# Redes Neurais - Treinamento
## Funções de erro
COmo em todos os modelos até agora, para fazer o treinamento de uma rede neural, **precisamos de uma função de erro!**
No entanto, para problemas de regressão e classificação, precisamos usar diferentes funções de ativação na unidades de saída.
### Regressão
**Saída:**
\\[y = f\left(\sum^M_{j=1}w_{kl} z_j \right)\\]
onde a função de ativação \\(f(\cdot)\\) será a **IDENTIDADE**!
Portanto, a função de erro para minimizar será a **Error Sum of Squares (SSE)**:
* Para uma única saída: \\[E(w) = \frac{1}{2}\sum^N_{n=1}(y_n - t_n)^2\\]
* Para uma saída vetorial: \\[E(w) = \frac{1}{2}\sum^N_{n=1}\sum^K_{k=1}(y_{nk} - t_{nk})^2\\]
### Classificação
#### Caso binário (2 classes)
**Saída:**
\\[y = f\left(\sum^M_{j=1}w_{kl} z_j \right)\\]
onde a função de ativação \\(f(\cdot)\\) será a **SIGMOIDE**!
Portanto, a função de erro para minimizar será a **Cross-Entropy**:
\\[E(w) = -\sum^N_{n=1}t_n \ln{(y_n)} + (1 - t_n)\ln{(1-y_n)}\\]
#### K classes não mutuamente exclusivas (a instância pode pertencer a mais de uma classe)
**Saída:**
\\[y = f\left(\sum^M_{j=1}w_{kl} z_j \right)\\]
onde a função de ativação \\(f(\cdot)\\) será a **SIGMOIDE**!
Portanto, a função de erro para minimizar será a **Cross-Entropy**:
\\[E(w) = -\sum^N_{n=1}\sum^K_{k=1}t_{nk} \ln{(y_{nk})} + (1 - t_{nk})\ln{(1-y_{nk})}\\]
#### K classes mutuamente exclusiva
**Saída:**
\\[y = f\left(\sum^M_{j=1}w_{kl} z_j \right)\\]
onde a função de ativação \\(f(\cdot)\\) será a **SOFTMAX**!
Portanto, a função de erro para minimizar será a **Multiclass Cross-Entropy**:
\\[E(w) = -\sum^N_{n=1}\sum^K_{k=1}t_{nk} \ln{(y_{nk})} \\]
## Treinamento da rede neural
Queremos aprender os pesos da rede neural para minimizar uma função de erro. Nossos pesos são todas as setinhas no diagrama de uma rede:

### Quantos parâmetros temos? **questão de prova**
Em uma rede neural totalmente conectada temos que o número de parâmetros é:
\\[ \text{Número total de parâmetros} = \sum_{l=1}^{L} (n_{l-1} + 1) \times n_l\\]
onde:
\\(n_{l-1}\\) é o número de neurônios na camada anterior (ou no caso da camada de entrada, o número de características),
\\(n_l\\) é o número de neurônios na camada \\(l\\),
+1 é adicionado para levar em conta o viés (bias) em cada neurônio.
Exemplo:
Por exemplo, considere uma rede neural com uma camada de entrada de 3 características, uma camada oculta de 5 neurônios, outra camada oculta de 3 neurônios e uma camada de saída com 2 neurônios. O cálculo seria:

\\[4 \cdot 5 + 6 \cdot 3 + 4 \cdot 2 = 46\\]
### Minimizando a função de erro
A função de erro é uma superfície assentada sobre o espaço de peso. Nosso objetivo é encontrar o mínimo global em meio a todos os mínimos locais.

Normalmente essa superfície é muito complexa e não temos forma fechada para \\(\Delta E(w) = 0\\).
Portanto, usaremos um procedimento número iterativo.
Para isso, devemos escolher um valor inicial para \\(w\\) e, em seguida, mover ele pelo espaço dos pesos de forma a minimizar o peso, usando:
\\[w^{(\tau + 1)} = w^{(\tau)} + \Delta w^{(\tau)}\\]
Para esse curso iremos ver duas abordagens simples usando a informação do gradiente:
1. Otimização de descida de gradiente batch (ou descida mais íngreme – “gradient descent”)
\\[w^{(\tau + 1)} = w^{(\tau)} + \eta \Delta E(w^{(\tau)})\\]
onde \\( \eta \\) é chamada de **taxa de aprendizado**.
**Método batch** porque usa todo o conjunto de dados de uma só vez.
```PYTHON
def gradient_descent_batch(X, y, w_initial, learning_rate, num_iterations):
w = w_initial
for _ in range(num_iterations):
# Calcular o gradiente para todo o conjunto de dados
gradient = calculate_gradient(X, y, w)
# Atualizar os pesos usando a fórmula de descida de gradiente
w = w - learning_rate * gradient
return w
```
2. Otimização de descida de gradiente sequencial (ou estocástica – stochastic gradient descent)
Temos que o erro é composto por:
\\[E(w) = \sum^N_{n=1}E_n(w)\\]
onde o \\(E_n(w)\\) é o erro devido ao ponto de dados \\(n\\). Então:
\\[w^{(\tau + 1)} = w^{(\tau)} + \eta \Delta E_n(w^{(\tau)})\\]
faz uma atualização com base em um datapoint por vez.
```PYTHON
def gradient_descent_stochastic(X, y, w_initial, learning_rate, num_epochs):
w = w_initial
for _ in range(num_epochs):
# Embaralhar o conjunto de dados para garantir aleatoriedade
shuffled_indices = np.random.permutation(len(X))
X_shuffled = X[shuffled_indices]
y_shuffled = y[shuffled_indices]
for i in range(len(X_shuffled)):
# Calcular o gradiente para um único ponto de dados
gradient = calculate_gradient(X_shuffled[i:i+1], y_shuffled[i:i+1], w)
# Atualizar os pesos usando a fórmula de descida de gradiente estocástica
w = w - learning_rate * gradient
return w
```
**Pontos importantes:**
* **Cenários intermediários:** as atualizações são baseadas em lotes de pontos de dados.
* Pode ser necessário executar um algoritmo baseado em gradiente várias vezes, com diferentes pontos de partida para que não tenhamos uma solução em mínimos locais.
### Um procedimento iterativo para minimizar uma função de erro em uma rede neural
Cada passo tem 2 etapas:
1. Calcular as derivadas da função de erro em relação aos pesos
2. Usar as derivadas para calcular os ajustes dos pesos
**Estágio 1 - backprop:**
* pode ser aplicado a muitos tipos de rede.
* pode ser aplicado a diferentes funções de erro
* pode ser usado para calcular outras derivadas, como as matrizes jacobianas e hessianas.
**Estágio 2:**
Pode usar uma variedade de esquemas de otimização (também mais poderosos do que o gradiente descendente).
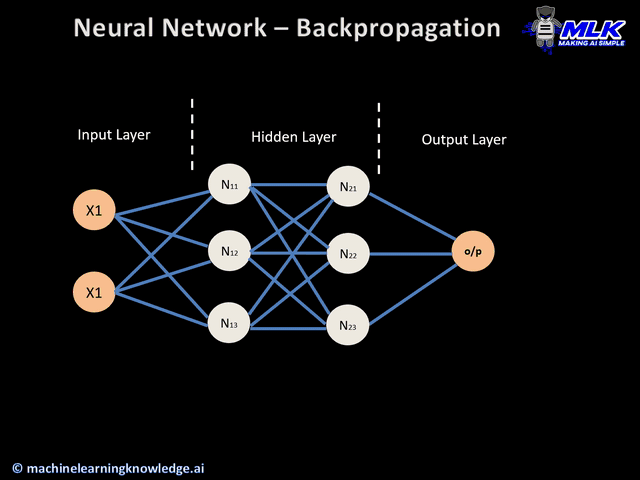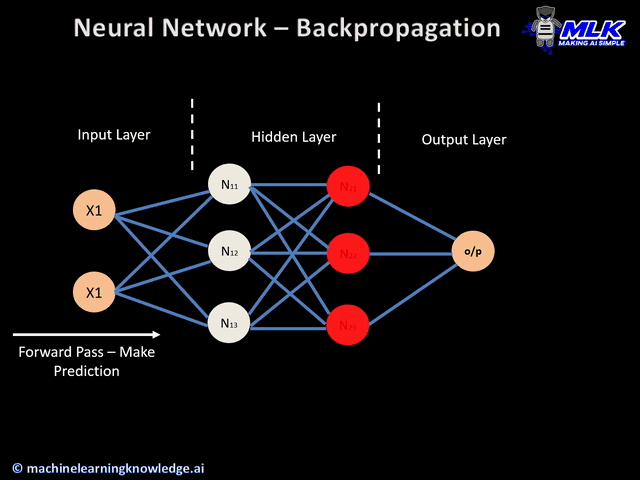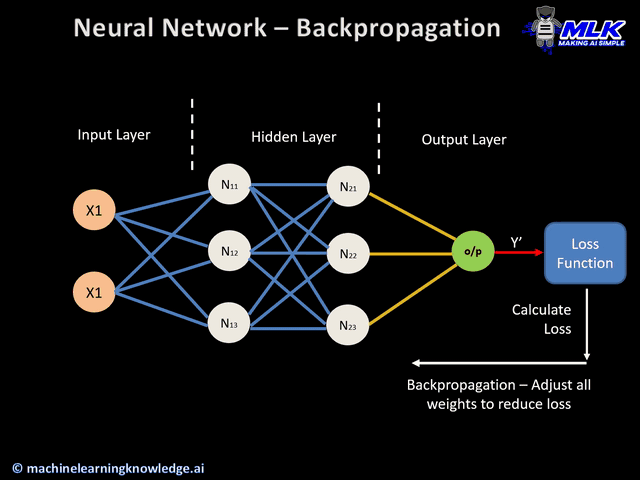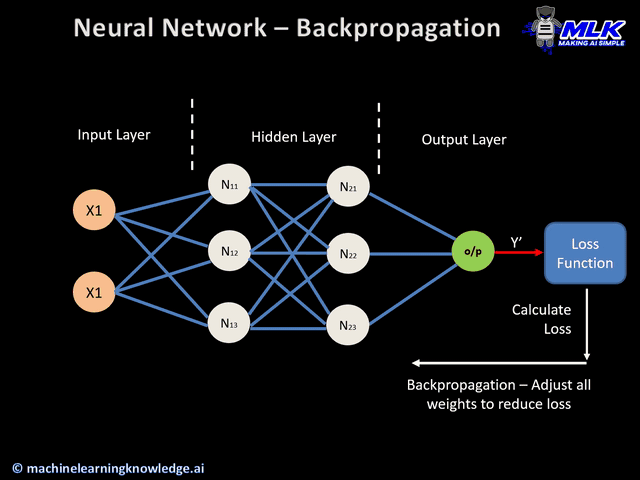
Para calcular o erro e então atualizar o peso da última camada é fácil, pois sabemo como deve ser nosso output, mas e as demais?

### Backpropagation
Dada uma rede neural artificial e uma função de erro, o método calcula o gradiente da função de erro em relação aos pesos da rede neural.
Vou mostrar a fórmula geral, mas vamos considerar a seguinte rede neural para exemplo:

Ou seja, queremos aprender os parâmetros:

*obs: Podemos armazenar esses pesos quero quisermos, mas irei fazer assim para facilitar a visualização.*
Para fazer os cálculos, iremos separar em duas partes: a primeira será a última camada e a outra erá as camadas ocultas.
Primeiramente, para qualquer camada na nossa rede neural, temos que nosso objetivo é, para cada \\(w\\), calcular:
\\[\frac{\partial E}{\partial w_{st}} = \frac{\partial E}{\partial a_s} \cdot \frac{\partial a_s}{\partial w_{st}}\\]
onde:
\\[a_s = \sum^tw_{st}z_t\\]

Para facilitar a representação dos cálculos, definiremos:
\\[\delta_s = \frac{\partial E}{\partial a_s}\\]
e, portanto, temos:
\\[\frac{\partial E}{\partial w_{st}} = \delta_s \cdot z_{t(camada-anteior)}\\]
#### Equações da Camada Final
Como na camada final temos o target para comparar, sabemos como nossos pesos devem variar, sendo a mesma coisa que fizemos na regressão linear e logistica.

Ou seja, no nosso caso que estamos na última camada, o\\(s\\) seria o nosso \\(s\\)-imo output da nossa rede.
Vamos dizer que nosso problema seja o de classificação e que estamos usando uma sigmoide, então nossa camada final seria:

Portanto, a função de erro será (estamos olhando apenas 1 datapoint):
\\[E = -\sum^S_{s=1}(t_s\ln(y_s) + (1-t_s)\ln(1-y_s))\\]
Portanto, como calculamos a derivada na aula sobre regressão logistica, temos que:
\\[\frac{\partial E}{\partial w_{st}} = (t_s - y_s)z_t\\]
**Ou seja, para calcular a derivada precisamos apenas da diferença da predição com o target e do valor \\(z\\) do neurónio anterior conectado a \\(w\\).**

*obs: Como vistos nas outras aulas, para o problema de regressão a fórmula para calcular a derivada será mesma!*
#### Equações da Camada Final
Novamente, queremos atualizar o peso \\(w_{ti}\\), ou seja:
\\[\frac{\partial E}{\partial w_{ti}} = \frac{\partial E}{\partial a_t} \cdot \frac{\partial a_t}{\partial w_{ti}} = \delta_t \cdot z_{i(camada-anteior)}\\]

Portanto, temos que calcular:
\\[\delta_t = \frac{\partial E}{\partial a_t} = \sum_s \frac{\partial E}{\partial a_s} \frac{\partial a_s}{\partial a_t}\\]
Sendo
\\[a_s = \sum_t w_{st}z_t = \sum_t w_{st}h(a_t)\\]

portanto:
\\[\frac{\partial a_s}{\partial a_t} = h'(a_t)w_{st}\\]
E assim:
\\[\delta_t = \sum_s \delta_sh'(a_t)w_{st} = h'(a_t)\sum_s \delta_sw_{st}\\]
Por fim, FINALMENTE:
\\[\frac{\partial E}{\partial w_{ti}} = \left(h'(a_t)\sum_s \delta_sw_{st}\right) z_{i}\\]
**Para que não haja confusão nos indices, a ideia é calcular o valor que do neurónio anterios \\((z_i)\\) e multiplicar pela derivada da função de ativica que nosso peso está conectado \\((h'(a_t))\\) multiplicado pela soma dos pesos \\(w_s\\) multiplicados pelos seus respectivos deltas do neurônio da camada que fizemos o último cálculo.**
Uma ideia é sempre pensar que para atualizar um peso, precisamos de todos os outros pesos e neurônios que conectam ele:

### Retropropagação de erro na prática
Como sempre precisamos de muitas coisas para calcular as derivadas, na computação é necessário guardar os valores de \\(a\\) e os \\(\delta\\) de cada unidade:
1. Aplique um vetor de entrada \\(x_n\\) à rede e avance a propagação através da rede (foward pass);
2. Avalie o \\(\delta_s\\) para todas as unidades de saída;
3. Use a fórmula de retropropagação para retropropagar os \\(\delta \\) e obter \\(\delta_t\\) para cada unidade oculta (backward pass)
4. As derivadas necessárias são dadas por \\(\delta_tz_i\\).
## Regularização
\\[ a_j = \sum^D_{i=1}w^{(1)}_{ji}x_i - w^{(1)}_{j0} \\]
\\[a_j = \sum^D_{i=1} w^{(1)}_{ji}x_i - w^{(1)}_{j0}\\]
 Sign in with Wallet
Sign in with Wallet







