# D01: phonebook
###### tags: `sysprog2018`
==作業解說 [video](https://www.youtube.com/watch?v=ZICRLKf_bVw)==,請對照觀看
:::info
主講人: [jserv](http://wiki.csie.ncku.edu.tw/User/jserv) / 課程討論區: [2018 年系統軟體課程](https://www.facebook.com/groups/system.software2018/)
:mega: 返回「[作業系統設計與實作](http://wiki.csie.ncku.edu.tw/sysprog/schedule)」課程進度表
:::
## 預期目標
* 準備 GNU/Linux 開發工具
* 學習使用 Git 與 GitHub
* 學習效能分析工具
* 研究軟體最佳化
* 技術報告寫作練習
## Linux 效能分析工具: Perf
* Perf 全名是 Performance Event,是在 Linux 2.6.31 以後內建的系統效能分析工具,它隨著核心一併釋出。藉由 perf,應用程式可以利用 PMU (Performance Monitoring Unit), tracepoint 和核心內部的特殊計數器 (counter) 來進行統計,另外還能同時分析運行中的核心程式碼,從而更全面了解應用程式中的效能瓶頸
* 請詳讀 [perf 原理和實務](https://hackmd.io/s/B11109rdg) 並在自己的 Linux 開發環境實際操作
* 再次提醒:你的 GNU/Linux「不能」也「不該」透過虛擬機器 (如 VMware, VirtualBox, QEMU 等等) 安裝,請務必依據 [2017 年春季作業說明](https://hackmd.io/s/Bk-1zqIte) 指示,將 Linux 安裝於實體硬碟並設定好多重開機
## 案例探討:電話簿搜尋
* 詳細閱讀 [Programming Small](https://hackmd.io/s/SkfffA-jZ) 裡頭的電話簿程式,研究降低 cache miss 的方法
* 雖然這是探討 cache miss 和效能議題,其實是帶著同學重新複習 C 語言和資料結構。以前大家只是「背誦心法」,從來就不會去理解個別資料結構對整體的衝擊。
* 自 GitHub 取得作業程式碼
```
$ git clone https://github.com/sysprog21/phonebook
$ cd phonebook
```
* 編譯
```
$ make
```
* 測試。當看到 `[sudo] password for` 字樣時,輸入自己的 Linux 使用帳號密碼
```
$ make run
```
* 參考輸出: (按下 `Ctrl`-`C` 可以離開畫面)
```
size of entry : 136 bytes
execution time of append() : 0.043859 sec
execution time of findName() : 0.004776 sec
```
* 透過 gnuplot 建立執行時間的圖表 (保持耐心等待,中間過程不要切換視窗)
```
$ make plot
```
* 正確執行後,目錄裡頭會有個名為 `runtime.png`,可用 `eog runtime.png` 命令來觀看
# 善用 gnuplot 來製圖
* 從今天起忘記 Microsoft Excel,因為 gnuplot 可以給你更專業的圖表,而且能夠批次產生
* 先啟動 gnuplot:
```
$ gnuplot
```
* gnuplot 啟動後,需要做一些必要設定,例如設定圖片名稱,XY軸的資訊等等:
```
> set title 'my plot' @ 設定圖片名稱
> set xlabel 'x axis' @ 設定XY軸座標名稱
> set ylabel 'y axis'
> set terminal png @ 設定輸出格式為 .png
> set output 'output_plot.png' @ 設定輸出檔名
> plot [1:10][0:1] sin(x) @ 畫出 sin(x) 函式
@ x軸座標範圍 1-10
@ y軸座標範圍 0-1
```
* 可以將這些設定另外存成一個檔案,作為 gnuplot 的腳本。假設上述指令存在一個名為 plot 的檔案裡面,以後只要輸入 `gnuplot plot` 即可畫出我們想要的圖表。
* 參考圖表: 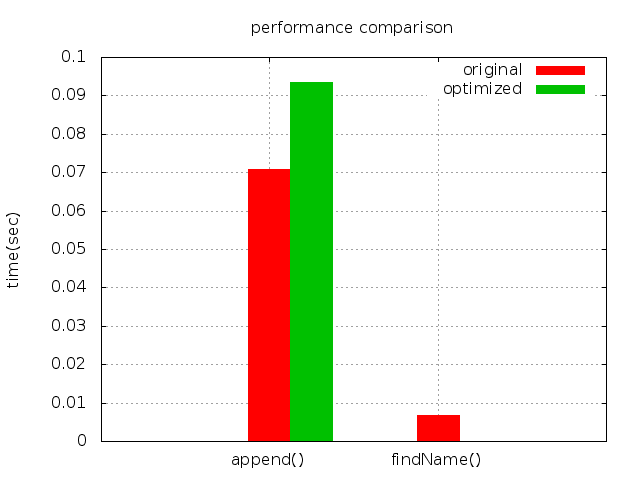
* 請繼續閱讀 [gnuplot 語法解說和示範](https://hackmd.io/s/Skwp-alOg)
## 使用 astyle + Git 實做自動程式碼排版檢查
* 使用一致的 coding style 很重要,我們可透過 astyle 這個工具來協助。調整作業程式要求的風格為以下:
```
$ astyle --style=kr --indent=spaces=4 --indent-switches --suffix=none *.[ch]
```
* 你可以想像 Apple 和 Google 的工程師隨便安置程式碼,然後不用管合作的議題嗎?
* 即便一個人寫作業,其實是三人的參與:過去的你、現在的你,以及未來的你
* 當首次執行 `make` 後,Git pre-commit hook 將自動安裝到現行的工作區 (workspace),之後每次執行 `git commit` 時,Git hook 會檢查 C/C++ 原始程式碼的風格是否一致:
* 我們介紹 [Git hooks](https://goo.gl/CNMHZJ) 是為了日後銜接 Continuous integration (CI),專業程式設計必備的準備工作
* 任何人都可以寫出機器看得懂的程式碼 (在檔案總管裡面對 EXE 檔複製貼上即可),但我們之所以到資訊工程系接受訓練,為了寫出人看得懂、可持續維護和改進的程式
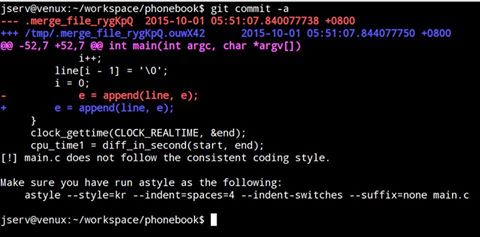
* 下圖展示 Git pre-commit hook 偵測到開發者的修改並未遵守一致的 coding style,主動回報並提醒開發者:
## 作業要求
* 在 GitHub 上 fork [phonebook](https://github.com/sysprog21/phonebook/) (若你在 2018 年 2 月 27 日之前已經 fork [phonebook](https://github.com/sysprog21/phonebook/),那應該重新 fork 過),然後適度修改 `phonebook_opt.c` 和 `phonebook_opt.h` 兩個檔案,使得這兩者執行時期的 cache miss 降低。請用 perf 驗證,而且改進的過程中,不能有功能方面的減損。
* `phonebook_orig.[ch]` 不需要修改,我們關注的是 `phonebook_opt.[ch]`,當然要修改 `main.c` 也是允許的
* `findName()` 的時間必須原本的時間更短
* `append()` 的時間可以比原始版本稍久,但不應該增加太多,請參照下方共筆選讀的方法,著手縮減 `append()` 的時間開銷
* `main.c` 應該只有一份,不要建立新的 `main()`,善用 Makefile 定義對應的 `CFLAGS`
* 過程中也會需要改動到 `Makefile`,請詳閱 [Makefile 語法和示範](https://hackmd.io/s/SySTMXPvl)
* 在提交程式前,務必詳閱 [如何寫好 Git Commit Message](https://blog.louie.lu/2017/03/21/%E5%A6%82%E4%BD%95%E5%AF%AB%E4%B8%80%E5%80%8B-git-commit-message/)
* 在執行程式(`phonebook_orig` 和 `phonebook_opt`) 前,先清空 cache:
```
$ echo 1 | sudo tee /proc/sys/vm/drop_caches
```
* 詳閱 [cache 原理和實驗](https://hackmd.io/s/S14L26-_l),作業中也該提及你的認知並描述對應的實驗方法
* 除了修改程式,也要編輯「[作業區](https://hackmd.io/s/SJONH8fuz)」,增添開發紀錄和 GitHub 連結
* 至少要列出效能分析,以及充份說明你如何改善效能
* 以 [gnuplot](http://www.gnuplot.info/) 繪製效能分析圖表
* 改善電話簿的效能分析,透過大量的重複執行,找出 95% 信賴區間,而且允許動態新增資料 (較符合現實) 和查詢
* 除了降低 `findName()` 的 cache miss 與執行成本,`append()` 也該想辦法縮減時間
* 建立 phone book 時,既然 lastName 是索引值,可以優先建立搜尋表格,其他資料可稍後再補上
* 回答以下問題:本例選用的 dataset (也就是輸入電話簿的姓名) 是否存在問題?
* 有代表性嗎?跟真實英文姓氏差異大嗎?
* 資料難道「數大就是美」嗎?
* 如果我們要建立符合真實電話簿情境的輸入,該怎麼作?
* 詳細閱讀 [示範用的 Phonebook 作業](https://hackmd.io/s/SklSEW6G-),嘗試在自己的環境中重現裡頭的實驗,比照其中的寫作格式,第一段要提及「開發環境」,並且充分比較不同資料結構的影響
* 引入多項效能改進並在 HackMD 詳細論述: (詳情參照下方「見賢思齊」提及的共筆)
* 使用 binary search tree 或其他資料結構改寫
* 藉由 hash function 來加速查詢,請詳閱 [hash function 觀念和實務](https://hackmd.io/s/HJln3jU_e)
* 既然 first name, last name, address 都是合法的英文 (可假設成立),使用[字串壓縮的演算法](http://stackoverflow.com/questions/1138345/best-compression-algorithm-for-short-text-strings),降低資料表示的成本
* 截止日期:
* Mar 12, 2018 (含) 之前
* 越早在 GitHub 上有動態、越早接受 code review,評分越高
## 挑戰題
* 支援 [fuzzy search](http://www.informit.com/articles/article.aspx?p=1848528),允許搜尋 lastName 時,不用精準打出正確的寫法
* 比方說電話簿有一筆資料是 `McDonald`,但若使用者輸入 `MacDonald` 或 `McDonalds`,也一併檢索出來
* 延伸閱讀: [Levenshtein Distance (編輯距離)](https://charles620016.hackpad.com/ep/pad/static/Japi4qFyAzt)
## 見賢思齊:共筆選讀
- [2017 年秋季期班中報告](https://hackmd.io/s/BJl6pFyzf)
- [2017 年春季班期中報告](https://hackmd.io/s/H1g0s3sax)
* 支援 fuzzy search,允許搜尋 lastName 時,不用精準打出正確的寫法
* 指出原有 dataset 的問題 (需要有工程分析,拿出統計學) 並改進。
- [0xff07](https://hackmd.io/s/SkpIRTvKe)
* perf 運作原理
* 分析英文字母出現頻率
- [ryanwang522](https://hackmd.io/s/Sk-qaWiYl)
* 原本 Linked list 的查找時間複雜度為 O(n) ,他將資料結構調整成 BST 後,時間複雜度為 O(logn),由圖表也可得知查找效率也大幅改善。
* BST 應針對 cache line 的特性去調整
- [ierosodin](https://hackmd.io/s/SJ4uqs9Yx)
* 引入 memory pool,降低記憶體存取的成本
- [heathcliffYang](https://hackmd.io/s/Hyr9PhFYx)
* 嘗試引入 Soundex 演算法來提高可用性,允許相似音的查詢。
* Soundex 演算法利用英文字的讀音計算近似值,值由 4 個字元構成,第 1 個字元為英文字母,後 3 個為數字。在拼音文字中有時會有會念但不能拼出正確字的情形,可透過 Soundex 達成類似模糊匹配的效果。
* 例如 Knuth 和 Kant 二個字串的 Soundex值都是 "K530"。不過要注意的是,因為給定的 data set 非常不理想 (不是真的英文姓名),透過 Soundex 的效果很有限,應該著手改進輸入資料。
* 0140454: [共筆](https://hackmd.io/s/Bkx3cYX6)
* 觀察程式中所使用的 words.txt,他發現,輸入已照字典序排序好,接著他思考:「如果把資料打亂再測試一次的話,結果是否會有所不同?」
* 他打亂後發現,未優化前與前兩種方式所受到的影響比較小。而,trie 和 red-black tree 的方式,均有明顯的不同。原因在於順序的不同,導致在維護樹的時候有所差異。
* 下一步,應該尋找一個適當的lastname dataset來做測試,因為words.txt中包含了許多沒有名字意義的單字。
* 考慮用詞彙庫代替phonebook,挑戰會高很多也實用多了,就隨機輸入一篇專業文章然後逐步搜尋字彙。詞彙庫可以用微軟的: https://www.microsoft.com/Language/zh-tw/Terminology.aspx
* nekoneko: [共筆](https://hackmd.io/s/rJCs_ZVa)
* 引入 hash function 來改寫電話簿的搜尋機制時,針對 h(x) = x mod M 形式的函數,用不同的 M 帶入,發現 hash value 分佈落差很大
* 延伸閱讀: MIT 線上課程 [10. Dictionaries](https://www.youtube.com/watch?v=Mf9Nn9PbGsE) (video)
* 單純將字元直接相加就是 lose-lose hash function
* 可參考這篇: [Hash Functions](http://www.cse.yorku.ca/~oz/hash.html)
* 另外 hash function 做 mod 出來如果呈現 uniform distribution 才是最好的,搜尋每一個 bucket 的 worst case 都差不多,而像 lose-lose 遇到 worst case 就糟糕了
* jkrvivian: [共筆](https://hackmd.io/s/SyOQgOQa)
* 觀察修改 data representation 對於 cache miss 和整體執行時間的衝擊外,她嘗試引入字串壓縮演算法,想研究 SMAZ 一類的字串壓縮演算法,對於 cache 的影響。
* 因為我們給定的字典檔跟現實落差太大,所以常見的字串壓縮演算法往往無法發揮作用,會得到比原本字串還長的輸出,導致反效果。不過,如果善用壓縮演算法,針對特定的情況,會有幫助。
* 實驗的精神、方法,以及最後如何解讀並且提出新的假設再持續調整,非常重要
* louielu: [共筆](https://hackmd.io/s/BJjL6cQ6)
* 研究 perf 資料的同時,花了很多時間研究究竟如何精準測量執行時間 (再多核心系統中,這件事越來越困難),他從 PMU 的原理開始研讀,交叉對照 Intel® 64 and IA-32 Architectures Developer’s Manual,知曉 perf event 背後的議題,他也著手翻譯了部份技術文件,相當難得。
* __builtin___clear_cache 可清除指定範圍內的 instruction cache,實做在 GNU Toolchain 提供的 libgcc 中。呂同學還注意到給定的 linked list 實做上,透過 e = append(line, e) 這種方式來 append,可以降低一般 linked list append 需要 O(n) 的時間,可是必須要維護一個 list head,這是很重要的發現
* [dada](https://embedded2016.hackpad.com/ep/pad/static/YkqjhwgnQcA)
* [rnic](https://embedded2016.hackpad.com/ep/pad/static/9eSkToGwJvZ)
* [Yuron](https://embedded2016.hackpad.com/ep/pad/static/NcHhQCQ4ijr)
## 參考資料
:::warning
引用過往作業成果時,務必標註出處 (包含 GitHub 帳號或人名),連帶相關的超連結
:::
* [2017 年春季班課程作業區](https://hackmd.io/s/Hy2rieDYe)
* [2016 年秋季班課程作業區](https://hackmd.io/s/H1B7-hGp): 提供錄影解說
* [2016 年春季班課程作業區](https://embedded2016.hackpad.com/2016q1-Homework-1-tiduo3FfIQD)