:dart: W13 - SVM and BERT
===
<!-- ## Table of Content
[Toc] -->
## 名字:靖涵
### BERT
Bidirectional Encoder Representations from Transformers, BERT
- 與 BERT 出現以前的模型相比,特點有:可以 bidirectional 雙向地學習 context(即便是 bi-LSTM 也僅是分開學習順向和逆向後 concatenate 兩種結果)
- **Transformer**:
由 **encoder** 和 **decoder** 兩大部分組成,首先在 encoder 會把 input sequence 每個字都轉換成 embeddings(vectors embedded the meanings of the words),接著這些 embedding 就會作為 decoder 的 input 然後產出結果。
以機器翻譯為例,在 encoder 可以輸入中文 input sequence '我愛你',接著在 encoder 轉換成相對應的 embedding 後丟入 decoder 處理後產出英文翻譯 'I love you'。也就是 **sequence to sequence**。
如果只有 encoder 就是 Bidirectional Encoder Representations from Transformers (BERT);但若只有 decoder 就是 Generative Pre-trained Transformer(GPT),所以叫做生成模型,因為可以吐/生/output 出東西來。
- **BERT** vs. **GPT**
皆是 tranformer (特點為有 self-attention: 可以計算一個字對其他字重不重要,即對他們的權重是多少。)
- BERT: Transformer encoder
self-attention
會看完上下文,再去預測文字。一個字中可以看到所有文字對他的權重有多少。
要拿來用的東西是最後一個 hidden state 裡的東西,因為它包含了整個序列的資訊。
這個 hidden state 被稱為 context,是要拿來丟到 decoder 的 input。
- GPT: Transformer decoder
constrained self-attention
只能看到前一個文字,然後一直預測下一個字。
要使用 BERT 解決問題的訓練可以分作 pre-train(to understand language) 和 fine tune(to learn specific task) 兩部分:
1. Pre-training: 學會 language 和 context
包含 Masked Language Model (MLM) 和 Next Sentence Prediction (NSP)
MLM:像是學習克漏字一樣,隨機挖空句子中的部分[MASK],然後訓練 BERT 可以產出這些 masked 的地方,就會使 BERT 可以學習上下文的資訊。
NSP: 學習判斷兩個句子是否是接連出現的。
2. Fine Tuning: 依照不同要執行的任務(例如:QA問答)去調整 fully connected output layer。
[Reference_BERT_1](https://www.youtube.com/watch?v=xI0HHN5XKDo)
### Loss function 損失函數
loss function 可以用來評估模型表現,看模型預測出的結果跟實際值差距有多大,因為會希望可以最小化 loss function,代表模型預測出的結果跟真實的值更相近。常見的計算方式有下列兩者:
1. **Mean Square Error, MSE(均方誤差)/ L2 loss** :預測值 $\hat{y}_i$ 與真實值 $y_i$ 之間差異的平均平方值
$$ MSE = 1/n * Σ_{i=1}^{n} (y_i - \hat{y}_i)^2$$
因為預測資料有非常多筆,不是計算單一 $y_i$ 和 $\hat{y}_i$ 之間的差距,所以要算平均值。
另外,舉例其中 y1=0, y2=1 結果模型預測 ŷ1=50, ŷ2=-49
loss1 = y1- ŷ1 = 0–50=-50
loss2 = y2- ŷ2= 1-(-49)=50
loss1 + loss2 = -50+50=0
若單以差距值相加,正負會相抵,因此需要計算平方值。
2. **Mean Absolute Error, MAE(平均絕對值誤差)/ L1 loss** :預測值 $\hat{y}_i$ 與真實值 $y_i$ 之間差異的平均絕對值
同上面 MSE,若單以差距值相加正負相消,除了平方值可以解決這個問題,絕對值也可以解決這個問題,公式如下。
$$ MAE = 1/n * Σ_{i=1}^{n} |y_i - \hat{y}_i | $$
從兩者的算法也可以看出 L2 使用平方值會讓對 outlier 的計算較敏感。
另外在分類模型中,常使用的 loss function 有之前提到的 cross entropy。
[Reference_LossFunction_1](https://chih-sheng-huang821.medium.com/%E6%A9%9F%E5%99%A8-%E6%B7%B1%E5%BA%A6%E5%AD%B8%E7%BF%92-%E5%9F%BA%E7%A4%8E%E4%BB%8B%E7%B4%B9-%E6%90%8D%E5%A4%B1%E5%87%BD%E6%95%B8-loss-function-2dcac5ebb6cb)
[Reference_LossFunction_2](https://www.datacamp.com/tutorial/loss-function-in-machine-learning)
---
## 名字:予茜
### 支援向量機(Support Vector Machine,SVM)
特色:是一種監督式的學習方式,其概念為找到一條線將兩個類別完美的區分開來。要好好的區分,就要讓兩個類別之間的邊界(margins)**最大化**,
假設:有一個超平面(hyperplane,(wTx+b=0))可以完美分割兩組資料。SVM的目的在找出參數w和b,使兩組之間的距離最大化。
若是從正上方來看使用SVM劃分的兩個類別資料,可以發現就像是被一條虛擬的線分開了。

[pic](https://notes.andywu.tw/2020/白話文講解支持向量機二-非線性svm/)
今天兩組資料,藍色區域是w*x<-k,而粉色區域是w*x>k。兩類中各找一點X1和X2,**W**是X1向量-X2向量得到的向量投影,為**邊界**(margins)。邊界取最大值,且在Y*(W*X) **≥**k 的條件下,也就是兩條虛線中間**沒有其他資料點**,即為所求的線。(為什麼要≥k? 因為線要在粉色區域的上面,不可以比粉色區域更下面)
> 在邊界上的樣本(在容忍邊界內的樣本)稱為Support vectors,也就是X1和X2。

公式:
[pic](https://medium.com/jameslearningnote/資料分析-機器學習-第3-4講-支援向量機-support-vector-machine-介紹-9c6c6925856b)
例子:有男生和女生兩類,特徵資料為「身高」和「體重」。男生有10組資料,女生也有10組資料。
虛線到實線的距離為**邊界**(margins),而SVM就是尋找邊界最大的那個**實線**。

[pic](https://chih-sheng-huang821.medium.com/機器學習-支撐向量機-support-vector-machine-svm-詳細推導-c320098a3d2e)
[ref](https://notes.andywu.tw/2020/白話文講解支持向量機二-非線性svm/)
[ref](https://chih-sheng-huang821.medium.com/機器學習-支撐向量機-support-vector-machine-svm-詳細推導-c320098a3d2e)
### BERT
**B**idirectional **E**ncoder **R**epresentations from **T**ransformers,是理解上下文的語言模型。
特色:是google提出的語言模型。BERT 的架構是Transformer 的Encoder。就是將輸入的序列資料轉換成**向量**,之後再由 Decoder 讀取該向量的資訊後產生 output 。BERT 是傳統語言模型的變形,而語言模型(Language Model, LM)做的事情就是在給定一些詞彙的前提下,估計下一個詞彙出現的機率分佈。
公式:

在給定前t個在字典裡的詞彙,讓語言模型估計第t+1個詞彙的機率分佈 P
[pic](https://leemeng.tw/attack_on_bert_transfer_learning_in_nlp.html)
現今NLP的做法:
首先,預先訓練出一個對自然語言有一定「理解」的模型。
再將該模型拿來做特徵擷取或是處理下游的任務。
BERT總共有三個步驟。
首先是預訓練,有**兩**個步驟同時進行:
1.克漏字測驗
第一個訓練,是讓模型去預測被**masked**的詞是什麼。如果預測出兩個詞,代表兩個詞義可能是相近的,有類似的embedding。例如潮水「退」了,和潮水「落」了,可能有相似的語義。
2.預測下一個句子
第二個訓練,讓模型判斷上下兩個句子是接在一起的,還是**不是**接在一起的。CLS是一個特殊的tokens,代表要做分類。為何是放在句子的最前面,而不是最後面呢? 因為Transformer 的Encoder內部是 **self attention**的機制,兩個相鄰的字和兩個很遠的字對它來說是一樣的。

[pic](https://leemeng.tw/attack_on_bert_transfer_learning_in_nlp.html)
第二步驟:過三層嵌入(Embedding)加總取得運算用的向量,讓模型的輸入層能具備三者特徵,這三層分別為詞向量嵌入、分段向量嵌入以及位置向量嵌入。
第三步驟:將輸入的向量依序經過數層 Transformer 的編碼器形成的BERT模型,最後將模型的輸出,交給下游解決語言任務處理。
[ref](https://ndltd.ncl.edu.tw/cgi-bin/gs32/gsweb.cgi/login?o=dnclcdr&s=id="111YUNT0396039".&searchmode=basic)
BERT可以和其他不同的模型一起做訓練:
例如,輸入一個句子,要判斷它是正面還是負面,或是對文章做分類,此為體育新聞或是社會新聞,即為此例。
如何做呢?在句子的開頭放一個分類的符號(CLS),讓它去預測輸入的句子其分類為何。通常Linear classilier要從頭學習,而BERT只要微調參數,因為多數參數在BERT中已經學習得很好了。

[pic](https://leemeng.tw/attack_on_bert_transfer_learning_in_nlp.html)
[ref](https://leemeng.tw/attack_on_bert_transfer_learning_in_nlp.html)
### Naive Bayes 單純貝氏分類器
特色:
1. 以**貝氏定理**為基礎,以機率作預測。貝氏定理討論隨機事件A和B,在一個已知B事件會發生下,計算A事件發生的機率。公式為以下:

P(A│B)為已知B發生後A的機率,也稱為A的事後機率。P(A)是A事件的事前機率。P(B)是B事件的事前機率。P(B│A)為已知A事件發生後B發生的機率,也稱為B的事後機率。
[pic](https://ithelp.ithome.com.tw/m/articles/10297660)
假設:
1. 已知類別所有屬性機率**互相獨立**
2. 要找**發生機率最高**的目標P(yi|Xi),其中Xi=x1,x2, … ,xn,代表各個特徵,yi其中一個分類,而發生機率最高的P(yi|Xi)裡的yi我們稱之為**y∗**,也就是最終會預測出來的分類,為最大後驗機率(MAP)。
公式:
因各特徵互相獨立,又要取最大的後驗機率

例子:計算鐵達尼號存活率、分類文章、判別垃圾郵件等。
[ref](https://ithelp.ithome.com.tw/m/articles/10297660)
[ref](https://roger010620.medium.com/貝氏分類器-naive-bayes-classifier-含python實作-66701688db02)
---
## 名字:俞辰
### Bert
BERT 是 BiDirection Encoder Representations from Transformers 的縮寫,是 Google 開發的一種強大的自然語言處理 (NLP) 模型。
BERT 使用多層雙向 Transformer 編碼器來表示高維度空間中的輸入文字。這意味著它可以考慮句子中每個單字的整個上下文,這有助於它更好地理解文本的含義。最有趣的事情之一是它是一個預先訓練的模式。這意味著 BERT 可以在大量文字資料(例如書籍、文章和網站)上進行訓練,然後針對特定的下游 NLP 任務(包括文字分類)進行微調。
Bert的兩步驟訓練法
首先,語言文字作為一種符號的序列排列,已經存在的各種排列方式(語句)本身就蘊含了特定的規律。例如,最普遍的一個規律就是,兩個詞語如果在序列中鄰近出現的頻率高,那麼它們的語義可能就越相近。想一想,「狗」可能最經常與「犬」一起出現,也可能與「貓」在一篇文章中同時出現,但很少會與「鯨魚」、「螞蟻」或非生物詞彙一起出現。
第一步-預訓練Pretraining:BERT透過一些已經定好的任務進行預訓練,這類任務的要求是不需要進行人工標註,只要利用序列本身已有的資訊即可。原始BERT的預訓練任務有兩個:其一是「克漏字」,隨機將語句中的少數詞語遮住,然後訓練BERT模型猜出被遮住的詞語是什麼;其二是「下一句預測」,將上下相連的兩個句子中的第二句(下一句)以固定比率替換成其他句子,訓練模型判斷這個句子是否是第一句的下一句。
第二步-微調Fine-tune:實際應用場景中,我們需要文本的分類、命名實體識別、問答、摘要等等。要讓已經預訓練好的模型學會實際任務的處理方式,也同時調整它已經學到的文本的表示來適應該任務的文本語義,我們必須做fine-tune。這個步驟是在BERT模型的輸出部分設計一個自己的小模型(通常簡單的線性層即可),讓整個模型的輸出可以符合任務需要。
[Reference 1](https://medium.com/@khang.pham.exxact/text-classification-with-bert-7afaacc5e49b)
[Reference 2](https://ithelp.ithome.com.tw/articles/10260092)
### Support Vector Machines (SVM)
SVM是一種監督機器學習演算法,它透過尋找使 N 維空間中每個類別之間的距離最大化的最佳直線或超平面來對資料進行分類。
支援向量機的優點是:
* 在高維空間中有效。
* 在維度數大於樣本數的情況下仍然有效。
* 在決策函數中使用訓練點的子集(稱為支援向量),因此它也具有記憶體效率。
* 通用:可以為決策函數指定不同的核函數。提供了通用內核,但也可以指定自訂內核。
支援向量機的缺點包括:
* 如果特徵數量遠大於樣本數量,在選擇核函數時要避免過度擬合,正則化項至關重要。
* SVM 不會直接提供機率估計,這些機率估計是使用昂貴的五倍交叉驗證來計算的。
SVM演算法廣泛應用於機器學習中,因為它可以處理線性和非線性分類任務。然而,當資料不可線性分離時,可以使用核函數將資料變換到高維空間以實現線性分離。核函數的這種應用可以稱為“核技巧”,核函數的選擇取決於數據特徵和特定用途,例如線性核、多項式核、徑向基函數(RBF)核或S形核案件。
[Reference 1](https://scikit-learn.org/stable/modules/svm.html#svm-kernels)
[Reference 2](https://www.ibm.com/topics/support-vector-machine)
---
## 名字:瓈萱
### SVM (support vector machines)
是一種二元分類(Binary Classifier),是一種基於統計學習理論的監督式學習的分類演算法
- 機器學習 (ML)
著重於訓練電腦從資訊中學習,並根據經驗而有所改變,不是透過特定的程式碼一步一步叫電腦要做什麼,是讓他自己學習
- 分為監督式/非監督式/半監督式/強化式/機器學習
(1) 監督式學習:有給正確答案當範本去訓練機器(像是給機器有標記過的資料 什麼是狗 什麼不是 機器要根據這些正確答案去判別沒有標記過的料)
(2)非監督式學習:沒有給機器正確答案當作範本 透過沒標記的資料讓機器自己去辨識資料裡面的模式和關聯性,隨者資料越多、越多經驗,分類、辨識就會越準確
(3)半監督式:一半的資料有答案,一半沒答案 讓機器去學習。(就是介於監督是與非監督式的學習中間)
(4) 強化式: 隨著環境的改變,機器會慢慢調整他的行為,並評估每一個行動之後所到的回饋是正向(正確)的或負向(錯誤)的。
#### SVM 主要分為兩類 (線性SVM/非線性SVM)
(1)線性SVM
**概念:**
主要目想法目標是希望找到一條線,能將資料分為兩類,而且這條線距離兩個類別的資料越遠越好,例如線面的圖(1)中,A線會比B線好 因為如果今天突然又有另一個綠色小三角形出現(圖二)以B線條來說,他就會將綠色小三角形歸在藍色類別中,但這個綠色小三角形明明是離紅色那群比較近,應該他們要一群才對,所以可以看出B這條線他沒有很好的將資料分類。所以A這條線的分類會比較好(看以看到相比A線跟B線,A線離兩類資料的點都比較遠 所以A勝!)

圖(1)

圖(2)
- 那如何找到那條對的線呢?(去拜月老 沒)
SVM 會先計算出在不同資料類別之間最前面的那些點,這些點的距離就稱為**支持向量(support vectors)**,如下圖中綠色框框表示的東東。接下來SVM會在這些支持向量們之間找出那一條會離支持向量們有最大邊界距離的那條線,找出來的線就會是SVM 最終選擇用來分類的線。

(2) 非線性SVM
#### 概念
如果今天的資料點長得像下圖,沒有辦法用一條線去區分兩類資料時,就可以參考使用非線性SVM

- 作法:
拉高維度,將二維的資料拉到更高維度的去看
就會變看得更清楚知道可以怎樣分割資料ㄌ
像這樣:

所以運作方式是把低維度的資料點送到高維度中,並且在高維空間中找出一個超平面去分割不同類別的資料 並把低維度中的資料點送到高維度中儲存起來,然後當要預測新的資料時,資料也會被送來高維度中與『每一組』訓練資料一起運算。若運算結果大於0則被歸為一類,小於0即另一類。
[reference]([https://](https://notes.andywu.tw/2020/%e7%99%bd%e8%a9%b1%e6%96%87%e8%ac%9b%e8%a7%a3%e6%94%af%e6%8c%81%e5%90%91%e9%87%8f%e6%a9%9f%e4%ba%8c-%e9%9d%9e%e7%b7%9a%e6%80%a7svm/))
[reference]([https://](https://notes.andywu.tw/2020/%E7%99%BD%E8%A9%B1%E6%96%87%E8%AC%9B%E8%A7%A3%E6%94%AF%E6%8C%81%E5%90%91%E9%87%8F%E6%A9%9F%E4%B8%80-%E7%B7%9A%E6%80%A7svm/))
## neural network 神經網路
- 一種機器學習的架構 (是一種複雜的監督是學習)
人工智慧中的一種方法,它會建立一種可讓電腦用來從錯誤中學習並持續改善的適應型系統。因此,人工神經網路嘗試以更高準確度來解決複雜的問題,像是總結文件或圖形辨識。
概念源自於人類中樞神經系統,就如同人類神經系統,神經網路將各個神經元以節點的方式,連結各個節點,並產生想計算的結果,進而形成多層、多節點的神經網路

一個圓圈代表的就是一個neuron(神經元),然後一定數量的neuron就會構成一個layer(上圖的橘色圈圈們會形成一層layer 紫色圈圈們又是一個layer),當資料輸入進來後,就會通過第一層layer,然後輸出的結果再輸入到第二層layer,以此類推直到最後的結果出現。
基本結構:
- 輸入層(Input layer),很多神經元(Neuron)接受大量非線形輸入訊息。輸入的訊息稱為輸入向量。
- 輸出層(Output layer),訊息在神經元鏈中、分析、權衡,最後得到結果。
- 隱藏層(Hidden layer),就是不屬於input layer 跟output layer 的層 可以不只有一層
特點:可以學習和建模非線性和複雜的輸入與輸出資料之間的關係。例如,可以執行概化和推論 像是他可以知道A:您能告訴我如何付款嗎?跟B:如何轉帳? 兩個句子是相同的。
使用的領域:
圖形辨識、語音辨識、自然語言處例 等。
---
## 名字:植棻
### Transformer
**Sequence to Sequence (Seq2Seq)**
Encoder-Decoder的架構,Encoder會先將輸入句子進行編碼,得到的狀態會傳給Decoder解碼生成目標句子。

當訊息太長時,Seq2Seq 容易丟失訊息,因此引入了注意力機制 (Attention Mechanism)。其概念為將Encoder所有資訊都傳給Decoder,讓Decoder決定把注意力放在哪些資訊上。

**Transformer**
Transformer的網路架構,由Encoder-Decoder堆疊而成, Encoder-Decoder裡面的結構,有Multi-head Attention、Add&Norm、Feed Forward、Masked Multi-head Attention

