# 2024q1 Homework1 (lab0)
contributed by < [han1018](https://github.com/Han1018) >
#### Reviewed by `HenryChaing`
>可以在 list_sort.c 效能比較中,新增比較次數以及快取記憶體頁面失誤的測試項目。
其餘的 review 在底下有留言
## 開發環境
```shell
$ gcc --version
gcc (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0
Copyright (C) 2021 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
$ lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 43 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 12
On-line CPU(s) list: 0-11
Vendor ID: AuthenticAMD
Model name: AMD Ryzen 5 3600 6-Core Processor
CPU family: 23
Model: 113
Thread(s) per core: 2
Core(s) per socket: 6
Socket(s): 1
Stepping: 0
Frequency boost: enabled
CPU max MHz: 4208.2031
CPU min MHz: 2200.0000
BogoMIPS: 7200.08
```
:::danger
不需要複製作業要求,提出你的洞見和成果
:::
### 常需注意的程式撰寫風格
程式撰寫風格建議貼近 Linux 樣式,更易閱讀也易於協作。
1. C 語言縮排處理 switch 敘述的縮排方式是讓 case 與 switch 對齊
```c
switch (c) {
case 'h':
usage(argv[0]);
break;
```
2. 空格使用
關鍵字前後需加上空格,e.g., if/else, do/while,
```c
if (x == true) {
do_y();
} else {
do_z();
}
do {
/* body of do-loop */
} while (condition);
```
4. 二元運算子和三元運算子周圍新增一個空格
e.g., `= + - < > * / % | & ^ <= >= == != ? :`
5. `,` 點後需要加上空格
```c
typedef struct {
int width, height;
} screen_t;
```
:::warning
留意[資訊科技詞彙翻譯](https://hackmd.io/@sysprog/it-vocabulary),operator 是「運算子」
:::
## Valgrind 分析記憶體問題
Valgrind 是個在使用者層級 (user space) 對程式在執行時期的行為提供動態分析的系統軟體框架,具備多種工具,可以用來追蹤及分析程式效能。
由 dynamic Binary Instrumentation (DBI) 著重於二進位執行檔的追蹤與資訊彙整後,進行資料分析。shadow values 技術來實作,後者要求對所有的暫存器和使用到的主記憶體做 shadow (即自行維護的副本),這也使得 Valgrind 相較其他分析方法會較慢。
* shadow value:指的是保留每一個暫存器以及被使用到的主記憶體的複製版本,也因此需花費更多時間。
* 參見 [Valgrind: a framework for heavyweight dynamic binary instrumentation](https://dl.acm.org/doi/10.1145/1273442.1250746)
簡易而言,Valgrind 用作追蹤/分析程式的效能以及安全性(e.g., Memory Leak, Invalid Memory Access)。每次完成階段開發,便可以用於檢測。
### 使用案例
1. Memory Leak
:::danger
改進漢語表達。
台大電機系李宏毅教授對於 ChatGPT 的看法是,要善用人工智慧的成果,一旦人們得以善用,人類的書寫不該比 GPT 一類的語言模型差。
:::
Memory Leak 類型
>definitely lost: 真的 memory leak
indirectly lost: 間接的 memory leak,structure 本身發生 memory leak,而內部的 member 如果是 allocate 的出來的,一樣會 memory leak,但是只要修好前面的問題,後面的問題也會跟著修復。
possibly lost: allocate 一塊記憶體,並且放到指標 ptr,但事後又改變 ptr 指到這塊記憶體的中間
still reachable: 程式結束時有未釋放的記憶體,不過卻還有指標指著,通常會發生在 global 變數
即便是在所用的函式庫裡頭配置的記憶體,也可偵測到,這也是動態分析手法的優勢。
:::warning
"command" 一詞的翻譯是「命令」,常見於終端機裡頭執行的 shell,而 "instruction" 的翻譯是「指令」,特別指在 CPU (central processing unit,中央處理單元) 所執行的 instruction。儘管在漢語中,這兩個詞彙很容易相互混淆,但「Linux 核心設計/實作」課程特別強調兩者差異,並期望學員務必使用精準的用語。
:::
完成 C/C++ 程式編譯後,下命令 <s>指令</s>檢查:
```shell
$ valgrind -q --leak-check=full [執行程式檔]
```
`-q`:安靜模式,只輸出錯誤訊息。
`--leak-check=full`: Valgrind 在程式運行結束後進行完整的記憶洩漏檢查。這意味著 Valgrind 將檢查在程式執行期間動態分配的所有記憶體,並且報告未被釋放的記憶體區塊。
2. Invalid Memory Access
檢查配置記憶體是否在合法範圍之外的地方進行記憶體操作,或用了已釋放的記憶體。可能造成 segmentation fault
> segmentation fault:程式試圖存取不被允許存取或不存在的暫存位置,從而導致作業系統終止程式。
:::danger
無論標題和內文中,中文和英文字元之間要有空白字元 (對排版和文字搜尋有利)
:::
程式範例:
```c
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
int main(void) {
/* 1. Invalid write */
char *str = malloc(4);
strcpy(str, "Briant");
free(str);
/* 2. Invalid read */
int *arr = malloc(3);
printf("%d", arr[4]);
free(arr);
/* 3. Invalid read */
printf("%d", arr[0]);
/* 4. Invalid free */
free(arr);
return 0;
}
```
Valgrind 預期產生的報告輸出:
```
==13415== Invalid write of size 2
==13415== at 0x1086FA: main (case2.c:7)
==13415== Address 0x522d044 is 0 bytes after a block of size 4 alloc'd
==13415== at 0x4C2FB0F: malloc (in /usr/lib/valgrind/vgpreload_memcheck-amd64-linux.so)
==13415== by 0x1086EB: main (case2.c:6)
==13415==
==13415== Invalid write of size 1
==13415== at 0x108700: main (case2.c:7)
==13415== Address 0x522d046 is 2 bytes after a block of size 4 alloc'd
==13415== at 0x4C2FB0F: malloc (in /usr/lib/valgrind/vgpreload_memcheck-amd64-linux.so)
==13415== by 0x1086EB: main (case2.c:6)
==13415==
==13415== Invalid read of size 4
==13415== at 0x108726: main (case2.c:12)
==13415== Address 0x522d0a0 is 13 bytes after a block of size 3 alloc'd
==13415== at 0x4C2FB0F: malloc (in /usr/lib/valgrind/vgpreload_memcheck-amd64-linux.so)
==13415== by 0x108719: main (case2.c:11)
==13415==
==13415== Invalid read of size 4
==13415== at 0x10874B: main (case2.c:16)
==13415== Address 0x522d090 is 0 bytes inside a block of size 3 free'd
==13415== at 0x4C30D3B: free (in /usr/lib/valgrind/vgpreload_memcheck-amd64-linux.so)
==13415== by 0x108746: main (case2.c:13)
==13415== Block was alloc'd at
==13415== at 0x4C2FB0F: malloc (in /usr/lib/valgrind/vgpreload_memcheck-amd64-linux.so)
==13415== by 0x108719: main (case2.c:11)
==13415==
==13415== Invalid free() / delete / delete[] / realloc()
==13415== at 0x4C30D3B: free (in /usr/lib/valgrind/vgpreload_memcheck-amd64-linux.so)
==13415== by 0x10876B: main (case2.c:19)
==13415== Address 0x522d090 is 0 bytes inside a block of size 3 free'd
==13415== at 0x4C30D3B: free (in /usr/lib/valgrind/vgpreload_memcheck-amd64-linux.so)
==13415== by 0x108746: main (case2.c:13)
==13415== Block was alloc'd at
==13415== at 0x4C2FB0F: malloc (in /usr/lib/valgrind/vgpreload_memcheck-amd64-linux.so)
==13415== by 0x108719: main (case2.c:11)
```
輸出報告以換行作為每一個錯誤的輸出,依據每一個換行切分段落觀看錯誤訊息。
以第一個段落為例:
>Invalid write of size 2
at 0x1086FA: main (case2.c:7)
Address 0x522d044 is 0 bytes after a block of size 4 alloc'd
at 0x4C2FB0F: malloc (in /usr/lib/valgrind/vgpreload_memcheck-amd64-linux.so)
by 0x1086EB: main (case2.c:6)
`Invalid write of size 2` : 指出程式的錯誤
`at` : 觸發錯誤的程式位置和行數
`Address 0x522d044 is 0 bytes after a block of size 4 alloc'd` : 造成錯誤記憶體位置的詳細資訊
`by` : 錯誤發生原因的程式位置和行數
### `Linux/list.h` 中<s>常用方法</s>
:::danger
「常用」是怎麼看出來?你對整個 Linux 核心原始程式碼做分析了嗎?
:::
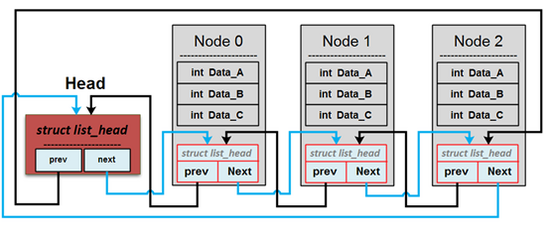
`list_head` 結構體 : struct list_head { struct list_head *prev, *next; }; 用於指定鏈結串列前/後一個 Node。
`list_add / list_add_tail`:將指定的 `node` 插入 linked list `head` 的開頭或者結尾
`list_del` : `node` 從其所屬的 linked list 結構中移走,但未被釋放需自行負責釋放。
`list_empty` : 檢查 `head` 的 `next` 是否指向自身,確認 list 是否為 empty 狀態
`list_is_singular` : 確認 linked list 是否只有一個節點。
`list_move / list_move_tail` : 將 `node` 從原本的 linked list 移動到另一個 linked list `head` 的開頭或尾端。
`list_entry` : 取出 list_head 指向物件的地址
`list_for_each` : 不能更改 `node` 的迴圈使用方法
`list_for_each_safe` : 可以移走目前的 `node` 的迴圈,透過 safe 紀錄
## 指定的佇列操作
> 注意事項:
> 1. 使用 git commit -a 取代 git commit -m
[如何寫一個 Git Commit Message](https://blog.louie.lu/2017/03/21/%E5%A6%82%E4%BD%95%E5%AF%AB%E4%B8%80%E5%80%8B-git-commit-message/)
> 2. `$ git commit --amend`:命令即可打開最近一次 Commit 的 message 檔案,提供修改。
> 3. `$ clang-format -i [modified code]` : 修改程式撰寫風格至符合專案風格
list 示意圖如下圖:
:::danger
無論標題和內文中,中文和英文字元之間要有空白字元 (對排版和文字搜尋有利)
:::
### Lab0 的目標
用鏈結串列實作的佇列。每個鏈結串列節點都有個 value 指標,指向一段連續的記憶體 (即 C-style string,以 NULL 字元結尾的字串),如下圖所示:

> queue 是一種具有先進先出 (FIFO, First-In-First-Out) 性質的資料容器,也就是最先被放入的資料會被最先取出。
<s> [資料來源](https://hackmd.io/@Ben1102/S1zcfIqnu) </s>
[更正資料來源](https://docs.oracle.com/javase/7/docs/api/java/util/Queue.html)
:::danger
優先引用權威材料。Wikpedia 本身不算權威資料,其指向的材料才是。
:::
### q_new
預防記憶體不足以新增一個 `list_head`,增加 `Return null` 的處理。
>「空」(empty) 的佇列是指向有效結構,但開頭 (head) 的值為 NULL;
根據作業要求,`INIT_LIST_HEAD` 可以滿足空佇列開頭 (head) 值為 `NULL` 的條件。
:::danger
改進你的漢語表達。
台大電機系李宏毅教授對於 ChatGPT 的看法是,要善用人工智慧的成果,一旦人們得以善用,人類的書寫不該比 GPT 一類的語言模型差。
$\to$ [2023 年 Linux 核心設計/實作課程第一次作業檢討](https://hackmd.io/@sysprog/linux2023-lab0-review)
:::
```c
/* Create an empty queue */
struct list_head *q_new()
{
struct list_head *head =
(struct list_head *) malloc(sizeof(struct list_head));
if (head == NULL)
return NULL;
INIT_LIST_HEAD(head);
return head;
}
```
:::warning
不需要額外對 `malloc` 進行轉型,亦即 `(struct list_head *)` 是多餘。請參照 C 語言規格書,以理解相關行為。
:::
:::danger
allocate 的翻譯是「配置」,以區隔 dispatch (分配/分發) 的翻譯
:::
根據 C11 標準(N1570),使用 `void *` 或其他非字元類型來接收 malloc() 返回值時,編譯器會自動執行適當的轉換。這種情形下,如果知道所<s>分配</s> 的記憶區塊實際上屬於特定的結構體類型,則可直接將它們視作該結構體類型的指標。
> C99 2007 7.20.3 Memory management functions 提到:
> The order and contiguity of storage allocated by successive calls to the **calloc**, **malloc**, and **realloc** functions is unspecified. **The pointer returned if the allocation succeeds ==is suitably aligned== so that ==it may be assigned to a pointer to any type of object== and then used to access such an object or an array of such objects in the space allocated (until the space is explicitly deallocated)**.
>
> The **lifetime of an allocated object extends from the allocation until the deallocation.** Each such allocation shall yield a pointer to an object disjoint from any other object.
>
> **The pointer returned points to the start (lowest byte address) of the allocated space.** **If the space cannot be allocated, a null pointer is returned.**
>
> If the size of the space **requested is zero, the behavior is implementation-defined**: either a null pointer is returned, or the behavior is as if the size were some nonzero value, except that the returned pointer shall not be used to access an object.
C 語言 malloc 成功時是回傳開頭位址,並且會自動對齊,因此使用上根本不需要做轉型。
```diff
/* Create an empty queue */
struct list_head *q_new()
{
- struct list_head *head =
- (struct list_head *) malloc(sizeof(struct list_head));
+ struct list_head *head = malloc(sizeof(struct list_head));
if (head == NULL)
return NULL;
INIT_LIST_HEAD(head);
return head;
}
```
### q_insert_head
<s>實做</s> 實作 `list_add` 插入節點至鏈結串列頭部。
:::warning
對照 Dictionary.com 對 [implement](https://www.dictionary.com/browse/implement) 一詞的解釋:
* to fulfill; perform; carry out:
* to put into effect according to or by means of a definite plan or procedure.
