# 鐵人30天
## 機器學習Day1 (介紹與動機)
### 自我介紹
哈囉,我是輔仁大學資訊管理學系的學生,目前為大三生
至於為什麼會想要寫機器學習?
因為專題正在搞機器學習的技術,所以想說利用鐵人賽來做做筆記?
而今天我們要來介紹一下機器學習到底在幹嘛
很多新聞媒體提到的"AI"或是"Machine Learning"是什麼
### 首先,有關Machine Learning這回事
- Machine Learning是啥
相信大家都有聽過"AI" "機器學習"跟"深度學習"
到底他們有什麼不同,先為各位上一張示意圖

直白的來說就是
AI:用電腦程式去學習並模仿人類的行為
ML:需要得到資料,並且建立模型、學習
DL:跟ML相似,但是是透過類神經網路去學習
- Machine Learning用在哪
- 影像辨識
- 語音辨識
- 證券市場預測分析
- 醫學診斷
上述的只是機器學習應用的一小部分,可見機器學習對於現代科技來說有多重要!!
在經過上面簡單的說明過後,我們這次的目標是ML,而要怎麼建立模型怎麼學習,就讓我們慢慢的看下去吧!!
Refference:
[medium-什麼是人工智慧、機器學習和深度學習?](https://medium.com/@chih.sheng.huang821/什麼是人工智慧-機器學習和深度學習-587e6a0dc72a)
[維基百科-機器學習](https://zh.wikipedia.org/wiki/机器学习)
## 機器學習Day2(為什麼用python寫比較好)
### 機器學習用Python?
在資料科學的領域中,寫機器學習最常用到的程式語言大多是**R**跟**Python**
為什麼很多網路資料都會使用Python當作學習Machine Learning的程式語言而不是R呢?

##### 答案是因為:
- Python相對於R而言進入門檻較低,簡潔易學,應用的範圍也相較R來的廣
- Python有強大的支援包,例如Numpy, pandas, scikit-learn等等可以支援使用者進行數據分析
所以接下來我們將會使用Python作為我們的開發語言,而首先當然不免俗的先安裝開發環境
### 安裝Python
- Anaconda
我們今天將會下載Anaconda,首先介紹一下什麼是Anaconda
Anaconda 是一個免費開源的Python以及R的發行版本,是目前最受歡迎的Python數據科學平台
下載完之後,打開Anaconda的介面就可以準備開工了
這裡附上Anaconda的安裝教學
[medium-Anaconda介紹及安裝教學](https://medium.com/python4u/anaconda介紹及安裝教學-f7dae6454ab6)
##### Reference:
[TechBridge-如何使用Python學習機器學習](https://blog.techbridge.cc/2017/04/08/how-to-mastering-machine-learning-with-python/)
## 機器學習Day3(機器學習的種類)
依據資料與判斷過程和結果的不同,機器學習的種類大致上可分為三種類型:

1. 監督式學習
2. 非監督式學習
3. 強化式學習
下面為大家介紹以上三種不同的機器學習類別
### 監督式學習(Supervised Learning)- 給什麼他學什麼
監督式學習是將所有資料都貼上標籤(Label),告訴機器相對應的值,讓機器在輸出的時候能夠自行判斷誤差。
這種方法為人工分類,相對電腦而言,人類會更辛苦,因為要一個一個幫資料貼標籤。
優點是準確性較高,因為相當於你給電腦正確答案,並讓他在學習過程中透過對比誤差,
一邊學習一邊修正。但因為要一個一個幫資料標籤,花費的時間成本也較高,而且當範圍擴大,
資料量較大的時候,很難針對每一個資料都去標記他的特徵,所以在面對未知領域時,基本上是無法運作。

### 非監督式學習(Unsupervised Learning)- 放牛吃草
非監督式的學習不用人類一個個貼標籤,機器透過尋找資料的特徵,自行分類。
對人類而言比較輕鬆,但對機器來說很辛苦,而且誤差較大,假設給機器100張貓跟狗的照片,機器要自己中找尋特徵並分類。在做預測的時候,就用機器自行得出的分類方式進行預測,但是結果不一定準確。

### 強化式學習(Reinforcement Learning)- 未知探索和既有知識間取得平衡
強化式學習是讓機器直接從互動中學習,不給予任何資料,但是告訴機器走哪一部是對的、哪一步是錯的。
根據反饋的好壞從中去做修正,並逐漸取得最大化的預期利益。為了使非監督式學習有一定的正確性,
強化式學習是不可或缺的,若機器自行把貓辨識成一隻狗,而人類給予錯誤的訊息,機器會再一次去辨認其特徵和分類。
透過一次次的修改,最後的預測結果就會越來越準確。

