# 2017q3 Homework2 (prefix-search)
contributed by <`changyuanhua`>
## 開發環境
* 輸入指令 ` lscpu `
```
Architecture: x86_64
CPU 作業模式: 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 4
On-line CPU(s) list: 0-3
每核心執行緒數:1
每通訊端核心數:4
Socket(s): 1
NUMA 節點: 1
供應商識別號: GenuineIntel
CPU 家族: 6
型號: 94
Model name: Intel(R) Core(TM) i5-6300HQ CPU @ 2.30GHz
製程: 3
CPU MHz: 799.890
CPU max MHz: 3200.0000
CPU min MHz: 800.0000
BogoMIPS: 4608.00
虛擬: VT-x
L1d 快取: 32K
L1i 快取: 32K
L2 快取: 256K
L3 快取: 6144K
NUMA node0 CPU(s): 0-3
```
## Trie 介紹
Trie ,又叫做前綴樹或是字典樹,是一個動態配置或關聯性配置的資料結構,用來保存關聯數組,常用在 string。 而當運用在 string 時, Trie 中每個節點由一個字元組成。
* Trie vs BST: Trie 不會直接將 key 儲存在節點中,反而是它在樹中的位置定義了它所關聯的 key。
* Trie樹的基本性質可以歸納為:
* 根節點不包含字元,除了根節點外的每個節點只包含一個字元。
* 從根節點到某一個節點,路徑上經過的字符連接起來,為該節點對應的字符串。
* 每個節點的所有子節點都有相同的前綴字串。
* 不是所有的節點都有對應的值,只有葉子節點和部分內部節點所對應的 key 才有相關的值。
* Trie 的應用: 主要在 bioinformatics , information retrieval
* Trie 的建立:
* 建立一個根節點,根節點必為空
```
@
```
* 插入單字 tea
1.先把 tea 拆分成 t, e, a
2.第一次出現前綴 t ,因此在根節點下建立新的子節點,節點為 t
3.從節點 t 開始看,e 也是第一次出現,因此在節點 t 下創造一個新的節點 e ......
```
@
/
t
/
e
/
a
```
* 再插入單字 to
1.節點 t 存在,就不再建立
2.節點 t 下不存在 o ,因此創造一個新的節點 o
```
@
/
t
/ \
e o
/
a
```
* 再插入 inn
* tea , to , in , inn 分別對應的value值為 0,1,2,3
* 執行 get(i) 時,會 return NULL,因為搜尋的末節點並不存在 value 值
* 執行 get(in) 時,會 return 2
* 執行get(ina)時,也會return NULL,因為 in 節點後並沒有 a 的節點位置
```
@
/ \
t i
/ \ \
e o(1) n(2)
/ \
a(0) n(3)
```
* 歸納:
* key 標註在節點中,而值標註在節點之下
* 可看出每一個值都對應一個完整的英文單詞,並且可以將 Trie 看作是一個確定有限狀態自動機。
* Trie 樹中,字符串 tea , to 都有相同的前綴 (prefix)為 “t” ,因此可以發現如果我們要存儲的字符串大部分都具有相同的前綴(prefix)時,那麼該 Trie 樹結構可以節省大量內存空間,因為 Trie 樹中每個單詞都是通過 character by character 方法進行存儲,所以具有相同前綴單詞是共享前綴節點的。
* 相反,如果 Trie 樹中存在大量字符串,並且這些字符串基本上沒有公共前綴,那麼相應的 Trie 樹將非常消耗內存空間,因此可得 Trie 的缺點是空指針耗費內存空間。
reference: [trie](https://zh.wikipedia.org/wiki/Trie)
## Ternary Search Tree (TST) 介紹
Trie 樹的結構,它的實現簡單但空間效率低。如果要支持26個英文字母,每個節點就要保存26個指針,假如還要加入標點符號、區分大小寫,內存用量就會急劇上升,以至於不可行。
因為 trie 的節點數組中保存的空指針,佔用了太多內存,因此考慮改用其他數據結構去代替,像是用 hash map。但是管理成千上萬個 hash map 不是什麼好主意,而且它還會使數據的相對順序信息丟失,所以使用 Ternary Tree 替代 trie。
* Binary Search Tree 查詢與建表時間是 O(log2n),但是在最糟的情況下時間複雜度可能轉為 O(n),除了要儲存的字串外不須另外分配空間。
* Trie 的時間複雜度是 O(n),能夠實現前者難以做到的 prefix-search,缺點是會有大量的空指針表,造成空間開銷過大。
* Ternary Search Tree,是一種 trie(亦稱 prefix-tree) 的結構,並且它結合字典樹的時間效率和 BST 的空間效率優點。
* 每個節點 (Node) 最多有三個子分支,以及一個 Key
* Key 用來記錄 Keys 中的其中一個字元 (包括 EndOfString)。
* low :用來指向比當前的 Node 的 Key 小 的 Node。
* equal :用來指向與當前的 Node 的 Key 一樣大 的 Node。
* high :用來指向比當前的 Node 的 Key 大 的 Node。
* Ternary Search Tree 的應用:
* spell check: Ternary Search Tree 可以當作字典來存儲所有的單詞。一旦在編輯器中輸入單詞,可以在Ternary Search Tree中並行搜索單詞以檢查正確的拼寫。
* Auto-completion: 使用搜索引擎進行搜索時,它會提供自動完成(Auto-complete)功能,讓用戶更加容易查找到相關的信息;假如:我們在Google中輸入ternar,它會提示與ternar的相關搜索信息。
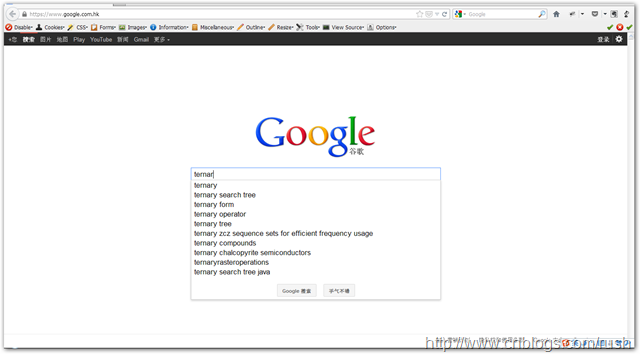
Google根據我們的輸入ternar,提示了ternary,ternary search tree等等搜索信息,自動完成(Auto-complete)功能的實現的核心思想三叉搜索樹。
對於Web應用程序來說,自動完成(Auto-complete)的繁重處理工作絕大部分要交給服務器去完成。很多時候,自動完成(Auto-complete)的備選項數目巨大,不適宜一下子全都下載到客戶端。相反,三叉樹搜索是保存在服務器上的,客戶端把用戶已經輸入的單詞前綴送到服務器上作查詢,然後服務器根據三叉搜索樹算法獲取相應數據列表,最後把候選的數據列表返回給客戶端。
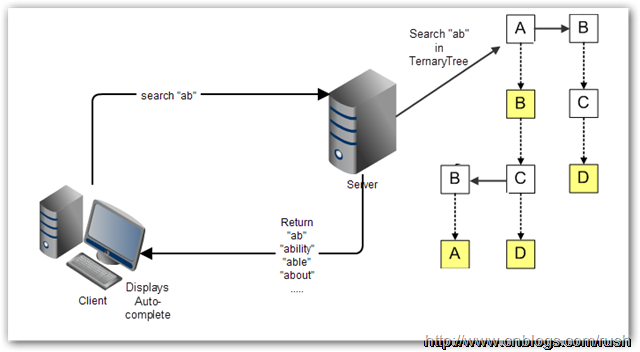
reference: [Ternary Search Tree 的應用]
(http://www.cnblogs.com/rush/archive/2012/12/30/2839996.html)
* Ternary Search Tree 的建立
* 插入 food ,拆分成 f , o , o , d ,`將 f 放入根節點`
1. 建立 root
2. 發現沒有字元在 root 中,設定為節點 f
3. 建立新的節點
4. 發現沒有字元在節點中,設定為節點 o
5. ......

* 插入單字 foot
1. 先比對 f,發現根節點與 foot 的 f 相同
2. 因此 pointer 往下,到節點 o ,發現與 foot 的 o 相同
3. 因此 pointer 往下,到節點 o ,發現與 foot 的 o 相同
4. 因此 pointer 再往下,到節點 d ,發現與 foot 的 t 不同,建立新的節點
5. 因為 **t>d** ,因此節點 d 的 **右子樹** 為 節點 t

* 插入單字 for

* 插入單字 foal
1. 先比對 f,發現根節點與 foal 的 f 相同
2. 因此 pointer 往下,到節點 o ,發現與 foal 的 o 相同
3. 因此 pointer 再往下,到節點 o ,發現與 foal 的 a 不同,建立新的節點
4. 因為 **a<o** ,因此節點 o 的 **左子樹** 為 節點 a
5. ......

* 插入單字 dog

reference: [Ternary Search Tree (Trie with BST of children)](https://www.cs.usfca.edu/~galles/visualization/TST.html)
reference: [twngbm 共筆](https://hackmd.io/s/rJKkryGpb)
## prefix-search 實做
* 編譯指令: `make`
* 執行指令: `./test_cpy`
### 修改 test_ref.c
發現把 `CPY` 改為 `REF` ,仍然可以使正確編譯,但是執行結果是錯誤的
* quit : 回報錯誤訊息
* search : 只有找到輸入字串本身,如下
```
choice: s
find words matching prefix (at least 1 char): Tain
Tain - searched prefix in 0.000011 sec
suggest[0] : Tain
suggest[1] : Tain
suggest[2] : Tain
suggest[3] : Tain
suggest[4] : Tain
suggest[5] : Tain
suggest[6] : Tain
suggest[7] : Tain
suggest[8] : Tain
suggest[9] : Tain
suggest[10] : Tain
suggest[11] : Tain
```
#### quit 解決方法
在 `tst.c` 檔中,有兩個 function
* `tst_free( )` : free the ternary search tree rooted at p, data storage **external** ,推斷專屬為 `REF` 所使用
* `tst_free_all( )` : free the ternary search tree rooted at p, data storage **internal**. ,推斷專屬為 `CPY` 所使用
因此將 `tesr_ref.c` 檔中的 `tst_free_all( )` 修改為 `tst_free( )` ,而後 quit 可以正確執行。
```clike=
case 'q':
tst_free(root);
/* tst_free_all(root);*/
return 0;
break;
```
#### search 解決方法
在 `tesr_ref.c` 檔中,有著下列的程式碼以及註解:
```clike=
/* FIXME: insert reference to each string */
res = tst_ins_del(&root, &p, INS, REF);
```
因此至 `tst.c` 檔中,觀看 `tst_ins_del()` 函式,下列為 `tst_ins_del()` 的程式碼
```clike=
void *tst_ins_del(tst_node **root, char *const *s, const int del, const int cpy)
{
/*......*/
if (*p++ == 0) {
if (cpy) { /* allocate storage for 's' */
const char *eqdata = strdup(*s);
if (!eqdata)
return NULL;
curr->eqkid = (tst_node *) eqdata;
return (void *) eqdata;
} else { /* save pointer to 's' (allocated elsewhere) */
curr->eqkid = (tst_node *) *s;
return (void *) *s;
}
}
/*......*/
}
```
從上面的程式碼可以發現,當 cpy 為 0 時,curr->eqkid 就會直接存 *s ,也就是將字串 (s) 直接存進 leaf 。
從上面的註解得知:
* CPY 不是零時,會直接指派一個空間給 s,利用 strdup() 預先指派好一塊記憶體空間放置複製的字串了
* CPY 是零時,會讓 s 存一個指標。
而在 `tesr_ref.c` 檔中,有著下列的程式碼:
```clike=
p = word;
tst_ins_del(&root, &p, INS, REF)
```
從上面兩段程式碼可以得知 *s 對映到 word 這個 pointer to character ,也就是說所有 insert 操作的節點都存到以 word 為起點的連續記憶體位址的其中一個位址。
解決方法: 利用 `strdup()` ,其會先用 malloc() 配置與 word 相同的空間 ,存入到此位址,然後反回位址值。如此就可以讓他們的位址皆不同。程式碼如下:
```clike=
p = strdup(word);
tst_ins_del(&root, &p, INS, REF)
```
結果 `./tesr_ref` 與 `./tesr_cpy` 相同:
```
choice: s
find words matching prefix (at least 1 char): Tain
Tain - searched prefix in 0.000011 sec
suggest[0] : Tain,
suggest[1] : Tainan,
suggest[2] : Taino,
suggest[3] : Tainter
suggest[4] : Taintrux,
```
reference: [st9007a 共筆](https://hackmd.io/s/SkeKQEq3Z)