owned this note
owned this note
Published
Linked with GitHub
# Brainstorming SAFE Network FUSE filesystem
###### tags: `filesystem` `fuse`
Nothing is all figured out here. This is a brainstorming document, intended to layout the current files API landscape and explore how things could evolve.
Here's a [slack discussion](https://maidsafe.slack.com/archives/CMTL335N3/p1593454821207800), with some background.
See also: [Survey of RUST/FUSE FileSystem Libraries.](/BHGtRwNXSUGUdRoe5Mkjcw)
## Current Situation
Presently, the safe-api exposes the concept of a FilesContainer, which consists of a BTreeMap where the keys represent file paths and the values represent metadata. The metadata is another BTreeMap of key/val pairs.
The FileContainer gets serialized to JSON in its entirety and stored on the network as one version of a PublicSequence. Changes and Reads of any path require [de-]serializing the entire directory structure, and filtering or re-writing it. This becomes expensive for large tree structures.
The exposed API is high-level and largely reflects the underlying "must grab entire FileContainer" reality. There is no equivalent to read_dir() for example. Also, concepts such as symlinks and glob() must be re-invented to provide basic functionality that CLI users have been accustomed to for decades now. Some user goals, such as 2 way syncing cannot be done efficiently with the provided API. The Files API itself has a lot of internal complexity and inefficiency around filtering one file or directory from the entire set and manipulating paths.
It has been [suggested](https://maidsafe.slack.com/archives/CMTL335N3/p1593523885236800?thread_ts=1593454821.207800&cid=CMTL335N3) that when the crdt PublicMap type is complete FileContainer can be modified to use it instead, thereby allowing changes to individual paths without re-writing the entire directory structure. That should provide a performance improvement. However, it is not clear (to me) yet how an efficient implementation of read_dir() could be provided with this. ( Actually, an idea just occurred: store child list in directory metadata. Of course this duplicates path data in the map keys, must be kept in sync, etc. ie, gross. )
In summary, I worry that:
1. The present files API is too inefficient for large tree structures.
2. The API is too high level and limiting for some (many?) applications
3. The API is becoming too complex internally
4. The API is quite different from what developers and users are used to.
5. We (I?) needlessly spend time re-inventing the wheel with things like symlinks, glob support, etc.
## Baby, Bathwater
Despite the above criticisms, the FileContainer mechanism has nice features we don't want to lose:
* integrates nicely with SafeURL. Every bit of content can be given a URL, and accessed via safe-browser
* integrates with NRS system
* all data is versioned, and any version can be referenced/retrieved via SafeURL.
Any alternative design should consider how to incorporate these features.
## Benchmarking current API performance.
I haven't done this, though it seems a useful exercise to get an idea of performance as trees get larger (broader and deeper). Will post a link here if I (or anyone) does it.
## How a native/FUSE FileSystem can help
The general idea of a FUSE based filesystem is that we implement the FUSE API in such a way that operating system calls to open(), write(), read_dir(), etc, etc are translated to SAFE Network calls for storing and retrieving data, possibly with a local (mem or disk) cache as an optimization.
In this scenario, a SAFE Network FileContainer (or some other level of granularity) would be locally mounted, just as any other filesystem.
At this point, we get pretty much all of the subcommands in `safe files` for free, and much more besides, because native OS tools for exploring, listing, copying, symlinking, rsyncing, scp'ing, etc all just work. So too, do all the scripts and programs people have already written that perform file operations.
Further, in the process of implementing the FUSE interface, we will necessarily create a low-level filesystem API that can be exposed to Safe network aware apps. That is to say that our code should be usable by Safe-Apps directly even if not FUSE mounted.
## Prior Efforts
### Safe NFS
@dirvine maybe you can provide here some history/architecture (maybe docs?) of SAFE NFS, and why we aren't still using it? It would be good to understand what worked and/or didn't work, to learn from.
Here's some links I dug up:
* [NFS Drive](https://github.com/maidsafe-archive/MaidSafe-Drive/blob/next/docs/nfs_drive.md)
* [FileSystem Hierarchy Discussion](https://safenetforum.org/t/filesystem-hierarchy/4987/14)
From Josh, on slack:
> safe-nfs still exists : https://github.com/maidsafe/safe-client-libs/tree/master/safe_core/src/nfs , it's a series of (largely deprecated, but still in the codebase) APIs. This was superceded by FilesContainers as we fleshed out safe-api/cli, which was largely the same idea but with (pseudo) RDF representations of metadata and simplified API for interacting with it to support NRS in these new APIs.
### Safe.NetworkDrive
[Safe.NetworkDrive](https://github.com/oetyng/SAFE.NetworkDrive) was written by Edward, before joining MaidSafe. It is designed for efficiency, supports versioning/snapshots/rollbacks, and generally seems a promising starting point. It is written in C# for windows platform, so would need to be ported to rust and made more cross-platform... at least the backend components.
See [Architecture Overview](https://safenetforum.org/t/release-safe-networkdrive-on-windows-v-0-1-0-alpha-1/27879/18?u=oetyng)
From github:
> Event sourced virtual drive, writing encrypted WAL to SQLite, synchronizing to MockNetwork and local materialization to in-memory virtual filesystem.
From Slack:
> This doesn't use the SAFENetwork file api, but instead just stores the incremental changes - events - to the network, and then builds up a virtual filesystem in memory with these events.
It does snapshot the filesystem structure (i.e. all metadata etc, and pointers to the actual data).
> That's right, no FileContainer at all. It just uses an ever-expandable database that I implemented over MDs, to insert events -an event store. The eventstore has Snapshot functionality.
So my impl did a snapshot of the filesystem structure every 1000 events, and recorded it as an ImD. So regardless of how many events I produced during the drive's lifetime, it would select at most 999 from the DB + 1 snapshot.
>> So what does the metadata storage look like on the network?
>>
> What happened is that all actual data was stored as chunks on the network, and the events contained all data about what had happened and a pointer to data in case new data was uploaded.
[Full discussion here](https://maidsafe.slack.com/archives/CMTL335N3/p1593454821207800)
This design using AppendOnlyDB seems about the best we could hope for atop a Sequence data type. However, merging concurrent updates remains an unsolved problem. Thus, a better design could be to marry the local cache and instant response aspect of this design with a CRDT Tree data type (introduced below).
### FileTree-PHP
This is a little prototype written by @danda over a couple days. The idea here is to implement FileItem as a tree structure of file metadata to make file operations more efficient. The end goal would have been to change FilesMap in safe-api from a BTreeMap to a tree of FileItem with a "real" traversable root directory.
This toy prototype is simple, but already supported:
* efficiently reading children of node, ie read_dir()
* lookup by path
* dirs/files/symlinks
* efficiently adding/remove paths at any level
* serialization to/from flat FileContainer json
* serialization to/from nested json.
This prototype only stored metadata, just as a FilesContainer did. In this sense, it does not qualify as an "in-memory filesystem". However, the process of implementing it got me to thinking more about filesystem concepts and led me to start investigating FUSE in-mem filesystems, etc and in general thinking about other approaches we could take.
## Thoughts on Design
As I see it, there are two high-level approaches to a FUSE based SAFE Network filesystem:
1. Read/write directly to/from network.
2. Read/write to memory file system that periodically syncs with network.
These approaches could potentially exist as modes in a single implementation. (1) is going to have considerable latency which causes applications to block, so (2) can be thought of as a performance optimization for (1).
Safe.NetworkDrive implements (2) and goes to considerable lengths to support offline operation. Latency is reportedly quite low and the system feels snappy. Complexity arises around merging changes, eg if two or more devices (mounts) modify or move the same file/dir since the last sync. Strategies are needed to deal with such merge conflicts. Here `CRDT-Tree` (below) offers a path forward via eventual consistency.
In general I believe Safe.NetworkDrive solves a lot of the problems. It is worth reviewing the design in detail and possibly/probably porting much of it to rust.
[syncer](https://github.com/pedrocr/syncer) is another caching/remote fuse filesystem worth reviewing, and maybe could be built upon.
### Platform Differences
The main platforms to consider for now are unix and windows. Well, iOS and Android also, but afaict, they can't actually mount FUSE, so apps would need to use a SAFE Network library for transfers.
A question naturally arises if we should try to have a single rust implementation for all platforms, or independent implementations.
My initial thought is that we should strive for a single, mostly platform-independent API library/crate. Let's call it `safe-fs` for now. So `safe-fs` would be used by `safe-fs-fuse-daemon` which is (slightly) specific to each platform.
### Related Research
Paper: [A highly-available move operation for replicated tree and distributed filesystems](https://martin.kleppmann.com/papers/move-op.pdf) Code: [Github](https://github.com/trvedata/move-op/) Klepmann, et al. Awaiting publication.
> * We define a CRDT for trees that allow *move* operations without any coordination between replicas such as locking or consensus. This has previously been thought to be impossible to achieve.
> * We formalize the algorithm using Isabelle/HOL, a proof assistant base on higher-order logic, and obtain a computer-checked proof of correctness. In particular, we prove that arbitrary concurrent modifications to the tree can be merged such that all replicas converge to a consistent state, while preserving the tree structure.
> * To demonstrate the practical viability of our approach, we refine the algorithm to to an executable implementation within Isabelle/HOL and prove the equivalence of the two. We extract a formally verified Scala implementation from Isabelle and evaluate its performance with replicas across three continents.
> * We perform experiments with Dropbox and Google Drive, and show that they exhibit problems that would be prevented by our algorithm.
**PHD Dissertation: A Highly Available Distributed Filesystem**
See writeup: [Notes on PHd Dissertation: A Highly Available Distributed Filesystem.](/1dBKrtkQTa656k070hxVvw)
### Network Storage
#### Data Representation
The `CRDT-Tree` presented by Kleppman et al seems to check all the boxes for us. In particular, it is a tree structure, designed with a distributed filesystem in mind. As a CRDT, it is eventually consistent, thus solving the merge challenges for concurrent modifications noted by @edward in his design... problems that even affect Dropbox and Google Drive. Also, the paper shows that, even without optimizations, the design is performant enough to achieve 600 writes/sec with replicas on 3 continents.
A practical/implementation problem for us at this time is that this design only exists as pure Isabelle/HOL logic and machine generated (and formally proven) Scala code. In an ideal world, the Isabelle/HOL tool could also generate formally proven Rust code. That not being the case (I checked), we will need to create our own Rust implementation.
#### Tree Data Type
A `CRDT-Tree` gives us a new tree datatype to work with. Let's call it simply the `Tree` data type, a sibling of `Map` and `Sequence`. Being a generic tree data structure, it could support storing any tree-ish data.
#### FileContainer --> FileTree
We presently have a `FileContainer`, which is a specialization of a Sequence. The `FileContainer` can be modified to utilize the `Tree` data type instead.
I propose that we also change the name to `FileTree` which reflects that it is a specialization of `Tree`. The term `FileTree` will be used henceforth in this document to differentiate from the `Sequence` based `FileContainer`.
Like a `FileContainer`, the `FileTree` type will store only tree metadata. Files themselves will continue to be stored as `ImmutableObject`.
Unlike the `FileContainer` API, the `FileTree` API will support standard filesystem calls such as opendir(), readdir(), fopen(), fread(), fwrite(), fclose(). It is proposed that there will be a low-level (non-caching) API and high-level (locally cached) API. Or possibly a single API with some type of *no_cache* flag.
These calls are necessary to build a FUSE filesystem and also will enable SAFE applications to perform tasks that could not be done with the current safe-api.
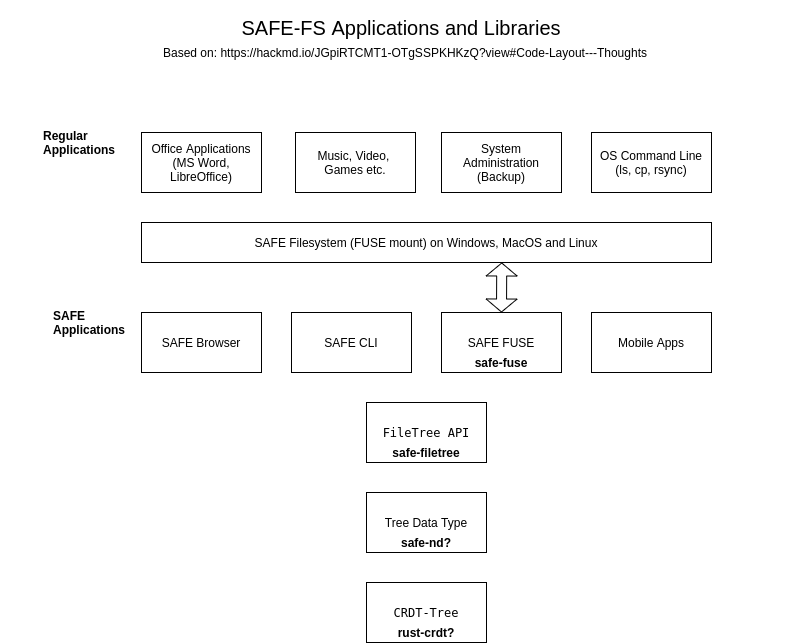
#### Code Layout - Thoughts
The `CRDT-Tree` CRDT implementation could exist in rust-crdt, assuming David Rusu agrees, or possibly in its own crate, tbd.
The `Tree` Safe Data Type wrapping `CRDT-Tree` could exist in safe-nd crate, or possibly in its own crate, tbd.
The `FileTree` API should exist in its own crate/module, ie safe-filetree. It can be used by safe-api, safe-cli, safe-browser, safe-fuse, etc.
The `SafeFuse` mountable filesystem should exist in its own repo, safe-fuse, as a library + executable. It will be a translation layer between fuse and safe-filetree API.
Here is a diagram, provided by @happybeing that encapsulates the above.
#### Mounts
##### What can be mounted?
###### Mounting CRDT-Trees
Each `FileTree` object represents a root directory and becomes a mount point.
A question immediately arises: should only the root of the `FileTree` be mountable, or any sub-directory? Logically, any directory could be chosen as "root" of the local mount. Seems nicer, if technically achievable. May be problematic for symlinks though, so for now let's keep it simple and specify that only the root of a `FileTree` is mountable, not any sub-tree thereof.
note: We also want safe-browser to be able to load arbitrary public `FileTree` and view the contents. That should be possible, without mounting, providing it uses the same APIs for reading the `FileTree` as the FUSE daemon does.
###### Global Mount?
Does it make sense for us to have a single global (worldwide) mount for public data? That appears to be what ipfs does, eg:
```
/ipfs/<hash>/path/to/file
```
Here is a real IPFS link via cloudflare gateway. Note the path after the hash: https://cloudflare-ipfs.com/ipfs/QmXoypizjW3WknFiJnKLwHCnL72vedxjQkDDP1mXWo6uco/wiki/Bill_English.html
So the mount point is /ipfs, which provides access to a global ipfs namespace, where content (directories and files) is addressed via CID (hash).
The above seems very analagous to SAFE Network XorNames in a single global namespace.
The primary advantage of mounting the entire global namespace is that one can easily reference more than one XorName with a single mount, and copy/move files between them.
However, if a `FileTree` is our fundamental representation of a filesystem that we design our Filesystem API around, then we have some related issues:
1. There are many distinct `FileTree` objects. Any user can create as many as they like.
2. There are many Data Types in SAFE that are NOT `FileTree` or any type of `Tree`. These objects could be ignored, or provided as a file with metadata info, so not a big problem.
In theory, it should be possible for a filesystem layer to aggregate any number of`FileTree` beneath a global `/safe` root and thereby implement a global namespace FS, similar to /ipfs. But that requires special cases for `/` root directory and the `FileTree` root directories and there are theoretical problems trying to move items between different underlying `CRDT-Tree` data objects.
Thus for now, it seems simplest and best (KISS principle) to build the FileSystem API around the `FileTree` data type only. Possibly a later phase/iteration of the project could extend it to a global namespace.
### Local Storage
Data that is written to or read from the filesystem API can be cached locally as operations in an event log, either in memory or possibly on disk (via another mounted filesystem) for fast access.
The idea would be to:
1. Download all the filesystem data (tree structure+files) at time of mount. After the first mount, this can be only the diffs.
2. Make file operations blazing fast because they are all performed locally, and operations written to an event log, which is periodically bi-directionally synced with the network
3. enable working with the mounted filesystem even offline.
Of course, this scheme is only workable if the local storage (mem, disk) is large enough to contain the remote `FileTree` and associated `ImmutableObjects`.
See the design of Safe.NetworkDrive for details.
Also, the paper [Local-first software: You own your data, in spite of the cloud](https://www.inkandswitch.com/local-first.html) by Kleppman et al is worth a read.
### NRS, SafeUrl Linking
SafeUrl resolution should work with a `FileTree` similar to how it works with a FileContainer.
The main difference in the code is that when URL resolution reaches a `FileTree` node, all further path resolution would be handled by the `FileTree` api.
## Open Issues
### from @scnOr4R4TKa64D1BpaAzpQ
A couple of comments on that paper/algo ^^ as per my understanding:
- Unless I'm misunderstanding, the comment from @dirvine about "caching" ops non-causally ready (in yesterday's meeting about policies) seems to be applicable to this algo too, as it keeps "unsafe" operations in the log as they could eventually become "safe", pag 7, section 3.5:
> Note that the safety of an operation (whether or not it would introduce a cycle) may change as subsequent operations with lower timestamps are applied. For example, an operation may initially be regarded as safe, and then be reclassified as unsafe after applying a conflicting operation with a lower timestamp. The opposite is also possible: an operation previously regarded as unsafe may become safe through the application of an operation that removes the risk of introducing a cycle. For this reason, the operation log must include all operations, even those that were ignored.
### File Content Storage
The `CRDT-Tree` data type is only meant for storing tree data, ie the tree structure itself.
I suppose in theory it could store file data in the metadata associated with each node/triple but that does not seem to be what the paper's authors contemplate as they state:
> In a distributed filesystem, replication and conflict resolution is required not only for the directory structure, but also for the contents of individual files. This can be accomplished by using CRDTs for file contents as well. We discuss distributed filesystems furth in S6.2.
However, S6.2 is a general survey of distributed filesystem projects and does not address use of a CRDT for file contents.
Further, in SAFE Network we already have ImmutableData for storing/chunking file content.
So long as ImmutableData becomes implemented as a CRDT, then we should be ok here I think...
### Causally Stable Threshold
The `CST` is defined as the lowest timestamp/clock of the set of known replicas, where all replicas are known.
Operations that occurred before the CST can be discarded/pruned. This is useful for keeping log sizes small and is also a requirement for emptying the filesystem Trash (which nodes are moved to when deleted/unlink'ed).
I had some concerns about the `CST` for our use case, so I asked Martin Kleppman, author of the paper:
> On 16 Aug 2020, at 18:59, Dan wrote:
>
> Hi Martin,
>
> From your paper:
>
> > In this case, we can keep track of the most recent timestamp we have seen from each replica (including our own) and the minimum of these timestamps is the causally stable threshold.
>
> Ok, so let's say we have replicas a, b, c, with timestamps: {a: 500} and {b: 200}. C has never initiated any operation -- maybe it is a read-only replica or only an infrequent writer. All replicas have converged to same state.
>
> In this case, is the causally stable timestamp {b: 2} or None? I tend to think the answer is None, but worry about the implications of that in practice.
>
> I'm just trying to figure out the operational constraints of log truncation and emptying trash because if I'm understanding correctly, it seems like this only really works well if all replicas are (a) known to all and (b) initiating operations regularly. But for a shared filesystem, I think one must deal with read-only or infrequent-write replicas, and ideally replicas can join and leave...
and Martin replied:
> Hi Dan,
>
> If a replica has never initiated an operation, but there is a possibility that it may initiate an operation in the future, then you have to include it in the causally stable threshold, because otherwise it may generate an operation with a timestamp that is lower than the threshold, and then that operation might not be able to be processed correctly.
>
> However, there's a way round this: even if a replica doesn't initiate operations, it can acknowledge the timestamp it has seen. If it also stores the timestamp it has seen on disk (so that it's not forgotten in the case of a crash), then you can use the last acknowledged timestamp from each replica to compute the causal stability threshold.
