# w3filecoin pipeline
> Follow up from starting proposal https://hackmd.io/ZwnrfW3GR4GMnbCwzkh6zg?both
_Getting new uploads into Filecoin deals using ♠️_
## Motivation
Uploads made to the new api are not being stored in Filecoin Storage Providers.
The `dagcargo` implementation that we use for the old api was intended to be a short term fix. It's on life-support maintenance only. We could update it to source CARs from the new w3up s3 bucket, but the preference is to move on to the new way...
...and dagcargo aggregation was block based and expensive when we receive huge uploads with many blocks. We have an oportunity to simplify it by creating aggregates for deals out of the existing user uploaded CARs.
## Spade Integration
Riba is working on an api to get data into Filecoin deals and keep it there, called ♠️ aka https://spade.storage
Spade requires an aggregated CAR with size between 15.875GiB and 31.75GiB to create deals with Filecoin Storage Providers.
> Exact range (inclusive):[ 1+127*(1<<27) : 127*(1<<28) ]
web3.storage can receive CAR files of arbitrary sizes (up to 5Gb - S3 limit for single put operation). We need a strategy to track CAR files awaiting for being included in a Filecoin deal, so that these CARs can be aggregated by Spade.
web3.storage should persist commP hash of the aggregate CAR file where each individual uploaded CAR is included:
- we can use this mapping to get information about deals from Spade on demand (eg. current `api.web3.storage/status/:cid` gets information about deal)
- we should have a cache in place for these requests
Once tracked CARs total size is within the range above, we can ask Spade to collect them, compute the aggregate commP hash and handle the Filecoin deal on our behalf.
To ask Spade to collect the CARs and create the Filecoin deal, we should provide a Manifest with public URL of CARs to include in an aggregated deal, together with their md5 to guarantee data integrity.
**interface TBD**
- Inspiration from Riba https://tldp.org/HOWTO/Debian-Jigdo/howjigdoworks.html
- Send a report-URI
- allows us to generate receipt
- Garbagge collect, Cache
Other notes:
- tracking of these CAR files should? include a range without CAR header
- this allows Spade to not worry about removing CAR headers out, as well as to enable us to track a more accurate size
- But, will we need to compute md5 of the range?
## CAR aggregation strategies
Several options were already pointed out in previous proposal document.
:::info
Listing them here for convenience:
1. deal per account when near 31GiB
2. deal per space when near 31GiB
3. deal per uploads accross all accounts & spaces every 31GiB (what dagcargo v1 does today)
4. deal per upload (!many uploads are way less than 31GiB)
:::
Each one of the above strategies have different UX concerns, as well as different implementation complexities:
- Dividing deals based on account and space will likely mean longer times without deals. Taking into account our free model with 5GB, free users will basically be out of the equation for getting their content into Filecoin.
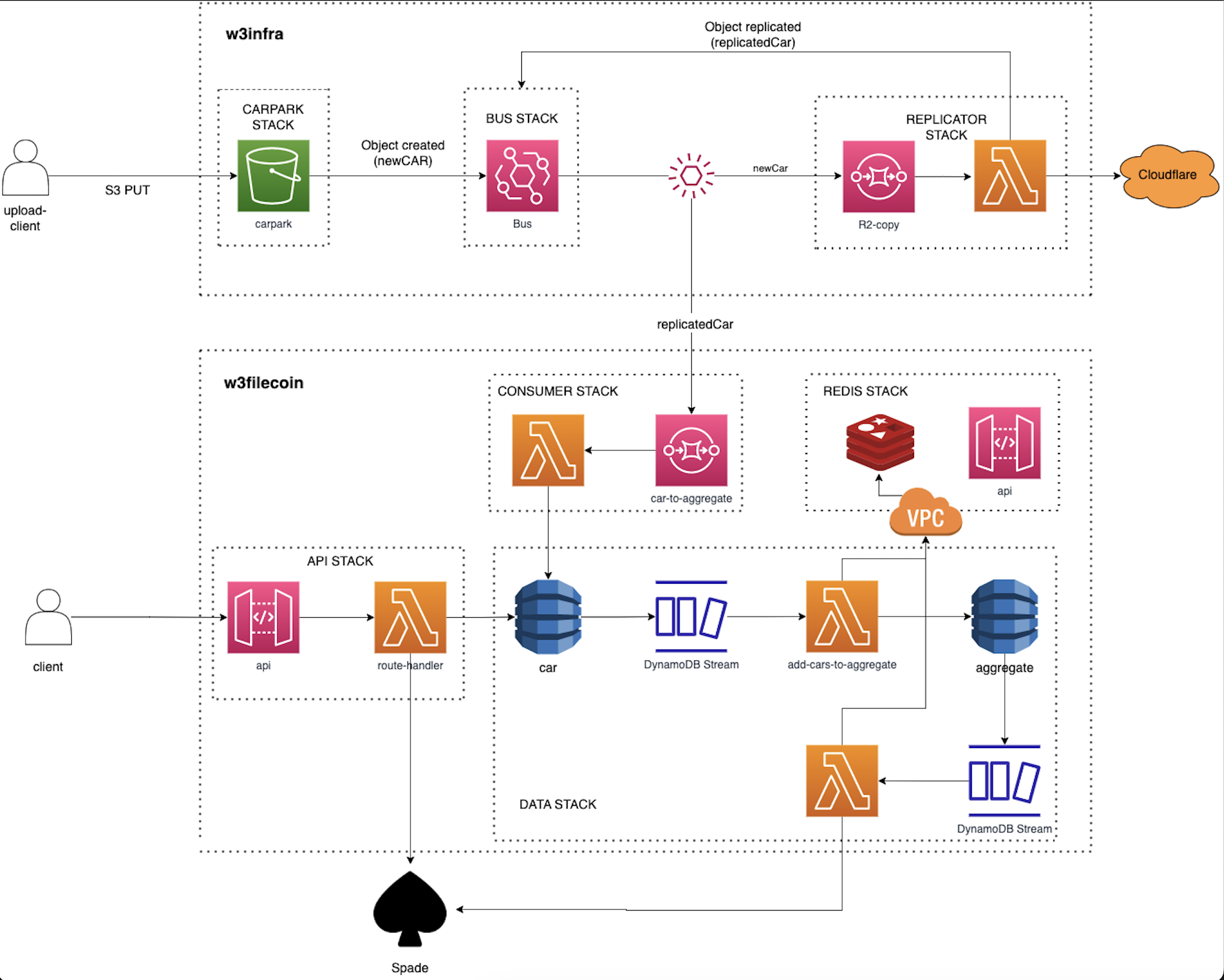
- In our running system [w3infra](https://drive.google.com/file/d/1HiRAMBjDmV21D_PDMkqAZb57pZhxzcnF/view?usp=sharing), each CAR written into the CARPARK bucket is handled in the same way. On CAR write event, multiple queues process this event asynchronously independently of where the CAR is coming from. Consequently, when grouping CARs based on a given characteristic (same account, same space, shards of same upload), we get out of the easy to follow system we built so far with predictable event sequences.
- Considering keeping shards of an upload together in same CAR aggregate:
- by protocol, we support incremental `upload/add`, where new shards are added under same root. Not having a definition of "complete upload" makes this solution difficult to achieve.
- given scope of `upload/add` is separate from scope of events triggered from writing CARs into buckets, extra complexity is introduced to guarantee that shards already were processed by R2 copy queue.
- this creates an hard limit on 31GiB Upload
- Creating aggregates where we don't care about where CARs come from means adding complexity to read from Filecoin Storage Providers.
Deal per stored CARs across all accounts & spaces is the easier/cleaner solution to implement in our system. It also will enable distribution of load across minders when reading from multiple sources a larger upload with CARs in multiple places.
## Proposed design
The high level flow for the Filecoin Pipeline is:
- Event is triggered once each CAR is copied into R2, its metadata {URL+size+md5} is added to the consumer of the w3filecoin pipeline (AWS SQS)
- SQS lambda consumer will add given entries to a CAR tracking DB where we keep track of the CARs awaiting a deal.
- Aggregates will be filled in as CARs are written into tracking DB. Once we get to a valid size, we can "lock" this aggregate and ask Spade to handle it.
- New pending aggregate is created for following elements in queue
- When deal is performed by Spade, a receipt is generated
Edit diagram URL: https://drive.google.com/file/d/1YkrtgJlBy_sR4VGQxudP61W5LCRChmcl/view?usp=share_link
### Filecoin pipeline trigger - consumer stack
We rely on R2 URLs as the source that `spade` will use. This way, we need to wait on the replicator to write CAR files into R2.
At the moment of writing, R2 does not provide bucket events like S3 does. As a consequence of this, we need to rely on an external source to trigger an event to the filecoin pipeline. Taking into account our current writes pipeline implementation, we always write to S3 which triggers an event to copy given CAR into R2 in a lambda. This CAR replicator lambda **can also be the trigger to the Filecoin pipeline** once CAR is replicated.
Further down the line, in case we make writing to R2 first to better optimize gateway performance, it will also be an easy path forward to hook Filecoin pipeline with it.
There are a couple of ways to wire up this trigger with the Filecoin pipeline:
1. Replicator lambda sends event to event bridge, being `w3filecoin` responsible for listening on the event bridge for `car-replicated` events
2. Rely on UCAN Stream (Kinesis) and specify a replicator UCAN protocol based on [invocations & receipts](https://hackmd.io/@gozala/invocations). `w3filecoin` would listen on UCAN STREAM and act upon replicated UCAN invocations.
Defining a UCAN protocol should be the way to go in the long run. Specially when we add features like allowing replication across Cloud Providers and their regions. Given the larger scope later on, for simplicity we should start with simply sending an event to Event Bridge and act upon it. It will be fairly simple swap to listen from UCAN Stream later on when we UCANIFY the replicator once we have invocations & receipts in place.
### Land CARs into aggregated deal
To put CARs into an aggregated deal, we will need to persist the metadata of CARs pending being added to a Filecoin deal. The flow to request a Filecoin deal to spade will be based in events triggered by Database writes to guarantee fault tolerance and state obervability. We can see this as loading up a ferry with CARs until it is ready for departure.
#### Data Model
**`car table`**: track CARs pending a Filecoin deal, including their metadata
link | size | url | commP | aggregateId? | insertedAt
-- | -- | -- | -- | -- | -- | --
`bagy...1` | `101` | `https://...` | `commp...a` | `a50b...1` | `2022-11-23T...`
string | number | string | string | string | string | string (ISO 8601)
_stored CAR CID_ | _CAR size bytes_ | _public URL_ | _bytes commP_ | _aggregate ID_ | _when DB recorded_
Notes:
* table entries can be dropped once deal is made
* maybe include range?
* maybe include `aggregateId` when sent to Spade to be able to query state? depends on how Spade API looks like
**`aggregate table`**: tracks aggregate state, including their size and CARs to be included
aggregateId | size | state | commP? | cars | insertedAt
-- | -- | -- | -- | -- | --
`a50b...1` | `101` | `https://...` | `bafy...1` | `Set<bagy...1>` | `2022-11-23T...`
string | number | string | string | Set | string (ISO 8601)
_aggregate ID_ | _accumulated size bytes_ | _aggregate state_ | _piece CID of the deal_ | _set of CARs_ | _when DB recorded_
#### Data Flow
A `car-to-aggregate` queue receives the flow of incoming CARs to aggregate for a deal, while a lambda consumer reads batches of these CARs and batch write them into a `car` dynamoDB table.
Insert events from `car` dynamoDB table are be propagated via dynamoDB streams in batches, so that we can associate them to an aggregate. We will not have the `commP` of a deal until the aggregated CAR is created by `spade`. Consequently, we need to generate an identifier for a `aggregateId` to bind multiple CARs together (see this later).
An aggregate can have a set of well defined states:
- `INGESTING`: aggregate currently being filled
- `READY`: aggregate is ready to be sent to Spade. It MUST not receive more CARs!
- `DEAL_PENDING`: aggregate information sent to Spade - might be redundant given retries will happen in case of failures
- `DEAL_PROCESSED`: spade told us that deal is made for given aggregate
<img width="512" alt="image" src="https://user-images.githubusercontent.com/7295071/215122521-66e92b4f-e671-4e23-b360-86e7d68f9f8d.png">
A lambda consumer `add-cars-to-aggregate` triggered by the `car` dynamoDB event stream will try to add the received CARs to the aggregate currently being filled. `aggregate` dynamoDB table tracks aggregate states. For this, a DynamoDB transaction should be attempted by the lambda consumer with following steps:
- Get aggregateId with `INGESTING` state (aka aggregate cursor)
- Created new one in case there is no aggregate in `INGESTING` state
- Update aggregate row with new CARs set + increment size
- Add update condition: in case size exceeds maximum size allowed by Spade this DynamoDB transaction should fail.
- DynamoDB event stream consumer MUST have [bisectBatchOnError](https://docs.aws.amazon.com/cdk/api/v2/docs/aws-cdk-lib.aws_lambda_event_sources.DynamoEventSourceProps.html#properties) enabled, so that batch is split in half and retried until it fits the maximum size
- In case current `INGESTING` aggregate has a bigger size than minimum required by Spade, aggregate state MUST be updated to `READY`.
- Follow up items in the stream will go to a new Aggregate given this is already locked and waiting for Spade.
Once a row in `aggregate` dynamoDB table is inserted/updated with state `READY`, a DynamoDB stream event is triggered. A lambda consumer should immediately be called (batch size of 1) to prepare the request Spade and perform it. It will assemble all the information from each CAR present in the aggregate and request Spade to assemble the aggregate and proceed with the Deal.
Note:
- Note that batch sizes need to be tweaked according to our usage. Starting with 100 and evaluate based on CAR sizes and load should be a good start.
- An aggregate will never reach an undesirable state with a strategy of relying on `bisectBatchOnError` and closing an aggregate as soon as it has the minimum size required:
- We limit CAR ingestion to 5Gb ([and probably will decrease](https://github.com/web3-storage/w3infra/issues/123) to 4GiB-padded)
- Spade requires an aggregated CAR with size between 15.875GiB and 31.75GiB
- Once an aggregate reaches a size of 15.875GiB, we will immediately close it in the current batch. In the event the current batch having quite big CAR files and current aggregate size exceeds 31.75GiB, the transaction will fail and lambda will re-run with half of the batch recursively until an aggregate has an acceptable size.
- We need a strategy for sizes in case we track complete CAR sizes, i.e. with CAR header
- if we do not use ranges to inform Spade, strategy to know when we have enough bytes needs to take into account that Spade will get rid of the CAR Headers. For this, we can create a formula that relies on the number of CARs in the aggregate to get a plausible accepted target number.
- TBD
## Spade reporting
When an aggregate+deal operation is requested to Spade, `w3filecoin` will wait on a report back from `Spade`. For this, the request to spade should include a `reportUrl` that Spade can use to report us back.
Once spade reports us back that a deal is done, following should happen:
- warm cache for client retrieval of deal status
- `aggregate` table is updated with status `DEAL_PROCESSED` and `commP` value
- `car` table rows from given `aggregateId` can be dropped - not needed for MVP
- Receipt is generated
## HTTP API
We need to allow requests to get information about the Filecoin state of a given CAR. We should not persist deal information on our own Databases given it will change over time with deal renewals, etc. With that in mind, we should simply proxy requests to Spade with a proxy on top for the HOT requests.
## Follow up needs
- Script to handle back filling
- UCANIFY replicator
## Other options
### Data Model with single table
**`aggregate table`**: tracks both the state of an aggregate and its CARs to be included in a Deal.
**pk**: aggregateId
**sk**: id - either `carCid` or `header` (aggregate grouping)
aggregateId | id | size | state? | commP? | metadata? | updatedAt
-- | -- | -- | -- | -- | -- | --
`2022-11-23T...` | `bagy...1` or `header` | `101` | string | string | JSON | `2022-11-23T...`
string | string | number | string | `INGESTING` | -- | string (ISO 8601)
_aggregate ID_ | _CID or Header_ | size bytes | _aggregate state_ | commP hash | CAR metadata | _when DB updated_
Example:
<table>
<thead>
<tr>
<th>aggregateId</th>
<th>id</th>
<th>size</th>
<th>state</th>
<th>commP</th>
<th>metadata</th>
<th>updatedAt</th>
</tr>
</thead>
<tbody>
<tr>
<td rowspan=4>`2023-01-01T...`</td>
<td rowspan=1>Header</td>
<td>30000</td>
<td>DEAL_PENDING</td>
<td></td>
<td></td>
<td>`2023-01-01T...`</td>
</tr>
<tr>
<td>`bagy...1`</td>
<td>10000</td>
<td></td>
<td>hash</td>
<td></td>
<td>`2023-01-01T...`</td>
</tr>
<tr>
<td>`bagy...2`</td>
<td>10000</td>
<td></td>
<td>hash</td>
<td></td>
<td>`2023-01-01T...`</td>
</tr>
<tr>
<td>`bagy...3`</td>
<td>10000</td>
<td></td>
<td>hash</td>
<td></td>
<td>`2023-01-01T...`</td>
</tr>
<tr>
<td rowspan=2>`2023-01-02T...`</td>
<td>Header</td>
<td>10000</td>
<td>INGESTING</td>
<td></td>
<td></td>
<td>`2023-01-02T...`</td>
</tr>
<tr>
<td>`bagy...4`</td>
<td>10000</td>
<td></td>
<td>hash</td>
<td></td>
<td>`2023-01-02T...`</td>
</tr>
</tbody>
</table>
#### Limitations
- We cannot use an update expression to increment. A read + write is always needed
---
@alan
1. SQS entry point queueing CARs that got in the system
2. A Lambda consumer of concurrency N will take X items as a batch from the SQS and writem them into `car` table
3. DynamoDB stream with lambda consumer concurrency 1.
or
1. SQS entry point queueing CARs that got in the system
2. A Lambda consumer of concurrency N will take X items as a batch from the SQS and write them into SQL `car` table +
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet