# 2017q1 Homework1 (phonebook)
contributed by < `ktvexe` >
繼續之前的實作,研究尚未討論的議題。
### Reviewed by `jserv`
* 沒有嘗試不同的 data set,原本的程式輸入是已排序、非典型英文姓氏,這與現實不匹配
* 實做提到透過引入 hash 加速 `fineName()` 的操作,但缺乏不同 hash function 的效能比較和設計取捨
* 在 `append()` 中,`malloc()` 是個顯著的時間開銷,缺乏減緩效能衝擊的方案,而且沒考慮到 `malloc()` 失敗的情況

* 在上圖的環境中,可用記憶體不足以載入 35 萬筆電話資料,於是連 `phonebook_orig` 執行都會失敗:
```shell
$ ./phonebook_orig
size of entry : 136 bytes
程式記憶體區段錯誤
```
* 缺乏搜尋演算法的評估和效能分析
* 考慮到電話簿需要作到動態資料新增和刪除,若引入 hash,面對大量資料時,會有什麼影響?
* 儘管已經整理頗多 perf 和效能測量的資料,但並未反映到此程式效能分析,除了 cache miss,還請一併探討 branch prediction accuracy 等議題
* `main.c` 無法透過 function pointer 來切換和比較不同實做的效能落差,應該先設計一份可通用的軟體界面,然後將 binary tree, hash table, trie 等不同實做機制加入
* 將 `append()` 和 `findName()` 時間加入統計的意義不大,真實應用往往是個別操作,特別在圖表的呈現
* commit [e814bce400bee28b2f60433a431cc2f54ae54df8](https://github.com/ktvexe/phonebook-1/commit/e814bce400bee28b2f60433a431cc2f54ae54df8) 的標題是 "collect lastname to structure",對照看具體程式碼修改,其實很不直覺,不只是英文表達不好,行為面也有落差
* 請閱讀 Malte Skarupke 撰寫的 [I Wrote The Fastest Hashtable](https://probablydance.com/2017/02/26/i-wrote-the-fastest-hashtable/),重新實作以 hash table 為基礎的資料查找機制
## 開發環境
我們知道phonebook這份作業考量到cache miss的議題
先來複習一下電腦的規格:
```shell
ktvexe@ktvexe-SVS13126PWR:~$ lscpu
Architecture: x86_64
CPU 作業模式: 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 4
On-line CPU(s) list: 0-3
每核心執行緒數:2
每通訊端核心數:2
Socket(s): 1
NUMA 節點: 1
供應商識別號: GenuineIntel
CPU 家族: 6
型號: 58
Model name: Intel(R) Core(TM) i5-3210M CPU @ 2.50GHz
製程: 9
CPU MHz: 1316.308
CPU max MHz: 3100.0000
CPU min MHz: 1200.0000
BogoMIPS: 4988.52
虛擬: VT-x
L1d 快取: 32K
L1i 快取: 32K
L2 快取: 256K
L3 快取: 3072K
NUMA node0 CPU(s): 0-3
```
看到L1d,L1i好高興阿,回想了Architecture的觀念,來貼個圖增加印象
看圖說故事:在Harvard 架構下,我們可以同時進行指令與資料的存取,因為指令與資料是分開存放在不同的記憶體中,並且各自有自己的bus連接 CPU。
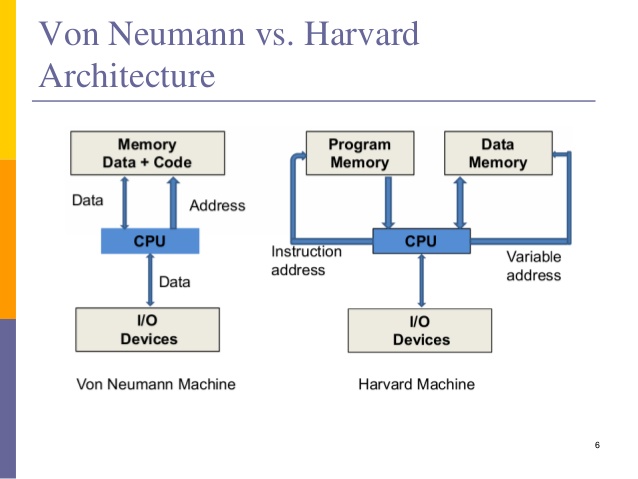
但是CPU與DRAM的速度還是差太多了,這樣的架構會導致效能不佳的結果,所以才有了L1i與L1d,如圖:

linux kernel:
```shell
ktvexe@ktvexe-SVS13126PWR:~$ uname -a
Linux ktvexe-SVS13126PWR 4.2.0-36-generic
#42-Ubuntu SMP Thu May 12 22:05:35 UTC 2016 x86_64 x86_64 x86_64 GNU/Linux
```
## **perf top**
`$ ./phonebook_orig & sudo perf top -p $!`
```
29.88% libc-2.21.so [.] __strcasecmp_l_avx
18.69% phonebook_orig [.] findName
7.52% libc-2.21.so [.] _int_malloc
5.82% libc-2.21.so [.] _IO_fgets
5.61% phonebook_orig [.] main
4.61% [kernel] [k] clear_page_c_e
```
## Phone book效能
更改phonebook_opt
重點提示:
可能的效能改進方向:
* 改寫 struct __PHONE_BOOK_ENTRY 的成員,搬動到新的結構中
* 使用 hash function 來加速查詢
* 既然 first name, last name, address 都是合法的英文 (可假設成立),使用字串壓縮的演算法,降低資料表示的成本
* 使用 binary search tree 改寫演算法
## Original
其實phonebook_orig.c非常的簡單,只是單純的重頭找到尾而已,entry是他的struct type
```clike=
entry *findName(char lastname[], entry *pHead)
{
while (pHead != NULL) {
if (strcasecmp(lastname, pHead->lastName) == 0)
return pHead;
pHead = pHead->pNext;
}
return NULL;
}
```
結果:
```shell
ktvexe@ktvexe-SVS13126PWR:~/sysprog21/phonebook-1$ ./phonebook_orig
size of entry : 136 bytes
execution time of append() : 0.085390 sec
execution time of findName() : 0.006302 sec
```
cache miss 高達96%
```shell
Performance counter stats for './phonebook_orig' (100 runs):
2,104,427 cache-misses # 96.003 % of all cache refs
2,205,941 cache-references
262,396,733 instructions # 1.35 insns per cycle
195,377,242 cycles
0.067539350 seconds time elapsed ( +- 1.23% )
```
## Optimization 1(By struct)
### Step 1:
in `main`,可以發現不管append還是findName其實都也只用到lastname
```clike=
e = pHead;
/* the givn last name to find */
char input[MAX_LAST_NAME_SIZE] = "zyxel";
e = pHead;
assert(findName(input, e) &&
"Did you implement findName() in " IMPL "?");
assert(0 == strcmp(findName(input, e)->lastName, "zyxel"));
```
所以一開始先從struct下手,先把其他欄位都給comment out

```clike=
typedef struct __PHONE_BOOK_ENTRY {
char lastName[MAX_LAST_NAME_SIZE];
/*
char firstName[16];
char email[16];
char phone[10];
char cell[10];
char addr1[16];
char addr2[16];
char city[16];
char state[2];
char zip[5];
*/
char *firstName_ptr;
struct __PHONE_BOOK_ENTRY *pNext;
} entry;
```
```shell
Performance counter stats for './phonebook_opt' (100 runs):
275,241 cache-misses # 75.118 % of all cache refs
387,945 cache-references
242,059,187 instructions # 1.80 insns per cycle
134,146,788 cycles
0.047033038 seconds time elapsed ( +- 0.64% )
```
### step2:
不過只有lastname的電話簿是不符合規定的,所以說把結構內加入char*,到時想要增加其他的資訊再另外加。
所以結果如下:
處理時間上差異不大,可以看出明顯差異的是entry的大小改變。
```shell
ktvexe@ktvexe-SVS13126PWR:~/sysprog21/phonebook-1$ ./phonebook_opt
size of entry : 40 bytes
execution time of append() : 0.075857 sec
execution time of findName() : 0.003739 sec
```
接下來把其他資料補完後
`phonebook_opt.h`
程式碼:
```clike=
#ifndef _PHONEBOOK_H
#define _PHONEBOOK_H
#define MAX_LAST_NAME_SIZE 16
/* TODO: After modifying the original version, uncomment the following
* line to set OPT properly */
#define OPT 1
typedef struct __PHONE_BOOK_ENTRY {
char lastName[MAX_LAST_NAME_SIZE];
char *firstName_ptr;
char *email_ptr;
char *phone_ptr;
char *cell_ptr;
char *addr1_ptr;
char *addr2_ptr;
char *city_ptr;
char *state_ptr;
char *zip_ptr;
struct __PHONE_BOOK_ENTRY *pNext;
} entry;
entry *findName(char lastname[], entry *pHead);
entry *append(char lastName[], entry *e);
void append_elements(char elements[16],char *info);
#endif
```
```clike
ktvexe@ktvexe-SVS13126PWR:~/sysprog21/phonebook-1$ ./phonebook_opt
size of entry : 96 bytes
execution time of append() : 0.052291 sec
execution time of findName() : 0.003656 sec
```
總共96 bytes,而cache miss也降到72%,這是可以想像的,結構變小,cache會因為超出容量而踢block。
<pre>shell
Performance counter stats for './phonebook_opt' (100 runs):
1,098,896 cache-misses # <mark>71.509%</mark> of all cache refs
1,529,886 cache-references
259,741,175 instructions # 1.53 insns per cycle
165,656,122 cycles
0.062172392 seconds time elapsed ( +- 1.14% )
</pre>

### step3
不過要是只有這樣entry size還是很大,結構愈大,能放入block的數量愈少,但是要如何改善呢?
所以接下來嘗試把lastname包在同一個struct,使其記憶體連續,以增加cache hit。
所以我將struct加入了index,可以用於紀錄lastName存到哪一個index,並更改findName使他多回傳一個index參數,結構如下,一個struct我裝了128個lastName,所以index用unsigned char。
程式碼:
```clike=
#ifndef _PHONEBOOK_H
#define _PHONEBOOK_H
#define MAX_LAST_NAME_SIZE 16
/* TODO: After modifying the original version, uncomment the following
* line to set OPT properly */
#define OPT 1
typedef struct __PHONE_BOOK_ENTRY {
char lastName[128][MAX_LAST_NAME_SIZE];
unsigned char index;
struct __PHONE_BOOK_ENTRY *pNext;
} entry;
entry *findName(char lastname[], entry *pHead);
entry *append(char lastName[], entry *e);
void append_elements(char elements[16],char *info);
#endif
```
結果:
```shell
ktvexe@ktvexe-SVS13126PWR:~/sysprog21/phonebook-1$ ./phonebook_opt
size of entry : 2064 bytes
execution time of append() : 0.255562 sec
execution time of findName() : 0.026220 sec
```
```shell
Performance counter stats for './phonebook_opt' (100 runs):
14,304,593 cache-misses # 95.516 % of all cache refs
14,768,166 cache-references
691,889,967 instructions # 0.72 insns per cycle
911,402,051 cycles
0.335309653 seconds time elapsed ( +- 0.80% )
```
```shell
17.06% phonebook_opt [.] findName
11.38% libc-2.21.so [.] __strcasecmp_l_avx
10.25% [kernel] [k] clear_page_c_e
9.26% libc-2.21.so [.] _int_malloc
8.54% [kernel] [k] page_fault
3.21% [kernel] [k] get_page_from_freelist
2.77% phonebook_opt [.] main
```
cache miss並沒有下降,可能是我一個struct大約是2KB,而cache是32K,如此雖然可裝16*128個lastName,但卻並不合block的大小,導致這樣的配置沒有將成果發揮出來。
### step4
如果將結構增加一個index,在append時記下各開頭的index,這樣的話findname時直接從其index開頭開始搜尋,換句話說就是將原本只有1條的link-list拆成多條,這應該也可以提升執行效能,best case當然是如果每條差不多長,記憶體不會隔太遠,就能降低cache miss,且不嚴重增加append的時間,又能使findName迅速。
## Optimization 2(By hash)
根據作業要求中的提示,來實作hash,以加快findName性能,不過這hash怎麼做呢?
google搜尋一下,選擇了BKDR-Hash。
網路上找到的範例code長著樣,依樣畫葫蘆,照著寫一段。
```clike=
unsigned int BKDRHash(char *str)
{
unsigned int seed = 131; // 31 131 1313 13131 131313 etc..
unsigned int hash = 0;
while (*str) {
hash = hash * seed + (*str++);
}
return (hash & 0x7FFFFFFF);
}
```
因為我本身每個struct中有128個lastName,所以我將bucket先設成256。
預測分析:
當然這樣的方式有可能可以減少link list的長度,長度變短,像我的struct可以裝128比資料,所以長度可以縮短128倍,要append的時間就可以縮短,因為跑到尾端的距離較短,不過也可能因為每個entry過大,導致cache miss,而損失的效能。
實驗結果:
findName如同預期的效能提升了,而且非常的明顯,不過我沒有想到的是,append的效能也一起提升,我感覺這並不太正常,原先append雖然將全部資料串在一起,資料亮大時會很長,不過作hash明明還要找bucket,然後要串各比資料時,記憶體應該更為分散,應該不會有效能的提升才是阿。

```
Performance counter stats for './phonebook_opt_hash' (100 runs):
301,701 cache-misses # 39.013 % of all cache refs
685,079 cache-references
164,446,947 instructions # 1.26 insns per cycle
124,774,408 cycles
0.050262105 seconds time elapsed ( +- 6.92% )
```
最後來寫一個free來解決memory leak。
```C
void freeList(entry *head)
{
while (head != NULL){
entry *tmp = head;
head = head->pNext;
free(tmp);
}
}
```
## 小結:
我覺得自己在整理資料上,都要花費比別人還長的時間,而且成果也沒有比較完善,很羨慕能快速整理重點、彙整資訊的人,我閱讀資料時經常會發散,書一本又一本的開,google分頁愈開愈多,只得到越來越多資料,也不確定哪些是我需要的,很佩服其他能再時間內完成3種、4種實作的同學,覺呢能跟他們一起學習真是太好了,希望能一起變強。
我覺得這次phonebook的分析真的可以複習很多以前學過的東西,當然還有很多沒有學過的,而且透過跟大家學習,可以知道自己的不足,還來不及完成的實作,我也會在以後陸續補上。
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet