# 2016q3 Homework2 (phonebook-concurrent)
contributed by <`ChenYi`>
###### tags `ChenYi` `sysprog`
## 開發環境
Distribution: Ubuntu 16.04 LTS
```
Architecture: x86_64
CPU 作業模式: 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 8
On-line CPU(s) list: 0-7
每核心執行緒數:2
每通訊端核心數:4
Socket(s): 1
NUMA 節點: 1
供應商識別號: GenuineIntel
CPU 家族: 6
型號: 60
Model name: Intel(R) Xeon(R) CPU E3-1231 v3 @ 3.40GHz
製程: 3
CPU MHz: 3748.632
CPU max MHz: 3800.0000
CPU min MHz: 800.0000
BogoMIPS: 6784.07
虛擬: VT-x
L1d 快取: 32K
L1i 快取: 32K
L2 快取: 256K
L3 快取: 8192K
```
## 預期目標
* 做好筆記 (上次的自己看都覺得慘不忍睹)
>> 幻滅是成長的開始 [name=jserv]
* 弄懂concurrency 和 parallelisms 的差別
* 學會使用pthread
* 效能分析
之前對於這類東西一直覺得很混淆,學OS的時候也只是考過就忘,這次先嘗試把背景知識補齊再開始動工
>> 這部份一直很弱ˊ~ˋ [name=ChenYi]
## 教材閱讀重點整理
閱讀[冼鏡光的並行計算投影片](http://blog.dcview.com/article.php?a=BTgBYw1qUWIAaQ%3D%3D)與[Toward concurrency](https://hackmd.io/s/H10MXXoT)的一些重點紀錄
#### 一些要搞懂的關鍵字
* 行程(Process)
* 一個process中可以有多個thread並行執行
* 不同的process有不同的記憶體空間
* 執行緒(Thread)
* 在同個process內的執行緒可以同時共享資源(ex.記憶體,code
* 在大多數的狀況下,process由threads所組成
* 若CPU有多個processor,可以做到平行化執行(parallel)
* 並行(Concurrency)
* 多個問題交由一個processor處理
* 可連續或交錯進行
* 平行(Parallelism)
* 同個問題交由多個processor來處理
* 同時並進
* Asynchronous 和 Synchronous用圖解比較好懂
>> 可用 [GraphViz](http://www.graphviz.org/) 製圖,HackMD 有支援。中文示範: [Graphviz - 用指令來畫關係圖吧!](http://www.openfoundry.org/tw/foss-programs/8820-graphviz-) [name=jserv]
* Synchronous
* 
* 左右分別是synchronous的1 thread || multi-threads
* O1, O2 , O3皆為空白時間
* Asynchronous
* 
* Conditional Variable
* 資料參考 https://www.cs.mtu.edu/~shene/NSF-3/e-Book/MONITOR/CV.html
* conditional variable事實上是event而不是variable
* conditional varialbe有wait和signal的operation
* 當一個thread等待有事件發生時,他放入waiting queue中(等待呼叫 ==> wait
* 當該thread被呼叫後,會執行signal
* signal發生時,monitor會尋找在waiting queue中的其中一個thread來執行
* 若完全沒有的話,這個signal就會被完全忽視掉
* Semaphore(信號標)
* 是一個具有counter , waiting list ,和兩個作用signal和wait
* counter主要有兩種
* counting
* binary
* 和conditional variable的差別在conditional variable的signal若沒有人接收是會忽視的,而semaphore若沒有設立處理函式的話,有可能導致thread或是整個程式的中止
* 所以必須在thread pool產生執行緒前就事先指定處理函式。
在[The Free Lunch Is Over: A Fundamental Turn Toward Concurrency in Software](http://www.gotw.ca/publications/concurrency-ddj.html)一文中指出由於硬體製作商,在時脈,散熱,與功耗上遇到了瓶頸(提高時脈,提高溫度,但散熱能力仍無法有效改善)又因為64bits系統所用的程式基本型態例如pointer size從 4 -> 8 bytes,而導致cache裡能存的資料更少,所以逐漸轉向multi-processor的製作,及加大CPU內部的cache size。撰寫Concurrency與Parallel的程式變成了一種趨勢,而不是單純地靠著硬體設備上的更新,就能使程式跑的更快更有效率。
##### Functional Programming正好是軟體開發逐漸走向multi-thread的受益者
* 因為Funcitonal Languages不會共享資源(有自己的區塊)
* 不需要設鎖就可以確保程式的正確性
* 愈來愈多的程式語言支援部份的functional programming
>> 不要打錯字,是 "functional (programming) language",知道重要性後,趕快把 recursion 學好,頭腦體操可以磨練你。 [name=jserv]
>> 謝謝提醒 [name=chenyi]
#### Thread pool
* 紀錄有多少thread可以使用,且有多少工作要做
* 讓各執行緒知道該做什麼工作
於 [Toward Concurrency](https://hackmd.io/EYRgzAbAZgDA7ADgLRQJwIMZICww2JYCCLOAQ2GAQQFMxVUATVIA?view#lock-free-thread-pool) 裡有比較詳細的實作,裏面使用的方法是mutex lock,但mutex的獲取與釋放,對於效能會有一定的影響
所以後面又提出了lock-free的解決方案
>> 問題不在於 branch,而在於同步的成本,你之前參照的文章就提到了。 [name=jserv]
>> 喔喔 感謝提醒! [name=chenyi]
#### Lock-Free Thread Pool
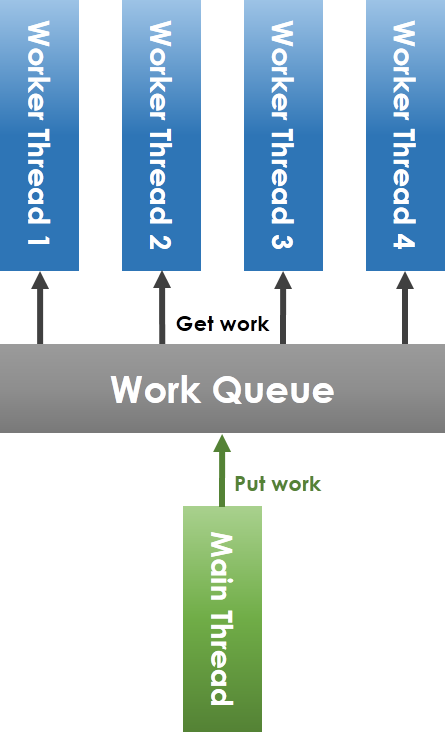
上面是一般會使用的thread pool實作方式
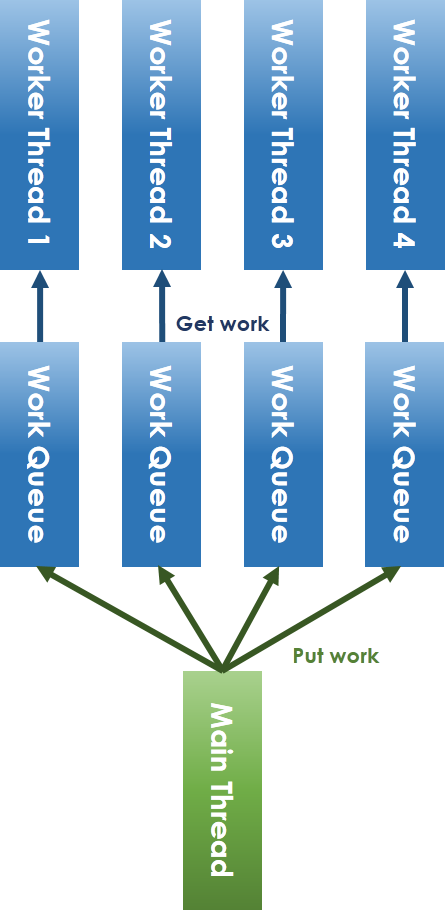
以下是lock-free化的thread pool
一般的thread pool實作方式是使用共用的work queue,以mutex保護,在發現待執行工作數目大於worker thread的情況下,將會利用conditional variable來喚醒等待狀態的worker thread。
不同於一般的作法,lock-free的作法是給予每個worker threads自己的work queue。
對於main-thread放工作和worker thread取工作的衝突採ring-buffer解決
此實作參考 https://github.com/xhjcehust/LFTPool
* Ring buffer

在這個實作裡的任務排程為
* Round-Robin : 一個一個問有沒有空來工作
* Least-Load : 找最閒的那位
*
另外還有做Task migration
* 考慮各個worker的load-balancing的話,task的遷移是必須的
* 有兩個function
* migrate in - 由main thread分配工作
* migrate out - 存在競爭資源問題 (該worker可能正在做事
* 利用C11裏面就有的atomic機制來處理lock問題
* atomic為同步處理機制,不用像是mutex的東西,便能確保變數間的同步
## POSIX Threads
資料來自於大家所熟知的 [POSIX Threads Programming](https://computing.llnl.gov/tutorials/pthreads/)上
>> 看了一下這邊好像沒什麼能寫的...上面的教學網站太好用了,man上也幾乎都能解決,暫時不做這邊的筆記[name=chenyi]
[Mutexes](https://computing.llnl.gov/tutorials/pthreads/#Mutexes)
試著從他的mutex範例學習(只紀錄重點)
(程式碼的部份連上去比較好看清楚mutex相關的部份)
```C
pthread_mutex_lock (&mutexsum);
dotstr.sum += mysum;
pthread_mutex_unlock (&mutexsum);
```
(mutex作用為提供各個執行緒在寫入共享記憶體區段的時候,避免覆(誤)寫的情況出現)
所以在進critical section的時候,要使用pthread_mutex_lock()將寫入鎖住,讓其他執行緒,等待該執行緒寫入完成。
## 實作部份
記一下要做什麼
* 預計實作一般版的thread pool
* 效能測試及畫圖
修正一下main.c的部份
```C=
entry *etmp;
pHead = pHead->pNext;
for (int i = 0; i < THREAD_NUM; i++) {
if (i == 0) {
pHead = app[i]->pHead->pNext;
dprintf("Connect %d head string %s %p\n", i,
app[i]->pHead->pNext->lastName, app[i]->ptr);
} else {
etmp->pNext = app[i]->pHead->pNext;
dprintf("Connect %d head string %s %p\n", i,
app[i]->pHead->pNext->lastName, app[i]->ptr);
}
etmp = app[i]->pLast;
dprintf("Connect %d tail string %s %p\n", i,
app[i]->pLast->lastName, app[i]->ptr);
dprintf("round %d\n", i);
}
```
這邊的pHead = pHead->next的部份是沒意義的(pHead->next在此時為NULL)
然後進去迴圈時的i=0的時候,可以省去做判斷,提出來在外面,大部份for迴圈裏面的都是debug用的樣子,另外沒理解錯的話,i = 0的時候phead的值應該要是 app[0]->pHead 才對,etmp目的應該是為了串接分開來的app,所以回圈裡的etmp->pNext應該要給予的值是app[i]->pHead
刪減過後
```C=
entry *etmp;
pHead = app[0]->pHead;
etmp = app[0]->pLast;
for (int i = 1; i < THREAD_NUM; i++) {
etmp->pNext = app[i]->pHead;
etmp = app[i]->pLast;
}
```
重整後在試跑一次確認程式正確性
```
./phonebook_opt
size of entry : 24 bytes
execution time of append() : 0.005126 sec
execution time of findName() : 0.005588 sec
```
修正後各thread執行時間

我認為會慢因為原本的方法裏面採的有順序的join (0-1-2-3)
```C
for (int i = 0; i < THREAD_NUM; i++)
pthread_join(tid[i], NULL);
```
以上面的4條thread為例,若是2先跑完,他必須等到0和1跑完join完才能join進main thread裡
而當thread數目夠高,各thread完成的順序就不會是0-1-2-3-4....而會是看系統怎麼安排(或者原本有寫thread pool去作管控)
先試試看[吳彥寬的實驗筆記](https://hackmd.io/s/BkN1JNQp)裡提到的用非同步的join
> 觀察一下程式碼,可以發現是在各自thread裡做append的動作,最後才做串接,也就是說,整個append的過程應該是沒有critical section的,如果能各自先結束並儲存,不要等待其他thread完成的話,應該能節省不少時間 [name=`chenyi`]
>
## Reference
* [作業網站](https://hackmd.io/s/rJsgh0na)
* [Toward Concurrency](https://hackmd.io/EYRgzAbAZgDA7ADgLRQJwIMZICww2JYCCLOAQ2GAQQFMxVUATVIA?view)
* [Process wiki](https://en.wikipedia.org/wiki/Process_(computing))
* [Thread wiki](https://en.wikipedia.org/wiki/Thread_(computing))
* [Asynchronous vs synchronous execution, what does it really mean?](http://stackoverflow.com/questions/748175/asynchronous-vs-synchronous-execution-what-does-it-really-mean)
* [POSIX Thread Programming](https://computing.llnl.gov/tutorials/pthreads)
* [C 的Thread pool筆記](http://swind.code-life.info/posts/c-thread-pool.html)
* [Semaphore wiki](https://en.wikipedia.org/wiki/Semaphore_(programming))
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet