# Giới thiệu về NoSQL
## 1. MỞ ĐẦU
### 1.1. Thời đại bùng nổ dữ liệu
Thế giới đang bước vào **kỷ nguyên dữ liệu**: mọi hoạt động của con người đều tạo ra dữ liệu. Sự phát triển của Internet, thiết bị IoT, mạng xã hội, thương mại điện tử… làm cho dữ liệu tăng trưởng với tốc độ theo cấp số nhân.
#### a. Các nguồn tạo ra dữ liệu
- **Internet & Web:** Hàng tỷ trang web được truy cập mỗi ngày.
- **Công cụ tìm kiếm (Google, Bing…)** lưu trữ và phân tích dữ liệu khổng lồ.
- **Mạng xã hội:** Facebook, Instagram, TikTok, Twitter/X… sinh ra dữ liệu dạng văn bản, hình ảnh, video. Trung bình mỗi ngày có hàng tỷ lượt tương tác (like, share, comment).
- **Thiết bị IoT và cảm biến:** Camera giám sát, đồng hồ thông minh, cảm biến trong xe, thiết bị y tế. Sinh ra dữ liệu thời gian thực.
- **Giao dịch số & Thương mại điện tử:** Dữ liệu từ mua sắm online, thanh toán điện tử, chuỗi cung ứng.
- **Hoạt động khoa học – công nghệ:** Genomics, vật lý hạt nhân, thiên văn học… sinh ra dữ liệu petabyte/exabyte.
- **Chính phủ & quản lý đô thị:** Dữ liệu dân cư, thuế, giao thông, y tế, an ninh.
#### b. Đặc trưng của Big Data – 5V

* **Volume (Khối lượng):** Dữ liệu khổng lồ, tính bằng TB, PB, EB.
* **Velocity (Tốc độ):** Dữ liệu được tạo ra và phải xử lý theo thời gian thực.
* **Variety (Đa dạng):** Văn bản, hình ảnh, video, dữ liệu cảm biến, log máy.
* **Veracity (Độ tin cậy):** Dữ liệu có thể nhiễu, không chính xác → cần xử lý, làm sạch.
* **Value (Giá trị):** Giá trị kinh tế, xã hội, khoa học được trích xuất từ dữ liệu.
#### c. Thách thức trong kỷ nguyên Big Data
* **Lưu trữ:** Hệ thống lưu trữ truyền thống không đủ khả năng.
* **Xử lý:** Yêu cầu kiến trúc phân tán, điện toán đám mây, HPC.
* **Bảo mật & riêng tư:** Nguy cơ rò rỉ thông tin cá nhân.
* **Kỹ năng nhân lực:** Cần đội ngũ Data Scientist, Data Engineer.
* **Chất lượng dữ liệu:** Làm sạch, chuẩn hóa, xử lý dữ liệu thiếu.
### 1.2. Hạn chế của cơ sở dữ liệu quan hệ
* Cơ sở dữ liệu quan hệ (RDBMS) (ví dụ: MySQL, Oracle, SQL Server, PostgreSQL) đã chiếm ưu thế trong nhiều thập kỷ.
* Tuy nhiên, cùng với sự bùng nổ dữ liệu và nhu cầu mới (Big Data, IoT, AI, Cloud), RDBMS bộc lộ nhiều hạn chế.
* Điều này thúc đẩy sự ra đời và phát triển của cơ sở dữ liệu phi quan hệ (NoSQL).
#### a. Các hạn chế chính của RDBMS
* Hạn chế về khả năng mở rộng (Scalability)
- RDBMS chủ yếu hỗ trợ Vertical Scaling: nâng cấp phần cứng (CPU, RAM, SSD).
- Tốn kém và khó mở rộng vô hạn.
- Không tối ưu cho môi trường phân tán nhiều máy chủ (Distributed System).
* Hiệu năng với dữ liệu lớn (Big Data)
- Khi dữ liệu đạt mức TB → PB, tốc độ truy vấn giảm rõ rệt.
- Các thao tác JOIN nhiều bảng tốn nhiều tài nguyên.
- Không thích hợp cho dữ liệu phi cấu trúc (hình ảnh, video, log IoT).
* Linh hoạt về cấu trúc dữ liệu (Schema Flexibility)
- RDBMS cần schema cố định (cấu trúc bảng, kiểu dữ liệu).
- Thay đổi schema (ALTER TABLE) khó khăn, ảnh hưởng toàn hệ thống.
- Trong thực tế, dữ liệu thường đa dạng, thay đổi liên tục.
* Khả năng xử lý dữ liệu phi cấu trúc và bán cấu trúc
- RDBMS phù hợp với dữ liệu có cấu trúc (structured).
- Không tối ưu cho dữ liệu semi-structured (JSON, XML) hay unstructured (text, image, video, sensor log).
* Hạn chế về tính khả dụng (Availability)
- Mô hình ACID đảm bảo tính toàn vẹn dữ liệu → tốt cho giao dịch, nhưng làm giảm tốc độ và khả năng mở rộng trong hệ thống phân tán.
- Khó đạt được tính khả dụng cao (High Availability) khi dữ liệu phân tán trên nhiều trung tâm dữ liệu.
#### b. So sánh tóm tắt
| Tiêu chí | CSDL quan hệ (RDBMS) | Yêu cầu thời đại Big Data |
| --------------------------- | -------------------------- | -------------------------------- |
| Khả năng mở rộng | Vertical scaling | Horizontal scaling (distributed) |
| Loại dữ liệu | Chủ yếu structured | Structured + Semi/Unstructured |
| Schema | Cố định, khó thay đổi | Linh hoạt, schema-less |
| Tốc độ truy vấn dữ liệu lớn | Giảm mạnh khi dữ liệu > TB | Cần tốc độ cao, real-time |
| Hỗ trợ hệ thống phân tán | Hạn chế | Yêu cầu cốt lõi |
::: info
* RDBMS vẫn quan trọng, nhưng không còn đủ cho nhu cầu dữ liệu khổng lồ, đa dạng, thời gian thực.
* Đây chính là động lực cho sự ra đời của NoSQL Database.
:::
### 1.2. Mục tiêu bài học
* Hiểu khái niệm NoSQL.
* Nắm các đặc điểm chính, mô hình phổ biến.
* Phân biệt SQL và NoSQL.
* Ứng dụng thực tế & xu hướng.
## 2. ÔN TẬP NGẮN VỀ CƠ SỞ DỮ LIỆU QUAN HỆ
### 2.1. Mô hình quan hệ
* Cơ sở dữ liệu quan hệ (RDB – Relational Database): Mô hình dữ liệu dựa trên các bảng (table/quan hệ).
* Mỗi bảng gồm:
- Thuộc tính (Attribute/Column): mô tả đặc tính dữ liệu.
- Bộ (Tuple/Row): một bản ghi cụ thể.
* Toàn bộ dữ liệu được mô tả thông qua các quan hệ.
### 2.2. Ưu điểm
* Cấu trúc đơn giản, trực quan.
* Hỗ trợ tính toàn vẹn, nhất quán dữ liệu.
* Có ngôn ngữ chuẩn hóa (SQL).
* Dễ dàng mở rộng, bảo trì.
### 2.3. Nhược điểm
Khó mở rộng ngang, schema cứng nhắc, không phù hợp dữ liệu phi cấu trúc.
## 3. GIỚI THIỆU NoSQL
### 3.1. Khái niệm
NoSQL (Not Only SQL) là họ các hệ quản trị cơ sở dữ liệu phi quan hệ hoặc đa mô hình, ưu tiên:
- Lưu trữ dữ liệu linh hoạt về lược đồ (schema-flexible / schema-optional).
- Khả năng mở rộng ngang (scale-out) trên nhiều máy.
- Hiệu năng cao cho một số kiểu truy vấn/khối lượng công việc cụ thể (thường là đọc/ghi lớn, độ trễ thấp).
### 3.2. Lịch sử phát triển
* 1970s–1990s: RDBMS & SQL thống trị (ACID, chuẩn hoá, OLTP/OLAP).
- Đầu 2000s: Web bùng nổ → kiến trúc phân tán quy mô lớn tại các Big Tech:
- Amazon Dynamo (2007): nền tảng ý tưởng cho key-value phân tán, eventual consistency.
- Google Bigtable (2006): mô hình column-family cho dữ liệu khổng lồ, đặt nền cho HBase.
- MapReduce/GFS: hệ sinh thái xử lý phân tán (tiền đề Hadoop).
* 2008–2012: Thuật ngữ NoSQL phổ biến; xuất hiện nhiều dự án mã nguồn mở & dịch vụ:
- Cassandra (2008): kết hợp ý tưởng Dynamo + Bigtable, AP theo CAP, scale-out cực tốt.
- MongoDB (2009): document JSON-like, lược đồ linh hoạt, hệ sinh thái phong phú.
- Redis (2009): in-memory key-value, cấu trúc dữ liệu phong phú, độ trễ cực thấp.
- HBase (2008/2010): Hadoop ecosystem, mô hình wide-column theo Bigtable.
- Neo4j (2007/2010s): đồ thị, ngôn ngữ Cypher.
* 2013–nay: Đa mô hình & dịch vụ đám mây:
- DBaaS (MongoDB Atlas, DynamoDB, Cosmos DB), Time-Series (InfluxDB, Timescale), Search (Elasticsearch), Vector DB (Milvus, Pinecone) cho NLP/Embedding/RAG.
- Khuynh hướng polyglot persistence: dùng nhiều loại CSDL cho những phần việc khác nhau trong cùng hệ thống.
### 3.3. Đặc điểm chính
* **Tính linh hoạt:** NoSQL cung cấp các sơ đồ linh hoạt giúp công đoạn phát triển nhanh hơn và có khả năng lặp lại cao hơn. Điều này giúp NoSQL trở nên lý tưởng cho các ứng dụng cần lưu trữ dữ liệu phi cấu trúc hoặc dữ liệu có cấu trúc thay đổi theo thời gian.
* **Khả năng mở rộng:** NoSQL được thiết kế để tăng quy mô bằng cách sử dụng các cụm phần cứng được phân phối thay vì bổ sung máy chủ mạnh và tốn kém. Qua đó, chúng được đánh giá là khá phù hợp cho các ứng dụng có lượng dữ liệu lớn hoặc lượng dữ liệu tăng trưởng nhanh chóng.
* **Hiệu năng cao:** NoSQL được tối ưu cho các truy vấn nhanh và xử lý khối lượng lớn dữ liệu phi cấu trúc hoặc bán cấu trúc, chẳng hạn như dữ liệu dạng JSON, BSON, hoặc XML. Điều này làm cho NoSQL lý tưởng cho các ứng dụng yêu cầu phản hồi nhanh.
