# GANs for Image Translation
# Introduction
<div style="text-align: justify">
Many problems in image processing, computer graphics, and computer vision can be posed as *translating* an input image into a corresponding output image. Just as a concept may be expressed in either English or French, a scene may be rendered as an RGB image, a gradient field, an edge map, a semantic label map, etc. In analogy to automatic language translation, we define automatic image-to-image translation as the task of translating one possible representation of a scene into another, given sufficient training data.
The community has already taken significant steps in this direction, with convolutional neural nets (**CNNs**) becoming the common workhorse behind a wide variety of image prediction problems. CNNs learn to minimize a loss function and although the learning process is automatic, a lot of manual effort still goes into designing effective losses. In other words, we still have to tell the CNN what we wish it to minimize.
It would be highly desirable if we could instead specify only a high level goal, like “make the output indistinguishable from reality”, and then automatically learn a loss function appropriate for satisfying this goal. Fortunately, this is exactly what is done by the recently proposed **Generative Adversarial Networks** (GANs)
</div>
# Generative Adversarial Networks
## Global Context
<div style="text-align: justify">
A **Generative Adversarial Networks** (GAN) is a class of machine learning systems invented by *Ian Goodfellow* in 2014. Two neural networks contest with each other in a game. Given a training set, this technique learns to generate new data with the same statistics as the training set.
They are one of the most interesting ideas in computer science today. Two models are trained simultaneously by an adversarial process. A **generator** ("the artist") learns to create images that look real, while a **discriminator** ("the art critic") learns to tell real images apart from fakes.
</div>
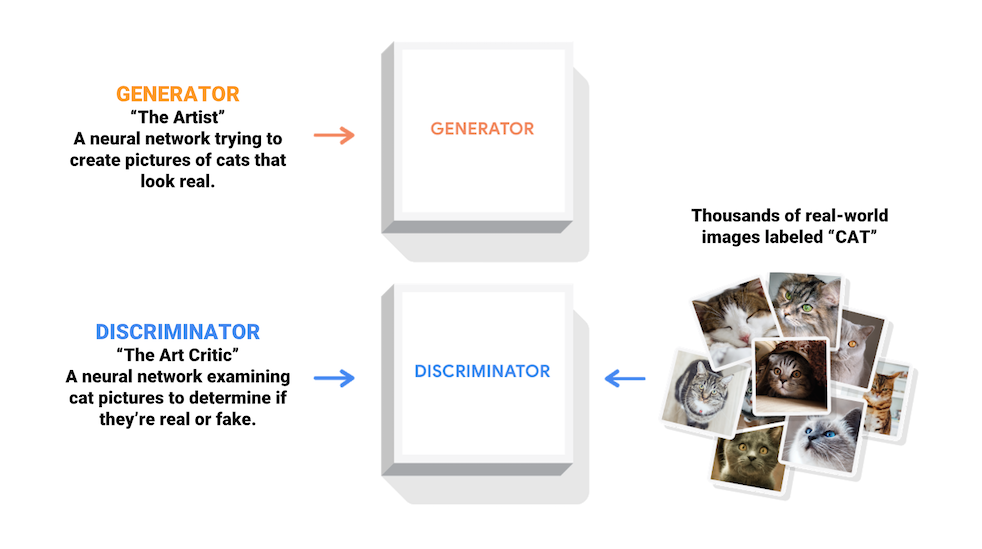
*Figure 1: Explanation of a GAN model*
<div style="text-align: justify">
During training, the generator progressively becomes better at creating images that look real, while the discriminator becomes better at telling them apart. The process reaches equilibrium when the discriminator can no longer distinguish real images from fakes.
</div>
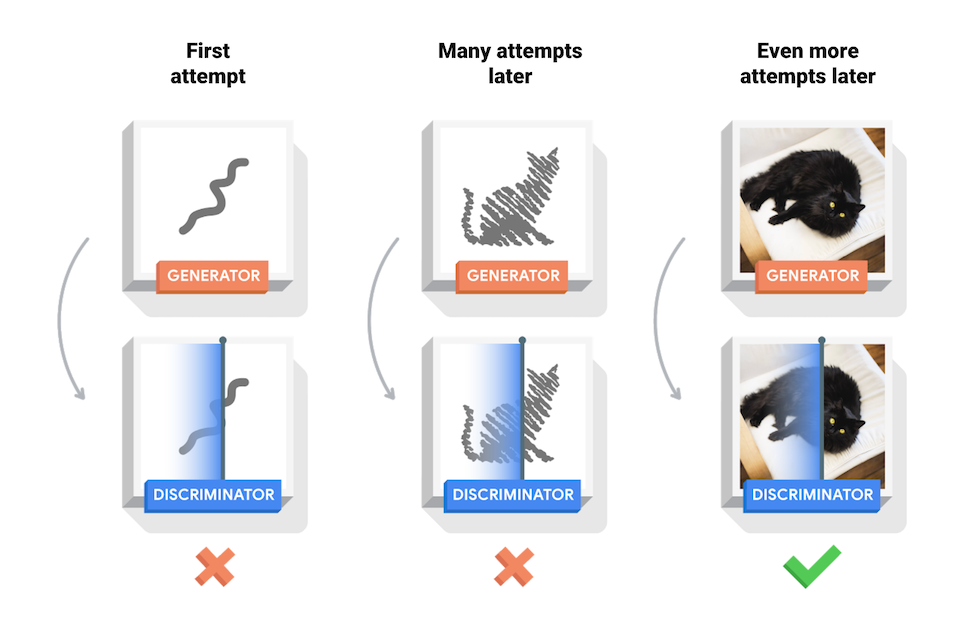
*Figure 2: Explanation of GAN training*
## GAN in depth
<div style="text-align: justify">
They are two main type of GANs :
- *Unconditionnal GANs*
- *Conditionnal GANs*
Unconditionnal GANs are generative models that learn a mapping from random noise vector $z$ to output image $y$, $G : z → y$
In contrast, conditional GANs learn a mapping from observed image x and random noise vector $z$, to $y$, $G : (x, z) → y$
Our objectif here is to transfer expression to facial paralysis patient. Therefore we will use a conditionnal GAN. The objective of a conditional GAN can be expressed as :
$$
L_cGAN(G, D) = \mathbb{E}_{x,y}[log(D(x, y))] + \mathbb{E}_{x,z}[log(1 − D(x, G(x, z))]
$$
where $G$ tries to minimize this objective against an adversarial D that tries to maximize it. I.E $G^∗ = arg(min_G(max_D(L_cGAN(G,D))))$
</div>
# State of the art
## Models presentation
- **DIAT**
<div style="text-align: justify">
Given the source input image and the reference attribute, Deep **Identity-Aware Transfer of Facial Attributes** (DIAT) aims to generate a facial image that owns the reference attribute as well as keeps the same or similar identity to the input image. In general, the model consists of a mask network and an attribute transform network which work in synergy to generate photorealistic facial image with the reference attribute :

*FIgure 3: Schematic illustration of the DIAT model*
The result observed might be pretty good :
| mouth open | mouth close | glasses removal | gender | age
|---|---|---|---|---|---|---|
| 0.821 | 0.806 | 0.763 | 0.684 | 0.702 |
</div>
- **CycleGAN**
<div style="text-align: justify">
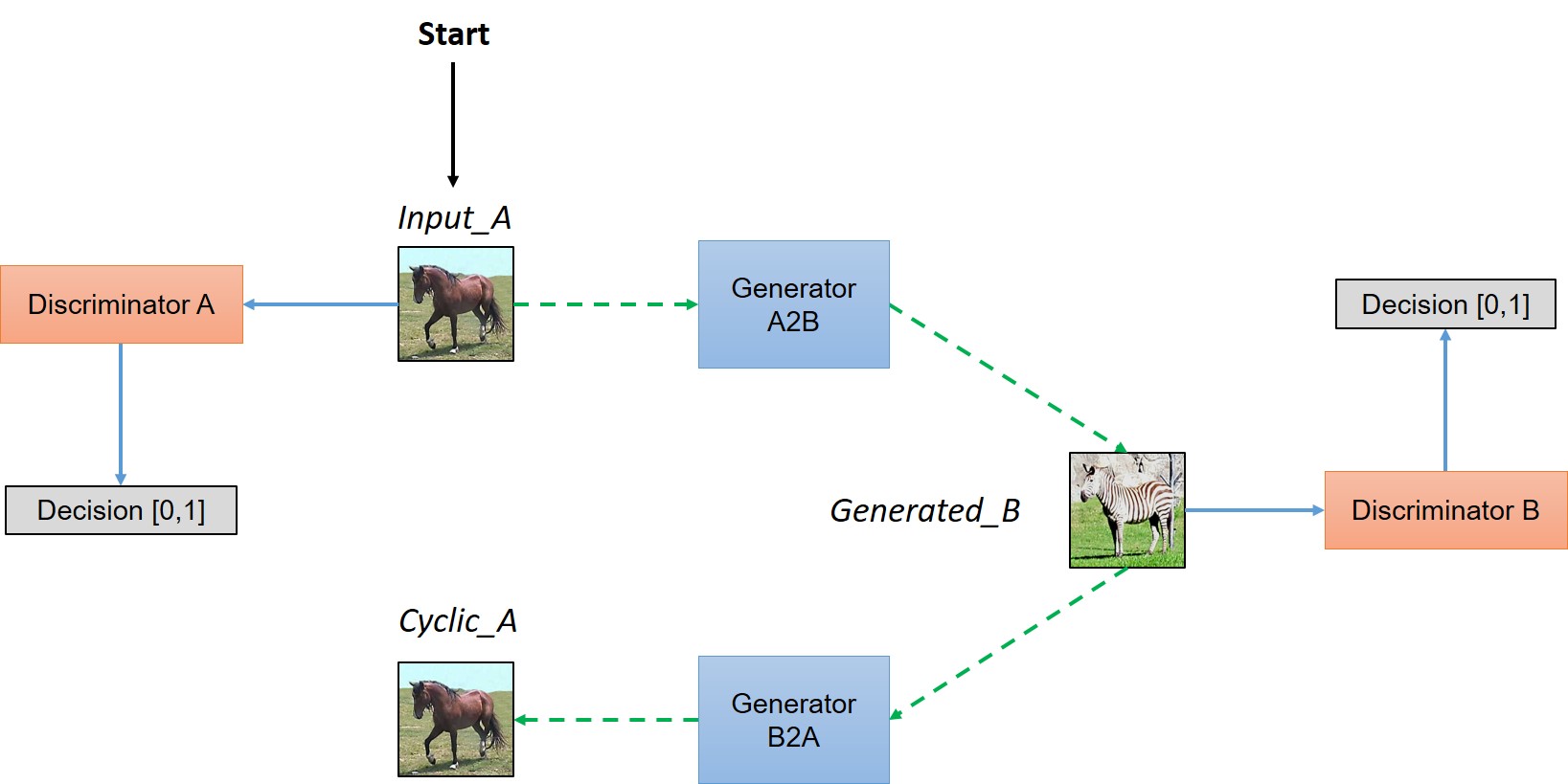
**CycleGAN** works without paired examples of transformation from source to target domain. The power of CycleGAN lies in being able to learn such transformations without one-to-one mapping between training data in source and target domains. The need for a paired image in the target domain is eliminated by making a two-step transformation of source domain image - first by trying to map it to target domain and then back to the original image. Mapping the image to target domain is done using a generator network and the quality of this generated image is improved by pitching the generator against a discrimintor
</div>
-----
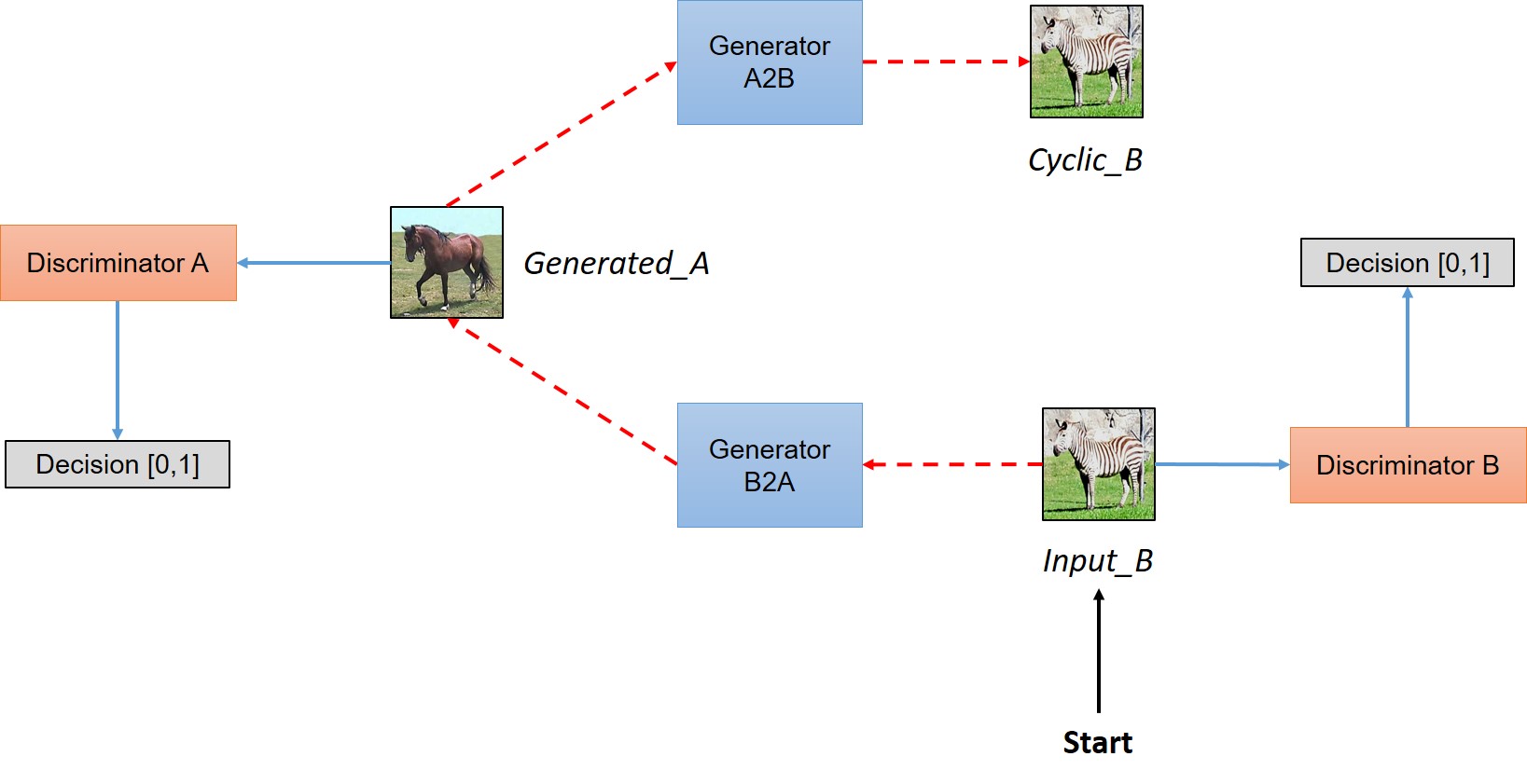
*Figure 4: Schematic representation of CycleGAN model*
In a nutshell, the model works by taking an input image from domain $D_A$ which is fed to our first generator $GeneratorA→B$ whose job is to transform a given image from domain $D_A$ to an image in target domain $D_B$. This new generated image is then fed to another generator $GeneratorB→A$ which converts it back into an image, $CyclicA$, from our original domain $D_A$ (think of autoencoders, except that our latent space is $D_t$). And as we discussed in above paragraph, this output image must be close to original input image to define a meaningful mapping that is absent in unpaired dataset.
This model seems not to fit our problem here as it works as a "style tranfer"; therefore, results on expression translation hasn't got a well pace.
- **IcGAN**
<div style="text-align: justify">
**Invertible Conditional GANs** (IcGANs) are composed of a cGAN and an encoder.

*Figure 5: Scheme of a trained IcGAN*
#### Encoder
A generator $x_0 = G(z, y_0)$ from a GAN framework does not have the capability to map a real image $x$ to its latent representation $z$. To overcome this problem, we can train an encoder/inference network E that approximately inverses this mapping $(z, y) = E(x)$.
If combined with a cGAN, once the latent representation $z$ has been obtained, explicitly controlled variations can be added to an input image via conditional information $y$
</div>
- **StarGAN**
StarGAN is a GAN model that allows mappings among multiple domains using only a single generator. The domain is represented by a one-hot encoded vector. This allows the model to learn different information from different datasets with different labels and not just one fixed translation as for exemple black hair to blond hair.

*Figure 6: Comparison between the cross-domain models and StarGAN model*
We can see that StarGAN has a significant higher quality of emotion translation than the other GAN models. It also preserves the face of the initial photo which is what we want in our case.

*Figure 7: Comparison between the 4 main GAN's model*

*Figure 8: Comparison between the 4 main GAN's model*
## StarGan Implementation
- Check pour mettre conda sur son truc de super calculateur
- bdd
- Image analysis
- can we find more data
- How to store data
- How to load data
- uniformise data
Note: for speed purposes, the whole dataset will be loaded into RAM during training time, which requires about 10 GB of RAM. Therefore, 12 GB of RAM is a minimum requirement. Also, the dataset will be stored as a tensor to load it faster, make sure that you have around 25 GB of free space.
- techno
- python 3.7 / anaconda, all ML libraries (TF/pytorch)
- traitement d'image (openCV, scikit-image)
- Comment on va faire
* Quick baseline Model prototype
* build ML pipeline Spark
* data augmentation
* Feed/train model
* Evaluation model
* Tuning model and parameters
- methodes de travail
- semi agile (jira trello)
- monthly meetings to report current work
- time planning (GANTT)
```mermaid
gantt
title Diagramme de Gantt
dateFormat YYYY-MM-DD
section Research
Gan Study :2020-03-01, 15d
AutoFormation :2020-03-01, 20d
section Analysis
BDD analysis :a1, 2020-03-10, 7d
BDD unif :after a1 , 7d
Baseline POC :7d
MLPipeline :2020-03-20 , 7d
Data augm :2020-03-25 , 7d
Tuning :2020-03-22 , 10d
section Develop
BDD management :2020-04-01 , 15d
Finding data :2020-04-01 , 15d
```
- Estimation charges (backlog)
## Custom GAN
Test un custom GAN From scratch ou autre modèle sur même data set pour comparer perfs
 Sign in with Wallet
Sign in with Wallet







