# 2019q3 Homework3 (list)
<contributed by:`xl86305955`>
###### tags:`sysprog2019` `list` `Homework3`
## 自我檢查事項:
### Q1:為何 Linux 採用 macro 來實作 linked list?一般的 function call 有何成本?
Macro 與 Fumction 比較:
| | Macro | Function |
| -------- | -------- | -------- |
| 編譯階段 | Preprocessor | Compiler |
| 型態檢查 | 無 | 有 |
| 程式碼長度 | 短 | 長 |
| Side effects | 有 | 無 |
| 執行速度與成本 | 快,在 preprocessor 階段就展開成相對應程式碼, 不依賴編譯器最佳化 | 慢 ,在函式呼叫的時候 我們除了需要把參數推入特定的暫存器或是堆疊, 還要儲存目前暫存器的值到堆疊 |
| 適用場合 | 經常使用的較短程式碼 | 經常使用的較長程式碼 |
| 是否檢查 Compile errors | 無 | 有 |
參考:[Macro vs Function in C](https://stackoverflow.com/questions/9104568/macro-vs-function-in-c)
#### 何謂 macro 的 side effect ?
參考 [Duplication of Side Effects](https://gcc.gnu.org/onlinedocs/cpp/Duplication-of-Side-Effects.html)
定義 macro 如下:
```clike
#define min(X, Y) ((X) < (Y) ? (X) : (Y))
```
在以下式子中,即存在 macro 的 `side effect` ,因為在展開時, `foo(z)` 會算兩次,可能導致最終結果不一致:
```clike
next = min (x + y, foo (z));
```
展開得到兩個 `foo(z)` 在式子中,因為程式在執行時不能假設一行高階語言能夠一氣呵成執行完, 因此 `foo(z)` 結果可能會發生前後不一致之情形:
```clike
next = ((x + y) < (foo (z)) ? (x + y) : (foo (z)));
```
可以多令一個變數儲存 `foo(z)` 的值,改善前後 `foo(z)` 可能不一致之情形:
```clike
#define min(X, Y) \
({ typeof (X) x_ = (X); \
typeof (Y) y_ = (Y); \
(x_ < y_) ? x_ : y_; })
```
除此之外,為了要將值存下來,就要把型態搞定,因此使用 `typeof` 在不知 foo(z)的型態下也能正確處理
延伸:
引用自 C99 `side effect` 範例:
>Accessing a volatile object, modifying an object, modifying a file, or calling a function that does any of those operations are all side effects
簡單來說,只要 `object` 內的值更動,或是檔案被更動,都可以被稱為 `side effect`
最簡單的,如 assign 這動作就是一個 `side effect`,例如:
```clike
int i;
i = 3;
```
:::warning
C99 提及之 side effect 與 macro 的 side effect 意思並不相同, macro 的 side effect 更像是 '副作用' 的意思
:::
* 上述 [volatile](https://en.wikipedia.org/wiki/Volatile_(computer_programming)) 之註解,取材自維基百科:
> The volatile keyword indicates that a value may change between different accesses, even if it does not appear to be modifie
在 C 中, `volatile` 宣告會告訴編譯器這個變數可能隨時都會被修改,即便上下文中並沒有任何對其進行修改的語句。經由 `volatile` 宣告後,每次變數存取都會直接從變數位置讀取資料。又因為 `volatile` 不是 `atomic` 且隨時都有可能被修改,因此不是 `thread safe`,在使用時必須特別注意同步問題。若是沒有對變數宣告為 `volatile` ,在編譯器最佳化時可能會將該變數替換掉,造成程式錯誤。經常在 `memory-mapped I/O` 中使用。
在 `memory-mapped I/O` 相關範例:
`foo` 值為 0, CPU執行時會不斷輪詢 `foo` 之質直到 `foo` = `255`
```clike
static int foo;
void bar(void) {
foo = 0;
while (foo != 255)
;
}
```
因為在上述程式中,沒有任何值對 `foo` 有修改更動的動作,因此在編譯器最佳化時會把 while 中條件修改:
```clike
void bar_optimized(void) {
foo = 0;
while (true)
;
}
```
然而 `foo` 可能是個共享變數,不同 thread 之間都有可能來存取 `foo` 之質,若 `foo` 沒有宣告為 `volatile` ,會因爲編譯器最佳化而導致程式發生錯誤。因此將 `foo` 宣告為 `volatile` :
```clike
static volatile int foo;
void bar (void) {
foo = 0;
while (foo != 255)
;
}
```
#### 執行速度與成本
在 [你所不知道的C語言:技巧篇](https://hackmd.io/@sysprog/HyIdoLnjl?type=view) 中 `Linked list 的各式變種` 提及, function call 因為需要把參數推入特定暫存器或堆疊,及儲存目前的暫存器的值至堆疊。隨著呼叫次數提升,這些動作會造成運作時比使用 macro 還慢
#### 結論
綜合表格內的種種特性,因為 linux kernel 中大量使用 linked list ,且 linked list 具操作簡單,程式碼較短之特性;又 macro 在大量執行上會比 function call 來的快。因此 linux kernel 選擇使用 macro 而不是 function call
---
### Q2:Linux 應用 linked list 在哪些場合?舉三個案例並附上對應程式碼,需要解說,以及揣摩對應的考量
Linked list 最大好處就是,不需要在撰寫程式時就訂定好大小,能在有需要時動態增加釋放空間,使用上有非常大的彈性;而 array 在宣告初期,需事先告知大小,無法動態增加或刪除,對於資料的動態增刪非常不利
除了動態增刪的特點,允許不連續的儲存空間也是 linked list 的特點之一。且 linked list 結構簡單,在實作與維護上也較為輕鬆
因此,在 linux kernel 中有關 linked list 的應用,大多符合這些特點,像是 [你所不知道的C語言:技巧篇](https://hackmd.io/@sysprog/HyIdoLnjl?type=view) 提到的:
* Process Management
* inode
* Network File System (NFS)
Process、檔案系統皆可能在任何時間做新增刪除的動作,因此配置的記憶體空間不一定為連續,且記憶體空間也可以動態增刪,符合 linked list 之特性
另外像是:
* hash table : [hashtable.h](https://github.com/torvalds/linux/blob/6f0d349d922ba44e4348a17a78ea51b7135965b1/include/linux/hashtable.h)
定義在 `list.h`:
```cpp
/*
* Double linked lists with a single pointer list head.
* Mostly useful for hash tables where the two pointer list head is
* too wasteful.
* You lose the ability to access the tail in O(1).
*/
#define HLIST_HEAD_INIT { .first = NULL }
#define HLIST_HEAD(name) struct hlist_head name = { .first = NULL }
#define INIT_HLIST_HEAD(ptr) ((ptr)->first = NULL)
static inline void INIT_HLIST_NODE(struct hlist_node *h)
{
h->next = NULL;
h->pprev = NULL;
}
static inline void hlist_add_head(struct hlist_node *n, struct hlist_head *h)
{
struct hlist_node *first = h->first;
n->next = first;
if (first)
first->pprev = &n->next;
WRITE_ONCE(h->first, n);
n->pprev = &h->first;
}
```
在註解中提到:
>Mostly useful for hash tables where the two pointer list head is too wasteful
其中 `two pointer` 是指 lsit head 中的 `next` 跟 `prev` ,而 `hlist` 是特別為 hash table 所設計
Hash table 結構如下,其中 `hlist_node` 中具有 next 指標,與 `pprev` 指標的指標指向前一個 node:
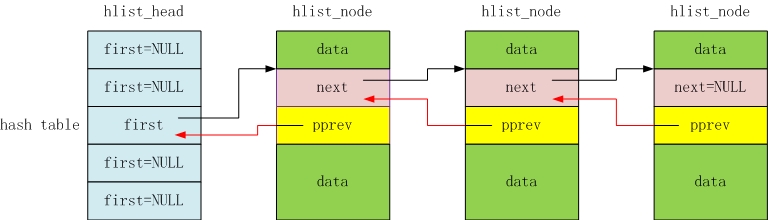
定義在 `hashtable.h`,以新增為例:
```cpp
/**
* hash_add - add an object to a hashtable
* @hashtable: hashtable to add to
* @node: the &struct hlist_node of the object to be added
* @key: the key of the object to be added
*/
#define hash_add(hashtable, node, key) \
hlist_add_head(node, &hashtable[hash_min(key, HASH_BITS(hashtable))])
```
參數 `key` 會決定 node 分配到哪個 bucket,若有碰撞產生,則加至該 bucket 的第一個,假設 obj1 比 obj9 早進入 hash table:
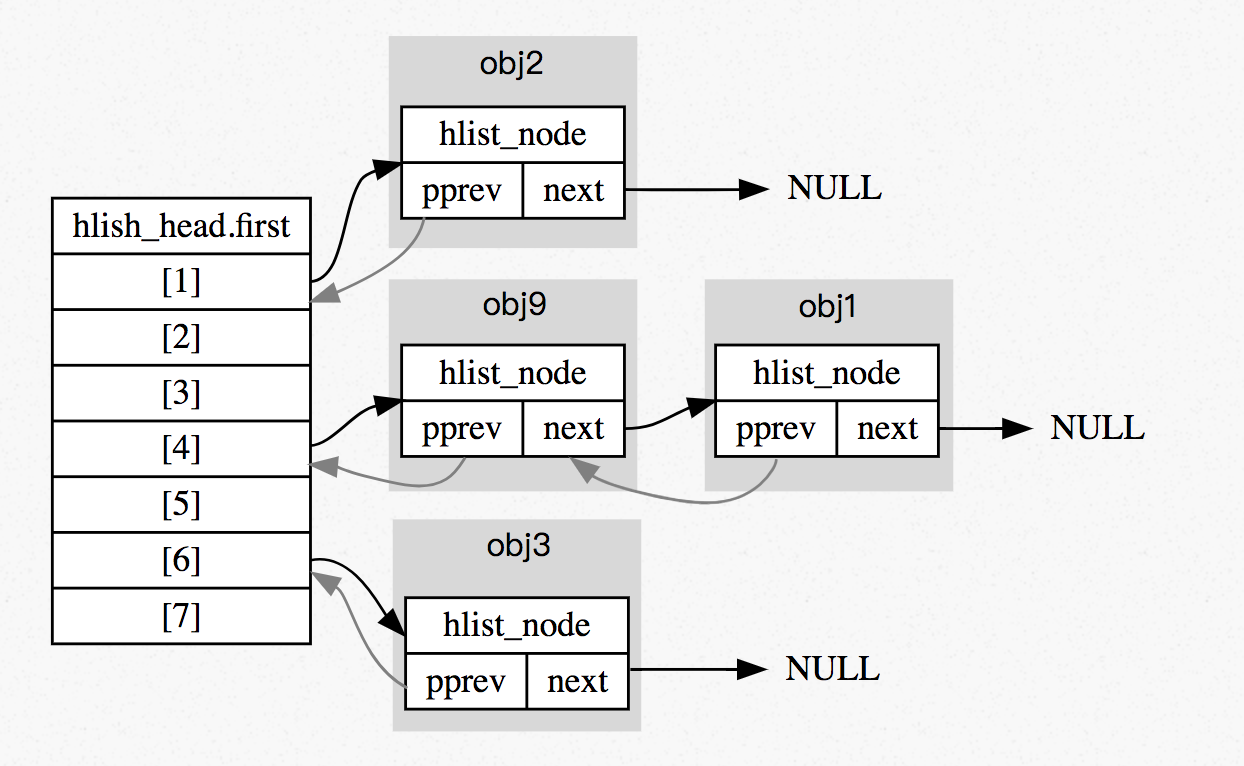
參考資料:[linux kernel中HList和Hashtable](http://liujunming.top/2018/03/12/linux-kernel%E4%B8%ADHList%E5%92%8CHashtable/)
#### 什麼是 WRITE_ONCE
待補充
----
### Q3:GNU extension 的 [typeof](https://gcc.gnu.org/onlinedocs/gcc/Typeof.html) 有何作用?在程式碼中扮演什麼角色?
除了標準以外,有時候也需要用到標準以外的東西,這就是為何需要 extension,如處理最佳化、debugging 等等
在處理巨集時,因為通常無法預先得知正確的參數型態,若需要宣告變數時,可使用 typeof 正確宣告型態
範例:
```clike
int a;
typeof(a) b; // 宣告一個 int 型態的變數 b
char s[6] = 'Hello';
char *ch;
typeof(ch) k = s; // 宣告 k 為 char 的指摽指向 s 之位置
```
----
### Q4:解釋以下巨集的原理
```cpp=
#define container_of(ptr, type, member) \
__extension__({ \
const __typeof__(((type *) 0)->member) *__pmember = (ptr); \
(type *) ((char *) __pmember - offsetof(type, member)); \
})
```
* line 2 `__extension__` :GCC 有許多對 C 語言的擴展,若不是使用 Ansi C 開發,沒有透過`__extension__` 告訴編譯器,編譯器就會跳出警告,使用 `__extension__` 即是提醒編譯器不要提出警告
* line 3:宣告一個 `const __typeof__(((type *) 0)->member)` 型態的指標 `_pmember`,所指向的位置與 `ptr` 相同
* const :不允許變數被改變
* __typeof__ :若在 ISO C 規範下執行,需使用 __typeof__
* ((type *)0)->member:為一個 NULL pointer
這樣 line 3可以看成:宣告 `_pmember` 為一個型態與指向 member 的指標相同的指標,其中指向 `ptr ` 的位置
* line 4:透過 offsetof 算出 struct 的起始位置,即 (x + offset) 為 member 位置,也就是_pmember 指向的位置;(x + offset) - offset 得到的就是起始位置
簡單來說:得知了 struct 中其中一個成員的位置後,透過 `offsetof` 即可由此推算整個 struct 的起始位置

----
### Q5:除了你熟悉的 add 和 delete 操作,`list.h` 還定義一系列操作,為什麼呢?這些有什麼益處?
Linux kernel 中的 linked list 採用 `Abstract Data Type` 之設計,定義了一系列操作,使用者僅需知道裡面定義的功能,不需知道內部是如何實做的。這樣使程式變得乾淨整潔,開發者使用時也不需要做多餘的描述,而維護上也變得更加簡單
* 新的節點取代舊的節點
```clike
/**
* list_replace - replace old entry by new one
* @old : the element to be replaced
* @new : the new element to insert
*
* If @old was empty, it will be overwritten.
*/
static inline void list_replace(struct list_head *old,
struct list_head *new)
{
new->next = old->next;
new->next->prev = new;
new->prev = old->prev;
new->prev->next = new;
}
```

* 兩個 list 串接成一條新 list
```clike
static inline void __list_splice(const struct list_head *list,
struct list_head *prev,
struct list_head *next)
{
struct list_head *first = list->next;
struct list_head *last = list->prev;
first->prev = prev;
prev->next = first;
last->next = next;
next->prev = last;
}
```

----
### Q6:`LIST_POISONING` 這樣的設計有何意義?提示: 和 [Linux 核心記憶體管理](https://hackmd.io/@sysprog/rJBXOchtE)有關
----
### Q7:linked list 採用環狀是基於哪些考量?
* 環狀使得實作上更加方便,因為串列的頭端跟尾端可以視為與其他節點一樣,不需要考慮特別的 case 做額外處理
----
### Q8:什麼情境會需要對 linked list 做排序呢?舉出真實世界的應用,最好在作業系統核心出現
如 CPU 排班。 process 宣告時, 在 kernel 記憶體空間中會配置給每個 process 一個 block 稱為 `Process Control Block` ,紀錄所有有關 process 之所有相關資訊,像在 `scheduling info` 中,就會記載排班有關資訊,如:優先權、到達時間等等
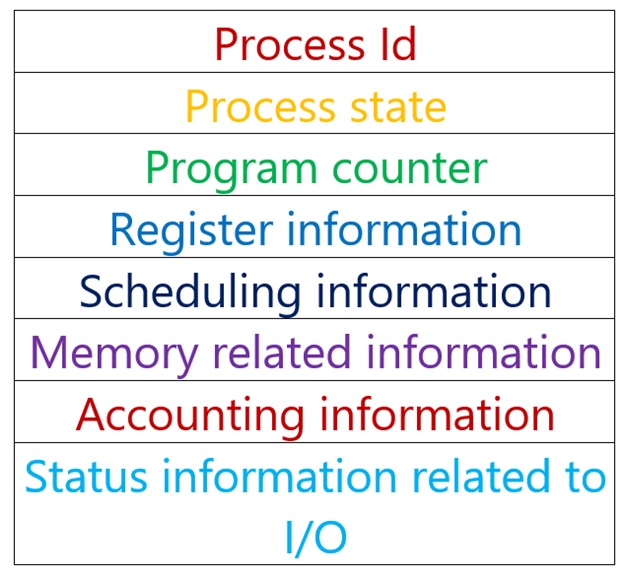
當 process 抵達 ready queue 時,kernel 則會根據 PCB 中 `scheduling info` 的資訊進行排班。而其中 `ready queue` 就是以 linked list 作為它的資料結構
假設今天是以優先權做排班,在 ready queue 中記載各 PCB 位置的 linked list 會從中排出一個由大優先權大到優先權小的序列,讓 process 進入 cpu 執行。除此之外, PCB 也紀錄 I/O 資訊,因此 I/O 排班也可透過 linked list sorting 達成

另外像是指令`$ htop` 可以對 process cpu 使用率作排序而 cpu 使用率即是記載在 PCB 的 `Accounting info` 中:

----
### Q9:什麼情境會需要需要找到 [第 k 大/小元素](https://www.geeksforgeeks.org/kth-smallestlargest-element-unsorted-array/) 呢?又,你打算如何實作?
利用 `prune and search` 實作:
* Divide and Conquer 策略
Input:一組數字 $S$ ,其中包含 n 個元素
Output:$S$ 中第 `kth` 大/小的元素
Step 1:將 $S$ 分成 $\lceil \frac{x}{5} \rceil$ 個 group,即每個 group 中有 5 個元素
Step 2:針對每個 group 中五個元素做排序
Step 3:針對 $\lceil \frac{x}{5} \rceil$ 個 group 中的第 `3` 個元素,遞迴尋找出 `median of median` `p`
Step 4:將 $\lceil \frac{x}{5} \rceil$ 個 group 中第 `3` 個元素根據剛找出的 `median of median` `p`,分成 $S_1$、$S_2$、$S_3$ 的子集其中:
* $S1 = { a_i | a_i < p , 1 \leq i \leq n}$
* $S2 = { a_i | a_i = p , 1 \leq i \leq n}$
* $S3 = { a_i | ai_ > p , 1 \leq i \leq n}$
Step 5: 分成三個case
* case 1:若 k $\leq$ p,k $\in$ $S_1$ ,去掉 $S_2$、$S_3$ 搜尋 $S_1$
* case 2:若 k = p ,搜尋 $|S_1|$ + $|S_2|$
* case 3:若 k $\geq$ p ,去掉 $S_1$、$S_2$,搜尋 $S_3$

每次大約去掉四分之一的資料量,這是 `divide` 的部分,搜尋比原資料量的較小的子集即是 `conquer`
:::success
Time complexity of prune and search : $O(n)$
:::
----
### Q10:list_for_each_safe` 和 `list_for_each` 的差異在哪?"safe" 在執行時期的影響為何?
* 參考: [直播錄影1:23:00](https://youtu.be/0B0GNPv02zg?t=4980)
有 safe 版本意味著存在著額外的考量,list_for_each_safe 註解中也寫到,這是一個考量到 head 被刪除的版本
```clike
/**
* list_for_each - iterate over a list
* @pos: the &struct list_head to use as a loop cursor.
* @head: the head for your list.
*/
#define list_for_each(pos, head) \
for (pos = (head)->next; pos != (head); pos = pos->next)
```
在 list_for_each_safe 中,多令一個變數 n 指向下一個的下一個,可以預防像是在 head 被刪除的情形下,在快走完整個 list 時仍舊找得到下一個節點在哪。雖然多花了空間,但是也因為 `n = pos->next` 判斷式能夠少走一次
```clike
/**
* list_for_each_safe - iterate over a list safe against removal of list entry
* @pos: the &struct list_head to use as a loop cursor.
* @n: another &struct list_head to use as temporary storage
* @head: the head for your list.
*/
#define list_for_each_safe(pos, n, head) \
for (pos = (head)->next, n = pos->next; pos != (head); \
pos = n, n = pos->next)
```
----
### Q11:for_each 風格的開發方式對程式開發者的影響為何?
:::info
提示:對照其他程式語言,如 Perl 和 Python
:::
使得程式具有更高的可讀性,讓開發者能夠省略一些 index 敘述,能用更貼近人的思考方式撰寫,eg:
```python
num_list = [1, 2, 3]
for num in num_list:
print num
```
若是 linux kernel 中的 linked list 未將其設計成 ADT,日後其他程式開發人員將在 index 閱讀上花大量時間。這也是 ADT 的好處,只管實作,不管內部如何實作
----
### Q12:程式註解裡頭大量存在 `@` 符號,這有何意義?你能否應用在後續的程式開發呢?
:::info
提示: 對照看 Doxygen
:::
#### 什麼是 Doxygen
註解與文件皆為在軟體開發時不可或缺的元素,註解能使自己及其他開發者了解程式碼,以便日後維護;而文件則可使剛接著到專案時能夠快速進入狀況
__Doxygen 就是一種文件產生工具,其中一個功能就是,只要按照規定格式撰寫註解,Doxygen 即可幫你產生出對應的文件內容__
如此一來,程式開發者就不需要花額外的心力在文件上,修改程式碼中的註解內容,文件中內容也會跟著一並修改
#### `@` 符號
像是在 link_add 註解中, `@` 後面緊接的就是 list_add 函數中的參數
```clike
/**
* list_add - add a new entry
* @new: new entry to be added
* @head: list head to add it after
*
* Insert a new entry after the specified head.
* This is good for implementing stacks.
*/
```
----
### Q13:`tests/` 目錄底下的 unit test 的作用為何?就軟體工程來說的精神為何?
unit test 的精神在於,把程式中的 function 依照功能切分成一個個獨立的測試單位,確保程式執行如同預期設計時的一樣,能夠在系統中正確無誤執行,且能確保程式碼之品質,進而加速程式開發速度
unit test 在大型系統中尤其重要,因為無法確保在加入新的 function 後原先系統會不會因此出錯而導致系統無法運作。除此之外,程式在開發初期,function 與 function 可以拉出來獨立測試,就不需要等到整個都程式撰寫完後,按下 compile 鍵才知道測試結果
#### 相關補充:Test-driven development (TDD)
Test-driven development 從字面上看就是,“測試推動開發”。正如其中意思,在程式開發時,先撰寫測試檔,再著手進行程式功能中的內容
TDD 好處是,能夠使開發者模組化整個程式,透過單位測試使得目標程式能夠更為精簡,在撰寫測試程式時,事先想好整個目標程式的架構,且能保證目標程式能夠正確執行
Step 1:思考如何設計目標程式,撰寫好其測試程式
Step 2:編譯測試程式是否有誤,而目標程式內容尚未開始撰寫,因此測試失敗
Step 3:實作目標程式
Step 4:確保程式通過測試程式
Step 5:優化目標程式,並確保程式可讀性、可維護性、擴充性等等,每次修改皆要保證能夠通過測試程式
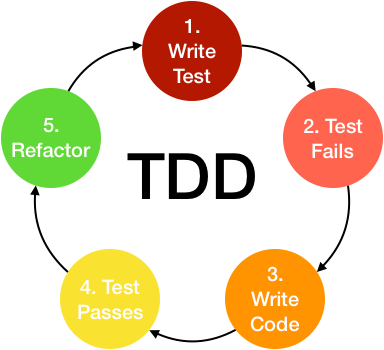
相關資料:[TDD 開發五步驟,帶你實戰 Test-Driven Development 範例](https://tw.alphacamp.co/blog/tdd-test-driven-development-example)
----
### Q14:`tests/` 目錄的 unit test 可如何持續精進和改善呢?