>
> Dealing with replicas joining and leaving is harder. You can probably use a rule something like: once all other replicas have acknowledged the removal or addition of a replica, then it takes effect. But the details will require some careful thought.
>
> Cheers,
> Martin
So basically, we need to be careful here, but there doesn't seem to be a theoretical showstopper.
### file (or dir) name conflicts.
In a generic Tree CRDT, a filename is just metadata, and as such is not checked for unique-ness.
However, a file/dir/symlink name in a directory must be unique.
This uniqueness can be enforced for a single replica, but still two (or more) replicas can simultaneously create directory children with identical names, but different content, even different types.
I made an example test case that demonstrates this occurring. Replica 1&2 both create the file /tmp/file1.txt, and write different content to it.
The result is two Tree entries for /tmp/file1.txt, which is perfectly fine as far as the Tree CRDT is concerned:
```
$ php filesystem-split-inode.php test_fs_name_collision
------- fs state after: created /tmp/file1.txt. (replica1) -------
- null => forest
- 281474976710656 => {"name":"root","size":0,"ctime":1598666245,"mtime":1598666245,"kind":"dir"}
- 281474976710659 => {"name":"\/tmp","size":0,"ctime":1598666245,"mtime":1598666245,"kind":"dir"}
- 281474976710661 => {"name":"file1.txt","inode_id":281474976710660}
- 281474976710657 => {"name":"fileinodes","size":0,"ctime":1598666245,"mtime":1598666245,"kind":"dir"}
- 281474976710660 => {"size":0,"ctime":1598666245,"mtime":1598666245,"kind":"file","links":1,"content":"hello from replica1\n"}
- 281474976710658 => {"name":"trash","size":0,"ctime":1598666245,"mtime":1598666245,"kind":"dir"}
------- end state -------
------- fs state after: created /tmp/file1.txt. (replica2) -------
- null => forest
- 281474976710656 => {"name":"root","size":0,"ctime":1598666245,"mtime":1598666245,"kind":"dir"}
- 281474976710659 => {"name":"\/tmp","size":0,"ctime":1598666245,"mtime":1598666245,"kind":"dir"}
- 562949953421313 => {"name":"file1.txt","inode_id":562949953421312}
- 281474976710657 => {"name":"fileinodes","size":0,"ctime":1598666245,"mtime":1598666245,"kind":"dir"}
- 562949953421312 => {"size":0,"ctime":1598666245,"mtime":1598666245,"kind":"file","links":1,"content":"hello from replica2\n"}
- 281474976710658 => {"name":"trash","size":0,"ctime":1598666245,"mtime":1598666245,"kind":"dir"}
------- end state -------
------- fs state after: merged ops from replica2. (replica1 -------
- null => forest
- 281474976710656 => {"name":"root","size":0,"ctime":1598666245,"mtime":1598666245,"kind":"dir"}
- 281474976710659 => {"name":"\/tmp","size":0,"ctime":1598666245,"mtime":1598666245,"kind":"dir"}
- 281474976710661 => {"name":"file1.txt","inode_id":281474976710660}
- 562949953421313 => {"name":"file1.txt","inode_id":562949953421312}
- 281474976710657 => {"name":"fileinodes","size":0,"ctime":1598666245,"mtime":1598666245,"kind":"dir"}
- 281474976710660 => {"size":0,"ctime":1598666245,"mtime":1598666245,"kind":"file","links":1,"content":"hello from replica1\n"}
- 562949953421312 => {"size":0,"ctime":1598666245,"mtime":1598666245,"kind":"file","links":1,"content":"hello from replica2\n"}
- 281474976710658 => {"name":"trash","size":0,"ctime":1598666245,"mtime":1598666245,"kind":"dir"}
------- end state -------
== Pass! replica1 and replica2 filesystems match. ==
```
So what *should* happen when these conflicting changes merge?
The paper has this to say:
> One final type of conflict that we have not discussed so far is multiple child nodes with the same parent and the same metadata. For example, in a filesystem, two users could concurrently create files with the same name in the same directory. Our algorithm does not prevent such a conflict, but simply retains both child nodes. In practice, the collision would be resolved by making the filenames distinct, e.g. by appending a replica identifier to the filenames.
My thoughts:
1. appending a replica identifier to both filenames is kind of heavy-handed and gross. That is sort of like neither party wins.
2. keep in mind that this can occur for directories and symlinks, not only files.
3. How to detect the collision, which occurs during apply_op()? I'm thinking that apply_op() should accept a callback function that can inspect the metadata and decide if any collision is occuring. This callback would need to check for another child with same name, which is presently a slow operation (for loop).
4. In the event of a collision, it seems that once again a callback is needed for the application to resolve it, as the generic tree type doesn't understand the metadata.
5. Perhaps last-writer-wins is acceptable here. All replicas can agree on that. (deterministic). So the last writer would keep the original name. But what to do with the loser? It could be moved under trash (deleted) or could be renamed deterministically, perhaps using replica_id or full lamport timestamp (actor + counter). Or we could get fancier and create a sub-folder "conflicts", either in current location, or eg under root or other fixed/known location.
See followup: [CRDT Tree Filename collision experiments](/YgLTnGBcTzaO23EPB7AMjw)
### Lookup by name is slow.
Finding child matching name presently requires a loop over all entries in the directory. This becomes especially noticeable for large directories. We should consider how to make this faster. Perhaps by caching in a local HashMap upon first read.
### Storing CRDT in Ram vs Disk.
I saw this discussion about storing some or all of CRDT on disk, database style. We will probably need to think more about this as we progress with CRDT integrations.
https://www.reddit.com/r/rust/comments/ihxacr/a_conflictfree_replicated_data_type_crdt_tree/g349dzq/
### Network strings vs OS strings.
Rust has `String` and `OsString` types because string representations are different between OSes and also in the language.
Yet for a shared filesystem that is supposed to be mountable on any OS, there must be some agreement/conversion.
In fuse_rs, string parameters are generally of type &OsStr and returned values are of type &[u8] (array of bytes).
On Linux, filenames are really just bytes as far as the kernel is considered. In practice, they are usually utf-8, but I'm not certain we can rely on that.
On Windows, strings are a variant of UTF-16.
It would be *nice* if we could just force everything to utf-8 for storage, and convert as necessary, eg for windows. I believe ntfs-3g did this back in 2009, despite some grumbling. This approach seems to break if user is using anything besides LANG=xx_XX.UTF-8.
Some background:
* [one solution, in python](https://beets.io/blog/paths.html)
* [ntfs-3g discussion](https://tuxera.com/forum/viewtopic.php?f=2&t=1817&view=previous)
* [reddit discussion](https://serverfault.com/questions/87055/change-filesystem-encoding-to-utf-8-in-ubuntu)
* [convmv](https://www.linux.com/news/cli-magic-convert-file-names-different-encoding-convmv/)
More research will be needed on this.
Perhaps it is simplest to just use bytes, and convert for windows, as per beets.io solution.
However, for network purposes, I think we'd really like it converted into a neutral utf-8 for storage, display by browsers, etc. I think though, that to convert we have to know the FROM encoding, and I don't know that the fuse-filesystem process has access to env of program doing the writing. One solution could be to offer an encoding mount option, so that all byte strings are interpreted as originating in the source encoding.
We can also check how other network file systems handle this issue.
### Other OS differences:
#### path Case (in)sensitivity.
note: NTFS actually is case-sensitive, and since 2018 Windows supports per-folder case sensitivity flag in the UI. So I think we can kind of just rely on it.
See:
* https://devblogs.microsoft.com/commandline/per-directory-case-sensitivity-and-wsl/
* https://www.tiraniddo.dev/2019/02/ntfs-case-sensitivity-on-windows.html
#### path allowable characters
#### mode, flags, uid, gid
### Backup/Archive vs Sharing vs Deployment
People will use safe_fs for various purposes.
We can broadly group these into categories:
Backup/Archive: User wants to backup files with all local metadata and restore them to local system later with metadata intact, including user/group info, permissions/mode, timestamps, etc.
Sharing: User wants to share files with others, possibly on any operating system.
Deployment: User wants to deploy a Safe website or other type of application/service.
 Sign in with Wallet
Sign in with Wallet