---
以上就是今天的筆記
##### Reference
[三大類機器學習:監督式、強化式、非監督式](https://ai4dt.wordpress.com/2018/05/25/三大類機器學習:監督式、強化式、非監督式/)
[三分鐘了解機器學習的四個學習方式](https://www.ecloudvalley.com/zh-hant/machine-learning/)
## 機器學習Day4(ML 流程)
剛踏進Machine learning不知道從哪裡開始著手嗎?
就先讓我們來了解一下ML的整的過程吧~
### Machine Learning Process

#### 首先,要明確的定義問題
明確定義問題是進行機器學習工作流的第一步。由於機器學習和一般的 Web 網頁應用程式開發不一樣,其需要的運算資源和時間成本比較高,若能一開始就定義好問題並將問題抽象為數學問題將有助於要蒐集的資料集和節省工作流程的時間。
#### 獲取資料
資料集的完整性某種程度決定了預測結果是否能發揮模型最大功效。
#### 資料前處理
不論是從網路上爬下來的資料,或是從任何網站上取得的資料,我們都應該要先將資料處理好再交給機器去學習。
資料處理過程:
1. 處理缺失值
2. 去除極端值
3. 資料正規劃
4. 資料整合
#### 模型訓練與校正
可以用python的機器學習工具Scikit-Learn選擇想要的演算法,如果不知道要選擇哪一個演算法比較好的話,下面提供Scikit-Learn提供的cheet-sheet,可以一步一步比對找到適合資料的演算法。

#### 模型驗證
在找到適合的演算法後,對預測結果做檢查。以監督式學習來說,會將資料分成測試資料(testing data)和訓練資料(training data),在利用training data訓練好模型之後,針對testing data做預測,並且去計算預測的正確率。
#### 模型優化
一般來說,模型優化可以用的方法有下列幾種:
1. 特徵工程:選擇更適合特徵值或是更好的資料清理,某種程度上很需要專業知識的協助(domain konwledge)去發現和整合出更好的feature
2. 調整模型參數:調整模型的參數
3. 模型融合:結合幾個弱分類器結果來變成強的分類器
---
以上是今天的筆記
#### Reference
[用 Python 自學資料科學與機器學習入門實戰:Scikit Learn 基礎入門](https://blog.techbridge.cc/2017/11/24/python-data-science-and-machine-learning-scikit-learn-basic-tutorial/)
## 機器學習Day5(What is 缺失值 ?)
今天我們要進入資料前處理的部份
首先,先來認識一下資料缺失值
### 造成缺失值的原因
- 無意的:因一些作業疏失而造成的缺失值
- 有意的:有些數據集在特徵描述中會規定將缺失值視為一種特徵,這時候可將缺失值看作一種特殊的特徵值
- 不存在的:有些數據本身就不存在,譬如一個未婚者的配偶欄本身就是空的
```
數據中含有缺失值的變量稱為不完全變量,不含缺失值的變量稱為完全變量。
```
### 缺失值的種類
- 完全隨機缺失:數據的缺失是完全隨機的,不依賴也不影響任何完全變量或不完全變量。
- 隨機缺失:數據的缺失是不完全隨機的,該數據的缺失依賴於其他完全變量。
- 非隨機缺失:數據的缺失與不完全變量自身的取值有關。
### 處理缺失值的方法
#### 直接刪除
- 優點
- 最簡單粗暴
- 缺點
- 犧牲了大量的數據,透過刪除資料缺失值換取資料的完整性,但可能丟失隱藏的重要信息
- 如果缺失值的比例較大的時候,直接刪除可能會導致數據偏離
#### 數據填補
數據填補方式主要可以分類為三種:**替代缺失值**、**擬合缺失值**、**虛擬變量**
替換缺失值是通過其他非缺失值的相似性去填補,擬合是透過特徵建模來填補,而虛擬變量是透過衍生的新變量代替缺失值。
**替代缺失值**的方式大概有以下幾種:
1. 均值差補
若今天資料是定量資料(Quantitative),我們可以使用資料的眾數(mode)來填補,舉例來說,假設今天一個學校有500個男生跟100個女生,那麼對於其餘的缺失值我們會用人數較多的男生去填補。
若今天資料是定性資料(Qualitative),我們可以使用平均數(mean)或中位數(median)來填補,若特徵值為常態分佈的話(Normal distribution),使用平均值的效果會比較好;若特徵值因異常值的影響為非常態分佈的話,用中位數比較好。
> 註:這個方法雖然簡單,但是不夠精確,可能會引入噪音(Noise),或者會改變特徵原有的分佈。
2. 熱卡填補(Hot dick imputation)
3. K-平均演算法
**擬合缺失值**
擬合就是利用其他變量做模型的輸入進行缺失值的預測,跟正常建模的方法一樣,只是目標變成缺失值
> 註:如果其他特徵變量與缺失變量無關,則預測的結果毫無意義;如果預測結果相當準確,則說明這個變量完全沒有必要進行預測,因為這一定是跟特徵變量存在重複的信息。
**虛擬變量**
虛擬變量是缺失值的一種衍生變量,具體做法是通過判斷特徵值是否有缺失值來定義新的二分類變量。比如說,特徵為A的變量含有缺失值,這時我們定義一個新的變量B,如果A中特徵值有缺失,那麼相應的B中的值為1,反之為0。
#### 不處理
填補缺失值只是將未知的值用我們主觀估計值補上,不一定完全符合客觀事實,在對不完整的資料進行缺失值填補的時候,我們可能會改變原始資料的完整性。因此,在許多情況下,我們會保持原有的資料,在不影響資料結構的前提下對資料進行處理。
---
以上是今天的筆記。
#### Reference
[Python數據分析基礎 - 數據缺失值處理](https://zhuanlan.zhihu.com/p/40775756)
## 機器學習Day5(What is 缺失值 ?)
今天我們要進入資料前處理的部份
首先,先來認識一下資料缺失值
### 造成缺失值的原因
- 無意的:因一些作業疏失而造成的缺失值
- 有意的:有些數據集在特徵描述中會規定將缺失值視為一種特徵,這時候可將缺失值看作一種特殊的特徵值
- 不存在的:有些數據本身就不存在,譬如一個未婚者的配偶欄本身就是空的
```
數據中含有缺失值的變量稱為不完全變量,不含缺失值的變量稱為完全變量。
```
### 缺失值的種類
- 完全隨機缺失:數據的缺失是完全隨機的,不依賴也不影響任何完全變量或不完全變量。
- 隨機缺失:數據的缺失是不完全隨機的,該數據的缺失依賴於其他完全變量。
- 非隨機缺失:數據的缺失與不完全變量自身的取值有關。
### 處理缺失值的方法
#### 直接刪除
- 優點
- 最簡單粗暴
- 缺點
- 犧牲了大量的數據,透過刪除資料缺失值換取資料的完整性,但可能丟失隱藏的重要信息
- 如果缺失值的比例較大的時候,直接刪除可能會導致數據偏離
#### 數據填補
數據填補方式主要可以分類為三種:**替代缺失值**、**擬合缺失值**、**虛擬變量**
替換缺失值是通過其他非缺失值的相似性去填補,擬合是透過特徵建模來填補,而虛擬變量是透過衍生的新變量代替缺失值。
**替代缺失值**的方式大概有以下幾種:
1. 均值差補
若今天資料是定量資料(Quantitative),我們可以使用資料的眾數(mode)來填補,舉例來說,假設今天一個學校有500個男生跟100個女生,那麼對於其餘的缺失值我們會用人數較多的男生去填補。
若今天資料是定性資料(Qualitative),我們可以使用平均數(mean)或中位數(median)來填補,若特徵值為常態分佈的話(Normal distribution),使用平均值的效果會比較好;若特徵值因異常值的影響為非常態分佈的話,用中位數比較好。
> 註:這個方法雖然簡單,但是不夠精確,可能會引入噪音(Noise),或者會改變特徵原有的分佈。
2. 熱卡填補(Hot dick imputation)
3. K-平均演算法
**擬合缺失值**
擬合就是利用其他變量做模型的輸入進行缺失值的預測,跟正常建模的方法一樣,只是目標變成缺失值
> 註:如果其他特徵變量與缺失變量無關,則預測的結果毫無意義;如果預測結果相當準確,則說明這個變量完全沒有必要進行預測,因為這一定是跟特徵變量存在重複的信息。
**虛擬變量**
虛擬變量是缺失值的一種衍生變量,具體做法是通過判斷特徵值是否有缺失值來定義新的二分類變量。比如說,特徵為A的變量含有缺失值,這時我們定義一個新的變量B,如果A中特徵值有缺失,那麼相應的B中的值為1,反之為0。
#### 不處理
填補缺失值只是將未知的值用我們主觀估計值補上,不一定完全符合客觀事實,在對不完整的資料進行缺失值填補的時候,我們可能會改變原始資料的完整性。因此,在許多情況下,我們會保持原有的資料,在不影響資料結構的前提下對資料進行處理。
---
以上是今天的筆記。
#### Reference
[Python數據分析基礎 - 數據缺失值處理](https://zhuanlan.zhihu.com/p/40775756)
## 機器學習Day6(用Python讀資料)
我們在第2天已經安裝好了Anaconda,打開它可以看到Jupyter notebook,我們用它來寫Python
那今天我們要試著寫讀檔跟一些基本的資料操作。
首先讓我們把Pandas(類似python版的excel), numpy, matplotlib(畫圖套件)等套件讀進來
```python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
```
接下來我們可以利用Pandas的讀套件發法,讀取csv或是excel檔
```python
data = pd.read_csv('檔案路徑')
```
不過我們今天先懶惰一點,直接使用scikit-learn裡的資料包作為我們今天的測試資料
如果要使用scikit-learn的資料,理所當然,得先將套件讀進我們的程式裡頭
```python
from sklearn.datasets import load_boston
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
```
接下來我們可以看看資料裡有哪些特徵
```python
df = load_boston()
print(df.feature_names)
```
跑出的東西如下
```
array(['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD',
'TAX', 'PTRATIO', 'B', 'LSTAT'], dtype='<U7')
```
由此可知load_boston的特徵有上面的幾項,其實當你呼叫這個資料集時,它給的是一些回傳值譬如說:data,target,feature_names等等
想知道詳細一點的這裡附上官網文件的連結[load_boston](https://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_boston.html#sklearn.datasets.load_boston)
而今天的目標是先能夠讀得到資料,之後我們會開始對這些資料做一系列的處理。
---
以上是今天的筆記
#### Reference
[scikit-learn datasets load_boston](https://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_boston.html#sklearn.datasets.load_boston)
[pandas documents](https://pandas.pydata.org/docs/reference/index.html)
## 機器學習Day7(DIY測試資料)
前兩天我們有介紹過資料缺失值了,今天我們就試著來用Python實作看看
首先今天為了講求資料的可看性,我決定自己來建個小型的表格,這樣比較好看整體資料的變化
建立表格前先引入我們需要用到的函示庫,然後我們試著用pandas, numpy建立我們的表格
```python
import numpy as np
import pandas as pd
my_df = pd.DataFrame(data = np.random.randint(high = 30, size = (7,5)),
columns = list("ABCDE"), index = range(1,8))
my_df
```
我們要做一個7x5的陣列資料,資料的值用隨機的亂數填寫,我們設最大值是30,然後把columns的名字改成ABCDE,
rows的名字改成1~7
結果顯示如下圖
)
接著我們來故意隨機選6個資料挖空
```python
for i in range (6):
x = np.random.randint(1,8)
y = np.random.choice(list("ABCDE"))
my_df.loc[x,y]= None
my_df
```
結果如下
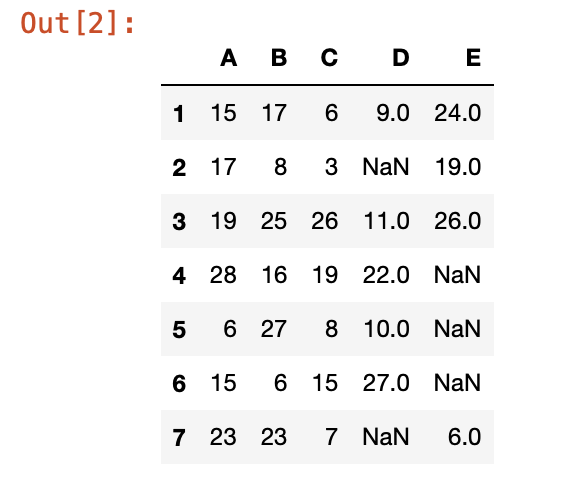
這樣我們今天的測試資料就用好了~
---
以上是今天的筆記
#### Reference
[numpy documents](https://numpy.org/doc/stable/reference/random/generated/numpy.random.RandomState.randint.html#numpy.random.RandomState.randint)
[pandas documents](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.loc.html#pandas.DataFrame.loc)
## 機器學習Day8(用Python處理資料缺失值)
接續昨天的進度,我們今天要來處理我們自己資料的缺失值啦~
今天我們會用到pandas來處理我們的缺失值
先介紹一下pandas有哪些處理缺失值的方法吧
### 查看是否有缺失值
如果今天想要確認資料有沒有缺失值,可以透過呼叫pandas的函式**isnull()**,把isnull()接在你的dataframe後面或是series後,以便查看,如果是缺失值(包含NA, NA values, numpy.NaN),則會在該資料格的位置回傳True,如果不是缺失值(包括空字串'', numpy.inf)則回傳False;同樣的如果想要知道有哪些不是缺失值,可以使用notna(),則回傳值與isnull()的回傳值相反
拿昨天做好的資料當例子:
```
df2
```
先將dataframe印出來看一下

