# 2016q3 Homework5 (rubi)
contributed by <`fzzzz`>, <`nekoneko`>, <`abba123`>
###### tags `fzzzz` `nekoneko` `abba123` `sysprog`
## 預期目標
* 閱讀 Dynasm ,了解 bf_dynasm.c
* 學習 JIT 編譯器設計,透過輔助開發工具
* 設計 benchmark suite
* 延展程式語言
## TODO
- [ ]學習 Dynasm ,了解 bf_dynasm.c
- [ ]研讀 rubi 的程式碼
- [ ]參照 jit-compiler ,設計 rubi 的 benchmark ,並解釋為何如此設計
- [ ]試圖最佳化並利用上面的 benchmark suite 來比對解釋
## 資料閱讀
### Dynasm
#### Tutorial
- .arch :
設定產生組語的指令集類型
- dasm_init :
- allocate Dynasm state
```c
|.section code
dasm_init(&d, DASM_MAXSECTION);
```
- .section :
`| .section name1 [, name2 [, ...]]`
允許宣告多個 code section ,宣告的 name 會是新的 directive ==.name== 。之後呼叫 `dasm_encode()` 把所有的 section 合併成單一連續的 machine code block 。
- DASM_MAXSECTION :
- code section 的數量
- Dynasm preprocessor 會根據 .section directive 的描述自動產生 `#define DASM_MAXSECTION 1`
- ex :
bf_dynasm.c 第62行`| .section code` 對應到 第142行 `| .code`
- dasm_setupglobal
```c
|.globals lbl_
void* labels[lbl__MAX];
dasm_setupglobal(&d, labels, lbl__MAX);
```
- | .globals *indent*
經過 Dynasm preprocessor 產生 enum 包含 *indent_MAX*
- void* labels[indent_MAX];
- 用來紀錄 global labels 的位址( address ),紀錄的位址會再呼叫 dasm_link 裡用到。
- After ==dasm_link== has been called, the address of a global label can be retreived by indexing into the array previously passed to ==dasm_setupglobal== using one of the enum members defined by ==.globals==.
- global lables :
格式 : `|->name:`
> 不確定有沒有理解錯誤,附上原文[name=cheng hung lin]
- dasm_setup :
- 初始化 Dynasm state
```c
|.actionlist bf_actions
dasm_setup(&d, bf_actions);
```
- | .actionlist _indent_
- 經過 preprocessor 後產生 static const unsigned char 的陣列,紀錄有用到哪些組語語言。
- The contents of the array reflects the assembly used in the DynASM source file, though in an unspecified format.
- dasm_growpc :
- ~~紀錄 dynamic labels~~ 設定 dynamic lables 可以使用的數字的上限
- dasm_growpc:
呼叫dasm_growpc(dynasm_state, maxpc)後,可使用命名為 0 到 (maxpc-1) 之間的lables,也就是 |=>0 到 |=>(maxpc-1)。
- dynamic labels :
- 格式: `|=>imm32:`
- 跟 global label 類似,差別只在於 dynamic label 只限用非零整數作為命名
- Abstractions :
- .define 和 .macro 將單個或多個 instructions 和 registers 定義成 abstractions
- prologue : ~~建立 stack frame~~ 儲存進入 function 會使用到的 register 的原值到 stack,複製傳近來的參數( rcx )到 aState( r12 )
- prepcall1 arg1 : 儲存 local register ( arg1 )到 stack 並傳遞 arg1
- prepcall2 arg1, arg2 : 儲存 local register ( arg1, arg2 )到並傳遞 arg1, arg2
- postcall n : pop n 個 stack 元素
- epilogue : ~~刪除stack~~ 將進入 function 前register保留的原值,從 stack pop 儲來。並回到 caller 的 address + 1
> 這邊abstractions是bf_dynasm.c裡自訂的,非內建instrucitons。[name=cheng hung lin][color=#1652f7]
> > [prologue 和 epilogue 的概念](https://en.wikipedia.org/wiki/Function_prologue)[name=cheng hung lin]
- .type :
syntex suger,可以使用語法詳閱 [.type](http://corsix.github.io/dynasm-doc/reference.html#_type)
- dasm_State\*\* Dst = &d :
Dynasm preprocessor 產生dasm_put(Dst, int start, ...) ,將所有 verticla bar 的描述轉成 dasm_put 的呼叫
- Arithmetic :
- `| add byte [aPtr], n` :
在對記憶體做存取與運算時,需要決定記憶體單位,例如上述存取的單位為 byte,詳細可參照 [memory](http://corsix.github.io/dynasm-doc/instructions.html#memory)
- Loop:
- 對`[-]`做優化,`while(*p--) ;` 等價於 `*p = 0;`
- loop assembly
```
| cmp byte [aPtr], 0
| jz =>nextpc+1 -------
|=>nextpc: <--- |
... | |
| cmp byte [aPtr], 0 | |
| jnz =>loops[nloops] --- |
|=>loops[nloops]+1: <------
```
- case '[' :
- 假如 code 為 `[-]` ,則代表等價於 `*ptr = 0;`
```
| xor eax, eax // 自己 exclusive-or 自己 為 0
| mov byte [aPtr], al // al 為 exa 裡最右側的word
```
- nextpc 等於 pc:
呼叫 dyn_growpc 增加 dynamic labels 可使用的上限。
- `loops[nloops++] = nextpc;`
用來紀錄 nextpc 的位址,用於讀到`]`才知道跳回去的address
- Epilogue:
```c
| epilogue
link_and_encode(&d);
dasm_free(&d);
return (void(*)(bf_state_t*))labels[lbl_bf_main];
```
- link_and_encode(&d) :
```c=
size_t sz;
void* buf;
dasm_link(d, &sz);
buf = mmap(0, sz, PROT_READ | PROT_WRITE, \
MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
dasm_encode(d, buf);
mprotect(buf, sz, PROT_READ | PROT_EXEC);
return buf;
```
- int dasm_link(Dst_DECL, size_t *szp) :
計算會產生 machine code 的 size
- mmap :
allocate一塊 memory ,可讀可寫但還不可執行
- int dasm_encode(Dst_DECL, void *buffer) :
將 machine code 寫入到 buffer裡,其中紀錄 global labels address 的陣列,也會寫入
- mprotect :
將 buffer 的 memory protection 改為 PROT_EXEC,變為可執行的 memory block
- `return (void(*)(bf_state_t*))labels[lbl_bf_main];`
- labels 是用來紀錄 global labels 的位址,所以這行是還傳 bf_main 函式,讓外部做呼叫 bf_main function call 定傳入型態為 bf_state_t \* 的變數
- 參照`prologue`可以看出傳入的參數為 bf_state_t \*
```
|.macro prologue
| push aPtr
| push aState
| push aTapeBegin
| push aTapeEnd
| push rax
******* | mov aState, rArg1 ****passing argument***
```
- bf_c.c & bf_dynasm.c
- ~~brainfuck 語言的實做是 Turing Machine~~ brainfxck 是一個符合 turing completeness 的程式語言,ptr所指向的記憶體在本程式中是有限的,定義在 `bf_state_t bf_state` ,記憶體size則定義在 `#define TAPE_SIZE 30000` 。另外,bf_state_t還包含兩個 pointer to function 實做對 tape 記憶體讀取和寫入。
> 這邊第一句中文怪怪的, 改成 brainfxck 是一個符合 turing completeness 的程式語言感覺會更好點(Turing completeness is the ability for a system of instructions to simulate a Turing machine.)。[name=fzzzz]
```c=4
#define TAPE_SIZE 30000
```
```c=7
typedef struct bf_state
{
unsigned char* tape;
unsigned char (*get_ch)(struct bf_state*);
void (*put_ch)(struct bf_state*, unsigned char);
} bf_state_t;
```
- bf_interpret 裡宣告的`tape_begin 和 tape_end`是為了在`>`和`<`中對記體位置移動時,做超出邊界的判斷。
```c=22
unsigned char* tape_begin = state->tape - 1;
```
```c=27
case '<':
for(n = 1; *program == '<'; ++n, ++program);
if(!nskip) {
ptr -= n;
while(ptr <= tape_begin)
ptr += TAPE_SIZE;
}
break;
```
- tape 示意圖

### Interpreter, Compiler, JIT
* Interpreter
* 直接轉譯並執行程式,不經過編譯的步驟
* 不會一次看完程式整體
* Compiler
* 將高階語言編譯成組合語言
* 相較於JIT,編譯時會輸出成檔
* Just-In-Time Compiler
* 每次執行時都會重新進行編譯成機器碼,但不會輸出成檔。
* 相較於 interpreter ,因其會看到程式整體,所以能做的最佳化也會比較多
## 研讀 rubi 程式碼
#### lex
- 在 rubi.h 檔有宣告一個 structure "tok"
```c=10
typedef struct { char val[32]; int nline; } Token;
struct {
Token *tok;
int size, pos;
} tok;
```
Token 用來紀錄 toke 所在的行號與內容
- tok.size 和 tok.pos 初始化在 engine.c 裡的 init()
```c=28
void init()
{
tok.pos = 0;
tok.size = 0xfff;
set_xor128();
tok.tok = calloc(sizeof(Token), tok.size);
brks.addr = calloc(sizeof(uint32_t), 1);
rets.addr = calloc(sizeof(uint32_t), 1);
}
```
- tok 的賦值在 lex.c 裡的 lex(char \*)
- lex(char \*)
- 讀入 number
- 讀入 ident ,指的是像變數名稱或是函式名稱等。變數命名上支援字母開頭,中間可夾雜數字和 "\_"
- skip whitespace and tab
- skip comment
- 讀入 string ,若在兩個 " 之間出現 `\0`,則會有語意分析錯誤
- 換行符號,`\n` 或 `\r\n`,會以 `;` 的 tok val 來記錄
- 其餘 :
- 支援以上除外的單元符號
- 支援部份雙元符號 : `\*=`, `++`, `--`。其中第一個`*`表示任何符號,像是 `+=`, `-=` 等等之類
- engine.c 裡的 dispose() 會將配置給tok的記憶體釋放
#### parser
如果有觀察一下程式碼,可以發現在跑完 parser 的同時就整個編譯過程就結束了,所以我們要關注的點是 parser.dasc 這份檔案
(當然還有 codegen.c , 但因為他是由執行 ./minilua dynasm.lua 所產生的,所以在這裡先不討論)
Q: parser 是在幹嘛的?
parsing 是對輸入做語法分析( semantic/syntax analyze ),看是否合乎程式語言規範的一項步驟
:::info
程式在編譯時會經歷以下幾個步驟
* lexical analyzer -> Syntax/Sematic Analyzer(Parser) -> Intermediate-code Generator
但在這份實作裡,因為是使用 Dynasm 做code generation 的部份,所以 parser 裡就有指示 Dynasm 怎麼去做 code generation 了
:::
直接看程式碼
```C
int (*parser())(int *, void **)
{
jit_init();
tok.pos = 0;
strings.addr = calloc(0xFF, sizeof(int32_t));
main_address
dasm_growpc(&d, npc);
|->START:
| jmp =>main_address
eval(0, 0);
for (int i = 0; i < strings.count; ++i)
replaceEscape(strings.text[i]);
uint8_t* buf = (uint8_t*)jit_finalize();
for (int i = 0; i < functions.count; i++)
*(int*)(buf + dasm_getpclabel(&d, functions.func[i].espBgn) - 4) = (locVar.size[i+1] + 6)*4;
dasm_free(&d);
return ((int (*)(int *, void **))rubilabels[L_START]);
}
```
這段程式碼位於 parser.dasc 中,其作用是 parsing 的主體(廢話XD
```C
jit_init();
```
jit 的起始
初始化 dsm_state 並設置一些全域的東西
( labels , actions , 詳情可見上方的 dynasm 研讀部份 )
```C
jit_finalize();
```
jit 的尾端
link 然後把要用的機械碼利用 mmap() 放入我們執行時期要用到的記憶體
然後將值寫入 mmap() 的區塊。
```C
for (int i = 0; i < functions.count; i++)
*(int*)(buf + dasm_getpclabel(&d, functions.func[i].espBgn) - 4) = (locVar.size[i+1] + 6)*4;
```
知道了 jit 的頭跟尾後,再來看看那邊是負責 parse 的地方
```C
eval(0,0);
```
最後回傳剛剛建置完的程式的起始點
```C
return ((int (*)(int *, void **))rubilabels[L_START]);
```
### x86 Assembly
參考資料來自[x86 Assembly Guide](http://www.cs.virginia.edu/~evans/cs216/guides/x86.html)
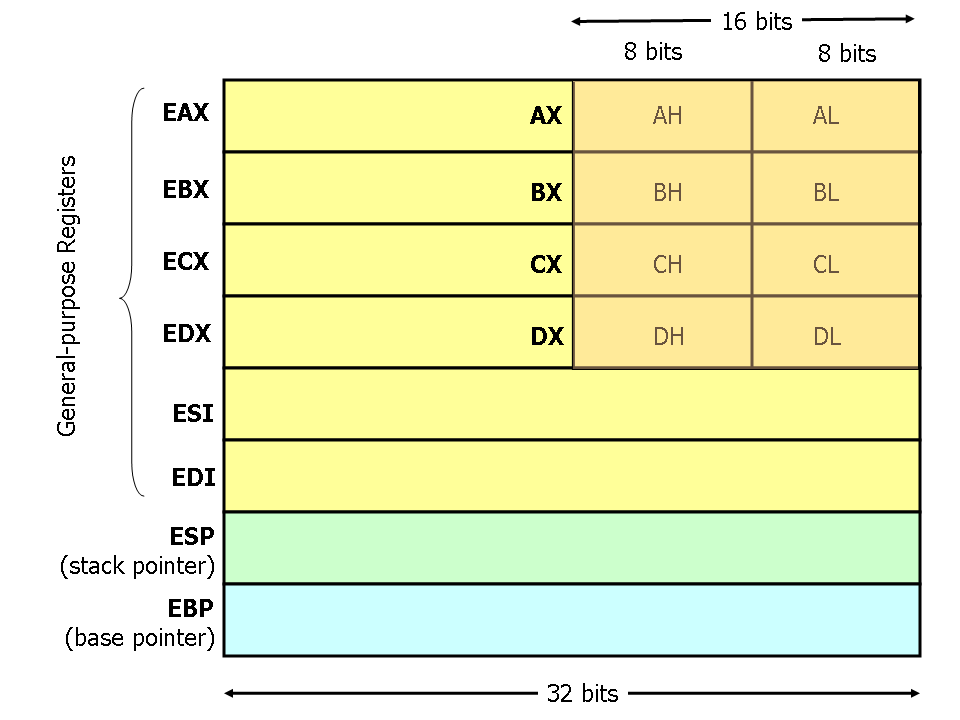
* special purposes register — stack pointer (ESP) and base pointer (EBP).
* base pointer - The base pointer is used by convention as a point of reference for finding parameters and local variables on the stack.
* push — Push stack
* usage : push target — push target onto stack.
* pop — Pop stack
* usage : pop dst. — pop the top element of the stack into dst.
因為 general-purpose register 有限( eax , ebx , ecx , edx ),所以當我們需要更多的 register 時,會把之前的 register 內的值, push 上去 stack,需要的時候再 pop 出來即可。(詳情請看參考資料的 Callee Rules )
```=298
|=>func_addr:
| push ebp
| mov ebp, esp
```
挪出空間給 local variable,並定義 func_esp 的 label
```=302
| sub esp, 0x80000000
|=>func_esp:
```
> 這裡不懂為什麼要用 func_esp ,會跳到這裡嗎?
接著將 arguments 存入我們剛剛開的空間
```C=304
for(int i = 0; i < argsc; i++) {
| mov eax, [ebp + ((argsc - i - 1) * sizeof(int32_t) + 8)]
| mov [ebp - (i + 2)*4], eax
}
```
### Code Refactoring
發現TODO!!
```C=536
else if ((inc = skip("++")) || (dec = skip("--"))) {
// TODOs
```
但發現實際上執行時不會跑到這裡,所以這裡算是 dead code => 砍掉!
### benchmark

### 其他
- 在`~/.vimrc`設定 *.dasc 為 C type file ,使其支援 C 的 syntax highlight
```
" associate *.dasc with c filetype
au BufRead,BufNewFile *.dasc set filetype=c
```
- 沒有做 function without end 的handling
```Ruby
def func
return 1
```
> 會 segmentation fault(core dumped)[name=fzzzz]
### References
[Interpreter, Compiler, JIT](http://nickdesaulniers.github.io/blog/2015/05/25/interpreter-compiler-jit/)
[林郁寧共筆](https://embedded2015.hackpad.com/-Homework4-B-h5FfVE6RTeu)
[x86 Assembly Guide](http://www.cs.virginia.edu/~evans/cs216/guides/x86.html)