# 2018q3 Homework3 (dict)
###### tags: `GOGOGOGOGOGOG`
# 作業目標
* 在 GitHub 上 fork [dict](https://github.com/sysprog21/dict),研讀並修改 `Makefile` 以允許 `$ make plot` 時,視覺化 ternary search tree + bloom filter 的效能表現。注意,需要設計實驗,允許不同的字串輸入並探討 TST 回應的統計分佈
* 要考慮到 prefix search 的特性還有詞彙的涵蓋率
* 限用 gnuplot 來製圖
* 參閱 [Hash Table Benchmarks](http://incise.org/hash-table-benchmarks.html)
* 以 perf 分析 TST 程式碼的執行時期行為並且充分解讀
* 考慮到 CPY 和 REF 這兩種實作機制,思考效能落差的緣故,並且提出後續效能改善機制
* 充分量化並以現代處理器架構的行為解讀
* 注意:這兩者都該加入 Bloom filter,而且分析具體效益 (原有程式存在若干缺陷,也該指出並修正)
## 事前準備
- 首先先將perf進行安裝,輸入`sudo apt-get install linux-tools-common `系統便會開始自行安裝,但要注意的點是安裝的檔案版本不同的問題,老師所給的指令`$ sudo apt-get install linux-tools-3.16.0-50-generic linux-cloud-tools-3.16.0-50-generic `其版本不一定適用於每個人,需要根據提示字元進行安裝。
- 由於這次需要自行設定makefile所以需要開啟權限,透過指令` sudo sh -c " echo -1 >/proc/sys/kernel/perf_event_paranoid" ` 來開啟權限。
- 可以參考這篇 https://hackmd.io/s/Skwp-alOg# 非常詳盡的解說了gnuplot的使用,但這次作業scripts已經都寫好了,需要更改的部份不多。
- 關於如何編譯Makefile: https://hackmd.io/c/rJKbX1pFZ/https%3A%2F%2Fhackmd.io%2Fs%2FSySTMXPv
# 了解Trie和Ternary search tree (TST)
## Trie
Trie ,又叫做前綴樹或是字典樹,是一個動態配置或關聯性配置的資料結構,用來保存關聯數組,常用在 string。 而當運用在 string 時, Trie 中每個節點由一個字元組成。
* Trie樹的基本性質可以歸納為:
* 根節點不包含字元,除了根節點外的每個節點只包含一個字元。
* 從根節點到某一個節點,路徑上經過的字符連接起來,為該節點對應的字符串。
* 每個節點的所有子節點都有相同的前綴字串。
* 不是所有的節點都有對應的值,只有葉子節點和部分內部節點所對應的 key 才有相關的值。
* Trie 的應用: 主要在 bioinformatics , information retrieval
## Ternary Search Tree (TST) 介紹
Trie 樹的結構,它的實現簡單但空間效率低。如果要支持26個英文字母,每個節點就要保存26個指針,假如還要加入標點符號、區分大小寫,內存用量就會急劇上升,以至於不可行。
因為 trie 的節點數組中保存的空指針,佔用了太多內存,因此考慮改用其他數據結構去代替,像是用 hash map。但是管理成千上萬個 hash map 不是什麼好主意,而且它還會使數據的相對順序信息丟失,所以使用 Ternary Tree 替代 trie。
* Binary Search Tree 查詢與建表時間是 O(log2n),但是在最糟的情況下時間複雜度可能轉為 O(n),除了要儲存的字串外不須另外分配空間。
* Trie 的時間複雜度是 O(n),能夠實現前者難以做到的 prefix-search,缺點是會有大量的空指針表,造成空間開銷過大。
* Ternary Search Tree,是一種 trie(亦稱 prefix-tree) 的結構,並且它結合字典樹的時間效率和 BST 的空間效率優點。
* 每個節點 (Node) 最多有三個子分支,以及一個 Key
* Key 用來記錄 Keys 中的其中一個字元 (包括 EndOfString)。
* low :用來指向比當前的 Node 的 Key 小 的 Node。
* equal :用來指向與當前的 Node 的 Key 一樣大 的 Node。
* high :用來指向比當前的 Node 的 Key 大 的 Node。
* Ternary Search Tree 的應用:
* spell check: Ternary Search Tree 可以當作字典來存儲所有的單詞。一旦在編輯器中輸入單詞,可以在Ternary Search Tree中並行搜索單詞以檢查正確的拼寫。
* Auto-completion: 使用搜索引擎進行搜索時,它會提供自動完成(Auto-complete)功能,讓用戶更加容易查找到相關的信息;假如:我們在Google中輸入ternar,它會提示與ternar的相關搜索信息。
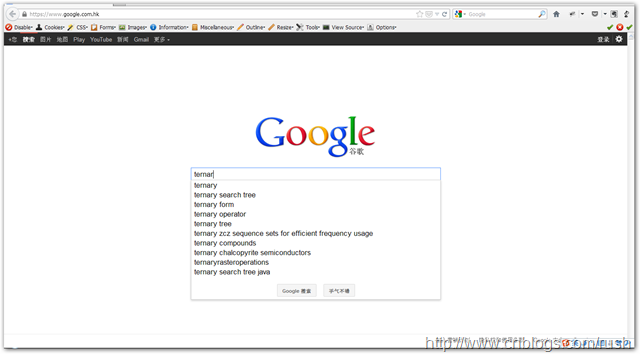
Google根據我們的輸入ternar,提示了ternary,ternary search tree等等搜索信息,自動完成(Auto-complete)功能的實現的核心思想三叉搜索樹。
對於Web應用程序來說,自動完成(Auto-complete)的繁重處理工作絕大部分要交給服務器去完成。很多時候,自動完成(Auto-complete)的備選項數目巨大,不適宜一下子全都下載到客戶端。相反,三叉樹搜索是保存在服務器上的,客戶端把用戶已經輸入的單詞前綴送到服務器上作查詢,然後服務器根據三叉搜索樹算法獲取相應數據列表,最後把候選的數據列表返回給客戶端。
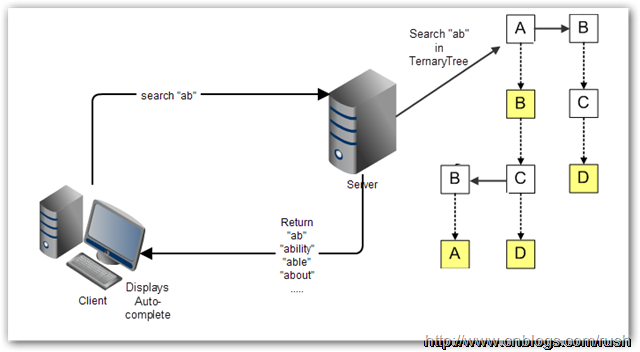
reference: [Ternary Search Tree 的應用]
(http://www.cnblogs.com/rush/archive/2012/12/30/2839996.html)
## TST的實作程式碼:
首先一樣的fork本次的作業,並且進行`git clone https://github.com/GOGOGOGOGOGOG/dict.git `但要注意的點是本次作業除了要`git init ` 以外,需要先安裝pref等等套件才可以執行。
- 了解Makefile:
```
TESTS = test_cpy test_ref
TEST_DATA = s Calva
CFLAGS = -O0 -Wall -Werror -g
...
test: $(TESTS)
echo 3 | sudo tee /proc/sys/vm/drop_caches;
perf stat --repeat 100 \
-e cache-misses,cache-references,instructions,cycles \
./test_cpy --bench $(TEST_DATA)
perf stat --repeat 100 \
-e cache-misses,cache-references,instructions,cycles \
./test_ref --bench $(TEST_DATA)
bench: $(TESTS)
@for test in $(TESTS); do\
./$$test --bench $(TEST_DATA); \
done
output.txt: test calculate
./calculate
plot: output.txt bench_cpy.txt bench_ref.txt
gnuplot scripts/runtime.gp
eog runtime.png
gnuplot scripts/runtime3.gp
eog runtime3.png
gnuplot scripts/runtimept.gp
eog runtime2.png
calculate: calculate.c
$(CC) $(CFLAGS_common) $^ -o $@
clean:
$(RM) $(TESTS) $(OBJS)
$(RM) $(deps)
rm -f bench_cpy.txt bench_ref.txt ref.txt cpy.txt output.txt caculate
-include $(deps)
```
前半部份為:
* `TESTS ` 是進行test_cpy和test_ref的程式碼,也就是進行make後的所產生的執行碼。
* `TEST_DATA `測試的字串,原本為 Tai 但未來滿足作業需求進行實驗,我改成了Calva,下面會解釋實驗流程。
* `CFLAGS` 代表 `GCC` 編譯時用的參數。
* 後半部份的`TEST `輸入 `make test` 會使用 `pref` 去測試 `test_cpy` 和 `test_ref` 總共會測試100次。
* `make bench` 則會對兩個執行檔 `test_cpy` 和 `test_ref` 進行檢測。
* `make clean `會對執行檔和txt檔進行清除。
### make plot的執行與建構:
- 在著手進行`make plot `之前我們必須先整理清楚各個GNU的.gp檔所需要的內容是什麼,例如:runtime.gp 是需要`output.txt` 而 runtime3.gp 則是需要`test_cpy.txt `等等.....
( 關於如何生成`bench_cpy.txt ` `bench_ref.txt ` `ref.txt ` `cpy.txt ` `output.txt `我會在後面的bug標題進行說明。)
### `plot`
```clike=
plot: output.txt bench_cpy.txt bench_ref.txt
gnuplot scripts/runtime.gp
eog runtime.png
gnuplot scripts/runtime3.gp
eog runtime3.png
gnuplot scripts/runtimept.gp
eog runtime2.png
```
在第一行中代表的是輸入plot指令後需要的檔案,分別為`bench_cpy.txt ` `bench_ref.txt `和 `output.txt `而指令 `gnuplot scripts/runtime.gp ` 則是執行gnuplot該gp檔的程序,`eog runtime.png `則是顯示圖形。執行畫面如下:
首先鍵入指令`make plot `後,輸入完密碼開始進行檢測並紀錄執行時間。

執行完成後會產生三張圖形:分別是cpy和ref的執行時間比;cpy的搜尋效率;ref和cpy的搜尋效率對照,如圖:



## 字串實驗的實現與紀錄
本次作業的要求:
視覺化 ternary search tree + bloom filter 的效能表現。注意,需要設計實驗,允許不同的字串輸入並探討 TST 回應的統計分佈。於是我做了以下實驗,其得到的結果是:ref的執行效率低於cpy並且會隨著輸入字串的增加越來越明顯,如同我上述所提到的我將測試的字串改為`Calva `但其實我一開始是從字串`C `開始進行實驗然後再逐一增加字串數量,例如增加為`Ca ` 等等...測試的結果如下

增加為Ca

增加為Cal

增加為Calv

增加為Calva

可以發現雙方的執行時間從0.38秒的差距拉開到0.47秒,可知ref和cpy的效率的確是差了一些。
:::warning
探討造成此現象可能的原因?
:::
:::info
10/15 將runtime.gp作修改:
```go=
reset
set ylabel 'time(sec)'
set style fill solid
set key center top
set title 'perfomance comparison'
set term png enhanced font 'Verdana,10'
set output 'runtime.png'
plot [:][y=0:5.000]'output.txt' using 2:xtic(1) with histogram title 'cpy', \
'' using 3:xtic(1) with histogram title 'ref' , \
'' using ($0-0.500):(0.110):2 with labels title ' ' textcolor lt 1, \
'' using ($0-0.500):(0.320):3 with labels title ' ' textcolor lt 2,
```
:::
## Bug的問題與解決:
首先比較容易發現的bug在test_cpy.c和test_ref.c之間的差異,執行完程式碼後會發現無法生成ref的文字檔,其原因是在於test_ref.c中程式碼少了輸出txt檔的程式碼:如下:
```clike=
if (argc == 2 && strcmp(argv[1], "--bench1") == 0) {
int stat = bench_test(root, BENCH_TEST_FILE, LMAX);
tst_free_all(root);
return stat;
}
FILE *output;
output = fopen("ref.txt", "a");
if (output != NULL) {
fprintf(output, "%.6f\n", t2 - t1);
fclose(output);
} else
printf("open file error\n");
```
將此程式碼輸入後即可產生`bench_ref.txt ` 除此之外也要記得執行calculate.c檔來產生`output.txt `
不過最讓我好奇的還是:
## 尋找 search "A" 發生 Segfault 的原因
如圖:
會發現在輸入A後會出現segfault的狀況,後來發現其問題是出在 tst.c檔中:
```C=317
void tst_suggest(const tst_node *p,
const char c,
const size_t nchr,
char **a,
int *n,
const int max)
{
if (!p || *n == max)
return;
tst_suggest(p->lokid, c, nchr, a, n, max);
if (p->key)
tst_suggest(p->eqkid, c, nchr, a, n, max);
else if (*(((char *) p->eqkid) + nchr - 1) == c)
a[(*n)++] = (char *) p->eqkid;
tst_suggest(p->hikid, c, nchr, a, n, max);
}
```
參考了:(https://hackmd.io/nLSb34t0SE2V-56Gxi7ErA?both# )之後才發現原來是因為,*n不斷的滿足條件進入遞迴(return)當進行到330行時,程式早已經不符合原來的設定了,*n的持續增加會造成存取到不正確的記憶體。需要將程式修改成:
```clike=
else if (*(((char *) p->eqkid) + nchr - 1) == c && *n != max)
```
即可修復這個bug。
:::info
### 10/16 新增關於輸入功能cpy和ref之間的效率比較
- 修改runtimebox裡的gp內容,如下:
```clike
reset
set xlabel 'test'
set ylabel 'time(microsec)'
set title 'perfomance comparison(add)'
set term png enhanced font 'Verdana,10'
set output 'addruntime.png'
set format x "%10.0f"
set xtic 10
set xtics rotate by 45 right
plot [:300][:]'cpy.txt' title 'cpy_ add',\
'ref.txt' title 'ref_ add'
```
- 圖形顯示

可以看到cpy和ref在輸入功能中仍舊是cpy的速度較快,其中原因我想也來自於cpy和ref存取的方式不同,前者是用TST不過後者是用bloom filter,但關於本次作業要求要兩個都加入bloom filter還是不懂。
10/17更新: ref還使用了bloom filter去搜尋字串所以可能是因為這樣,在時間上才會高於cpy。
:::
## 關於coredumped的問題
:::warning
~~時間不夠待補上~~ 對ref進行perf分析時,會導致coredumped,如圖:

:::
:question: 為什麼執行perf會導致test_ref coredumped呢?是不是內部還有bug?待用gdb去做檢測。
# Linux perf效能分析


:::info
10/19更新:
在test_cpy新增bloom_filter進行測試:
```clike=
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <time.h>
#include "bloom.h"
#include "bench.c"
#include "tst.h"
/** constants insert, delete, max word(s) & stack nodes */
enum { INS, DEL, WRDMAX = 256, STKMAX = 512, LMAX = 1024 };
#define REF INS
#define CPY DEL
long poolsize = 2000000 * WRDMAX;
#define BENCH_TEST_FILE "bench_cpy.txt"
#define TableSize 5000000
/* simple trim '\n' from end of buffer filled by fgets */
static void rmcrlf(char *s)
{
size_t len = strlen(s);
if (len && s[len - 1] == '\n')
s[--len] = 0;
}
#define IN_FILE "cities.txt"
int main(int argc, char **argv)
{
char word[WRDMAX] = "";
char *sgl[LMAX] = {NULL};
tst_node *root = NULL, *res = NULL;
int rtn = 0, idx = 0, sidx = 0;
FILE *fp = fopen(IN_FILE, "r");
double t1, t2;
if (!fp) { /* prompt, open, validate file for reading */
fprintf(stderr, "error: file open failed '%s'.\n", argv[1]);
return 1;
}
t1 = tvgetf();
bloom_t bloom = bloom_create(TableSize);
/* memory pool */
char *pool = (char *) malloc(poolsize * sizeof(char));
char *Top = pool;
while ((rtn = fscanf(fp, "%s", Top)) != EOF) {
char *p = Top;
/* insert reference to each string */
if (!tst_ins_del(&root, &p, INS, REF)) { /* fail to insert */
fprintf(stderr, "error: memory exhausted, tst_insert.\n");
fclose(fp);
return 1;
} else { /* update bloom filter */
bloom_add(bloom, Top);
}
idx++;
Top += (strlen(Top) + 1);
// break;
}
t2 = tvgetf();
fclose(fp);
printf("ternary_tree, loaded %d words in %.6f sec\n", idx, t2 - t1);
```
後來經過討論後,發現原來 test_ref是代表tst加上bloom_filter,而test_cpy則是只有tst而已,而在之前的圖形中,之所以ref需要的時間會比cpy還的長的原因是因為bloom_filter需要建立還有更新的時間,再兩者都加入bloom_filter後所產生的搜尋圖形和新增圖形之比較如下:

由上圖可知,兩者所需的時間是差不多的。

:::
:::info
提問:

上面的圖形是關於新增功能的比較,但不太清楚過程中的波動是因為什麼原因造成的?
:::