## 4. SO SÁNH SQL & NoSQL
| Tiêu chí | SQL| NoSQL|
| --------------------------- | -------------------------- | -------------------------------- |
| Ngôn ngữ truy vấn| Sử dụng ngôn ngữ SQL để truy xuất dữ liệu.| Sử dụng ngôn ngữ truy vấn riêng, API, công cụ truy vấn đặc thù thay cho SQL.|
| Khả năng mở rộng| Mở rộng theo chiều dọc bằng cách nâng cấp phần cứng.| Mở rộng theo chiều ngang bằng cách bổ sung node vào hệ thống.|
| Tính nhất quán| Tuân thủ các thuộc tính ACID, đảm bảo tính toàn vẹn và nhất quán của dữ liệu.| Áp dụng các thuộc tính BASE, ưu tiên tính sẵn sàng và khả năng chịu lỗi hơn tính nhất quán.|
| Cách thức lưu trữ| Dữ liệu được tổ chức theo mô hình xác định trước, bao gồm bảng, hàng và cột. | Dữ liệu có cấu trúc và phi cấu trúc có thể được lưu trữ linh hoạt dưới nhiều định dạng khác nhau.|
| Mô hình dữ liệu| Mô hình dữ liệu có cấu trúc (bảng).| Mô hình dữ liệu linh hoạt: Document, Graph, Key-Value, Wide-Column…|
## 5. CÁC MÔ HÌNH NoSQL PHỔ BIẾN
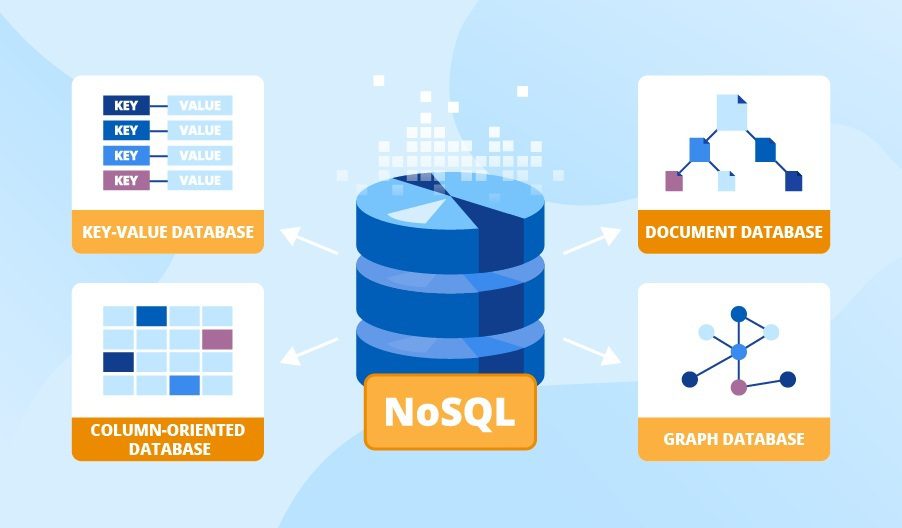
### 5.1. Key–Value Store
* Dữ liệu được tổ chức dưới dạng các cặp key -value (khóa- giá trị), trong đó mỗi đối tượng được định danh duy nhất bởi khóa và toàn bộ thông tin gắn với đối tượng được chứa trong giá trị tương ứng.
* Mô hình dữ liệu Key-value lưu trữ dữ liệu giống với một cơ sở dữ liệu quan hệ (RDMS) nhưng các bảng của cơ sở dữ liệu key-value chỉ có 2 cột.
* Hệ thống truy vấn value bằng cách sử dụng index key. Cơ sở dữ liệu Key-value lưu trữ dữ liệu giống với một cơ sở dữ liệu quan hệ (RDMS) nhưng các bảng của cơ sở dữ liệu key-value chỉ có 2 cột.
* Một số cơ sở dữ liệu Key-Value phổ biến: Redis, Amazon DynamoDB, Riak, Aerospike
### 5.2. Document Store
* Mô hình dữ liệu Document là một sự mở rộng của mô hình dữ liệu Key-value, nơi dữ liệu được tổ chức trong các tài liệu có cấu trúc như JSON hoặc XML. Các tài liệu này giúp dễ dàng ánh xạ các đối tượng (Object) trong phần mềm hướng đối tượng (Oriented Object software).
* Mô hình dữ liệu Document không yêu cầu phải xác định trước schema và cho phép lưu trữ dữ liệu phức tạp ở định dạng tài liệu như JSON hoặc XML. Mỗi tài liệu trong cơ sở dữ liệu Document là độc lập và không thể thực hiện các phép nối (join) mà trong ngữ cảnh này có nghĩa là không có cơ chế tự động để duy trì tính toàn vẹn quan hệ giữa các phần dữ liệu khi thực hiện các phép nối.
* Mặc dù không hỗ trợ dữ liệu quan hệ và bên cạnh các ưu điểm tương tự như mô hình dữ liệu key-value,mô hình dữ liệu Document có những ưu điểm bổ sung như khả năng truy vấn không chỉ bằng key mà còn truy vấn thuộc tính (attribute) trong tài liệu. Dữ liệu trong mỗi tài liệu có thể ở định dạng khác nhau và có thể được truy vấn một cách linh hoạt.
* Một số cơ sở dữ liệu Document phổ biến: MongoDB, CouchDB, Couchbase, RethinkDB, Firebase Firestore.
### 5.3. Column-family Store
* Mô hình dữ liệu Column Family kết hợp đặc điểm khai báo của cơ sở dữ liệu quan hệ với đặc điểm key-value pair và free schema của cơ sở dữ liệu Key-value. Thay vì lưu trữ dữ liệu dưới dạng hàng như cơ sở dữ liệu quan hệ, Column Family lưu trữ chúng dưới dạng các cột.
* Có hai loại Column Family:
- Standard Column Family: gồm một cặp key-value, trong đó key được ánh xạ tới một giá trị (value) là một tập hợp các cột.
- Super Column Family: bao gồm một cặp key-value, trong đó key được ánh xạ tới một giá trị (value) là các column family. Tương tự như trong cơ sở dữ liệu quan hệ, super column family có thể được coi là một “view” trên một loạt các bảng. Nó cũng có thể được hiểu như một bản đồ của các bảng.
* Một số cơ sở dữ liệu Column-family phổ biến: Apache Cassandra, HBase, ScyllaDB.
### 5.4. Graph Database
* Dữ liệu được lưu trữ theo hướng đồ thị. Một cơ sở dữ liệu Graph phải có tính năng truy xuất dữ liệu không cần index.
* Mỗi nút chứa một con trỏ (pointer) trực tiếp đến các nút liền kề của nó. Khi số lượng node tăng, chi phí để di chuyển từ nút này sang nút khác (hay còn gọi là một “bước nhảy”) vẫn được duy trì ổn định.
* Một số cơ sở dữ liệu Graph Database phổ biến: Neo4j, ArangoDB, OrientDB, Amazon Neptune.
### 5.5. Time-series Database (TSDB)
* TSDB mô hình hóa dữ liệu như các chuỗi thời gian—mỗi chuỗi là một dãy quan sát $(t_i,v_i)$ được gắn mốc thời gian $t$ và một hoặc nhiều giá trị đo $v$. Một chuỗi được nhận diện bởi khóa chuỗi (series key) gồm tên phép đo và tập nhãn (metadata) bất biến theo thời gian.
* Một số đặc điểm của mô hình dữ liệu TSDB:
- **Thông lượng ghi cao:** Dữ liệu chuỗi thời gian thường được tạo ra một cách liên tục và với tốc độ cao. Ví dụ điển hình là dữ liệu cảm biến từ các thiết bị IoT, dữ liệu nhật ký (log) từ máy chủ, hoặc giá cả trên thị trường chứng khoán. Các cơ sở dữ liệu chuỗi thời gian (TSDB) được tối ưu hóa cho việc xử lý khối lượng lớn các thao tác ghi tuần tự, giúp dễ dàng tiếp nhận các luồng dữ liệu có thông lượng cao mà không gây ra tắc nghẽn (bottleneck).
- **Truy vấn hiệu quả trên khoảng thời gian:** Do hầu hết các truy vấn trên dữ liệu chuỗi thời gian đều tập trung vào một khoảng thời gian nhất định, các TSDB được tối ưu hóa riêng cho những loại truy vấn này. Các truy vấn theo khoảng thời gian trên TSDB nhanh và hiệu quả hơn so với cơ sở dữ liệu quan hệ, nơi mà việc truy vấn theo thời gian có thể đòi hỏi phải quét qua nhiều hàng dữ liệu không cần thiết.
- **Lưu trữ và nén dữ liệu:** Dữ liệu chuỗi thời gian có tốc độ tăng trưởng rất nhanh, nhưng giá trị của dữ liệu lịch sử thường giảm dần theo thời gian. Các TSDB thường tích hợp sẵn các chính sách lưu trữ dữ liệu (data retention policies), cho phép tự động xóa bỏ (expiring) hoặc giảm tần suất lấy mẫu (downsampling) dữ liệu cũ (ví dụ: chỉ giữ lại giá trị trung bình hàng ngày của dữ liệu sau một năm). Ngoài ra, chúng còn áp dụng các thuật toán nén chuyên biệt, giúp giảm đáng kể yêu cầu về không gian lưu trữ.
* Một số cơ sở dữ liệu TSDB phổ biến: InfluxDB, TimescaleDB, OpenTSDB, Prometheus.
### 5.6. Search Engine Database
* Search Engine Database là mô hình dữ liệu được xây dựng chuyên biệt cho việc đánh chỉ mục (indexing) và truy vấn (querying) thông tin. Loại cơ sở dữ liệu này được tối ưu hóa cho việc tra cứu trên các tập dữ liệu lưu trữ có khối lượng lớn, dựa trên truy vấn của người dùng, sau đó trả về kết quả được xếp hạng theo mức độ liên quan.
* Quy trình trả về kết quả cho một truy vấn:
- Trong quá trình thu nạp dữ liệu (ingestion), cơ sở dữ liệu sẽ lưu trữ mỗi phần tử dữ liệu dưới dạng một tài liệu (document), tiến hành phân tích tài liệu đó, và bổ sung các chỉ mục (indexes) ánh xạ đến các tài liệu này. Ví dụ, một chỉ mục có thể ghi nhận tất cả các tài liệu chứa từ khóa “cat”.
- Sau khi dữ liệu đã được lưu trữ và đánh chỉ mục, người dùng có thể bắt đầu thực hiện truy vấn và tìm kiếm. Quá trình này thường đòi hỏi một dạng giao diện người dùng (UI) nào đó. Truy vấn sẽ được phân tách thành các token (đơn vị từ), và sau đó, chỉ mục được sử dụng để tìm ra tất cả các tài liệu liên quan đến truy vấn đó.
* Một số cơ sở dữ liệu Search Engine Database phổ biến: Elasticsearch, Solr, Vespa.
## 6. KIẾN TRÚC VÀ NGUYÊN LÝ HOẠT ĐỘNG
### 6.1. Replication và Sharding
#### 6.1.1. Replication là gì?
Replication là quá trình sao chép và duy trì dữ liệu trên nhiều máy chủ khác nhau. Thay vì chỉ lưu trữ dữ liệu ở một nơi duy nhất, hệ thống sẽ tạo ra các bản sao (replicas) của dữ liệu và đặt chúng trên các máy chủ (nodes) khác nhau trong một cụm (cluster). Mục tiêu chính của replication là đảm bảo tính sẵn sàng cao (high availability) và khả năng chịu lỗi (fault tolerance).
Nói một cách đơn giản, nếu một máy chủ chứa dữ liệu gặp sự cố (ví dụ: hỏng phần cứng, lỗi mạng), hệ thống vẫn có thể tiếp tục hoạt động bình thường bằng cách sử dụng dữ liệu từ các bản sao trên các máy chủ khác.
#### 6.1.2. Lợi ích của Replication
- Tăng tính sẵn sàng và độ tin cậy: Đây là lợi ích quan trọng nhất. Khi máy chủ chính gặp sự cố, một trong các bản sao sẽ được "bầu" lên làm máy chủ chính mới để tiếp tục xử lý các yêu cầu, giúp giảm thiểu thời gian gián đoạn dịch vụ.
- Tăng khả năng đọc (Read Scalability): Các truy vấn đọc có thể được phân phối trên nhiều máy chủ bản sao thay vì dồn toàn bộ về máy chủ chính. Điều này giúp giảm tải cho máy chủ chính và cải thiện đáng kể hiệu suất đọc của toàn hệ thống, đặc biệt hữu ích với các ứng dụng có lượng truy vấn đọc lớn.
- Phục hồi sau thảm họa (Disaster Recovery): Dữ liệu có thể được nhân bản đến một trung tâm dữ liệu ở vị trí địa lý khác. Nếu có sự cố nghiêm trọng xảy ra ở trung tâm dữ liệu chính (thiên tai, mất điện diện rộng), hệ thống vẫn có thể được khôi phục từ các bản sao ở xa.
#### 6.1.3. Các mô hình Replication phổ biến
Có hai mô hình nhân bản chính được sử dụng trong các hệ thống NoSQL:
- Master-Slave (Leader-Follower) Replication:
- Trong mô hình này, sẽ có một node được chỉ định là Master (hoặc Primary/Leader). Mọi thao tác ghi (write operations như insert, update, delete) đều phải được thực hiện trên node Master này.
- Sau đó, dữ liệu từ Master sẽ được sao chép (nhân bản) một cách tự động sang các node khác, gọi là Slaves (hoặc Secondaries/Followers).
Các node Slave thường chỉ xử lý các yêu cầu đọc (read operations).
- Ưu điểm: Đảm bảo tính nhất quán của dữ liệu ghi vì chỉ có một nguồn ghi duy nhất.
- Nhược điểm: Node Master có thể trở thành điểm nghẽn cổ chai (bottleneck) khi lưu lượng ghi quá lớn. Nếu Master bị lỗi, hệ thống cần một khoảng thời gian nhỏ để bầu chọn một Slave lên làm Master mới.
- Peer-to-Peer (Master-Master/Multi-Leader) Replication:
- Trong mô hình này, tất cả các node đều có vai trò như nhau và đều có thể xử lý cả yêu cầu đọc và ghi.
- Khi một node nhận yêu cầu ghi, nó sẽ tự động đồng bộ hóa sự thay đổi đó với các node khác trong cụm.
- Ưu điểm: Ghi dữ liệu có thể thực hiện trên bất kỳ node nào, giúp phân tán tải ghi và tránh được điểm nghẽn cổ chai. Rất phù hợp cho các hệ thống phân tán trên nhiều trung tâm dữ liệu ở các vị trí địa lý khác nhau.
- Nhược điểm: Phức tạp hơn trong việc giải quyết xung đột khi cùng một dữ liệu được cập nhật đồng thời trên nhiều node khác nhau (write conflicts).
#### 6.1.4. Sharding là gì?
Nếu Replication là việc sao chép toàn bộ dữ liệu ra nhiều nơi, thì Sharding là việc chia nhỏ dữ liệu thành nhiều phần và lưu trữ mỗi phần trên một máy chủ riêng biệt. Đây là một phương pháp phân vùng dữ liệu theo chiều ngang (horizontal partitioning). Mỗi một phần dữ liệu được chia nhỏ ra gọi là một shard. Mỗi shard hoạt động như một cơ sở dữ liệu độc lập, chứa một tập con của tổng thể dữ liệu.
Sharding giải quyết bài toán khi khối lượng dữ liệu trở nên quá lớn, vượt quá khả năng lưu trữ hoặc xử lý của một máy chủ duy nhất.
#### 6.1.5. Lợi ích của Sharding
- Mở rộng khả năng lưu trữ và ghi: Khi dữ liệu tăng lên, thay vì nâng cấp phần cứng (mở rộng theo chiều dọc - vertical scaling) vốn tốn kém và có giới hạn, chúng ta có thể thêm các máy chủ mới (các shard mới) vào hệ thống (mở rộng theo chiều ngang - horizontal scaling). Điều này giúp tăng cả dung lượng lưu trữ và khả năng xử lý các thao tác ghi.
- Tăng hiệu suất truy vấn: Khi dữ liệu được phân tán trên nhiều shard, một truy vấn thường chỉ cần thực thi trên một hoặc một vài shard chứa dữ liệu liên quan, thay vì phải quét qua toàn bộ cơ sở dữ liệu. Điều này làm giảm thời gian phản hồi của truy vấn.
- Cân bằng tải (Load Balancing): Dữ liệu và các yêu cầu truy vấn được phân phối đều trên các shard, tránh tình trạng một máy chủ bị quá tải trong khi các máy chủ khác lại rảnh rỗi.
#### 6.1.6. Kiến trúc và cách hoạt động của Sharding
Một hệ thống sharding điển hình (ví dụ trong MongoDB) bao gồm ba thành phần chính:
- Shards: Là các máy chủ chứa các phần dữ liệu đã được phân mảnh. Để đảm bảo tính sẵn sàng cao, mỗi shard thường là một replica set (tức là kết hợp cả Sharding và Replication).
- Config Servers (Máy chủ cấu hình): Lưu trữ metadata của cluster, tức là thông tin về việc dữ liệu nào đang được lưu ở shard nào. Nó giống như một "bản đồ" chỉ đường cho các truy vấn.
- Query Routers (Bộ định tuyến truy vấn, ví dụ: Mongos trong MongoDB): Là thành phần giao tiếp với ứng dụng client. Khi nhận một truy vấn, nó sẽ hỏi Config Server để biết dữ liệu cần tìm nằm ở shard nào, sau đó chuyển tiếp truy vấn đến shard đó và trả kết quả về cho client.
Để phân phối dữ liệu lên các shard, hệ thống cần một **Shard Key**. Đây là một hoặc nhiều trường có trong mỗi bản ghi, và giá trị của shard key sẽ quyết định bản ghi đó được lưu vào shard nào. Việc lựa chọn shard key là cực kỳ quan trọng vì nó ảnh hưởng trực tiếp đến hiệu quả phân tán dữ liệu và hiệu suất của hệ thống.
#### 6.1.7. Kết hợp Replication và Sharding
Trong các hệ thống lớn, Replication và Sharding không loại trừ lẫn nhau mà thường được sử dụng kết hợp để tận dụng ưu điểm của cả hai.
Kiến trúc phổ biến là mỗi **shard** sẽ là một **replica set**.
- Sharding giúp chia nhỏ dữ liệu để hệ thống có thể mở rộng quy mô, xử lý được khối lượng dữ liệu và lượng truy cập lớn.
- Replication trong mỗi shard đảm bảo rằng nếu một máy chủ trong shard đó bị lỗi, dữ liệu của shard đó vẫn an toàn và shard vẫn có thể hoạt động, đảm bảo tính sẵn sàng cao cho toàn bộ hệ thống.
### 6.2. CAP Theorem
Định lý CAP, cũng được gọi là Định lý Brewer, được đề xuất bởi Eric Brewer vào năm 2000. Định lý này nêu rõ những đánh đối vốn có khi thiết kế hệ thống phân tán.

#### 6.2.1. Phát biểu của định lý CAP
Định lý CAP chỉ ra rằng trong hệ thống phân tán với dữ liệu được nhân bản thì không thể đảm bảo được cả 3 thuộc tính: tính nhất quán\(C\), tính khả dụng\(A\) và chịu lỗi phân vùng\(P\).
- C - Consistency: Trong hệ thống phân tán, tính nhất quán nghĩa là tất cả các nút hoặc bản sao trong hệ thống có dữ liệu giống nhau tại cùng 1 thời điểm. Khi có một máy khách đọc dữ liệu, nó sẽ nhận được dữ liệu mới nhất hoặc thông báo lỗi. Nói cách khác không có sự khác biệt về dữ liệu ở các nút khác nhau,
- A - Availability: Tính khả dụng nghĩa là các nút đang hoạt động bình thường của hệ thống có khả năng trả lời mọi yêu cầu từ máy khách, kể cả khi có nút gặp vấn đề hoặc bị phân vùng mạng. Một hệ thống khả dụng đảm bảo mọi yêu cầu đều nhận được câu trả lời, mặc dù nó không đảm bảo dữ liệu là phiên bản mới nhất.
- P - Partition Tolerance: Chịu lỗi phân vùng liên quan đến khả năng hệ thống có thể tiếp tục hoạt động ngay cả khi xảy ra phân vùng mạng. Phân vùng mạng có thể khiến các nút mất kết nối với nhau. Gây khó khăn cho việc giao tiếp và đồng bộ hoá.
Hãy tưởng tượng bạn đang vận hành một website với hai máy chủ — một ở Mỹ và một ở châu Âu. Khi một người dùng cập nhật hồ sơ công khai (ví dụ: tên hiển thị), quá trình sẽ diễn ra như sau:
1. Người dùng A kết nối tới máy chủ gần nhất (Mỹ) và cập nhật tên của mình.
2. Bản cập nhật này được replicate sang máy chủ ở châu Âu.
3. Khi Người dùng B ở châu Âu xem hồ sơ của A, họ sẽ thấy tên mới được cập nhật.

Mọi thứ đều hoạt động trơn tru cho đến khi xảy ra một sự cố phân vùng mạng — kết nối giữa máy chủ Mỹ và châu Âu bị gián đoạn. Lúc này chúng ta phải đưa ra một quyết định quan trọng:
- Phương án A: Trả về lỗi, vì không thể đảm bảo dữ liệu luôn mới nhất (chọn Consistency).
- Phương án B: Hiển thị dữ liệu có thể đã cũ (chọn Availability).
Trong một hệ thống phân tán, khả năng chịu lỗi phân vùng mạng là bắt buộc phải có. Khi có vấn đề lỗi mạng xảy ra, hệ thống phải lựa chọn giữa tính nhất quán và tính khả dụng.
#### 6.2.2. Khi nào chọn tính nhất quán
Một số hệ thống bắt buộc phải đảm bảo tính nhất quán, ngay cả khi phải đánh đổi tính sẵn sàng như:
- Hệ thống đặt vé: Hãy tưởng tượng nếu người dùng A đặt ghế 6A trên một chuyến bay, nhưng do lỗi phân vùng mạng, người dùng B vẫn thấy ghế đó còn trống và cũng đặt được. Kết quả là có hai người cùng đến nhận một ghế!
- Kho hàng thương mại điện tử: Nếu Amazon chỉ còn 1 chiếc bàn chải đánh răng, nhưng hệ thống lại hiển thị là “còn hàng” cho nhiều người dùng trong lúc xảy ra phân vùng mạng, họ có thể bán vượt quá số lượng thực tế.
- Hệ thống tài chính: Các sàn giao dịch chứng khoán cần hiển thị sổ lệnh (order book) chính xác và cập nhật theo thời gian thực. Nếu hiển thị dữ liệu cũ, giao dịch có thể được thực hiện với mức giá sai.
#### 6.2.3. Khi nào chọn tính khả dụng
Phần lớn các hệ thống có thể chấp nhận một mức độ không nhất quán tạm thời, và do đó nên ưu tiên tính sẵn sàng. Trong những trường hợp này, eventual consistency (nhất quán cuối cùng) là chấp nhận được. Nghĩa là hệ thống cuối cùng sẽ trở nên nhất quán, nhưng có thể mất vài giây hoặc vài phút.
- Mạng xã hội: Nếu người dùng A thay đổi ảnh đại diện, việc người dùng B vẫn thấy ảnh cũ trong vài phút là hoàn toàn chấp nhận được.
- Nền tảng nội dung (như Netflix): Nếu ai đó chỉnh sửa mô tả của một bộ phim, việc một số người dùng vẫn thấy mô tả cũ trong thời gian ngắn không phải là vấn đề nghiêm trọng.
- Trang đánh giá (như Yelp): Nếu một nhà hàng cập nhật giờ mở cửa, việc hiển thị thông tin hơi cũ một chút vẫn tốt hơn là không hiển thị gì cả.
Câu hỏi mấu chốt cần tự đặt ra là: “Liệu có thảm họa không nếu người dùng tạm thời thấy dữ liệu không nhất quán?”
- Nếu câu trả lời là có, hãy chọn Consistency.
- Nếu câu trả lời là không, hãy chọn Availability.
6.2.4. Ví dụ thực tế
Khi ưu tiên tính nhất quán, có thể chọn:
- Các RDBMS truyền thống như PostgreSQL, MySQL, ...
- Google Spanner.
- DynamoDB.
Khi ưu tiên tính khả dụng, có thể chọn:
- Cassandra.
- Redis.
### 6.3. BASE Model
ACID và BASE là 2 mô hình giao dịch của cơ sở dữ liệu, xác định cách một cơ sở dữ liệu tổ chức và thao tác với dữ liệu.
Trong ngữ cảnh cơ sở dữ liệu, một transaction (giao dịch) là bất kỳ thao tác nào mà cơ sở dữ liệu coi là một đơn vị công việc duy nhất. Một giao dịch phải hoàn tất toàn bộ thì cơ sở dữ liệu mới giữ được trạng thái nhất quán.
Ví dụ: khi bạn chuyển tiền từ tài khoản ngân hàng này sang tài khoản khác, tiền phải được trừ khỏi tài khoản của bạn và đồng thời phải được cộng vào tài khoản của bên nhận. Bạn không thể coi giao dịch đã hoàn thành nếu một trong hai bước chưa xảy ra.
- Cơ sở dữ liệu ACID ưu tiên tính nhất quán (Consistency) hơn là tính sẵn sàng (Availability) - toàn bộ giao dịch sẽ thất bại nếu có lỗi xảy ra ở bất kỳ bước nào trong giao dịch.
- Cơ sở dữ liệu BASE thì ngược lại, ưu tiên tính sẵn sàng hơn tính nhất quán. Thay vì làm giao dịch thất bại, hệ thống cho phép người dùng tạm thời truy cập dữ liệu chưa nhất quán. Sự nhất quán dữ liệu vẫn sẽ đạt được, nhưng không ngay lập tức.
#### 6.3.1. Giải nghĩa mô hình BASE
- **Basically available** có nghĩa là cơ sở dữ liệu luôn có thể được nhiều người dùng truy cập đồng thời. Một người dùng không cần phải chờ người khác hoàn tất giao dịch trước khi cập nhật bản ghi.
Ví dụ: khi có một đợt tăng đột biến lượng truy cập trên một nền tảng thương mại điện tử, hệ thống có thể ưu tiên hiển thị danh sách sản phẩm và nhận đơn đặt hàng. Ngay cả khi việc cập nhật số lượng tồn kho bị chậm trễ một chút, người dùng vẫn có thể tiếp tục mua hàng.
- **Soft state** ám chỉ việc dữ liệu có thể tồn tại ở trạng thái tạm thời, thay đổi theo thời gian, thậm chí ngay cả khi không có tác động hay đầu vào bên ngoài. Nó mô tả trạng thái trung gian của bản ghi khi nhiều ứng dụng cùng lúc cập nhật nó. Giá trị cuối cùng của bản ghi chỉ được xác định sau khi tất cả các giao dịch hoàn tất.
Ví dụ: khi người dùng chỉnh sửa một bài đăng trên mạng xã hội, thay đổi đó có thể chưa hiển thị ngay cho người khác. Tuy nhiên, sau đó bài đăng sẽ tự động cập nhật (phản ánh thay đổi cũ) mặc dù không có ai kích hoạt lại thao tác chỉnh sửa.
- *Eventually consistent* có nghĩa là bản ghi cuối cùng sẽ đạt được trạng thái nhất quán khi tất cả các cập nhật đồng thời đã hoàn tất. Lúc này, mọi ứng dụng truy vấn bản ghi đều sẽ nhìn thấy cùng một giá trị.
Ví dụ: trong một hệ thống chỉnh sửa tài liệu phân tán, nhiều người dùng có thể đồng thời chỉnh sửa cùng một phần của tài liệu. Nếu Người dùng A và Người dùng B chỉnh sửa cùng lúc, các bản sao cục bộ của họ có thể tạm thời khác nhau cho đến khi các thay đổi được truyền và đồng bộ. Tuy nhiên, theo thời gian, hệ thống sẽ đảm bảo tính nhất quán cuối cùng bằng cách lan truyền và hợp nhất các thay đổi từ nhiều người dùng.
#### 6.3.2. So sánh BASE và ACID
||BASE|ACID|
|-|-|-|
|Khả năng mở rộng|Mở rộng theo chiều ngang|Mở rộng theo chiều dọc|
|Sự linh hoạt|Linh hoạt hơn. Cho phép nhiều ứng dụng cùng lúc cập nhật một bản ghi.|Ít linh hoạt hơn. Khi xử lý, sẽ khóa bản ghi để ứng dụng khác không thể truy cập.|
|Hiệu năng|Xử lý được dữ liệu lớn, phi cấu trúc với thông lượng cao.|Hiệu năng giảm khi xử lý khối lượng dữ liệu lớn.|
|Đồng bộ dữ liệu|Không đồng bộ ở mức cơ sở dữ liệu.|Có. Nhưng việc đồng bộ gây độ trễ.|
#### 6.3.3. Chọn BASE hay ACID khi nào
Mặc dù có nhiều điểm khác biệt, cả hệ quản trị cơ sở dữ liệu ACID và BASE đều phù hợp trong những ứng dụng khác nhau.
- **ACID** là lựa chọn lý tưởng cho các ứng dụng doanh nghiệp đòi hỏi **tính nhất quán, độ tin cậy và tính dự đoán cao**.
👉 Ví dụ: ngân hàng sử dụng cơ sở dữ liệu ACID để lưu trữ giao dịch của khách hàng, vì tính toàn vẹn dữ liệu là ưu tiên hàng đầu.
- **BASE** phù hợp hơn cho các tác vụ **xử lý phân tích trực tuyến (OLAP)** với **dữ liệu phi cấu trúc, khối lượng lớn**.
👉 Ví dụ: các website thương mại điện tử sử dụng cơ sở dữ liệu BASE để cập nhật giá sản phẩm, vốn thay đổi thường xuyên. Trong trường hợp này, độ chính xác tuyệt đối của giá không quan trọng bằng việc đảm bảo tất cả khách hàng có thể truy cập giá sản phẩm theo thời gian thực.
## 7. Ứng dụng và thực tiễn
### 7.1. Xu hướng phát triển
Trong những năm gần đây, hệ sinh thái NoSQL tiếp tục phát triển mạnh mẽ, song hành cùng nhu cầu xử lý dữ liệu lớn (Big Data), phân tán (Distributed) và thời gian thực (Real-time Analytics). Một số xu hướng nổi bật có thể kể đến như sau:
1. Hướng tới mô hình lai (Hybrid / Multi-Model Database)
Ngày càng nhiều hệ quản trị NoSQL hỗ trợ đa mô hình dữ liệu trong cùng một nền tảng — ví dụ như ArangoDB hoặc Couchbase có thể lưu trữ dữ liệu document, key–value, graph và search đồng thời.
Mục tiêu là tận dụng ưu điểm của nhiều mô hình khác nhau mà không cần triển khai nhiều hệ thống tách biệt.
2. Hỗ trợ mạnh hơn cho truy vấn phức tạp và tính nhất quán
Các hệ thống NoSQL hiện đại như MongoDB, Cassandra, TiDB hay YugabyteDB đã dần bổ sung ngôn ngữ truy vấn tương tự SQL (SQL-like), ACID transaction, secondary index và join hạn chế.
Điều này giúp thu hẹp khoảng cách giữa NoSQL và RDBMS, mở rộng khả năng ứng dụng vào các hệ thống nghiệp vụ phức tạp.
3. Tích hợp chặt chẽ với hệ sinh thái Big Data & Cloud Native
NoSQL ngày càng được tích hợp sâu với các nền tảng xử lý dữ liệu như Apache Spark, Flink, Kafka, Airflow hay Kubernetes.
Các dịch vụ Database-as-a-Service (DBaaS) như Amazon DynamoDB, Azure Cosmos DB, hay MongoDB Atlas trở nên phổ biến, cho phép người dùng triển khai, mở rộng và giám sát cơ sở dữ liệu dễ dàng trên đám mây.
4. Xu hướng hướng tới hiệu năng cực cao và low-latency
Các hệ thống mới như ScyllaDB (C++), FoundationDB, hoặc DragonflyDB được tối ưu về hiệu năng I/O, đa luồng, và bộ nhớ đệm, hướng đến hàng triệu truy cập mỗi giây với độ trễ thấp.
Xu hướng này phù hợp với các ứng dụng thời gian thực như game, IoT, và phân tích streaming.
5. Mở rộng sang lĩnh vực AI và dữ liệu phi cấu trúc
Sự bùng nổ của AI/ML và vector database kéo theo xu hướng NoSQL tích hợp lưu trữ vector embedding để phục vụ tìm kiếm ngữ nghĩa (semantic search) và retrieval-augmented generation (RAG).
Nhiều cơ sở dữ liệu NoSQL như Milvus, Weaviate, hay Pinecone được thiết kế riêng cho nhu cầu này.
### 7.2. Ứng dụng thực tế của NoSQL
NoSQL không chỉ là một xu hướng kỹ thuật mà đã trở thành thành phần cốt lõi trong hạ tầng dữ liệu của nhiều hệ thống quy mô lớn hiện nay. Tùy theo đặc điểm dữ liệu và yêu cầu hiệu năng, từng loại NoSQL được áp dụng trong các lĩnh vực khác nhau.
1. Thương mại điện tử (E-commerce)
Các hệ thống như Amazon, eBay, hay Shopee sử dụng NoSQL để lưu trữ catalog sản phẩm, lịch sử truy cập, và giỏ hàng tạm thời.
Dữ liệu thay đổi liên tục và yêu cầu độ trễ thấp, nên các cơ sở dữ liệu như MongoDB, Redis, hoặc Cassandra thường được lựa chọn.
Ngoài ra, NoSQL hỗ trợ mở rộng ngang, giúp hệ thống vẫn ổn định khi lưu lượng truy cập tăng đột biến (ví dụ trong dịp giảm giá).
2. Mạng xã hội (Social Network)
Mỗi người dùng tạo ra hàng nghìn tương tác mỗi ngày (bài đăng, bình luận, tin nhắn, lượt thích).
Hệ thống cần lưu trữ mối quan hệ đồ thị (graph) giữa người dùng — vì thế, Neo4j, JanusGraph, hay Amazon Neptune được sử dụng để quản lý mạng kết nối.
Bên cạnh đó, Cassandra và ScyllaDB thường được dùng để lưu dòng sự kiện (timeline feed) do khả năng ghi nhanh và phân tán tốt.
3. Internet of Things (IoT)
Các cảm biến và thiết bị IoT gửi dữ liệu dòng thời gian (time-series) liên tục.
Những hệ thống như InfluxDB, TimescaleDB, Cassandra hoặc MongoDB thường được dùng để lưu trữ dữ liệu này.
Kết hợp với các công cụ xử lý streaming (Kafka, Flink), NoSQL giúp phân tích dữ liệu theo thời gian thực, phát hiện bất thường và dự đoán sự cố.
4. Logging và phân tích hành vi người dùng
Các nền tảng như Elasticsearch, ClickHouse, Cassandra thường được triển khai để lưu trữ log ứng dụng, truy vết (tracing) hoặc sự kiện người dùng.
Khả năng truy vấn nhanh và mở rộng dễ dàng khiến NoSQL trở thành lựa chọn phổ biến cho hệ thống giám sát, observability, và phân tích dữ liệu lớn.
5. Trí tuệ nhân tạo và tìm kiếm ngữ nghĩa (AI / Vector Search)
Với sự phát triển của Large Language Models (LLM), nhu cầu lưu trữ vector embedding để tìm kiếm ngữ nghĩa (semantic search) tăng mạnh.
Các Vector Database như Milvus, Weaviate, Pinecone, Qdrant — về bản chất là NoSQL thế hệ mới — đang được tích hợp vào các hệ thống RAG (Retrieval-Augmented Generation) và chatbot doanh nghiệp.
6. Hệ thống tài chính và thanh toán
Trước đây, lĩnh vực này gắn liền với cơ sở dữ liệu quan hệ. Tuy nhiên, với yêu cầu xử lý giao dịch song song và dữ liệu phi cấu trúc (log, event, metadata), NoSQL ngày càng được ứng dụng nhiều hơn.
Ví dụ: Couchbase và FoundationDB hỗ trợ ACID transaction mạnh mẽ, thích hợp cho các ứng dụng đòi hỏi vừa tốc độ vừa tính nhất quán.
### 7.3. Triển vọng tương lai
Sự hội tụ giữa NoSQL và NewSQL đang tạo ra thế hệ cơ sở dữ liệu “đa năng”, vừa hỗ trợ tính mở rộng phân tán, vừa đảm bảo tính toàn vẹn dữ liệu.
Nhiều hệ thống hiện đại như CockroachDB, TiDB, hay YugabyteDB kế thừa ưu điểm của cả hai thế giới, mở ra kỷ nguyên “One database for all workloads”.
Bên cạnh đó, xu hướng serverless database và AI-native database sẽ định hình thế hệ tiếp theo của NoSQL, nơi mà hệ thống có thể tự tối ưu, tự mở rộng và hiểu ngữ cảnh dữ liệu.
📘 Tổng kết chương 7:
NoSQL ngày nay không chỉ là lựa chọn thay thế cho SQL mà là nền tảng chủ đạo trong kiến trúc dữ liệu hiện đại — từ thương mại điện tử, mạng xã hội, IoT, cho đến trí tuệ nhân tạo. Việc hiểu rõ đặc điểm và ứng dụng thực tiễn của từng loại NoSQL giúp kỹ sư dữ liệu, lập trình viên và nhà nghiên cứu lựa chọn công nghệ phù hợp nhất cho từng bài toán cụ thể.
 Sign in with Wallet
Sign in with Wallet







