CS:APP 3/e cachelab
===
###### tags: `sysprog2018`
[實驗說明](http://csapp.cs.cmu.edu/3e/cachelab.pdf)
## 任務:
1. 完成 csim.c 中的 cache simulator。
2. 完成 trans.c 中,可能造成 cache misses 的矩陣運算。
## 工具
* 檢查全部
``$./driver.py``
* 檢查 csim 中的模擬器的正確性
``$ ./test-csim``
* 檢查矩陣運算的正確與效能
```
$ ./test-trans -M 32 -N 32
$ ./test-trans -M 64 -N 64
$ ./test-trans -M 61 -N 67
```
* 預先提供的參考用模擬器:csim-ref
## Part A
### 要求
* 模擬一個參數如下的 cache。
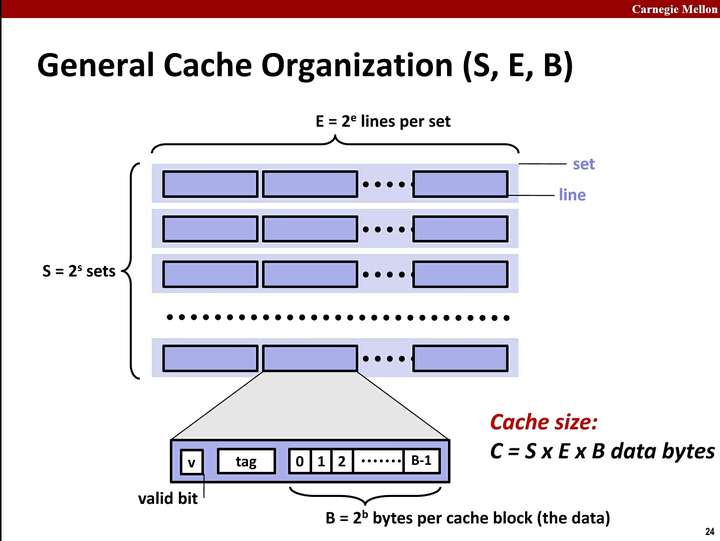
以 32 bit address 為例:

* -v: Optional verbose flag that displays trace info
* -s : Number of set index bits (S = 2^s is the number of sets)
* -E : Associativity (number of lines per set)
* -b : Number of block bits (B = 2^b is the block size)
* -t : Name of the valgrind trace to replay
* 對其作 `trace/***.trace` 中的記憶體操作。
```
Ex:
I 0400d7d4,8
M 0421c7f0,4
L 04f6b868,8
S 7ff0005c8,8
每行代表一個操作,格式:
[space]operation address,size
“I” 代表 instruction load,
“L” 代表 data load,
“S” 代表 data store,
“M” 代表 data modify (i.e., a data load followed by a data store)
```
* 這次實作不需要考慮 "I",只需要考慮 "L"、"S"、"M"
- "L" 表示載入(讀)、"S" 表示儲存(寫),兩者在檢查 cache 時的行為一樣,只要判斷 set、tag 跟 valid bit 即可
- "M" 代表修改,需要一次讀檔與一次寫入,因此會檢查兩次 cache
### 定義 cache 結構 & 建立 cache table
每行 cache line 的資料結構如下圖:

* 這次並不會進行資料搬移,只需要透過比較同個組中 valid bit 跟 tag 就可以判斷 hit/miss,所以在定義資料結構時沒有加入 data。
* cache 的取代採用 least recently used,因此在每筆資料中需要一個參數紀錄該筆資料在什麼時間點被使用,我們以一個 operation 作為一個時間單位,程式一開始為 0,每進行一個操作數值加一,因此數值愈小表示愈久未被使用。
```c
typedef struct cache_data{
int valid_bit;
int tag;
int time_be_used;
} cache_data;
cache_data **cache_table;
```
* 使用者輸入的 s 表示此 cache table 會有 $2^s$ 組
* 每組底下有 E 行 cache line
* 以動態宣告二維陣列的方式產生 cache table 並進行初始化
```c
int S = 1<<s;
cache_table = malloc(S*sizeof(cache_data *));
for (int i = 0; i < S; i++) {
cache_table[i] = malloc(E*sizeof(cache_data));
}
for (int i = 0; i < S; i++) {
for (int j = 0; j < E; j++) {
cache_table[i][j].valid_bit = 0;
cache_table[i][j].tag = 0;
cache_table[i][j].time_be_used = 0;
}
}
```
### 取得使用者輸入指令、參數 (-v -s -E ...)
* 使用[getopt(3)](https://linux.die.net/man/3/optarg)取得 argv 參數
* getopt 的基礎用法為:```getopt(argc, argv, "hvs:E:b:t:")```
- 第三個參數所代表的是使用者輸入: -h -v -s 等附加指令
- 參數後的冒號(:)表示該指令需要再帶入一參數,如 "s:" 表示實際輸入應為 -s test
- 指令後所帶的參數透過 optarg 取得
```c
char c ;
while((c=getopt(argc, argv, "hvs:E:b:t:")) != -1){
switch(c){
case 'h':
break;
case 'v':
ifprint = true;
break;
case 's':
s = atoi(optarg);
break;
case 'E':
E = atoi(optarg);
break;
case 'b':
b = atoi(optarg);
break;
case 't':
file_name = optarg;
break;
}
}
```
### 讀檔 & 字串處理
* 由於檔案帶有空白符,因此必須使用```fgets```而非```scanf```
* 搭配```strtok```對字串進行切割
- 用法為:```strtok(word, "\n")``` ,第一個參數為要切割的字串,第二個參數是切割的符號,切割的方式是留下切割符號之前的字串
- 透過 ```strtok(NULL, "\n")``` 取得切割符號後的字串
- ```fgets``` 會保留 "\n" 換行符號,因此會先進行切割
- 以 "空白" 將 operation 取出
- 以 "," 將地址、記憶體大小分離
* 需要特別注意的是**將 char 轉換成 16進位整數**
- 使用 ```strtol(buf, NULL, 16)``` 進行處理
```c
char word[50];
FILE *fp = fopen(file_name, "r");
while (fgets(word, 50, fp)){
count++;
if(ifprint)
printf("%s ", strtok(word, "\n"));
/* 處理讀檔內容 */
char *instruction = strtok(word, " ");
char *addr = strtok(NULL, ",");
unsigned int addr_hex = (unsigned int)strtol(addr, NULL, 16);
/* 將16進位地址再次處理 */
parse(s,b,addr_hex);
if(ifprint)
printf(" %d %d %d ", tag, set, offset);
switch(*instruction){
case 'I':
break;
case 'L':
check_cache();
break;
case 'M':
check_cache();
check_cache();
break;
case 'S':
check_cache();
break;
}
if(ifprint)
printf("\n");
}
```
* parse function, 將16進位地址進一步處理
- 可拆解成 \[tag]\[set]\[offset] 三個部分
- offset 為 b 個 bit (使用者輸入 -b 帶的數值)
- set 為 s 個 bit (使用者輸入 -s 帶的數值)
- tag 為剩下的位元,這次一共 32 bits,所以 tag 的位元數為 32-s-t
了解各位元如何區分後以簡單的 bitwise 進行分解
```c
void parse(int s, int b, int var){
unsigned int mask_offset = (1 << b) - 1;
unsigned int mask_set = (1 << (s+b)) - ( 1 << b);
unsigned int mask_tag = ~0 - (mask_offset + mask_set);
tag = (var & mask_tag) >> (s+b);
set = (var & mask_set) >> (b);
offset = var & mask_offset;
}
```
### 檢查 cache table
cache table 檢查只需要依據 set、tag 跟 valid bit 進行判斷即可
* set、tag 皆相同且 valid bit 為 1 表示 hit ,可直接返回
* 非 hit 的情況皆為 miss
* 檢查每個組中所有行的 valid bit,若 valid bit 為 0 則直接將資料搬入該行 cache 並返回;若一組中所有 cache 的 valid bit 都為 1 則比較最近一次的使用時間,紀錄最近最少使用的
- 我們的計算方式以每一個 operation 為一個時間單位,紀錄該 cache 在第幾個時間單位被使用,因此數值愈小表是最近愈少使用。
* 將最近最少使用的 cache 取代
```c
void check_cache(){
for (int i = 0; i < E; i++) {
if(cache_table[set][i].valid_bit == 1 && cache_table[set][i].tag == tag){
cache_table[set][i].time_be_used = count;
hits += 1;
if(ifprint)
printf("hit ");
return;
}
}
misses += 1;
if(ifprint)
printf("miss ");
int n_lru = 0;
for (int i = 0; i < E; i++) {
if(cache_table[set][i].valid_bit == 0){
cache_table[set][i].valid_bit = 1;
cache_table[set][i].tag = tag;
cache_table[set][i].time_be_used = count;
return;
}
else{
if(cache_table[set][n_lru].time_be_used > cache_table[set][i].time_be_used)
n_lru = i;
}
}
evictions += 1;
if(ifprint)
printf("eviction ");
cache_table[set][n_lru].valid_bit = 1;
cache_table[set][n_lru].tag = tag;
cache_table[set][n_lru].time_be_used = count;
}
```
## Part B
### 要求
前情提要:轉置矩陣時會有 cache miss發生,但由於矩陣的記憶體空間是連續的,所以可以運用其 locality優化,降低cache miss。
* 這部分的實驗要求針對 s=5, E=1, b=5 進行優化。
* 要進行轉置的矩陣有 32x32(miss < 300), 64x64(miss < 1300), 61x67(miss < 2000) 三個尺寸。
### 轉置 32x32 矩陣
首先觀察 cache 中每個 block 的大小,我們能算出一個 block(b=5) 有 32 bytes 的空間,能裝得下 8 個 int。於是以每列(row)8 個 int 逐列轉置矩陣。
| |0~| 8~|18~|24~|
|:-:|:-:|:-:|:-:|:-:|
| 0|index1|index2|index3|index4|
| 1|...|...|
| 2|...|...|
| 3|...|||
| 4|...|||
| 5|...|||
| 6|...|||
| 7|...|...|index31|index32|
| 8|...|...|
```shell
yichung@merry:~/git/cache_lab(master 16h36m)$ ./test-trans -M 32 -N 32
Function 0 (2 total)
Step 1: Validating and generating memory traces
Step 2: Evaluating performance (s=5, E=1, b=5)
func 0 (Transpose submission): hits:1710, misses:343, evictions:311
```
但仍無法達到要求,
觀察 trace 檔,發現不斷讀出/存入的過程中,輪流使用 AB 矩陣,容易因為相同的 index (s),產生 cache miss。進一步改良,一次從 A 載入 8 個 int,再一次 8 個存入 B 矩陣。
```shell
yichung@merry:~/git/cache_lab(master 16h39m)$ ./test-trans -M 32 -N 32
Function 0 (2 total)
Step 1: Validating and generating memory traces
Step 2: Evaluating performance (s=5, E=1, b=5)
func 0 (Transpose submission): hits:1766, misses:287, evictions:255
```
成功完成目標。
### 轉置 64x64 矩陣
第一次相同的方式執行,64x64 的矩陣運算 cache miss 飆到不合理的 4611 次。
試著畫出矩陣中每 8 個 int 對應 block 的 index。
ArrayA:
| | 0~| 8~|18~|24~|32~|40~|48~|56~|
|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|
| 0|index1|index2|index3|...|...|...|index7|index8|
| 1|...||
| 2|...|||
| 3|index25|index26|...|...|...|...|index31|index32|
| 4|index1|index2|index3|...|...|...|index7|index8|
| 5|...|||
|...|
試著改為4個4個 int 操作,cache miss 次數下降為 1651。
```shell
yichung@merry:~/git/cache_lab(master 16h36m)$ ./test-trans -M 64 -N 64
Function 0 (2 total)
Step 1: Validating and generating memory traces
Step 2: Evaluating performance (s=5, E=1, b=5)
func 0 (Transpose submission): hits:1710, misses:1651, evictions:311
```
但4個4個操作卻又浪費了,block 空間,試著載入多一點的 int 並操作。但由於是進行矩陣轉置,無法同時對AB兩個矩陣進行優化,一直無法突破。
參考[马天猫Masn的 Cachelab 筆記](https://zhuanlan.zhihu.com/p/28585726)
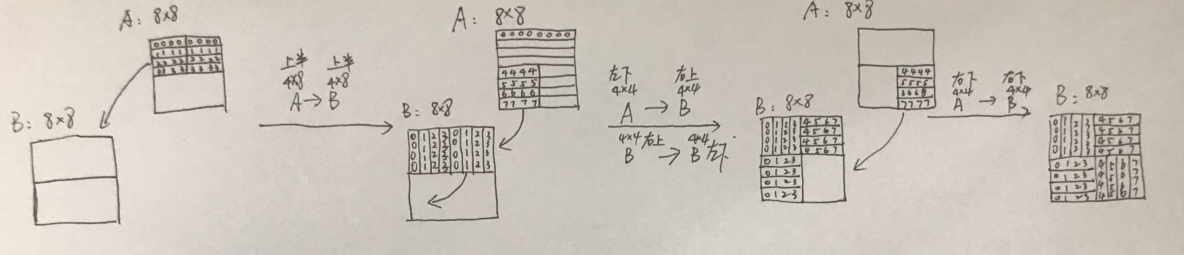
此方式透過時間上的 locality 降低了 cache miss。
中間步驟,A左下角讀出->B右上角讀出->B右上角寫入->B左下角寫入。連續操作B上角的空間,降低了 cache miss。
### 轉置 61x67 矩陣
可以發現這次限制不如前次來得嚴格,先以 32x32 的方式轉置,發現分區轉置能降低 cache miss。
以數種不同大小的分區轉置不規則的 61x67 矩陣,最終在 15. 16 時有最小的 cache miss。