# 以 Linux 為分析對象
## 實驗和統計的重要

* [ [source](https://plus.google.com/+StevenVaughanNichols/posts/M6xFE8h3eqk) ]

* [ [source](https://www.facebook.com/photo.php?fbid=1686757911542493&set=a.1686757751542509.1073741928.100006249004357&type=1&theater) ]
**「Process 和 Thread 有什麼差異?」**
大部份的學生很快就可以「背誦」作業系統課程給予的「心法」,回答一長串,可是,其中多少人「看過」Process 和 Thread 呢?多少人知道這兩者怎麼實做出來?又,為何當初電腦科學家和工程師會提出這兩個概念呢?
書本說 thread 建立比 process 快,但你知道快多少?是不是每次都會快?然後這兩者的 context switch 成本為何?又,在 SMP 中,是否會得到一致的行為呢?
之前選修課程的學生透過一系列的實驗,藉由統計來「看到」process 與 thread。物理學家如何「看到」微觀的世界呢?當然不是透過顯微鏡,因為整個尺度已經太小了。統計物理學 (statistical physics) 指的是根據物質微觀夠以及微觀粒子相互作用的認知,藉由統計的方法,對大量粒子組成的物理特性和巨觀規律,做出微觀解釋的理論物理分支。今天我們要「看到」context switch, interrupt latency, jitter, ... 無一不透過統計學!
* [Solving Problems at Google Using Computational Thinking](https://www.youtube.com/watch?v=SVVB5RQfYxk) (video)
<div>
## 以 Linux 為分析對象
**[ [Thread & Synchronization](http://wiki.csie.ncku.edu.tw/embedded/2015q1w9/thread-sync.pdf) ]**
* Shared Code and Reentrancy
* [reentrancy](https://en.wikipedia.org/wiki/Reentrancy_(computing)) 會造成問題的案例: strtok()
* 解決辦法: strtok_r()
* newlib 實做:
* [strtok](https://github.com/eblot/newlib/blob/master/newlib/libc/string/strtok.c)
* [strtok_r](https://github.com/eblot/newlib/blob/master/newlib/libc/string/strtok_r.c)
* 沒有全域變數
* 有個工作區,去保存變數
```C=
char *
_DEFUN (strtok_r, (s, delim, lasts),
register char *s _AND
register const char *delim _AND
char **lasts)
{
return __strtok_r (s, delim, lasts, 1);
}
```
* Use condition variables to atomically block threads until a particular condition is true.
* Always use condition variables together with a mutex lock
* Mutex in Linux: Various implementations for performance/function tradeoffs
* Speed or correctness (deadlock detection)
* lock the same mutex multiple times
* priority-based and priority inversion
* forget to unlock or terminate unexpectedly
* [Priority Inversion on Mars](http://www.slideshare.net/jserv/priority-inversion-30367388)
* FUTEX (fast mutex)
* Lightweight and scalable
* In the noncontended case can be acquired/released from userspace without having to enter the kernel.
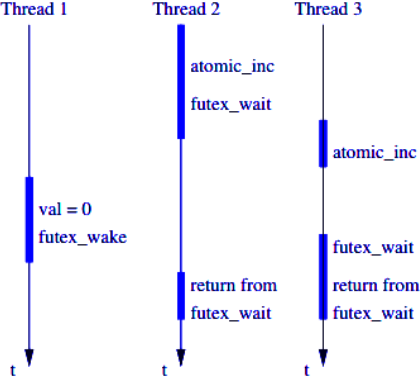
* invoke `sys_futex` only when there is a need to use futex queue
* need atomic operations in user space
* race condition: atomic update of unlock and system call are not atomic
* Kernel preemption
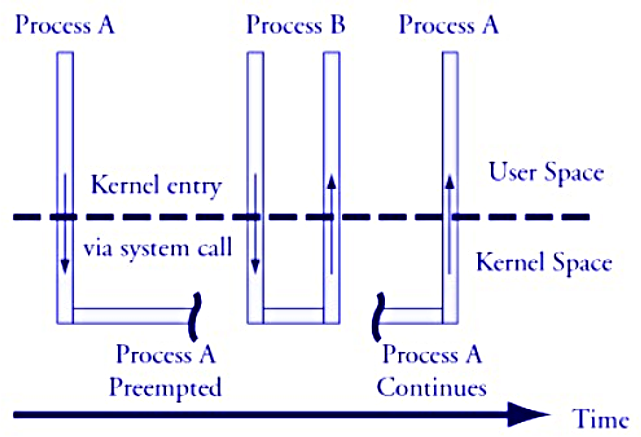
* a process running in kernel mode can be replaced by another process while in the middle of a kernel function
* process B may be waked up by a timer and with higher priority
* 考量點: 降低 dispatch latency
* Linux kernel thread
```C
static struct task_struct *tsk;
static int thread_function(void *data)
{
int time_count = 0;
do {
printk(KERN_INFO "thread_function: %d times", ++time_count);
msleep(1000);
} while(!kthread_should_stop() && time_count<=30);
return time_count;
}
static int hello_init(void)
{
tsk = kthread_run(thread_function, NULL, "mythread%d", 1);
if (IS_ERR(tsk)) { …. }
}
```
* Work Queue
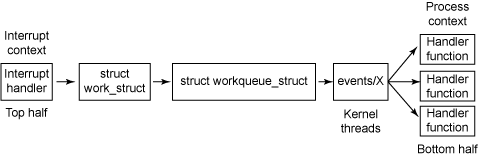
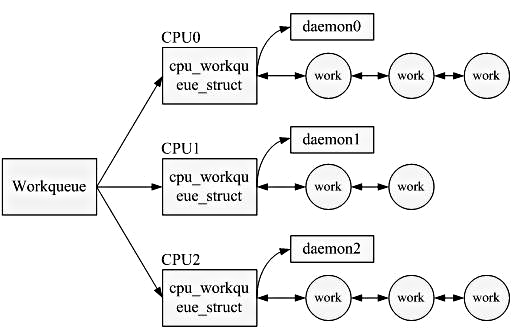
* tasklets execute quickly, for a short period of time, and in atomic mode
* workqueue functions may have higher latency but need not be atomic
* Run in the context of a special kernel process (worker thread)
* more flexibility and workqueue functions can sleep.
* they are allowed to block (unlike deferred routines)
* No access to user space
* Atomic Operations
* provide instructions that are:
* executable atomically;
* without interruption
* Not possible for two atomic operations by a single CPU to occur concurrently
* ARM: SWP (早期); LDREX/STREX (ARMv6+) [ [source](http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.faqs/14979.html) ]
* support multi-master systems, for example, systems with multiple cores or systems with other bus masters such as a DMA controller.
* Their primary purpose is to maintain the integrity of shared data structures during inter-master communication by preventing two masters making conflicting accesses at the same time, i.e., synchronization of shared memory.
* Spinlock
* 作用: Ensuring mutual exclusion using a busy-wait lock
* really only useful in SMP systems
* Spinlock with local CPU interrupt disable
```C
spin_lock_irqsave(&my_spinlock, flags);
/* critical section */
spin_unlock_irqrestore(&my_spinlock, flags);
```
* Reader/writer spinlock (存在效能議題,近年許多替代方案被提出)
* Semaphore
* blocked thread can be in TASK_UNINTERRUPTIBLE or TASK_INTERRUPTIBLE (by timer or signal)
* 之後探討 real-time Linux 時,這部份會重新分析
* Blocking Mechanism
* ISR can wake up a block kernel thread which is waiting for the arrival of an event
* Wait queue
* [wait_for_completion_timeout](http://lxr.free-electrons.com/source/kernel/sched/completion.c)
* specify "completion" condition, timeout period, and action at timeout
* "complete" to wake up thread in wait queue
* wake-one or wake-many
* Reader/Writer
* 這部份**很重要**,下個月繼續探討
**[ [Process Management](http://wiki.csie.ncku.edu.tw/embedded/ProcessManagement.pdf) ]**
* Scheduling
* Find the **_next suitable_** process/task to run
* Context switch
* Store the context of the current process, restore the context of the next process
* Process context + interrupt context
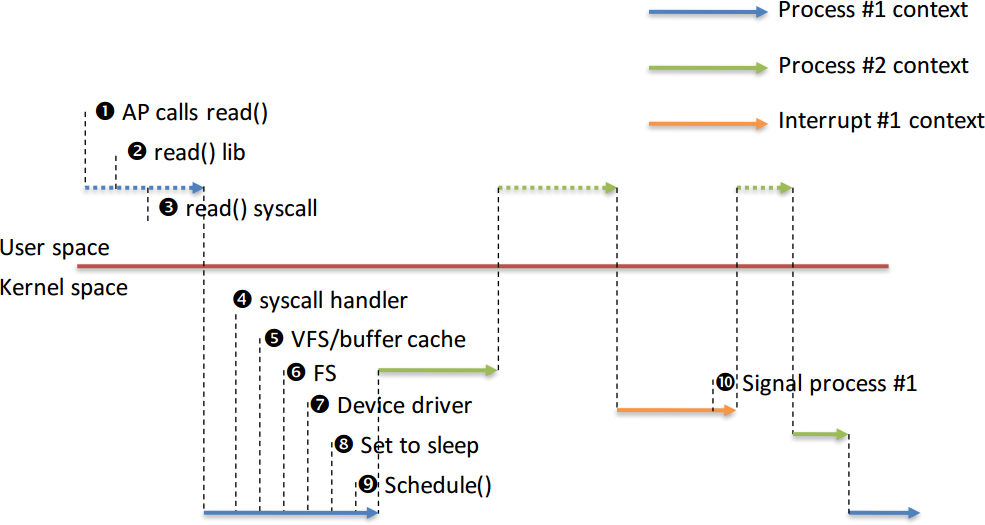
* Linux kernel is possible to preempt a task at any point, so long as the kernel does not hold a lock
* Kernel can be interrupted ≠ kernel is preemptive
* Non‐preemptive kernel, interrupt returns to interrupted process
* Preemptive kernel, interrupt returns to any schedulable process
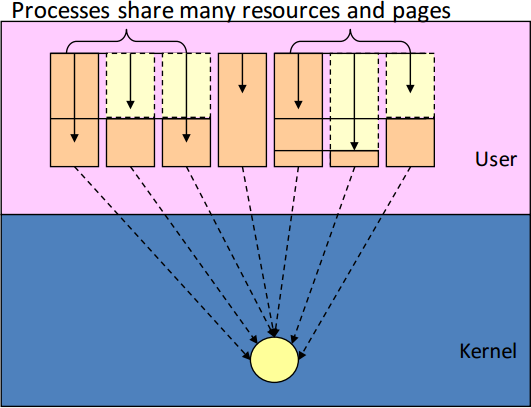
* [ Page 48 - 51 ] Process vs. Thread
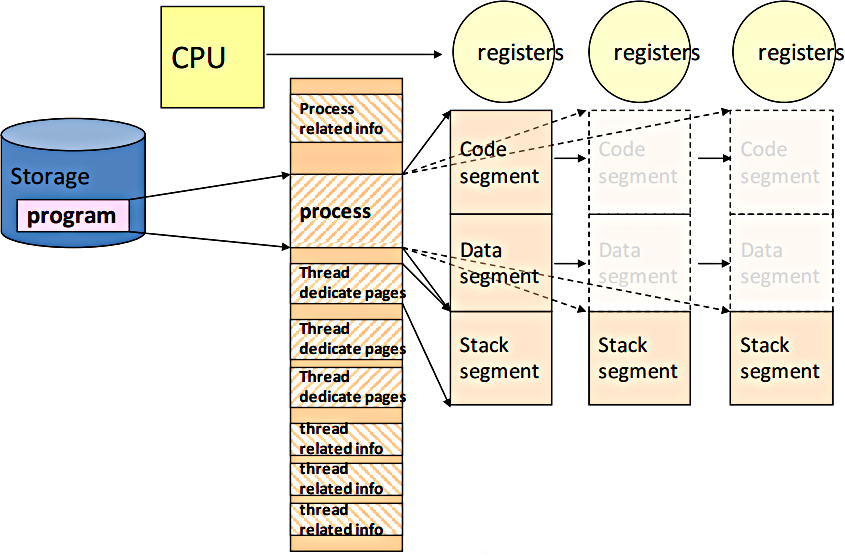
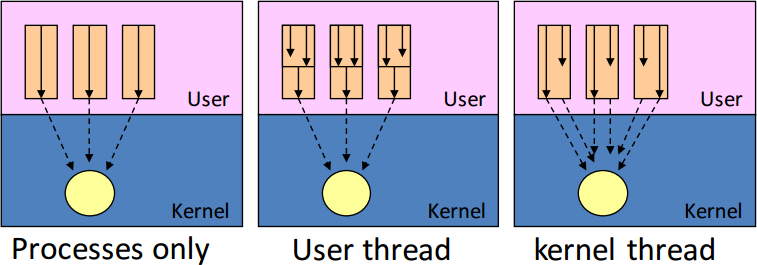
* (和作業系統和計算機組織結構的設計有極大的落差)
* Scheduling simulation
* [LinSched: Simulating the Linux Scheduler in user space](http://www.ibm.com/developerworks/library/l-linux-scheduler-simulator/)
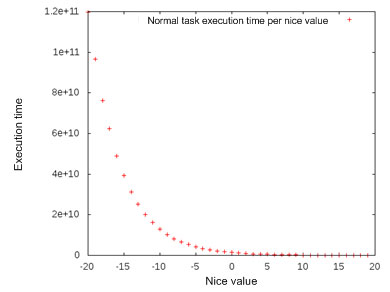
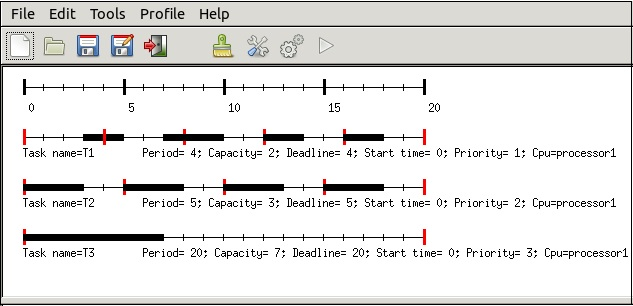
* [Cheddar project : real-time scheduling analyzer](http://beru.univ-brest.fr/~singhoff/cheddar/)
對照 2015 年選修課程學生的 [ARM-Linux 技術報告](http://wiki.csie.ncku.edu.tw/embedded/arm-linux)
- [ ] ==[Concurrency in The Linux Kernel](https://hackmd.io/s/Hy9JyrBw)==
## ARM + Multitasking
**[ [Build A Minimal OS Kernel for](http://wiki.csie.ncku.edu.tw/embedded/summer2015/mini-arm-os.pdf)[k](http://wiki.csie.ncku.edu.tw/embedded/summer2015/mini-arm-os.pdf)[ ARM](http://wiki.csie.ncku.edu.tw/embedded/summer2015/mini-arm-os.pdf) ]**
**[ [STM32 程式開發:以 GNU Toolchain 為例](https://docs.google.com/document/d/1Ygl6cEGPXUffhTJE0K6B8zEtGmIuIdCjlZBkFlijUaE/edit) ]**
**[ [Build minimal ARM Kernel from Scratch](https://embedded2015.hackpad.com/Build-minimal-ARM-Kernel-from-Scratch-uudMy6PqXcj) ]**
* UART 概念
* [USART](http://wiki.csie.ncku.edu.tw/embedded/USART) (最詳盡的中文資訊)
* mini-arm-os 裡面 [USART 驅動說明](https://embedded2015.hackpad.com/Week7Week-8-eifNIs0bjEF)
* [USART interrupt 的行為](http://wiki.csie.ncku.edu.tw/embedded/2015q1w7)
* mini-arm-os 中,[改用 PLL 作為 SYSCLK source](https://embedded2015.hackpad.com/fV9s38DkLRB)