# Introduction to Elasticsearch
Matthew Worthington
Developer @ ThoughtWorks
github.com
/worthington10TW/ElasticsearchBrownBag
Note:
- Twitter: worthington10
---
## What we will cover
- Overview of Elasticsearch
- Useful terminology
- How to get up and running
- Index some documents
- What is Kibana and why do I care?
- How to improve search results
- How our queries can impact performance
- And how to test it
---
### Week 1
- Overview of Elasticsearch
- Useful terminology
- How to get up and running
- Index some documents
---
## Prerequisites
(If you want to code along)
- Docker
- dotnet core (C#)
- If you want to dive into the code
---
## Our example data set
Fictitious ThoughtWorks university
Trainers and students
---
## What is Elasticsearch?
Elasticsearch is a distributed, RESTful search and analytics engine capable of addressing a growing number of use cases. As the heart of the Elastic Stack, it centrally stores your data for lightning fast search, fine‑tuned relevancy, and powerful analytics that scale with ease.
---
### Simply put
Stores data
Organises data
Retrieves data
> You know, for Search-
> *Elasticsearch tagline*
---
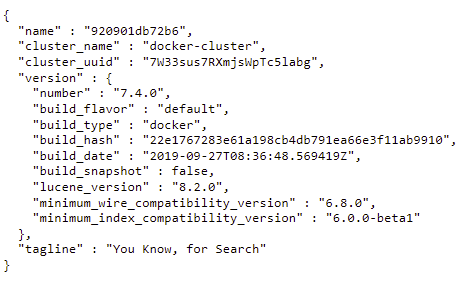
### Up and running
[home (port 9200)](http://localhost:9200)
---
## Glossary
- Documents
- Indexes
- (Types of) Nodes
- Shards
- Clusters
*www.elastic.co/*
*guide/en/elasticsearch/*
*reference/current/glossary.html*
---
## Documents
Stored as JSON
Contains fields (Key value pairs)
They have a `version`, `type` and `id`
Original document is stored in the `_source` field
Stored in an `index`
Note:
Types are now not used, a document is linked to a single type
And can be reindexed and mapped
---
## Documents JSON

---
## ID
Identifier of our document
ES will generate these when omitted
---
## Field
How your data is stored
Some examples
- lists
- dates
- numbers
- true/ false
- ranges
---
### What if my data is complex?
- flat JSON (All the data in a single field)
- Nested object (preserves the relationship)
- Join (Parent child)
---
### What about locations?
- Geo
- long / lat
- polygons
- coordinate system (Cartesian)
- points
- geometries (shapes)
---
## Document from ES

Note:
We have ingested without a mapping type, using Elastics dynamic mapping
---
## Indexes
Place to keep your documents
The logical name which maps to one or more `shards`
---
### Adding document to an index
```curl
PUT trainer/_doc/1
{
"Name": "Matthew",
"Subjects": ["C#", "Java", "Elasticsearch"]
...
}
```
Note:
To add a document to Elasticsearch we push it to an 'Index'
---
## Adding many documents to an index
```curl
POST _bulk
{ "index" : { "_index" : "trainer", "_id" : "1" } }
{ "field1" : "value1" }
{ "index" : { "_index" : "trainer", "_id" : "2" } }
{ "field1" : "value2" }
{ "index" : { "_index" : "trainer", "_id" : "2" } }
{ "field1" : "value2" }
```
---

---
### Creating an index
```curl
PUT /trainer
{
"settings": {
"index": {
"number_of_shards": 3,
"number_of_replicas": 2
}
},
"mappings": {
"properties": {
"bio": { "type": "text" },
"subjects": { "type": "keyword" },
"name": { "type": "text" }
}
}
}
```
Note:
Index aliases
---
## Index alias
Rename your index
Group many indexes
---
### Index alias example
At ThoughtWorks University
We have **trainers**
We have **students**
We want to search across **people**
An index alias of people containing teachers and pupils to the rescue!
---

---
## Nodes you should know
Data nodes
Ingest nodes
Master nodes
Client nodes
Note:
Data nodes
stores data and executes data-related operations such as search and aggregation
Ingest nodes
(Default role).Apply an ingest pipeline to a document in order to transform and enrich the document before indexing. With a heavy ingest load, it makes sense to use dedicated ingest nodes and to not include the ingest role from nodes that have the master or data roles.
ETL
Master nodes
in charge of cluster-wide management and configuration actions such as adding and removing nodes
Client nodes
forwards cluster requests to the master node and data-related requests to data nodes
---
## Other nodes
Tribe nodes
Machine learning nodes
Note:
Tribe nodes
act as a client node, performing read and write operations against all of the nodes in the cluster
Machine Learning nodes
These are nodes available under Elastic’s Basic License that enable machine learning tasks. Machine learning nodes have xpack.ml.enabled and node.ml set to true.
---
### Data nodes
Contains indexes
Data nodes host the shards

---
## Shards
Single lucene index
Automatically managed by Elasticsearch
We can configure primary and replica count
Placed in random nodes across the cluster
Indexes are split into 5 shards by default
The rest should just work itself out
---
### Lucene
Open source
Core search library
Written in Java
---
### Replica shards
Used when primary fails
Never on the same node as the primary shard
Increased search performance
---

---
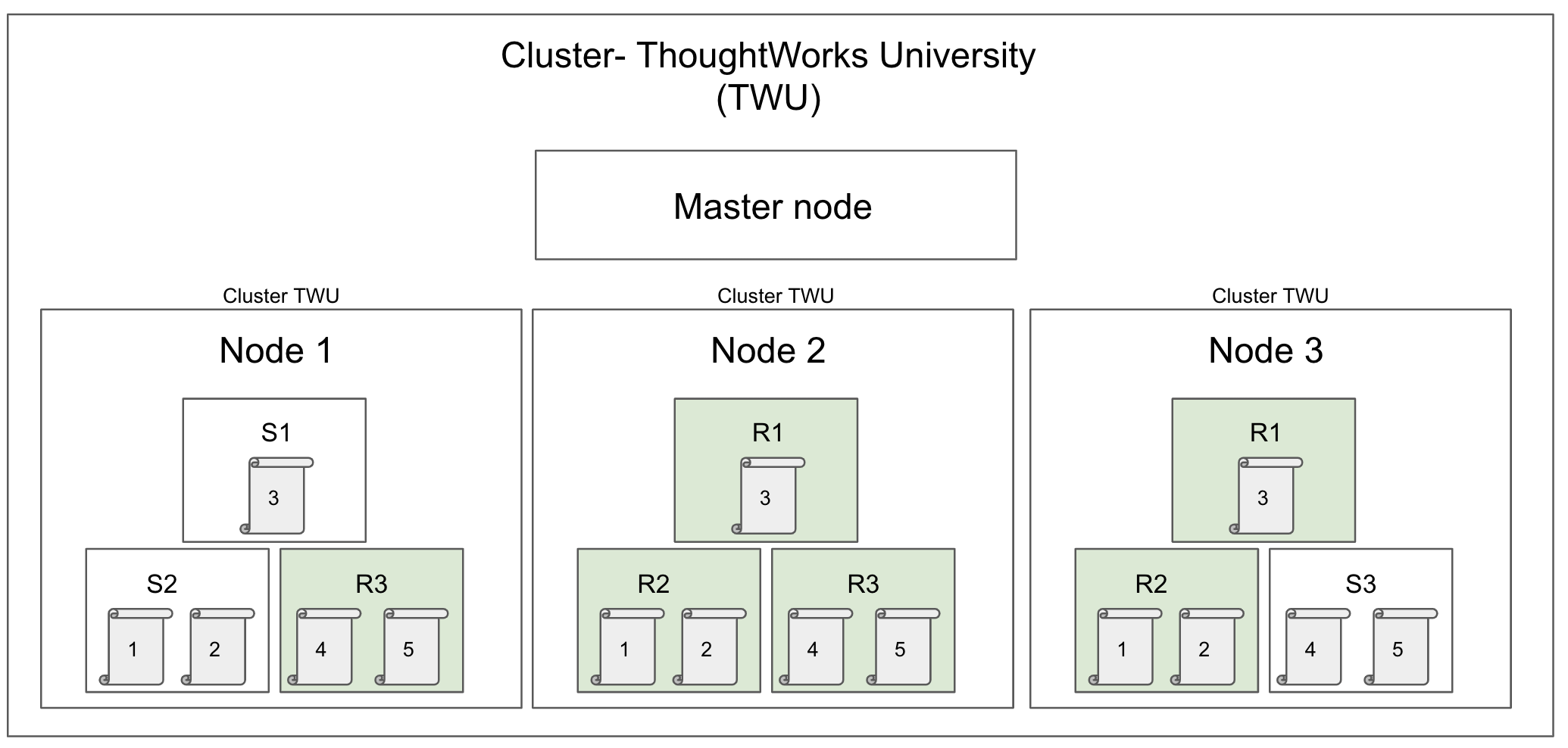
## Cluster
One of more nodes
Master node controllers cluster management
Nodes all share the same cluster name
---
---
## Time to play with Elasticsearch!
```sh
git clone github.com/worthington10TW/ElasticsearchBrownBag
```
```sh
docker-compose up
```
---
## The code

---
## ES in docker

---
## Data in ES
---
## The trainers

---
## The students

---
# Demo
---
## Next time
- Creating an index alias
- Continue creating queries
- Create search templates
- Document mappings
- Compare results with Quepid
*Or, let me know what you would like to see*
---
## Thank you
Send me some feedback
mworthing@thoughtworks.com
{"metaMigratedAt":"2023-06-15T15:49:46.103Z","metaMigratedFrom":"Content","title":"Introduction to Elasticsearch","breaks":false,"contributors":"[{\"id\":\"729e7f13-2a8d-46ab-a3d6-c06f51f4864a\",\"add\":15512,\"del\":8294}]"}