# Rebutal Decision-Transducer (DTd) for UAI_2023
# For Reviewer UNee
## <span style="color:red"> Relying to intriguing result</span>.
We're very grateful for your suggestions and definetly will update the next version of the paper to reflect our discussion.
We believe the S-A-R DTd's bad performance is different from A-S-R.
* **Confusion of R.** As shown in the plot in our last response, the performance is still increasing. While A-S-R lack the modalities to make a decision, S-A-R has states to predict. We have explained that S-A-R is very inefficient due to confusion **caused by R at the Joint encoder**. We believe that if we train it 100k steps like vanilla DT instead of 25k, it may yield reasonable performance.
* **Lacking of inteaction with action.** As shown in the Figure 1, other modalities have to interact with action in order to make a decision. Since it is the second most important cross-modal interactions, placing it at the botton will decrease the chances to expose action to other modality for cross-modal interactions. **While DTd S-R-A allows action to interact with R and S, S-A-R only allows action to interaction with R**.
We found that multimodal research [1] has tried to provide theory on why more complicated multimodal interaction should be built on uni-modal one. However, we're not aware of any research that attempts to explain why we should place important cross-modal interactions over others, which makes this direction promising or future work.
> [1] Wörtwein, T., Sheeber, L., Allen, N., Cohn, J., & Morency, L. P. (2022, December). Beyond Additive Fusion: Learning Non-Additive Multimodal Interactions. In Findings of the Association for Computational Linguistics: EMNLP 2022 (pp. 4681-4696).
## <span style="color:red"> Relying to intriguing result</span>.
Dear reviewer, we're very grateful for your time and effort to provide constructive feedback on our paper.
While current theory generally being short of analyzing such an complicated deep neural network like transformer, we would like to share our intuition on these phenomena.
Before we start to provide thoughts on A-S-R and S-A-R failures, we want to restate the design of DTd. The architecture of DTd itself actually is self-explained to the phenomenon.
* (a) The modality encoder in the center models the goal of the task.
* (b) The last layer (Joint encoder) of the DTd takes the most important modalities for decision making.
**A-S-R failure due to lack of state**
* We believe the state modality is the most important modality in decision-making. According to Powel [1], "The state variables describe what we need to know to model the system forward in time." In the paper, the Figure 1 heatmap empirically validates the importance of cross-modal interactions between states and other modalities in decision-making. Besides, among intra-model interactions, state-state interaction is still the most important one. While A-S-R variant do have a state sequence as input, the state serves as input to the center encoder and doesn't make its way to the joint encoder where the most imporant modalities (e.g. state) has to be presented for action prediction **(b)**. Without relying on the information carried by state, it is hard to obtain a good policy.
**S-A-R failure due to confusion**
1. As explaned in the paper and **(a)**, DTd's architecture is designed to take advantages of the goal modality placed at the center encoder. Generally, the modality of the goal represents the achievement targeted by the agent in the environment. For example, Both DT and TT make use of Return-to-go (Rtg) to prompt the transformer for the return it want to achieve **in the future**. Placing the action in the middle won't play a good role as a goal modality.
2. According to **(b)**, Joint encoder only takes the most important modalities to make a final decision. The S-A-R variant not only presents state to the Joint net but also the least important modality in the decision-making --- return. Our belief is that s-r at the Joint encoder creates a confusion to the model. It has to learn to ignore the return sequence and assign attention weights to the state sequence. Below is one example with hopper-medium-replay.
3.
[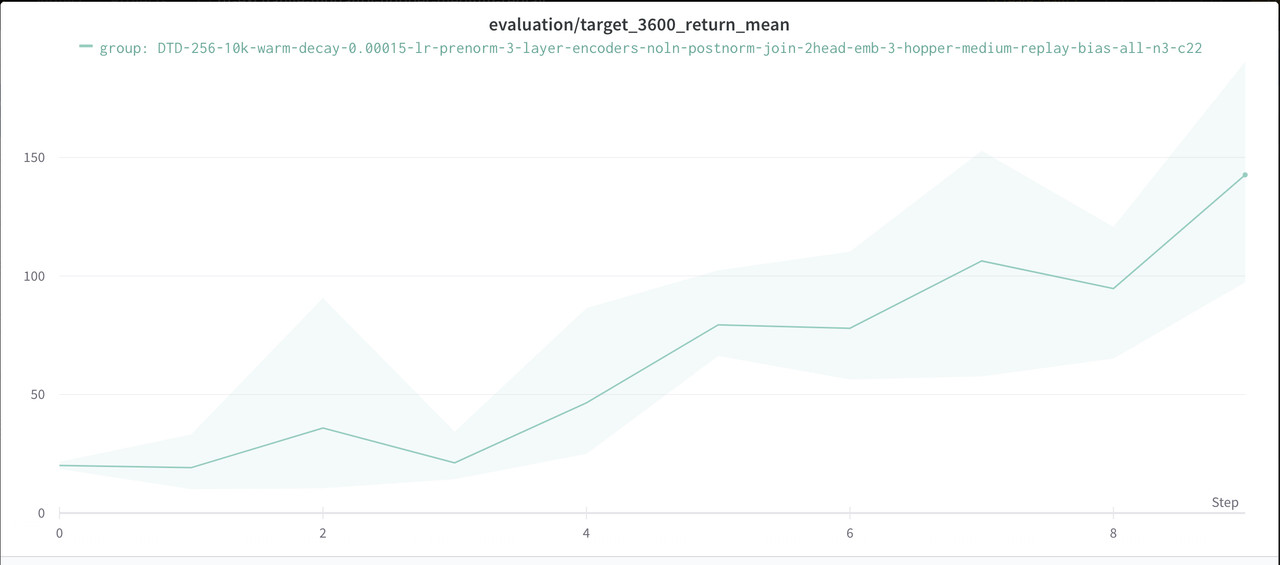](https://postimg.cc/svNM2S6g)
* The plot we presented above is a S-A-R model evaluated 10 times on hopper-MR and all other hyper-parameters are the same with DTd. The episode return at test time is very poor after training with 25k gradient steps. It is noticeable that the return is gradually increasing. We believe that's due to the DTd gradually learns to ignor less important modality (i.e. return) at the last layer. While DTd with S-R-A only have to learn a policy by taking important modalities, DTd with S-A-R has to learn to ingore 1 modality and then learns a policy based on another one. The setting of S-A-R is very ineffient.
The constructive feedback you provided is greatly appreciated. If some of the points are unclear, it is our pleasure to provide a further clarification.
> [1] Powell, W. B. (2021). Reinforcement learning and stochastic optimization.
## <span style="color:blue"> Further followup in author-reviewer discussion period</span>.
Dear Reviewer UNee
Thank you again for your time and valuable feedback. The author-reviewer discussion period is coming to an end, and we are wondering whether our response addresses your concerns. It would be appreciated if you could provide a follow-up response at your earliest convenience. We have addressed the following points so far which are summarised below for your convenience:
1. Explaination for attention score collection.
2. New ablation studies on modality ordering has been added to validate the heuristic driven architecture.
3. Motivation for adding modality embeddings while different modalities has been addressed by different encoders.
4. Reasons for DTd-zero advantages over BC
We highly appreciates your detail comments and promise to address typos, labels, and unspecified notations in the next version of the paper. Additional to the items has been addressedd above, we are happy to provide further clarifications on our responses and papers.
Best regards, Paper Authors
## Followup
Dear reviewer, we provide our thoughts and further experimental results according to your feedback.
### 1. How to compute aggregated attention scores for Figure 1?
Our apologies for not making this clearer, which is vital to understand the method proposed in the paper. We use the following notation S,A,R for State, Action, and Return in the explanation below.
Figure 1 in the paper is made of aggregated attention scores from the **last layer** of a trained Decision Transformer (DT). We believe it represents the typical modality interaction within DT since it is the most task-relevant layer. Below is the meta data of the figure 1 in the paper.
| | R | A | S |
| --- | -------- | -------- | -------- |
| R | 4 | 0 | 0 |
| A | 17 | 10 | 0 |
| S | 20 | 23 | 26 |
However, the idea of gathering attention scores across blocks/layers of DT is more reasonable. Since the interactions between modalities may vary between layers, it is crucial to gather information from all layers. Therefore, we _**conduct a new experiment to recompute the scores**_ for figure 1 **across all layers** and yields the result below:
| | R | A | S |
| --- | -------- | -------- | -------- |
| R | 4 | 0 | 0 |
| A | 20 | 12 | 0 |
| S | 19 | 23 | 22 |
High-level heuristics is the same: cross-modal interaction is more important than intra-model one (20+19+23 > 4+12+22). Interestingly, after aggregating all attention scores across all layers, state-action becomes the most significant interaction and further validates our design choices: state-action interactions should be placed at top since it is the most important (cross-modal) interaction.
We found that the importance rank of state-return and action-return changes when we collect attention scorers from all layers . In DTd's Joint net, however, data sources from left and right are treated equally. Thus, this change do not affect the current model design.
To conclude, DTd's architecture choices are further validated by the attention analysis across all layers. We will update Figure 1 and Section 4.2 according to the results of the analysis at all layers in the next version of the paper.
### 2. Experimentally validate the heuristic guided architecture.
Thank you for bringing this important point to our attention. Currently, we are not aware of any papers using attention scores to design a new model that selectively fuses two different modalities on different layers. Thus, we provide a _**new experimental results**_ on different ordering of the inputs as further ablation studies in the following two tables, and try to **validate the heuristic design based on Figure 1**.
#### New experimental results
In the Joint net of the DTd, the results from the left and right sides are weighted equally, so the main difference between the ordering of the modalities is **which modality is placed in the center**. We list the 3 valid ordering of modalities:
- S-R-A (DTd current setup where R is placed at the center)
- S-A-R (action is placed at the center)
- A-S-R (state is placed at the center)
- ~~A-R-S~~ (symmetric to S-R-A)
- ~~R-S-A~~ (symmetric to A-R-S)
- ~~R-A-S~~ (symmetric to S-A-R)
| Ordering of Modalities | Cross-modal interactions at Joint net |
| -------- | -------- |
| S-R-A (current design)| S and A |
| S-A-R | S and R |
| A-S-R | A and R |
Each of the three orderings above leads to different combinations of input modalities for the Joint net (shown above). Based on our heuristics, the only choice of modalities for Joint net is state and action, and the bottom input must be S-R-A or A-R-S. Otherwise, performance will be degraded. Here are some notations for the table below: ME (medium-expert data) MR (medium-replay)
| Setting | S-R-A (current) | S-A-R | A-S-R |
| -------------- | --------------- | ----- | ----- |
| hopper-ME | $$112.5\pm1.2$$ | $$5.1\pm1.4$$ | $$5.0\pm1.3$$ |
| walker2d-ME | $$109.0\pm0.4$$ | $$0.9\pm0.9$$ | $$0.8\pm0.2$$ |
| halfcheetal-ME | $$92.1\pm0.7$$ | $$2.1\pm0.03$$ | $$2.1\pm0.1$$ |
| hopper-MR | $$91.2\pm6.8$$ | $$5.3\pm1.4$$ | $$4.1\pm0.9$$ |
| walker2d-MR | $$81.8\pm3.0$$ | $$0.7\pm0.1$$ | $$1.0\pm0.1$$ |
| halfcheetal-MR | $$41.4\pm0.8$$ | $$2.1\pm0.09$$ | $$2.25\pm0.1$$ |
| Average | $$88.0$$ | $$2.7$$ | $$2.5$$ |
Empirical results validates our heuristics: state-action interactions should be presented to the Joint Net to take advantage of the less important cross-modal interactions below. When Joint net is presented with less-important modalities, its performance will be greatly degraded.
### 3. Reply to the detailed comments
We're thankful for your details comments. We shall address these comments in a point to point manner.
The H_{s''} and H_{a''} are the representation of states and actions after the Joint net. The prediction head for action will only apply to H_{s''}. We shall fix those typos and unspecified formula in the new version.
**1. DTd-zero doing much better than BC because of architecture?**
Yes. We belive the main difference in terms of performance is due to the architecure. The BC reported is a simple MLP implemented in DT paper [3]. We believe it is promising to close the gap between BC and DTd-zero by implementing a 1-directionall RNN as BC's architecture, similar to [4].
**2. Why includes different modality embeddings while each modality has been processed separately?**
The major reason to include modality embeddings is to facilitate the Joint net to identify the multi-modal data within a sequential inputs [1][2]. Therefore, the Joint net's self-attention will be modality-awared and likely to be more effective. Otherwise, a modal without modality embedding may believe the input is uni-modal one (e.g. vanilla DT).
In particular, we add modality embeddings at the beginning of the uni-modal encoder and relying on the cross-attention (biasing) and additive fusion (combiner) to help Joint net to be aware of the source of the data. In this caes, each source of data send to the Joint net from left or right is already multimodal and contains 2 modality embeddings fused together already. The Joint net will figure out the source of the data (left or right) and how to use them.
Lastly, we're grateful for your detail comments. We will fix the typos and unclear figure comments in the next version of the paper.
>[1] Bao, H., Wang, W., Dong, L., Liu, Q., Mohammed, O. K., Aggarwal, K., ... & Wei, F. (2022). Vlmo: Unified vision-language pre-training with mixture-of-modality-experts. Advances in Neural Information Processing Systems, 35, 32897-32912.
[2] Kim, W., Son, B., & Kim, I. (2021, July). Vilt: Vision-and-language transformer without convolution or region supervision. In International Conference on Machine Learning (pp. 5583-5594). PMLR.
[3] Chen, L., Lu, K., Rajeswaran, A., Lee, K., Grover, A., Laskin, M., ... & Mordatch, I. (2021). Decision transformer: Reinforcement learning via sequence modeling. Advances in neural information processing systems, 34, 15084-15097.
[4] Siebenborn, M., Belousov, B., Huang, J., & Peters, J. (2022). How Crucial is Transformer in Decision Transformer?. arXiv preprint arXiv:2211.14655.
# For Reviewer aYnS
Dear reviewer, we would like to thank you for your constructive suggestions and your appreciation of our novelty and experiment sections. According to your feedback, we provide our thoughts and further experimental results below.
## <span style="color:blue"> Further followup in author-reviewer discussion period</span>.
Dear Reviewer aYnS
We're very grateful to your time and valuable feedback. As the deadline for discussion approaches, we will be highly appreciated if you could provide a follow-up response at your earliest convenience. For your convenience, we provide a concise summary for the items have been addressed in our previous response:
1. Clarify training/inferencing time hyperparameter
2. We provide a further explanation for the motivation of comparing DTd-zero/DTd-left/DTd-right.
3. A new ablation study to further help reader to understand the importance of modality interaction in offline RL.
4. Explanation for why did DTd fail in some cases an how to improve it.
5. We share our opinion on DTd's influences on the long-horizon decision making problems in the future.
We promise to update the next version of the paper with the results from our discussion. If you would like more information about our response or paper, we are happy to provide it.
Best regards, Paper Authors
## Reply to weakness
### 1. Training/inferencing time, hyperparameter tuning?
Thanks for pointing out this question. We reproduce the baselines and our work DTd by strictly following the inference time hyper-parameters (initial Rtg) from the original paper. For a fair comparison, both DT and DT-large use the hyper-parameters from [1] in their inference.
Except for the batch size, learning rate (lr) schedule, gradient steps, and most of the training hyper-parameters are inherited from [1]. A detailed discussion can be found in the page 1 of the supplement material. In the next version of the paper, we will update the paper and add a brief explanation for the readers who are interested in the training/inference details in the main text.
### 2. Richer ablation study on the DTd-zero/left/right
We greatly appreciate your feedback on this point. First, we want to highlight that DTd-zero, DTd-left, and DTd-right are indeed ablations of our proposed model DTd to show the effectiveness of the proposed strategical cross-modal interactions. In addition, to further validate the design of DTd, we provide another ablation study in the section below to answer:
* Is the current choice of the input modalities (return in the center, state and action at both sides) the most appropriate one, according to the heuristics from Figure 1?
* Could we achieve good results without following the heuristics of Figure 1?
#### 2.1 _**Addinional ablations**_ on modaities choices
There exists other 2 ordering of input modalities of DTd compared to the current ordering (State, Return, Action) suggested by the heuristics from section 4.2 of the paper. S,A,R stands for State, Action, and Return below.
- S-R-A (DTd current setup suggested by heuristic)
- S-A-R
- A-S-R
- ~~A-R-S~~ (symmetric to S-R-A)
- ~~R-S-A~~ (symmetric to A-R-S)
- ~~R-A-S~~ (symmetric to S-A-R)
We _**add a new ablation**_ below to test the 3 ordering of modalities listed above, we validate that the only effective input to make DTd works is S-R-A suggested by our heuristics. Otherwise, the performacne will be degraded significantly. Some notations for the table below: ME(medium-expert data) MR(medium-replay).
| Setting | S-R-A (current) | S-A-R | A-S-R |
| -------------- | --------------- | ----- | ----- |
| hopper-ME | $$112.5\pm1.2$$ | $$5.1\pm1.4$$ | $$5.0\pm1.3$$ |
| walker2d-ME | $$109.0\pm0.4$$ | $$0.9\pm0.9$$ | $$0.8\pm0.2$$ |
| halfcheetal-ME | $$92.1\pm0.7$$ | $$2.1\pm0.03$$ | $$2.1\pm0.1$$ |
| hopper-MR | $$91.2\pm6.8$$ | $$5.3\pm1.4$$ | $$4.1\pm0.9$$ |
| walker2d-MR | $$81.8\pm3.0$$ | $$0.7\pm0.1$$ | $$1.0\pm0.1$$ |
| halfcheetal-MR | $$41.4\pm0.8$$ | $$2.1\pm0.09$$ | $$2.25\pm0.1$$ |
| Average | $$88.0$$ | $$2.7$$ | $$2.5$$ |
With further ablation on our choices of modalities above guided by the heuristics, hopefully the architecture of DTd is more convincing to the reader.
### Reply to detail comments
**1. Some baselines perform better than DTd on Table 1,2: potential future improvement.**
#### Table 1
1. With respect to the transformer family in table 1 (DT, DT-large, DT, TT), DTd achieves better results in most cases. In hopper medium), interestingly, larger models such as our DTd, DT-large and reproduced TT from [2] all yieds scores around 60% while DT as a smaller model achieves 67%. This indicates that a larger model may perform worse in this case, while a lightweight model such as DT may do better. In three of nine cases, DTd was beaten by TT, all of which were medium/medium-replays with suboptimal data quality. DTd could only repeat the trajectory within a suboptimal dataset, as it is model-free. Since TT is a model-based transformer capable of modeling its environment dynamics, it is generally able to benefit from its planning capability when data quality is poor.
2. We highlight that when the temporal difference based methods such as CQL/IQL are better than DTd, the performance of DTd only slightly worse than that of CQL/IQL, which may also partly arises from randomness. In addition, we didn't conduct hyper-parameter search for DTd but directly use all the inference hyper-parameters from DT [1] to ensure a fair comparison between DTd and its predecessor DT. So the hyper-parameters are likely to be suboptimal for our DTd. Therefore, it is promising to close the perforamance gap if we conducts a careful hyper-parameter search for DTd. For example, one direct way to boost DTd performance on all tasks is to do a Return_to_go (Rtg) search at the initial step of the evaluation.
#### Table 2
3. To further improve model-free transformer performance, we believe that manually specified Rtg should be replaced by a learned one. The multi-game decision transformer [3] provides a contribution to such a direction, by sampling a return from the transformer rather than a Rtg from humans. In addition to human-specified Rtg, some temporal difference baseline could be integrated to DTd so that the Rtg could be an estimated value function. We have made such an attempt in the antmaze experiment by combining IQL's value function and DTd, as in **table 2**. Since the value from IQL may not be stable, the DTd could not use OOD value effectively compared to DT (shown in ** Figure 4 **). While our attempt is naive, we direct readers to Q-learning Decision Transformer [4], which studies the problem of combining temporal difference methods to transformer-based method to mitigate some disadvantages of transformer (e.g. stitching).
**2. Examples of DTd's application: DTd's influences on the long-range decision making problems.**
Thanks for raising this valuable question. To answer this question, we assume long-range decision making means decision making requires many timesteps. We will try to answer this question from the following two perspectives: impact on offline RL, and beyond.
Given the fact that DTd is essentially a multimodal sequence modeling framework:
1. For offline RL task that requires many timesteps to complete (long horizon) and input is sequential and multimodal, DTd is a useful framework.For example, if the current state is not sufficient to determine the action prediction (non-markovian) or the actions are dependent to each other, modeling different modalities in a sequence like DTd will bringe advantages compares to DT or TT.
2. DTd impacts could go far beyond offline RL. DT [1] and TT [2] are in fact motivated by advances in Large Langauge Models (LLMs). Because LLM in the past were unimodel (text only), TT and DT pretents input is also unimodal. In our DTd, we demonstrate that multimodal design can improve offline RL decision-making. Since the latest LLM has started becoming multimodal (e.g. [GPT4](https://openai.com/research/gpt-4) input is image and text) and is often fine-tuned as an actor (policy) using model-free RL like PPO, it may be possible in the future to apply a multi-modal transformer (e.g. DTd) to multimodal LLMs' advancement. Another application of DTd is in instruction-following robotics research. When processing multimodal sequential input inculding visual observations, instructions, and action such as [5] [6], people typically use only one transformer, similar to DT. These areas could also benefit from our architecture.
In the next version of the paper, we will certainly revise the paper with the discussion above and share our code publically so that the reader will be given a better sense of the implementation details and potential future direction. Thank you very much for your comments.
>[1] Chen, L., Lu, K., Rajeswaran, A., Lee, K., Grover, A., Laskin, M., ... & Mordatch, I. (2021). Decision transformer: Reinforcement learning via sequence modeling. Advances in neural information processing systems, 34, 15084-15097.
[2] Janner, M., Li, Q., & Levine, S. (2021). Offline reinforcement learning as one big sequence modeling problem. Advances in neural information processing systems, 34, 1273-1286.
[3] Lee, K. H., Nachum, O., Yang, M. S., Lee, L., Freeman, D., Guadarrama, S., ... & Mordatch, I. (2022). Multi-game decision transformers. Advances in Neural Information Processing Systems, 35, 27921-27936.
[4] Yamagata, T., Khalil, A., & Santos-Rodriguez, R. (2022). Q-learning decision transformer: Leveraging dynamic programming for conditional sequence modelling in offline rl. arXiv preprint arXiv:2209.03993.
[5] Pashevich, A., Schmid, C., & Sun, C. (2021). Episodic transformer for vision-and-language navigation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 15942-15952).
[6] Shridhar, M., Manuelli, L., & Fox, D. (2023, March). Perceiver-actor: A multi-task transformer for robotic manipulation. In Conference on Robot Learning (pp. 785-799). PMLR.
# For Reviewer HMV8
## <span style="color:blue"> Further followup in author-reviewer discussion period</span>.
Dear Reviewer HMV8
We're very grateful to your time and valuable feedback. The author-reviewer discussion period is coming to an end, and we are wondering whether our response addresses your concerns or not. We're willing to provide futher clarification on our response and paper if some of your concern hasn't been stressed properly. For your convenience, we provide a concise summary for the items have been addressed in our previous response:
1. DTd initiaization with Pre-train LM.
2. Explanation on DTd's increamental improvement on 9 test cases.
We highly appreciate all your feedback and we promise to reflect our response in the next version of the paper. If you would like more information about our response or paper, we are happy to provide it.
Best regards, Paper Authors
### 1. Pre-train weights + DTd.
Thanks for raising this interesting question. We believe what your suggestion inspires an excellent future work direction for DTd and also all other transformer-based decision making models. Nevertheless, there are two reasons that we didn't involve pre-train model initiaization in this paper shown as below:
* **Not related to our main contribution**. We want to recall that our main contribution lies in the design of the multimodal architecture, rather than proposing to bridge LM and offline RL together. Incorporating our main multimodal architecture design and also the pre-training technique into the proposed algorithm simultaneously will bring more difficulty in investigating the benefits brought only by the multimodal architecture. Given the fact that "pre-train weights on text for offline RL transformer" has been explored by [1] and is less relevant for our main contribution, we decide not to include it at this moment but will definitely consider this direction as our future work.
* **Using pre-training weights is nontrivial**. Moreover, most offline RL transformers are very small (e.g. vanilla DT has only 0.73M parameters) compared to LMs (e.g. Bart or T5) when it comes to total parameters (hundreds of millions, billions), hidden state dimensions, input dimensions, number of layers, etc. Thus, it is not trivial to initialize a LM-like policy such as DT,TT with LM weights. DTd, a mix of four transformers with 2.5M parameters, makes initializing it with billions of LM weights even more difficult.
>[1] Reid, M., Yamada, Y., & Gu, S. S. (2022). Can wikipedia help offline reinforcement learning?. arXiv preprint arXiv:2201.12122.
### 2. DTd only become SOTA in 3 out of 9 evaluations.
Thank you for raising this question. Although it is every researcher's dream to come up with an approach that could surpass every baselines in every scenarios, we admit that it is hard for us to achieve this over these diverse offline RL tasks given different levels of history datasets. We provide our thoughts on this in the paragraph below.
1. In 6 out of 9 cases, DTd wins all its relatives (transformer-based approach, including DT, DT-large, and TT) that are reproduced by us with the same evaluation protocol (e.g. random seeds). Regarding this, the results indicates that formulating offline RL via multimodal sequence modeling via transformer is beneficial and boosts the performance for transformer on most conducted cases.
2. It could be possible that DTd's performance will benefit from hyper-parameter tuning. For the scores reported in the paper, we inherit most of the training hyper-parameters and all the inference hyper-parameters from DTd's predecessor DT [1]. We don't do any hyper-parameter search for DTd, in order to make a fair comparison with DT. Given the fact the DTd is larger than DT and is more sophiticated, we believe a careful hyper-parameters search will further improve DTd's performance.
>[1] Chen, L., Lu, K., Rajeswaran, A., Lee, K., Grover, A., Laskin, M., ... & Mordatch, I. (2021). Decision transformer: Reinforcement learning via sequence modeling. Advances in neural information processing systems, 34, 15084-15097.
# For Reviewer z8vL
Dear reviewer z8vl, we're glad that you found the idea of multimodal sequence modeling in RL is novel and we really appreciate your kind words for the paper's strength and the quality of experiments.
### 1. Is H^{joint} multimodal or unimodal?
Thanks for pointing out this great question. In this paper, we are making the assumption that H^{joint} could be multimodal. We believe H^{s"} and H^{a"} disentangled from H^{joint} possess different information and we only predicted action using H^{s"}. Such an idea is also validated in vanilla DT. DT chooses to predict action using state representation even it treats the input as uni-modal. If a multi-modal sequence becomes uni-modal after 3 layers of self-attention, we should be able to predict action not only on state, but also action and return.
### 2. How does DT-Large designed?
Thank you for raising this question and suggestion. Indeed, to ensure a fair comparison, we not only increase the hidden dimensions but also increase the number of the decoder blocks (layers). Recalling that the vanilla DT has 128 as the dimension of the hidden layers and possess 3 layers in total, DT-large takes 213 as the dimension of the hidden layers and uses 4 layers in total. In particular, our logic to design DT-large will be provided below:
High-level goal is to provide a fair comparison between DTd and DT-large. DT-large is design to match every perspective of DTd.
1. First, we increase the **number of layers** of DT to become similar to DTd. We argue that DTd's architecture is close to a 4-layer transformer: 3 layers of transformer (modality encoder) and 1 layer equivalent to a vanilla transformer decoder (cross-attention (biasing) + FFN (combiner), self-attention-FFN (Joint net)).Thus, we design DT-large to have 4 layers.
2. Since DTd has 3 modality encoders at the bottom where each is a 1-head 3 layer transformer, we **increase the number of heads** of DT-large from 1 to 3. The hope is to faciliate DT-large to look at the tri-modal input with 3 views so that it is similar to DTd with 3 modality encoders.
3. We **increase DT-large hidden dimension** from 128 to 213 where 213 is multiple of 3 so that DT-large could have 3 haeds. Besides, higher dimension makes DT-large's total parameters to match DTd easier.
Finally, DT-large has total parameters of 2.41M. It has the 4 layers, just like DTd. It is also capable to process tri-modal input from 3 different perspectives (DTd use 3 modality encoders, DT-large use 3 attention heads).
For futher details, you may refer to the supplement materials, which has provided a comparison of the architectures between DTd and DT-large, including total parameters, hidden dimensions, and total number of layers.
### 3. Who is responsible for OOD generalization degradation for DTd?
Thanks for raising this interesting question. Our hypothesis is that: it the biasing-combiner architecture who cause the robustness issue when encoutering OOD return.
To answer the reivewer's question and verify the hypothesis, we conduct _**additional robustness experiments**_ on DT-left/right with the same inference time hyper-parameters. Note that the biasing-combiner will force the last layer (Joint net) to consider state and action that has been fused with the return.
[](https://postimg.cc/0KPGx2Pt)
In the experiment above, we compare DTd (both state and action are fused with return), DTd-left (only state is fused with return), and DTd-right (only action is fused with return). Note that Joint net still takes bi-modal input, no matter it is DTd, DTd-left, or DTd-right. The action prediction is always based on state representation.
According to the plot, DTd-left and DTd are not robust to OOD returns. As state representation is forced to consider ODD returns **due to the biasing-combiner**, action prediction based on state is negatively affected.
Since the **biasing-combiner** in DTd-right only **force the OOD return to fuse into the action representation**, the action prediction based on state is less impacted.
Results above verify that it is the biasing-combiner architecture who contributess to the sensitiveness of DTd to OOD return. By applying biasing-combiner to the modality that participates in action prediction (states), the model achieves better performance and sample efficiency (table 1, figure 3) by taking return into account explictly. The trade off is that the OOD return will have more impact on the final prediction.
### 4. Reply to detail comments
#### Releasing the code.
Thanks for the wonderful suggestion! We will definitely release the code to Github/open source platform for the researchers to reproduce/use the idea for subsequent works.
#### Additional experiment on vanilla DT with modality embeddings.
Thank you very much for raising this questison. To better investigate this question, we _**conduct new experiments**_ to see whether DT with modality embeddings will be better than vanilla DT. Towards this, we name a vanilla DT enhanced by modality embeddings (3 types of embedding for 3 modalities) as **DT-mod**. The vanilla DT name is **DT** whose score is from the one reported in this paper.
We show the performance of **DT-mod** with comparison to that of **DT** as below, using the evaluation protocol specified in the paper. M (medium), MR (medium-replay), ME (medium-expert).
| Setting | DT | DT-mod |
| -------------- | --------------- | -------------- |
| hopper-MR | $$55.2\pm18.4$$ | $$62.8\pm18.2$$ |
| walker2d-MR | $$59.0\pm12.8$$ | $$62.9\pm12.2$$ |
| halfcheetal-MR | $$33.3\pm3.1$$ | $$37.3\pm1.2$$ |
| hopper-M | $$67.8\pm5.8$$ | $$63.4\pm7.1$$ |
| walker2d-M | $$77.8\pm4.4$$ | $$70.6\pm10.8$$ |
| halfcheetal-M | $$42.9\pm0.4$$ | $$42.9\pm0.5$$ |
| hopper-MR | $$110.6\pm1.7$$ | $$94.7\pm16.9$$ |
| walker2d-MR | $$100.6.0\pm10.8$$ | $$106.9\pm0.3$$ |
| halfcheetal-MR | $$83.2\pm3.0$$ | $$84.0\pm3.9$$ |
| Average | $$70.1$$ | $$69.5$$ |
The results show that providing modality embedding to vanilla DT provides no significant benefits with comparison to vanilla DT. Our hypothesis is that DT is generally lack of architecture with inductive bias to effectively make use of different modalities. It is designed in a way that it treats the multimodal sequential input as unimodal. Therefore, embeddings with modality information won't benefits DT significantly.
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet