# Chapter 11: Hierarchical models
#### Key idea
We learn generalized concepts naturally:
- poodle, Dalmatian, Labrador → dog
- sedan, coupe, convertible, wagon → car
How do we build models that can learn these _abstract_ concepts?
### Example 1: Bags with colored balls
Each bag can learn its own categorical distribution. It explains previously observed data well but fails to generalize.
Let's say this is what we observe:
```javascript
var observedData = [
{bag: 'bag1', draw: 'blue'},
{bag: 'bag1', draw: 'blue'},
{bag: 'bag1', draw: 'black'},
{bag: 'bag1', draw: 'blue'},
{bag: 'bag1', draw: 'blue'},
{bag: 'bag1', draw: 'blue'},
{bag: 'bag2', draw: 'blue'},
{bag: 'bag2', draw: 'green'},
{bag: 'bag2', draw: 'blue'},
{bag: 'bag2', draw: 'blue'},
{bag: 'bag2', draw: 'blue'},
{bag: 'bag2', draw: 'red'},
{bag: 'bag3', draw: 'blue'},
{bag: 'bag3', draw: 'orange'}
]
```

Human observation: All bags have __blue__ as predominant color. This is an abstract (generalized) notion of distribution of colors in bags. The below approach does not work:

As you can see, it predicts poorly the distribution of bags 3 and N.
But if we try to learn a shared prototype, it works:

It predicts the distribution of an unseen bag N very well.
---
### Example 2: Learning generalized vs specific prototypes
> Suppose that we have a number of bags that all have identical prototypes: they mix red and blue in proportion 2:1. But the learner doesn’t know this. She observes only one ball from each of N bags. What can she learn about an individual bag versus the population as a whole as the number of bags changes?
>
If the data comes from different bags, the generalized prototype learns well but the specific one does not:
```javascript
var data = [{bag:'bag1', draw:'red'}, {bag:'bag2', draw:'red'}, {bag:'bag3', draw:'blue'},
{bag:'bag4', draw:'red'}, {bag:'bag5', draw:'red'}, {bag:'bag6', draw:'blue'},
{bag:'bag7', draw:'red'}, {bag:'bag8', draw:'red'}, {bag:'bag9', draw:'blue'},
{bag:'bag10', draw:'red'}, {bag:'bag11', draw:'red'}, {bag:'bag12', draw:'blue'}]
```

But if all samples come from a single bag, the specific prototype learns well but the generalized one does not:
```javascript
var data = [{bag:'bag1', draw:'red'}, {bag:'bag1', draw:'red'}, {bag:'bag1', draw:'blue'},
{bag:'bag1', draw:'red'}, {bag:'bag1', draw:'red'}, {bag:'bag1', draw:'blue'},
{bag:'bag1', draw:'red'}, {bag:'bag1', draw:'red'}, {bag:'bag1', draw:'blue'},
{bag:'bag1', draw:'red'}, {bag:'bag1', draw:'red'}, {bag:'bag1', draw:'blue'}]
```

---
### Learning Overhypotheses: Abstraction at the Superordinate Level
> Suppose that we observe that `bag1` consists of all blue marbles, `bag2` consists of all green marbles, `bag3` all red, and so on. This doesn’t tell us to expect a particular color in future bags, but it does suggest that bags are very regular—that all bags consist of marbles of only one color.
>
Suppose we have the following data:
```javascript
var observedData = [
{bag: 'bag1', draw: 'blue'}, {bag: 'bag1', draw: 'blue'}, {bag: 'bag1', draw: 'blue'},
{bag: 'bag1', draw: 'blue'}, {bag: 'bag1', draw: 'blue'}, {bag: 'bag1', draw: 'blue'},
{bag: 'bag2', draw: 'green'}, {bag: 'bag2', draw: 'green'}, {bag: 'bag2', draw: 'green'},
{bag: 'bag2', draw: 'green'}, {bag: 'bag2', draw: 'green'}, {bag: 'bag2', draw: 'green'},
{bag: 'bag3', draw: 'red'}, {bag: 'bag3', draw: 'red'}, {bag: 'bag3', draw: 'red'},
{bag: 'bag3', draw: 'red'}, {bag: 'bag3', draw: 'red'}, {bag: 'bag3', draw: 'red'},
{bag: 'bag4', draw: 'orange'}]
```
Note that we only have one sample from `bag4` and no sample from `bag N`.
- We can confidently say that all samples from `bag4` are orange.
- For bag N, any color is equally probable.
This can be modeled by defining our prototype as:
```javascript
// the global prototype mixture:
var phi = dirichlet(ones([5, 1]))
// regularity parameters: how strongly we expect the global prototype to project
// (ie. determine the local prototypes):
var alpha = gamma(2,2)
var prototype = T.mul(phi, alpha)
```
After observing the data, `alpha` will end up being significantly smaller than 1.
> This means roughly that the learned prototype in phi should exert less influence on prototype estimation for a new bag than a single observation.
>
Now let's say we have the following data:
```javascript
var observedData = [
{bag: 'bag1', draw: 'blue'}, {bag: 'bag1', draw: 'red'}, {bag: 'bag1', draw: 'green'},
{bag: 'bag1', draw: 'black'}, {bag: 'bag1', draw: 'red'}, {bag: 'bag1', draw: 'blue'},
{bag: 'bag2', draw: 'green'}, {bag: 'bag2', draw: 'red'}, {bag: 'bag2', draw: 'black'},
{bag: 'bag2', draw: 'black'}, {bag: 'bag2', draw: 'blue'}, {bag: 'bag2', draw: 'green'},
{bag: 'bag3', draw: 'red'}, {bag: 'bag3', draw: 'green'}, {bag: 'bag3', draw: 'blue'},
{bag: 'bag3', draw: 'blue'}, {bag: 'bag3', draw: 'black'}, {bag: 'bag3', draw: 'green'},
{bag: 'bag4', draw: 'orange'}]
```
> The marble color is instead variable within bags to about the same degree that it varies in the population as a whole.
>
In this case `alpha` is significantly greater than 1.
---
### Example: The Shape Bias
It is `the preference to generalize a novel label for some object to other objects of the same shape, rather than say the same color or texture.`
Let's say each object category has four attributes: `'shape', 'color', 'texture', 'size'`. Let's say the following data is observed:
```javascript
var observedData = [{cat: 'cat1', shape: 1, color: 1, texture: 1, size: 1},
{cat: 'cat1', shape: 1, color: 2, texture: 2, size: 2},
{cat: 'cat2', shape: 2, color: 3, texture: 3, size: 1},
{cat: 'cat2', shape: 2, color: 4, texture: 4, size: 2},
{cat: 'cat3', shape: 3, color: 5, texture: 5, size: 1},
{cat: 'cat3', shape: 3, color: 6, texture: 6, size: 2},
{cat: 'cat4', shape: 4, color: 7, texture: 7, size: 1},
{cat: 'cat4', shape: 4, color: 8, texture: 8, size: 2},
{cat: 'cat5', shape: 5, color: 9, texture: 9, size: 1}]
```
Let's define the range of values of attributes:
```javascript
var values = {shape: _.range(11), color: _.range(11), texture: _.range(11), size: _.range(11)};
```
> One needs to allow for more values along each dimension than appear in the training data so as to be able to generalize to novel shapes, colors, etc.
>
Here each `attr` has its own `phi` and `alpha`:
```javascript
var categoryPosterior = Infer({method: 'MCMC', samples: 10000}, function(){
var prototype = mem(function(attr){
var phi = dirichlet(ones([values[attr].length, 1]))
var alpha = exponential(1)
return T.mul(phi,alpha)
})
var makeAttrDist = mem(function(cat, attr){
var probs = dirichlet(prototype(attr))
return Categorical({vs: values[attr], ps: probs})
})
var obsFn = function(datum){
map(function(attr){observe(makeAttrDist(datum.cat,attr), datum[attr])},
attributes)
}
mapData({data: observedData}, obsFn)
return {cat5shape: sample(makeAttrDist('cat5','shape')),
cat5color: sample(makeAttrDist('cat5','color')),
catNshape: sample(makeAttrDist('catN','shape')),
catNcolor: sample(makeAttrDist('catN','color'))}
})
```
> The program above gives us draws from some novel category for which we’ve seen a single instance. In the experiments with children, they had to choose one of three choice objects which varied according to the dimension they matched the example object from the category.
>
---
### Example: Beliefs about Homogeneity and Generalization
[In this study](https://scholar.google.com/scholar?q=%22The%20use%20of%20statistical%20heuristics%20in%20everyday%20inductive%20reasoning.%22), the authors found that:
> to what extent people generalise depends on beliefs about the homogeneity of the group that the object falls in with respect to the property they are being asked to generalize about.
>
Let's say on a new island you encounter one male person a tribe T.
__Obesity__: If he is obese, how likely are other male members of tribe T to be obese?
__Intuition__: Not so likely because obesity is a feature with heterogenous distribution within a tribe.
__Skin color__: If he is brown, how likely are other male members of tribe T to be brown?
__Intuition__: Quite likely because skin color varies across tribes but is uniform in a single tribe.
#### Analogy to bags with color balls
Bag: tribe
Color: obesity or skin color
Here is what they found:
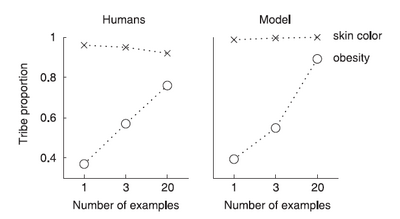
Again, a compound Dirichlet-multinomial distribution was used to model this experiment.
---
### ToDo: One-shot learning of visual categories
> __Motivation__: Humans are able to categorize objects (in a space with a huge number of dimensions) after seeing just one example of a new category. For example, after seeing a single wildebeest people are able to identify other wildebeest, perhaps by drawing on their knowledge of other animals.
Read [this paper (pdf)](http://proceedings.mlr.press/v27/salakhutdinov12a/salakhutdinov12a.pdf).
---
### ToDo: Get some ideas using overhypotheses from [this](https://sci-hub.tw/https://www.cambridge.org/core/journals/journal-of-child-language/article/variability-negative-evidence-and-the-acquisition-of-verb-argument-constructions/D62EDBFF5A8F1ACC821451FEAD3C88FB) paper.
###### tags: `probabilistic-models-of-cognition`