<!--
Docs for making Markdown slide deck on HackMD using Revealjs
https://hackmd.io/s/how-to-create-slide-deck
https://revealjs.com
-->
## 🧑🏫 + :computer: + :earth_asia: = :grey_question:
## Teaching machines about our planet
### *Viewing :eyes:, Learning :female-student:, Imagining :thinking_face:*
<small> EARTHSC 8898 seminar talk, Friday 8 Apr 2022, 17:45-19:00 (UTC) </small>
_by **[Wei Ji Leong](https://github.com/weiji14)**_
<!-- Put the link to this slide here so people can follow -->
<small> P.S. Slides are at https://hackmd.io/@weiji14/2022earthsc8898</small>
----
### Why Machine Learning on Earth Observation data?
<div class="r-stack">
<p class="fragment current-visible">
<small>To see how our planet is changing, and understand patterns over time</small>
<img src="https://github.com/weiji14/30DayMapChallenge2021/releases/download/v0.1.0/day14_new_tool.gif" alt="Iceberg A-74 calving off Brunt Ice Shelf" width="50%">
<small>Iceberg A-74 (1270 sq km, or 2x size of Chicago) calving off Brunt Ice Shelf, Antarctica</small>
<small>https://earthobservatory.nasa.gov/images/148009/breakup-at-brunt</small>
</p>
<p class="fragment current-visible" >
<small>Exponential increase in amount of satellite data</small>
<img src="https://user-images.githubusercontent.com/23487320/162349190-1e7dc490-5692-4ac4-96f0-64792edbf669.png" alt="Rise of Open Satellite Data">
<small>Source: https://www.radiant.earth/infographic</small>
</p>
<p class="fragment current-visible" >
<small>Higher spatial resolution calls for new image analysis techniques</small>
<img src="https://user-images.githubusercontent.com/23487320/162349347-2ac9d4f6-ad9d-4234-b365-d830c8bf6e2b.png" alt="Higher and higher resolution imagery" width="80%">
<small>Source: https://www.radiant.earth/infographic</small>
</p>
</div>
----
### Computer Vision
<small>Do you look at the leaves, trees, or the forest?</small>
<img src="https://miro.medium.com/max/764/0*Ie6XtQURFvOc5sN5.png" alt="Image of Kauri trees" width="39%">
- <small>Leaf - the colour of an individual **pixel**</small>
- <small>Tree - a group of pixels forming an **object**</small>
- <small>Forest - an entire optical satellite/aerial **image**</small>
<!--Image source https://medium.com/on-location/identifying-trees-using-r-ab1cb5000231-->
----
### (Machine) Learning Strategies
*Supervised / Unsupervised / Reinforcement*
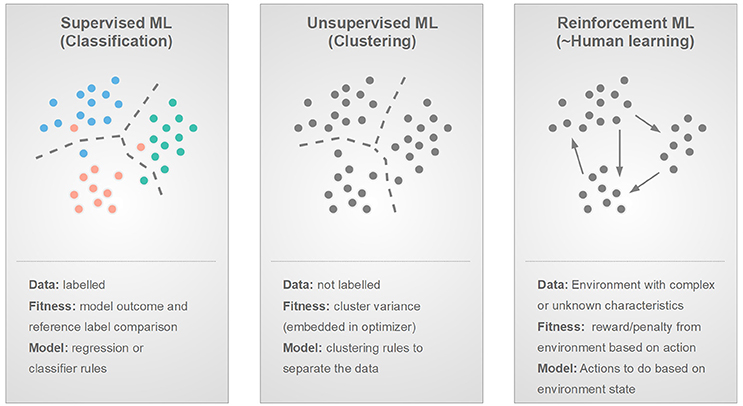
<!-- Image source from Fig 7 of https://doi.org/10.3389/fphy.2018.00051 -->
----
### Tasks
*Recognition / Detection / Segmentation*

<!--Image adapted from https://doi.org/10.3390/rs12101667-->
<small>*Note, sometimes Recognition is called Classification</small>
----
### Tasks (II)
<div class="r-stack">
<p class="fragment current-visible" >
Pan-sharpening
<img src="https://webpages.charlotte.edu/cchen62/img/thumbnail/pan-gan.jpg" alt="Pan-sharpening GAN from https://doi.org/10.1016/j.inffus.2020.04.006" width="90%">
</p>
<p class="fragment current-visible">
Cloud removal
<img src="https://github.com/Penn000/SpA-GAN_for_cloud_removal/raw/bcbe7f4311e98daeb0d4f40e910a4f59ee9f6733/readme_images/test_0000.png" alt="Cloud removal from https://github.com/Penn000/SpA-GAN_for_cloud_removal">
<small>Cloudy image Attention map Model output Ground-truth </small>
</p>
<p class="fragment current-visible" >
Art (Style Transfer)
<img src="https://miro.medium.com/max/1400/1*dAIdctAelAfGCwG5QLSQsQ.jpeg" alt="Transferring Picasso style to aerial imagery from https://medium.com/@mcculloughrt/neural-style-transfer-on-satellite-imagery-cbc6c207c949">
</p>
</div>
<small>More at https://github.com/robmarkcole/satellite-image-deep-learning</small>
---
### A whirlwind tour of examples :cyclone:
- :checkered_flag: **Pixel**-based image classification (2014)
- Classying proglacial lakes (Classic ML)
- :mag: **Object**-based image analysis (2017-present)
- Iceberg or ship? (ConvNet)
- Building outlines/Ship detection (Unet)
- Crevasse detection & Navigation (A3C)
- Super-resolution bed topography (ESRGAN)
- Point cloud anomaly detection (DBSCAN)
- :telescope: Beyond pixels and objects ... (2022-future?)
---
<!-- .slide: data-background="https://user-images.githubusercontent.com/23487320/161560096-37c77268-7977-4672-9752-82898f11d3f5.jpg" .slide: data-background-opacity="0.5"-->
## Classifying proglacial lakes
<small>
in Aoraki/Mount Cook National Park, NZ using Landsat 5 and 7 from 2000-2011
*an undergraduate project done in 2014*
*back when we didn't call it machine learning
</small>
----
### Study region over Southern Alps, NZ
<small>Tracking proglacial lake growth tells us how glaciers are retreating</small>
<img src="https://user-images.githubusercontent.com/23487320/161558676-6a3f8204-6f63-46a3-ab52-c74c37947cef.png" alt="Aoraki/Mount Cook Study Region" width="70%">
----
### Unsupervised classification :see_no_evil:
<small>Specify how many 'classes' you want to separate image</small>
<img src="https://user-images.githubusercontent.com/23487320/161565173-ae60de0e-92f1-4420-a21d-099e78d926c4.png" alt="Unsupervised classification in ENVI" width="80%">
<small>Algorithm (e.g. K-means, ISODATA) groups pixels with similar 'colour' into many classes</small>
----
### Unsupervised classification - 5 classes

----
### Supervised classification :monkey_face:
<small>
Telling the algorithm what a lake's colour looks like by drawing regions of interest (ROI)
</small>
<img src="https://user-images.githubusercontent.com/23487320/161567871-edd891f4-4e8b-4f9a-aad6-75b3084dc94d.png" alt="Supervised classification Region of Interest selection in ENVI" width="45%">
<small>Algorithm (e.g. Parallelepiped, Minimum distance, Mahalanobis distance) finds pixels with similar 'colour' to those ROI examples</small>
----
### Supervised classification results
<img src="https://user-images.githubusercontent.com/23487320/161567875-ae06c365-e31e-4b20-857a-5f1a7babcef8.png" alt="Supervised classification results with Mahalanobis Distance" width="50%">
<small>Lake (red), ice (blue), rock/debris-covered glacier (green)</small>
----
### Results of proglacial lake classification
| | |
|--|--|
|  |  |
<small>As a proglacial lake grows in size, that means the glacier behind it is retreating</small>
----
<!-- .slide: data-background-color="white" .slide: data-background="https://user-images.githubusercontent.com/23487320/161574013-29a876da-69a2-49ea-87c3-709a92bab7c1.png" .slide: data-background-opacity="0.25"-->
### What happened?
- Pixel-based classification
- <small>The algorithm calculates statistics based on each band/channel (i.e. colour)</small>
- <small>Individual pixels separated into classes (water, rock, ice) based on some statistical 'similarity' measure</small>
<br>
<br>
### Challenges
- All the time spent
- <small>Finding cloud-free imagery to download (and dealing with missing Landsat 7 stripes)</small>
- <small>Days of trial and error to find a good algorithm and suitable parameters</small>
---
<!-- .slide: data-background-color="black" .slide: data-background="https://images.theconversation.com/files/114594/original/image-20160310-31867-ivdtan.jpg" .slide: data-background-opacity="0.3"-->
### 2015 to 2017: A good time to learn about AI/ML
| Year | What came out | What I did |
|------|:--------------------------:|:----------:|
| 2015 | Unet paper on image segmentation | More remote sensing BSc (Hons) |
| 2016 | AlphaGo beat Lee Sedol 4-1 | Worked in geospatial industry |
| 2017 | Andrew Ng's popular Deep Learning Coursera course | Started PhD and took that course! :point_left: |
----
### Convolutional Neural Networks
<small>Kernels/Filters are learned to detect 'Features' like edges, corners, etc.</small>
<div class="r-stack">
<table>
<tr>
<td>
<img src="https://user-images.githubusercontent.com/23487320/161880413-578989f6-80f6-4adb-8821-c58008daa24a.gif" alt="Animation of a Convolution operation">
</td>
<td>
<img src="https://distill.pub/2020/circuits/equivariance/images/slim_conv1.png" alt="Convolutional kernels from https://doi.org/10.23915/distill.00024.004" width="1000px">
</td>
</tr>
</table>
<img class="fragment current-visible" src="https://www.frontiersin.org/files/Articles/412254/fnins-12-00777-HTML-r1/image_m/fnins-12-00777-g004.jpg" alt="Convolutional Neural Network Model architecture from https://doi.org/10.3389/fnins.2018.00777" width="90%">
</div>
<small>Subsequent convolutional layers build on these basic representations to learn complex high level features like texture, patterns and shapes.</small>
----
### Iceberg or ship? 🧊/:ship:?
<small>To detect potential hazards out at sea using radar imagery</small>
<img src="https://user-images.githubusercontent.com/23487320/161878837-d5fe2914-f61e-45de-b188-11520da30937.png" alt="Iceberg or ship from satellite image" style="margin:0px auto;display:block" width="60%">
<small>*Image Classification using a ConvNet - [Kaggle competition](https://www.kaggle.com/c/statoil-iceberg-classifier-challenge) in 2018 Jan*</small>
<small>Code at https://www.kaggle.com/weiji14/keras-tinyyolo-based-model/notebook</small>
----
### Unet - A Fully Convolutional Neural Network
<small>Allowing arbitrary sized image input and same scale output</small>
<img src="https://lmb.informatik.uni-freiburg.de/people/ronneber/u-net/u-net-architecture.png" alt="Unet model architecture" style="margin:0px auto;display:block" width="70%">
<small>Ronneberger, O., Fischer, P., & Brox, T. (2015). *U-Net: Convolutional Networks for Biomedical Image Segmentation*. https://arxiv.org/abs/1505.04597</small>
----
### Detecting ships in Sentinel-1 radar imagery
<small>Developing a solution for maritime monitoring on Earth Observation data</small>
| | |
|--|--|
|  |  |
<small>*Image Segmentation using Unet -- 2-day hackathon in 2018 Apr*</small>
<small>Code at https://github.com/weiji14/actinspacenz</small>
----
### Building outlines over NZ :house_with_garden:
<small>Automating a tedious task of manually digitizing shapes in images</small>

<small>*Image Segmentation using Unet -- side-project from 2018 Feb-Mar*</small>
<small>Code at https://github.com/weiji14/nz_convnet</small>
---
<!-- .slide: data-background="https://miro.medium.com/max/1400/1*8Vw-P7yAQYcgvx5pxBpUlA.jpeg" .slide: data-background-opacity="0.25"-->
### Crevasse detection & Navigation over Antarctica
<small>To avoid falling into big holes when traversing the Ross ice shelf</small>
<div class="r-stack">
<img class="fragment current-visible" src="https://user-images.githubusercontent.com/23487320/161890822-9c6e43aa-a10c-4b74-96fb-4b8c115e2d42.png" alt="Ross Ice Shelf crevasses" width="70%">
<p class="fragment current-visible">
<img src="https://user-images.githubusercontent.com/23487320/39678382-dd2066bc-51df-11e8-99e0-7d88299a3146.png" alt="Model architecture" width="100%">
<small>Crevasse Classifier module | Route Navigator module</small>
</p>
</div>
<small>*Image Segmentation using Unet + Reinforcement Learning using A3C -- Yet another challenge project from 2018 Mar-May*</small>
<!--Image sourced from https://towardsdatascience.com/value-iteration-to-solve-openai-gyms-frozenlake-6c5e7bf0a64d-->
----
### Crevasse Classifier + Route Navigator
<small>Satellite image --> Crevasse map --> Actions</small>
<small> :arrow_left: :arrow_up: :arrow_down: :arrow_right: </small>
| | |
|--|--|
|  |  |
<small>Code at https://github.com/weiji14/nz_space_challenge</small>
----
### Asynchronous Advantage Actor Critic (A3C) model
<small>An async (parallel) version of an actor-critic (agent vs reward) model, whereby the model learns to do good actions that maximizes rewards</small>
<div class="r-stack">
<img class="fragment current-visible" src="https://upload.wikimedia.org/wikipedia/commons/thumb/1/1b/Reinforcement_learning_diagram.svg/1024px-Reinforcement_learning_diagram.svg.png" alt="Actor-Critic intro 1" width="45%">
<img class="fragment current-visible" src="https://user-images.githubusercontent.com/23487320/162359815-94628556-b952-4abf-ba0f-92afcc556376.png" alt="Reward over training epochs" width="100%">
</div>
<small>Good infographic at https://hackernoon.com/intuitive-rl-intro-to-advantage-actor-critic-a2c-4ff545978752</small>
---
### Resolving the bed topography of Antarctica :flag-aq:
<small>Going from BEDMAP2 (1km) to a 4x higher resolution (250m) DeepBedMap DEM</small>
<img src="https://www.researchgate.net/profile/Wei_Ji_Leong/publication/340681807/figure/fig1/AS:881070211866625@1587074916790/DeepBedMap-Generator-model-architecture-composed-of-three-modules-The-input-module_W640.jpg" alt="ESRGAN architecture - Generator Network" style="margin:0px auto;display:block" width="70%">
<small>*Using an Enhanced Super-Resolution Generative Adversarial Network (ESRGAN) -- First PhD project from 2018 Jun - 2019 Sep*</small>
<small>Code at https://github.com/weiji14/deepbedmap</small>
----
### Visualizing the model training
<small>ESRGAN model learns to produce finer topography textures after many iterations (example over Thwaites Glacier, ice flow from right to left)</small>
<table align="center">
<tr>
<td>
<img style="width: 400px; height: 450px" src="https://user-images.githubusercontent.com/23487320/96398523-9142d480-1228-11eb-8ee3-2b574c542b57.png">
<small>Epoch 1</small>
</td>
<td>
<img style="width: 400px; height: 450px" src="https://user-images.githubusercontent.com/23487320/96398734-0c0bef80-1229-11eb-8720-9570b444fbcf.gif"/>
<small>Training</small>
</td>
<td>
<img style="width: 400px; height: 450px" src="https://user-images.githubusercontent.com/23487320/96398791-33fb5300-1229-11eb-8ae0-a006203533de.png"/>
<small>Epoch 100</small>
</td>
</tr>
</table>
----
### Generative Adversarial Network intuition
<small>Two competing neural networks working to improve the image's finer details</small>
<img src="https://user-images.githubusercontent.com/23487320/162362778-f62158d4-0633-4010-b6cb-aa294146e83e.png" alt="Generative Adversarial Network mechanism from https://www.uv.es/gonmagar/talks/https://docs.google.com/presentation/d/1gMVuW7j6CAAha8Zzkjq8lhq85_9zB0lsOxQ5Vko9cGI/edit?usp=sharing" width="90%">
<small>Generator (artist) learns to produce better image to convince Discriminator, Discriminator (teacher) points out where the image is incorrect</small>
<small>https://towardsdatascience.com/intuitive-introduction-to-generative-adversarial-networks-gans-230e76f973a9</small>
---
### Finding Antarctic active subglacial lakes :snowflake:
<small>Detected from areas of rapid ice surface elevation change in ICESat-2 point clouds</small>
<table align="center">
<tr>
<td>
<img style="width: 340px; height: 360px" src="https://openaccess.wgtn.ac.nz/ndownloader/files/28808760/preview/28808760/preview.gif" alt="Subglacial Lake Whillans draining and filling over time"/>
</td>
<td>
<img style="width: 280px; height: 360px" src="https://user-images.githubusercontent.com/23487320/162366127-adcd698e-0fd9-4027-8606-db89ab48f130.jpg" alt="Active subglacial lake map over Antarctica"/>
</td>
</tr>
</table>
<small>*Anomaly detection using unsupervised density-based clustering (DBSCAN) -- Final PhD project from 2019 Oct - 2021 Oct*</small>
<small>Code at https://github.com/weiji14/deepicedrain</small>
----
<div class="sketchfab-embed-wrapper"> <iframe title="Siple Coast ICESat-2 point cloud" frameborder="0" allowfullscreen mozallowfullscreen="true" webkitallowfullscreen="true" allow="autoplay; fullscreen; xr-spatial-tracking" xr-spatial-tracking execution-while-out-of-viewport execution-while-not-rendered web-share width="1200" height="600" src="https://sketchfab.com/models/bb9994e9dac241198d13575cd5d3a8f2/embed?annotations_visible=1&annotation_cycle=1&dnt=1"> </iframe> </div>
<small><sub>Code at https://github.com/weiji14/agu2021</sub></small>
----
### Density-Based Spatial Clustering of Applications with Noise (DBSCAN)
<small>Used to find dense clusters of where a pattern (e.g. rapid elevation change) is occuring, without specifying the number of clusters beforehand</small>
<img src="https://user-images.githubusercontent.com/23487320/162365311-545e7b53-12e3-4411-b923-206b53aa3666.gif" alt="DBSCAN animation on Gaussian Mixtures" width="30%">
<small>Set a distance (epsilon) to cluster points, and a minimum points (minPts) threshold required to form a cluster</small>
<small>https://www.naftaliharris.com/blog/visualizing-dbscan-clustering!</small>
----
<section data-visibility="hidden" data-visibility="uncounted">What happened?</section>
<!--

### What happened?
- Object based image analysis
- <small>Considering local groups of pixels or points together</small>
- <small>Enabled by high-resolution (<100m, <10m) satellite data</small>
<br>
<br>
### Limitations of ConvNets
- Translational [equivariance](https://distill.pub/2020/circuits/equivariance)
- <small>Seeing patches of images, but not the bigger picture at once (can be good or bad depending on the task)</small>
- <small>'Limited' field of view means long-range dependencies cannot be captured properly. How to understand a full scene?</small>
-->
---
### So What's next :rocket:
Up and coming stuff to keep an eye out for!
----
### S2S2Net - Super-Resolution Segmentation :national_park:
<small>Sentinel-2 image (10m @ 5-day repeat) -> Super-Resolution river masks (2m) over Alaska/Canada</small>
<div class="r-stack">
<img class="fragment current-visible" src="https://user-images.githubusercontent.com/23487320/162107585-0f3b2866-2218-443f-89bc-210ef6139a72.gif" alt="Super-resolution river mask zoomed in" width="70%">
<img class="fragment current-visible" src="https://user-images.githubusercontent.com/23487320/162035229-d1316b46-a73f-4eb5-a382-768c8a150a83.png" alt="Alaska/Canadian Arctic rivers" width="70%">
</div>
<small>*Multi-task learning with Vision Transformers -- 2022 (ongoing) with Ziwei Li & Joachim Moortgat*</small>
<!-- <small>Code at https://github.com/weiji14/nz_space_challenge</small> -->
----
### Vision Transformer - [An image worth 16x16 words](https://doi.org/10.48550/arXiv.2010.11929)
<small>Able to capture long-range dependencies (e.g. how a river is connected) in an image, overcoming limited field of view in standard Convolutional Neural Networks</small>
<div class="r-stack">
<img class="fragment current-visible" src="https://upload.wikimedia.org/wikipedia/commons/3/3e/Vision_Transformer.gif" alt="Vision Transformer model architecture" width="80%">
<img class="fragment current-visible" src="https://user-images.githubusercontent.com/23487320/162108921-5cde0171-346c-45db-bf5a-240d457443aa.png" alt="Vision Transformer Attention from https://jacobgil.github.io/deeplearning/vision-transformer-explainability">
</div>
<small>Taking in the whole scene at once, but paying 'attention' to what matters</small>
<small>A model architecture from Natural Language Processing adapted for Computer Vision</small>
----
### H2Oval - Continent to Planetary scale prediction
<small>Locating oval features in optical imagery that may potentially yield hydrogen gas</small>
<div class="r-stack">
<img class="fragment current-visible" src="https://user-images.githubusercontent.com/23487320/162016847-5b13f950-2dff-4f27-8f84-1844185b442c.png" alt="Oval features over Australia - zoomed in">
<img class="fragment current-visible" src="https://user-images.githubusercontent.com/23487320/162022137-933cd75f-aaba-4477-9e07-1251369e4a97.png" alt="Oval features over South-West Australia" width="80%">
</div>
<small>*Object Detection project using YOLOX -- 2022 (ongoing) with team at SES/Byrd*</small>
<small>From Australia to the whole world? - Every bit of efficiency counts!</small>
----
### MLOps - From model-centric to data-centric
<small>(Clean) labels are still very important!</small>
<div class="r-stack">
<img class="fragment current-visible" src="https://user-images.githubusercontent.com/23487320/162116216-f0bf6f3d-141b-4cb0-9943-db0e7f67a3dc.png" alt="MLOps lifecycle">
<img class="fragment current-visible" src="https://user-images.githubusercontent.com/23487320/162115411-bb3313c6-45bb-4df5-9226-becf9c2c02b1.png" alt="MLOps Clean vs Noisy data" width="60%">
</div>
<small>**Model-centric** - How can I tune the model architecture to improve performance?</small>
<small>**Data-centric** - How can I modify my data (new examples, more labels, etc) to improve performance?</small>
<small>Watch Andrew Ng's video - https://youtu.be/06-AZXmwHjo</small>
---
## Ethics of machine learning/map making
----
### Carbon emissions of ML experiments
<small>Are you aware of how much electricity goes into training a neural network?</small>
<table>
<tr>
<td>
<img src="https://user-images.githubusercontent.com/23487320/161581074-fe26cc48-0175-4f26-a862-e271fdbcca73.png" alt="Animation of a Convolution operation">
</td>
<td>
<img src="https://user-images.githubusercontent.com/23487320/162369436-90ccf3c8-d20c-4467-a8cd-082380c6ca1a.png" alt="CO2 emissions from training neural networks from https://doi.org/10.48550/arXiv.1906.02243" width="600px">
</td>
</tr>
</table>
<small>Hint: Use https://github.com/mlco2/codecarbon</small>
----
### Beyond technical fixation
- As a geographer :earth_asia:, we need to ask:
- Whose problems are being solved? Who defines these problems? :thinking_face:
- Who is involved in the generation of solutions :bulb:? For whom are these solutions valid and good?
- How do alternative approaches or worldviews fit in? 👫🏽
Put another way, how can our map :world_map: affect people?
<!--On bias, interpretation, and just generally being a good human-->
---
<!-- .slide: data-background-color="black" .slide: data-background="https://user-images.githubusercontent.com/23487320/162113015-dae98227-c654-4d42-a717-badfadd84065.png" .slide: data-background-size="1200px" .slide: data-background-opacity="0.5"-->
<center>
...
Viewing forests, not trees
Learning smarter, from each other
Imagining a future, a blue planet still to be
...
</center>
{"metaMigratedAt":"2023-06-16T22:30:10.088Z","metaMigratedFrom":"YAML","title":"Teaching machines about our planet: Viewing, Learning, Imagining","breaks":true,"description":"EARTHSC 8898 seminar talk","slideOptions":"{\"theme\":\"beige\"}","contributors":"[{\"id\":\"c1f3f3d8-2cb7-4635-9d54-f8f7487d0956\",\"add\":110508,\"del\":86130}]"}