# Can we have a better feature store
by zhukovgreen
PyCon CZ 23
---
## Disclaimer
----
- My talk represents my opinion regards to what I think is good and bad
- I'll try to be very short in outlining general items,
such as what is the feature store, its cons/pros, and what tools are available on the market.
All these you can find on the internet
----
- My talk primary based on the feasibility study, which I was conducted
during the adoption of the feature store in my current company (Paylocity)
- I have a working prototype of the described solution, which I will be
opensourcing (good to set the goals)
- I am sorry for the lack of smiles and fun pictures in slides
Please prepare reading and listening!
---
## Me

----
- https://github.com/zhukovgreen
- mailto:iam@zhukovgreen.pro

In :heart: with Python and Spark. My first Python version was 2.6
----
Data Engineer at Paylocity.
* working with data
* building data pipelines, tools
* evaluating data architectures
* ci/cd systems
* other software development.
Very like functional programming, Python's
typing ecosystem, software design architectures.
Inspired by Scala.
---
How many of you uses feature store as a primary tool to read/write data?
Please write on Slido which tool you're using for this
---
## What is the feature store
```text
Feature store is the abstraction around the data tables.
It facilitates the discoverability of the
features (columns in tables), through the binding of
metadata to features. As well as enables to build the
features liniage graphs.
It also makes the features consuming/producing easier
(reuse of features).
And it has a strong focus on the tooling to simplify the
data science workflows (i.e. generating training/testing
datasets, snapshoting).
```
---
## Available solutions (very brief overview)
----
The most popular are:
- Databricks feature store
- AWS Sagemaker
- Tecton
Other known:
- Feast
- H2O feature store
- Butterbee
- ... (many others)
----
What is in common:
- all of them use some kind of a RDBMS database for storing the metadata
- therefore all need some infrastructure
- most of them do not support Spark for IO with the feature store
and focused on Pandas
- bad/impossible local development support
----
Databricks feature store
:+1:
* Very feature-rich and nicely designed (compared to others)
* It supports feature lookups
* It is spark first
* Uses delta format (almost ACID transactions/walk-in time ...)
----
:-1:
* Not supporting local development at all
* Metadata is tables centric
* Poor search experience (very plain)
* Lineage requires you to upgrade to the Unity catalog
* Unity catalog makes the local development almost impossible
----
AWS Sagemaker
:+1:
* Better local development support
* Data is available on s3
* Good integration with the Glue data catalog
----
:-1:
* Very small supported types subset
* Not support reading from the feature store into the spark dataframe
* Writing to the feature store a spark dataframe accomplished with
not actively developed external project
----
h2o feature store
:+1:
* Very comprehensive open-sourced tool (includes data catalog and
transformations tooling)
* Good local development experience
----
:-1:
* Complex deployment via kubernetes helm charts
---
## What things can be better
----
* The search experience is very plain. See a typical search UI example:
https://dbc-3bc168f5-c0de.cloud.databricks.com/?o=1796303353019077#feature-store/feature-store
----
* Need the infrastructure deployment and maintenance
----
* Metadata is not feature oriented
Metadata is usually bound to the tables, not features.
This makes the search experience worse and just confuses users.
----
* Lack of spark support
* Lack of local development support
* Strong push to the "web ide" saas
* Hiding interesting parts in the black boxes
* No help in optimizing queries, even though the source of the data
is here
* Not stable and complex interfaces which breaks downstream clients
Probably many others (if we would be able to access their code)...
---
## Your own feature store
----
It would be fair to say that sometimes (probably as a rule) companies are
just not going to accept the risk of building something own. It has some
logic.
But if your company has experience with building its own
production-grade components, then let's discuss how it might look like
----
Let's start from "Why"?
----
The same reasons which applies to the open source projects.
But not just that...
----
- own solution can be more tuned to the company
- own solution will be evolving together with the team
- it is much easier to integrate the own solution into the team tooling set,
building new useful composite components
- you're not locked to some vendor
---
## Design orienteers
---
```text
- build on spark and for spark
- in order to use: just `pip install` and set the
configuration. No infrastructure
- metadata should be feature-centric (all the metadata
should be bound to the features)
- but feature store reader/writer should support tables,
as this is the main entity the whole data engineering stack
is focused on
- convenient feature search (feature rich, supporting complex queries, fuzzy
search etc.)
- metadata repository decentralized, version controlled
- simple and extendable (let others adapt it to their needs by
contributing or forking)
- can be deployed to any cloud platform (hint - just
no need to deploy would work)
- supports time traveling and point-in-time snapshotting
- support setting feature level permissions (GDPR/PII etc.)
- query optimization mechanisms :question:
```
----
Now very cool part...
----
- query optimization mechanism :question:
This is actually the only place when you can make a reasonable
estimate on how better to optimize your data to improve the
query experience
```text
Query statistics Decision on
as metadata --> optimization approaches
|
Data storage/ |
partitioning/ <--------
z-ordering action
...
```
---
## Components of the system
----
* Feature Store - interacts with the metadata (hot and cold). Publishes it to
the GitHub repo as csv files
* Reader/Writer - clients to read/write to tables
* QueryOptimizer - analyses query stats and publishes the write strategy
----
```text=
┌─────────────────┬─────────────┐
│ Repository with │ ▼
┌─────►│ metadata │◄────── query
│ └────────┬────────┘ optimizer
│ │ ▲
│ │ │
│ │ │
│ │ │
│ │ │
FeatureStore │ │
(metadata layer) │ │
│ │
▼ │ ┌────┐
FS Reader/Writer ──────►│Data│
└────┘
```
----
Example table:
```text
+----------+------+-------------------+
| Date|Number| Timestamp|
+----------+------+-------------------+
|2022-12-02| 1|2022-12-02 01:00:00|
|2022-12-03| 2|2022-12-03 02:00:00|
|2022-12-04| 3|2022-12-04 03:00:00|
+----------+------+-------------------+
```
Metadata table:
```text=
+------------+-------------+------------+---------------+--------------------------+-------------+--------+------------------+-------------------+-------------+
|feature_name|feature_dtype|source_table|source_table_pk|created_at |creation_date|is_valid|tags |feature_description| queries_stat|
+------------+-------------+------------+---------------+--------------------------+-------------+--------+------------------+-------------------+-------------+
|Number |string |TableA |Date |2023-05-24 15:50:45.016364|2023-05-24 |true |[TagD, TagE, TagF]|Some number | ... |
|Timestamp |timestamp |TableA |Date |2023-05-24 15:50:45.016364|2023-05-24 |true |[TagG, TagH, TagJ]|Some timestamp | ... |
|Date |string |TableA |Date |2023-05-24 15:50:45.016364|2023-05-24 |true |[TagA, TagB, TagC]|Some date | ... |
+------------+-------------+------------+---------------+--------------------------+-------------+--------+------------------+-------------------+-------------+
```
----
The repository with the metadata located on some spark friendly storage accessed
by the organization (hot metadata storage):
- ftp:/
- s3a://
- hdfs://
...
---
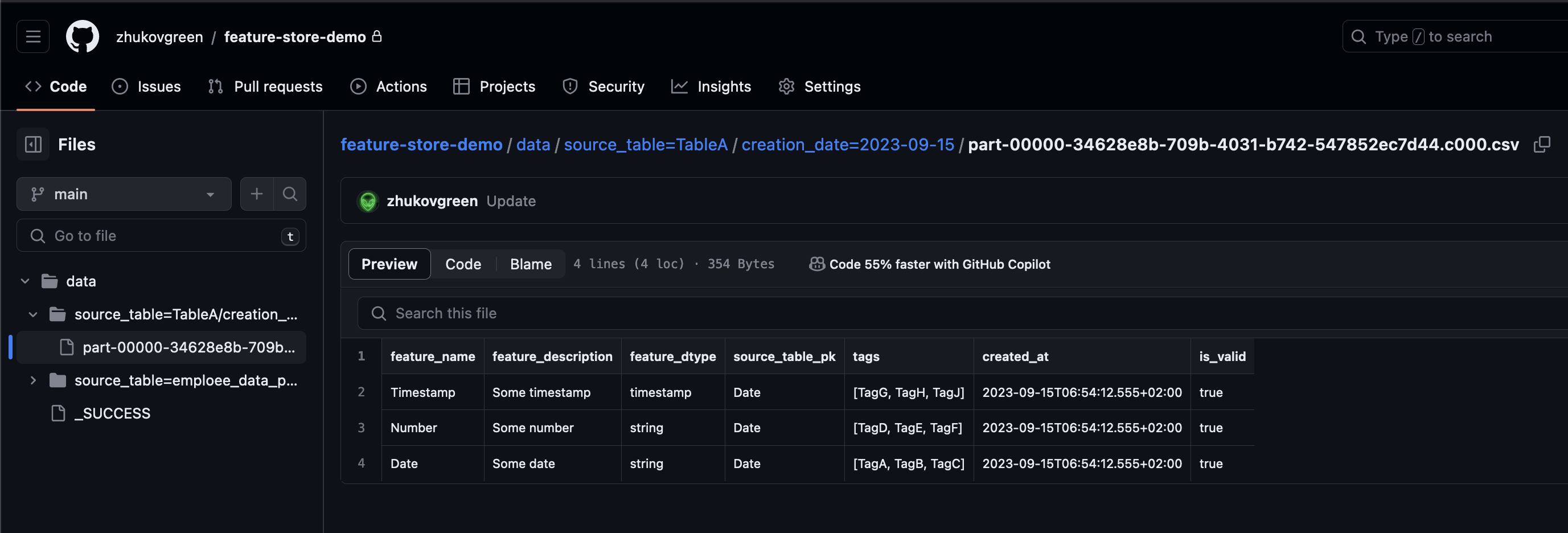
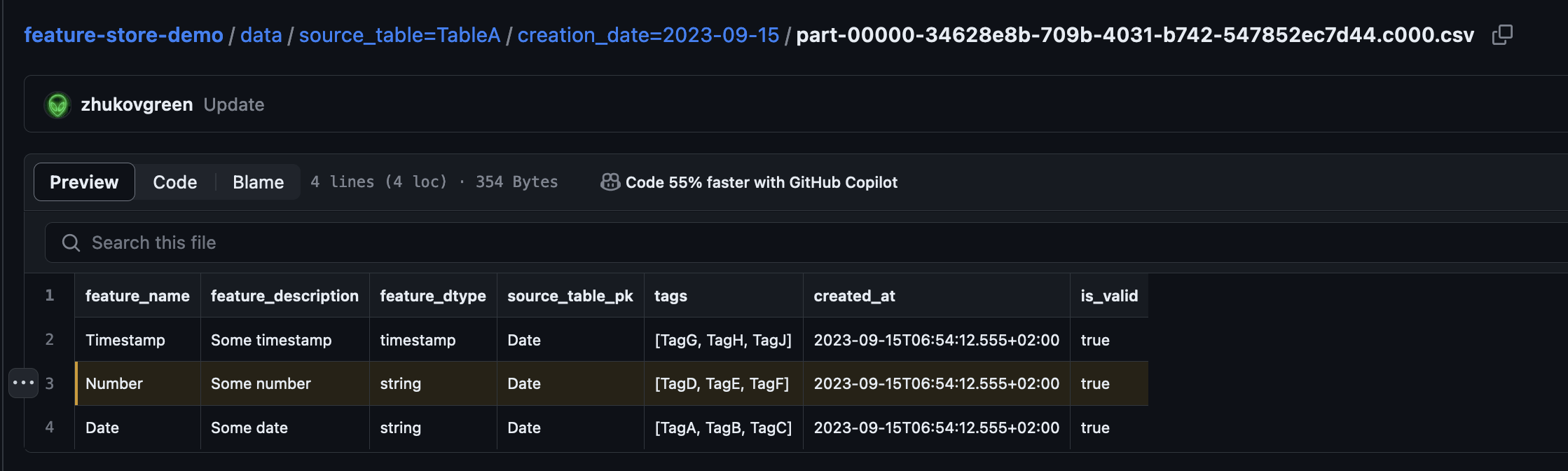
# Feature searching
----
FeatureStore client publishes the metadata as csv files to the GitHub
repository (cold metadata)
This enables us to search the features + do all the cool stuff from the
VCS system (i.e. git blame to see who contributed the feature, or
git revert etc.
)
----
----


---
## Interfaces
----
Feature store client provides clients to interact with the metadata,
update them and commit changes
```python=
@attrs.define(slots=True, auto_attribs=True, frozen=True)
class FeatureStores(Protocol[TableType_co]):
uri: AnyPath
fs_schema: ClassVar[T.StructType]
def register_table(
self,
name: TableName,
df: DataFrame,
pk: Tuple[FeatureKey, ...],
feature_tags: Dict[FeatureKey, Tuple[TagVal, ...]],
feature_descriptions: Dict[FeatureKey, FeatureDescription],
) -> TableType_co:
...
def update_table(self, name: TableName) -> TableType_co:
...
def update_meta_repo(self, path: LocalPath) -> None:
...
def publish_meta(self) -> None:
...
```
----
Feature store writer:
```python=
@attrs.define(slots=True, frozen=True, auto_attribs=True)
class FSWritersV1(Protocol[ConfigType]):
"""Base class for feature store writers.
:param config: each writer should have a config attribute,
specific to the implementation
:param spark: spark session
"""
config: ConfigType = attrs.field()
spark: SparkSession = attrs.field()
def create_table(
self,
name: TableName,
primary_keys: tuple[PrimaryKey, ...],
schema: T.StructType,
path: PathLike,
prerequisite_tags: PrerequisiteTags,
columns_description: ColumnsDescription,
*,
if_not_exists: bool = True,
timestamp_keys: tuple[TimestampKey, ...] = (),
partition_columns: tuple[PartitionColumn, ...] = (),
description: TableDescription | None = None,
) -> DataFrame:
"""Create a feature table.
If the table already exists, it should return it and give a warning,
that can't create already existing table.
:param primary_keys: primary keys of the table, used for features
lookups
:param df: spark dataframe to write to the feature store
:param prerequisite_tags: key:value tags required to be specified
:param if_not_exists: if true (default), then returns existing df if
exists
:param timestamp_keys: timestamp keys, used for point in time
processing of the data when preparing the training subset
:param partition_columns: columns which will be used as a partitions
when the dataframe will be written
:param tags: dict with any arbitrary tags. If there are the same
keys in prerequisite_tags or columns_description, then the
value will be overwritten by the value in these containers
"""
...
def write_table(
self,
name: TableName,
df: DataFrame,
mode: WriteMode = WriteMode.merge,
) -> DataFrame:
"""Write to the feature table.
Using the merge as a default writing mode, which does a delta table
upsert operation.
If the table doesn't exist,
then it should be created first, from the
metadata, stored in the configuration.
"""
...
def drop_table(self, table_name: TableName) -> None:
"""Drop the table."""
...
```
----
Reader interface
```python=
@attrs.define(slots=True, frozen=True, auto_attribs=True)
class FSReadersV1(Protocol[ConfigType, FeatureTable_co]):
"""Base class for feature store readers.
Each reader should have a config and spark session.
:attr config: The specific reader configuration
:attr spark: The spark session
"""
config: ConfigType = attrs.field()
spark: SparkSession = attrs.field()
def read_table(
self,
name: TableName,
as_of_date: datetime.date | None = None,
as_of_timestamp: datetime.datetime | None = None,
) -> DataFrame:
"""Read a table from the feature store.
as_of_date and as_of_timestamp are mutually exclusive or both None.
Specified as_of_* looks for the nearest table snapshot
:param as_of_date: The date to read the table as of.
If specified
:param as_of_timestamp: The timestamp to read the table as of.
If specified
...
"""
def get_features(
self,
feats: tuple[FeatureKey, ...],
where: Expr,
tables: tuple[TableName, ...] = (),
):
"""Get a table containing specified features.
Look for tables containing the given features,
selecting specified features and joining them
on the pk specified in the table's meta.
where: is an optional filter
tables: only specified tables if not empty, otherwise
all tables will be joined
"""
```
---
# Bonus item (if I have time)
Show how you can patch the databricks feature store to be able to
test your code locally
---
# Questions?
Link to the presentation

{"description":"View the slide with \"Slide Mode\".","title":"can-we have-a-better-feature-store","contributors":"[{\"id\":\"2a089c74-c1e2-4106-ab8f-e7197ae3bbe3\",\"add\":26350,\"del\":25270}]"}