結論:Encoder會利用==注意力機制==關注彼此,接著在Decoder中除了關注本身前幾層的輸出外,還會關注Encoder的輸出。這樣全部基於==attention==的架構有利於平行運算,比起 RNN、CNN 能夠得到更好的表現結果,同時還提升了訓練速度。
[Ref](https://medium.com/ching-i/transformer-attention-is-all-you-need-c7967f38af14)
### BERT
BERT全名為Bidirectional Encoder Representations from Transformers
BERT模型的結構主要為 Transformer 的編碼器 (Encoder),透過雙向 (Bidirectional) 設計讓模型能夠考慮文本字詞的前後關係,以增強模型對文本的理解,最後將理解的結果透過文字表徵 (Representation) 的方式輸出。
**BERT的機制可分為三大部分:**
1. 模型輸入
2. Encoder
3. 最終輸出
**模型輸入**
會需要將**文字符號**轉變成**向量**,因為計算機只能理解數字無法理解符號。可以理解成對文本序列中的每一個詞進行特徵抽取,抽取出來的一串特徵值組成了==高維度的向量==。
下圖是BERT的輸入架構圖:
1. 一個完整的文本序列
2. Embedding的轉換
3. 序列中每個詞語對應的多維向量
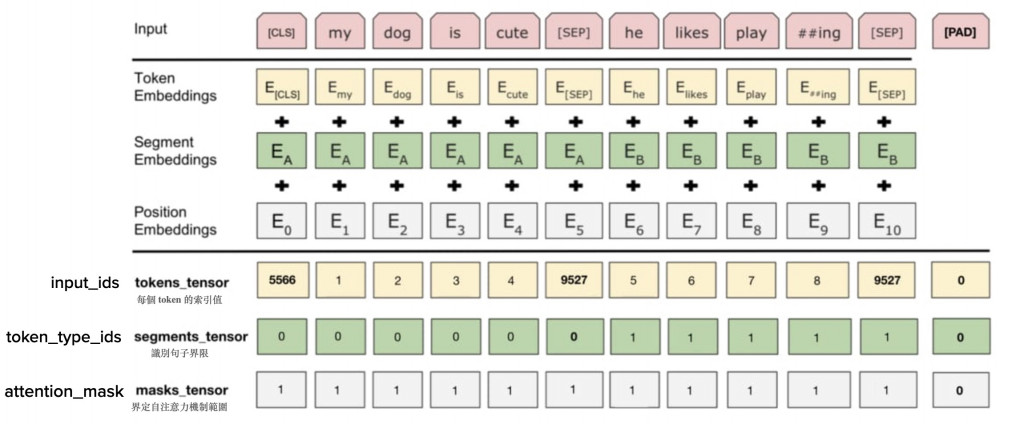
**嵌入 Embeddings**
- **Token Embeddings:詞嵌入**
Token embeddings是最淺層的詞嵌入,只能代表詞語的淺層特徵(例如字符長度之類的),還沒有包含上下文脈絡。
- **Segment Embeddings:分段嵌入**
只有兩種不同的向量,用在輸入兩個句子時,分辨token是屬於哪個句子。第一句子的詞對應一種Segment Embedding,第二句對應第二種Segment embedding。
- **Position Embeddings:序列位置的嵌入**
因為BERT是同時輸入做平行計算,而非一步步按照序列進行輸入,所以無法自然得知序列的前後順序,需要一個位置嵌入來補足。
[Ref_1](https://edge.aif.tw/aicafe-bert-20220728/)
[Ref_2](https://ithelp.ithome.com.tw/articles/10260396)
---
## 名字:喻璞
### pointwise mutual information (PMI) measure
這個指標用來衡量 兩個事物(如兩個字) 之間的相關性。
> $PMI(x;y) = log\frac{p(x,y)}{p(x)p(y)}=log\frac{P(x|y)}{p(x)}=log\frac{P(y|x)}{p(y)}$
如,想衡量 "like" 這個字的正向/負向情緒,可以先挑選出一些正向的詞,如 "good",接著計算 "like" & "good" 的 PMI:
> $PMI(like, good) = log\frac{p(like,good)}{p(like)p(good)}$
- $p(like)$ 表示 "like" 在語料庫中的機率 (freq of like/N)
- $p(like, good)$ 表示 "like" 與 "good" 在一句話中同時出現的機率 (freq of like & good/N^{2})
- $PMI(like, good)$ 的值越大,表示正向情感的傾向越明顯
[ref](https://blog.51cto.com/u_15069487/2581470)
#### Mutual information (MI) 相互資訊/互見訊息
MI是訊息理論(information theory)中的基本概念,計算的方式是兩個事件**共同出現的機率**除以個別事件出現的機率的積除再取以二為底的對數。
> $MI(x,y)=log_{2}\frac{P(x,y)}{P(x)P(y)}$
- 當MI值越高,表示詞的相連性越高。
- 當語料庫夠大時,而MI大於零,表示這兩個詞常常一起出現很可能是collocations、成語、或常見的人名、地名。
- 利用MI可以從中文語料庫中自動抽取詞彙。
[ref](https://teric.naer.edu.tw/wSite/DoDownload?xmlId=1508971&fileName=1400756267989&format=pdf)
### Machine learning algorithms
機器學習算法是一種計算模型,它使計算機能夠根據數據理解patterns,並且無需明確的code/指令就可以進行預測或做出判斷。
以下為常見的演算法:
1. Supervised Machine Learning Algorithms: 監督式學習,使用標記的數據集來訓練模型或算法。優點是有最佳的預測精度,且評估方式最簡單直接。缺點是需要成本高,標註需花費時間與金錢。
1. Linear Models:
1. Regression (e.g. Simple Linear Regression)
2. Orthogonal Matching Pursuit (OMP, e.g. Bayesian Regression)
3. Classification: Logistic Regression
2. K-Nearest Neighbors (KNN)
3. Support Vector Machines (SVM)
4. Decision Tree
5. Ensemble Learning (e.g. Random Forest)
6. Generative Model (e.g. Naive Bayes, Hidden Markov Models (HMMs))
2. Unsupervised Machine Learning Algorithms: 無監督學習,使用未標記的數據集來尋找數據集中的模式、結構或關係 (e.g. clustering: K-Means clustering)。優點為可以處理不可能標註的任務,且資料成本低。缺點是此類學習對資料的要求較高,且模型需要複雜的建模以及運算力。
3. Semi-supervised Learning Algorithm: 半監督式學習,對少部分資料進行「標註」。優點為標註成本相對較低,但缺點是需符合Low-Density Seperation假設。
監督學習、半監督學習、無監督學習的圖示 [pic](https://miro.medium.com/v2/resize:fit:1400/format:webp/0*T7wfS28ROrHNIUkH.png)
4. Reinforcement Learning: 強化學習,agent通過與周圍環境的交互來學習連續做出決策。強化學習,agent的目的是通過反覆試驗發現最佳策略。
[ref1](https://www.geeksforgeeks.org/machine-learning-algorithms/) [ref2](https://u9534056.medium.com/%E6%A9%9F%E5%99%A8%E5%AD%B8%E7%BF%92%E4%BB%BB%E5%8B%99-%E7%9B%A3%E7%9D%A3%E5%AD%B8%E7%BF%92-%E5%8D%8A%E7%9B%A3%E7%9D%A3%E5%AD%B8%E7%BF%92-%E7%84%A1%E7%9B%A3%E7%9D%A3%E5%AD%B8%E7%BF%92-9b75972f91d6)
#### Naive Bayes (NB) 單純貝氏分類器
> 貝氏定理:$P(class|data) = \frac{P(data|class)P(class)}{P(data)}$
> 最大後驗機率(特徵下事件發生機率最高的目標P(yi|Xi)):$y^{*} = arg \textup{max}_{y_{i} \epsilon y} P(y_{i})\prod_{n}^{j}P(x_{i}|y_{i})$
[例子](https://miro.medium.com/v2/resize:fit:436/format:webp/1*IaLT5fZDQhPq9IBs_TUWyg.jpeg)
假如,觀察到今天的天氣特徵(天氣=晴、溫度=適中)可判斷今天是否該取消活動。
- P(取消) = 5/14
- P(進行) = 9/14
- P(取消|天氣=晴,溫度=適中) = P(取消)P(天氣=晴|取消)P(溫度=適中|取消) = 5/14(3/5*2/5) = 0.0857
- P(進行|天氣=晴,溫度=適中) = P(進行)P(天氣=晴|進行)P(溫度=適中|進行) = 9/14(2/9*4/9) = 0.0635
- 最大後驗機率:y = arg max(P(取消|天氣=晴,溫度=適中),P(進行|天氣=晴,溫度=適中))
=arg max(0.0857,0.0635)=取消
- 機率標準化:P(取消) = 0.0857/(0.0857+0.0635)=0.5745
[ref](https://roger010620.medium.com/%E8%B2%9D%E6%B0%8F%E5%88%86%E9%A1%9E%E5%99%A8-naive-bayes-classifier-%E5%90%ABpython%E5%AF%A6%E4%BD%9C-66701688db02)
#### Maximum Entropy (MaxEnt) 最大熵
最大熵值法是一種整合各種資訊來源(infomation sources)的方法,嘗試將多個資訊來源合併成一個新的模型。
在最大熵值法中,每一個資訊來源都會引發一群限制,而這些限制的交集區域辨識代表滿足所有限制的機率分佈的集合。
此即河內的機率分佈可能有無窮多個,然而在這些機率分佈中,最高熵值(highest entropy)便是答案~
##### 例子:俗套的擲骰子
每一點的機率都是:1/6
基本限制:
- P(1)+P(2)+P(3)+P(4)+P(5)+P(6) = 1
- P(1) = P(2) = P(3) = P(4) = P(5) = P(6) = 1/6
如果我們獲得其他資訊:
- P(1) + P(2) = 1/2
得知:
- P(1) = P(2) = 1/4
- P(3) = P(4) = P(5) P(6) = 1/8
再獲得新資訊:
- P(2) + P(5) = 3/10
...
隨著越多的資訊加入,限制也越來越多,要找出所有限制最平均分配的機率就越難。
##### 公式
###### Entropy
> $H(P)=-\sum_{i=1}^{N}P(w_{i})log_{2}P(w_{i})$
當某個事件 w_{i} 的機率為1時, w = w_{i};當 w_{i} 的機率為0時,H(P) 有最小值 =0。這時,H(P)的最大值出現在每個事件間為平均分佈(uniform distribution)的情況下:
$P(w_{1})=P(w_{2})=...=\frac{1}{N}$
此時的 entropy 為 $H(P)=-log_{2}P(1/N)$。 [ref](https://api.lib.ntnu.edu.tw:8443/server/api/core/bitstreams/409a7a3e-6625-4c43-bef3-d62869bcd4ed/content)
#### Support Vector Machines (SVMs) 支援向量機
SVM是一種線性分類器,同時卻也可以推展到解決非線性的分割問題。
[pic: SVM左右兩種都可分](https://i0.wp.com/pyecontech.com/wp-content/uploads/2020/03/image-23.png?w=1280&ssl=1)
#### 原理
SVM 是將在低微度空間線性不可分的樣本映射到高維度空間去,找到一個**超平面(Hyperplane)**將這些樣本做有效的**切割**,而且,這個超平面兩邊的樣本要盡可能地遠離這個超平面。換句話說,給定有標籤的訓練數據(監督學習),該算法輸出一個最優超平面,該超平面將新的示例分類。
可用來做分類或迴歸。透過**訓練**獲得在模型,接著透過這個訓練好的模型去**預測**資料的所屬類別。
#### Margin 邊界
邊界小 vs 邊界大?
選擇邊界較大者:邊界較大者其推論錯誤率優於邊界較小者,這是因為邊界如果
太小,那麼任何些微的變動都會引起顯著的影響!
#### Kernel Function 核函數
從低維度映射到高維度的方法:由點跟點之間的 “內積” 關係來討論。
#### SVM的優缺點
1. 優點
- 核函數可以有效處理高維數據
- 不同核函數可以處理不同的資料
- 決策函數由少量的支持向量決定,預測效率高
2. 缺點
- 維度過高容易造成運算上的負擔
- 特徵遠大於樣本的情況下容易造成過度擬和的問題
[ref1](https://pyecontech.com/2020/03/24/svm/) [ref2](http://debussy.im.nuu.edu.tw/sjchen/Project_Courses/ML/SVM.pdf)
### neural networks
#### Long Short-Term Memory LSTMs
[圖示](https://miro.medium.com/v2/resize:fit:1400/format:webp/0*1Ll0xq1yxnG_Dc_T.png)
由於 Recurrent neural network (RNN) 在長期記憶的表現並不如預期,因此有了長短期記憶模型 (LSTM) 的出現。
LSTM 透過不斷重複的單元彼此相連所構成,單元彼此之間會交互作用,輸入與輸出的資料形成多組向量組成的序列。LSTM是一種特殊的 RNN,能夠學習長期依賴性。也就是說,長時間記住資訊實際上是他們的**預設行為**,而不是他們努力學習的東西!
> 演化(?):RNN → LSTM → GRU
[ref1](https://u9534056.medium.com/rnn-lstm-gru%E4%B9%8B%E9%96%93%E7%9A%84%E5%8E%9F%E7%90%86%E8%88%87%E5%B7%AE%E7%95%B0-23eba88afa1e) [ref2](https://colah.github.io/posts/2015-08-Understanding-LSTMs/)
#### Convolutional Neural Networks (CNNs/ConvNets) 卷積神經網路
[pic](http://brohrer.github.io/images/cnn5.png)
##### 卷積 convolution
每當 CNN 分辨一張新圖片時,在不知道上述特徵在哪的情況下,CNN 會比對圖片中的任何地方。為了計算整張圖片裡有多少相符的特徵,我們在這裡創造了一套**篩選機制**。這套機制背後的數學原理被稱為卷積(convolution),也就是 CNN 的名稱由來。
##### 池化 pooling
[pic](http://brohrer.github.io/images/cnn8.png)
CNNs 所使用的強大工具是池化(pooling)。池化是一個壓縮圖片並保留重要資訊的方法:池化會在圖片上選取不同窗口(window),並在這個窗口範圍中選擇一個最大值。實務上,邊長為二或三的正方形範圍,搭配兩像素的間隔(stride)是滿理想的設定。
原圖經過池化以後,其所包含的像素數量會降為原本的四分之一,但因為池化後的圖片包含了原圖中各個範圍的最大值,它還是保留了每個範圍和各個特徵的相符程度。 [ref](https://brohrer.mcknote.com/zh-Hant/how_machine_learning_works/how_convolutional_neural_networks_work.html)
### N-gram models
N-gram language model 是是統計式計算語言學中最簡單 也最常用的語言模型。
他假設一個句子第 N 個詞的**機率**可以由前面 的 N-1 個詞決定。
雖然這個假設過於簡化語言的複雜性,但在語音辨識與其它應用上不失為一個有效的方法。 [ref1](https://teric.naer.edu.tw/wSite/DoDownload?xmlId=1508971&fileName=1400756267989&format=pdf)
當N值較大時,對字詞的約束性更高,具有更高的辨識力,複雜度較高;當N值較小:字詞在文本出現的次數較多,更可靠的統計結果,但對字詞的約束性較小。 [ref2](https://medium.com/programming-with-data/7-%E5%9F%BA%E7%A4%8E%E8%AA%9E%E8%A8%80%E6%A8%A1%E5%9E%8B-n-gram-40f91a464ad1)
#### unigrams: 你、好、嗎
##### bag-of-words
##### TF-IDF being the most popular along with BTO and TO weighting schemes
#### bigram: ()你、你好、好嗎、嗎()
#### trigram: ()()你、()你好、你好嗎、好嗎()、嗎()()
當 Trigram 預測每個字的機率都是零時,可用 Bigram 和 Unigram 來輔助,稱之為 Smoothing of Language Models:
1. Back-off Smoothing
2. Interpolation Smoothing
---
## 名字:孟桁
### unsupervised sentiment analysis / supervised sentiment analysis
In the supervised approach, data required labelling in the pre-processing stage, while the unsupervised approach doesn’t. Overall the unsupervised approach is more flexible and cost-effective as they analyze text patterns and structure to determine sentiments, unlike supervised sentiment analysis which relies heavily on labels that may require updates to ensure accuracy. With sufficient labeled data and specific dataset quality, the supervised approach is usually more reliable.
### Bidirectional Encoder Representations from Transformers
A model that processes tasks with transfer learning, which is applying an old model trained through other tasks to the current project
---
<!-- ## tags, 拜託不要刪除以下 -->
###### tags: `QL2024`
<!-- ---
## 名字:
### 以下如果要用到標題請打三個以上的井字號 -->
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet