---
tags : Computer Architecture
---
# Lab1: RV32I Simulator
[TOC]
## Introduction
I implement MergeSort in RISC-V Assembly Code
It can sort both positive and negative numbers
## MergeSort
- It follows a concept called "**Divide and Conquer**"
- It can be finished in **O(n logn)**
- It is a **stable** algorithm

**[ picture from google ]**
## Environment
:::warning
Use `gcc --version | head 1` for shorter output.
:notes: jserv
:::
* gcc version

After `C99`, " C " can use **variable** when declared the `array length`, and then put the array into **stack**.
## C Code ([MergeSort.c](https://github.com/waynelinbo/Computer_Architecture_Lab1_MergeSort/blob/main/MergeSort.c))
```c=
#include<stdio.h>
#include<stdlib.h>
void merge(int *arr, int start, int mid, int end)
{
int total = end - start + 1;
//int *array = (int *)malloc(sizeof(int)*total);
int array[total]; // variable array length stored in stack
for(int i = 0; i< total;i++)
array[i] = arr[i+start];
int left_c = 0;
int right_c = mid-start+1;
int l_max = mid-start;
int r_max = end-start;
int output_c = start;
while(left_c <= l_max && right_c <= r_max)
{
if(array[left_c] <= array[right_c])
{
arr[output_c] = array[left_c];
output_c++;
left_c++;
}
else
{
arr[output_c] = array[right_c];
output_c++;
right_c++;
}
}
if(left_c <= l_max)
{
while(left_c <= l_max)
{
arr[output_c] = array[left_c];
output_c++;
left_c++;
}
}
else
{
while(right_c <= r_max)
{
arr[output_c] = array[right_c];
output_c++;
right_c++;
}
}
}
void mergesort(int *arr, int start, int end)
{
if(start<end)
{
int mid = (end+start)/2;
mergesort(arr, start, mid);
mergesort(arr, mid+1, end);
merge(arr, start, mid, end);
}
}
int main()
{
int arr[] = {7, -4, 10, -1, 3, 2, -6, 9};
int size = 8;
printf("Before Sort : ");
for(int i = 0;i<8;i++)
printf("%d , ", arr[i]);
printf("\n");
mergesort(arr, 0, size-1);
for(int i = 0;i<8;i++)
printf("%d , ", arr[i]);
printf("\n");
return 0;
}
```
## RISC-V Code ([MergeSort.s](https://github.com/waynelinbo/Computer_Architecture_Lab1_MergeSort/blob/main/MergeSort.s))
```clike=
.data
size: .word 8
arr: .word 7, 4, 10, -1, 3, 2, -6, 9
str1: .string " Before Sort : "
str2: .string " After Sort : "
newline: .string "\n"
comma: .string " , "
.text
############## main ################
main:
addi sp, sp, -4
sw ra, 0(sp)
# print str1
la a0, str1
addi a7, x0, 4
ecall
# print current array
la a0, arr
lw a1, size
jal ra, printArray
# do MergeSort(&arr, int start, int end)
la a0, arr
addi a1, x0, 0
lw a2, size
addi a2, a2, -1
jal ra, mergeSort
# print str2
la a0, str2
addi a7, x0, 4
ecall
# print current array
la a0, arr
lw a1, size
jal ra, printArray
lw ra, 0(sp)
addi sp, sp, 4
jalr x0, ra, 0
###########################################
############ mergeSort ##############
# s0 : &addr
# s1 : start
# s2 : end
# s3 : mid = (start+end)/2
mergeSort:
# sp : ra
# sp+4 : &addr
# sp+8 : start
# sp+12 : end
# sp+16 : mid
addi sp, sp, -20
sw ra, 0(sp)
# copy argument to saved register
addi s0, a0, 0 # s0 : &addr
addi s1, a1, 0 # s1 : start
addi s2, a2, 0 # s2 : end
# if(start<end), else go to label(endMergeSort)
bge s1, s2, endMergeSort
# use substract to implement divide
# s3 <= mid = (start+end)/2
add s3, s1, s2 # mid(s3) = start(s1) + end(s2)
addi s4, x0, 0 # (s4+1) each time when (s3-2) until s3 < 0
div:
blt s3, x0, endDiv
addi s3, s3, -2 # each time s3 - 2
addi s4, s4, 1 # each time s4 + 1
jal x0, div
endDiv:
addi s3, s4, -1 # s3 = mid : floor((start+end)/2)
# save &addr(s0), start(s1), end(s2), mid(s3) to mem
sw s0, 4(sp)
sw s1, 8(sp)
sw s2, 12(sp)
sw s3, 16(sp)
# prepare argument to do left mergeSort
# mergeSort(&arr(a0), start(a1), mid(a2))
addi a0, s0, 0 # a0 <= &addr (s0)
addi a1, s1, 0 # a1 <= start (s1)
addi a2, s3, 0 # a2 <= mid (s3)
jal ra, mergeSort
# prepare argument to do right mergeSort
# mergeSort(&arr(a0), mid(a1)+1, end(a2))
lw a0, 4(sp) # a0 <= &addr (sp+4)
lw a1, 16(sp) # a1 <= mid (sp+16)
addi a1, a1, 1 # a1 <= mid + 1
lw a2, 12(sp) # a2 <= end (sp+12)
jal ra, mergeSort
# prepare argument to do merge
# mergeSort(&arr(a0), start(a1), mid(a2), end(a3))
lw a0, 4(sp) # a0 <= &addr (sp+4)
lw a1, 8(sp) # a1 <= start (sp+8)
lw a2, 16(sp) # a2 <= mid (sp+16)
lw a3, 12(sp) # a3 <= end (sp+12)
jal ra, merge
endMergeSort:
lw ra, 0(sp)
addi sp, sp, 20
jalr x0, ra, 0
###########################################
########### merge ################
# a0 : &addr
# a1 : start
# a2 : mid
# a3 : end
merge:
# 0. we have left sorted array(start..mid) & right sorted array(mid+1..end)
# 1. copy array[start..end] from memory to stack
# 2. use 2 index (left: from 0, right : from mid-start+1) to compare left & right in stack
# 3. write the smaller back to memory, and the smaller index + 1
# 4. check is there any index have reached(>) the max index(left: mid-start, right: end-start)
# 5. if no, go back to step 2; else write the left/right left value back to memory
# calculate how many stack space we need
# t0 : total count of index => end - start + 1
# t1 : total space of memsize => t0*4
# t2 : 2's complement of t1 => -t1
sub t0, a3, a1 # total(t0) = end(a3) - start(a1)
addi t0, t0, 1 # total(t0) = end(a3) - start(a1) + 1
add t1, t0, t0 # space(t1) = total(t0)*2
add t1, t1, t1 # space(t1) = space(t1)*2 = total(t0)*4
xori t2, t1, 0xffffffff # 1's complement + -> -, t1 -> t2
addi t2, t2, 1 # 2's complement(t2) => 1's complement(t2) + 1
add sp, sp, t2
# copy array[start..end] from memory to stack
# t2 : current index of new array(stack)
# t3 : current index of old array(memory)
addi t3, a1, 0 # memory index(t3) start from start(a1)
addi t2, x0, 0 # stack index(t2) start from 0
read2Stack:
blt a3, t3, endRead # if(mem_index(t3) < end(a3)), else go to label(endRead)
add t4, t3, t3 # offset_space(t4) = mem_index(t3)*2
add t4, t4, t4 # offset_space(t4) = offset_space(t4)*2 = mem_index(t3)*4
add t4, a0, t4 # mem_addr(t4) = &addr(a0) + offset_space(t4)
lw t5, 0(t4) # t5 = *mem_addr(t4)
add t6, t2, t2 # offset_space(t6) = st_index(t2)*2
add t6, t6, t6 # offset_space(t6) = offset_space(t6)*2 = st_index(t2)*4
add t6, sp ,t6 # st_addr(t6) = initial_addr(sp) + offset_space(t6)
sw t5, 0(t6) # *st_addr(t6) = t5
addi t2, t2, 1 # st_index + 1
addi t3, t3, 1 # mem_index + 1
jal x0, read2Stack
endRead:
# do merge
# view stack as two parts(left sorted & right sorted), compare each, then store to memory from little to big
# prepare some variable
# t2 : left part index => 0
# t3 : right part index => mid(a2) - start(a1) + 1 => t4 + 1
# t4 : left terminate index(when t2 > t4) => mid(a2) - start(a1)
# t5 : right terminate index(when t3 > t5) => end(a3) - start(a1)
# t6 : write back index of old array(memory) => start(a1)
sub t4, a2, a1 # left max(t4) = mid(a2) - start(a1)
sub t5, a3, a1 # right max(t5) = end(a3) - start(a1)
addi t2, x0, 0 # left index(t2) = start form 0
addi t3, t4, 1 # right index(t3) = start from mid(a2) - start(a1) + 1
addi t6, a1, 0 # t6 : write back index from start(a1)
# if((left index <= left terminate) && (right index <= right terminate)), else go to label(endMergeLoop)
# t0 : boolean <= (left terminate(t4) < left index(t2))
# t1 : boolean <= (right terminate(t5) < right index(t3))
# if t0 or t1 is true, it will be go to go to label(endMergeLoop)
# if neither => go on
# t0 : calculate the left mem, then load value in it
# t1 : calculate the right mem, then load value in it
# compare which is smaller, then save the smaller in old array(memory)
mergeLoop:
slt t0, t4, t2 # t0 = (left terminate(t4) < left index(t2))
slt t1, t5, t3 # t1 = (right terminate(t5) < right index(t3))
or t0, t0, t1 # t0 = t0 || t1
xori t0, t0, 0x1 # t0 = ~t0
beq t0, x0, endMergeLoop # if((t0||t1) != 0), else go to label(endMergeLoop)
add t0, t2, t2 # offset_space(t0) = left_index(t2)*2
add t0, t0, t0 # offset_space(t0) = offset_space(t0)*2 = left_index(t2)*4
add t0, sp, t0 # left_addr(t0) = initial_addr(sp) + offset_space(t0)
lw t0, 0(t0) # left_value(t0) = *left_addr(t0)
add t1, t3, t3 # offset_space(t1) = right_index(t3)*2
add t1, t1, t1 # offset_space(t1) = offset_space(t1)*2 = right_index(t3)*4
add t1, sp, t1 # right_addr(t1) = initial_addr(sp) + offset_space(t1)
lw t1, 0(t1) # right_value(t1) = *right_addr(t1)
blt t1, t0, rightSmaller # if(left_value(t0)<=right_value(t1)), else go to label(rightSmaller)
add t1, t6, t6 # offset_space(t1) = mem_index(t6)*2
add t1, t1, t1 # offset_space(t1) = offset_space(t1)*2 = mem_index(t6)*4
add t1, a0, t1 # mem_addr(t1) = &addr(a0) + offset_space(t1)
sw t0, 0(t1) # *mem_addr(t1) = left_value(t0)
addi t6, t6, 1 # mem_index + 1
addi t2, t2, 1 # left_index + 1
jal x0, mergeLoop
rightSmaller:
add t0, t6, t6 # offset_space(t0) = mem_index(t6)*2
add t0, t0, t0 # offset_space(t0) = offset_space(t0)*2 = mem_index(t6)*4
add t0, a0, t0 # mem_addr(t0) = &addr(a0) + offset_space(t0)
sw t1, 0(t0) # *mem_addr(t0) = right_value(t1)
addi t6, t6, 1 # mem_index + 1
addi t3, t3, 1 # right_index + 1
jal x0, mergeLoop
endMergeLoop:
# if left part still have elements, store leave in to old array
# if right part still have elements, store leave in to old array
bge t5, t3, rightLoop # if(right index <= right terminate) => right part still have elements, go to label(rightLoop)
leftLoop: # else go on label(leftLoop)
add t0, t2, t2 # offset_space(t0) = left_index(t2)*2
add t0, t0, t0 # offset_space(t0) = offset_space(t0)*2 = left_index(t2)*4
add t0, sp, t0 # left_addr(t0) = initial_addr(sp) + offset_space(t0)
lw t0, 0(t0) # left_value(t0) = *left_addr(t0)
add t1, t6, t6 # offset_space(t1) = mem_index(t6)*2
add t1, t1, t1 # offset_space(t1) = offset_space(t1)*2 = mem_index(t6)*4
add t1, a0, t1 # mem_addr(t1) = &addr(a0) + offset_space(t1)
sw t0, 0(t1) # *mem_addr(t1) = left_value(t0)
addi t6, t6, 1 # mem_index + 1
addi t2, t2, 1 # left_index + 1
bge t4, t2, leftLoop # check left part whether still have elements
jal x0, endMerge
rightLoop:
add t1, t3, t3 # offset_space(t1) = right_index(t3)*2
add t1, t1, t1 # offset_space(t1) = offset_space(t1)*2 = right_index(t3)*4
add t1, sp, t1 # right_addr(t1) = initial_addr(sp) + offset_space(t1)
lw t1, 0(t1) # right_value(t1) = *right_addr(t1)
add t0, t6, t6 # offset_space(t0) = mem_index(t6)*2
add t0, t0, t0 # offset_space(t0) = offset_space(t0)*2 = mem_index(t6)*4
add t0, a0, t0 # mem_addr(t0) = &addr(a0) + offset_space(t0)
sw t1, 0(t0) # *mem_addr(t0) = right_value(t1)
addi t6, t6, 1 # mem_ndex + 1
addi t3, t3, 1 # right_index + 1
bge t5, t3, rightLoop # check right part whether still have elements
jal x0, endMerge
# revert stack space
# t0 : total count of index => end - start + 1
# t1 : total space of memsize => t0*4
endMerge:
sub t0, a3, a1 # total(t0) = end(a3) - start(a1)
addi t0, t0, 1 # total(t0) = end(a3) - start(a1) + 1
add t1, t0, t0 # space(t1) = total(t0)*2
add t1, t1, t1 # space(t1) = space(t1)*2 = total(t0)*4
add sp, sp, t1
jalr x0, ra, 0
###########################################
########### printArray ###############
printArray:
addi t0, a0, 0
addi t1, a1, 0
addi t2, x0, 0
printLoop:
add t3, t2, t2 # i+=i
add t3, t3, t3 # i+=i ==> i*4
add t3, t0, t3
lw a0, 0(t3)
addi a7, x0, 1
ecall
addi t2, t2, 1
bge t2, t1, endPrint
la a0, comma
addi a7, x0, 4
ecall
jal x0, printLoop
endPrint:
la a0, newline
addi a7, x0, 4
ecall
jalr x0, ra, 0
###########################################
```
## Result
we can check result in console

## How to Use ?
You can change the arr & its responding size to implement another array
Then, check the result in console

## Ripes Simulator

**Ripes** is a 5-stages pipeline CPU
### CPU Design Concept
In order to accelerate `speed` and improve [`IPC`](https://en.wikipedia.org/wiki/Instructions_per_cycle)
We normally implement the concept of `pipeline`
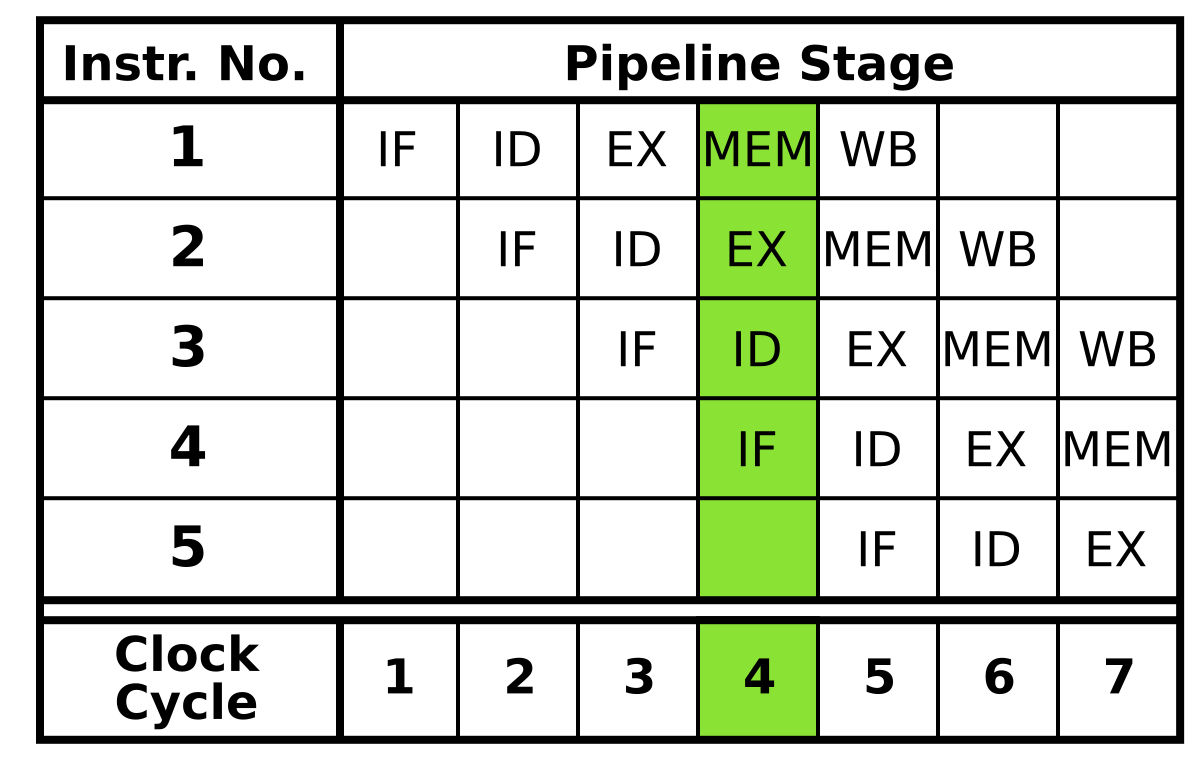
Normally, in education, we roughly divide CPU into 5-stages
Of course, in business, it can be not only 5
However, performance doesn't necessarily get better as the stage number gets bigger, it depends on how you divide it.
```
The keypoints mainly have three below
1. stage numbers
2. whether the execution time of each stage is nearly
3. hazard problems
```
Of course, the execution time of each stage as near as possible is better
The time get short as the stages get smaller
But, the hazard problems get more as the stages get more, then resulting in time get longer
So, you should dicide between stages and hazard to get the highest performence.
Back to the topic. That's talk about **Ripes 5-stages pipeline CPU Simulator**
### Ripes ###
In Ripes, we have 5-stages
* **IF**
* **ID**
**RISC-V have the fixed position of rs1, rs2 ,rd
You can check the table below**

* **EX**
**I roughly classify the instructions in RV32I
It is a little bit different to official classification
But, I think it's helpful when design CPU especially in EX stage**

:::info
**ALU's Op1 & Op2 Choose**
| Instruction | Op1 | Op2 |
|:-----------:|:---:|:---:|
|LUI | --- |imme |
|AUIPC | pc |imme |
|R type | reg1|reg2 |
|I type | reg1|imme |
|B type | pc |imme |
|jal | pc |imme |
|jalr | reg1|imme |
|L | reg1|imme |
|S | reg1|imme |
:::
* **MEM**
* **WB**
### Hazard
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet