# D06: list
contributed by < `vulxj0j8j8` >
## Birthday problem
bithday problem 是指隨機挑選人,這些人會在同一天生日的機率其實會飆高的很快。
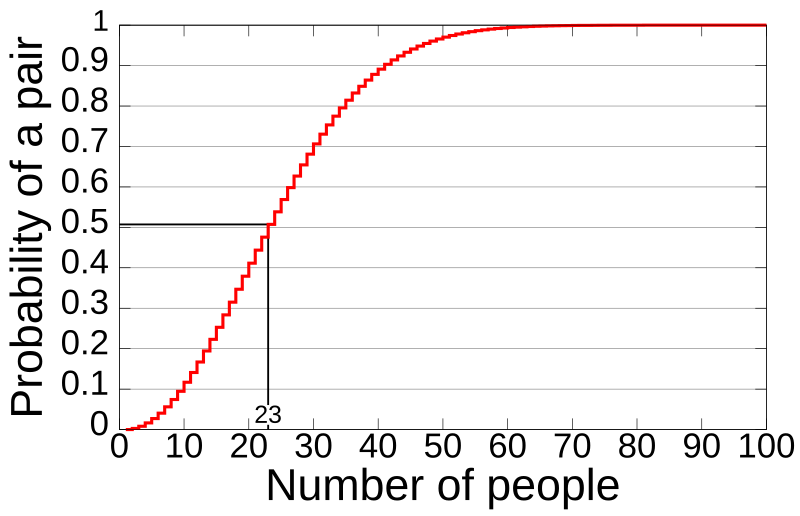
上圖取自[wikipedia](https://en.wikipedia.org/wiki/Birthday_problem)
由圖可以發現,若隨機取23人,其中有兩個人生日相同的機率就大於50%
隨機取57 人,相同生日的機率就達到99%
在資訊安全上birthday problem 的應用就是 [birthday attack](https://en.wikipedia.org/wiki/Birthday_attack),其實基本上就是窮取法
在一般的Preimage attack狀況下,窮取法的時間複雜度是 $2^n$ 其中 n 代表是使用n-bit hash
只是根據birthday problem 我們可以計算得知,如果我們今天有一個hash function,再二進位的電腦上,會有很高的機率在 $\sqrt {2^{n}}$次的測試下,遇到collision
若是在三進位的量子電腦上,這個次數會變成$\sqrt [3] {2^{n}}$,碰到碰撞的機率大幅上升
Message Digest: 訊息摘要
類似於fingerprint,理論上不同的訊息所產生出來的 message digest 都不會是相同的,因此可以用來驗證訊息在傳輸的過程中是否有被竄改過。
目前的作法中,是以複雜的 hash function (雜湊函數) 所計算出來。
#### Collision Attack and Preimage Attack
* pre-image attack:
adversary 僅有 hash value,但是嘗試透過hash value 去產生原本的message
* 2nd pre-image attack:
adversary 無法選擇可以進行攻擊的 message (可能數量有限),想透這些可使用的messages 找到m1 $\neq$ m2 但是 Hash(m1) = Hash(m2)
* collision attack:
adversary 可以自由的選擇可以進行攻擊的 message 以及 hash value
藉此嘗試找到一組 m1 $\neq$ m2 但是 Hash(m1) = Hash(m2)
其他應用應該還有可能有低估碰撞的機率
- [ ] 自我檢查事項
* 如何透過近似的運算式,估算上述機率計算呢?附上有效的 LaTeX 算式
* [Birthday problem](https://en.wikipedia.org/wiki/Birthday_problem) 對資訊安全的影響在哪些層面?
* 像是 [Random Number Generator](http://stattrek.com/statistics/random-number-generator.aspx) 這樣的產生器,是否能產生「夠亂」的亂數呢?
## Linux 風格的 linked list
- [ ] 自我檢查事項:
* 為何 Linux 採用 macro 來實作 linked list?一般的 function call 有何成本?
* 一般的 function call 有呼叫的成本,把function和相應的arguments 放到 stack 中所消耗的時間成本等
* 若採用 macro 的話該段程式碼在編譯的 preprocess 時期就展開了。因此再程式運作的時候,不會有呼叫 function 把function 放到stack 的成本
* Linux 應用 linked list 在哪些場合?舉三個案例並附上對應程式碼,需要解說,以及揣摩對應的考量
* GNU extension 的 [typeof](https://gcc.gnu.org/onlinedocs/gcc/Typeof.html) 有何作用?在程式碼中扮演什麼角色?
* typeof 可以回傳該參數的變數型態
```Clike
int a = 0;
typeof(a) y;
// the code above is equal to the code below
int a = 0;
int y ;
```
就可以達到多型的效果
* 解釋以下巨集的原理
```Clike
#define container_of(ptr, type, member) \
__extension__({ \
const __typeof__(((type *) 0)->member) *__pmember = (ptr); \
(type *) ((char *) __pmember - offsetof(type, member)); \
})
```
#### offsetof
[[參考](https://myao0730.blogspot.tw/2016/09/linuxcontainerof-offsetof.html)]
Linux 的巨集
offsetof 用來計算某一個struct結構的成員相對於該結構起始位址的偏移量,也就是這個成員的記憶體位址距離整個 struct 結構的記憶體位址距離多遠
```Clike
/*
TYPE: name of struct
MEMBER: member in struct
*/
#define offsetof(TYPE, MEMBER) ((size_t)&((TYPE *)0)->MEMBER)
```
offsetof 將 0 強制轉型成 TYPE 的指標。這樣指到的 MEMBER 地址就是距離 struct 開頭的距離。例子如下。
```Clike
#include <stdio.h>
#include <stddef.h>
typedef struct testStruct {
int in1, in2;
struct pool *next;
} teStru;
int main()
{
teStru *te = (teStru *) malloc(sizeof(teStru));
printf("offset in1 = %d \n", offsetof(teStru, in1));
printf("offset in2 = %d \n", offsetof(teStru, in2));
printf("offset next = %d \n", offsetof(teStru, next));
printf("test for my ver \n");
printf("offset in2 without size_t = %d \n", &((teStru *)0)->in2);
printf("offset in2 from nonzero = %d \n", &((teStru *)100)->in2);
/* this one below will cause segmentation fault
* Because it access the address at 0x0 which is invalid
*/
printf("offset in2 without & = %p \n", ((teStru *)0)->in2);
return 0;
}
```
結果
```
offset in1 = 0
offset in2 = 4
offset next = 8
test for my ver
offset in2 without size_t = 4
offset in2 from nonzero = 104
Segmentation fault
```
#### container_of
Linux 巨集
給定一個struct 成員,就可以得到struct 的起點地址,可以直接餵給另個指標
* 除了你熟悉的 add 和 delete 操作,`list.h` 還定義一系列操作,為什麼呢?這些有什麼益處?
* `LIST_POISONING` 這樣的設計有何意義?
* linked list 採用環狀是基於哪些考量?
* `list_for_each_safe` 和 `list_for_each` 的差異在哪?"safe" 在執行時期的影響為何?
* for_each 風格的開發方式對程式開發者的影響為何?
* 提示:對照其他程式語言,如 Perl 和 Python
* 程式註解裡頭大量存在 `@` 符號,這有何意義?你能否應用在後續的程式開發呢?
* 提示: 對照看 Doxygen
* `tests/` 目錄底下的 unit test 的作用為何?就軟體工程來說的精神為何?
* `tests/` 目錄的 unit test 可如何持續精進和改善呢?
## 針對 linked list 的排序演算法
研讀 [A Comparative Study Of Linked List Sorting Algorithms](https://www.researchgate.net/publication/2434273_A_Comparative_Study_Of_Linked_List_Sorting_Algorithms)
- [ ] 自我檢查事項
* 對 linked list 進行排序的應用場合為何?
* 考慮到 linked list 在某些場合幾乎都是幾乎排序完成,這樣貿然套用 quick sort 會有什麼問題?如何確保在平均和最差的時間複雜度呢?
* quick sort 在幾乎排序完成的資料時,進行排序時間會是worst case O($n^2$),而且quick sort best case 時間是 O(n),這樣再不同資料分佈狀況下,進行排序所花的時間變化太多。故選用merge sort可能是更好的方法。
因為 merge sort 的時間複雜度是穩定的 O($nlogn$)
* 能否找出 Linux 核心原始程式碼裡頭,對 linked list 排序的案例?
* 透過 [skiplist](https://en.wikipedia.org/wiki/Skip_list) 這樣的變形,能否加速排序?
* 研讀 [How to find the kth largest element in an unsorted array of length n in O(n)?](https://stackoverflow.com/questions/251781/how-to-find-the-kth-largest-element-in-an-unsorted-array-of-length-n-in-on),比照上方連結,是否能設計出針對 linked list 有效找出第 k 大 (或小) 元素的演算法?
* [linux-list](https://github.com/sysprog21/linux-list) 裡頭 `examples` 裡頭有兩種排序實作 (insertion 和 quick sort),請簡述其原理
#### callback function
#### MMIO (Memory Map IO)
有一段記憶體他上面的位址對應到的是周邊裝置,比如說今天去讀取0xFFF0這個位置的資料,可能就是讀取網路卡所取得的封包
#### /proc/_cmdline_
This file shows the parameters passed to the kernel at the time it is started.
### memory layout
https://pinglinblog.wordpress.com/2016/10/18/linux-程序的-memory-layout-初淺認識/
https://www.geeksforgeeks.org/memory-layout-of-c-program/
https://www.csie.ntu.edu.tw/~sprout/algo2017/homework/week3.pdf
https://stackoverflow.com/questions/40392218/operating-systems-what-is-the-size-of-the-virtual-memory
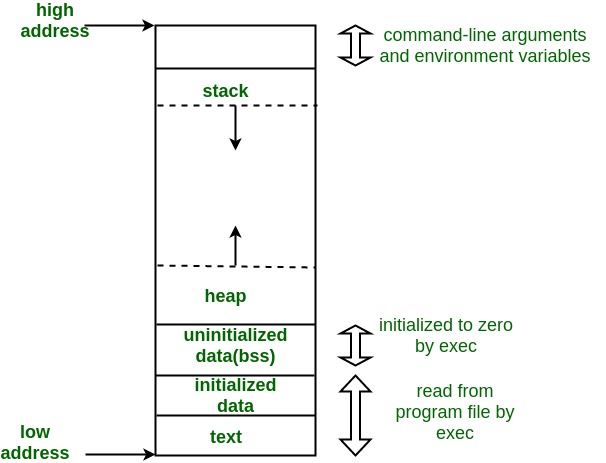
C語言所寫出來的程式的記憶體佈局如下圖
#### Text Segment
此區域存放程式的機器指令碼,即是要給CPU執行的部份。因為怕修改造成程式的崩潰,所以此區域為唯讀。但為了與其他程式共享,此區域為共享。機械指令碼是 C 語言程式在經過編譯器優化、編譯之後,會轉變成只有電腦才看得懂的機器指令碼。
#### Initialized Data Segment
有些變數是一執行就固定位置的,例如全域變數 (global variable)、靜態變數
(static variable),這些變數如果在程式碼中有被使用者手動初始化 (這邊的手動
初始化是指宣告時就順便賦值的初始化,事後自己賦值或者 memset 等等的並不
算),就會被配置於此區塊。
#### uninitialized data segment:
通常又被稱為 bss segment (block started by symbol, bss),包含未明確初始的global 和 static 變數,當執行程式時會將其這區段的記憶體初始為零。那之所以把未初始化的在分隔到一區段的原因是因為,當程式存放在硬碟中的時候,沒有那個必要留空間存放這些未初始化的資料,只需要執行時去紀錄位置和所需大小,在run time的時候利用program loader 分配。
例子如下
```Clike
static char mbuf[10240000];
```
縱使我們在程式內宣告一個這麼大的空間,但因為沒有明確的初始,所以其Binary file只有"8.7K",因為其只需在run time的時候分配大小;但是一旦我們修改為
```Clike
static char mbuf[10240000]={1};
```
Binary file的大小會激增到"9.8M",因為存放的segment改變了。
p.s: 如果改成初始為0,一樣會是"8.7K",應該是因為預設就是初始為0。
```Clike
static char mbuf[10240000]={0};
```
#### Heap
記憶體被動態指派時,會指派 heap 的記憶體給程式,像 malloc 還有 calloc。分派給 heap 的位址是往上增加的。
可以透過 `brk` 和 `sbrk` 調整此區域大小。
#### Stack
Stack 存放了所有的automatic variable,像是程式的local variable, argument, return address(進入這個函式前程式跑到的哪裡)。所以呼叫函式後,不是把整個函式當成物件放進去記憶體,是把其中的變數放進記憶體。
每個函式只要被呼叫都有自己的 stack frame,每個stacj frame的架構如下圖
實作上 stack 比 heap 更常使用,因為 heap 得搜尋地址,可是 stack 只要去跟暫存器要 stack pointer 就好

其中幾個暫存器的功用為
%rip:instruction pointer,用來指到下一個instruction的位置.
%rbp:base pointer/frame pointer,用來指到目前stack frame的開頭.
%rsp:stack pointer,用來指到目前stack的top,也是尾巴。
caller: 呼叫 callee 的函式
callee: 呼叫 callee 的函式
i.e.
- main 是 caller,而 main 裡面的函式是 callee
參考 [連結](http://karosesblog.blogspot.tw/2016/10/cmu-buffer-overflow-attack.html)
函數調用參考 [連結](http://www.cnblogs.com/bangerlee/archive/2012/05/22/2508772.html)
#### Automatic Variable
自動變數又稱為內部變數,一般在函式內宣告 的變數若未註明儲存類別,都預設為自動變數。譬如函式內宣告的局部變數以及區塊內所宣告的區域變數都是屬於自動變數。自動變數在程式執行階段(Run Time),系統才在動態堆疊區配置記憶體給該變數使用,當函式完成它的工作離開函式返回呼叫處,該變數又從堆疊中取出釋放掉,將使用過的記憶體歸還給系統。所以,自動變數就是能自動產生與自動消失的變數。
### Stack Frame
free 的輸入值是 NULL 的話,free是不會有動作的
## 技巧篇
prefer to return a value rather than modifying pointer
傳遞 stack(pointer) 跟傳遞 structure 在效能上是差不多的
傳遞一串 structure 的時候編譯器會給一個連續的空間放這些 structure,然後傳遞開頭的位址
#### danglin else
if else 的 else 是要找最近的 if,根據下面的例子
```Clike
#define CALL_FUNC(x) \
if (<condition>) \
foo(a); \
else \
bar(a); \
if (<condition>)
CALL_FUNCS(a);
else
bar(a);
```
macro 代進去後,macro裏面 bar後的分號會結束下面整個if 判斷式,因此程式會無法編譯。這個問題稱作 dangling else
可以透過下面方法解決
```Clike
#define CALL_FUNCS(x) \
do { \
if (<condition>) \
foo(a); \
else \
bar(a); \
} while (0)
if (<condition>)
CALL_FUNCS(a);
else
bar(a);
```
### backtrace
gdb 指令,可以逐個 frame 往前,把每個 frame 的資料印出來
A backtrace is a summary of how your program got where it is. It shows one line per frame, for many frames, starting with the currently executing frame (frame zero), followed by its caller (frame one), and on up the
[官方doc](https://sourceware.org/gdb/onlinedocs/gdb/Backtrace.html)
### \__extension__()
GCC uses the \_\_extension\_\_ attribute when using the -ansi flag to avoid warnings in headers with GCC extensions. This is mostly used in glibc with function declartions using long long
If you get a warning that you use an extension to the language, you can either change you code or add `__extension__` to tell the compiler that you **intended** to write unportable code, and it doesn't have to tell you that again. Otherwise it is of no use.
## Reference
https://www.csie.ntu.edu.tw/~sprout/algo2017/homework/week3.pdf
https://pinglinblog.wordpress.com/2016/10/18/linux-程序的-memory-layout-初淺認識/
https://www.geeksforgeeks.org/memory-layout-of-c-program/
https://www.hackerearth.com/practice/notes/memory-layout-of-c-program/
http://karosesblog.blogspot.tw/2016/10/cmu-buffer-overflow-attack.html
http://www.cnblogs.com/bangerlee/archive/2012/05/22/2508772.html
https://myao0730.blogspot.tw/2016/09/linuxcontainerof-offsetof.html
 Sign in with Wallet
Sign in with Wallet







