# Part I: The way AI transforms
---
### How AI have elvoved in the past decade?
2010. Deep Belief Network
2011. Deep convnets for tiny image classification *(inductive-bias)*
2012. AlexNet: deep convnets for ImageNet *(inductive-bias)*
2014. VGG convnets *(inductive-bias)*
2015. GoogleNet, MobileNet *(inductive-bias)*
---
### How AI have elvoved in the past decade?
2016. Residual networks, Transformers *(inductive-bias)*
2017. AlphaGo 4:1 Lee Sedol *(self-play)*
2018. OpenFive vs human on Dota2 *(self-play)*
2019. GPT-2, Turing-NGL/DeepSpeed *(self-learn)*
2020. GPT-3 *(self-learn)*
---
### More is More
* Model sizes: thousands $\rightarrow$ billions (trillions in 2021?)
* Accuracy improved as models grow bigger
* Accuracy improved as more data thrown in
---
### On the Generalization of Neural nets
* Intermediate neural layers capable of learning latent representation
* Learned representation is reusable
* Representation is data-domain bounded
---
### Pre-training as Generalization
* Prior 2010, only layer-wise pre-training can harness deep nets
* Early 2010s pre-training is indispensable to train on small-size data
* Enter the era of data explosion, pre-training becomes an option
---
### Pre-training Strikes back
* Prior 2010, only layer-wise pre-training can harness deep nets
* Early 2010s pre-training is indispensable to train on small-size data
* Enter the era of data explosion, pre-training becomes an option
---
### NLP is the new Vision
* 2010-2015: DL in NLP not so impressive as in CV
* Now NLP's turn influences CV
* NLP thing: pretext training on massive unlabeled data
---
### More is Less
* The more amount of unlabeled data and the bigger model is,
* the lesser amount of labeled data is required
---
### Over-parametrization
* As model size grows, micro-structures do not matter much
* Initial conditions are not very important either
* Many equally good local minima found
---
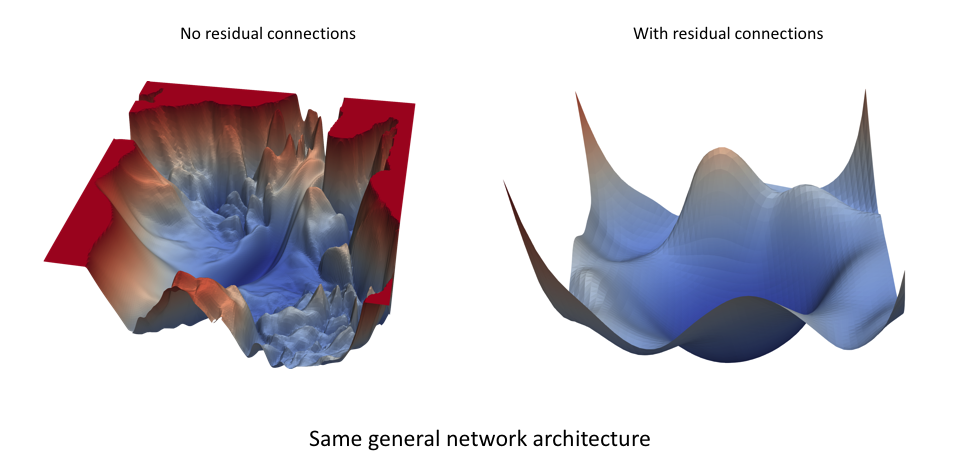
### Optimization Landscape

---
### Less is More ?
* Since 2015, embedding deep learning spinned off from big models
* Whole lots of topics on model compression, fp16 inference, etc.
* Limited math ops, packed memory, low TFLOPS
* "Detached" from the reality of "bigger-better"
---
### Less is More: A How-To
* Distangle efficiency vs accuracy
* Orthogonize epxerimenting versus production
* Model cycle: Research - "Productionize" - Production
* Productionize (v): distilizing big models to minis
---
### Knowledge Distillation

---
### Less is More !
* Freely pursuit higher accuracy with big models + big data
* While maintaining well-defined "productionize" procedure to normalize experimental models into well-tested, hardware-compatible efficient small models
---
# DIY: Our Inventory
---
### Data
* 1.47 million of labelled events
* 27.8 million of raw images
* Enough to facilitate self-supervised learning
---
### Compute
* Each V100 card can fit 1 billion model
* DeepSpeed (MSFT) boosts ~10x (compute, speed)
---
### Algorithms
* Attention is All You Need
* Invented in 2016 for NLP, lazy-smart way to learn fro mdata
* Influence back to CV, attention *will* replace convolution
* Attention can solve *best image picking*, *change detect*
---
### Algorithms
* Knowledge distillation with Teacher-student learning
* Inductive bias of residual connections
* More efficient networks for mobiles
---
### Algorithms
---
### Farther Future ?
Adding memory, a stateful AI machine
{"metaMigratedAt":"2023-06-15T12:58:00.206Z","metaMigratedFrom":"YAML","title":"Part I: The way AI transforms","breaks":true,"slideOptions":"{\"transition\":\"slide\"}","contributors":"[{\"id\":\"39292a0b-1532-4d33-b895-e48f35752611\",\"add\":8129,\"del\":4288}]"}