# Fernet 52
*Towards a unified proposal abstracting the common parts of [B52](https://hackmd.io/@aztec-network/b52) and [Fernet](https://hackmd.io/@aztec-network/rk5KDMUU3?type=view).*
## Protocol phases
In both proposals, each block goes through three main phases in the L1: proposal, proving, and finalisation. Transactions can achieve soft finality at the end of the proposal phase.

### Proposal phase
During the initial proposal phase, proposers submit to L1 a **block commitment**, which includes a commitment to the transaction ordering in the proposed block, the previous block being built upon, and any additional metadata required by the protocol:
**Block commitment contents:**
- Hash of the ordered list of transaction identifiers for the block (with an optional salt).
- Identifier of the previous block in the chain.
- *Fernet*:
- The output of the VRF for this sequencer.
- *B52*:
- The amount of native token that will be burnt by the builder if the block becomes the head of the chain.
- The amount that the prover network will receive if the block becomes canonical.
- Hash of the transcript that defines which staker will produce which part of the proof binary tree.
- The total score for this proposal based on burn and number of votes.
At the end of the proposal phase, the network can identify which block commitment has the highest score. It should be safe to assume that, in the happy path, this block would become final, so this provides early soft finality to transactions in the L2.
### Proving phase
During this phase, provers coordinate to build a proof of what they consider to be the next canonical block. In the ideal scenario, this should be the block with the highest score from the previous phase. However, if the block proposer fails to reveal the commitment preimage (such as the tx ordering), or the commitment is somehow invalid, or the network decides against such an ordering, they could opt to work on a different block.
Before the end of the proving phase, it is expected for the block proof to be published to L1 for verification, and the block contents to be published to a data availability layer such as EIP4844 blobs.
**Block submission:**
- Root rollup proof of the correctness of all txs included in the block.
- Proof for the correctness of the score published in the commitment.
- Contents of the block (updated roots, new commitments, new nullifiers, etc).
At the end of this phase, one or more of the block commitments from the proposal phase should have been proven and submitted.
### Finalisation
A last L1 transaction is needed to finalize the current winning block and pay out rewards. The finalisation transaction will automatically designate as final the block with the highest score that fits the following criteria:
**Canonical block selection:**
- Has been proven during the proving phase.
- Its contents have been submitted to the DA layer.
- Its referenced previous block is also canonical.
> In Fernet, if the proof from the highest-ranked sequencer is submitted and verified as correct (since then it's certain they have won), this last tx is not actually needed. In this happy case, finalisation _could_ happen at the time the proof is verified.
Once this transaction is mined on L1, the corresponding L2 block is considered final. However, note that the L2 block could still be reorg’d in the event of an L1 reorg.
> The effect of L1 reorgs can be mitigated by choosing a scoring function that stays constant in the event of an L1 reorg. This allows the original work done by the network to just be replayed. In B52, this is already the case. In Fernet, this can be done by picking an old enough RANDAO value as the source of entropy.
## Next block
The cycle for block N+1 (ie from the start of the proposal phase until the end of the finalisation phase) can start at the end of block N proposal phase, where the network has reasonable assumptions on which block will be the one finalised as canonical.

However, if a different block is selected, this can lead to L2 reorgs as deep as an entire cycle:

The number of blocks reorg'd in this scenario is proportional to the ratio between the proposal phase length and the proving phase length. Assuming proposal phases of 60 seconds (5 Ethereum blocks) and 10-minute proving phases (50 Ethereum blocks), we end up with a reorg depth of 10+1 Aztec blocks.
## Customisations
The following parts of the protocol are customisable, leading to the differences between Fernet and B52.
### Block scoring
Both protocols define a scoring function to decide which proven block is chosen as final. In B52 this function depends on the burn and the number of votes: `PROVER_VOTE^3 * BURN_BID^2`. In Fernet, it depends on a VRF score, and potentially on the % of fees that the proposer offers to share with the provers.
### Eligible block proposers
B52 has no differentiated role of block _proposer_. Instead, anyone who acts as a block builder can freely submit a block commitment to be voted on by the network. On the other hand, Fernet has a designated ranked set of block proposers for each round. These proposers must previously register as such via staking.
### Eligible provers
B52 requires provers to stake, since they also act as voters for choosing the winning block commitment. Given the set of provers that have voted on a block, its either on the block builder to assign individual proofs to each of them through the transcript, or it [can be regulated by the protocol](https://discourse.aztec.network/t/ideas-on-a-proving-network/724#protocol-elected-provers-17). Fernet can also follow a similar protocol-regulated prover selection algorithm, or rely on a separate [unregulated proofs marketplace](https://discourse.aztec.network/t/ideas-on-a-proving-network/724#fernet-16) that does not require provers to pre-register in the protocol.
## Known issues and mitigations
Some known problems with the protocols as they are defined in the previous sections, along with ideas for mitigations. This section was written targeting Fernet, though it may also apply to B52.
### Sequencer withholding data
Sequencers can choose to whithhold data from the rest of the network. This can be due to malicious behaviour, but also as a form of supporting private-mempool transactions. Note that withholding just a single tx from the block is enough to disrupt operations.
Sequencers can withhold both tx contents and proofs. If contents are withheld in block N, then the chain cannot progress safely for block N+1: neither the clients nor the sequencer for block N+1 know the latest state to build upon. This will most likely trigger a reorg.

In this situation, the sequencer from block N+1 has to a) not submit anything, b) build on top of block N-1, or c) build on top of a non-winning proposal for N. There's no easy way to decide across these options, they are all bad for sequencer N+1, and there's no penalty to sequencer N for behaving this way. With a block reveal phase, a proposal is ruled out if not revealed in time.
Note that the sequencer may also withhold tx proofs. Depending on the model we use for the proving network, this could also be a risk.
#### Mitigation: Block reveal phase
Instead of posting the block contents at the end of the proving phase, we can add a **block reveal phase** inbetween the proposal phase and the proving phase. This guarantees that the next sequencer will have all data available to start building the next block, and clients will have the updated state to create new txs upon.
> Note that this reveal does not imply that the block can be finalised, since the sequencer may still withhold the *proofs* of the transactions, which are not uploaded.

Block proposals that do not reveal their contents at the end of the reveal phase are not eligible for finalisation, and are dropped from the protocol. This prevents a sequencer from finalising a block whose contents were not made public in due time.

In this model, cycle N+1 starts at the end of the reveal phase for N, not at the end of the proposal phase. This ensures that the sequencer for block N+1 has all the data needed to assemble its block.

The main downside of this mitigation is that it extends the effective block time. Since cycle N+1 requires both the proposal and reveal phase to be finished before starting, the time for each block is increased by the duration of the reveal phase.
#### Mitigation: Slashing
To further discourage sequencers from data withholding, we can enable slashing conditions for the winning sequencer if their block doesn't get proven. We can extend this to slashing all sequencers who participated in the proposal phase if no block gets proven.
> Note that this may tip the scales in favor of provers, depending on the proving scheme we choose. If a sequencer faces a penalty of X if they are not able to produce a block, then the prover network could charge as much as X-1. This assumes no competition within the network though, which will probably not be the case.
### Backup sequencers not incentivised to do work
We call a _backup sequencer_ a sequencer that put forward a proposal but doesn't have the highest score. These sequencers have all reasons to believe that the leading sequencer is doing their work, so they would not reveal their block contents to L1/DA, nor start proving their block.
If the leading sequencer withholds data (contents or proofs), it's not possible for a backup sequencer to know if they will fail to submit a proof, or they are proving via a private network. So the safest move is not to act, given the high costs of proving or posting data to L1/DA. This affects the _reveal phase_ mitigation above as well, where backup sequencers are discouraged from revealing contents.
> Note that the cost of publishing block contents will depend on the DA layer chosen (such as 4844 blobs).
Furthermore, backup sequencers are discouraged from revealing block contents if they don't have certainty of being winners, since by this act they are revealing valuable MEV-extracting operations, that a following sequencer could steal.
#### Mitigation: Gas rebates for data upload
We can introduce a gas rebate for subsidising the costs of uploading data to L1/DA, covering the cost for the top N sequencers that decide to publish block contents. However, this will increase total fees in the protocol.
#### Mitigation: L1 private mempool service
Backup sequencers could rely on a flashbots-like API so that their reveal txs only get included if the winner's isn't. This only works if they wait until the very last block of the phase though.
#### Mitigation: Extended reveal phase
_I don't really like this option, feel free to skip._
We can extend the reveal (or proving, if reveal is not implemented) phase for a short period of time if the winning sequencer fails to submit. During this brief extension, the winning sequencer is no longer allowed to participate, so the next sequencers are encouraged to engage as backups.
The main issue with this approach is that it only helps with mitigating L1/DA upload costs, but not proving. It still requires that backup sequencers kick off their proving processes early, since the proving phase extension is not long enough by design. If we did extend the proving phase by 2x, then the result is equivalent to a reorg. For this reason, this extension may be better suited for the reveal phase instead.
#### Mitigation: Elect single leader after proposal phase
A simpler way to deal with backup sequencers is to just remove them from the equation. We can adjust the protocol so that only the sequencer with the highest score at the end of the block proposal phase can submit a block during the proving phase (and block reveal phase if implemented, since it pairs well with this modification).
The advantage for this is reducing uncertainty about which block will be finalised in the chain, leading to stronger early finality. It also simplifies things for non-winning sequencers: if they don't win at the end of the proposal phase, there's no need for them to stand by or build a block _just in case_. It also removes the need for a separate finalisation phase. And if the sequencer VRF is run on a public value, then the winning sequencer can know they are the winner, and bundle the proposal and reveal into a single tx as an optimisation.
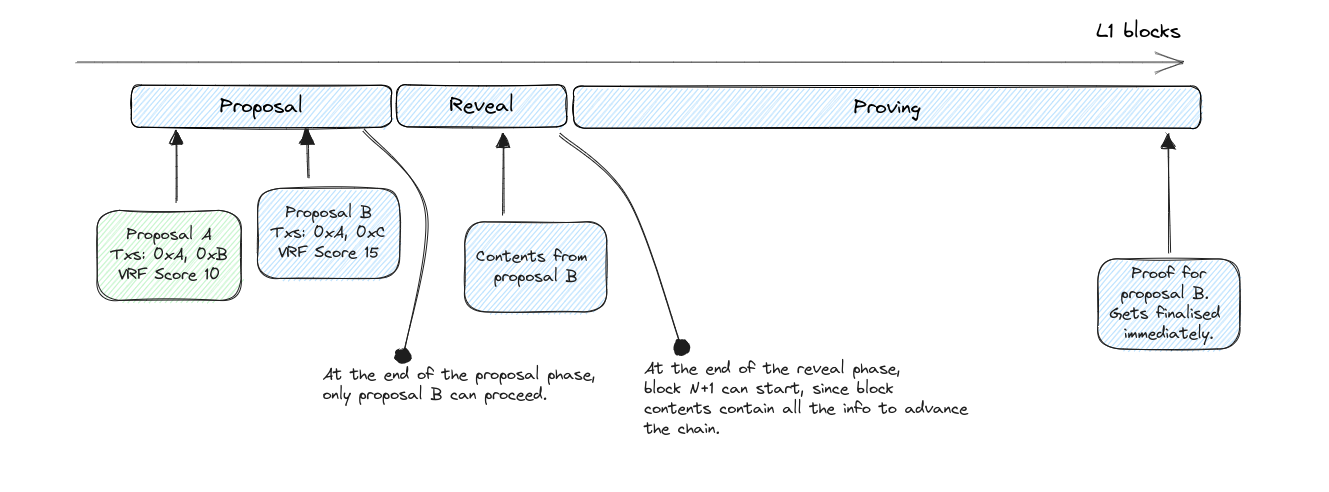
Note that if we couple this with a block reveal phase, then the sequencer for the following block has complete certainty on which block to build on top of: if contents for a block are not revealed, then that block is simply skipped by the protocol. We can also disallow block N+1 from building on top of block N-1 unless block N is flagged as skipped.
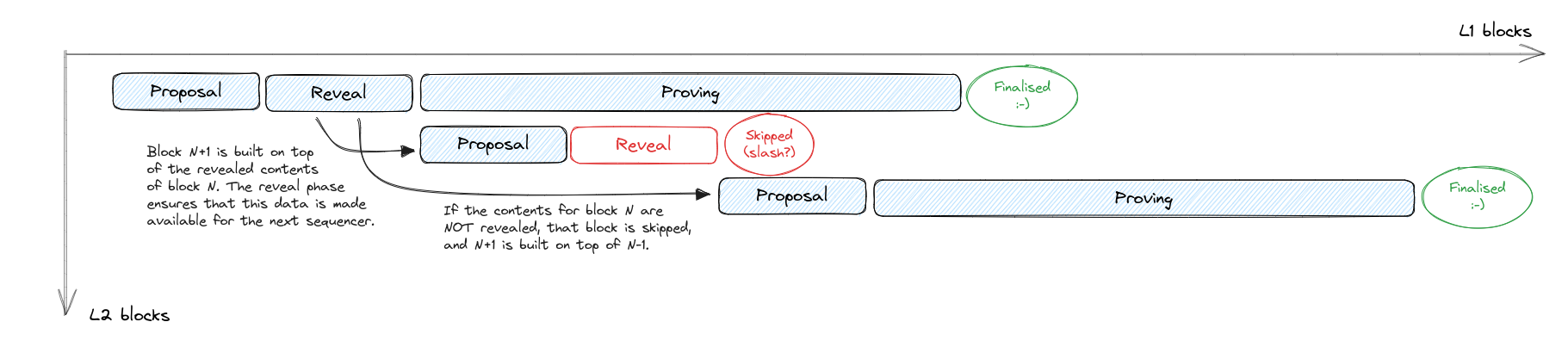
In this model, the only way to trigger an L2 reorg (without an L1 one) is if block N is revealed but doesn't get proven. In this case, as with most reorg scenarios reviewed so far, all subsequent blocks become invalidated and the chain needs to restart from block N-1.

To mitigate the effect of wasted effort by all sequencers from block N+1 until the reorg, we could implement uncle rewards for these sequencers. And if we are comfortable with slashing, take those rewards out of the pocket of the sequencer that failed to finalise their block.
This model solves well the problem of disclosing MEV opportunities without the need for extended phases. At the end of the proposal phase, the winning sequencer knows they have exclusive rights to that slot, so they can feel free to disclose whatever data they want, as long as they can prove it.
The disadvantage for this model is on liveness. A sequencer that publishes a commitment but doesn't move forward with it will halt the chain for the length of a proposal plus reveal phase. But this seems like an acceptable tradeoff to reduce reorg conditions, which are much more damaging to the network.
## Batching
As an extension to the protocol, we can bake in batching of multiple blocks. Rather than creating one proof per block, we can aggregate multiple blocks into a single proof, in order to amortise the cost of verifying the root rollup ZKP on L1, thus reducing fees.
> A note on terminology: we always refer to a block as an ordered set of txs as submitted in a block proposal. If we implement batching, then we aggregate multiple individual L2 blocks into a single L1 submission. The block is **not** the batch, instead the batch contains multiple blocks.
### Naive batching
In naive batching we have multiple proposal phases one after the other, each led by its own sequencer, before progressing into the proving phase. The proposal phases for the following batch can start at the end of the previous set of proposal phases, much as in the original version. This leads to a continuous sequence of proposals, which get aggregated into proofs and finalised every `BATCH_SIZE` blocks.
When batching, the canonical block is only finalised once a proof is submitted. In the event of proofs submitted for multiple blocks, the winner is the one with the highest score for the first block, then for the second block, and so forth.

A major downside of batching is that finalisation takes longer, so L2 reorgs can be deeper. The size of a reorg is not just `PROPOSAL_PHASE_BLOCKS + PROVING_PHASE_BLOCKS`, but potentially `PROPOSAL_PHASE_BLOCKS * BATCH_SIZE + PROVING_PHASE_BLOCKS`.
### Batching proofs
An improvement over the batching model above is to start proving the first block immediately as it is proposed. The flow is similar to the non-batching version, with the exception that most blocks do not get finalised, and instead their proofs are posted to the DA layer (4844) along with their contents. These proofs can be verified by any participant on the L2 chain, giving stronger finalisation guarantees for each block. Furthermore, if the proof for a given block is not uploaded within a time window, we can invalidate that block, allowing the chain to progress.
Every `BATCH_SIZE` blocks, all these proofs are aggregated into a single one and posted to L1 during a finalisation phase, whichs finalises all blocks included.
The advantage over naive batching is that the total time to finalisation is reduced, since proving starts earlier. The total number of proofs executed should be roughly the same, assuming all blocks contain full trees (even if of different heights).

### Proving chain
A further improvement from the previous approach is to not submit individual block proofs to the DA layer, but rather integrate them into the proof tree of the following block. As the final step in building the proof for block N, the proof from block N-1 is merged with the root proof from the transactions tree of N, effectively building a proofchain (rather than a blockchain).
The advantage here is that there is no need for a separate proof aggregation phase, and all individual block proofs are valid as candidates to finalise the current batch. This opens the door to dynamic batch sizes, so the proof could be verified on L1 when it's economically convenient, similar to the AC model.

The downside is that we lose the pre-confirmations that were enabled by posting the individual proofs to the DA layer.
## Resources
- [Excalidraw diagrams](https://excalidraw.com/#json=U8YzRABYAQzatvMgh4PwL,8pHM2EgZxpaZKqRSCCfHQQ)







