查資料(data)與程式碼(code)佔幾個byte。
2. 根據第一步資訊,loader要去memory裡面找到邏輯上足夠大的連續空間。
3. 把程式call到memory裡面啟動執行。
4. 把主程式的argument放進stack,以C為例就是`int main()`括號裡面的argument。
5. 初始化一般目的暫存器(GPR),像是gp, sp, fp。
6. 設定program counter的值,但並不會指向memory的code區,因為如此的話,程式執行起來控制權在程式手上,會破壞系統資源,在這種情況下若OS沒辦法掌握系統全局,系統是不安全的,所以解決方法是**讓program counter指向OS的副程式start-up routine,start-up routine會call要被執行的程式**,因此任意程式都是start-up routine,當程式執行完後會跳回start-up routine,這時start-up routine會呼叫另一個副程式 - exit,釋放掉程式所占用的軟硬體資源,終結程式執行。
---
### Java的interpretation步驟
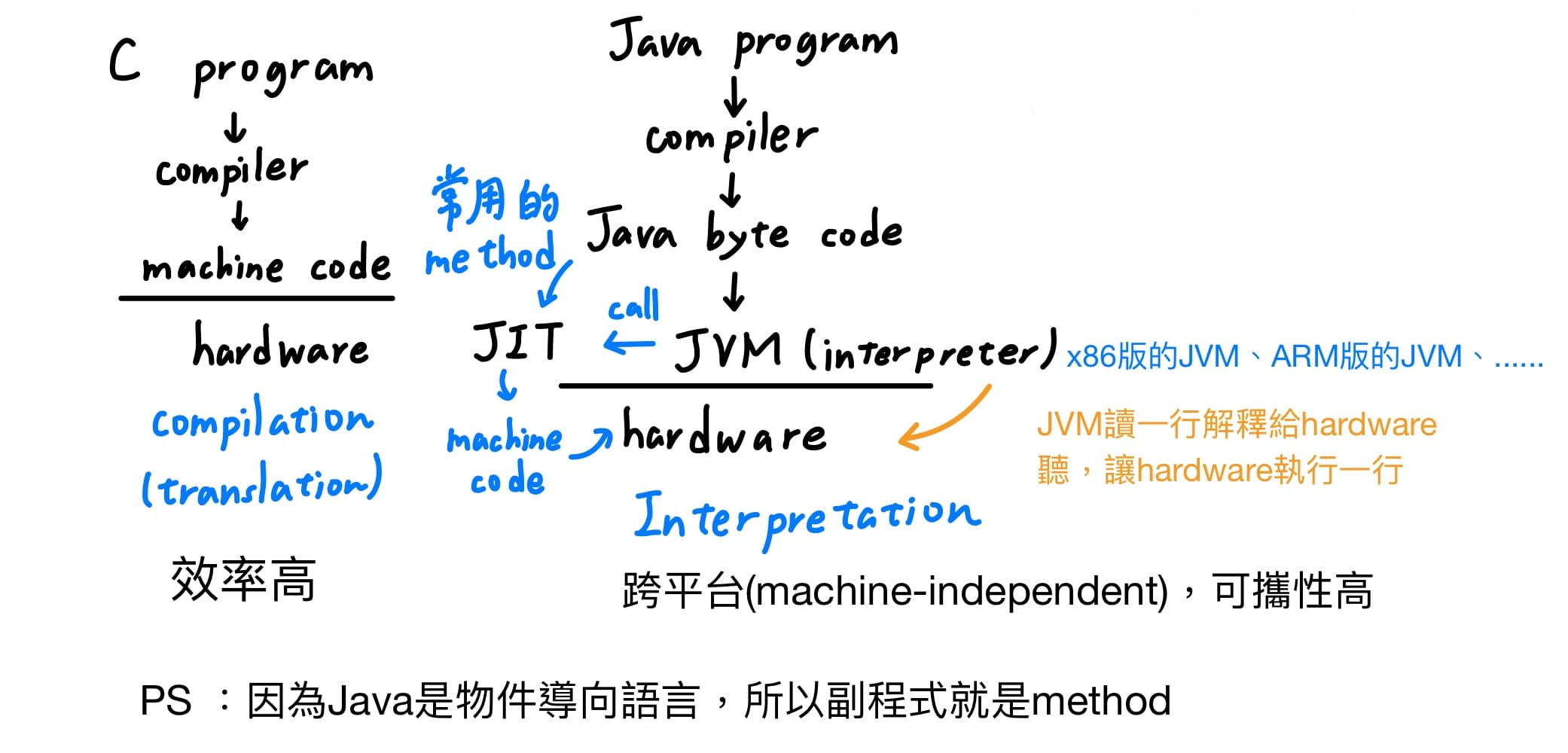<br>
C語言的執行流程稱為compilation(translation),但並不是所有高階語言都遵照這個流程,但還有一部分的程式語言像是Java,執行流程稱為interpretation。首先用compiler,把Java程式轉為一種中間的語言稱為Java byte code,接著使用透過不同種的JVM(x86版,ARM版, ...),JVM讀一行解釋給hardware聽,讓hardware執行一行,但是這樣執行效率實在太差,為了改善執行效率,所有Just In Time compiler (JIT)的出現,會把最常用到的method轉為machine code,當程式執行到最常用到的method時,就可以直接調用machine code,剩餘的就改JVM逐行解釋給解釋給hardware聽。
---
### 指令類型
1. **data transfer指令** - 從一個儲存體copy到另一個儲存體。在MIPS只有load(mem -> CPU)和store(CPU -> mem)這2個指令,其他動作靠這2個指令組合完成即可;舉例來說記憶體位置若要移轉,就需要從記憶體位置A`lw`到暫存器,再從暫存器`sw`回記憶體位置B。
2. **operation指令** - 對暫存器的數值做運算,分為算數和邏輯指令,算數又細分為整數與浮點數。
3. **flow control指令** - 正常指令是由上而下依序執行,但遇到flow control會改變預設的指令順序。分為只在自身程式跳轉的intra program、跳至其他程式的inter program、跳至OS的system call。
---
### operation -> 算數指令
1. 只能執行二元運算,代表一次只能相加2個值,無法連續加超過3個數值。
2. 每個指令有3個運算元,順序為目的暫存器、來源1暫存器、來源2暫存器。
3. 運算完成後,目的暫存器內容會被改變,而來源暫存器不變。
編譯程式有3個步驟
1. 指配暫存器給予常用變數(register assignment)。
2. 轉譯(translation),由高階語言轉換為組合語言。
3. 最佳化(optimization),使用最精簡的指令使得程式碼(code)占用記憶體的空間減少,以加速程式的執行。
由於編譯程式第1個與第3個步驟是NP-complete問題,機制過於複雜,因此題目上只需要執行步驟2的轉譯即可,如以下例題
給定register assignment為`A -> $s0, B -> $s1, C -> $s2, D -> $s3, E -> $s4, F -> $s5`,與高階C語言
```c
A = B + C + D;
E = F - A;
```
因此MIPS的組合語言為
```assembly
add $t0, $s1, $s2 # binary operation
add $s0, $t0, $s3
sub $s4, $s5, $s0
```
---
### data transfer指令
對MIPS而言,資料轉移指令只有2個,一是從記憶體轉到暫存器的load,二是從暫存器轉到記憶體。要存取的記憶體地址採用基底/位移(base or displacement)表示方式,就是一個基底暫存器(base register)內容加上一個限定為"常數"資料型態的位移量。
由高階語言轉換為組合語言例題如下,給定register assignment為`A -> $s0, H -> $s1`,與高階C語言
```c
A[12] = H + A[8]
```
首先理解一下機制,compiler會把必要的資訊放在可執行檔裡面,OS照做即可,所以loader的第5個步驟時就會把暫存器$s0初始化為array的起始位置;而高階語言中`H`在暫存器,`A`陣列由於數字過多,所以在記憶體裡面,因此需要先將陣列數值從memory中load進入暫存器才能執行運算,故MIPS的組合語言為
```assembly
lw $t0, 32($s0)
add $t0, $s1, $t0
sw $t0, 48($s0)
```
其中`lw, sw`代表load word, store word,一次存取的基本單位為word,因此offset需要乘以4才代表實際數值,計算機會將**基底暫存器`$s0`的數值與offset常數`32`丟進ALU相加即為要存取memory的地址**,接下來對load指令而言,會讀取該地址的data,存進暫存器`$t0`裡面。
<br><br>
若offset並非常數,在高階語言轉組語的題目當中,我們就必須模擬計算機的行為,先將"不是常數"的offset與base register相加,給定例題 - register assignment為`f, g, h, i, j`在`$s0 - $s4`;`A, B`在`$s6 - $s7`,與高階C語言
```c
f = g - A[ B[4] ]
```
MIPS的組合語言為
```assembly
lw $t0, 16($s7) # t0 = B[4]
sll $t0, $t0, 2 # 4 * t0
add $t0, $s6, $t0 # base register of array A + offset
lw $s0, 0($t0)
sub $s0, $s1, $s0
```
最後探討`lw,sw`的變化指令`lh, lhu, sh, lb, lbu, sb`。
1. 在高階C語言中有`char, short`等佔較少位元的資料型態,同理也要有對應的組合語言。
2. 與load word類似,差別只在於byte數目,由於一個word是4個byte,所以half word為2個byte,而load byte則為1個byte。
3. `lh`與` lhu`一個視讀入資料為有號數(signed)、一個視讀入資料為無號數,因此把資料從記憶體讀入register做符號擴充(sign extension),無號數空格直接補0,而有號數要複製MSB位元至所有空格。
4. `sh, sb`對上`lh, lb`與`sw`對上`lw`的關係雷同,差別在於`lh, lb`是少數memory位元要讀取進入多位元的register,會有多餘空格需要考慮符號擴充;但是`sh, sb`是多位元的register填入少數memory位元,因此只需要將register靠近右邊的位元擷取出來寫入memory即可,不會有符號擴充的問題。
---
### intra program的flow control指令
流程控制指令並不做任何運算,其唯一的目的便是改變指令執行順序,否則一般指令都是由上而下依序執行,分為2種 - 一是有條件的改變指令執行順序稱為分支(branch) ,二是無條件的改變指令執行順序稱為跳躍(jump)。而分支目的以"label"表示,**label值為要跳至執行的記憶體位置**;當條件成立,要跳指令時,program counter會用這個label的數值去更新。
給定register assignment為`f, g, h, i, j`在`$s0 - $s4`則以下為高階C語言轉MIPS組合語言
1. **If敘述加上go to**<br>
高階C語言
```c
If (i == j) go to L1;
f = g + h;
L1 : f = f - i;
```
觀察`if`語句若相等要跳,不相等不要跳,且繼續依序執行所有指令,因此用`beq`指令,則MIPS組合語言
```assembly
beq $s3, $s4, L1 # go to L1 if i equals j
add $s0, $s1, $s2 # f = g + h (skipped if i equals j)
L1: sub $s0, $s0, $s3 # f = f- i (always executed)
```
2. **If else敘述**<br>
高階C語言
```c
If (i == j)
f = g + h;
else
f = g - h;
```
觀察`if`語句若相等不要跳,不相等要跳,因此用`bne`指令,則MIPS組合語言
```assembly
bne $s3, $s4, Else # go to Else if i not equals j
add $s0, $s1, $s2 # f = g + h (skipped if i not equals j)
j Exit # go to Exit
Else: sub $s0, $s1, $s2 # f = g - h skipped if i = j)
Exit:
```
3. **loop敘述**<br>
高階C語言
```c
Loop: g = g +. A[i];
i = i + j;
if (i != h) go to Loop;
```
觀察`if`語句若相等不要跳,不相等要跳,因此用`bne`指令,則MIPS組合語言
```assembly
Loop: sll $t1, $s3, 2 # Temp reg $t1 = 4 * i
add $t1, $t1, $s5 # $t1 = address of A[i]
lw $to, O($t1) # Temporary reg $t0 = A[i]
add $s1, $s1, $t0 # g = g + A[i]
add $s3, $s3, $s4 #i=i+j
bne $s3, $s2, Loop # go to Loop if i is not equal h
```
4. **while loop敘述**<br>
高階C語言
```c
While (save[i] == k)
i = i + j
```
MIPS組合語言
```assembly
Loop: sll $t1, $s3, 2 # Temp reg $t1 = 4 * i
add $t1, $t1, $s6 # $t1 = address of save[i]
lw $t0, 0($t1) # Temp reg $t0 = save[i]
bne $to, $s5, Exit # go to Exit if save[i] <> k
add $s3, $s3, $s4 #i = i + j
j Loop # go to Loop
Exit:
```
---
### 基本區塊
**基本區塊(basic block)是編譯程式執行最佳化的最基本單位,其定義為沒有分支與沒有分支目的的指令,若有分支也只能在區塊的最後一個指令,若有分支目的也只能在區塊的第一個指令**。以上面MIPS組合語言為例,拆成1到4行、5、6行、7行之後的3個basic block。
因此程式在執行時,compiler會以下3步驟
1. 將高階語言轉會為低階語言。
2. 將指令分割為基本區塊(basic block),並在基本區塊內做最佳化。
3. 執行各基本區塊之間的最佳化
所謂最佳化就是指使用最少、最精簡的指令完成其程式要執行的功能、**以減少程式碼佔用的記憶體空間並加速程式執行**。
---
### 虛擬指令
虛擬指令(pseudo-instruction or directive instruction)是指實際機器並不存在但組譯程式卻可以接受的指令,MIPS並不提供
- blt (branch if less than)
- bgt (branch if greater than)
- ble (branch if less and equal than)
- bge (branch if greater and equal than)
等分支指令,但我們可以使用beq, bne, slt(set if less than)等指令造出以上4種虛擬指令。
|虛擬指令|MIPS指令|虛擬指令|MIPS指令|
|---|---|---|---|
|`blt $s1, $s2, L`|`slt $t0, $s1, $s2`<br>`bne $t0, $zero, L`|`bgt $s1, $s2, L`|`slt $t0, $s2, $s1`<br>`bne $t0, $zero, L`|
|`bge $s1, $s2, L`|`slt $t0, $s1, $s2`<br>`beq $t0, $zero, L`|`ble $s1, $s2, L`|`slt $t0, $s2, $s1`<br>`beq $t0, $zero, L`|
---
### 邏輯運算指令
位移(shift)指令理論上有分邏輯上的左移與右移(sll, srl),算數上的左移與右移(sla, sra),邏輯與算數的差別在於邏輯視數字為無號數,算數視數字為有號數,但MIPS不存在sla指令,因為與sll功能重複。
MIPS提供and / or / nor / xor指令,其中nor為先做or後做not,xor (exclusive-or)為相同數為0,相異數為1。
- AND的特性為1跟任何數做AND為任何數;0跟任何數做AND為0,可以用作mask - 感興趣的bit保留下來,不感興趣的bit清除為0。
- OR的特性為0跟任何數做OR為任何數;1跟任何數做OR為為1,可以用作set - 感興趣的bit設定為1,不感興趣的bit保持原狀。
- MIPS未提供not指令,因為not指令的格式只有2個運算元的格式,可以改用`nor $t0 $s0 $0`代替,任何數與0做or都是任何數,或是改用`nor $t0 $s0 $s0`代替,自己跟自己做or還是自己,再做not,綜合以上這兩部就具有not指令的功能。
- 若兩個數字`$s0, $s1`要互相交換,而規定只能用兩個暫存器,可以使用XOR的特性來實現
```assembly
xor $s0, $s0, $s1 # $s0 ⊕ $s1 $s1
xor $s1, $s0, $s1 # $s0 ⊕ $s1 ($s0 ⊕ $s1) ⊕ $s1 = $s0
xor $s0, $s0, $s1 # ($s0 ⊕ $s1) ⊕ $s0 = $s1 $s0
```
---
### 立即版本的指令
由於**程式經常使用常數**當作運算元`a = b + 5`,根據前面所學過的指令,就必須assign一個變數為5,並從記憶體載入這個變數到register做運算,如此就會增加指令的延遲時間,因此MIPS對幾乎每個運算指令額外設計其對應的立即版本指令(immediate instruction)。
一個指令有32 bit,扣除6 bit的opcode、2個5 bit的暫存器地址,剩下能表示常數的只有16個 bits,使用2的補數來表示正數與負數,因此能表示範圍為$- 2^{15}$到$(2^{15} - 1)$,當做運算時,需要將16 bit的常數做sign extension至32 bit,才能與暫存器的數值做運算,若是邏輯類(andi)運算則視16 bit為無號數,左邊16 bit直接補0即可;若是算數類(addi)運算則將MSB向左複製擴充至32 bit。
由於立即指令只能存取16-bit的數字,因此若需要將完整32-bit常數放入暫存器,就需要使用`lui`(load upper immediate)指令,其功能為將16-bit常數載入暫存器左半邊16 bit,剩下右半邊16 bit則清為0;由於`ori`是邏輯運算,加上0與任何數OR會是任何數,所以接下來就使用`ori`指令將16 bit常數載入暫存器右半邊。
前面提到immediate使用2的補數表示,可以是正數與負數,因此MIPS就沒有設計`subi`指令,其功能等同於`addi`。
---
### 組合語言與機器語言之間轉換
根據指令**參與運算的元素不同**,分為3種不同格式的機器指令表示,MIPS有3種指令格式
|參與運算的元素|組合語言指令|機器指令格式|
|---|---|---|
|3個暫存器|算數與邏輯指令|R-type|
|2個暫存器加上16-bit的常數或地址|load, store, branch, 立即版本指令|I-type|
|26-bit的地址|jump|J-type|
**機器指令中幾個連續位元所構成有意義的資訊稱為欄位**,指令不同欄位的排列方式就稱為指令格式(instruction format),而不管哪種指令長度都是一樣為32 bit。
<br>
不管哪種指令opcode都需要等長,否則機器就無法執行指令,其中R-type有共用相同的opcode為`000000`,這是因為假設所有指令有128個,因此需要7 bit的opcode,但是I-type和J-type的位置有限,只能塞6 bit的opcode,而R-type會有多出來的6個bit,因此把R-type的opcode設定相同,共用相同的opcode,剩下多出來的6個bit稱為function code就可以來區別即可。
再來rs, rt的field為來源1與來源2暫存器,如果指令只有用到一個來源暫存器的話,根據MIPS規定則將該暫存器填入後者 - 來源2暫存器,前面 - 來源1暫存器則全部填0。shamt為shift amount的全名,其數值"有效"的位移量,由於data是32bit所以有效位移量是從0到31,佔5個bit,如果沒有用到shamt這個field則根據規定全部填0。
組語翻譯機器語言有3個步驟
1. 決定屬於哪種指令格式的機器指令?
2. 畫出對應的機器指令格式(如上方圖)
3. 查表,有opcode table, function table(R-type才會用到), register table。
另外需要組語翻譯機器語言時需要注意 - **組合語言目的暫存器要放前面,來源暫存器要放後面;但機器語言則相反**,原因有以下兩點,一是早期使用CISC,指令不等長,所以為了讓目的暫存器的位置固定,所以把目的暫存器放在前面;二是考慮到實際硬體設計,硬體要先放牧目的暫存器再放來源暫存器,才能確保線路不會交錯,而有電磁干擾等問題。
branch指令翻譯 - 由於branch指令通常不會跳躍太遠,因此採用PC相對定址法(PC-relative addressing),**以branch指令的下一個指令的地址為基準點往上用負數,往下用正數,計算經過多少指令(word)可以到達跳躍目的的數值**,因此分支目的位置 = program counter值 + 4 * 16-bit address;而其最大跳躍空間就是相對上下$- 2^{15}$到$(2^{15} - 1)$個word的地方,或是說相對上下$- 2^{15} \cdot 2^2$到$(2^{15} - 1) \cdot 2^2$個byte的地方。
當執行程式,此時特殊暫存器PC = 80012時,從記憶體80012的位置抓指令執行,同時PC = PC+4 = 80016,當確定要跳時,就會抓reference值(假設等於4)進行運算,使得PC = 80016 + 2*4 = 80024。
由於branch能跳的最大距離為下一個指令的地址相對上下$- 2^{15}$到$(2^{15} - 1)$個word的地方,若是超過這個位置,則可以將原本branch指令改成**反向條件的branch指令加上無條件跳躍的jump指令**來解決。
jump指令翻譯 - 使用虛擬絕對定址法(pseudo-direct addressing),白話來說存的是"假的"記憶體絕對位置。MIPS作業系統於記憶管理時會將$2^{32} = 2^2 \cdot 2^{30} = 4 \rm G$的記憶體空間**切割成16個大小相等的256M區塊,任何一個程式只能侷限於一個區間之內** (這樣的空間已經夠大了,以windows的OS來說,程式大小才幾百MB而已),因此相同區塊內的任何指令最左邊4個bit都是相同的,jump指令最左邊的4個bit就不需要紀錄;另外由於**MIPS規定記憶體存放data或是code必須alignment**,一定要是4的整數倍,因此最右邊的2個bit也不需要紀錄,總結jump要跳的位置只要26個bit就能表達所有要跳的位置。
當CPU執行jump指令要還原原本的地址時,只需要把頭串接(concatenate)上program counter的前4個bit,尾巴串接上2個0就可以還原出原本記憶體的位置。
### 程式呼叫(procedure call)
執行程式呼叫時有以下6大步驟
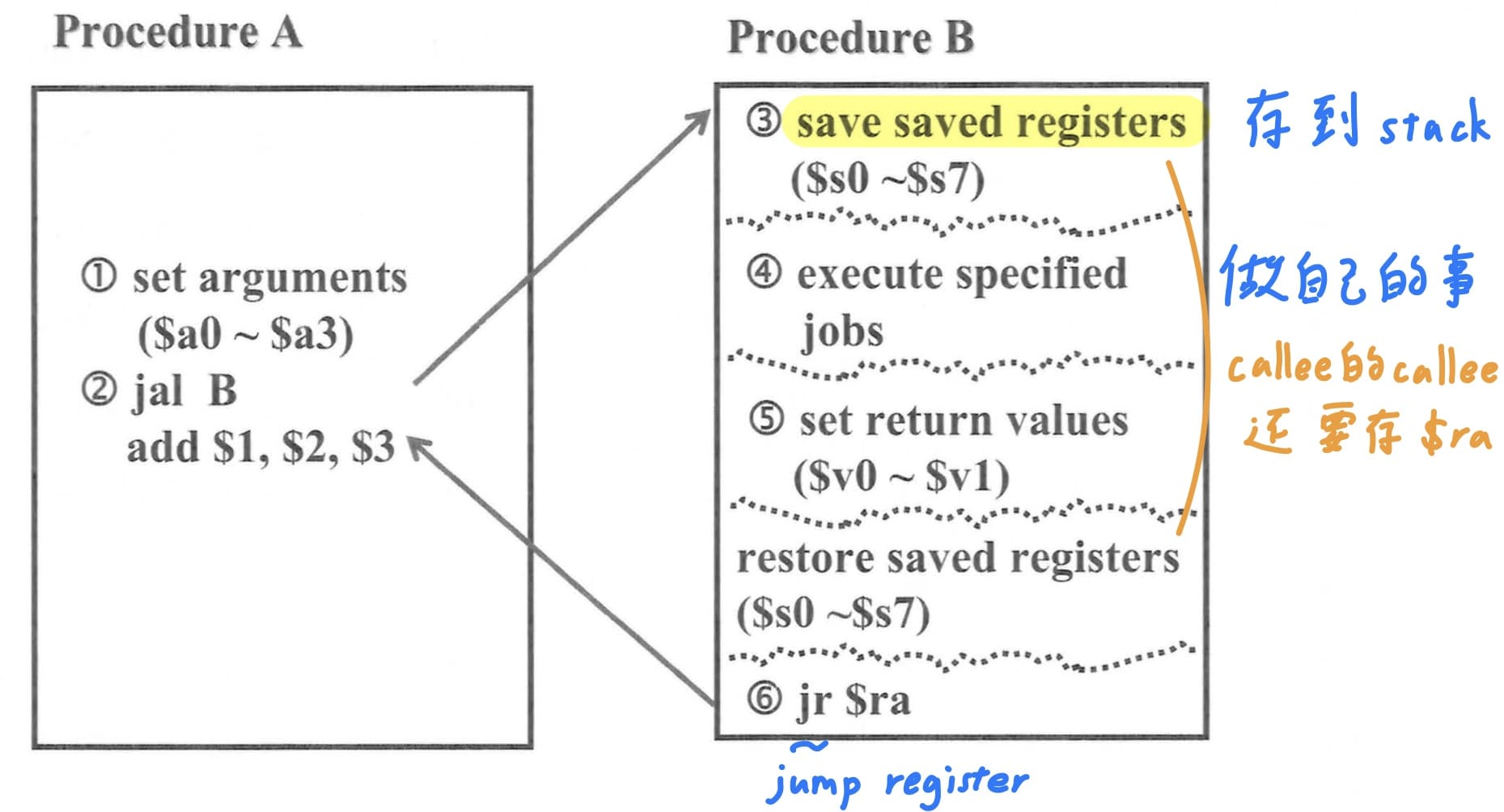
1. caller要把傳遞給callee的引數存入argument暫存器。
2. 執行jump and link指令,跳至callee程式的執行位置,並同時把下一個指令的位置存入暫存器`$ra`,讓procedure B執行後有辦法跳回procedure A。
3. 為了避免callee蓋掉caller的save暫存器,MIPS規定callee有責任存放與還原他要用的save暫存器,會先將stack pointer暫存器(指向整個stack最頂端的位置)向地址小的成長,將要用的save暫存器push進stack。
4. 執行callee自己要做的工作。
5. callee將要傳遞給caller的運算結果存入values for results暫存器,以C而言就是關鍵字`return`。接下來callee回復原本被破壞的save暫存器,從stack pop出原來的數值。
6. 執行jump register指令,program counter會更新至`jr`後面的register內的數值,在此就是`$ra`值,返回procedure A的,下一個執行add指令。
當procedure A呼叫procedure B,而procedure B又繼續呼叫procedure C,這樣繼續呼叫下去,稱為遞迴呼叫,此時callee既是caller,給定算階層的C語言
```c
int fact(int n){
if (n < 1) return (1);
else return (n * fact(n - 1));
}
```
先決定哪些變數要存,哪些變數不要存,caller有責任存argument與temp暫存器,callee有責任存save與ra暫存器,在此情況下沒有local變數,因此只需要存argument和ra暫存器。
接下來照結構翻譯即可
```assembly
fact:
addi $sp, $sp, -8 # Adjust stack for 2 items
sw $ra, 4($sp) # Save the return address
sw $a0, 0($sp) # Save the argument n
slti $t0, $a0, 1 # Test for n < 1
beq $t0, $zero, Ll # If n >= 1 go to Ll
addi $v0, $zero, 1 # Return 1
addi $sp, $sp, 8 # Pop 2 items off stack
jr $ra # Return to caller
Ll:
addi $a0, $a0, -1 # n ~ 1; argument gets (n - 1)
jal fact # Call fact with (n - 1)
lw $a0, 0($sp) # Return from jal: restore argument n
lw $ra, 4($s p) # Restore the return address
addi $sp, $sp, 8 # Adjust stack pointer to pop 2 items
mul $v0, $a0, $v0 # Return n*fact (n - 1)
jr $ra # Return to the caller
```
---
### MIPS的5個定址模式
**定址模式(addressing mode)為說明指令如何取得運算元或是指令如何計算跳躍目的位置**。
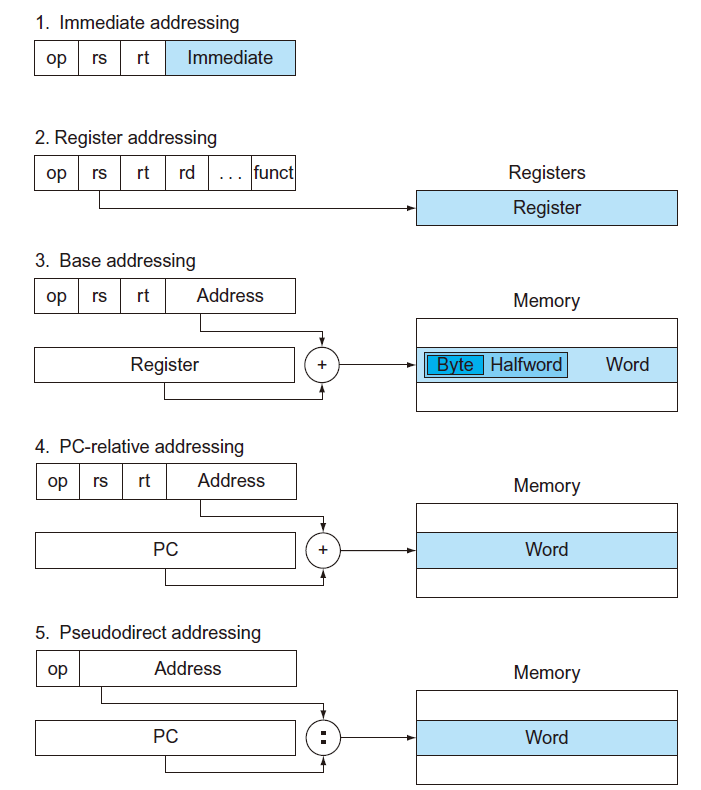<br>
有3種取得運算元的方法
|定址模式|指令|運算元位置|
|---|---|---|
|立即(Immediate addressing)|立即版本的運算指令|在指令本身的16位元常數|
|暫存器(Register addressing)|add, sub, and|暫存器|
|基底或位移(base or displacement addressing)|load, store|記憶體,而記億體位址的計算方式為將基底暫存器的內容加上指令中16位元的常數|
有2種計算跳躍目的位置的方法
|定址模式|指令|跳躍目的位置|
|---|---|---|
|程式計數器相對(PC-relative addressing)|beq, bne|PC + 指令中的常數|
|虛擬直接(Pseudodirect addressing)|j, jal|指令的26位元與程式計數器高4位元串接|
---
### 不同型態的指令集
有4種不同型態的指令集
1. accumulator (one operand) - 所有運算結果都會發生在一個累積暫存器與記憶體。
2. mem-mem (three operands) - 每個指令有3個運算元,而這3個運算元都在記憶體裡面。
3. stack (zero operand) - 所有運算都發生在stack頂端,只能用push和pop指令存取記憶體。
4. load-store (three operands) - 所有運算都發生在暫存器,而且每個指令都有3個運算元,MIPS屬於這種,load-store是RISC,其餘3種都是CISC。
---
### 指令集的4大設計原則
1. 一致才會簡單(Simplicity favors regularity)
- 讓所有指令保持單一大小
- 在算數指令中一律要求3個運算元 (用nor指令取代not)
- 讓不同指令格式中的暫存器欄位在相同位置 (R-type和I-type的目的暫存器Rs和來源暫存器Rt在相同位置)
2. 愈小就愈快(Smaller is faster)
- MIPS只有32的一般目的暫存器,[暫存器(register)](#暫存器register)中提及暫存器如果數量過多,CPU解碼器越複雜,解碼時間拉長,clock cycle time拉長,頻率就降低,就會降低CPU的執行效率;此外電子元件變複雜,功率消耗也會提升。
3. 使經常發生的事件快速(Make the common case fast)
- 由於短距離跳躍經常發生,故在MIPS中branch用PC-相對定址模式,有別於ARM,在MIPS只要一個指令就可以判斷條件並決定是否分支跳躍。
- 由於程式經常使用常數當作運算元,故使用立即定址模式以得到常數運算元。
4. 好的設計需要有好的折衷方案(Good design demands good compromises)
- 使用3種指令格式,而非1種,否則只使用1種指令格式就必須拉長指令,以保持每個指令的一致性。
---
## ch2 計算機算數
### 綱要
- 有號數的sign and magnitude、1補數的缺陷
- 2補數的MSB權重是負,其餘是正的
- overflow發生條件為正數加正數卻是負數、負數加負數卻是正數
- 序向電路乘法器 - 傳統、硬體最佳化、Booth演算法
- 組合電路乘法器 - 快速、平行樹
- 序向電路除法器 - 傳統、硬體最佳化
- 在MIPS中,乘法器與除法器共用相同的硬體,差別只在於乘法運算往右移動;除法運算往左邊移動
- 浮點數 = 二進位的正規化數以有限硬體空間表示
- IEEE754浮點數單精度格式與雙精度格式
- 有號數使用bias notation的優點
- 計算IEEE754浮點數正規化數與非正規化數值範圍
- 浮點數的加法與乘法
- 有號數的負數中,右移不一定等於除以2的冪次方運算,需要做修正
- 有號數、無號數用組語偵測overflow
---
### 數的表示
1. 任意進位數轉10進位數 - 先表示為**係數權重表示式**,權重為base^i^,再用以10進位的方式乘開並加總。
2. 10進位數轉任意進位數 - 整數部分一直除下去,除到商數等於0為止,再用倒著的順序把所有餘數串起來;小數部分一直乘下去,取浮出小數點左邊的數,乘到小數為0為止,最後將所有數串起來。
數在計算機中的表示有以下幾類
1. floating point(浮點數)
2. integer(整數)
- unsigned(無號數)
- signed(有號數)
1. sign and magnitude
2. 1's complement
3. 2's complement
無號數只有正沒有負,包含0,若二進位的無號整數有n個bit,則能表示的範圍為$[0, 2^n -1]$。
sign and magnitude為用一個sign bit表示正負號,sign bit為1表示負,sign bit為0表示正,但有以下3個缺點
1. sign bit要放在右邊還是左邊?
2. 由於無法預先知道運算結果的正負,所以在執行加法運算時還需要一個額外步驟比兩數大小來設定符號位元。
3. 0有+0與-0兩種表示,會導致粗心的程序員發生錯誤。
1's complement要表示一數值之負數形式只要將各個位元取補數即可但有以下2個缺點
1. 0有+0與-0兩種表示,會導致粗心的程序員發生錯誤。
2. 運算後有時需要加1做端回進位修正。
2's complement為現代計算機採用有號數的表示方式,數值為1's complement再+1,而另一種轉換方式 - **從右往左邊的bit掃過去,碰到第1個1之前(包含1)保持原狀,接下來取補數**。2's complement每一位元的權重**除了MSB的權重是負的之外**,其餘位元的權重和二進位無號數是—樣的。若二進位的2's complement整數有n個bit,則能表示的範圍為$[-2^{n-1}, 2^{n-1} - 1]$。
用無號數會讓範圍檢查的組語縮短,檢查用有號數指令檢查$0 \leq x < y$的判斷等用無號數指令$x < y$,其原理在於任何一個負數,看成無號數,都會超過任何一個正數。
---
### 二進位的加法與減法與overflow
- 二進位加法與我們習慣的10進位加法一樣,而減法也是使用加法運算,A - B = A + (-B) = A + B的2補數。
- 由於硬體資源的限制使得運算結果無法表示時就稱為overflow,overflow發生條件為正數加正數卻是負數、負數加負數卻是正數。
1. 有號數運算發生overflow時,OS會出來把程式kill掉(exception),並丟給error machine告訴使用者發生錯誤的資訊。
2. **無號數運算發生overflow時,不會發生任何事**,程序員須自行負責。
---
### 多媒體運算
許多圖學系統使用3個8 bit(R、G、B三原色),來記錄一個點的顏色,用另一個8 bits(alpha)來記錄位置。但是運算上一次只會有1 byte的資料量,若以一般1個word的方式運算,過於浪費空間,因此以64位元**加法器中的進位鏈分割開來**處理器一次可處理8組 8 bits 運算元、或四組16 bits運算元、或2組32bits運算元的短向量進行運算(若是MIPS 的話,一次ALU為32 bits,故可處理4組 8bits資料量),此種運算稱為**Vector或SIMD**。
若是有超出或低於範圍的計算結果出現時,則將結果設為以最大的值與最負的值,此種方式稱為飽和運算(saturating operations)。
---
### 序向電路乘法器 - 傳統、硬體最佳化、Booth演算法
無號數的乘法分為傳統乘法器與硬體最佳化乘法器。
傳統乘法器,首先會檢查乘數最右邊的bit是0還是1,是0則不做任何事情,是1則執行"積 = 被乘數 + 積",由於運算子都是64 bit,因此也要有64 bit大的ALU,當執行完後,最後將乘數往右邊移1個bit,被乘數往左邊移1個bit(提高被乘數的權重),並反覆執行上述步驟32次。
硬體最佳化乘法器**將被乘數固定起來**,而改移動乘數,由於積與乘數每一次運算都是往右移,因此把乘數一同放到積(product)的64 bit暫存器的右半邊。首先會檢查product暫存器最右邊的bit是0還是1,是0則不做任何事情,是1則執行"左半部product = 被乘數 + 左半部product",當執行完後,最後product暫存器往右移1個bit,並反覆執行上述步驟32次。
有號數的乘法就是將乘數與被乘數轉為正數,使用上述無號數的乘法器求得結果,再根據原本正負號設定乘積的正負號。而這邊另外介紹一種有號數乘法的演算法 - Booth演算法,可以直接對兩個有號數運算,且"平均"運算速度也比傳統乘法器、硬體最佳化乘法器還快。
Booth演算法的硬體與硬體最佳化乘法器的硬體類似,差別是多加了一個mythical bit,用以一次檢查連續2個bit的資訊,因此會有以下4種處理方式
1. 00 - 0字串的中間部份,不執行運算。
2. 01 - **1字串的結尾**,左半部product = 左半部product + 被乘數。
3. 10 - **1字串的開頭**,左半部product = 左半部product - 被乘數。
4. 11 - 1字串的中間部份,不執行運算。
可以將Booth演算法想像為**用連續1字串的頭bit減去尾bit**,而傳統/硬體最佳化乘法器則是乘以每個bit代表的權重。
$$
a \times 0,011,100 = a \times (2^6 - 2^2) = a \times (2^5 + 2^4 + 2^3 + 2^2 )
$$
總結來說無號數乘法器有傳統、硬體最佳化,有號數乘法器有Booth演算法,這三種乘法器都屬於序向(sequential)電路,輸出由目前電路狀態(記憶元件)與輸入共同決定,步驟有3大點檢查(check)、動作(action)、位移(shift)。

---
### 組合電路乘法器 - 快速、平行樹
接下來是使用組合電路做的乘法器,觀察乘法運算就是一個輸入是被乘數、1個的位元乘數做AND 動作的結果形成partial product,再將這些partial product相加即可,根據partial product做加法的方式分為快速乘法器與平行樹乘法器。
快速乘法器速度較快的原因有3個
1. 組合電路不需要向序向電路一樣有clock驅動。
2. 組合電路元件數目就多,容易做最佳化。
3. 此架構容易做pipeline,讓多個乘法同時運算。
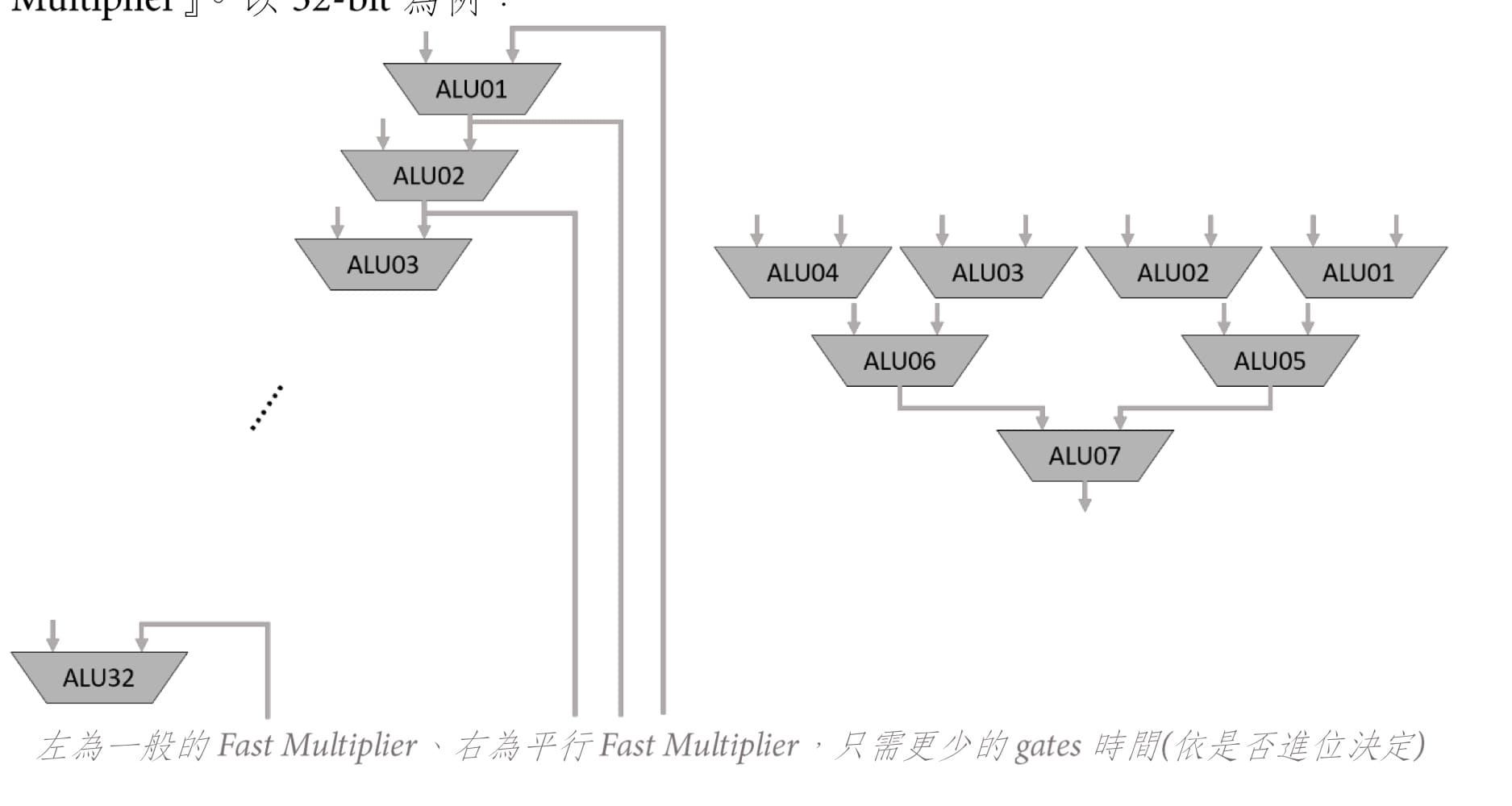
如左上圖,每一層依序將最右邊的bit拉下來就是答案,不需要跟別人加,有32個partial product,需要31個加法器,假設1個加法器的延遲時間是T,此電路需要經過31T的延遲時間。如右上圖,另一種架構 - 平行樹乘法器將partial product兩兩相加,此電路需要經過$log_232 = 5$T的延遲時間。但是課本上有錯誤,左邊的bit不可以直接拉下來,應該要考慮進位(此處有錯,但還是以課本為主)。
---
### 序向電路除法器 - 傳統、硬體最佳化
無號數的除法分為傳統除法器與硬體最佳化除法器。
傳統除法器首先會"被除數 = 被除數 - 除數";若結果為正代表夠減,將商數左移並塞入一個1;若結果為負代表不夠減,要累加回來以還原回原來的值,並將商數左移並塞入一個0,;當執行完後,最後除數暫存器往右移1個bit,並反覆執行上述步驟33次,需要注意要做33輪,因為第1輪是白做的。
硬體最佳化除法器**將除數固定起來**,而改移動被除數,由於被除數與餘數每一次運算都是往左移,因此把被除數一同放到餘數(remainder)的64 bit暫存器的右半邊。為了避免傳統除法器第1輪是白做的問題,首先先將remainder暫存器往左移才進入迴圈,執行"左半部remainder = 左半部remainder - 被除數",若結果為正代表夠減,將remainder暫存器向左移並塞入一個1;若結果為負代表不夠減,要累加回來以還原回原來的值,並將remainder暫存器並塞入一個0;當執行完後,放在remainder暫存器左半部的餘數要向右移1個bit做修正。
總結來說,傳統除法器和硬體最佳化除法器有4大步驟 - 相減(subtract)、檢查(check)、動作(action)、位移(shift)。

有號數的除法就是將除數與被除數轉為正數,使用上述無號數的除法器求得結果,若除數與被除數異號則將商數加以變號,另外MIPS規定於餘數與被除數必須同號還避免定義上的不同。
---
### MIPS的乘法與除法
在MIPS中,乘法器與除法器共用相同的硬體,差別只在於乘法運算往右移動;除法運算往左邊移動。
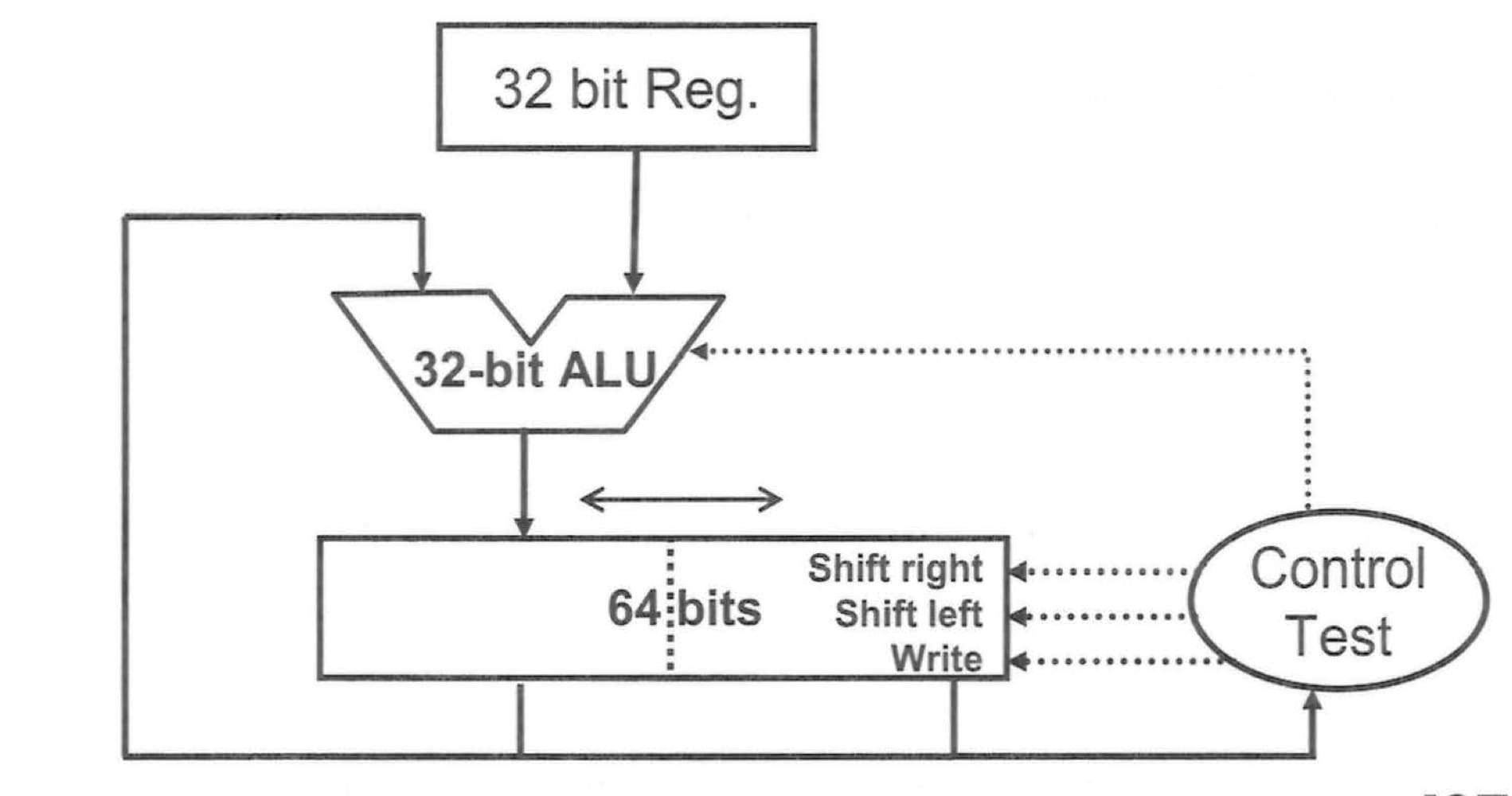
64 bit暫存器中右半部為特殊暫存器Lo,存放商數或是乘積的低位數;左半部為特殊暫存器Hi,存放餘數或是乘積的高位數,對應使用的組合語言為
```assembly
# multiplication
mult $s2, $s3 # {Hi, Lo} <- $s3 * $s2
mfhi $s0 # $s0 <- Hi
mflo $s1 # $s1 <- Lo
# division
div $s2, $s3 # Lo <- $s2 / $s3; Hi <- $s2 % $s3
mfhi $s0 # $s0 <- Hi
mflo $s1 # $s1 <- Lo
```
---
### 浮點數的表示
"廣義"上的科學記號有不唯一的表示方式,因此正規化數(normalized number)就是規定科學記號在小數點左邊只能有一個非0的數值,而**二進位的正規化數以有限硬體空間表示就稱為浮點數(floating point)**。
$$
(-1) \times 1.0101545 \times 2^{-123}
$$
其中$1.0101545$稱為significand,小數點後的數字$0101545$稱為fraction / mantissa、$2$稱為base / radix、$-123$稱為exponent。
IEEE754規範2種浮點數的表示方式,一是使用1個word的單精度格式、二是使用2個word的雙精度格式。
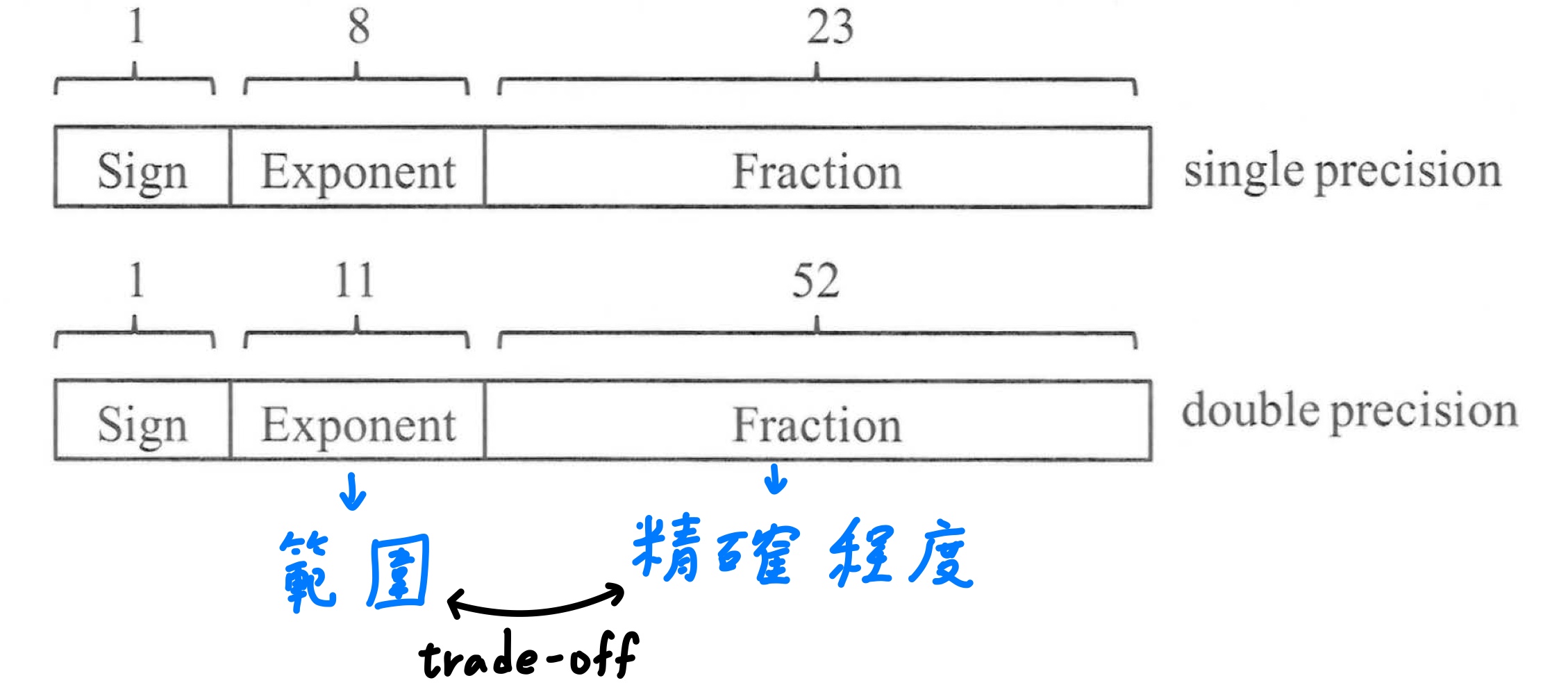
1. 從設計層面來看,在固定硬體大小之下,exponent和fraction要設計多大彼此是一個trade-off - 增加**exponent**能增加數字的**表示範圍**、增加**fraction**能增加數字的**精確度**。
2. 由於二進位正規化數在小數點左邊的位元必定是1,因此IEEE754**隱藏該位數**,而只表示fraction的部分。
3. 有號數表示不使用2的補數,而是改用bias notation,這是因為浮點數兩數相加時會需要先比較指數部分,而**無號數比較器相比2的補數比較器,速度還快**,為了快速比較指數而採用bias notation,故又名excess - X,這個X就是bias值。
4. bias notation的規則 - 給定$n$個bit的exponent,bias就是$2^{n - 1} - 1$,以8 bit為例,bias就是$2^{8 - 1} - 1 = 127 = 01,111,111$,真正填入的指數值就是計算出來的值加上bias值(偏移量)。
5. 以浮點數表示的數,其公式為
$$
(-1)^{\text{sign}} \times (1 . \text{fraction}) \times 2^{(\text{exponent} - \text{bias})}
$$
6. 將10進位數轉換為單精度浮點流程 - 首先把10進位數轉換為2進位數,再來正規化,最後將計算出來的指數部分加上bias值得結果,若分數部分填不進去field的話,需要做"round"的步驟。
7. IEEE754有定義5種數的表示方式,以單精度為例
|exponent|fraction|object represented|
|---|---|---|
|0|0|$\pm 0$|
|0|nonzero|$\pm$ denormalized number|
|1 - 254|anything|$\pm$ floating-point number|
|255|0|$\pm$ infinity|
|255|nonzero|NaN (not a number)|
因此正規化數能表示的範圍在
$$
+1.\underbrace{00 \ldots 00}_{23 個} \times 2^{1 - \text{bias}} < |x| < +1.\underbrace{11 \ldots 11}_{23 個} \times 2^{\underbrace{254 - \text{bias}}_{= \text{bias}}}
$$
非正規化數數值計算定義
$$
(-1)^{\text{sign}} \times (0 . \text{fraction}) \times 2^{\text{min exp in normalized number}}
$$
其中指數定義為正規化數指數負最多的值,非正規化數能表示的範圍在
$$
+0.\underbrace{00 \ldots 01}_{23 個} \times 2^{-126} < |x| < +0.\underbrace{11 \ldots 11}_{23 個} \times 2^{-126}
$$
由於非正規化數的數值實在太小,一般非科學性值的計算都幾乎不會跑到這個區間,因此不是每種指令集都支援非正規化數的數值範圍,若指令集有支援非正規化數,而數值小到不在非正規化數能表示的範圍,稱為gradual underflow;若指令集不支援非正規化數,而數值小到不在正規化數能表示的範圍,稱為underflow;若數值大於正規化數能表示的範圍則稱為overflow。

以下4種運算會產生NaN - $\frac{0}{0}, 0 \times \infty, a \times \text{NaN}, \infty - \infty$。
除了IEEE754浮點規定,另一種需要記憶的就是IBM format,一樣32個bit,但指數只有7個bit,bias為64,且base為16。
---
### 浮點數的加法與乘法
浮點數的加法有以下4步
1. **指數對齊 - 指數較小的數需要對齊指數較大的數**。
2. significand相加。
3. 正規化加完結果,並檢查有無underflow或是overflow。
4. 四捨五入。
浮點數的乘法有以下5步
1. 指數相加 - 若是兩個含有bias的指數相加,**需要再扣除一個bias,避免bias重複加到2次**。
2. significand相乘,相乘時不帶正負號。
3. 正規化結果,並檢查有無underflow或是overflow。
4. 四捨五入。若四捨五入的結果會讓significant變成非正規化形式,則須再正規化一次,並檢查有無underflow或是overflow。
5. 設定sign bit,兩運算元異號,sign bit則為1,否則為0。
---
### 浮點數四捨五入流程
從十進位開始,以方便說明,需要多保留2個bit的額外硬體空間,稱為保護位元(guard bit)和捨入位元(round bit),簡寫為GR,若GR = 0~49則捨去;若GR = 51 ~99則進位;若**GR = 50**,需要再1個bit的硬體空間,稱為黏著位元(sticky bit),若**運算時round bit右邊的bit被截掉,sticky bit便會設定為1**;反之,則就會根據LSB數值依據,執行"**round to nearest even (unbiased rounding)"原則**。
> sticky bit硬體上使用OR gate實現,只要被捨去的bit中有任何一個bit非0,結果就會是1。
將上述觀念改為二進位,影響結果的有4個bit - LSB, guard bit, round bit, sticky bit,如下面流程圖所示
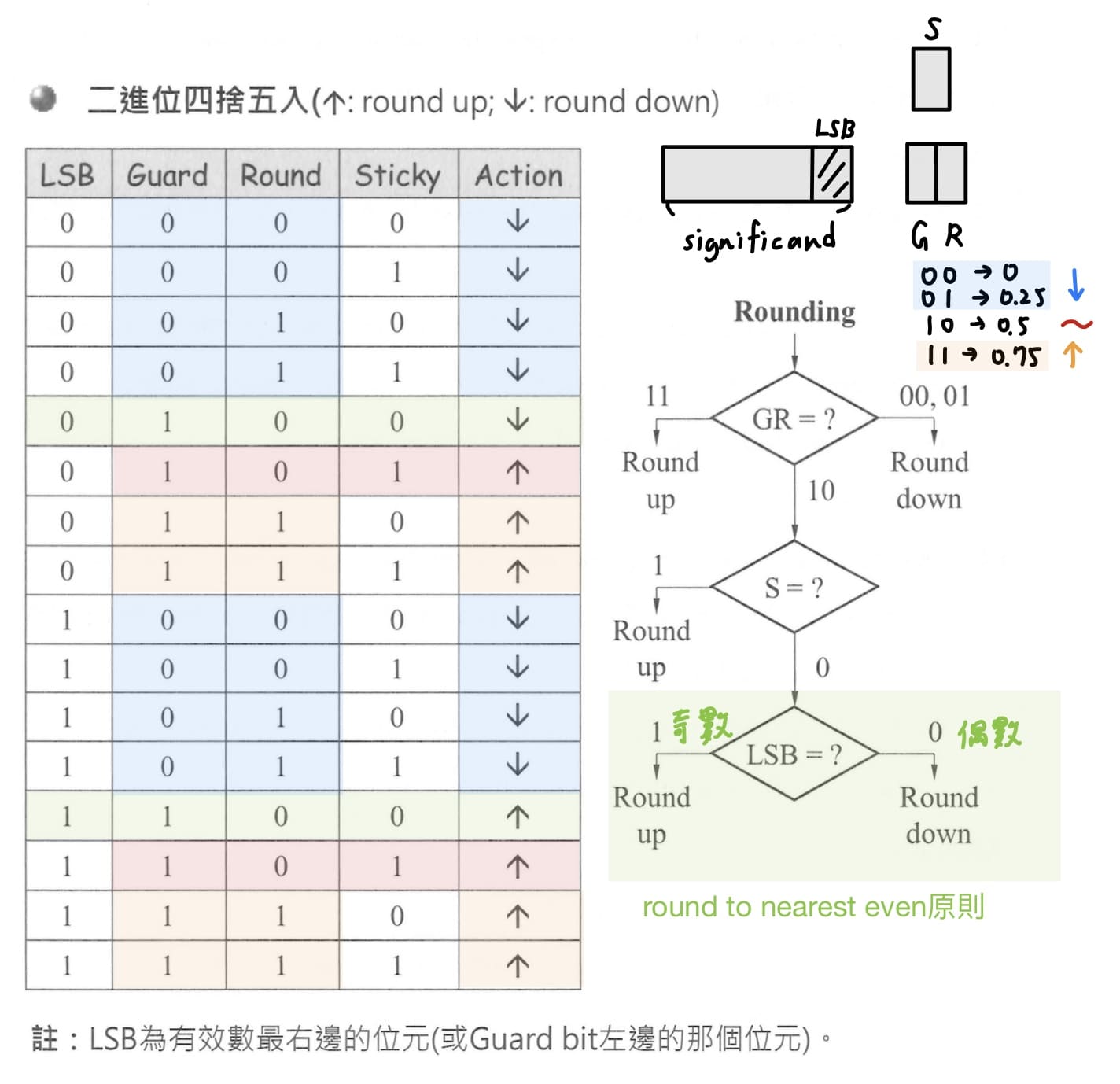
IEEE754共有4種捨去模式 - 朝向正無限大、朝向負無限大、截尾(不做四捨五入)、round to nearest even,上面介紹的是round to nearest even的捨去模式,而MIPS採用此種捨去模式。
由於快速傅立葉轉換經常使用大量加法和乘法,因此在一些指令集(ex : ARM)會設計乘法和加法連做的指令,IEEE754規定單一個指令既做乘又做加,只能最後結果做一次四捨五入,稱為fused multiply add。
---
### 浮點數額外議題
實數的加法具有結合率,而浮點數的加法是用來表示實數的,卻無結合率,這是因為浮點數是用有限硬體空間來表示實數,會有精確度上面限制的問題。
在無號數與有號數的正數中,右移等於除以2的冪次方運算;但**有號數的負數不一定**,當被移掉的bit不是全0,則"**右移結果 + 1 = 商數",因此需要將運算做修正 - 右移幾個bit,就先加上幾個bit 1的數值**,例如負數除以8需要先+7做修正,再向右移3個bit;負數除以16需要先將+15做修正,再向右移4個bit。