* Computers. to realize or instantiate (an element in a program), often under certain conditions as specified by the software involved.
* to fill out or supplement
「實作」會是符合上述 "implement" 語意的譯詞,取「起」以「創作」的意思,而「製造」本質上是固定輸入並通常產生固定輸出的行為。
$\to$ [資訊科技詞彙翻譯](https://hackmd.io/@sysprog/it-vocabulary)
:::
參考資料 : [你所不知道的 C 語言: linked list 和非連續記憶體](https://hackmd.io/@sysprog/c-linked-list)
```c
/* Insert an element at head of queue */
bool q_insert_head(struct list_head *head, char *s)
{
element_t *new_node = malloc(sizeof(element_t));
if (!new_node)
return false;
// 複製字串
new_node->value = malloc(strlen(s) + 1); // +1為'\0'
if (new_node->value == NULL) {
free(new_node);
return false;
}
strcpy(new_node->value, s);
list_add(&new_node->list, head);
return true;
}
```
> `make test` 警告:
> Dangerous function detected in /home/deepcat/Documents/Course/linux2024/lab0-c/queue.c
52: strcpy(new_node->value, s);
更改strcpy -> strncpy
```diff
/* Insert an element at head of queue */
bool q_insert_head(struct list_head *head, char *s)
{
element_t *new_node = malloc(sizeof(element_t));
if (!new_node)
return false;
// 複製字串
new_node->value = malloc(strlen(s) + 1); // +1為'\0'
if (new_node->value == NULL) {
free(new_node);
return false;
}
- strcpy(new_node->value, s);
+ strncpy(new_node->value, s, strlen(s) + 1);
list_add(&new_node->list, head);
return true;
}
```
### q_free
Todo Q&A:
> #define list_entry(node, type, member) container_of(node, type, member)
> 「[你所不知道的 C 語言: linked list 和非連續記憶體](https://hackmd.io/@sysprog/c-linked-list#list_entry)」中`container_of 等價的包裝,符合以 list_ 開頭的命名慣例,此處的 entry 就是 list 內部的節點。`
> 。
`container_of :「給定成員的位址、struct 的型態,及成員的名稱,傳回此 struct 的位址」`
:::danger
避免過多的中英文混用,已有明確翻譯詞彙者,例如「鏈結串列」(linked list) 和「佇列」(queue),就使用該中文詞彙,英文則留給變數名稱、人名,或者缺乏通用翻譯詞彙的場景。
:::
Q1 : Node 與 Entry 分別是什麼 / 各自差異?
A1 : 目前想法是Node 是指標且指向串列節點。而 Entry 為Node指標的實體。但有一個盲點是如果Node是指標,為何不 *Node 即可以得到 Entry
```c
/* Free all storage used by queue */
void q_free(struct list_head *l) {
struct list_head *list_iter, *_safe;
element_t *entry;
list_for_each_safe(list_iter, _safe, l) {
entry = list_entry(list_iter, element_t, list);
list_del(list_iter);
free(entry->value);
free(entry);
}
free(l);
}
```
:::warning
使用 GDB 觀察
:::
### q_insert_tail
`strncpy` : 原本使用 strcpy 在編譯時提醒為不安全的寫法,因此做了變更。使用了安全的 string copy 方法。
`list_add_tail` / `list_add` : 這兩個方法很方便的增加 node 至 鏈結串列的頭尾部
```c
/* Insert an element at tail of queue */
bool q_insert_tail(struct list_head *head, char *s)
{
element_t *new_node = malloc(sizeof(element_t));
if (!new_node)
return false;
// 複製字串
new_node->value = malloc(strlen(s) + 1); // +1為'\0'
if (new_node->value == NULL) {
free(new_node);
return false;
}
strncpy(new_node->value, s, strlen(s) + 1);
list_add_tail(&new_node->list, head);
return true;
}
```
### q_insert_head
```c
/* Insert an element at head of queue */
bool q_insert_head(struct list_head *head, char *s)
{
element_t *new_node = malloc(sizeof(element_t));
if (!new_node)
return false;
// 複製字串
new_node->value = malloc(strlen(s) + 1); // +1為'\0'
if (new_node->value == NULL) {
free(new_node);
return false;
}
strncpy(new_node->value, s, strlen(s) + 1);
list_add(&new_node->list, head);
return true;
}
```
### q_remove_head
解決 Error :
> ERROR: Attempted to free unallocated block. Address = 0x55a3f6cf93b0
ERROR: Attempted to free unallocated or corrupted block. Address = 0x55a3f6cf93b0
ERROR: Corruption detected in block with address 0x55a3f6cf93b0 when attempting to free it
Segmentation fault occurred.
添加了 `entry->value = NULL;` 以避免使用已經釋放的值。
```diff
/* Remove an element from head of queue */
element_t *q_remove_head(struct list_head *head, char *sp, size_t bufsize)
{
if (list_empty(head))
return NULL;
element_t *entry = list_entry(head->next, element_t, list);
if (entry->value != NULL) {
strncpy(sp, entry->value, bufsize);
free(entry->value);
+ entry->value = NULL;
}
// check if head is the only element
if (head->next == head->prev) {
list_del_init(head->next);
return entry;
} else {
list_del(head->next);
return entry;
}
}
```
因為無論如何都需要刪除 node 所以無需檢查是否為串列尾和頭是否為同一個
```diff
/* Remove an element from head of queue */
element_t *q_remove_head(struct list_head *head, char *sp, size_t bufsize)
{
if (list_empty(head))
return NULL;
element_t *entry = list_entry(head->next, element_t, list);
if (entry->value != NULL) {
strncpy(sp, entry->value, bufsize);
free(entry->value);
entry->value = NULL;
}
- // check if head is the only element
- if (head->next == head->prev) {
- list_del_init(head->next);
- return entry;
- } else {
- list_del(head->next);
- return entry;
- }
+ list_del(head->next);
+ return entry;
}
```
### q_remove_tail
```c
/* Remove an element from tail of queue */
element_t *q_remove_tail(struct list_head *head, char *sp, size_t bufsize)
{
if (list_empty(head))
return NULL;
element_t *entry = list_entry(head->prev, element_t, list);
if (entry->value != NULL) {
strncpy(sp, entry->value, bufsize);
free(entry->value);
entry->value = NULL;
}
// check if head is the only element
if (head->next == head->prev) {
list_del_init(head->prev);
return entry;
} else {
list_del(head->prev);
return entry;
}
}
```
因為無論如何都需要刪除 node 所以無需檢查是否為串列尾和頭是否為同一個
```diff
/* Remove an element from head of queue */
element_t *q_remove_head(struct list_head *head, char *sp, size_t bufsize)
{
if (list_empty(head))
return NULL;
element_t *entry = list_entry(head->next, element_t, list);
if (entry->value != NULL) {
strncpy(sp, entry->value, bufsize);
free(entry->value);
entry->value = NULL;
}
- // check if head is the only element
- if (head->next == head->prev) {
- list_del_init(head->prev);
- return entry;
- } else {
- list_del(head->prev);
- return entry;
- }
+ list_del(head->prev);
+ return entry;
}
```
`make test` 時 trace-07-string 一直無法正確,參照 [Jackiempty](https://github.com/Jackiempty) 程式注意到 stncpy 後<s>應當在最後一個位元設結束位元</s> ????,來避免 buffer size 小於 string 長度時無法將結束字元貼上而造成 segmentation fault。
> 應當在字串尾端設置結束位元,來避免 buffer size ${-1}$ 小於等於 string 長度時無法將結束位元貼上而造成的 segmentation fault。
> [name=HenryChaing]
:::danger
你在說什麼?位元是 bit,但字串是由一組連續的位元組 (byte) 構成。翻閱 C 語言規格書,用精準的術語來闡述你的所為。
:::
更正: 根據 C 語言規格書的規定,字串需要以一個 Null 結束位元組來表示字串的結尾。因此,在 buffersize - 1 位元組上指定 '\0',以表示字串的結束。
> $ C99 6.4.4.4 example 12 : The construction '\0' is commonly used to represent the null character.
> $ C99 5.2.1 :
> In a character constant or string literal, members of the execution character set shall be
represented by corresponding members of the source character set or by escape
sequences consisting of the backslash \ followed by one or more characters. <b>A byte with all bits set to 0, called the null character, shall exist in the basic execution character set;</b> itis used to terminate a character string.
```diff
if (entry->value != NULL) {
strncpy(sp, entry->value, bufsize);
+ sp[bufsize - 1] = '\0';
}
```
### q_delete_mid
參考[快慢指標](https://hackmd.io/@sysprog/ry8NwAMvT)實作
```c
// 快慢指標, fast 走兩步, slow 走一步, fast 到達終點時 slow 剛好是一半
while (fast->next != head->prev && fast->next->next != head->prev) {
slow = slow->next;
fast = fast->next->next;
}
slow = slow->next;
// 取出node, remove, delete
```
> 註解採用美式英文命名較恰當,參閱 [CONTRIBUTING.md](https://github.com/HenryChaing/lab0-c/blob/master/CONTRIBUTING.md#coding-convention)。
> [name=HenryChaing]
### q_delete_dup
:::danger
留意[資訊科技詞彙翻譯](https://hackmd.io/@sysprog/it-vocabulary)
:::
1. 將串列升冪排序,以便讓相同的字串或數字彼此相鄰。
2. <s>遍歷</s> 串列,刪除相鄰重複的項目。
> 可以使用走訪一詞。 參閱: [詞彙釋義]([https:/](https://hackmd.io/@sysprog/it-vocabulary#%E8%A9%9E%E5%BD%99%E9%87%8B%E7%BE%A9)/)
> [name=HenryChaing]
```c
/* Delete all nodes that have duplicate string */
bool q_delete_dup(struct list_head *head)
{
// https://leetcode.com/problems/remove-duplicates-from-sorted-list-ii/
if (!head || list_empty(head) || list_is_singular(head))
return true;
// Step 1: Sort the list in ascending order
q_sort(head, false);
// Step 2: Delete duplicate string nodes
struct list_head *li, *tmp;
bool last_dup = false;
list_for_each_safe (li, tmp, head) {
element_t *entry = list_entry(li, element_t, list);
element_t *next_entry = list_entry(tmp, element_t, list);
if (tmp != head && !strcmp(entry->value, next_entry->value)) {
last_dup = true;
list_del(li);
free(entry->value);
free(entry);
} else if (last_dup) {
last_dup = false;
list_del(li);
free(entry->value);
free(entry);
}
}
return true;
}
```
:::danger
改進你的漢語表達。
:::
### q_swap
1. 在迴圈中取出當前節點和下一個節點。
2. 交換兩個節點的值。
```c
/* Swap every two adjacent nodes */
void q_swap(struct list_head *head)
{
// https://leetcode.com/problems/swap-nodes-in-pairs/
if (head == NULL || list_is_singular(head))
return;
struct list_head *li, *tmp;
list_for_each_safe (li, tmp, head) {
if (li == head->prev)
return;
element_t *node = list_entry(li, element_t, list);
element_t *next_node = list_entry(tmp, element_t, list);
// swap node and next node string
char *tmp_string = node->value;
node->value = next_node->value;
next_node->value = tmp_string;
}
}
```
原方法是轉換字串的位置,而不是轉換整個 Node,使用現有函示+更簡潔方式轉換 Node。
```c
/* Swap every two adjacent nodes */
void q_swap(struct list_head *head)
{
// https://leetcode.com/problems/swap-nodes-in-pairs/
if (!head || list_is_singular(head) || list_empty(head))
return;
struct list_head *li, *tmp;
for (li = head->next, tmp = li->next; li != head && tmp != head;
li = li->next, tmp = li->next) {
list_move(li, tmp);
}
}
```
### q_reverse & q_reverse
:::danger
留意[資訊科技詞彙翻譯](https://hackmd.io/@sysprog/it-vocabulary)
:::
Reverse :
1. 在迴圈中取出下一個節點並將其放置於串列的頭部。
2. <s>遍歷</s>迴圈後可得到反轉的串列。
Reverse_K :
1. 在 Reverse 基礎上進行一些改變。
2. 每經過 k 次迴圈後,從前 k 個節點中取出並反轉
3. 將反轉串列放回原始串列。
```c
/* Reverse elements in queue */
void q_reverse(struct list_head *head)
{
if (list_empty(head) || list_is_singular(head))
return;
struct list_head *end = head->prev;
struct list_head *current = head->next;
while (current != end) {
struct list_head *next = current->next;
list_move(current, head);
current = next;
}
list_move(current, head); // add last node
}
```
```c
/* Reverse the nodes of the list k at a time */
void q_reverseK(struct list_head *head, int k)
{
// https://leetcode.com/problems/reverse-nodes-in-k-group/
if (!head || list_empty(head) || list_is_singular(head))
return;
struct list_head *node, *safe, target, *last_k_head = head;
int count = 0;
INIT_LIST_HEAD(&target);
list_for_each_safe (node, safe, head) {
count++;
if (count == k) {
list_cut_position(&target, safe, node); // cut k nodes
q_reverse(&target); // reverse k nodes
list_splice_init(&target, last_k_head);
count = 0;
last_k_head = safe->prev;
}
}
}
```
增加 list_head 為空的判斷,避免 segmentation fault
```c
if (!head || list_empty(head) || list_is_singular(head))
return;
```
### q_sort
:::danger
避免非必要的項目縮排 (即 `* `, `- ` 或數字),以清晰、明確,且流暢的漢語書寫。
授課教師在大學教書十餘年,見到不少學生在課堂表現不俗,但在面試場合卻無法清晰地闡述自己的成果和獨到的成就,從而錯過躋身一流資訊科技企業的機會。為此,要求學員書寫開發紀錄,並隨時做好「當主管問起,就能清晰解釋自己的投入狀況」,是強調讓學員「翻身」的本課程所在意的事。
濫用條列 (或說 bullet) 來展現,乍看很清爽,但在面試的場合中,就很難用流暢的話語說明。反之,若平日已有這方面的練習,則面試過程中,才可充分展現自己專業之處。
:::
實作 `quick sort` 遞迴版本。
1. 取出第一個節點作為 pivot。
2. 根據需求,比較 pivot 的值,將較小或較大的值放入新的串列中,然後進行分割。
3. 對新串列執行快速排序。
4. 最後將排序好的串列加回原始串列。
```c
/* Sort elements of queue in ascending/descending order */
void q_sort(struct list_head *head, bool descend)
{
struct list_head list_less, list_greater;
element_t *pivot;
element_t *item = NULL, *tmp = NULL;
if (head == NULL || list_empty(head) || list_is_singular(head))
return;
INIT_LIST_HEAD(&list_less);
INIT_LIST_HEAD(&list_greater);
pivot = list_first_entry(head, element_t, list);
list_del(&pivot->list);
list_for_each_entry_safe (item, tmp, head, list) {
if (descend == false) {
if (strcmp(item->value, pivot->value) < 0)
list_move_tail(&item->list, &list_less);
else
list_move_tail(&item->list, &list_greater);
} else {
if (strcmp(item->value, pivot->value) > 0)
list_move_tail(&item->list, &list_less);
else
list_move_tail(&item->list, &list_greater);
}
}
q_sort(&list_less, descend);
q_sort(&list_greater, descend);
list_add(&pivot->list, head);
list_splice(&list_less, head);
list_splice_tail(&list_greater, head);
}
```
預期 quick sort 可以達到 O(nlogn) 的時間複雜度,但在測資上無法通過因此改實作 Merge sort,並通過了測資 O(nlogn) 要求。
:::warning
你好,想請問 quick sort 無法達到 O(nlogn) ,除了測資以外, 還有使用什麼方式來確認或推導呢?
> 這裡我修改是因為無法通過測試項目的時間複雜度 O(nlogn),根據 [quick sort](https://zh.wikipedia.org/zh-tw/%E5%BF%AB%E9%80%9F%E6%8E%92%E5%BA%8F) 解釋,只有在極端情況下才會讓時間複雜度成為 $O(n^2)$ ,極大部分時間複雜度為 $O(n logn)$。檢查程式碼後我覺得是因為我 pivot 沒有隨機取,而是取第一個 `node` 為 `pivot`,才導致演算法沒有達到 $O(n logn)$。
:::
```c
void merge(struct list_head *l_head,
struct list_head *r_head,
struct list_head *head)
{
while (!list_empty(l_head) && !list_empty(r_head)) {
element_t *l_entry = list_entry(l_head->next, element_t, list);
element_t *r_entry = list_entry(r_head->next, element_t, list);
if (strcmp(l_entry->value, r_entry->value) <= 0)
list_move_tail(l_head->next, head);
else
list_move_tail(r_head->next, head);
}
if (!list_empty(l_head))
list_splice_tail_init(l_head, head);
else
list_splice_tail_init(r_head, head);
}
void merge_sort(struct list_head *head)
{
if (!head || list_empty(head) || list_is_singular(head))
return;
// Find middle node
struct list_head *slow = head, *fast = head;
do {
fast = fast->next->next;
slow = slow->next;
} while (fast != head && fast->next != head);
LIST_HEAD(l_head);
LIST_HEAD(r_head);
// Split list into two parts - Left and Right
list_splice_tail_init(head, &r_head);
list_cut_position(&l_head, &r_head, slow);
// Recursively split the left and right parts
merge_sort(&l_head);
merge_sort(&r_head);
// Merge the left and right parts
merge(&l_head, &r_head, head);
}
/* Sort elements of queue in ascending/descending order */
void q_sort(struct list_head *head, bool descend)
{
merge_sort(head);
if (descend)
q_reverse(head);
}
```
### q_ascend / q_descend
1. 進行升冪排序,使用迴圈尋找並比較前一個最小的值。
2. 若遇到比前一個更小的值,則從串列中刪除前一個最小值的位置到當前節點。
3. 進行降冪排序,尋找比前一個最大的值更大的值。
```c
/* Remove every node which has a node with a strictly less value anywhere to
* the right side of it */
int q_ascend(struct list_head *head)
{
// https://leetcode.com/problems/remove-nodes-from-linked-list/
struct list_head *last_biggest, *tmp, *li;
if (!head || list_empty(head))
return 0;
if (list_is_singular(head))
return 1;
element_t *last_biggest_entry = list_entry(head->next, element_t, list);
last_biggest = head->next;
list_for_each_safe (li, tmp, head) {
element_t *entry = list_entry(tmp, element_t, list);
if (li == head->prev) {
continue;
}
if (strcmp(entry->value, last_biggest_entry->value) < 0) {
while (last_biggest != tmp) {
struct list_head *next = last_biggest->next;
last_biggest_entry = list_entry(last_biggest, element_t, list);
list_del(last_biggest);
free(last_biggest_entry->value);
free(last_biggest_entry);
last_biggest = next;
}
last_biggest_entry = list_entry(last_biggest, element_t, list);
}
}
// calculate size
int size = 0;
list_for_each_safe (li, tmp, head) {
size++;
}
return size;
}
```
### q_merge
1. 將串列中所有佇列插入至第一個佇列
2. 排序第一個佇列
```c
/* Merge all the queues into one sorted queue, which is in
* ascending/descending order */
int q_merge(struct list_head *head, bool descend)
{
// https://leetcode.com/problems/merge-k-sorted-lists/
// insert all queue into one queue
queue_contex_t *output = list_entry(head->next, queue_contex_t, chain);
queue_contex_t *current = NULL;
list_for_each_entry (current, head, chain) {
if (current == output)
continue;
list_splice_init(current->q, output->q);
output->size = output->size + current->size;
current->size = 0;
}
// sort
q_sort(output->q, descend);
return 0;
}
```
:::warning
你好,我在 `q_merge` 這個函式參考了你的寫法,其中 `queue.h` 中有說明回傳值為合併後的佇列大小,我想你似乎沒注意到。
> 謝謝 我再修正!
:::
根據提醒,回傳了合併後的佇列大小:
```diff
// calculate size
+int size = 0;
+struct list_head *li, *tmp;
+list_for_each_safe (li, tmp, output->q) {
+ size++;
+}
+return size;
-return 0;
```
---
## lib/list_sort.c 並嘗試引入到 lab0-c 專案
閱讀 `lib/list_sort.c` 對於程式中的 `likely` 感到疑惑,發現這是存在於 Linux 中的巨集。
```c
# define likely(x) __builtin_expect(!!(x), 1)
# define unlikely(x) __builtin_expect(!!(x), 0)
```
<s>
[__built_expect()](https://www.ibm.com/docs/en/zos/2.4.0?topic=performance-builtin-expect) 是gcc的內建function,提供表達式和預期的值給編譯器,讓編譯器對程式碼進行優化。
</s>
:::danger
參照 GCC 手冊。
:::
而 `!!(x)` 意思,透過兩次 NOT 操作以確保值一定是 0 或 1。因為 if 內邏輯敘述的值可以是 0 或是非 0 的整數的,所以如果不做!!(x)就無法確保值一定是 0 或 1。
### 引入 list_sort.c
- 下載 list_sort.c & list_sort.h 程式至 lab0-c 專案底下,並在 queue.c 中加入標頭檔
更改 u8 至 uint8_t, 定義兩個 list_sort 中使用的兩個巨集, 刪除沒用到的 priv
```c
typedef unsigned char uint8_t;
# define likely(x) __builtin_expect(!!(x), 1)
# define unlikely(x) __builtin_expect(!!(x), 0)
```
- 修改 makefile 檔進行讓 list_sort 可以被編譯
```diff
OBJS := qtest.o report.o console.o harness.o queue.o \
random.o dudect/constant.o dudect/fixture.o dudect/ttest.o \
shannon_entropy.o \
+ list_sort.o \
linenoise.o web.o
```
詳細程式 : [df0aaf7](https://github.com/han1018/lab0-c/commit/df0aaf7f8c1ee4fc71b6082d64a3a61dee8356c9)
### 效能比較
參考 [ chiangkd ](https://hackmd.io/duPg38XOTL-XKa7_h0Ielw?view#%E7%A0%94%E8%AE%80-list_sortc-%E4%B8%A6%E5%BC%95%E5%85%A5%E5%B0%88%E6%A1%88)效能比較方法。隨機加入一百萬個 `node` 至佇列,比較 `my_sort` 和 `list_sort` 執行速度。
`qtest.c` 中 `console_init()` 中新增命令 list_sort 以及實作 do_list_sort()
```c
ADD_COMMAND(list_sort, "Sort queue in ascending order provided by linux kernel", "");
```
撰寫測試項目 traces/trace-sort.cmd
- `[sort]` 可以選擇剛新增的 `list_sort` 或是已寫好的 `sort`。(已經寫好的 `sort` 是實作 merge sort)。
- 透過 time 命令獲取 sort 執行的時間
- 設定 `--repeat 5` 重複五次
```bash
option fail 0
option malloc 0
new
ih RAND 1000000
time
[sort]
time
```
使用 `perf` 進行效能比較,參考 [Linux 效能分析工具: Perf ](https://wiki.csie.ncku.edu.tw/embedded/perf-tutorial)
- 排序執行時間
- cycles
- instructions
```shell
perf stat --repeat 5 ./qtest -f traces/trace-sort.cmd
```
排序時間:
| | my sort | list sort |
| -------- | -------- | -------- |
| 1 | 0.785s | 0.808s |
| 2 | 0.810s | 0.803s |
| 3 | 0.798s | 0.809s |
| 4 | 0.817s | 0.807s |
| 5 | 0.826s | 0.801s |
list_sort 的運行時間穩定在 0.803 的上下浮動。而 my_sort 雖然有時候比 list_sort 快,但大多數情況下比 list_sort 慢,而且在慢的時候表現更為明顯。
cycles & instructions 結果如下:
```shell
/*my sort */
Performance counter stats for './qtest -f traces/trace-sort.cmd' (5 runs):
1523.71 msec task-clock # 0.999 CPUs utilized ( +- 0.46% )
6 context-switches # 3.938 /sec ( +- 13.94% )
1 cpu-migrations # 0.656 /sec ( +- 67.82% )
3,5234 page-faults # 23.124 K/sec ( +- 0.00% )
63,2367,9181 cycles # 4.150 GHz ( +- 0.13% ) (83.35%)
1,9661,4495 stalled-cycles-frontend # 3.11% frontend cycles idle ( +- 2.03% ) (83.37%)
33,1120,7963 stalled-cycles-backend # 52.36% backend cycles idle ( +- 0.37% ) (83.37%)
50,1536,8542 instructions # 0.79 insn per cycle
# 0.66 stalled cycles per insn ( +- 0.14% ) (83.38%)
7,6236,8673 branches # 500.337 M/sec ( +- 0.13% ) (83.38%)
4822,7328 branch-misses # 6.33% of all branches ( +- 0.28% ) (83.15%)
1.52451 +- 0.00698 seconds time elapsed ( +- 0.46% )
/*list_sort */
Performance counter stats for './qtest -f traces/trace-sort.cmd' (5 runs):
1506.33 msec task-clock # 1.000 CPUs utilized ( +- 0.31% )
4 context-switches # 2.655 /sec ( +- 20.92% )
0 cpu-migrations # 0.000 /sec
3,5235 page-faults # 23.391 K/sec ( +- 0.00% )
62,7764,9618 cycles # 4.168 GHz ( +- 0.34% ) (83.32%)
2,0760,8002 stalled-cycles-frontend # 3.31% frontend cycles idle ( +- 4.76% ) (83.38%)
31,2053,1984 stalled-cycles-backend # 49.71% backend cycles idle ( +- 0.69% ) (83.38%)
49,3407,5477 instructions # 0.79 insn per cycle
# 0.63 stalled cycles per insn ( +- 0.36% ) (83.38%)
7,6812,7783 branches # 509.934 M/sec ( +- 0.20% ) (83.38%)
4863,2496 branch-misses # 6.33% of all branches ( +- 0.30% ) (83.16%)
1.50704 +- 0.00467 seconds time elapsed ( +- 0.31% )
```
整理重要項為表格 :
| | my sort | list sort |
| -------- | -------- | -------- |
| cycles | 63,2367,9181 | 62,7764,9618 |
| task clock | 1523.71 msec | 1510.40 msec |
| context switches | 6 | 4 |
| instructions | 50,1536,8542 | 49,3407,5477 |
list_sort 確實有比 my_sort 更加快速
> 可以觀察比較次數以及快取頁面失誤的改善,參閱: [共筆示範](https://hackmd.io/@sysprog/linux2022-sample-lab0#%E7%94%A8%E6%95%88%E8%83%BD%E5%88%86%E6%9E%90%E5%B7%A5%E5%85%B7%E6%AF%94%E8%BC%83-list_sortc-%E5%8F%8A%E8%87%AA%E5%B7%B1%E5%AF%A6%E4%BD%9C%E7%9A%84%E6%8E%92%E5%BA%8F)
> [name=HenryChaing]
---
## 研讀論文〈Dude, is my code constant time?〉
參考論文 [<Dude, is my code constant time?>](https://eprint.iacr.org/2016/1123.pdf) 、[dudect](https://github.com/oreparaz/dudect)、以及 [chiangkd](https://hackmd.io/@chiangkd/dudect-study)、[Lccgth](https://hackmd.io/@subsidium/linux2024-homework1#%E7%A0%94%E8%AE%80%E8%AB%96%E6%96%87-%E3%80%88-Dude-is-my-code-constant-time-%E3%80%89) 撰寫的導讀筆記
論文介紹的量測程式碼的方法 [dudect](https://github.com/oreparaz/dudect),用以量測其時間複雜度是否為常數時間 O(1)。
### 實驗方法
對執行時間進行洩漏檢測,然後分析時間分佈是否存在差異。
1. 量測方法:
採用 fix-vs-random 的方法,將第一組輸入設定為固定值,而第二組輸入則會根據每次的量測隨機設定
2. 後處理 :
在進行統計分析之前,需要對每次的量測結果進行後處理。由於大部分的量測值會集中在較小的執行時間,但也會有一小部分量測值出現特別高的執行時間,這可能導致時間分佈呈現正偏態。因此,需要對結果進行篩選或取捨,以確保統計分析的準確性。
> 負偏態 : 左右不對稱,眾數偏右,眾數>中位數>平均數。
常態 : 左右對稱,眾數在中間,眾數=中位數=平均數。
正偏態 : 左右不對稱,眾數偏左,眾數<中位數<平均數。

3. 統計測試:
使用 Welch 的 t 檢驗來測試兩組數據的時間分佈是否相等(e.g., 平均數是否相同)。如果檢驗結果顯示不相等,則可能意味著存在時間洩漏。
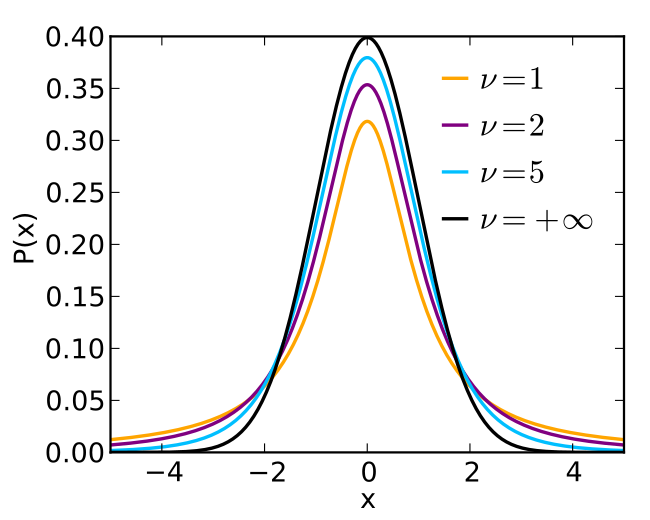
### 解釋 [Student's t-distribution](https://zh.wikipedia.org/wiki/%E5%8F%B8%E5%BE%92%E9%A0%93t%E5%88%86%E5%B8%83)
t 分佈是一種機率分佈,通常用於小樣本來估計未知標準差的母體期望值。t 分佈的自由度 v 控制其分佈的形狀,當 v 值越低時,出現極端值的概率較高,而當 v 值越高時,分佈越接近常態分佈
### 現有實作存在若干致命缺陷,請討論並提出解決方案
如同前面提到的,用小樣本來估計未知標準差的母體時可能會出現一些極端值,形成正偏態,量測出特別高的執行時間。因此,需要對結果進行篩選或取捨,以確保統計分析的準確性。
作業要求中提到「在 oreparaz/dudect 的程式碼具備 percentile 的處理,但在 lab0-c 則無」。這是一個潛在問題,如果沒有針對極端值進行篩選掉,會影響到分析的準確性。對照 lab0-c 中程式碼,確實沒有發現對 percentile 的處理。
參考了 [vax-r](https://hackmd.io/@vax-r/linux2024-homework1#%E8%A7%A3%E9%87%8B-simulation-%E5%81%9A%E6%B3%95) 對 simulation 的解釋,發現檢測常數時間的函式位於 `./dudect/fixture.c` 中。參照 `dudect` 的實作,在該檔案中增加了 percentile 處理,並補上了 dudect 實作的函式。在 doit 函式中的 update_statistics 前加入了 prepare_percentiles() 函式,去除極端值。
```c
static int cmp(const int64_t *a, const int64_t *b)
{
return (int) (*a - *b);
}
static int64_t percentile(int64_t *a_sorted, double which, size_t size) {
size_t array_position = (size_t)((double)size * (double)which);
assert(array_position < size);
return a_sorted[array_position];
}
/*
set different thresholds for cropping measurements.
the exponential tendency is meant to approximately match
the measurements distribution, but there's not more science
than that.
*/
static void prepare_percentiles(int64_t *exec_times) {
qsort(exec_times, N_MEASURES, sizeof(int64_t), (int (*)(const void *, const void *))cmp);
for (size_t i = 0; i < N_MEASURES; i++) {
exec_times[i] = percentile(exec_times, 1 - (pow(0.5, 10 * (double)(i + 1) / N_MEASURES)), N_MEASURES);
}
}
```
在 `dudect` 中 update_statistics() 放棄了前 10 個量測值,而非從頭開始,於是在 lab0-c 也做了對應的更改。
```diff
static void update_statistics(const int64_t *exec_times, uint8_t *classes)
{
- for (size_t i = 0; i < N_MEASURES; i++) {
+ for (size_t i = 10; i < N_MEASURES; i++) {
```
修改後,通過了 trace-17-complexity 測資,達到 100/100。
## 在 qtest 提供新的命令 shuffle
實作 [Fisher-Yates shuffle](https://en.wikipedia.org/wiki/Fisher%E2%80%93Yates_shuffle#cite_note-knuth-5) 演算法現代版本 - [Algorithm P (Shuffling)](https://en.wikipedia.org/wiki/Fisher%E2%80%93Yates_shuffle#cite_note-knuth-5) 對佇列洗牌
步驟:
1. 從佇列中取出最後一個節點,將其標記為 `last`,表示尚未進行隨機排序。
2. 在佇列中隨機選擇一個節點 K,與 `last` 節點進行交換。
3. 更新 `last` 為 `last` 前一個節點
4. 重複步驟 2 和 3,直到 `last` 為佇列的首節點。
時間複雜度 : O(n)
> 第四步驟的 last 應該只會移動到佇列首節點的下個節點,在你附的 Wikipedia 當中虛擬碼所述。
> [name=HenryChaing]
參考[你所不知道的 C 語言: linked list 和非連續記憶體](https://hackmd.io/@sysprog/c-linked-list#Modern-method),實作 q_shuffle 和對應的命令。
> commit : [d9c7543](https://github.com/Han1018/lab0-c/commit/d9c75430d9e6b0fd57a27c374d8eb045834f3b32)
```c
void q_shuffle(struct list_head *head)
{
if (!head || list_is_singular(head))
return;
int size = q_size(head);
struct list_head *last = head->prev;
while (last != head && --size) {
int index = rand() % size;
struct list_head *node = head->next, *temp = last->prev;
while (index--)
node = node->next;
list_move(last, node->prev);
if (node != temp)
list_move(node, temp);
last = node->prev;
}
}
```
---
## 整合 tic-tac-toe
### 轉移 ttt 至 Lab0-c 專案
轉移的方法是將 ttt 下除了 main.c 外所有的 .c 和 .h 檔案複製至 lab0-c 專案中。在 ttt 下的棋程式中,有多種演算法可供與人對弈,我首先引入至 lab0-c 專案的是 ttt 專案中預設的 negamax 演算法。
> 例如, train.c , elo.c 應該不用加入專案中。
> [name=HenryChaing]
接著,將 ttt 專案中的 main.c 程式碼複製到 qtest.c 檔案中。將控制遊戲運行的 main 函式重新命名為 do_ttt(),並在命令列中新增一個命令 ttt 來執行遊戲。
```c
ADD_COMMAND(ttt, "Tic-Tac-Toe Game", "");
```
在提交時,發現 mt19937-64.c 程式碼中有一些<s>語句</s> 敘述 (statement) 無法通過 precommit-hook 的檢查。由於希望盡可能不修改原始程式碼,因此在 pre-commit.hook 中忽略了對 mt19937-64.c 的檢查。
```shell
--suppress=nullPointer:zobrist.c \
```
> commit [d467084](https://github.com/Han1018/lab0-c/commit/d467084)
:::warning
實際需要調整的程式碼不多,你該嘗試更改。
> ok! 已做對應修改 commit [adfa401](https://github.com/Han1018/lab0-c/commit/adfa401)
:::
### Monte Carlo tree search (MCTS) 演算法
使用 mcts 取代預設的 `negamax` 演算法,並且刪除 `negamax` 相關的程式碼,mt19937-64、negamax、train.c、zobrist。
> commit [adfa401](https://github.com/Han1018/lab0-c/commit/adfa401)
TODO : 使用定點數來取代原本 jserv/ttt 的浮點數運算。
### 引入新的 option 命令,提供電腦對奕
增加 `option` 指令 `ai_mode`,讓 AI 和 AI 對弈,使用的演算法是 `negamax`。
```c
static int ai_ai_mode = 0;
if (ai_ai_mode) {
draw_board(table);
int move = negamax_predict(table, turn).move;
if (move != -1) {
table[move] = turn;
record_move(move);
}
add_param("ai_mode", &ai_ai_mode, "Set AI vs AI mode", NULL);
```
預設值為 0,欲更改時需要設定 `ai_mode` 的參數。在 `qtest` 要下的命令是:`option ai_mode 1`
> commit : [13ad69f](https://github.com/Han1018/lab0-c/commit/13ad69f)
螢幕顯示當下的時間 (含秒數):
```c
static void show_time()
{
struct timeval currentTime;
gettimeofday(¤tTime, NULL);
time_t rawtime;
time(&rawtime);
struct tm *timeinfo = localtime(&rawtime);
printf("Current Time: %02d:%02d:%02d:%02ld\n", timeinfo->tm_hour,
timeinfo->tm_min, timeinfo->tm_sec, currentTime.tv_usec / 10000);
}
```
> commit : [a52b4ca](https://github.com/Han1018/lab0-c/commit/a52b4ca)
### 引入若干 coroutine
## 問題詢問
>參考一:#define list_for_each_safe(node, safe, head) \
for (node = (head)->next, safe = node->next; node != (head); \
node = safe, safe = node->next)
> 參考二:linux/list.h 是 Linux 核心中相當實用的 circular doubly-linked list (雙向環狀鏈結串列,以下簡稱 list) 封裝,只要在自定義的結構中加入 struct list_head,就可以搭配 Linux 中一系列的 linked list 操作 (詳見The Linux Kernel API - List Management Functions) 來建立自定義結構的 linked list。
> [資料來源](https://hackmd.io/@sysprog/c-linked-list#Linked-list-%E5%9C%A8-Linux-%E6%A0%B8%E5%BF%83%E5%8E%9F%E5%A7%8B%E7%A8%8B%E5%BC%8F%E7%A2%BC)
1. 為何是 `node != (head);` 而不是`node != (head)->next` 在 `Linux/list.h` 中串列為 `circular linked list`,最後一個節點的 Next 指向的節點以為第一個?
Ans : 最後一個節點指向下一個節點的 list_head 是指向 head,這樣形成了循環<s>鏈表</s>,而第一個節點是接在 `head` 之後的。
:::danger
linked list 為「鏈結串列」,可簡稱為 list (串列),但不可稱「链表」,該資料結構不具備任何「表」的寓意,參見中華民國教育部重編國語辭典「[表](https://dict.revised.moe.edu.tw/dictView.jsp?ID=457)」,指「分格或分項以列記事物的文件」,而 linked list 作為資料結構,全然沒有「分格」和「分項」的意涵。
$\to$ [資訊科技詞彙翻譯](https://hackmd.io/@sysprog/it-vocabulary)
circular linked list 翻譯為「環狀鏈結串列」。
:::
2. <s>測資七</s>主要是測試哪些方法?嘗試用 make valgrind 找出錯誤地方但只有出現 `32 bytes in 1 blocks are still reachable in loss record 1 of 43`
:::danger
這裡是「測試項目」(item),而非「資料」(data),請查閱辭典以理解二者的差異。
> 暸解!
:::
>+++ TESTING trace trace-07-string:
> Test of truncated strings
>ERROR: Removed value meerkat_panda_squirrel_vulture_XX...省略...XXX != expected value meerkat_panda_squirrel_vulture
:::warning
TODO: 嘗試變更測試計畫
> ok!
:::
> 合併方式是當有 $3 \times 2^k$ 個節點時,合併前兩個 $2^k$ 變成 $2^{k + 1}$,並留下一個 $2^k$ 不動,維持著合併:不合併為 2 : 1 的比例,因為只要 $3 \times 2^k$ 可以放得進 L1 cache,可以避免 cache thrashing。`count` 為 pending list 中節點的數量,在 `count` 變 `count + 1` 後,可以觀察到第 `k` 個位元會改為 1,0 ~ `k - 1` 個 bit 會變 0,此時會將 2 個 $2^k$ 合併,並留下一個 $2^k$。
3. 在[Linux核心的鏈結串列排序](https://hackmd.io/-CaD-D3aS-q_-MvsoDRQqA?view#)中提到合併方式是當有 $3 \times 2^k$ 個節點時,我想請問老師 $3 \times 2^k$ 個節點的意思是什麼?因為後面提到將「$3 \times 2^k$ 可以放得進 L1 cache」時,我想到記憶體位置通常是2的倍數,這部分我無法理解為什麼是3。
Ans : [為什麼 list_sort 中串列大小的比例差距限制是 2 : 1](https://hackmd.io/-CaD-D3aS-q_-MvsoDRQqA?view#%E7%82%BA%E4%BB%80%E9%BA%BC-list_sort-%E4%B8%AD%E4%B8%B2%E5%88%97%E5%A4%A7%E5%B0%8F%E7%9A%84%E6%AF%94%E4%BE%8B%E5%B7%AE%E8%B7%9D%E9%99%90%E5%88%B6%E6%98%AF-21)
5. 「因為只要可以放得進 L1 cache,可以避免 cache thrashing」這句話不理解,<s>想請問老師下什麼關鍵字搜尋比較適合?</s>
:::danger
不要只想找關鍵字,為何不閱讀計算機組織/計算機結構的教科書呢?你需要全面而非零碎的知識來源。
> 好!會再查閱計算機組織書籍
:::
6. 閱讀[fork 帶來的 vm_area_struct 開銷](https://hackmd.io/@sysprog/unix-fork-exec#fork-%E5%B8%B6%E4%BE%86%E7%9A%84-vm_area_struct-%E9%96%8B%E9%8A%B7)時有疑問,為何講說 `fork` 後執行 `exec` 的記憶體開銷會轉瞬即逝很難捕捉到,為什麼沒辦法知道記憶體使用狀況?
> 和上個部份的分頁表開銷一樣,這個 vm_area_struct 物件的開銷也是轉瞬即逝的,很難捕捉到。無論如何這個開銷是沒有必要的,根本原因還是一樣,fork 中的全面複製沒有必要!
7. 「在執行新行程層面,clone 可僅僅 CLONE_VM 實作 LWP 來達成快速 exec,避免不必要的資源複製;
」這裡不理解為什麼 Linux 在行程 Clone 時需要設定 CLONE_VM。我查閱 linux manuel page,其說明設定 `CLONE_VM` 可以共享親代行程的記憶體空間。
> Linux manual page:
If CLONE_VM is set, the calling process and the child process run in the same memory space.
- 問題一:如果需要共享記憶體空間爲什麼不直接建立執行緒?什麼情況下會需要設定 `CLONE_VM`?
- 問題二:共享記憶體空間後 `exec` 會覆蓋既有行程,即失去 `Fork` 替換的用意?