有號數用組語偵測overflow
```assembly
addu $t0, $tl, $t2 # $t0 = sum, but don't trap
xor $t3, $t1, $t2 # Check if signs differ
slt $t3, $t3, $zero # $t3 = 1 if signs differ
bne $t3, $zero, No_overflow # $tl, $t2 signs !=, so no overflow
# signs =; sign of sum match too?
xor $t3, $t0, $t1 # $t3 negative if sum sign different
slt $t3, $t3, $zero # $t3 = 1 if sum sign different
bne $t3, $zero, Overflow # All three signs #; go to overflow
```
add和addu用的是同一個ALU,運算方式都一模一樣,差別只是在於對結果的解釋不同,add會偵測overflow,addu不會偵測overflow;如果一開始用add發生overflow,後面就不會執行了,會跑到OS去,OS把程式kill掉。
接下來前三行是做異號數相加一定不會有overflow;後三行是做正數加正數卻是負數,負數加負數卻是正數。
無號數用組語偵測overflow
```assembly
addu $t0, $tl, $t2 # $t0 = sum
nor $t3, $tl, $zero # $t3 = NOT $tl
sltu $t3, $t3, $t2 # $t3 < $t2 -> set t3 = 1
bne $t3, $zero, Overflow # t3 = 1 -> overflow
```
想法如下
$$
\begin{align*}
& t_1 + t_2 > 11 \ldots 11 \qquad(\text{overflow occurs})\\
\Rightarrow\;& t_2 > 11 \ldots 11 - t_1\\
\Rightarrow\;& t_2 > \overline{t_1}\\
\Rightarrow\;& \overline{t_1} < t_2
\end{align*}
$$
---
## ch3 效能評估
### 綱要
- 不同的效能定義會影響評估的結果
- execution time = IC * CPI * cycle time
- 平均CPI = 指令個別CPI乘以該指令所佔比例
- 軟體與硬體會影響到的效能參數
- Amdahl's law計算與speedup計算
- 效能總評 - 算術平均數(AM)、加權平均數(WAM)、幾何平均數(GM)
---
### 效能定義
不同的效能定義會影響評估的結果,因此在實施評估前先要對效能的定義有明確的了解。個人電腦會以執行時間做為效能評估的標準;而伺服器由於服務多人,則以生產量做為效能評估的標準。
1. 執行時間(execution time)、反應時間(response time) - 工作從開始到完成所花的時間,也就是program送至計算機開始執行直到執行結果的所花的時間。
2. 生產量(throughput) - 單位時間內所完成的工作量,也就是計算機單位時間完成的program(job)的個數。
本章主要考慮個人電腦,因此以以執行時間做為效能評估的標準,對電腦$X$,效能定義為執行時間的倒數
$$
\text{Performance}_X \triangleq \frac{1}{\text{Execution Time}_X}
$$
電腦$X$的速度是電腦$Y$的$n$倍
$$
n = \frac{\text{Performance}_X}{\text{Performance}_Y} = \frac{\text{Execution Time}_Y}{\text{Execution Time}_X}
$$
---
### 執行時間測量
計算機從工作從開始到完成所花的時間稱為elapsed time,其中包括等待I/O的時間與處理器時間(CPU time),CPU time又可進一步分為使用者處理器時間(user CPU time)與花在作業系統(服務使用者的程式運行)上的時間,稱為系統處理器時間(system CPU time)。當我們在run的程式個數不同,I/O time和system CPU time這兩個時間都是變動的,因此我們以user CPU time做為執行時間(execution time)的測量。
使用絕對時間user CPU time,由於時間過短難以測量。而由於計算機都需要clock來同步快慢有別的訊號源,因此改使用一個cycle所花的時間長度clock cycle time作為衡量之一的參數,再乘上一個程式使用cycle的個數clock cycle就是user CPU time,而clock rate又為clock cycle time的倒數,是一秒鐘clock訊號同步的次數。
$$
\begin{align*}
\text{(user) CPU time} &= \text{CPU clock cycles} \times \text{cycle time}\\
&= \frac{\text{CPU clock cycles}}{\text{clock rate}}
\end{align*}
$$
欲測量一個程式使用cycle的個數clock cycle,勢必要造出counter,此counter的clock要比CPU的clock更快,才能有效取樣,理論上是行不通的,因此上式公式較難估算。將clock cycle改定義為一個程式使用的指令個數instruction count(IC)乘上平均執行每個指令所需要花的clock個數cycles per instruction(CPI),因此user CPU time即為
$$
\begin{align*}
\text{(user) CPU time} &= \text{IC} \times \text{CPI} \times \text{cycle time}\\
&= \frac{\text{IC} \times \text{CPI}}{\text{clock rate}}
\end{align*}
$$
由於不同類別的指令CPI各不相同,例如乘法比起加法需要更多clock cycle數,因此在此的CPI為一加權平均值,等於第$i$類的CPI,乘以第$i$類指令佔所有指令的比例
$$
\begin{align*}
\text{CPI} &\triangleq \frac{\text{CPU clock cycles}}{\text{IC}}\\
&= \frac{\sum^n_{i = 1} (\text{CPI}_i \times \text{C}_i)}{\text{IC}}\\
&= \sum^n_{i = 1} (\text{CPI}_i \times \text{Freqency}_i)
\end{align*}
$$
接下來定義instruction time為平均1個指令執行時會用的CPU時間
$$
\begin{align*}
\text{instruction time} &= \frac{\text{(user) CPU time}}{\text{instruction count}}\\
&= \frac{\text{IC} \times \text{CPI}}{\text{clock rate}} \times \frac{1}{\text{IC}}\\
&= \frac{\text{CPI}}{\text{clock rate}} = \text{CPI} \times \text{cycle time}
\end{align*}
$$
instruction time的倒數就是instruction rate,代表單位時間內指令執行的次數,在以前常以1秒百萬次指令執行時間,作為衡量評估計算機效能的指標,但這是一個錯誤,因為MIPS沒有把每個指令的能力考量進來,像是CISC都比RISC的指令功能還強大,另外同一台電腦不同程式測量出來的MIPS也可能不同。
$$
\begin{align*}
\text{instruction time} &= \frac{1}{\text{instruction rate}}\\
&= \frac{1}{\text{MIPS} \times 10^6}
\end{align*}
$$
總結上述公式,整理出以下表格,以方便記憶
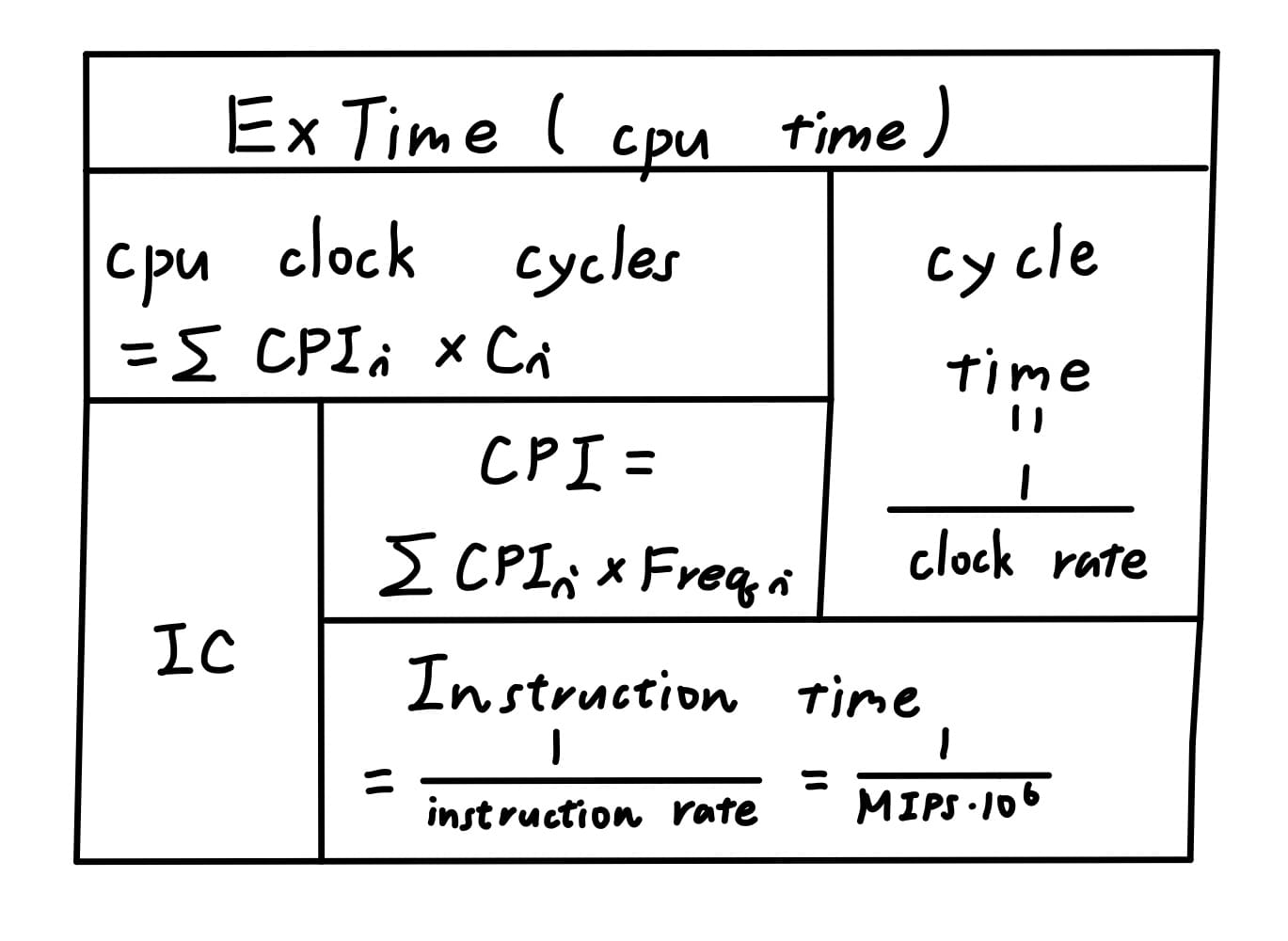<br>
對於2部不同硬體實踐架構但同一ISA的機器,當要比較效能也就是execution time時,首先要確保跑的是相同的程式(組合語言),也就代表instruction count相同,因此真正要比的就是instruction time。
以下為軟體與硬體會影響到的效能參數 $\text{execution time} = \text{IC} \times \text{CPI} \times \text{cycle time}$。
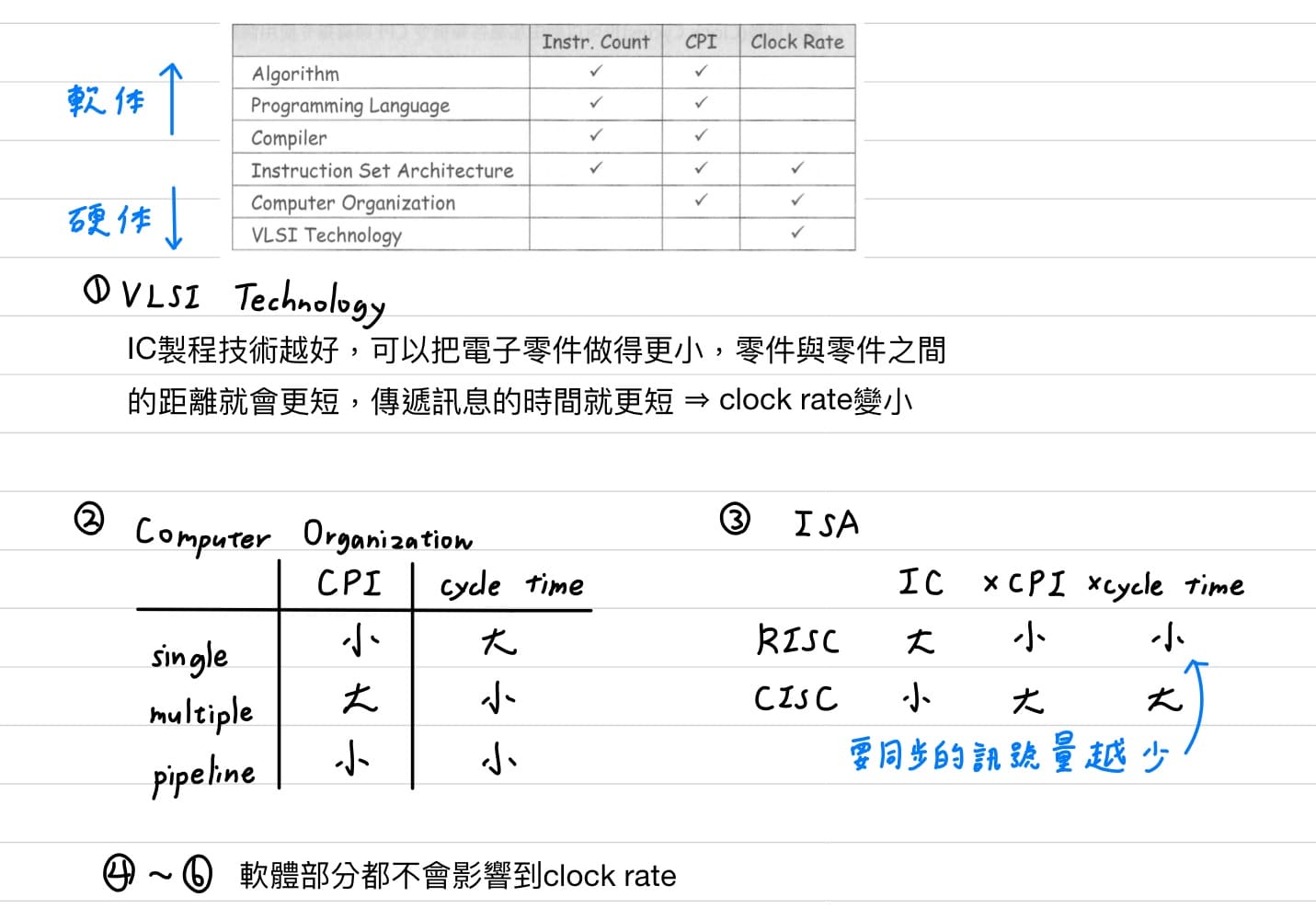
值得注意的是compiler不會影響個別指令的CPI,個別指令的CPI在硬體建構好就已決定,compiler會選擇較佳組合的指令,影響的會是平均的CPI。
---
### Amdahl's law
Amdahl's law是用來計算當某一機器改善了其中一部分後的執行時間。
$$
\text{ExTime after} = \frac{\text{ExTime affected}}{\text{Improve rate}} + \text{ExTime unaffected}
$$
由上式可知只要改善一般較常出現的程式部份,就會比去對極少出現的部份做最佳化要來得有效,符合[ch1 指令集的4大設計原則](#指令集的4大設計原則)其中一條 - make the common case faster。
而speedup是指機器在經過某種策略的改良之後·相對於原本效能之提升程度。
$$
\begin{align*}
\text{speedup} &= \frac{\text{ExTime before}}{\text{ExTime after}}\\
&= \frac{\text{ExTime before}}{ \frac{\text{ExTime affected}}{\text{Improve rate}} + \text{ExTime unaffected} }\\
&= \frac{1}{\frac{f}{s} + (1 - f)}, \text{ where } f : \text{ExTime affected}, s : \text{Improve rate}
\end{align*}
$$
---
### 效能總評
假設工作負載中每個程式的執行次數皆相同,則使用算術平均數(AM);若不是,則根據每個程式在工作負載中的出現頻率給予加權值,即使用加權平均數(WAM);平均數越小,代表機器效能越好。
同時評量2台以上機器的效能時,我們常會將某一部機器對某一程式的執行時間除以各機器的執行時間,稱為正規化得其比值,稱為spec ratio;spec ratio越大,代表機器效能越好。
$$
\text{spec ratio} = \frac{\text{ExTime referenced}}{\text{ExTime measured}}
$$
如果執行時間有被正規化,就不可再使用AM或是WAM做為總評的標準,因為會出現效能總評的矛盾,改使用幾何平均數(GM)
$$
\text{GM} = \sqrt[n]{\Pi^n_{i = 1} \text{} \text{spec ratio}_i}
$$
就能消除這個矛盾,因為GM具有此特性 \- 先取幾何平均再正規化 = 先正規化再取幾何平均,但GM就無法預測執行時間,且算出來的結果也不這麼準,因此當題目沒指定的話,還是以使用AM、WAM為準,使用GM是不得已的標準。
目前最普及的CPU效能評估程式就是SPEC(System Performance Evaluation Corporation)的benchmark(效能評估程式組),SPEC是由許多電腦廠商建立與支援的評效程式,目的是要為現代的電腦系統提供—組標準的評效程式,以SPEC CPU2000其中包括整數程式與浮點數程式的benchmark。
---
## ch4 單一時脈計算機
### 綱要
- 建構計算機的規格(ISA)與方法(抽象化設計)
- 建構計算機的基本零件 - register file, ALU, data memory, instrunction memory, adder, sign extension unit, PC
- CPU由datapath和control unit兩個電路單元組成。
- R-type, lw, sw, beq個別指令的datapath建構
- 合併R-type和lw,sw指令需要加入3個MUX
- 加上beq, jump指令需要加上各1個MUX
- 設計ALU control與main control內部電路
- main control有4條控制MUX、3條控制讀寫儲存體、2個控制ALU control
- ALU control有4條控制ALU要做的哪類運算
- 最長指令的時間做為single-cycle machine的minimum clock cycle time
- multiple cycle machine - 將每個指令拆成"執行時間較平均"的步驟(一個步驟只能使用一個主要功能單元)
---
### 建構計算機的規格(ISA)與方法(抽象化設計)
建構計算機要先搞清楚SPEC,這個SPEC就是ISA,**ISA = 指令集 + 根據指令集所制定硬體邏輯的規範**。我們要造計算機的指令集只有MIPS中的9個指令
1. 記憶體存取的lw, sw
2. 算數邏輯運算的add, sub, and, or, slt
3. 流程控制的beq, j
再來決定硬體規範
1. 暫存器 - 32個一般目的暫存器與特殊目的暫存器 - program counter,由於沒有mul指令,因此不包括特殊目的暫存器 - Ho, Lo。
2. 記憶體 - byte addressing(一個位置一個byte資料量),記憶體位置有32bit個資料量。
3. 指令格式 - R-type, I-type, J-type。
4. addressing mode - 包含有4個,register, base or displacement, PC-relative, pseudo-direct,但由於沒有立即版本的指令,所有沒有immediate。
建構計算機的方法使用**抽象化設計(design abstraction)**,是指設計複雜系統時先將系統較底層的細節隱藏以簡化設計時的複雜度。建構計算機時,並非拿電晶體造計算機,而是用數位邏輯建構出來的基本零件(ex: ALU, decoder)來造計算機,至於零件內部的細節不需要理會。
> 數位邏輯是拿邏輯閘當作基本元件,至於邏輯閘零件內部的細節不需要理會。
---
### 認識建構計算機的基本零件
1. **暫存器檔案(register file)**<br>
是一群暫存器的集合,MIPS R2000透過暫存器5個bit長度的編號可以讀出或寫入32個32位元的一般目的暫存器,支援同時讀出2個與寫入1個暫存器內容,另外還需要一個控制訊號來控制暫存器的寫入。
> 為什麼write要control線,但read就不用?<br>
假設不小心讀出來,只要不要有人誤用就沒事;但是寫入,只要不小心寫入,後面的人要讀入使用通通會錯,因此寫入要慎重,就需要控制訊號來控制。
2. **算數邏輯運算單元(ALU)**<br>
執行加、減、and、or、slt等算術與邏輯運算,一次允許2個32個bit的運算元運算,並由4個bit的控制訊號決定ALU要運算的類別;輸出除了一個32 bit的ALU result之外,還有一個1 bit的zero indicator,有點像是布林運算,當ALU result全為0時,zero indicator則為1,否則為0。
3. **記憶體(memory)**<br>
當建構computer的硬體架構不同,會用到的memory個數就不同,像是建構single cycle和pipeline都是使用2個memory;multiple cycle則是只需要使用1個memory。在此要建構single cycle拆分為2個部分,一是資料記憶體(data memory)、二是指令記憶體(instruction memory)。
- 資料記憶體(data memory)<br>
提供data的儲存的元件,資料可讀出或是寫入。**read控制線可要可不要,而課本是選擇resgister file不要,但data memory要**。
- 指令記憶體(instruction memory)<br>
照理說應該考慮一開始程式執行時,要如何將指令放入指令記憶體,但課本簡化元件,只有一個輸入,輸入要存取的指令位址;一個輸出,輸出指令。
> single-cycle machine在同一個cycle中,要在單一線路同時輸出指令與data,會導致控制訊號線出錯,因此需要將記憶體拆成兩部分。
4. **加法器(adder)**<br>
ALU雖然也可做加法,但有時候ALU自己也要計算,需要"助手"來減輕ALU運算負擔。加法器用於增加PC值 PC = PC + 4與計算branch target address。
5. **有號數擴充單元(sign extension unit)**<br>
將16 bit有號數擴充為32 bit有號數的元件,也就是複製16 bit有號數的MSB位元至所有空格(內部電路就是將MSB的線路分支到多出來的bit,理論上就不需要任何零件就可實現),因為ALU運算時要保證兩運算元都是同樣的bit數,才可正確運算。
6. **程式計數器(program counter, PC)**<br>
32 bit的特殊目的暫存器,永遠存放下一個要被執行指令所在的記憶體位址。
---
### CPU = datapath + control unit
CPU由datapath和control unit兩個電路單元組成。
1. **datapath** - 真正執行指令、處理資料的電路。
2. **control unit** - 9個指令會共用datapath,所以datapath裡面的零件是9個指令所需要零件的聯集,control訊號讓不同指令在datapath裡面執行時,只會通過該指令只要通過的零件,不會通過該指令不該通過的零件。
---
### 個別指令的datapath
先造出個別指令所需要的datapath,造完之後再經由合併成最後一個完整的datapath,此種方式稱為divide and conquer。
<br><br>
RTL(Register Transfer Language)只能描述資料從某一個儲存元件出發,中間經過基本算術運算(加減乘除,add, or, not)或是不經過運算,到達另一個儲存元件,其中儲存元件可以是暫存器或是memory。接下來要用RTL來描述datapath的行為。
1. **instruction fetch的datapath**<br>
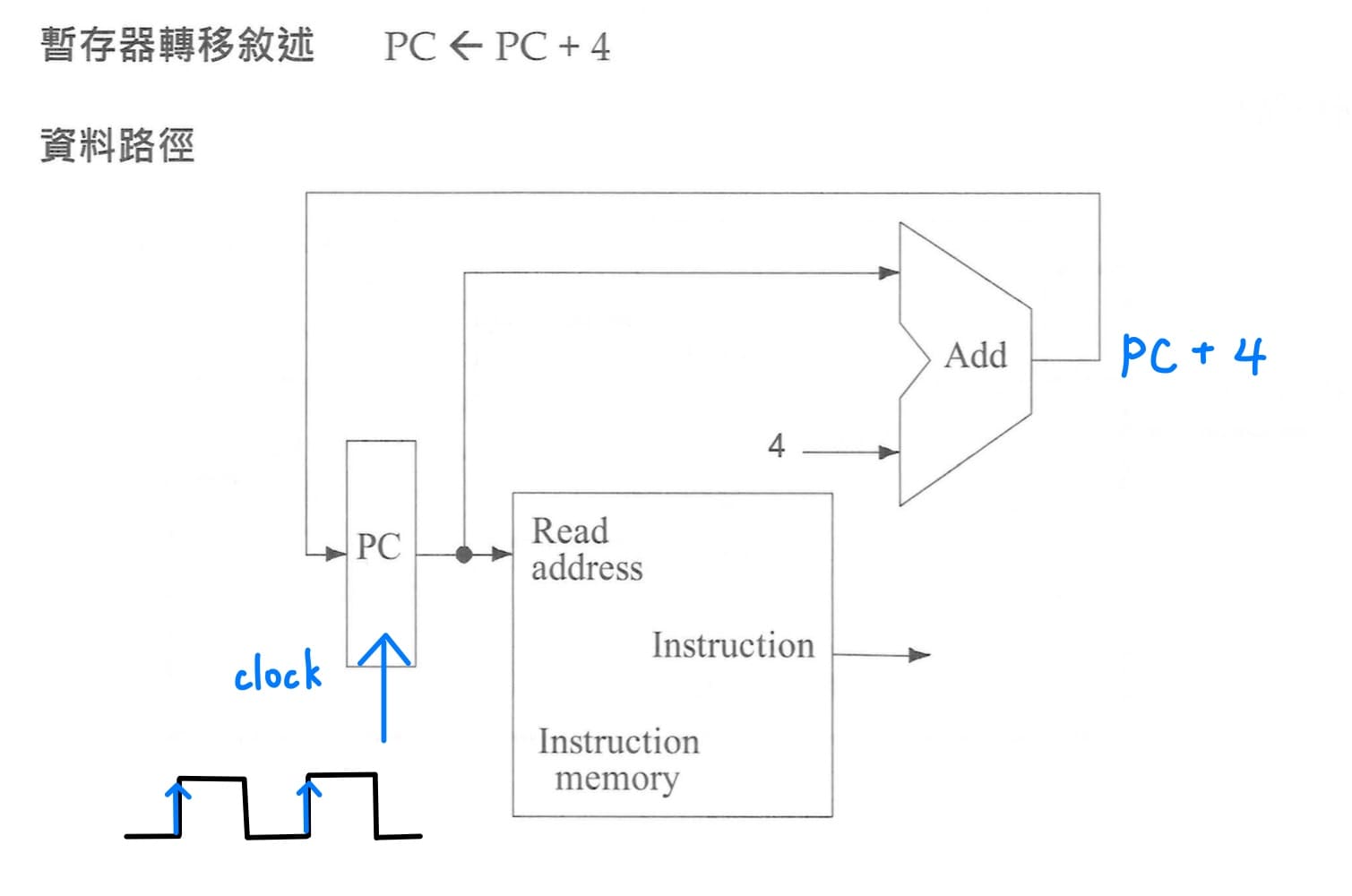<br>
任何指令的執行都需要先將指令從記憶體讀取出來,而program counter這個特殊目的暫存器提供當下要去哪裡抓記憶體的位置,每次指令從記憶體取出的同時,program counter會更新為PC = PC + 4,等到下一個clock來的時候,提供下一筆指令的位置。
2. **R-type指令的datapath**<br>
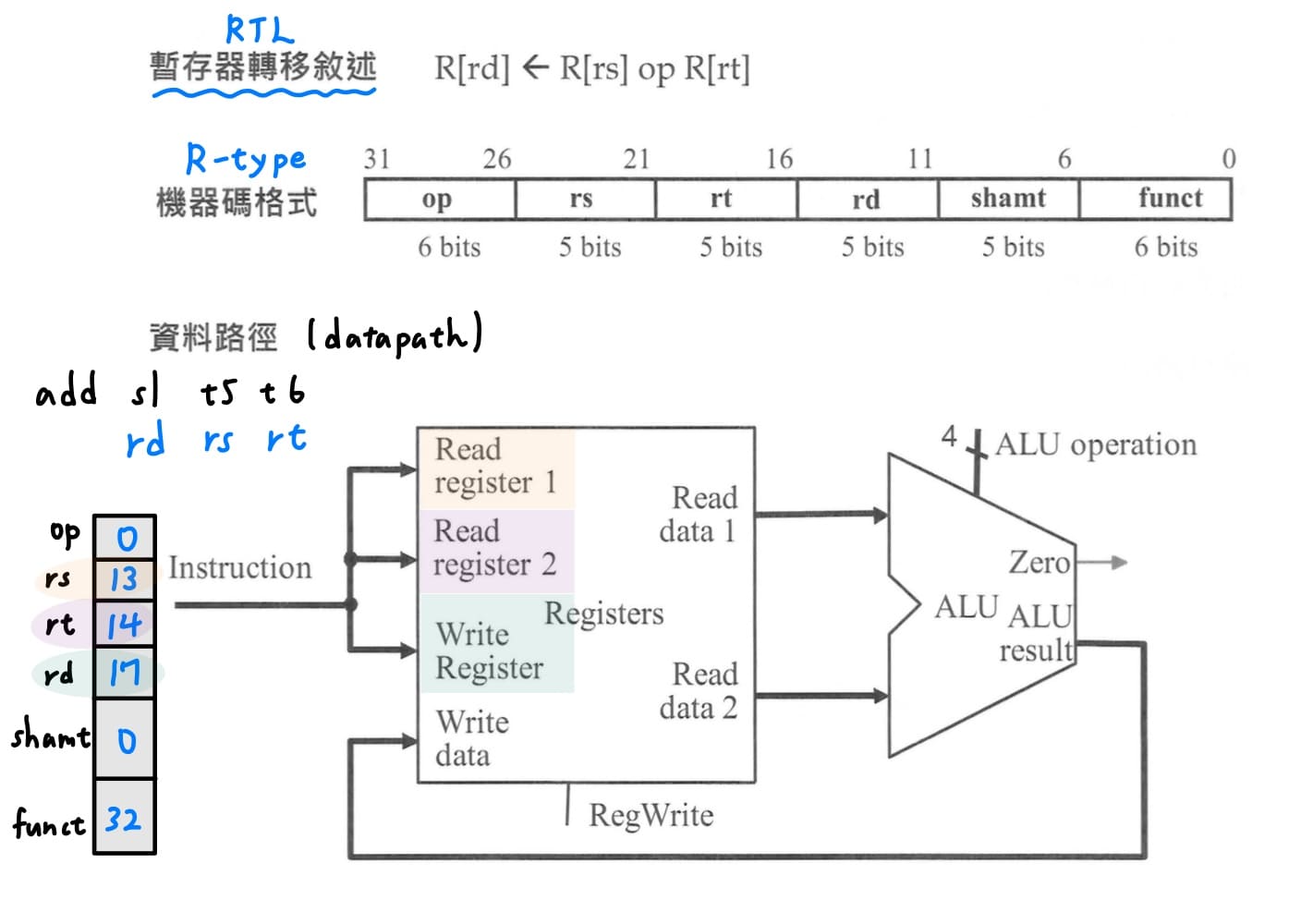<br>
R-type指令的rs和rt放要運算的暫存器號碼,把這兩個暫存器號碼分別放到read register 1和read register 2,抓出兩個要運算的暫存器內容,經過ALU做適當的運算(add, subtract, add, ...)後,拉回來寫入暫存器,寫入暫存器的號碼指定為rd。
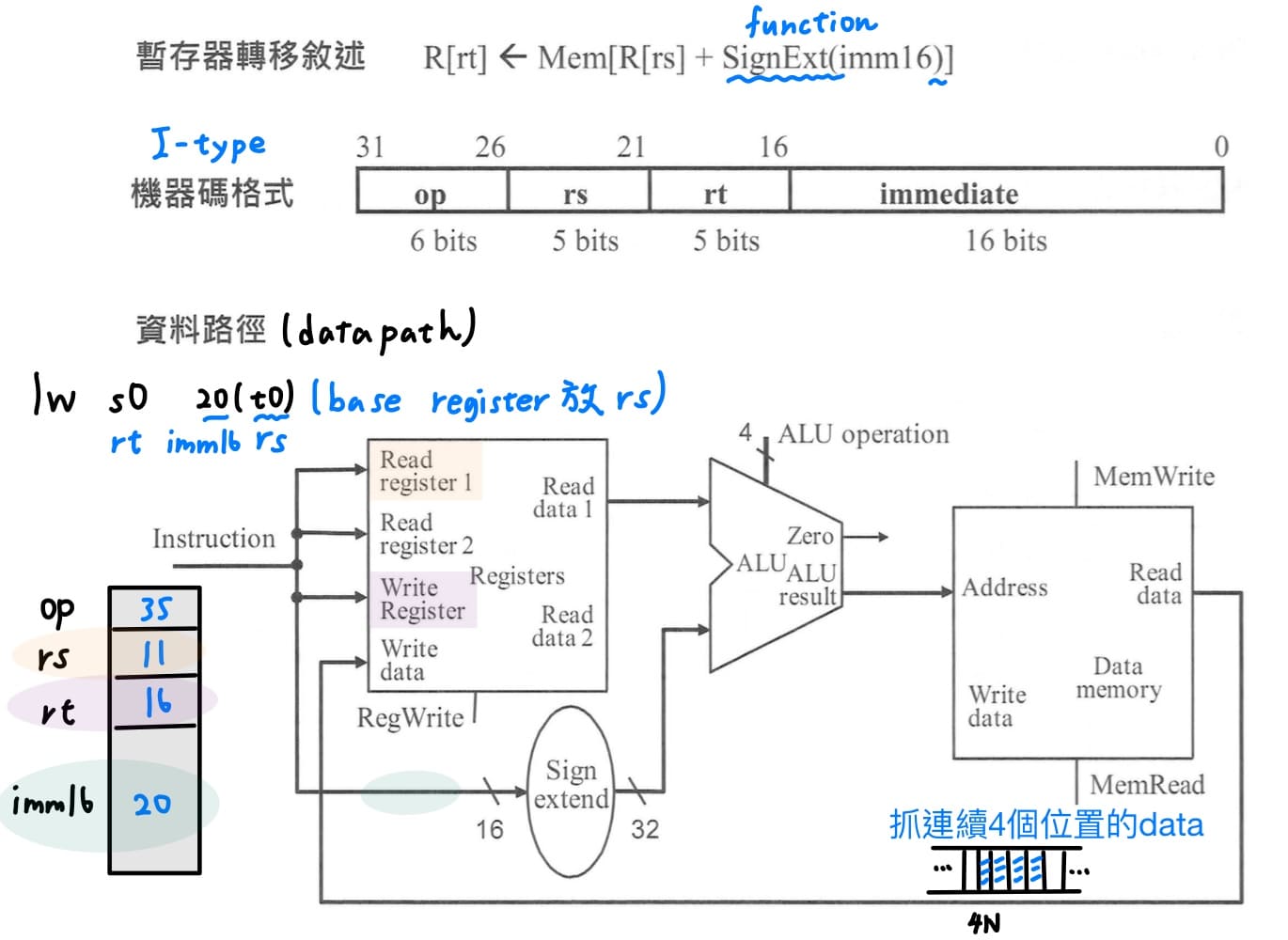
3. **load word指令的datapath**<br>
<br>
load word指令功能為讀取data memory內容並寫入暫存器,讀取記憶體的位置需要計算,I-type指令的rs放的是base register的號碼,放到read register 1,抓出base register的內容,放在ALU的上面;同時間把指令的常數imm16,經過sign extension unit擴充為32個bit,放在ALU的上面,讓ALU執行加法運算,ALU運算結果就是記憶體位址。根據這個記憶體位址到data memory把這個位址的data抓出來,送到write data,寫入暫存器。
<br><br>
至於rt放的是目的暫存器的號碼,所以要把rt拉到write register指定寫入暫存器的位置,另外還需要控制訊號線RegWrite設為1,才能成功寫入。
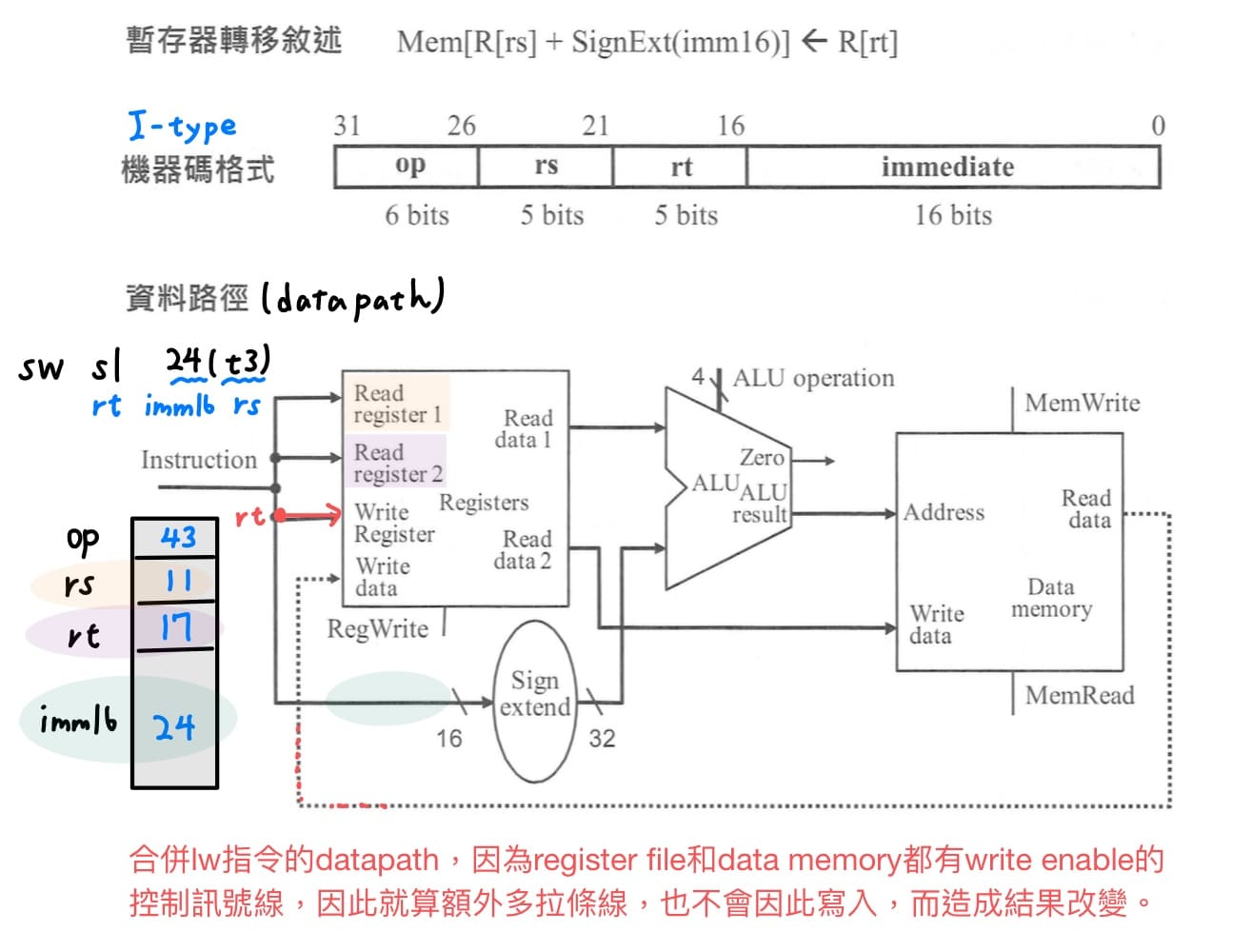
4. **store word指令的datapath**<br>
<br>
store word指令功能為把暫存器內容抓出來並寫入data memory,寫入記憶體的位置需要計算,I-type指令的rs放的是base register的號碼,放到read register 1,抓出base register的內容,放在ALU的上面;同時間把指令的常數imm16,經過sign extension unit擴充為32個bit,放在ALU的上面,讓ALU執行加法運算,ALU運算結果就是記憶體位址。
<br><br>
至於要寫入記憶體的暫存器號碼放在指令的rt,放到read register 2,抓出要寫入data memory的資料,把訊號送到data memory的write data輸入,另外還需要控制訊號線MemWrite設為1,才能成功寫入。
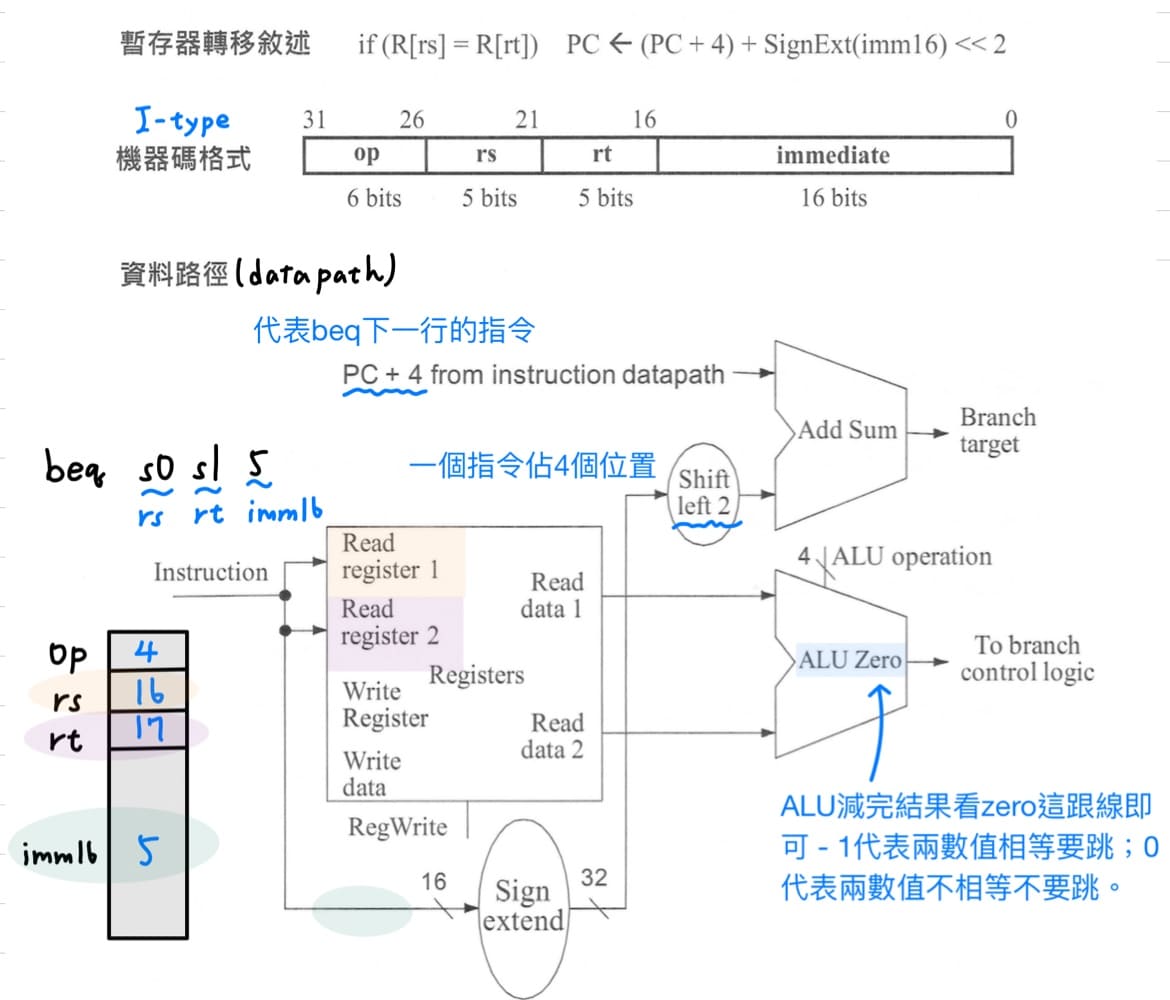
5. **beq指令的datapath**<br>
<br>
需要有2條路線同時進行 - 一是比兩個暫存器是否相等、二是計算跳躍目的的位置。
<br><br>
I-type指令的rs, rt放的是要比兩暫存器是否相等的暫存器號碼,送至read register 1和read register 2,抓出暫存器內容分別放入ALU的上面與下面,使用控制訊號線ALU operation,讓ALU執行減法運算,ALU減完結果若是0,zero線會變成1,代表兩暫存器數值相等,需要跳;ALU減完結果若是非0,代表兩暫存器數值不相等,不需要跳。
<br><br>
PC+4代表beq下一行的指令,放在adder的上面與I-type指令的常數imm16,經過sign extension unit擴充為32個bit,再向左移2個bit,代表乘以4,放在adder的下面,兩者相加就是跳躍目的的位置。
---
### 合併個別指令的datapath
1. **合併lw和sw指令**<br>
以lw的datapath基礎上把rt另外拉到read register 2,read data2輸出與write data輸入相連。因為register file和data memory都有write enable的控制訊號線,因此就算額外多拉條線,也不會因此寫入,而造成結果改變。
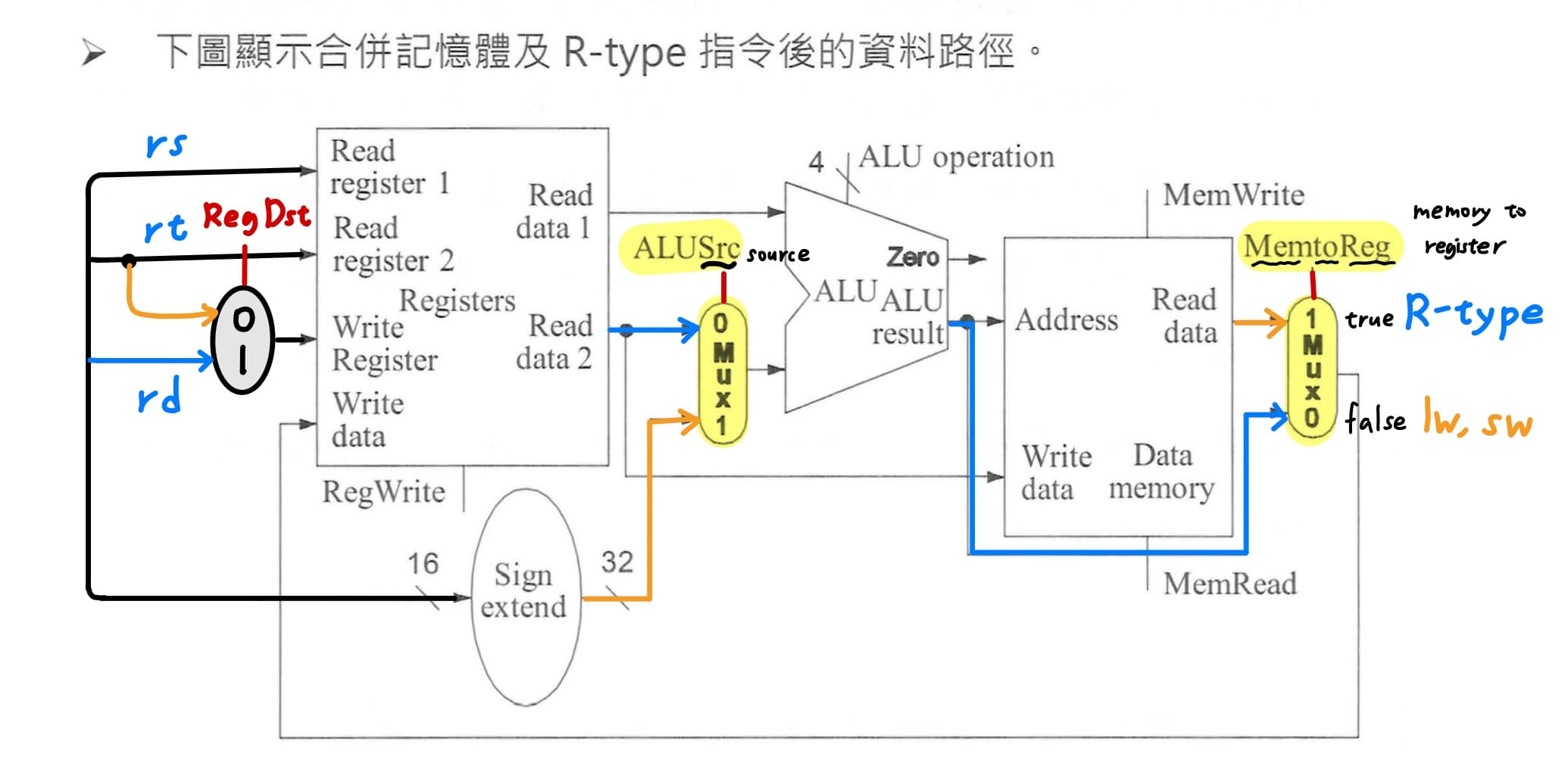
2. **合併R-type和lw,sw指令**<br>
<br>
觀察R-type和lw,sw指令,有3個"不同來源的資料要送到相同的地方"的衝突,因此就需要MUX,**MUX的功能是選擇多個輸入任一條作為單一輸出**。
|衝突發生位置|MUX的控制訊號|R-type指令的來源位置|lw和sw指令的來源位置|
|---|---|---|---|
|ALU下面的輸入|ALUSrc|register file讀出read data 2|經過sign extension後的常數imm16|
|register file中write data的輸入|MemtoReg|ALU運算後的結果|memory的read data|
|register file中write register的輸入|RegDst|R-type指令的rd欄位|I-type指令的rt欄位|
3. **加上ID, beq, j的datapath**<br>
最後依序加上instruction fetch, beq, jump的datapath,以及control unit線路。
<br><br>
beq指令的datapath有兩個主要功能,一是比兩者是否相等,此功能與R-type中減法指令相同,因此就可直接使用原本的datapath;二是計算跳躍目的位址,需要額外再加一個adder,將指令中imm16的相對位置向左移2個bit後與PC+4相加,算出實際跳躍目的位址。
<br><br>
此外還需要一個MUX來決定指令是否要跳與否,MUX的控制訊號是由branch控制訊號線與zero線做AND的結果,如果此指令是beq且兩暫存器相減為0,則MUX就會變為1,PC就會以跳躍目的位址做更新。
<br><br>
jump計算跳躍目的位址為`{NextPC[31:28], Instruction[25:0], 2'b00}`,首先將原指令中26 bit向左移增加2bit,右邊就會補0;再來將下一個指令最左邊4個bit的線路拉過來與原線路並排,就可合成出實際要跳躍的目的位址。
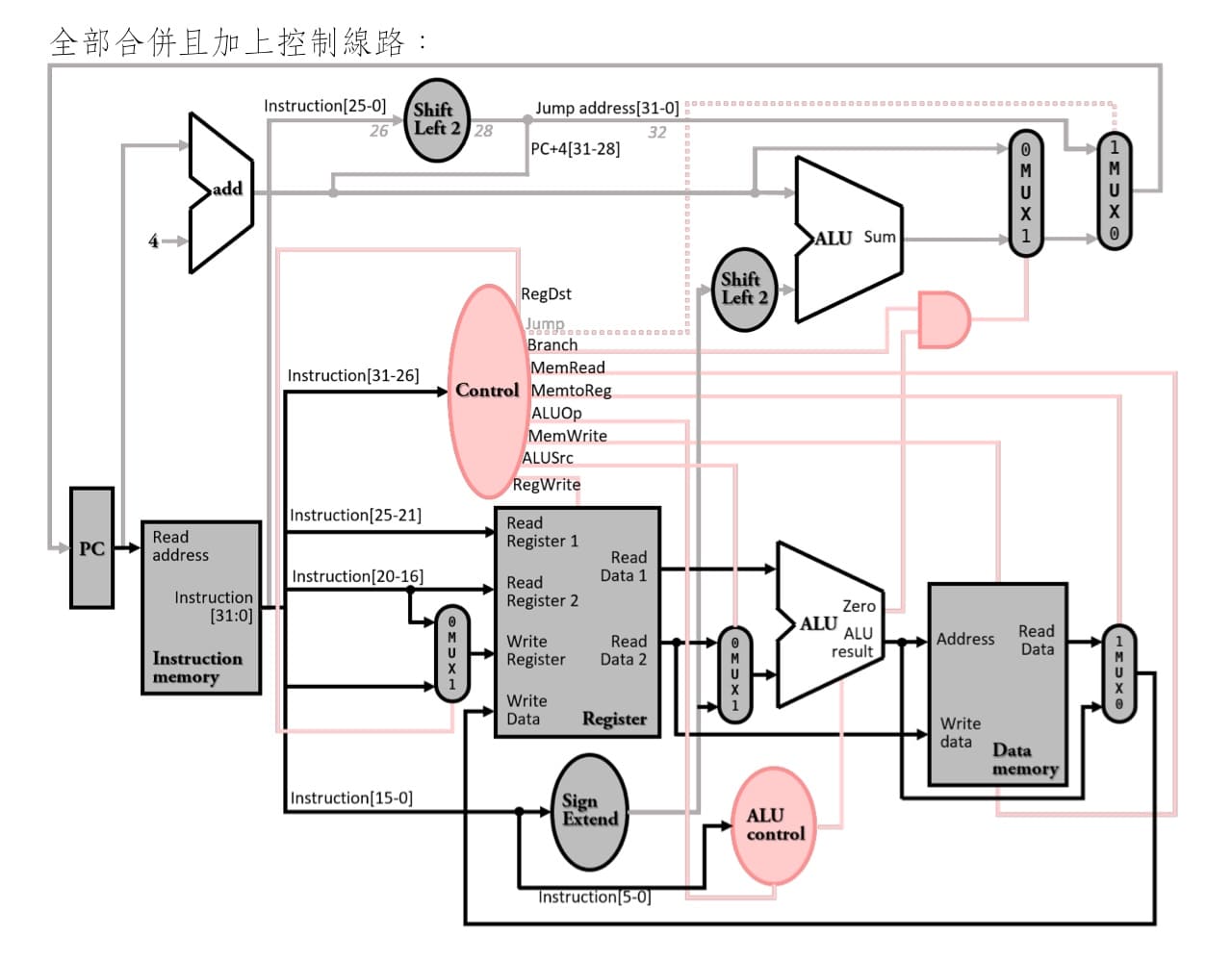
---
### control unit設計方式
multi-level control意思是將控制單元拆分為多個子單元,某一些控制子單元受控於另一個控制子單元,由於電路面積大小與輸入個數呈現指數正比,因此這樣設計就可降低控制單元電路面積大小,也可以加快控制電路的速度。
single-cycle machine使用multi-level control,拆成main control與ALU control兩個控制子單元,main control可藉由2個bit ALUOp的訊號線,控制ALU control。
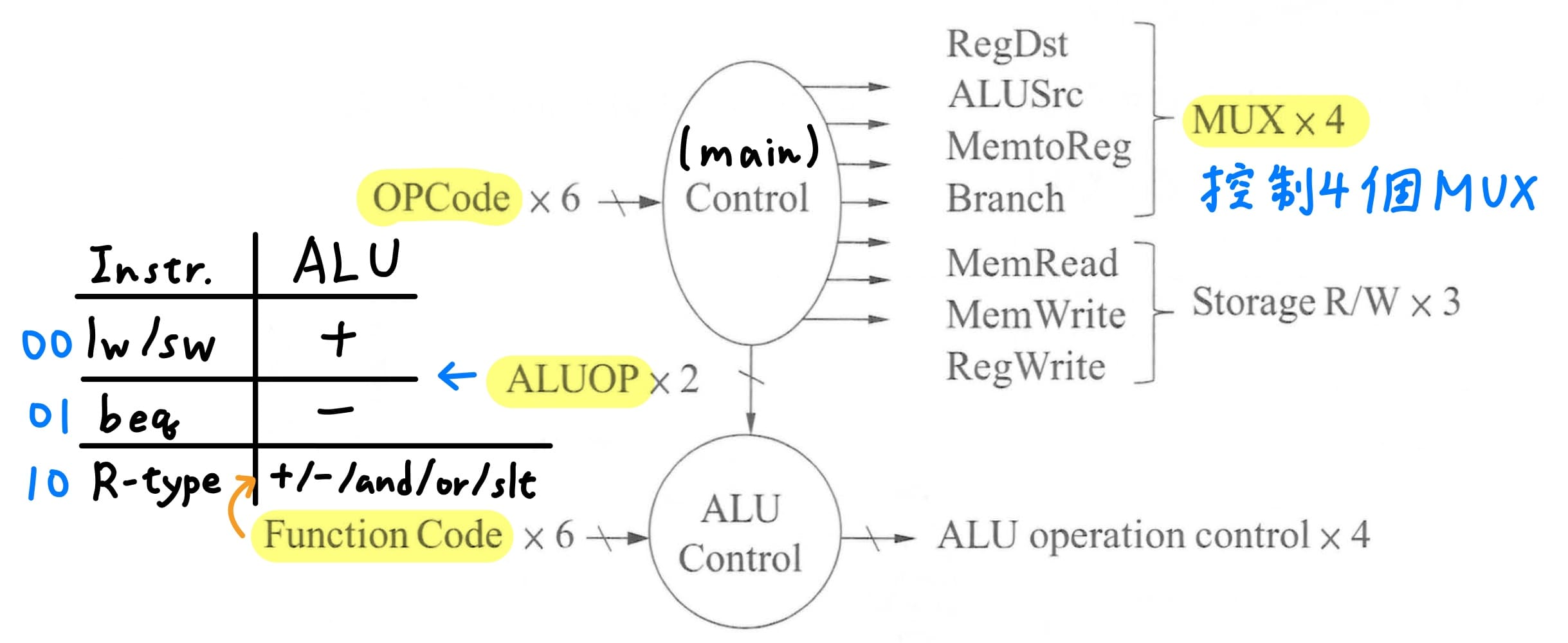
---
### 設計ALU control內部電路
main control根據指令中6 bit的opcode判斷出屬於哪個指令,並透過2 bit的ALUOp傳遞給ALU control。
|指令|ALUOp|ALU operation|
|---|---|---|
|lw/sw|00|+|
|beq|01|-|
|R-type|10|+ / - / and / or / slt|
若ALUOp為00,則ALU operation control會輸出給ALU控制訊號進行加法運算;若ALUOp為01,則ALU operation control會輸出給ALU控制訊號進行減法運算;若ALUOp為10,則會進一步根據R-type指令中6 bit的function field來判斷ALU要執行的運算。
因此就可建立6個輸入對4個輸出的truth table,改部分訊號don't care以在之後步驟獲得更大的化簡。由於沒有用到ALUOp為11的訊號線,就可改01 -> X1、10 -> 1X;在此計算機設計中,沒有用到function field第4、5個bit因此改為X。
由於輸入與輸出超過4個,無法用人工的K-map化簡,需要藉助Quine-McCluskey Tabular Method化簡,最後就可畫出最簡電路圖。
---
### 設計main control內部電路(不含jump的datapath)
main control的輸入為指令中6 bit的opcode,輸出則包含4條控制MUX的訊號線,分別是RegDst, ALUSrc, MemtoReg, PCSrc (Branch中MUX的控制訊號),以及3條控制基本元件讀寫的訊號線,分別是RegWrite, MemRead, MemWrite。
嘗試從CPU架構圖去trace各個指令資料流,就可得該指令需要設定的控制訊號,不過也可從控制訊號線的名稱來快速判斷,舉例來說MemtoReg設為1,代表data memory到register file的線是true,是通的;反之,MemtoReg設為0,代表data memory到register file的線是false,不通的,而是改由ALU result傳至register file。
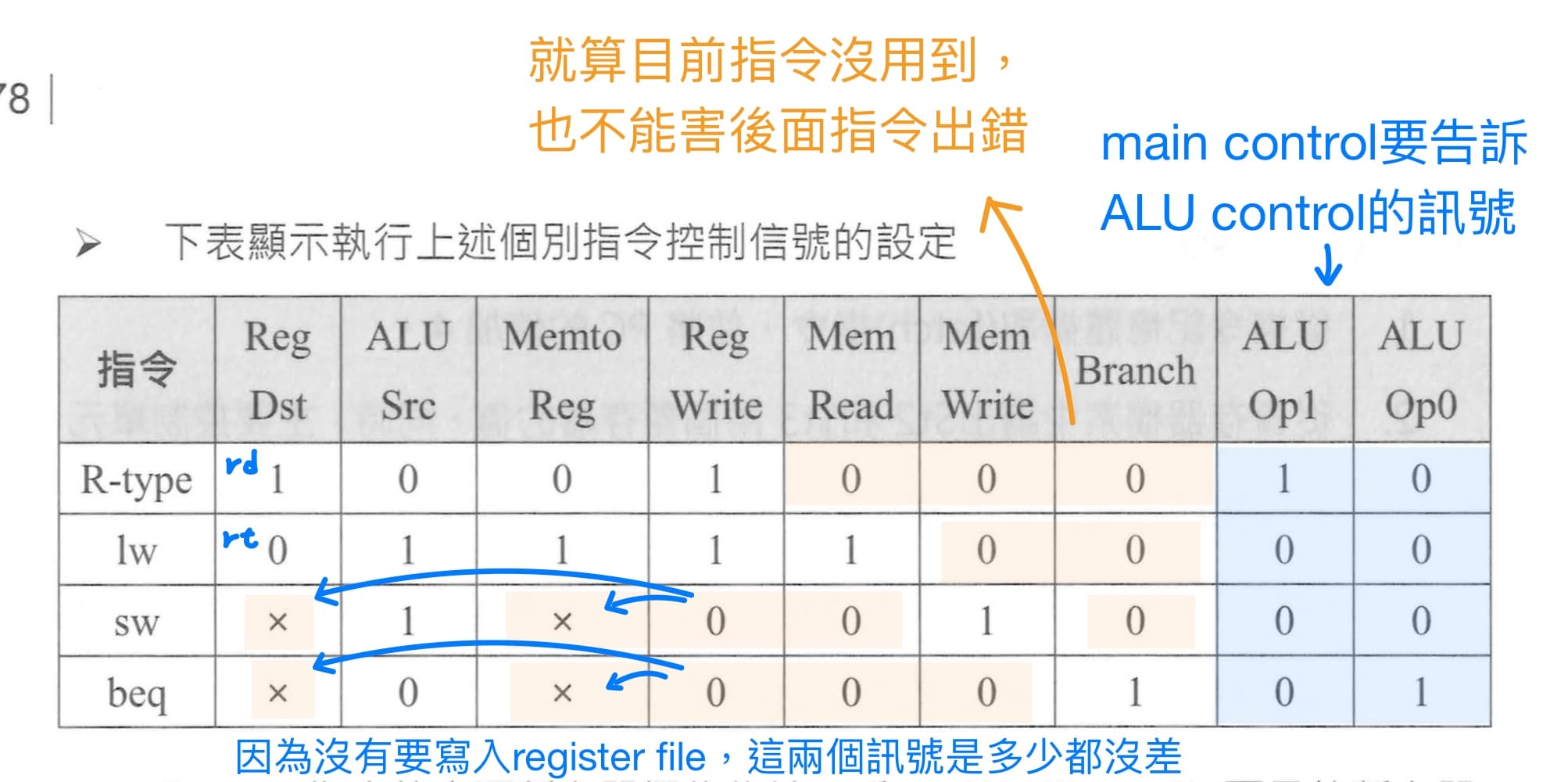<br>
接下來查表寫上各指令的opcode就可得到有輸入與輸出關係的truth table,在此不使用跟設計ALU control內部電路一樣的standard logic process,而是使用PLA,如此就可避免繁雜的化簡過程(Quine-McCluskey Tabular Method)。
PLA實作時,會放棄部分的don't care項,在此放棄全部的don't care項。
1. 有4個指令 ⇒ 拿出4個AND gate。
2. 當這個指令在執行時,要使這個AND gate輸出為1,其他為0。有0的地方要翻轉訊號。
4. 輸出1 - R-type執行則為1,不是R-type執行則為0。
4. 輸出2 - 非lw且非sw的指令執行時為0,因此將lw和sw做OR。
5. 接下來輸出以此類推。
> 實踐電路有3種方法
> 1. standard logic process - 化簡過程繁雜,但電路會最簡。
> 2. PLA - 介於兩者之間。
> 3. ROM - 過程最簡單,但硬體成本最高。
有jump的datapath的話,只要在原控制訊號線的基礎下加上jump訊號線即可,此外此計算機架構,"剛好"也可以執行addi指令。
參照課本P383練習,由於線路與ground line或是power line短路,就可能會產生訊號線永遠是0或是1,稱為stuck-at-0 / 1 fault,會造成以下影響,考試時需要自行判斷。

---
### single-cycle machine的效能評估
[ch3 效能定義](#效能定義)中在此效能的定義方式為execution time的倒數,而execution time = IC * CPI * cycle time;對於2部不同硬體實踐架構但同一ISA的機器,當要比較效能也就是execution time時,首先要確保跑的是相同的程式(組合語言),也就代表instruction count相同,因此真正要比的就是instruction time。
single-cycle machine顧名思義每個指令都只需要1個cycle的時間就可以完成,故CPI為1;而**用最長指令的時間做為single-cycle machine的minimum clock cycle time**,下圖分別trace這9個指令(R-type包含5個指令)的資料流
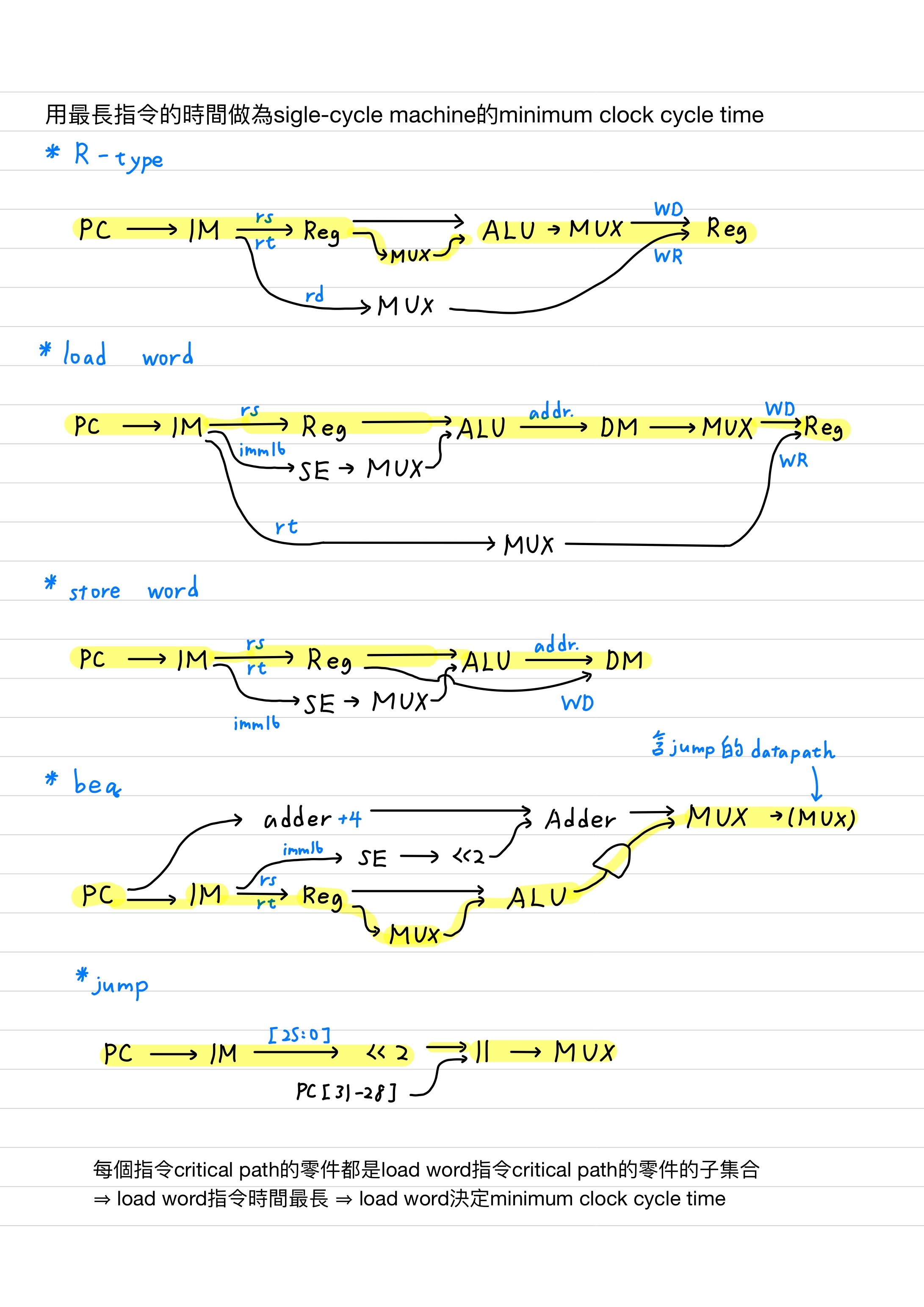
考試上會給各種零件需要運算的時間,如此從多個路徑計算,花最久的路徑就是critical path,就可計算critical path delay。由於每個指令critical path的零件都是load word指令critical path的零件的子集合,因此load word指令所需要花的時間最長,決定了minimum clock cycle time的時間。
---
### 考古題觀念
- **考題 P418 第25題 成大電機 - 如何控制data memory寫入?**<br>
觀察data memory寫入(sw)中的3個訊號時間來的順序
1. control unit速度最快,先送MemWrite訊號,開啟記憶體寫入,此時Write data和Address都是錯誤的,不對的位址寫入不對的資料。
2. 接下來Write data訊號過來,變成是對的資料複寫上不對的位址。
3. 最後Address訊號過來,才會是對的的資料複寫上對的位址。
由此可知一筆要寫入memory的資料除了寫到對的位址之外,還會寫到另一筆錯誤的位址。因此data memory要加clock,用clock邊緣來觸發資料寫入,避免一筆資料寫入2個不同記憶體的位址。同理register file也應該要加clock避免同一筆資料多寫入錯誤的位址。
在single-cycle machine中data memory要加clock,以同步MemWrite, Adress, Write data這三個訊號線,但在pipeline中EX/MEM的pipeline register會做好這3個訊號的同步工作。
---
### 練習 P389 台聯大電機
第1題題目問在"避免增加critical path的前提"下,是為了避免critical path增加,而影響到single-cycle machine的performance。接下來要計算最晚產生MemWrite的contro訊號線的時間,是因為不需要讓control unit那麼快產生控制訊號,讓main control的設計更有彈性,可以使用最差的IC製程技術,讓線做的最窄,電阻最大,使control unit的晶片面積縮小,降低成本,時間慢一點沒關係,只需要在時間內產生我所需要的控制訊號就好,而不影響clock cycle time,代表不影響single-cycle machine的performance。
第3題題目問"哪個訊號線需要最早產生?",首先畫出資料流
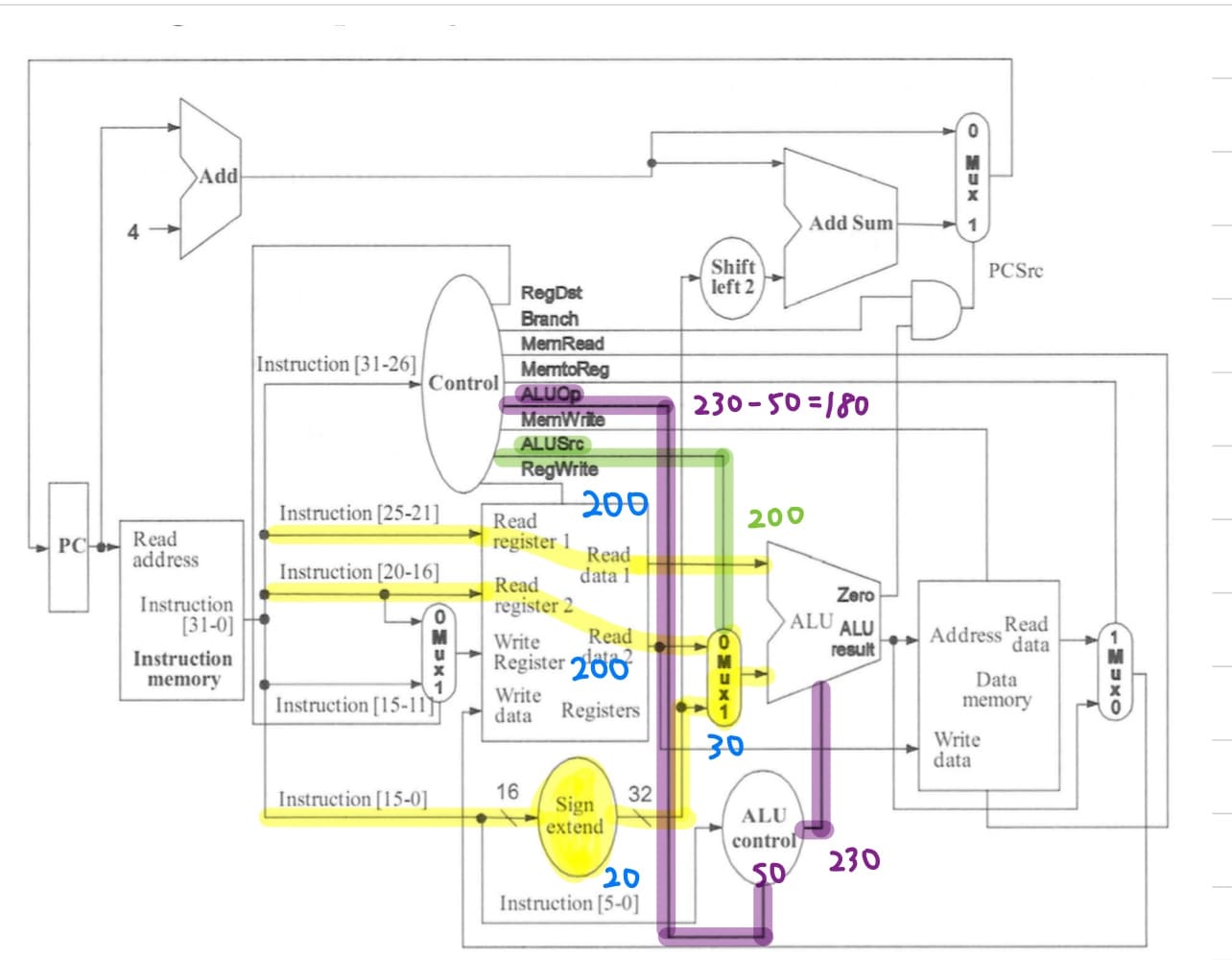<br>
讀取instruction memory抓出指令(不需要控制訊號線) -> 讀取暫存器(不需要控制訊號線) -> 開始計算(需要控制訊號線),因此最早需要產生控制訊號的是ALUSrc或是ALUOp。
> RegDst和RegWrite的控制訊號線跟寫入暫存器有關,不需要太早產生。
1. ALUOp最晚產生時間的計算<br>
送至ALU的運算元的critical path delay為230ps,代表控制訊號ALU operation control最晚要在230ps以前就要設定好;而ALU control需要花50ps運算,因此main conrol至少要在(230 - 50)ps就要將ALUOp設定好。
2. ALUSrc最晚產生時間的計算<br>
送至ALU src的MUX的critical path delay為200ps,代表main conrol至少要在200ps就要將ALUSrc設定好。
實際上,lw才是花最長的指令,而lw只會走rs和imm16那兩條,因此不可以算中間那條critical path,因此送至ALU的運算元的critical path delay為200ps,代表main control至少要在(200 - 50)ps就要將ALUOp設定好,但還是以原文書答案為主。
---
### multiple cycle machine
single-cycle machine固定clock cycle time為最長指令執行(lw)的時間,效率不佳,理想上是可變clock cycle time效能會最好,但實務上又造不出clock cycle time隨每個指令變動。因此退而求其次,想辦法讓長指令多用點時間,短指令少用點時間,只要有呈這個趨勢就好。
實踐方式就是將每個指令拆成"執行時間較平均"的步驟。課本提供分步驟的原則 - 一個步驟只能使用一個主要功能單元;因此clock cycle time由最長的主要功能單元時間所決定。
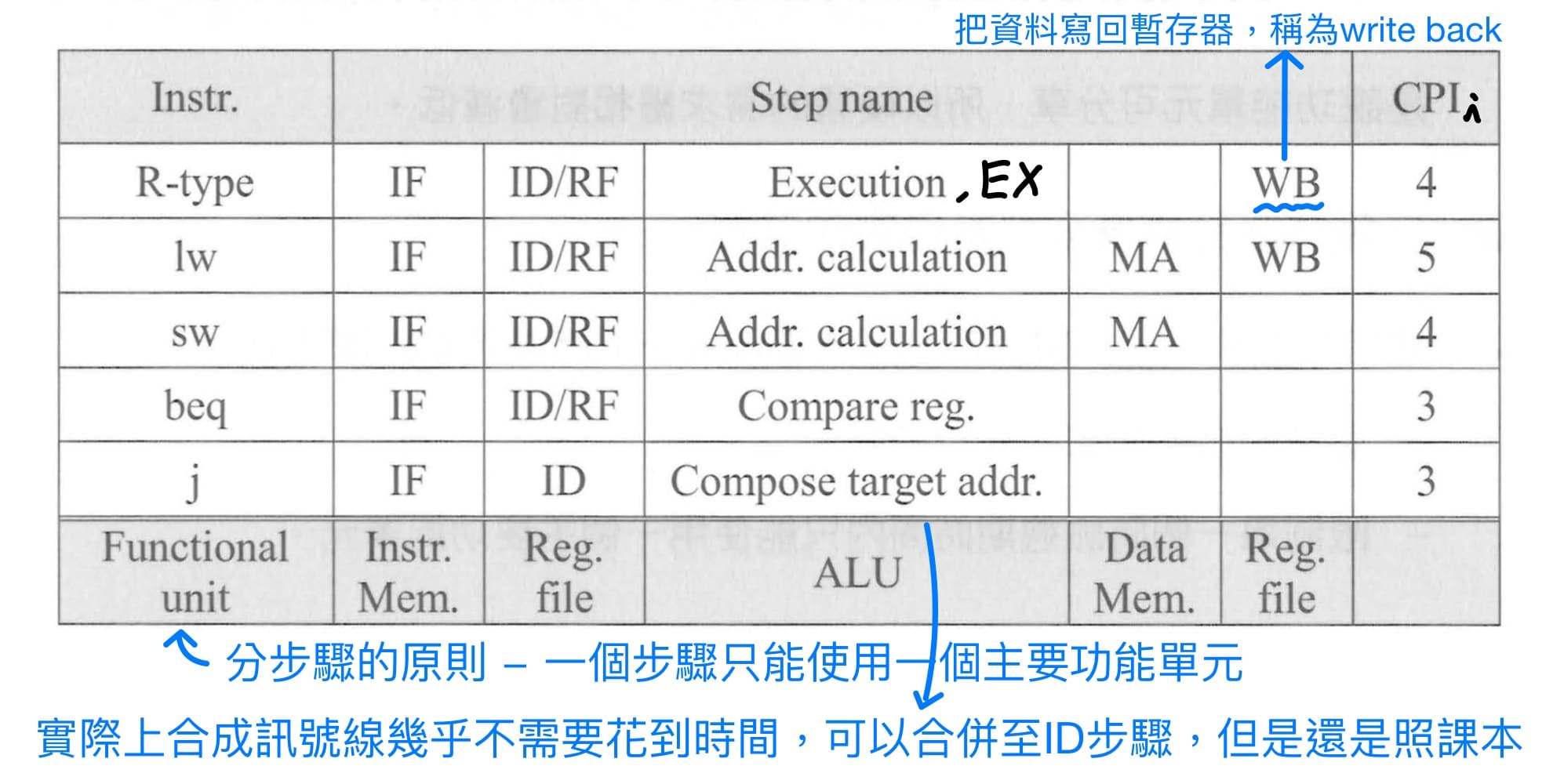<br>
其中IF = instruction fetch, ID = instruction decode, RF = register fetch, MA = memory access, WB = write back,個別指令所需要的CPI各不相同,需要注意切步驟時會有**額外的clock cycle time的時間**,這是因為每個步驟結束的時候,要把當下步驟的結果存入暫存器,在下一個clock來之後,提供給下一個步驟使用。
---
## ch5 管線化計算機
### 綱要
- pipeline對latency沒幫助,而是改善throughput
- pipeline分為5個stage - IF, ID, EX, MEM, WB
- pipeline的datapath設計(加上pipeline register、修正目的暫存器號碼)
- pipeline的control unit設計(把RegDst的MUX往下移至EXE階段,加上各stage的控制訊號線)
- structural hazard解法 - 加足夠硬體
- data hazard軟體解法 - 插入nop指令、重排指令順序
- data hazard硬體解法 - 非load-use指令使用forwarding
- data hazard硬體解法 - load-use指令使用stall + forwarding
- data dependency分類
- beq往前移以減少control hazard並解決變嚴重data hazard
- control hazard硬體解法 - 動態分支預測
- control hazard軟體解法 - 靜態分支預測、delayed branch與插入nop
- 增加ILP的方法 - superpipeline、multiple issue
- 增加ILP的方法 - speculation = 猜某個指令的性質,來決定跟這個指令相關後續的指令可以提早被執行
- static multiple issue - MIPS-64、VLIW、IA-64
- dynamic pipeline scheduling的三大步驟 - in-order issue、out-of-order execute、in-order commit
- 處理exception的步驟分為硬體與OS的部分
- pipeline處理exception的步驟
---
### pipeline的特性與效能評估
pipeline是一種計算機的實作技術,允許多個指令同時存在於datapath裡面,使指令重疊地、平行地被執行。pipeline跟multiple cycle machine一樣,需要將single-cycle machine分成若干階段,分步驟的原則是時間要平均分配 - 一個步驟只能使用一個主要功能單元,而最長步驟的時間就是pipeline的clock cycle time。
**pipeline並不會對單一個指令的執行時間(latency)有所幫助,反而會比single-cycle machine的latency還長**,因為每個pipeline的每個stage執行結束後,會卡在"柵欄"上,等下一個CLK來,柵欄"打開才能繼續執行。**pipeline是藉由多個指令在pipeline中使用不同部分的硬體資源,以提高硬體使用率,以增進整體工作的生產量(throughput)**。
假設pipeline不會停下來(stall),也就是理想pipeline的機器,給定週期時間$T$,$S$個stage,$N$個指令要執行,則
$$
\text{execution time} = [(S - 1) + N] \times T
$$
在尚未填滿pipeline的時候,沒有指令執行完畢,有$S - 1$個stage;接下來每個stage,也就是每隔一個cycle cycle就會有一條指令執行完畢。
$$
\text{(average) CPI} \triangleq \frac{\text{clock cycles}}{\text{instruction count}} = \frac{(S - 1) + N}{N}, \text{if } N \to \infty, \text{CPI} = 1
$$
平均CPI根據原始定義 - clock cycle個數除以指令個數計算,當指令越多時,平均CPI會趨近於1,也就是趨近single-cycle的CPI,但需要注意這裡是指平均CPI,而非單一指令執行的clock cycle數。
$$
\text{speedup} \triangleq \frac{\text{ExTime of single-cycle machine}}{\text{ExTime of pipeline}} = \frac{S \times N \times T}{[(S - 1) + N] \times T}, \text{if } N \to \infty, \text{speedup} = S
$$
從上式可知,pipeline的stage切越多,$S$越大,代表cycle time越短、clock rate越高,instruction rate越高,throughput(單位時間執行的指令數)越高,performance會越好。但是由於dynamic dissipation公式$P = \alpha C V_{DD}^2 f_{sw}$中,功率消耗與clock的頻率成正比,因此clock rate越高,CPU的功率就會提高,造成負面影響,這便是一個performance與power之間的trade-off。
---
### pipeline的datapath設計
根據一個步驟只能使用一個主要功能單元的原則,在MIPS指令執行時分為5個步驟
1. IF, instruction fetch - 從instruction memory中擷取(fetch)指令。
2. ID, instruction decode - control unit解碼指令,同時間RF, register fetch,從register file中擷取(fetch)暫存器內容。
3. EX, execute - R-type指令ALU執行運算,lw/sw指令計算記憶體位址,beq指令比兩暫存器是否相等。
4. MEM, memory - data memory的存取(access)。
5. WB, write back - 把data寫回register file。
劃分完stage後,要在相鄰的stage之間加上pipeline register,來儲存上一stage的執行結果,並在下一clock來之後提供下一個stage使用。pipeline register以相鄰的兩個stage來命名,其容量需要能夠容納上一stage的資料。
接下來會出現一個問題 - WB stage的指令無法寫入自己的目的暫存器,而是會寫入正在占用ID stage的指令的目的暫存器。解法 - 在ID stage選完的目的暫存器號碼,跟著指令沿著pipeline傳下去,最後在WD stage再往回拉,指定目的暫存器號碼。
---
### pipeline的control unit設計
設計完pipeline的datapath,接下來是設計pipeline的control unit,與single-cycle machine的訊號線一樣,差別只在於pipeline在ID階段control unit解完碼後,這些控制訊號線需要跟隨指令沿著pipeline傳下去,直到指令執行完畢。
需要注意要把原本在single-cycle machine中RegDst的MUX往下移至pipeline的EXE階段。假設main control需要花的時間特別長,dominate任何主要功能單元的時間,因此決定pipeline的clock cycle time,如果main control解完碼後,又用拉到RegDst的MUX去控制,還需要MUX的延遲時間,導致pipeline又需要多花上MUX的延遲時間,clock cycle time更長,這並不是一個很好的設計。
因此把MUX往後拉,在ID階段main control專心解碼就好,不用再弄其他控制訊號線,把MUX往後移一個stage到EX階段即可,也不需要刻意移到更後面的stage,因為這會導致pipeline register要額外的空間存rd和rt這64 bit的data。
因此各個stage需要設定的控制訊號線為
|stage|IF|ID|EX|MEM|WB|
|:-:|:-:|:-:|:-:|:-:|:-:|
|control<br>signal|X|X|ALUOp0<br>ALUOp1<br>ALUSrc<br>RegDst|MemRead<br>MemWrite<br>branch|MemtoReg<br>RegWrite|
畫出MIPS指令集5個stage pipeline的"原始設計",而branch在MEM時決定要不要跳。
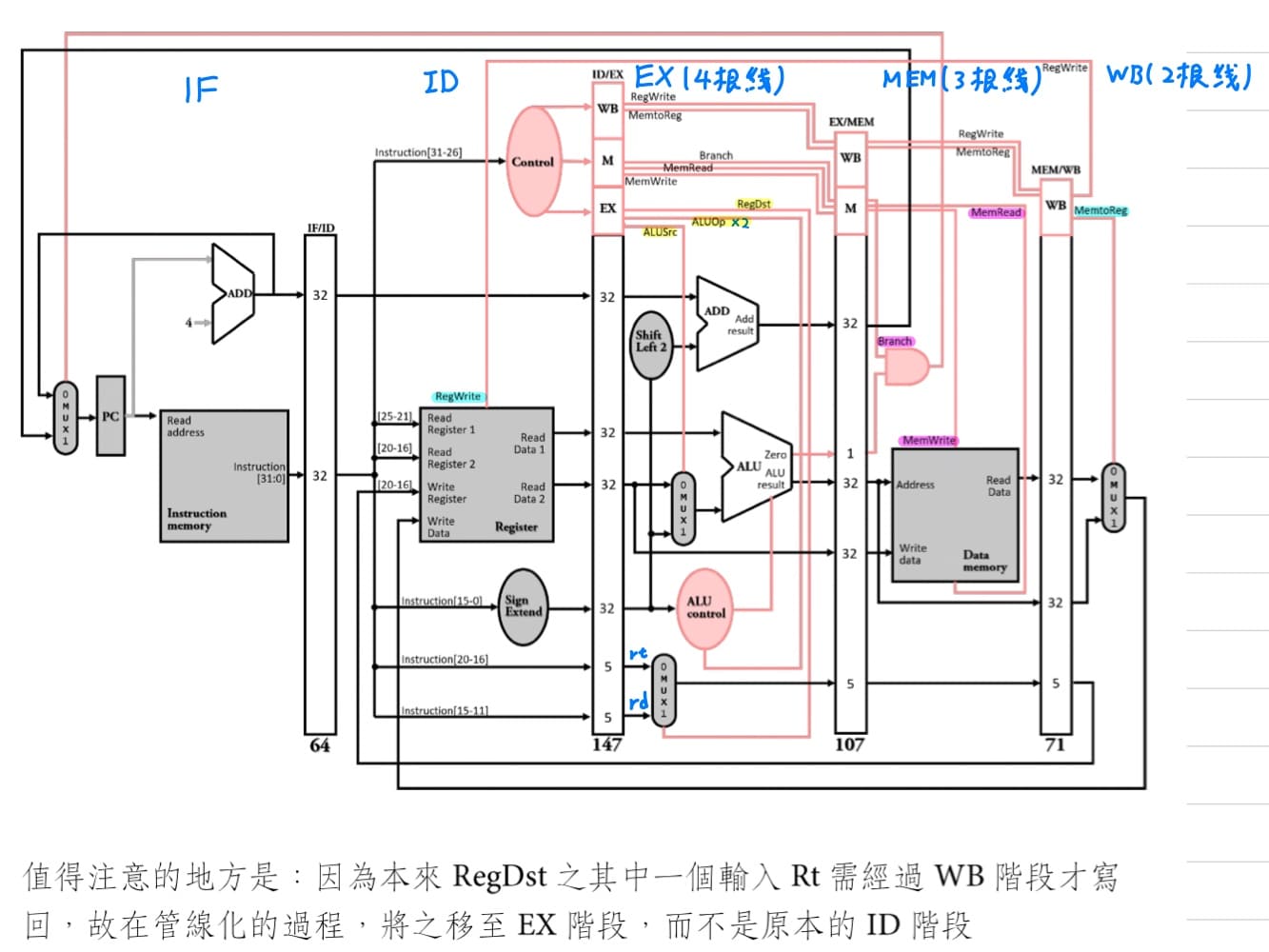<br>
總結畫pipeline的"原始設計"的圖有4個步驟
1. 先畫出single cycle machine。
2. 主要功能單元後面插入pipeline register。
3. 目的暫存器號碼問題修正。
4. 把RegDst的MUX往下移至EXE階段,加上各stage的控制訊號線。
接下來探討一個問題 - 在single-cycle machine中,一個指令既要讀又要寫register file,在同一個clock發生2次硬體資源access的衝突。解決方法 - 把讀與寫的時間錯開,**register file在clock前半周寫,在clock後半周讀**。
同理pipeline,我們把register file設計在clock前半周寫、在clock後半周讀,所以WB stage的指令在clock前半周寫,ID stage的指令在clock後半周讀,時間上會錯開,因此不會產生register file硬體資源在同一時間access的衝突。
---
### pipeline的hazard
hazard為pipeline不能在下一個clock執行下一道指令的狀況,分為以下3類
1. structural hazard<br>
硬體資源不足,導致相同時間點多個指令存取相同硬體資源。
2. data hazard<br>
因為指令之間存在data dependency,後面指令要用到前面指令的資料,但是前面指令還沒有產生。
3. control hazard<br>
branch指令走到MEM stage才知道後面指令要跟誰,但此時後面指令已經跟上了,如果branch一跳,後面指令就跟錯了,因為這個順序是錯的,程式就沒辦法執行。
不論是哪種pipeline的hazard都可以藉由暫停(stall)來避免,但是暫停pipeline會造成clock cycle數目變長,進而影響pipeline的performance,因此接下來對各種hazard要使用更有效的解決方式,在確保能解決問題的前提下,也不會影響到過多的performance。

---
### structural hazard
假設我們只有一個記憶體,而非像前面single-cycle machine或是pipeline一樣有兩個分離的記憶體,則在一指令IF階段與另一指令MEM階段時,需要同時read相同的硬體資源,造成structural hazard。
解決方法1加入足夠多的硬體;解決方法2是讓先進入pipeline的指令有較高使用硬體資源的priority,而讓將會發生structural hazard後進來的指令先stall。
---
### data hazard
- **產生條件**<br>
1. 資料存在data dependency - 後面指令的來源暫存器(rs, rt)有用到前面指令的目的暫存器(rd)。
2. 指令之間距離小於等於2。(register file設計是clock前半周寫,在clock後半周讀,因此一直到WB stage的指令與ID/RF stage的指令才不存在data hazard)
而sw, beq一定不會和後面指令發生data dependency,因為沒有寫入暫存器的動作。
1. **軟體解決 - 插入nop指令**<br>
nop泛指不改變暫存器的內容、memory的內容、指令的執行順序的指令,例如`addi $0, $0, 0`,`sll $0, $0 0`,而MIPS選擇`sll $0, $0 0`作為nop指令,翻成指令的機器語言剛好全都是0。採用nop指令解data hazard的優點是簡單,但缺點是會占用clock cycle,讓效率變差。
---
2. **軟體解決 - 重排指令順序**<br>
藉由不影響程式執行的正確性下,將指令執行順序重新排列,使會產生data hazard的instruction pair距離拉大於2,若重排指令還是未能解決data hazard,就只好插入nop指令。關於"**不影響程式執行的正確性"判斷方式有3項**,檢查指令1的目的和指令2來源暫存器、指令1的來源和指令2目的暫存器、指令1的目的和指令2目的暫存器,是否相等,若有均不相等則兩相鄰指令就可以對調順序。
---
3. **硬體解決 - 非load-use使用forwarding / bypassing**<br>
前一個指令還在pipeline中執行,尚未將正確結果寫入暫存器,但下一個指令已經緊跟在後面,而在ID(RF)階段存取到尚未更新的暫存器內容,因而產生data hazard。但觀察上一指令,假設上一個指令是R-type指令,**早已於EX stage完成運算得到運算結果**,因此我們嘗試直接拉一條線稱為forwarding path,將EX stage完成運算得到運算結果趕緊forward回前面要執行運算的EX stage,以"**即時修正**"改掉存取到錯誤暫存器內容的值。
首先需要有一個forward unit的控制單元來偵測是否需要forward,分別偵測EX stage和MEM stage之間、EX stage和WB stage之間有沒有存在data hazard。課本沒有實踐forwarding unit的內部電路,但有寫偵測碼來描述電路行為。
- **EX hazard**<br>
1. 前面指令一定要寫入暫存器,可以看在EX/MEM暫存器中控制訊號線RegWrite是否為1。
2. 不需要forward 0號暫存器欲先計算的內容,因為0號暫存器無法寫入任何數值,永遠都是常數0,因此前面指令的目的暫存器不能是0,可以看在EX/MEM暫存器的rd數值。
3. 前面指令的目的暫存器號碼跟後面指令的來源暫存器號碼一樣,可以看EX/MEM暫存器的rd與IF/ID暫存器的rt或是rs有沒有相同。
綜合以上3個條件可得EX hazard的偵測碼
```verilog
if (EX/MEM.RegWrite & (EX/MEM.RegisterRd != 0) & (EX/MEM.RegisterRd = ID/EX.RegisterRs))
ForwardA = 10
if (EX/MEM.RegWrite & (EX/MEM.RegisterRd != 0) & (EX/MEM.RegisterRd = ID/EX.RegisterRt))
ForwardB = 10
```
- **MEM hazard**<br>
MEM hazard的偵測碼與EX hazard的偵測碼觀念相同,差別只是將pipeline register從EX/MEM換成MEM/WB,而輸出的ForwardA、ForwardB從10改成01。此外需要再加上第4個條件 - **對相同欄位中,如果EX hazard發生,就不會再發生MEM hazard**,也就是對相同欄位中不存在EX hazard,因為前前一個指令的目的暫存器已經會被前一個指令的目的暫存器所複寫,所以目前指令使用的來源暫存器只會與上一個指令的目的暫存器產生data dependency。
```verilog
if (MEM/WB.RegWrite
and (MEM/WB.RegisterRd != 0)
and not (EX/MEM.RegWrite & (EX/MEM.RegisterRd != 0) & (EX/MEM.RegisterRd = ID/EX.RegisterRs))
and (MEM/WB.RegisterRd = ID/EX.RegisterRs))
ForwardA = 01
if (MEM/WB.RegWrite
and (MEM/WB.RegisterRd != 0)
and not (EX/MEM.RegWrite & (EX/MEM.RegisterRd != 0) & (EX/MEM.RegisterRd = ID/EX.RegisterRt))
and (MEM/WB.RegisterRd = ID/EX.RegisterRt))
ForwardB = 01
```
最後在EX stage的forward unit的輸出會控制ALU運算元前面的3對1的MUX,ForwardA控制ALU第一個運算元的數值,ForwardB控制ALU第二個運算元的數值,若為00則代表不需要forwarding,按照原本在ID stage抓取的暫存器數值計算;若為01則代表存在MEM hazard,需要在前前一個指令的WB stage往前forward給目前指令,在ALU運算之前及時更正運算元;若為10則代表存在EX hazard,需要在前一個指令的MEM stage往前forward給目前指令,在ALU運算之前及時更正運算元。
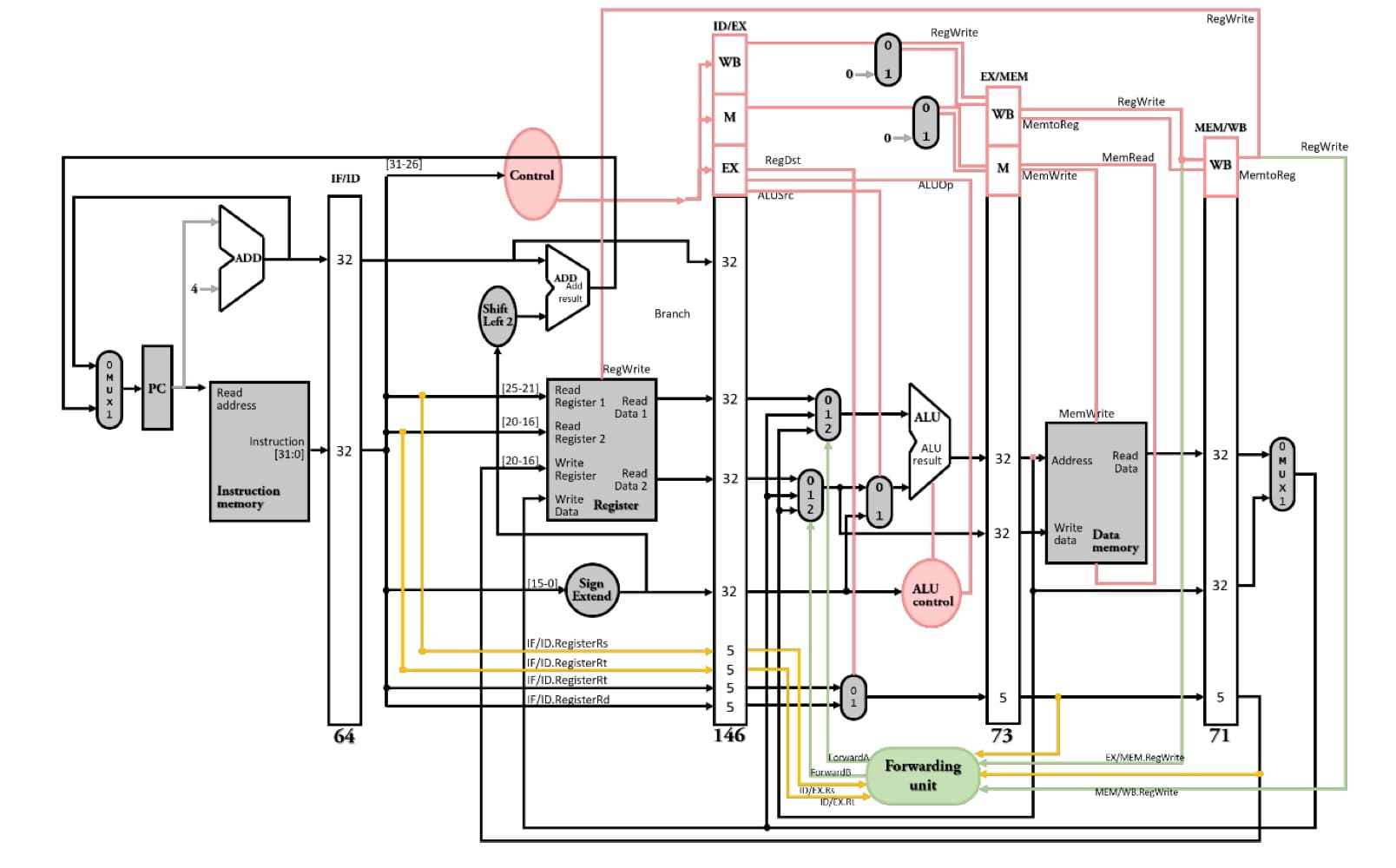
> 需要注意當pipleline的stage數越多,解決data hazard的代價就越大。
---
4. **硬體解決 - load-use使用stall + forwarding**<br>
當lw指令緊跟著"來源暫存器等於lw的目的暫存器"的指令,則稱為load-use data hazard。前一lw指令在MEM stage讀取資料的同時,目前指令已經在EX stage執行運算了,也來不及拉forwarding path及時救,需要一個clock的延遲時間,停掉IF stage和ID stage的指令,讓後面的指令繼續執行(這個暫停的行為稱為stall或是pipeline stall),等到前一個lw指令已經從記憶體抓到正確的數值後,在lw的WB stage階段拉forwarding path回來及時更正在EX stage執行運算的目前指令。
首先需要有一個hazard detection unit的控制單元來偵測是否需要stall指令。課本沒有實踐hazard detection unit的內部電路,但有寫偵測碼來描述電路行為。
1. 前面指令為lw指令,可以看在ID/EX暫存器中控制訊號線MemRead是否為1。
2. 前面指令的目的暫存器與目前指令的來源暫存器rs, rt是否相同。
綜合以上3個條件可得load-use data hazard的偵測碼
```verilog
if (ID/EX.MemRead and
((ID/EX.RegisterRt = IF/ID.RegisterRs) or (ID/EX.RegisterRt = IF/ID.RegisterRt)))
stall the pipeline
```
若是檢測發生load-use data hazard,在ID stage的hazard detection unit,其中2條輸出線`PCWrite`與`IF/ID.Write`會控制PC和IF/ID pipeline register不要正常接收到clock訊號,因此還是會保留原來暫存器的數值;其中1條輸出線`Stall`會把接在lw後面指令的9根控制訊號線全清為0,也就是殺掉原本指令改成對程式執行無任何影響的nop。
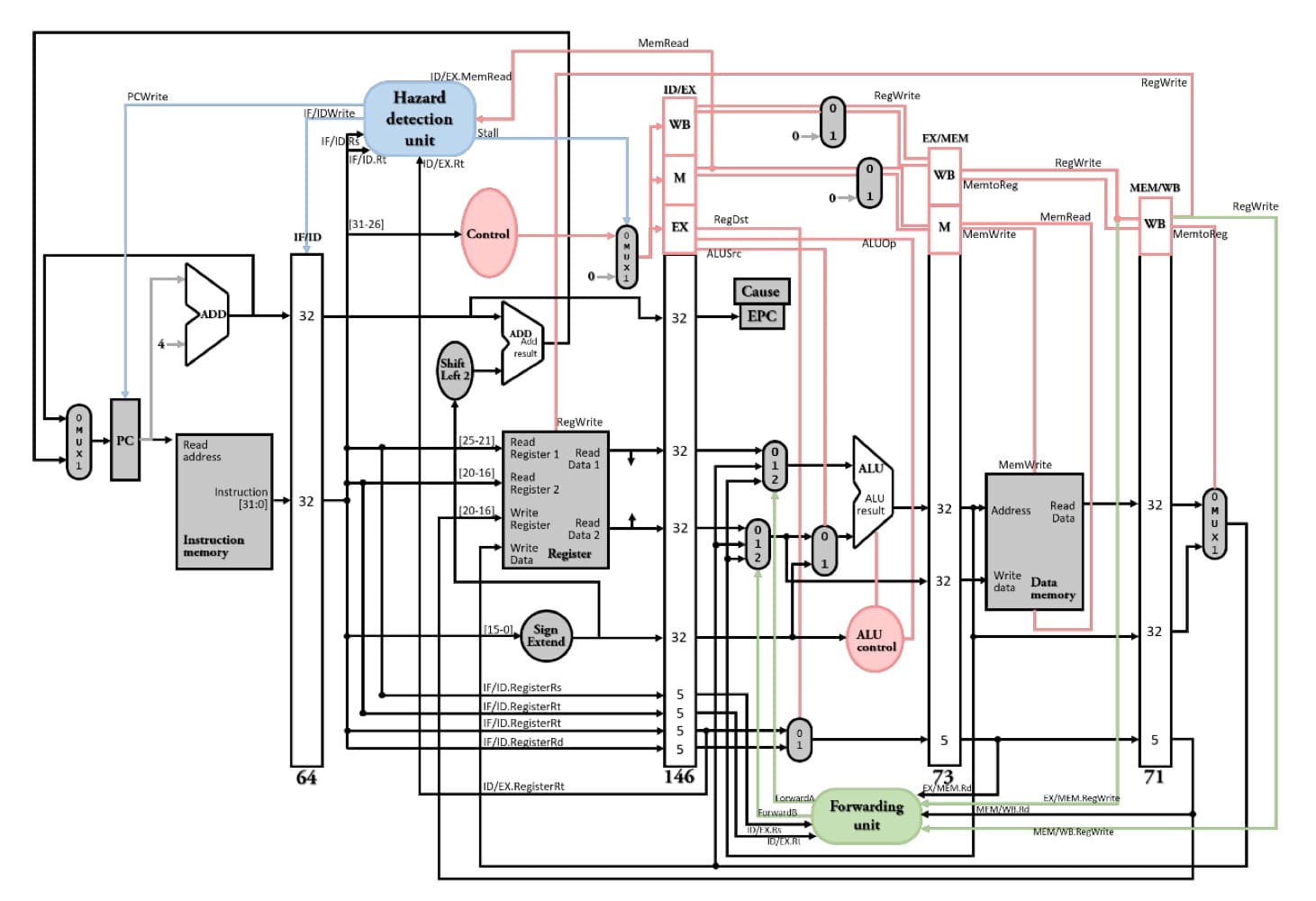
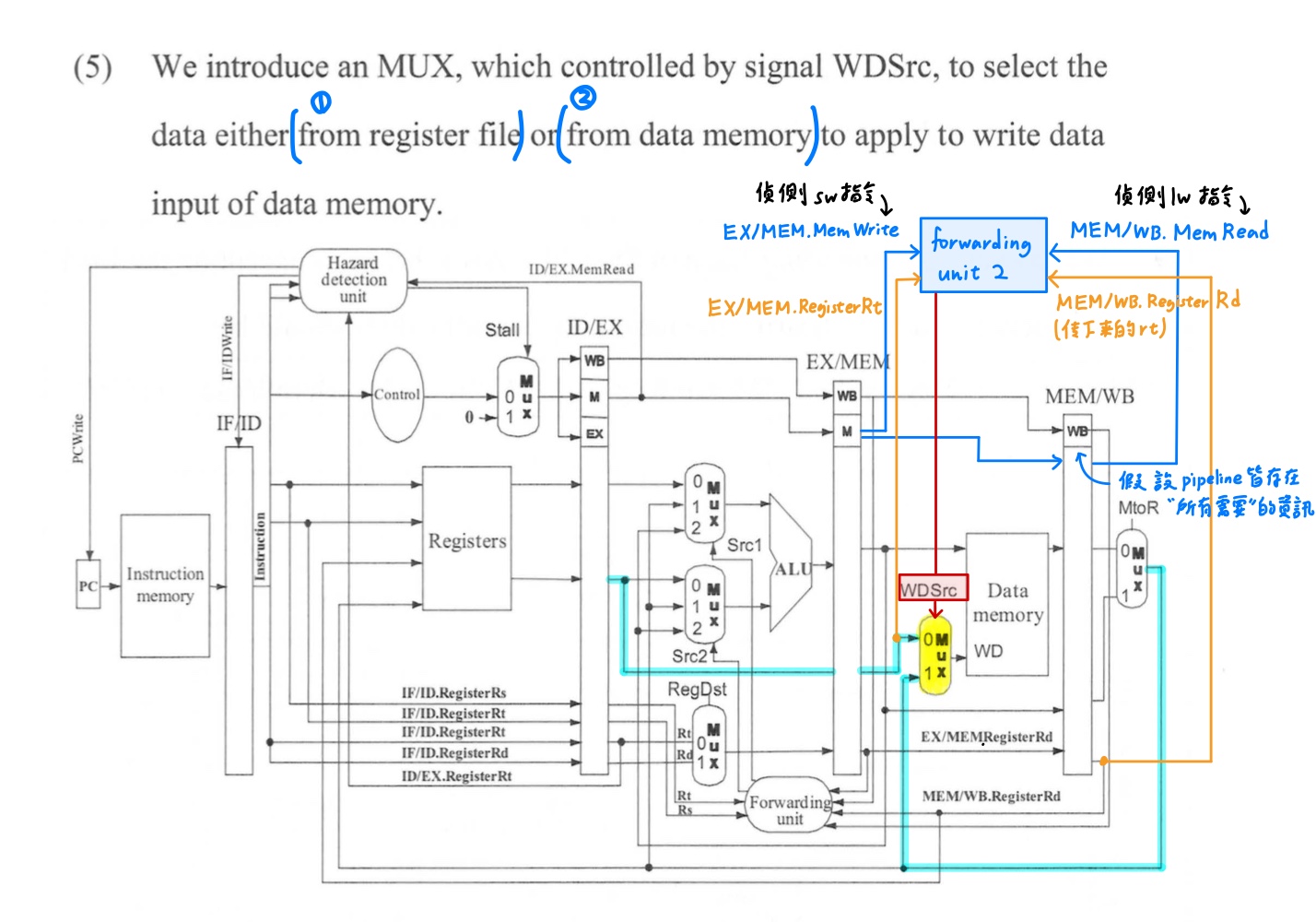
對相同rt欄位的load word與store word的load-use data hazard,不必像一般的load-use data hazard一樣需要stall + forwarding,而是可以直接forwarding及時更正要送至data memory中write data的資料,因為sw不需要在EX stage就需要正確的暫存器內容,而是等到下一個stage,也就是在MEM stage才需要將正確的暫存器內容寫入記憶體。
---
### data dependency
data dependency分為RAW、WAR、WAW。判別方式如下
1. RAW - 前面目的和後面來源比
2. WAR - 前面來源和後面目的比
3. WAW - 前後都看目的暫存器
在MIPS的5-stage pipeline架構中,只有RAW會發生data hazard,RAW稱為true data dependency,其餘WAR、WAW稱為false data dependency。對比在superscalar pipeline中亂序執行,後面指令可以超前前面指令提早執行,因此三種data dependency都有可能產生。
---
### beq往前移以減少control hazard並解決變嚴重data hazard
[ch5 pipeline的control unit設計](#pipeline的control-unit設計)MIPS指令集5個stage pipeline的"原始設計"是在MEM stage決定要不要跳。branch指令走到MEM stage才知道後面指令要跟誰,但此時後面指令已經跟上了,如果branch一跳,後面指令就跟錯了,因此解法是是將抓錯的指令flush掉。
flush掉越多指令會降低pipeline的效能(throughput),因此我們嘗試將決定要不要跳往前面的stage移動,以減少branch猜錯要flush掉的指令個數, branch不使用ALU進行減法運算比較兩暫存器是否相等,而是**多在ID stage增加XOR array這個硬體元件比較兩暫存器是否相等**,由於XOR array沒有像ALU一樣需要進位,因此運算速度會比ALU還快。
如果branch一跳,硬體需要清除後面跟上來在IF stage的指令,使用控制線`IF.Flush`,把IF/ID pipeline register全清為0,原指令就會轉換為`sll $0 $0 0`,也就是MIPS官方版本的nop指令。
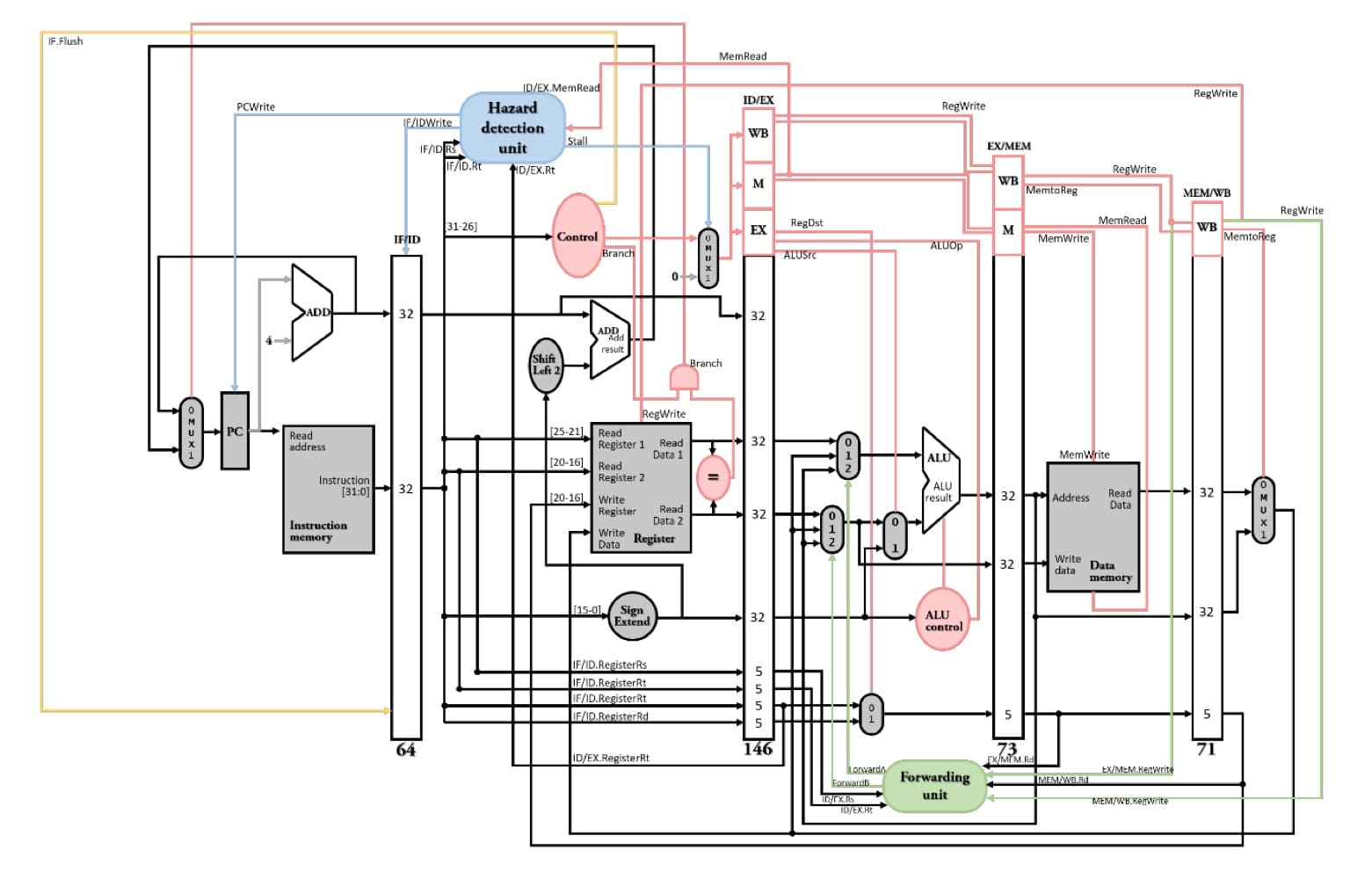
上述將branch決定要不要跳的地方從MEM stage移到ID stage後,會讓data hazard變嚴重,需要解決。
1. R-type後面跟beq產生data dependency時,需要**先pipeline stall 1個clock的時間**,等R-type指令在EX stage執行完運算後,在MEM stage再**往前forwarding**回在ID stage的beq,執行暫存器比較的運算。
2. lw後面跟beq產生data dependency時,需要先**pipeline stall 2個clock的時間**,等lw一直走到MEM stage從記憶體抓取數值後,由於register file設計在前半周寫、後半周讀,因此lw在WB stage前半周寫入記憶體,beq在ID stage後半周才會抓到正確的記憶體的內容,所以也不需要forwarding path。
總結一下有4條forwarding path。
1. 課本上的EX hazard。
2. 課本上的MEM hazard。
3. 對相同rt的lw與sw的load-use data hazard不用暫停pipeline,用forwarding來救即可。
4. R-type和在ID stage的beq指令產生data hazard = pipeline stall + forwarding。
---
### 硬體解法 - 動態分支預測
分支預測分為2類
1. 靜態分支預測 - 永遠猜跳,永遠猜不跳,由compiler在猜測並重排指令順序給硬體執行,若猜錯硬體需負責殺掉猜錯的指令。
2. 動態分支預測 - 根據run time information,也就是前幾次branch有沒有跳的歷史依據,來猜要跳或是不跳,由硬體在猜測,若猜錯硬體需負責殺掉猜錯的指令。
動態分支預測使用兩個硬體元件 - **分支歷史表(BHT, branch history table)的索引使用branch指令位址較低的位元,另外使用1個bit來指示前一次branch是否有發生跳躍**。BHT告訴我們分支是否會成立,但是分支目的位址的仍需計算,意味還需要一個clock cycle的計算懲罰,因此還需要**分支目的位址緩衝器(BTB, branch target buffer)作為快取(cache) ,來存放目的地PC或是目的地指令來消除這個懲罰**。
預測方式有1-bit與2bit方式,2bit的BHT存11, 10, 01, 00,但BHT只會輸出最左邊的bit,代表T(taken)或是NT(not taken),兩者預測方式都屬於counter-based(假設分支是發生的則下一個狀態值為目前狀態值加 1否則減1),且加、減都是採用飽和運算。
此外更複雜的預測方式有同時使用local(自己的branch)與global(其他地方的branch)為判斷依據的關聯預測器(correlating predictor),以及使用多個預測器並追蹤看是哪個預測器產生比較好的效果的競賽預測器(tournament predictor)。
---
### 軟體解法 - 延遲分支(delayed branch)
compiler會將不論分支條件是否成立總是會執行的指令(稱為安全指令)放到分支延遲插槽(branch delay slot) 中,而延遲分支總是執行後面的指令。因此不論分支條件是否成立都不需要丟棄其後的指令。插入安全指令有以下3種方法
1. from bottom - 在不影響程式執行的正確性之下,將branch上面的指令放到branch delay slot。
2. from target - 根據branch會跳的順序來安排指令的順序,若是branch不跳,會多被執行一個沒用的指令,但就算被執行,也不影響程式的正確性。
3. from fall through - 根據branch不會跳的順序來安排指令的順序,若是branch會跳,會多被執行一個沒用的指令,但就算被執行,也不影響程式的正確性。
若第1點無法無法執行則做第2、3點,而第2、3點再無法執行,則只能插入nop。
> 注意這是用軟體解決的方式,compiler排完指令順序後,所有指令一定都會被執行,不會像硬體一樣flush指令。
但是安全指令實在不好找,若是隨著pipeline切更細或是每個clock issue的指令變多,就需要更多的branch delay slot,如此delayed branch的解決方法就已經失去優勢。
---
### 增加ILP的方法
pipeline充分利用指令之間潛在的平行度。這類型的平行度稱為指令層次平行度(Instruction-Level Parallelism, ILP) 。
> 此外更高層級也有job-level parallelism, thread-level parallelism。
增加ILP有2種方法
1. superpipeline - 把pipeline切越細、增加管線的深度,好處是speedup會增加(ideal speedup = S)、但壞處是會更難平衡每個stage的時間、會產生hazard若無法有效解決會變成hazard penalty。
2. multiple issue - 複製電腦內部的單元,使其在每個pipeline的階段都可以執行多個指令,需要解決2個問題
- 打包指令(pack instruction) - 同時被塞到同一個pipeline的指令會形成一個指令包,指令包裡面的指令間不存在data dependency。
- 處理危害(handle hazard)。
multiple issue由軟體(compiler)處理稱為static multiple issue,由硬體處理稱為dynamic multiple issue,又稱superscalar。
無論是static或是dynamic的multiple issue都可以用speculation加速。**speculation是猜某個指令的性質,來決定跟這個指令相關後續的指令可以提早被執行**,如果原本在後面的指令可以提早被執行,就可以讓後面指令跟前面指令混在一起,讓指令包能盡量填滿,以提高ILP。軟體的speculation會重排指令順序,並加入其他指令以檢查猜測的正確性,提供一組修補程式以在猜錯的時候使用;硬體的speculation會將猜測結果暫時另外存到buffer,直到真正知道結果後,如果猜對會將結果寫回暫存器或是記憶體以完成指令,如果猜錯直接把buffer flush掉即可。
---
### static multiple issue - MIPS-64、VLIW、IA-64
static multiple issue會介紹3個例子
1. MIPS-64<br>
屬於2-issue,其中一個issue規定只能是R-type或是beq,另一個issue規定只能是lw或sw指令,需要熟練如何排指令順序(code scheduling),若是指令個數較少,可以嘗試**將迴圈展開(loop unrolling)以增加指令個數**,其中迴圈展開時,會產生WAR( = anti-dependency)、WAW( = output dependency)這類false data dependency,但實際上這不是真正的data dependency,只是因為硬體資源不足、暫存器名稱重複使用造成,可以用register renaming的方法的方法解決。
2. VLIW (very long intruction word)<br>
為了保持硬體簡單以提高硬體的擴充性,而沒有forwarding path,但是代價就是compiler工作量大,且hazard只能靠stall來解決,目的碼不相容(ex : 64bit和32bit編譯出來的目的碼不同)。
3. IA-64<br>
設計方向是以VLIW為基礎去改良。架構與MIPS-64相似,屬於RISC,但有加上可以提高ILP的指令 - predication指令,所以intel把它稱之EPIC,predication指令和一般指令的差別在於predication要執行運算前,會先測條件,藉以取代branch指令,以減少control hazard。
凡是無法被打包成instruction group(指令群)的指令,每隔3個指令,**硬體會把它們打包成instruction bundle**,丟到特製的硬體上面去執行,這個特製的硬體有5個功能單元,因此就不會存在data dependency;加上特製的硬體有大量的forwarding path,縱使有data dependency,也能盡早獲得該拿的資料,加速硬體的執行。
> 下列指的東西相同,只是名稱不同
> - 在MIPS-64稱為instruction package(指令包)
> - 在VLIW稱為very long instruction (超長指令)
> - 在IA-64稱為instruction group(指令群)
---
### dynamic multiple issue( =superscalar)
dynamic multiple issue( = superscalar)使用硬體來多指令分發,雖然是dynamic issue pipeline,但是compiler還是要盡量把指令執行順序排到最好,解決compiler有能力解決的hazard問題,當遇到compiler沒辦法解決的hazard問題,再丟給硬體做處理。
最核心的技術是dynamic pipeline scheduling - 選擇下一群要執行的指令並將這些指令重新排序,由於硬體資源足夠多,因此pipeline幾乎不會stall。分為3個主要單元
1. in-order issue - 照compiler排定指令的順序,抓指令、解碼指令、抓暫存器。
2. out-of-order execute - 丟到buffer稱為reservation station,等("預約")功能單元的使用權或是等與別的指令產生data dependency的指令forward給該指令。
3. in-order commit - 會先把運算結果存在reorder buffer,再按照原本資料流的順序提交,寫回暫存器或是記憶體。
其中dynamic pipeline scheduling的第2階段 - 亂序執行可能會遇到RAW、WAR、WAW,其中output dependency (= WAW)與anti-dependency (= WAR)都是重複使用硬體資源造成,而不是"真正"的data dependency,可用register renaming來消除。
---
### pipeline處理exception的步驟
處理器內部發生非預期事件干擾程式執行稱為例外(exception),可能是使用者呼叫OS(system call),算數類運算所發生的overflow、ARM程式拿到MIPS機器運行而產生illigal instruction;處理器外部發生非預期事件干擾程式執行稱為中斷(interrupt),可能是I/O外部設備請求。
處理exception的步驟分為硬體與OS的部分<br>
硬體先做3件事情
1. 把造成exception的指令位址存至EPC(exception program counter)。
2. 把造成exception的原因存至cause register。
3. 把絕對位置8000 0180(處理exception的起始位址)傳至PC。
硬體根據特定的記憶體位址把控制權轉交給OS
1. 基本處理。
2. 選擇1 - kill原程式、選擇2 - 根據EPC,讓原程式從剛剛斷掉的地方繼續執行下去。
pipeline處理exception的步驟,以算數類運算所發生的overflow為例
1. flush掉IF、ID、EX stage的指令,拉`IF.Flush, ID.Flush, EX.Flush`控制線。
2. 盡可能讓造成exception之前的指令完成執行。
3. 將造成exception指令(offending instruction)的記憶體位置存到EPC,但實際上會存到EPC + 4,所以之後OS會自動減4回來。
4. 呼叫OS來處理exception。
5. OS會根據EPC,讓原程式從剛剛斷掉的地方繼續執行下去。
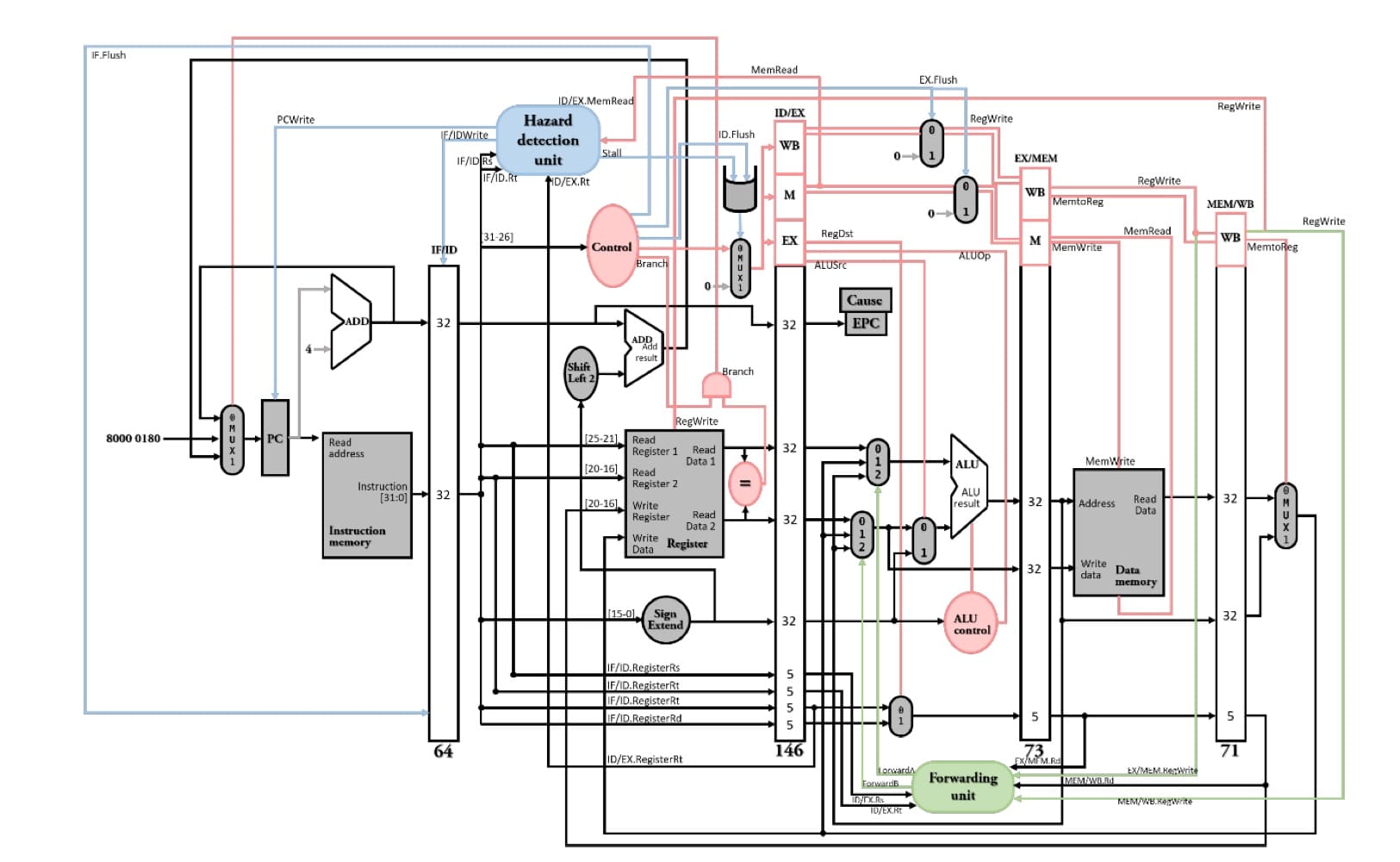
要確切紀錄到exception的指令位址不是一件簡單的事情,像是x86有四十幾個stage的pipeline,發生exception時,不知道哪個stage的指令發生exception,因此就不會記錄到發生exception的指令位址,稱為非精確例外(imprecise exception),此時OS只有一個選擇就是kill原程式,因為也不知道是該從哪個地方繼續執行原程式。
---
## ch6 記憶體
### 綱要
- 基於程式執行的locality性質建構memory hierarchy
- direct-mapped cache的對應方式
- direct-mapped cache的總容量計算
- block size與miss rate關係
- write hit情況下使用write-through或write-back
- write miss情況下使用write miss情況下write-back或write-back
- split cache與combined cache優缺點
- 增加memory與cache之間的頻寬 - wide, interleaved
- 增加memory與cache之間的速度 - DDR SDRAM技術
- set associative cache把cache分為數個集合,每個集合有n個block
- set associative cache的總容量計算
- multi-level cache中L1降低hit time、L2降低miss rate
- multi-level cache的extra CPI兩種公式
- AMAT(average memory access time)公式
- virtual address利用page table register與page table轉換成physical address
- page table的3種memory management bits
- 設計virtual memory大原則 - 避免存取硬碟
- page table的cache - TLB
- 把cache整合進TLB與virtual memory系統
- TLB / page table / cache hit or miss中各種可能與不可能的情況
- virtually addressed cache機制與解決aliasing問題
- 記憶體階層的4個問題
- 發生cache miss的原因分類 - 3C
- virtual machine的virtualization技術
- 減少page table占用memory空間的5種方法
---
### 基於程式執行的locality性質建構memory hierarchy
[ch1 記憶體(memory)](#記憶體memory)提及memory的功能是用來儲存正在執行中的程式,包含資料(data)與程式碼(code)。
1. 由於hard disk與memory之間的存取速度差數百萬倍,因此要盡量減少memory swap的次數,memory要設計大一點。
2. CPU存取memory地址時需要decoder,為了降低decoder電路複雜度,以加速解碼的速度,memory要設計小一點。
兩者需要在設計memory時就產生牴觸,幸好可以再利用一個程式執行的特性 - locality of reference。
1. temporal locality - 當一資料被存取時,很高機率在短時間內還會被存取一次,例如loop。
2. spatial locality - 當一資料被存取時,其周圍的資料很高機率在短時間內還會被存取一次,例如array。
來設計memory hierarchy,建構一層一層速度由快到慢、容量有小到大、每單位容量的價格由貴到便宜的memory,而前面memory存的資料是後面memory存的資料的子集合。
1. memory hierarchy將最近被存取的資料放在最接近CPU的記憶體層級,利用的是temporal locality的特性。
2. memory的基本單位為block( = line),一個block包含數個word,一次存放連續位址的資料,利用的是spatial locality的特性。
而現今memory hierarchy的架構設計依序是cache(由SRAM實作)、main memory(由DRAM實作)、hard disk,本章節前半部分會探討由cache和main memory之間的對應,稱為cache system;後半部分會討論由memory和hard disk之間的對應,稱為virtual memory。
---
### direct-mapped cache
對應方式為每個memory位址都直接對應到cache的唯一位置,對應方式為memory block address除以cache中的block個數等於cache的位址,而使用tag來判別是哪個memory block。
CPU丟出memory byte address,會切2刀
1. **一個block中的byte數**。左邊為memory block address,右邊為offset,其中offset又分為block offset(找一個block裡面的第幾個word)、byte offset(找一個word裡面的第幾個byte)。
2. **cache中的block總數**。左邊為tag,若與cache的tag比較相同為hit,不相同則為miss;右邊為index,代表要去cache哪個位址找資料。
另外還會加上valid bit,防止CPU拿到前面program的資料,一開始程式運行會把所有valid bit清為0。總結得到direct-mapped cache的電路結構圖如下
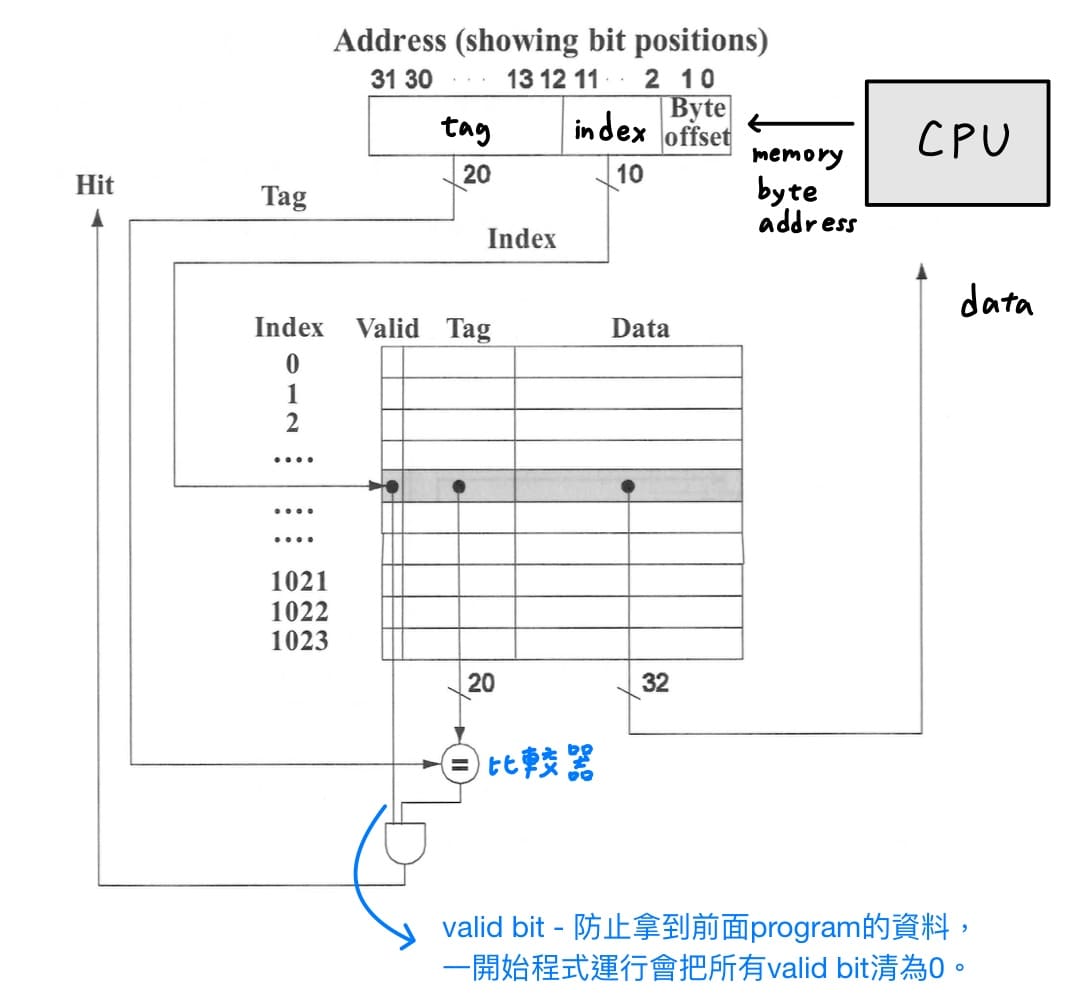
---
計算direct-mapped cache的容量題型會給定3個必要資訊
1. cache size
2. block size
3. address length
首先依序計算
1. cache中的block個數 = cache size / block size。
2. 切memory byte address求tag bit數,第一刀切一個block中的byte數,第二刀切cache中的block總數。
3. cache總容量為[valid bit + tag bit數 + data的bit數( = block size)] * (cache中的block總數)。
---
接下來探討block size與miss rate的關係。若一個block只包含1個word,則無法利用到程式執行的spatial locality特性,因此block會設計存放多個word才能利用到spatial locality,以降低cache miss rate。
但是block size過大,反而導致miss rate上升,有2點解釋的方式
1. 假設cache總資料量固定,隨著block size變大,cache的block總數會變少,block和block之間會互相競爭,1個block被搬上cache用沒幾個word又被搬下去。
2. spatial locality的密度下降。
另外一個增加block size的問題是miss penalty會增加。CPU存取cache發生miss,CPU會停下來,CPU停的時間就是miss penalty的時間,cache control unit會從main memory搬CPU要的word到cache,正常情況下,cache control unit會把CPU要的word所在的block全部搬完,才通知CPU過來存取cache。因此block size越大,需要搬的時間越長,CPU停的時間越長,miss penalty就越大。
有以下2個方式可以降低miss penalty的時間
1. early restart - cache control unit從main memory搬到cache時,搬到CPU要的word時,馬上通知CPU過來存取。
2. requested word first - cache control unit從main memory搬到cache時,先搬CPU要的word,並通知CPU過來存取。
---
### cache的機制
當CPU讀取cache經由tag比對,發現要讀取的資料不在cache時,稱為cache miss,處理方式如下
1. pipeline stall,凍結所有暫存器的內容。
2. 使用獨立於CPU的cache control unit,將CPU要讀取的word所屬的block讀入cache,並將位址上半部寫入tag值、開啟valid bit。
3. cache control unit通知CPU過來讀取,指令繼續執行。
給定sw指令,我們只有將資料寫入cache,而沒有寫入main memory,因此cache的資料與memory的資料不同,稱為memory inconsistence,在write hit與write miss情況下,各有2種解決方式。
1. write hit情況下使用write-through<br>
同時寫入cache與memory,優點是實作簡單,缺點是由於memory與cache的速度差太多,寫入時間過久,效率會變差;改良方法是write buffer,CPU先寫到write buffer,之後再交給cache control unit完成寫回記憶體的動作。
2. write hit情況下使用write-back<br>
暫時讓cache和main memory資料不一致,並使用dirty bit來記錄,等到該cache block要被置換時,再寫回memory,但實作上比write through複雜。
3. write miss情況下使用write allocate<br>
cache control unit把CPU要寫入資料的block搬上cache,再給CPU寫入後就結束了。
4. write miss情況下使用write around( = no write allocate)<br>
繞過cache,直接寫入main memory,違反memory hierarchy的大原則。
為了方便起見
1. write-through與write-around搭配,代表CPU除了會進入cache,還會直接存取main memory。
2. write-back與write-allocate搭配,代表CPU永遠只會存取cache。
如果write-through與write-allocate搭配,處理起來會十分麻煩,write hit時,write-through保證cache和main memory的資料一致;但是write miss時,cache control unit把CPU要寫入資料的block搬上cache,再給CPU寫入後就結束了,因此cache和main memory的資料就不一致。
---
### split cache與combined cache
1. split cache - 將cache拆分為instruction cache和data cache,由於可以同時存取指令與資料,平行執行,頻寬(單位時間存取的資料量)變兩倍,且不會像combined cache一樣有structural hazard的問題。
2. combined cache - 由於指令是用來存取資料的,因此指令與資料的locality of reference是混雜在一起的,hit rate提高。
---
### 降低miss penalty的方法
miss penalty的時間為將下層memory取代上層memory的時間加上將上層memory傳給CPU的時間,因此要降低miss penalty,有兩種方法
1. 增加memory與cache之間的頻寬,也就是加快單位時間存取的資料量<br>
方法一(wide)是加寬介於memory與cache之間的bus,使得一次可以傳送更多memory的資料;方法二(interleaved)將要讀取的資料分散在各個bank,要從記憶體存取資料時,就可以平行讀取分散在每個bank的資料,以減少記憶體存取的時間。
2. 增加memory與cache之間的速度<br>
原始記憶體是一維陣列,將其改成二維陣列,decoder就可以拆成row decoder和column decoder兩個部分,以減少輸入個數,加快電路的速度。
當在讀同一個block時,row address幾乎不變,而DRAM會把row讀取的所有資料放到buffer上,因此只需要解碼column address,移動I/O gate mask選擇要存取哪個word即可,此方式稱為page mode。
SDRAM(synchronous DRAM)切成好幾個橫切面,變成立體狀,當解碼完row和column得知要讀的位址後,接下來會進入burst access,不需要再提供地址,而是藉由clock快速讀取DRAM一串連續的資料。而DDR SDRAM(double date rate SDRAM)在clock上下緣都會存取資料,因此有成倍的讀取量;QDR SDRAM(quad date rate SDRAM)把讀和寫的電路分開,可同時進行,讀取量再翻倍,變成4倍。
---
### set associative cache
direct-mapped是一個很極端的方法,很容易產生block與block之間資源的競爭,進而導致miss rate上升,因此使用set associative cache解決,將cache分為數個集合,每個set都有n個block,稱為n-way或是associativity等於n的set associative cache。
cache中block總數 = set個數 * 關聯度(一個set包含的block個數)。增加關聯度可以減少block之間的競爭程度,miss rate會降低;但是比的tag數增加,導線拉得越長,訊號延遲的時間越長,因此比的時間會拉長,因此hit time增加。
而[ch6 direct-mapped cache](#direct-mapped-cache)介紹的direct-mapped cache其實就是set associative cache的特例。
- direct-mapped cache就是在每個set只有1個block(associativity = 1)中set associative cache的特例。
- fully associative cache就是在整個cache只含一個set中set associative cache的特例。
CPU丟出memory byte address,會切2刀
1. **一個block中的byte數**。左邊為memory block address,右邊為offset,其中offset又分為block offset(找一個block裡面的第幾個word)、byte offset(找一個word裡面的第幾個byte)。
2. **cache中的set總數**。左邊為tag,若與cache的tag比較相同為hit,不相同則為miss;右邊為index,代表要去cache哪個set找資料。
而tag拿來跟這個set中所有的block的tag同時做比對,考量到電路的速度,故使用平行比較。總結得到4-way set associative cache的電路結構圖如下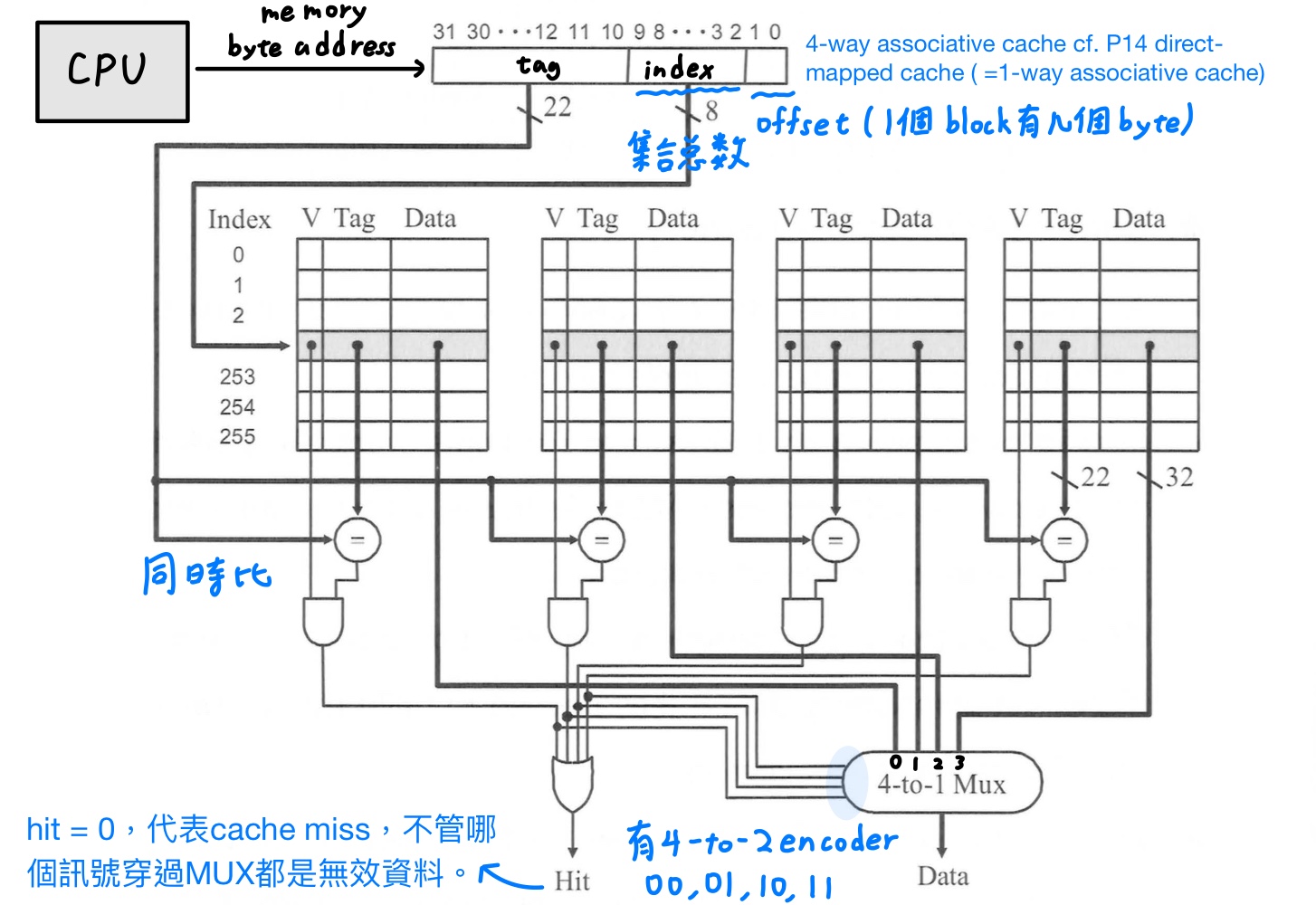
在direct-mapped cache發生cache miss時原本佔據的block就會被置換下來,而在set associative cache一個集合中的所有block都有機會被置換下來,因此可以使用random或是LRU(least recently used)的置換方式,LRU比起random雖然miss rate較低,但是實作電路複雜,也未必是一個好方法,各有各的優缺點。
---
計算set associative cache的容量題型會給定4個必要資訊
1. cache size
2. block size
3. address length
4. associativity(一個集合有幾個block)
首先依序計算
1. cache中的block個數 = cache size / block size。
2. cache中的set個數 = block個數 / associativity。
3. 切memory byte address求tag bit數,第一刀切一個block中的byte數,第二刀切cache中的set總數。
4. cache總容量為[extra bit + tag bit數 + data的bit數( = block size)] * (cache中的block總數),其中extra bit = valid bit + (dirty bit in write-back cache) + (LRU bit紀錄最不常被使用的block)。
---
### multi-level cache
multi-level cache的設計目是為了減少miss penalty,當L1發生cache miss時,L2幾乎包含大部分的資料,因此L1的miss penalty就由L2(SRAM)的讀取時間所決定,遠比讀取main memory(DRAM)的讀取時間還快數百倍。
multi-level cache在L1與L2設計著重的點不同<br>
L1的hit time會決定CPU的clock cycle time,所以要盡量設計小。
1. 使用split memory,頻寬加倍,以降低hit time。
2. L1會採用write-back或是write-through都可,因為L1和L2都是SRAM,速度都很快。
L2注重miss rate,要夠大才能涵蓋所有大部分需要的資料。
1. 使用combined memory,locality of reference增加,以降低miss rate。
2. L2下面一層就是main memory,SRAM和DRAM速度差非常多,因此會採用write-back。
---
對combined cache來說,multi-level cache的extra CPI的公式有兩個版本
$$
\begin{align*}
\text{extra CPI} &= \text{stall cycle per instruction}\\
&= (1 + \text{lw/sw}\%) \times \underbrace{\sum^n_{i = 1} \text{MR}_i \times \text{MP}_i}_{\text{stall cycle per access}}\\
&= \sum^n_{i = 1} \text{MRP}_i \times \text{MP}_i
\end{align*}
$$
其中MR = miss rate、MP = miss penalty、MPR = miss rate per instruction = 平均一個指令(不管該指令是否有cache access)在執行會造成cache miss幾次。
在上述公式缺條件時,有一些基礎假設
1. 題目沒給完美CPI ⇒ pipeline的完美CPI假設1。
2. 欲求miss rate per instruction,但只有給miss rate,也沒給lw/sw佔所有指令的比例 ⇒ lw/sw佔所有指令的比例設為0,也就是把miss rate當成miss rate per instruction。
3. 題目沒給clock cycle time ⇒ 把L1 cache的hit time當作clock cycle time。
一般miss rate題目沒特別指名都是只global miss rate,還有另一種是local miss rate。
1. GMR = 以CPU存取memory的次數為基準
2. LMR = 以存取到上一層memory的次數為基準
$$
\text{GMR}_i = \Pi_{k = 1}^i \text{LMR}_k = \text{LMR}_1 \times \text{LMR}_2 \times \cdots \text{LMR}_i
$$
最後在定義一個衡量標準,AMAT(average memory access time)代表CPU存取記憶體一次所需要的平均(絕對)時間。
$$
\text{AMAT} = \underbrace{\text{T}_1}_{\text{hit time in L1 (not stall)}} + \underbrace{\sum^n_{i = 1} \text{MR}_i \times \text{MP}_i}_{\text{stall cycle per access}}
$$
公式為第一層cache不stall的時間與發生stall的時間的加總。
可與extra CPI的公式做比較,兩者公式都有stall cycle per access的項,欲求AMAT per instruction
$$
\begin{align*}
\text{AMAT per instruction} &= \text{CPU存取記憶體一次所需要的平均時間} \times \text{有存取到記憶體的指令個數}\\
&= \text{AMAT} \times (1 + \text{lw/sw}\%)\\
&= (1 + \text{lw/sw}\%) \times (\text{T}_1 + \sum^n_{i = 1} \text{MR}_i \times \text{MP}_i)\\
&= (1 + \text{lw/sw}\%) \times \text{T}_1 + (1 + \text{lw/sw}\%) \times \sum^n_{i = 1} \text{MR}_i \times \text{MP}_i\\
&= (1 + \text{lw/sw}\%) \times \text{T}_1 + \sum^n_{i = 1} \text{MRP}_i \times \text{MP}_i
\end{align*}
$$
---
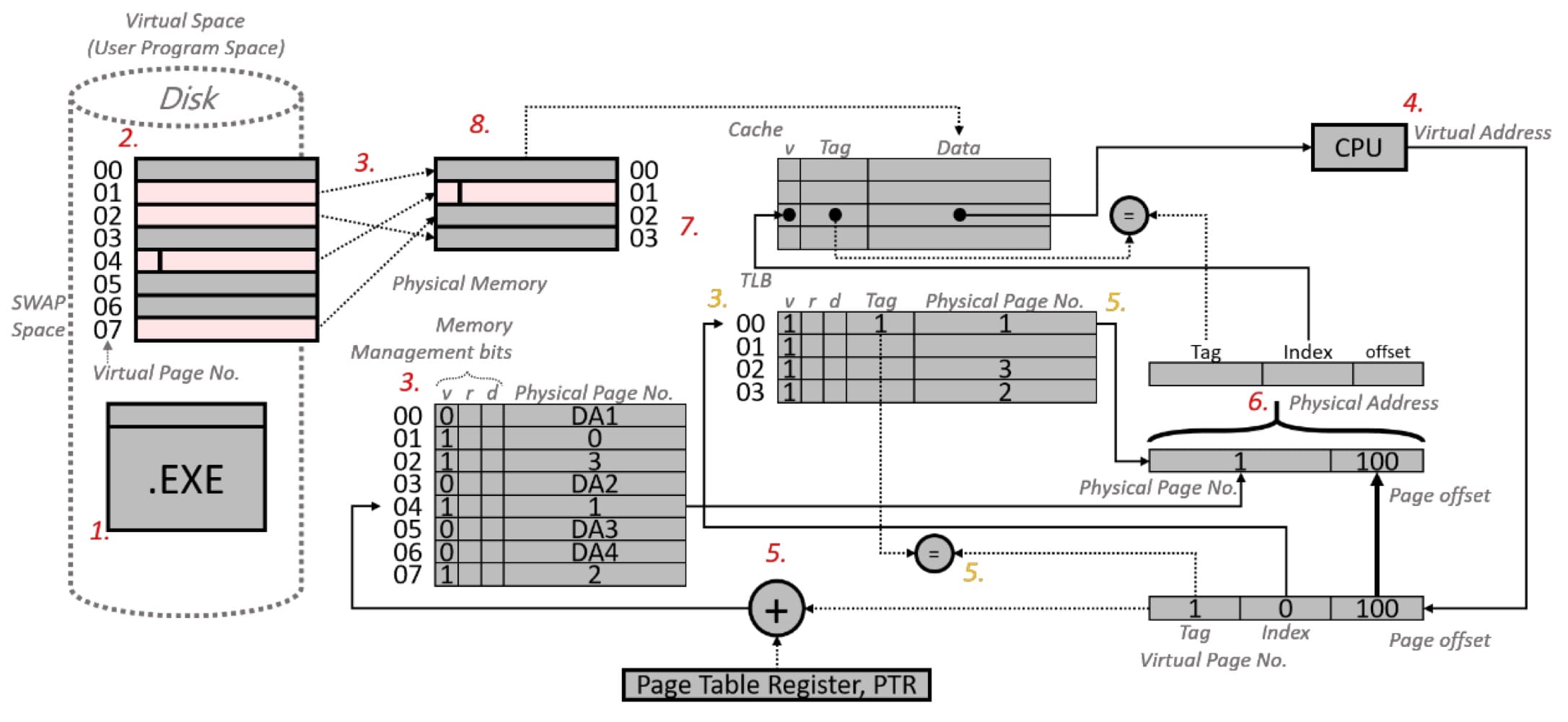
### 虛擬記憶體(virtual memory)
設計virtual memory的2大動機
1. 早期一次只能run一個程式,虛擬記憶體允許多個程式可以有效率且安全得分享記憶體。
2. 早期memory的容量小於程式大小就無法run程式,虛擬記憶體消除因為memory過小所造成的程式限制。
取得資料的過程
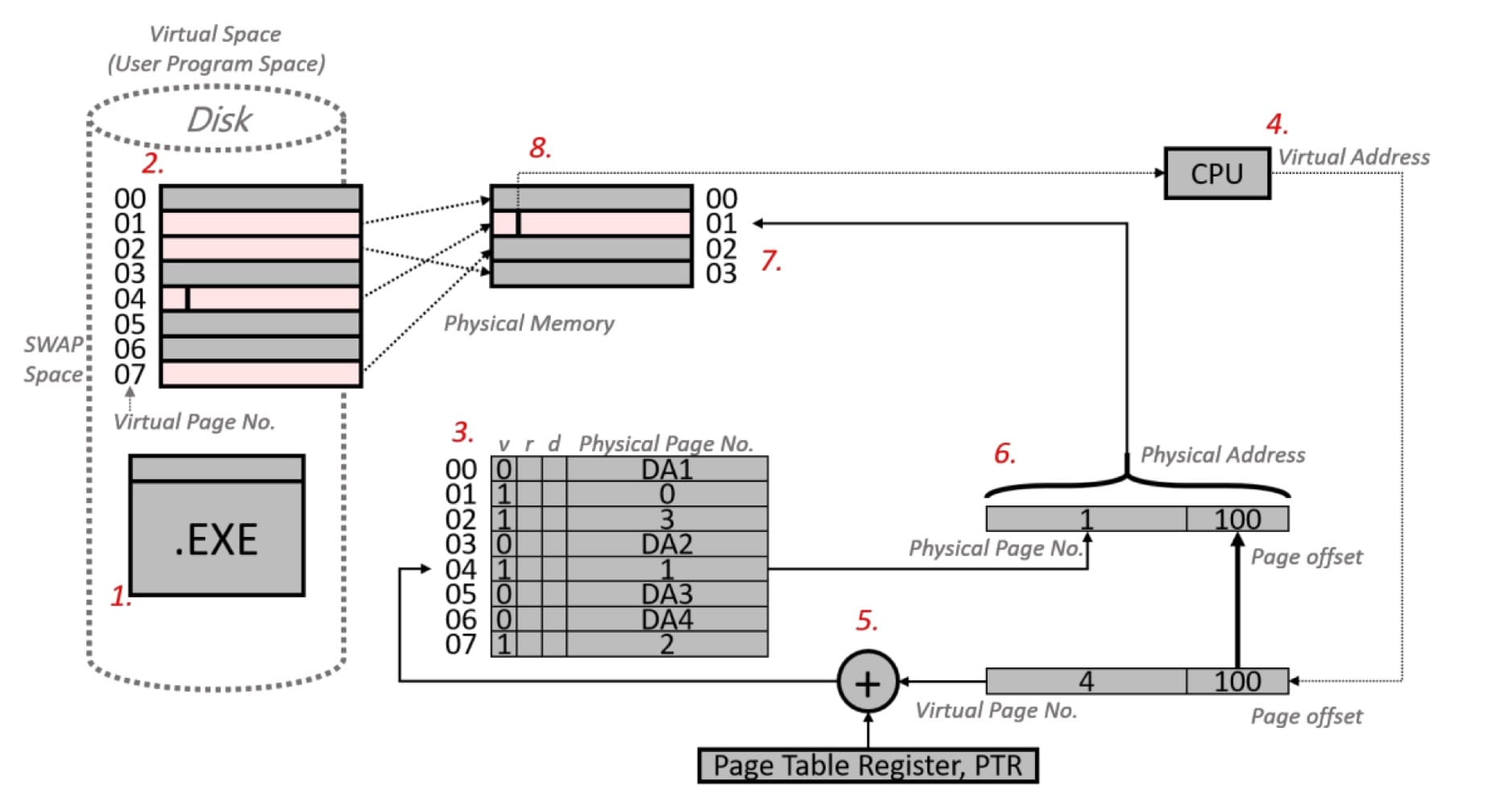
1. 開啟執行檔。
2. OS把程式複製到hard disk中的swap space,複製後的程式本身稱為virtual space ( = user program space)。
3. 當程式使用到的空間較記憶體大時,OS會先把部分資料複製到physical memory ( = main memory),並建立page table,以physical page number來記錄已經載入physical memory的資料的記憶體位址或是還在hard disk的資料的位址。page table的entry數量等於程式執行佔用的virtual space中virtiual page的數量,此外會加入memory management bits - valid bit, reference bit, dirty bit。
4. 當CPU要存取某一資料時,會發出virtual (byte) address的要求指令,直接指定virtual space的位址,virtual address分為2個部分 - virtual page number對應到virtual space的哪個page;page offset指出page中哪個byte (以memory byte address來說)。
5. 由於virtual address是指向hard disk中virtual space的位址,需要將經過適當轉換成可以存取physical memory的位址,也就是轉成physical addess。從virtual address擷取出virtual page number,加上**page table register(為一pointer,指向active程式的page table在memory的起始位址)以找到page table**,再從page table取得相應的physical page number。
6. 有了physical page number,再結合先前的page offset,便組合而成physical address。
7. 以physical address存取physical memory ( = main memory)取得資料。
8. 回傳給CPU進行運算。
memory management bits有3種
1. valid bit - 表示該資料是否存在main memory。
2. reference bit ( = use bit) - 完整的LRU置換法,需要有計數器,硬體成本太貴,因此大多使用"近似LRU"來完成。OS會週期性清除reference bit為0,page若有被讀取則將reference bit設為1,如此就可以追蹤哪一個page最近沒有被用到,OS會隨機選出任一個reference bit = 0的page作為要被置換出去的victim page。
3. dirty bit - 追蹤哪些page需要執行write back的動作,等到dirty bit = 1的page被置換後就需要執行write back的動作。
---
virtual memory與cache system的觀念相同,只是因為歷史脈絡,造就有不同的術語。在設計virtual memory時,與設計cache system不同點在於 - 避免存取硬碟,因為main memory跟hard disk速度差數百萬倍!
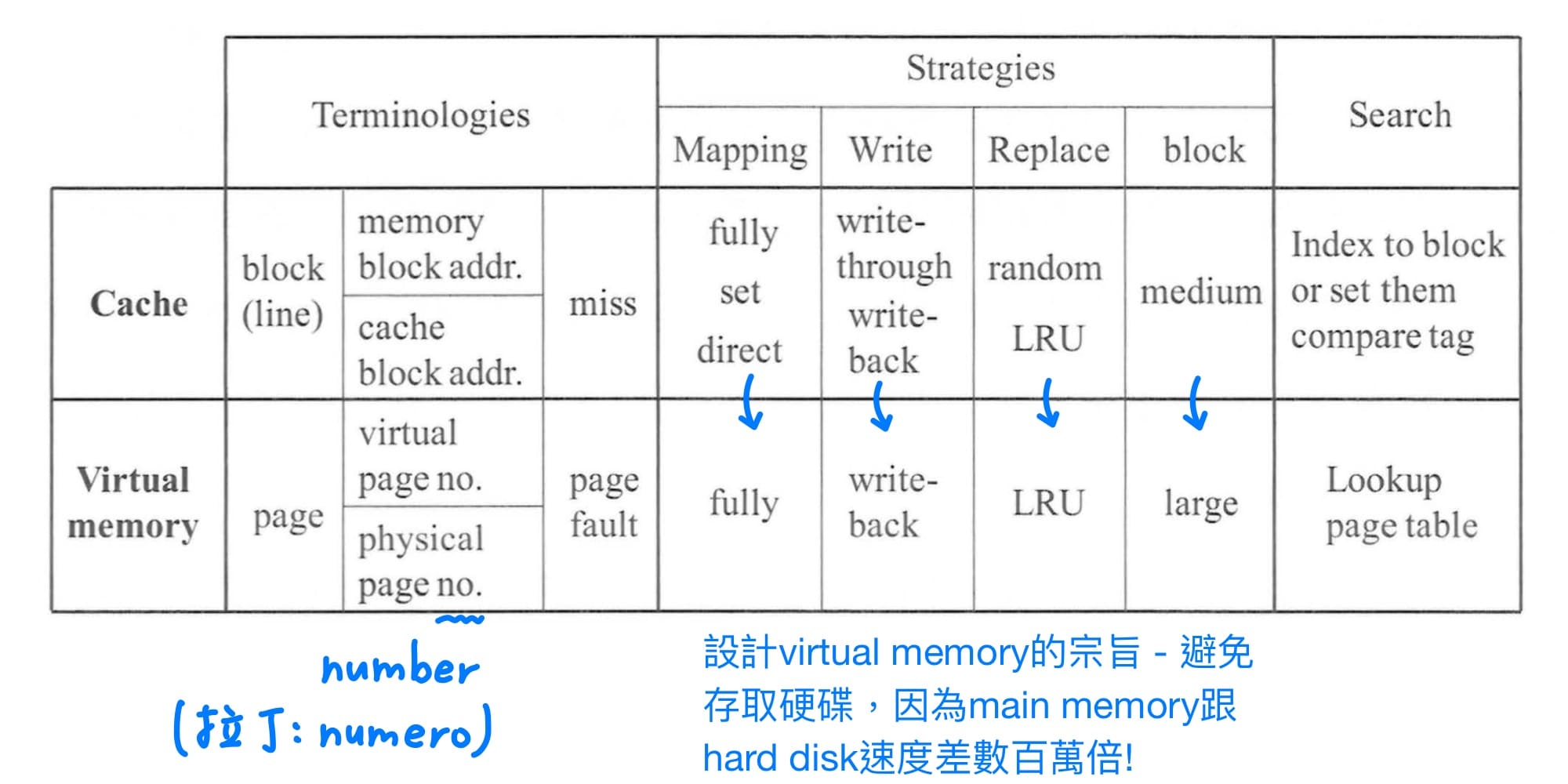
page table容量大小計算與cache不同點在於page table的entry需要round up to word的冪次方。原因是cache是SRAM可以量身訂造,但是page table是放在main memory,需要遵照memory的alignment規則,且計算memory位址時要用向左移替代乘法運算。
---
### page table的cache - TLB (translation-lookaside buffer)
page table存放在main memory,代表程式每一次memory access都要花2次存取的時間,第一次讀取memory的page table轉出physical address,第二次拿著physical address存取memory獲取資料或是指令,如此速度太慢,由於page table的存取也具有locality of reference,為了加速virtual address到pysical address之間的轉換速度,因此設計page table的cache,稱為TLB (translation-lookaside buffer)。
方式如同cache,也可以使用軟體實作。由於page很大,一次可以用很久,所以TLB需要的entry很少,故TLB一般使用fully associative cache,以降低miss rate,反正要比的tag也不多,此外選用random的置換方式。
> cf. L1的hit time會決定CPU的clock cycle time,所以使用direct-mapped cache,只比一個tag而已,電路延遲時間較短,hit time最小。
欲計算TLB的容量大小,可以由physical address求TLB的physical page number,由virtual address求TLB的tag。
把TLB整合到pipeline,由於要讀取指令與要讀取資料的記憶體位址都是virtual address,都需要經過TLB轉換為physical address,接下來才能去讀取cache;分為instruction的TLB接在instruction memory前面;data的TLB接在data memory前面,但由於MEM stage時間過長,所以有時候會把data的TLB放在EX stage。
最後再把cache整合進TLB與virtual memory系統,如下面3張圖所示
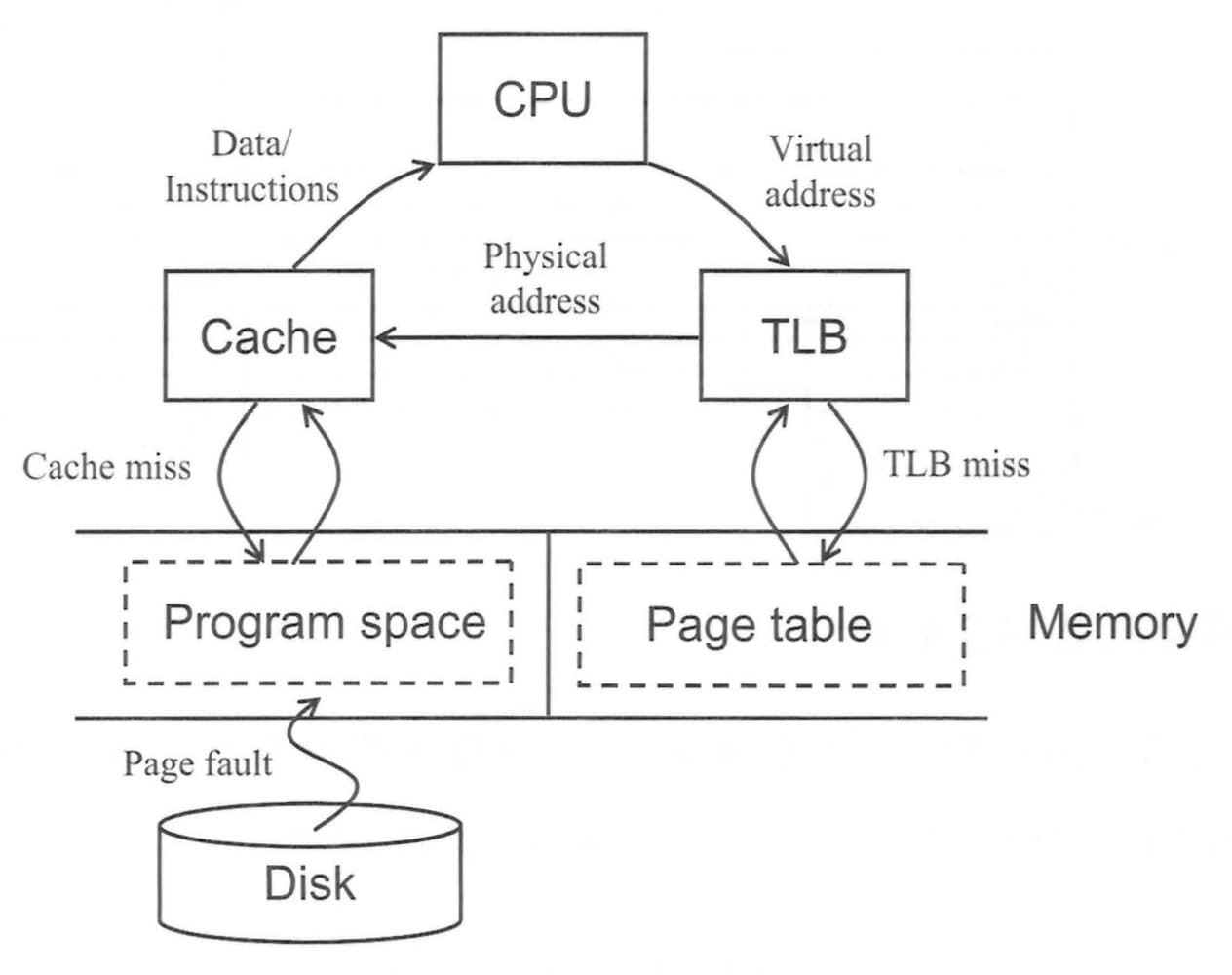

CPU丟出virtual (byte) address,根據page size的大小切成virtual page number與page offset,由於TLB在此使用fully associative cache,index值為0,故virtual page number等於tag值,拿著這個tag值跟TLB中的所有tag值做比對,若沒有相符項(TLB miss),再帶virtual page number找對應編號的page table,檢查valid bit是否為1,若valid bit = 0,則會觸發OS的exception - page fault;若valid bit = 1,則會把在main memory要存取的page搬至TLB。
順利從TLB存取到physical page number後,會將physical page number與page offset合成為physical address,physical address即為前面探討cache system的memory byte address,由[ch6 set associative cache](#set-associative-cache)觀念會切2刀
1. **一個block中的byte數**。左邊為memory block address,右邊為offset,其中offset又分為block offset(找一個block裡面的第幾個word)、byte offset(找一個word裡面的第幾個byte)。
2. **cache中的set總數**。左邊為tag,若與cache的tag比較相同為hit,不相同則為miss;右邊為index,代表要去cache哪個set找資料。
TLB的資料為page table的子集合,因此TLB hit代表page table一定也會hit;cache的資料為memory的子集合,因此cache hit代表資料存在memory中;page table與在memory中的資料又存在一對一的映射關係,因此page table hit與資料存在memory中是等價關係。欲判斷TLB / page table / cache hit or miss中各種可能與不可能的情況,若皆符合3者條件則有可能發生,反之只要有一個條件不滿足就不可能發生。
---
### virtually addressed cache機制與解決aliasing問題
前面都是假設讀取cache之前都需要將virtual address經過TLB轉換為physical address,也就是physically addressed cache的機制,存取一次記憶體,需要考慮到TLB和cache的時間,速度太慢。
因此改良版是直接使用virtual address作為cache的index與tag值,稱為virtually addressed cache,在cach hit的情況下,不需要額外存取到TLB;而在cache miss的情況下,才需要將virtual address經過TLB轉換為physical address,從main memory抓需要的block到cache。
這邊需要另外介紹aliasing - compiler在compile時,會把"兩個程式共用資料"的訊息告訴OS,所以當OS把兩程式的virtual space複製到physical memory時,只會複製一份"兩個程式共用資料"。若使用virtually addressed cache發生aliasing情況,就會造成aliasing問題。
解法是改使用virtually indexed, physically tagged cache。CPU發出virtual address切出index,到cache中找到對應的set;同一時間透過TLB轉出physical address,切出tag,與cache中所找到的set中所有tag做比對,若cache hit,則順利找到資料回傳給CPU;此外,需要配合軟體機制,兩個block不能同時有效,需要一個無效、另一個有效。由於cache中不同資料的index雖然不同,但tag都是一致的,因此不會產生aliasing問題。
---
### virtual memory的保護機制
[ch6 虛擬記憶體(virtual memory)](#虛擬記憶體virtual-memory)提及設計virtual memory有2大動機,其中之一就是virtual memory讓單一memory可以由多個process共享,為了達成這個目的,硬體需要支援以下3個能力
1. 支援2種模式 - user program在user mode運行;OS program在supervisor / kernel mode運行。
2. 在user mode下,一部分處理器狀態(mode bit, page table pointer, TLB)只能讀不能寫,只有在kernel mode下,OS執行"特權指令"才能更改數值。
3. 提供處理器在user mode與kernel mode之間跳轉的機制,從user mode跳到kernel mode需要system call這類exception達成;從exception跳回user mode則是跳回EPC地址,稱為return from exception (ERET)。
---
### 記憶體階層的4個問題
1. block可以可以被放在哪個地方?<br>
direct-mapped只能放在一個地方,set associative能放在其中一個集合之中,一個集合所能放的block數就是associativity;fully associative則可以放在cache的任意地方。欲減少miss rate,如果不計硬體成本(比較器),增加block size(也等比例提高cache size)會比提高關聯度還有效。
2. 如何找到一個block?<br>
direct-mapped根據index找到要搜尋cache的位址,只需比對1次檢查tag是否相同;set associative一樣根據index找到要搜尋cache的位址,但需要平行比對關聯度數量的tag是否相同;fully associative沒有個別的index,直接比對全部tag;至於physical memory如果跟fully associative cache一樣使用tag,則要比對tag的數目過多,因此會使用page table,直接查表,就不需要做比對的動作。
3. 發生cache miss,該置換哪個block?<br>
direct-mapped只有一個block的可能性,所以沒有這個問題,但是set associative和fully associative數個block都有機會被置換掉,因此使用2種策略方式 - 一是random,二是least recently used (LRU),由於真正的LRU硬體成本太高,所以page table使用近似LRU的方式,用reference bit ( = user bit)來記錄。
4. 寫入會發生什麼事?<br>
分為兩種,write-through是除了寫入cahce之外,也直接寫入記憶體,優點是硬體實作簡單;wite-back ( =copy-back)是使用dirty bit來記錄是否需要寫入,若dirty bit = 1則在置換時需要寫回memory下一個階層。在cache system中可以用write-through或是wite-back策略,但在virtual memory中,只能使用wite-back策略,因為main memory跟hard disk速度差數百萬倍!
---
### 發生cache miss的原因分類 - 3C
根據發生cache miss的原因做分類標準,分為3種 (3C)
1. **compulsory miss (= cold-start miss)**<br>
memory block"第一次"被使用,一定不在cache上面。可藉由增加block size,以降低compulsory miss發生的次數,但同時帶來的負面影響為miss penalty上升。
2. **capacity miss**<br>
只會發生在fully associative cache,cache容量不足以容納一個正在執行中的程式所需要用到的所有區塊。可以藉由加大cache size解決,但同時帶來的負面影響為cache hit time增加,進而影pipeline的clock cycle time。
3. **conflict miss (= collision miss)**<br>
只會發生在direct-mapped和set associative cache,幾個memory block競爭相同的cache set。可藉由提高關聯度,降低block之間的競爭,但同時帶來的負面影響為要比的tag數變多,cache hit time增加,進而影pipeline的clock cycle time。
至於set associative置換策略的選擇,選擇複雜置換策略好處是減少競爭程度,以降低conflict misses,但需要maintain的資訊變多,要判斷的資訊變多,造成決策時間變長。
降低compulsory miss的另一個方法是使用sequential prefetching。prefetching為發生cache miss後,一次抓2個block的資料到cache上,分為sequential (stride = 1)和stride。
sequential prefetching可以很直接理解就是利用程式存取的spatial locality特性,一次同時抓取下一個block;而stride存在原因 - 當陣列資料是2維,但存入memory變成一維資料並使用row-major順序存資料,當指令需要使用column major存取資料時,如果設定prefetching的stride為3,就可以抓到下一筆要執行的資料。
3C實戰題分為3步
1. **判斷cache hit / miss(假設關聯度 = 2的cache架構)**<br>
- index有2個不同者第一次出現 ⇒ miss。
- 往上找index一樣者,比tag值,若前面有2個tag都不一樣,代表set中的2個block都用完了,故發生cache miss。
2. **判斷3C類型**<br>
計算關聯度,fully associative cache不是compulsory miss,就是capacity miss;direct-mapped和set associative cache不是compulsory miss,就是conflict miss。
> compulsory miss跟程式占用幾個memory block有關,與使用哪種架構的cache無關。
3. **final content of cache**<br>
欲求cache的final content,就看各個index最後一次miss的值。
---
### 降低miss penalty的技術 - non-blocking cache用於superscaler
前面講的cache使用都是blocking cache,在cache還沒把資料搬完前,CPU會停下來;但在superscaler (= dynamic multiple issue)中,發生cache miss時,non-blocking cache允許CPU繼續執行存取cache的指令,利用後面的hit time來蓋過前面的miss penalty,稱為hit under miss;利用後面的miss penalty來蓋過前面的miss penalty,也就是允許多個未完成(outstanding) cache miss,稱為miss under miss。
---
### virtual machine
virtual machine的技術讓一部computer能run多個OS,有以下3個好處
1. 在一台computer裡面同時扮演多個server的角色,就不需要額外買多台computer。
2. 程式的執行不受限於OS,需要哪個OS直接install即可。
3. 隔離性與安全性較好,guest OS都是在user mode運行而已,縱使系統被攻擊,也只是一個software stack掛掉而已,其他OS還是活得好好的。
使用的是virtualization技術 - VMM (virtual machine monitor) / hypervisor會把"虛擬"的硬體mapping到"真"的硬體
1. time sharing - 把CPU切成時間片段,每個OS輪流使用一個時間片段。
2. partitioning - 將main memory拆成數個片段,分給各個OS,之後再利用virtual memory技術,讓OS誤以為有更大的記憶體空間。
3. emulation - 改變ROM裡面的程式,就可以改變硬體的特性。
VMM處在supervisor mode,而guest OS處在user mode,以確保guest OS不會直接改變真實硬體配置。
---
### 減少page table占用memory的空間
1. **一個limit register**<br>
使用一個limit register來限制page table的大小,轉出來的virtual page number與limit register做比較,若超過limit register的數值再動態加入所需entry到page table。
2. **兩個limit register**<br>
拆成管理stack和heap的page table,並使用2個limit register來限制個別page table的大小,MIPS使用此類方法。
3. **inverted page table**<br>
一般page table的高度由virtual space中virtual page的個數決定;而inverted page table相反,page table的高度由physical memory中physical page的個數決定。
4. **multiple level page table**<br>
用時間換取空間,只需要存目前指向page table的小區塊到memory就可,其餘page table放在hard disk中,因為一個page就可以用很久。
5. **allow page table to be paged**<br>
跟處理資料與資料相同的方式來處理page table,使用virtual memory基本的原理。
> multiple level page table與允許分頁表的分頁都是page table一部分放hard disk;一部分放main memory,只是機制上的不同。
## ch7 I/O設備
### 綱要
- 計算disk access time
- flash memory分為NOR flash與NAND flash
- 靠reliability與availability量化dependability
- RAID 0~6
- I/O設備定址分2種 - memory mapped I/O, special I/O instruction
- I/O設備與處理器的傳輸資料分4種 - polling, interrupt, DMA, I/O processor
---
### I/O設備介紹
對於CPU與memory著重於效能與成本,而I/O設備則是強調可靠度(dependability)與成本,可用3種特性來區別不同I/O設備
1. behavior - 輸入(鍵盤)、輸出(傳統螢幕)、可輸入也可輸出(儲存設備)
2. partner - 裝置另一端是人或是機器。
3. data rate - I/O設備與memory或是CPU之間最大的data transfer rate。
評估I/O效能,一般使用I/O bandwidth,有以下2種測量方式
1. 單位時間內,系統移動多少資料?
2. 單位時間內,處理多少I/O operation?
---
### 計算disk access time
disk藉由表面覆蓋磁性物質的plate與利用一個可移動的讀寫頭(read /write head)來存取資料,每個plate區分成多個同心圓,稱為track,而track又可分成sector,sector即為進出硬碟的實體基本單位。
disk access time計算分為以下5類相加
1. seek time - 移動讀寫頭到正確的track,由於移動讀寫頭是機械動作,速度會很慢,所以seek time幾乎占據disk access time大半的時間。
> 讀寫頭會停在最後讀完資料的地方,因此若是寫回一樣的地方,讀寫頭就在原本的track上,就不需要seek time。
2. rotational time ($= \frac{1}{\text{RPS}} \times 0.5$) - 等待plate將正確的sector旋轉至讀寫頭下方,期望值是旋轉plate半圈。
3. data transfer time ($= \frac{\text{data amount}}{\text{data transfer ratio}} = \frac{\text{data amount}}{\text{RPS} \times \text{data amount in a track}}$) - 將plate上儲存的資料,透過電磁感應傳輸資料到讀寫頭所花的時間。
4. controller time - 把OS下達的邏輯命令轉為讀寫頭實體運動移動的時間,disk需要有控制器去計算直流馬達要如何移動到指定的sector存取資料。
5. waiting time - 其他程序再使用硬碟需要等待所花的時間。
---
### flash memory
flash memory設計目的是用來取代hard disk的,但是由於磨損(wear out)之前能存取的次數太少,因此沒辦法直接取代hard disk,具有以下特性
1. 非揮發性,代表電源關閉資料還在。
2. 使用半導體製程技術做出來的。
3. 相較於hard disk,優點是抗震性較高、速度快100到1000倍、更不耗power、體積更小;缺點是單位容量價格較高。
4. 分為2種 - NOR flash可隨機存取,用於嵌入式系統的instruction memory;NAND flash以block作為存取的基本單位、相比NOR flash而言,密度更高、單位容量價格較便宜,用於USB或是相機的記憶卡。
---
### dependability
dependability是一個系統所能提供服務的品質,由於太過抽象,所以靠reliability與availability來"量化"一個系統的dependability。
- reliability - 用一陣子還是好的機率MTTF
- availability - 瞬間是好的機率$\frac{\text{MTTF}}{\text{MTTF} + \text{MTTR}}$
其中MTTF = mean time to failure,平均發生失敗時間;MTTR = mean time to repair,平均修復時間;MTBF = mean time between failure,平均失敗間隔,MTBF = MTTF + MTTR。增加MTTF有3個方法 - fault tolerance (系統錯誤依然可以繼續執行);fault avoidance (投票制,多個相同元件執行,選多數結果作為系統輸出);fault forecasting (估計常常發生錯誤的位置,當發生錯誤時,直接移除)。
---
### RAID
RAID (redundant arrays of inexpensive disks)主要想法是使用多個容量較少、較便宜的硬碟來獲得跟容量大、較昂貴的硬碟,有以下2種技術
1. data stripping - 將單一資料分散在不同硬碟,使存取一次資料可以平行存取多個硬碟資料,加快速度。
2. redundancy - 由於使用多個硬碟,代表增加零件,reliability會下降,因此使用多餘硬碟(增加redundancy),雖然不能增加系統的reliability,但能改善availability。
---
1. **RAID 0 - no redundancy**<br>
將一筆資料分散到不同硬碟之中(data stripping),以增加讀取硬碟的時間;但是沒有任何容錯硬碟,只要一顆硬碟壞掉,資料就會遺失,RAID 0 也有點名實不符,並沒有"redundant arrays",具有最佳的write latency。
2. **RAID 1 - mirroring**<br>
copy相同的資料備份到redundant disk,使得一份資料總是有2個copy,是最昂貴的RAID,因為儲存相同容量的資料下,需要最多硬碟,可以"選擇性"壞掉多個硬碟還是可以還原回資料,但若是同樣資料的2顆硬碟都壞掉,資料就再也救不回來。
3. **RAID 2 - ECC**<br>
利用Hamming code方式來偵錯與校正,但寫入少量資料時,就需要讀出所有data disk的資料,重新計算Hamming code並寫入ECC disk,因此效率不佳,因此才有RAID 3改良。
4. **RAID 3 - bit-interleaved parity**<br>
以bit為單位,將資料分散在各個data disk,partiy disk則是對同一個protection goup中的所有data disk做XOR的結果,若更新小筆資料,根據XOR的特性就不需要讀出其他data disk未更動的資料。當data disk有一個硬碟壞掉,把剩下完好的data disk和parity disk做XOR就可還原回資料。
<br><br>
RAID 3的缺點 - 在small read / write中,每次存取都會動用所有硬碟,霸佔所有硬碟的I/O operation,造成throughput(單位時間存取資料量)變差,因此才有RAID 4改良。
> 雖然在small read中throughput變差,但是latency會是所有RAID最好。
5. **RAID 4 - block-interleaved parity**<br>
RAID 3以bit為單位,而RAID 4改以block為單位,就可以平行處理small read,以增加throughput,但是平行處理small write時,由於都需要存取parity disk會遇到瓶頸,因此才有RAID 5改良。
> 當遇到large read / write(資料量遠超過一個block)時,RAID 4, RAID 5, RAID 6優勢不再,throughput會跟RAID 3一樣差。
6. **RAID 5 - distributed block-interleaved parity**<br>
RAID 5打散造成瓶頸的parity disk,混在同一個protection goup中的所有data disk,這樣就能解決單一的硬碟瓶頸。
7. **RAID 6 - P + Q redundancy**<br>
RAID 3, RAID 4, RAID 5最多只能容許1個disk壞掉而已,RAID 6將RAID 5中parity bit的數量增加2倍,使用的是Reed–Solomon校正碼,就可以容許2個disk壞掉。
8. **RAID 1+0 (striped mirror)與RAID 0+1(mirrored stripe)**<br>
不同RAID之間也可以排列組合。RAID 01為先做RAID 0再做RAID 1;RAID 10為先做RAID 1再做RAID 0。
---
### I/O設備定址
要下一個命令給I/O設備,處理器就必須要能夠定址I/O設備,由於每個I/O設備都會有data, status等暫存器,所以我們就可以對該暫存器編號,以定址I/O設備,分為以下2種
1. **memory mapped I/O**<br>
部分memory位址編號拿來給I/O設備編號用,memory系統就不需要理會這些指令,MIPS和ARM都屬於這種。
2. **special I/O instruction**<br>
處理器使用專屬的I/O指令,經由專屬的訊號線與編號與I/O設備溝通,而I/O指令都是特權指令,只有OS在supervisor mode之下才可使用。
---
### I/O設備與處理器的傳輸資料
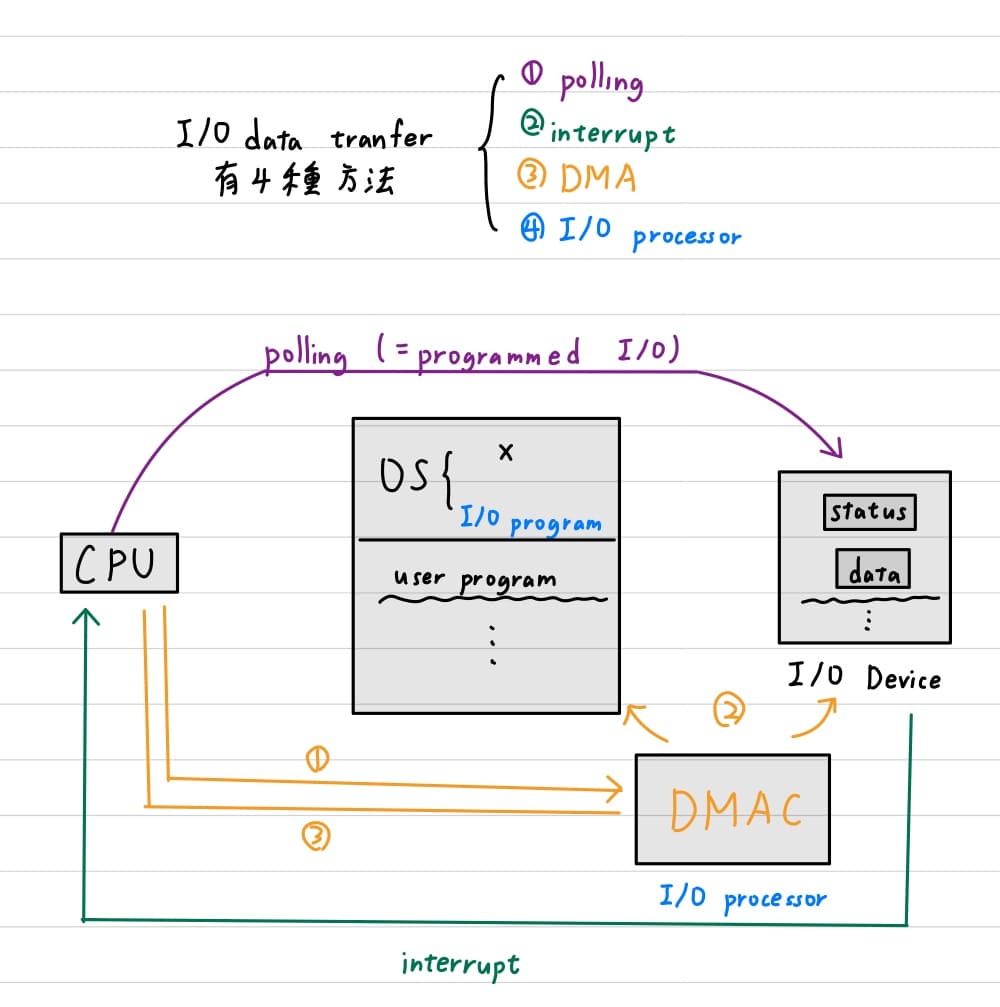
1. **polling ( =programmed I/O)**<br>
CPU會定時執行OS的polling routine,週期檢查I/O設備的status register。缺點是會浪費很多處理器時間,CPU讀取很多次status register,但是I/O都沒有完成I/O operation。
2. **interrupt**<br>
polling主動權在CPU,而interrupt的主動權則是在I/O設備上,I/O設備會拉一條實體線告知CPU並觸發interrput,此外告知中斷裝置的優先權,讓CPU先把優先級高、較緊急的interrupt先處理完。
3. **DMA (directed memory access)**<br>
為了降低處理器的負擔,會使用額外的硬體 - DMAC來處理I/O設備與memory之間傳輸資料,DMA傳輸分為以下3個步驟
1. CPU初始化DMAC,提供裝置身份、是讀還是寫的動作、存取記憶體的起始位址、傳輸的byte個數。
2. DMAC取得bus的使用權,監督資料在memory與I/O之間傳輸。
3. 一旦DMAC完成傳輸,中斷CPU,CPU會檢查DMAC與記憶體,看看是否完成操作。
4. **I/O processor**<br>
"更厲害"的DMAC,會直接執行OS製造出來I/O program的指令。
以上3種I/O設備與處理器的傳輸資料的排序
- 最少I/O operation latency - 1. polling 2. DMA 3. interrupt
- 最少CPU的使用率 - 1. DMA 2. interrupt 3. polling
---
## ch8 多重處理器系統
### 綱要
- 多處理器對sequential程式可增加JLP、對concurrent程式可增加TLP
- 多處理器資料交換方式分為SMP(UMA, NUMA)與MPP
- 用snooping協定(write-invalidate, write-update)解決UMA的cache coherence問題
- hardware multithreading允許多個thread交錯使用在單一個處理器上執行
- 平行電腦根據指令流與資料流分為 - SISD, SIMD, MISD, MIMD
- GPU的工作原理、GPU與CPU的差異
- 衡量不同network topology效能、容錯的4個參數
---
### 多處理器(multiprocessor)的2個好處與撰寫平行程式的4個難題
多處理器定義為至少含有2個處理器以上的computer,有以下2個好處
1. 如果程式在run time時沒辦法被平行分解(sequential program),可以將個別program分派給多個處理器執行,增加job-level parallelism。
2. 如果程式在run time時可以被平行分解(concurrent program),把程式分成基本的執行單位稱為thread,並將數個thread分派給多個處理器執行,增加thread-level parallelism。
處理器又可稱為核心(core),單一處理器稱為microprocessor,多個處理器放在同一個晶片稱為CMPs(chip multicore microprocessor)。非平行程式與平行程式都可以在一個處理器或是多個處理器運行。
撰寫平行程式會遇到4個難點
1. **scheduling** - 平行程式要怎麼分解?根據功能還是處理的資料型態分解?
2. **load balance** - 指令與資料有分好處理與難處理的。哪個處理器執行時間最長,就決定平行處理工作完成的時間。
3. **time of synchronization** - 處理器之間存在資料相依性,需要等處理器A執行完獲得結果給處理器B使用,處理器B才能開始執行。
4. **communication overhead** - 處理器之間要交換資料,怎麼送資料,才能讓時間最短?
而且並不是所有程式都可以被平行分解(concurrent program),多處理器的效能會受限於無法平行分解程式(sequential progam)的比例。
$$
\text{Speedup}(P) = \frac{1}{s + \frac{1 - s}{P}} \leq \frac{1}{s}, s : \text{ratio of sequential progam}
$$
多重處理器系統分2種 - strong scaling, weak scaling
1. strong scaling - problem size固定的前提下,便可以達到預期的speedup。
2. weak scaling - problem size固定的前提下,無法獲得預期的speedup;但是放大problem size,處理器個數也等比例增加,此時就可達到預期的speedup。
strong scaling由於problem size是固定的,處理器個數也是相同,也就是$S, (1-S), P$數值相同,因此受限於Amdahl's law;weak scaling的problem size可以改變,處理器個數也可以等比例增加,也就是$S, (1-S), P$數值都可會變動,因此不受限於Amdahl's law。
---
### 多處理器資料交換方式分為SMP(UMA, NUMA)與MPP
要讓多處理器之間達到資料交換的目的有兩種做法
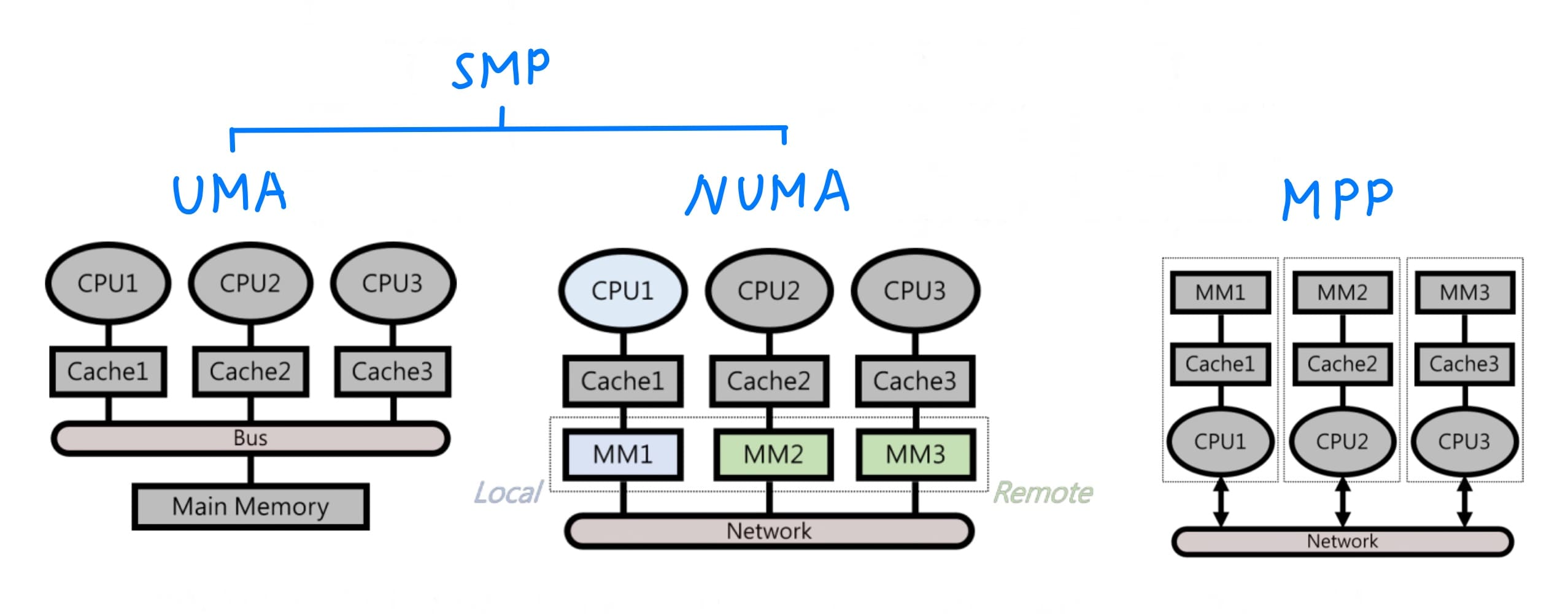
1. **記憶體共享多處理器(SMP, shared-memory multiprocessor)**<br>
讓多個處理器共用相同的memory空間,不同處理器如果要交換資料就可以宣告共用變數,透過不同處理器`lw, sw`記憶體中的共用變數,以達到資料交換的目的,又可細分為2種
- **UMA(uniform memory access multiprocessor, symmetric multiprocessor)**<br>
1. 邏輯與實際上只有一個memory,因此所有處理器存取memory的時間一致。
2. 用bus連接,由於bus頻寬有限,所以就沒辦法連接很多處理器,多處理器規模有限制。
3. 用bus連接,需要符合bus的通訊規則,每個處理器都要一模一樣(homogeneous multiprocessor)。
4. 由於都是homogeneous multiprocessor,所以在UMA寫程式較簡單。
- **NUMA(nonuniform memory access multiprocessor)**<br>
1. 邏輯上只有一個memory,但實際上分散多個memory到個別處理器底下,而處理器存取local memory(靠近自己的記憶體)較快、存取remote memory(遠離自己的記憶體)較慢,因此所有處理器存取memory的時間是不一致。
2. 用network連接,由於network頻寬較高,多處理器規模可以做比較大。
3. 用network連接,network的通訊規範較寬鬆,NUMA可以使用不一樣的處理器(heterogeneous multiprocessor)。
4. 由於是heterogeneous multiprocessor,所以在NUMA寫程式較困難。
5. 若將各自處理器要執行的程式盡量放在local memory,NUMA的存取效率會比UMA還好。
但SMP會遇到2個問題
1. synchronization(data race, critical section) - 硬體上用lock解決。
2. cache coherency - UMA使用snooping協定解決;NUMA使用directory解決。
而在MPP不會遇到這2個問題,因此SMP為了要解決這2個問題,在硬體實作上會比MPP複雜許多。
2. **訊息傳遞多處理器(MPP, message passing multiprocessor)**<br>
每個處理器擁有的cache都是"私有的",不同處理器如果要交換資料就需要透過處理器直接執行資料交換的命令`send(processor ID, message), receive()`。MPP從程式碼就可以知道不同處理器間有交換資料,是"外顯"的;但是SMP從程式碼看不出來不同處理器間有交換資料,是"內隱"的;此外MPP的硬體實作較SMP簡單。
---
### 用snooping協定解決UMA的cache coherence問題
在shared memory mutiprocesser系統中,一個memory的block可能同時存在在多個cache之中,如果任由處理器寫入各自的cache,就會造成**橫向之間cache資料的不一致,稱為cache coherence problem**。
> 對比[ch6 cache的機制](#cache的機制)講到cache system中,cache的資料與memory的資料不一致,稱為memory inconsistence。
UMA的cache coherence problem可以使用snooping protocol解決,每個cache都會窺探(snoop)bus上資料,以決定自己是否也要獲得一份相同資料的copy。使用2種方式解決
1. **write-invalidate**<br>
在改變自己處理器的cache之前,會將在其他處理器的cache的valid bit設為0、設為無效。
2. **write-update ( =write-broadcast)**<br>
在改變自己處理器的cache時,會透過bus廣播(broadcast)給其他cache,同步更新所有資料,但對bus的頻寬要求較大。
> 對比[ch6 cache的機制](#cache的機制)講到cache system中,解決memory inconsistence問題時,在write hit情況下使用write-through或是write-back;在write miss情況下使用write allocate或是write around( = no write allocate)。
在商用UMA中解決cache coherence問題,使用write-invalidate;解決memory inconsistence問題使用write-back,這是因為這兩種方式,對bus的頻寬要求比較小,避免造成bus頻寬上的瓶頸。
---
### hardware multithreading
**hardware multithreading允許多個thread交錯使用在單一個處理器上執行,來增加單一處理器功能單元的使用率**。根據切換thread時機分為2種
1. **fine-grained multithreading**<br>
輪流(round-robin fashion)讓多個執行續執行,優點是可以把short stall和long stall隱藏,缺點是由於每個執行緒頻繁切換,會拉長單一執行緒完成的latency。
2. **coarse-grained multithreading**<br>
只有遇到long stall時才會切換thread,優點是可以降低單一執行緒完成的latency,缺點一是遇到short stall會暫停;缺點二是由於切換thread時,需要清除與重新填入thread,會造成pipeline start-up成本。
3. **simultaneous multithreading(SMT)**<br>
跟fine-grained multithreading一樣,每個clock都會切換thread執行個別的指令包,但如果一個指令包不足4個指令,會從下一個thread的指令包拿指令,此外還會用到superscalar的硬體資源,除了利用到TLP之外,還有利用到ILP。
### 平行電腦分類
由Flynn提出,根據指令流(instruction streams)與資料流(data streans)分為
1. SISD - 單一指令處理單一資料,又稱為uniprocessor。
2. SIMD - 單一指令處理多筆資料,單一control unit會控制多個processing unit,適合向量運算,會運用到data-level parallelism。
3. MISD - 多個指令處理單一資料,現實無實作出這種機器,因為沒有必要。
4. MIMD - 多個處理器處理多個資料,就是標準的平行電腦,像是前面講的SMP、MPP都是屬於這種。
vector processor跟SIMD一樣,運用到data-level parallelism適合做向量運算,vector processor將ALU pipeline與大量暫存器存輸入與輸出結果,效能與SIMD差不多,但成本卻可以大大降低。
---
### GPU的工作原理、GPU與CPU的差異
1. GPU只是加速器,輔助CPU運算,因此無法像CPU一樣執行所有種類的指令,CPU與GPU的關係為heterogeneous multiprocessor。
2. GPU的程式語言使用high-level API,例如OpenGL、DirectX。
3. GPU的指令包括3D幾何指令,可以畫線與三角形;資料型態只有頂點$(x, y, z, w)$與圖像$(R, G, B, \alpha)$,長度皆為32 bit,也因此GPU不支援雙浮點運算。
4. GPU的working set(處理器在某一段時間內要處理的指令與資料)比CPU大上很多,且程式執行只具備spatial locality,不具備temporal locality。
5. GPU由多個SIMD組成,將程式拆成concurrent thread交錯在SIMD執行(hardware multithreading,用大量的thread交錯在單一處理器執行;SIMD會運用到data-level parallelism)。
6. 相較於memory latency,GPU更重視memory bandwidth,會使用memory bandwidth較高的特製DRAM。
7. 早期GPU使用heterogeneous special purpose processor與SIMD運算的指令(複習[ch2 多媒體運算](#多媒體運算),但為了降低編程的難度(負面影響 - 效率變差),現在逐漸使用一般目的暫存器與純量運算。
8. GPGPU (general purpose GPU) - 將一般目的的程式包裝成GPU可以接受的格式,便可以利用GPU高度平行處理資料的能力,來加速一般目的的程式。像是Nvidia的CUDA技術,即可使用C語言,就能編寫GPU的平行程式。
---
### network topology
network topology討論處理器之間如何連結,跟據線路切換開關次數分為single stage與mutliple stage,single stage在此介紹5種接法 - fully, linear, ring, 2-D mesh(一堆ring所組成), cube,mutliple stage在此介紹2種接法 - crossbar, omega network。
我們使用4個參數(2個用於評估效能 + 2個用於評估容錯)衡量不同network topology的優劣程度
1. **network bandwidth** - 所有網路的最大傳輸量,越大代表效能越好。
2. **bisection bandwidth** - 犧牲多少頻寬才可以把網路一切為2,越大代表容錯能力越好。
3. **nodal degree** - 要孤立一個處理器的話,要切斷幾個邊,越大代表容錯能力越好。
4. **diameter** - 最長兩點之間的最短路徑,任意兩個處理器至多經過n個邊就會傳送到對方,越大代表風險越高,花的時間也越長,效能越差。
下圖對3種不同single stage network topology,計算4個參數

---
## ch9 基礎概念
### 積體電路製作流程、成本計算、功率消耗
1. 積體電路(IC, integrated circuit) = 一顆晶片塞很多電晶體,電晶體扮演開關的角色,利用電壓來控制ON和OFF。
2. 積體電路製作流程如下
3. CMOS的功率消耗分為static與dynamic,static power由leakage current造成,而dynamic power公式為$C V_{DD}^2 f$,$C$為負載電容、$f$為CMOS的切換頻率,較詳細的介紹可以參照[2022/04/13(三)](https://hackmd.io/@HsuChiChen/2022-log-3#04/13(三))VLSI電路設計的power章節。
4. 摩爾定律是一個經驗法則,指出每隔18到24個月單位面積電晶體的數量就為增加一倍。
5. 積體電路的製造成本
- 一顆IC的成本 = 一片wafer成本 / (一片wafer上有幾顆IC \* 良率)
- 一片wafer上有幾顆IC = wafer面積 / 一顆IC的面積
- 良率 = 1 / (1 + (單位面積的錯誤率 * 一顆IC的面積/ 2))^2^,為經驗公式,只跟一顆IC的面積與製程技術的成熟度有關。
6. 我們不再追求單一個處理器的速度更快的2個主要原因 - power wall與memory gap(CPU與memory之間的速度差,memory進步的幅度跟不上CPU進度的幅度,因為我們對memory容量要求無止盡,memory既要快容量又要大很難達到)。
7. 過去30年,CLK頻率上升,但power卻沒有等比例上升的原因 - 工作電壓也跟著下降,從5V降至1V。