接著用isnull()看看有哪些地方有缺失值
```
df2.isnull()
```
結果如下圖

### 填入缺失值
接下來如果我們想要針對缺失值做填補的動作,可以使用pandas的fillna()
假設我們要在空值填上no表示他是缺失的
```
df2.fillna('no')
```

或是我們可以針對其中一欄做填補
```
df2['B'].fillna(8)
```
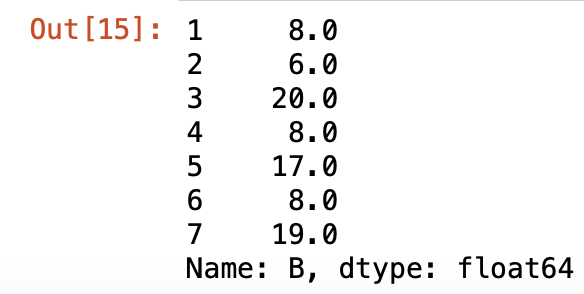
### 刪除含缺失值資料
有很多時候,因為資料筆數很大,若有缺失值的資料佔少數會習慣把它刪除,這時我們可以用dropna()來進行刪除
```
df2.dropna(axis=0)
```
axis=0代表對水平方向的欄位做刪除,axis=1代表對垂直欄位做刪除,結果如下
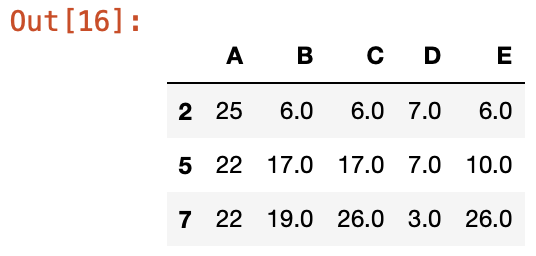
---
以上是今天的筆記
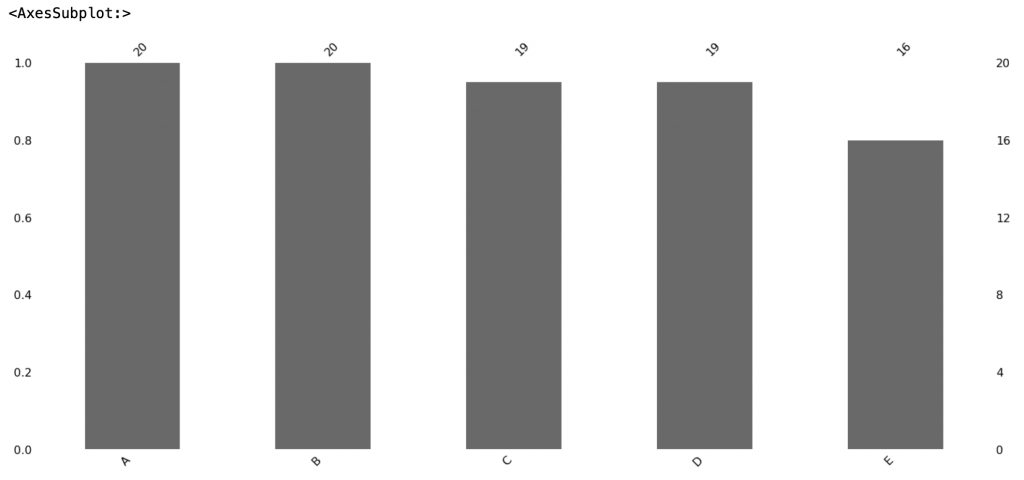
## 機器學習Day9(缺失值視覺化套件)
今天要來介紹一些可以顯示資料缺失值的python套件
### MissingNo
missingno 是一個能將缺失值視覺化的一個python套件,可以顯示出的圖表包括Matrix, Bar chart
Heatmap
首先要做的就是把missingno import進來
```python
import missingno as msno
```
接著可以選擇顯示Matrix, Bar chart或是Heatmap
```python
msno.matrix(df)
msno.bar(df)
msno.heatmap(df)
```
可以顯示出下列圖表

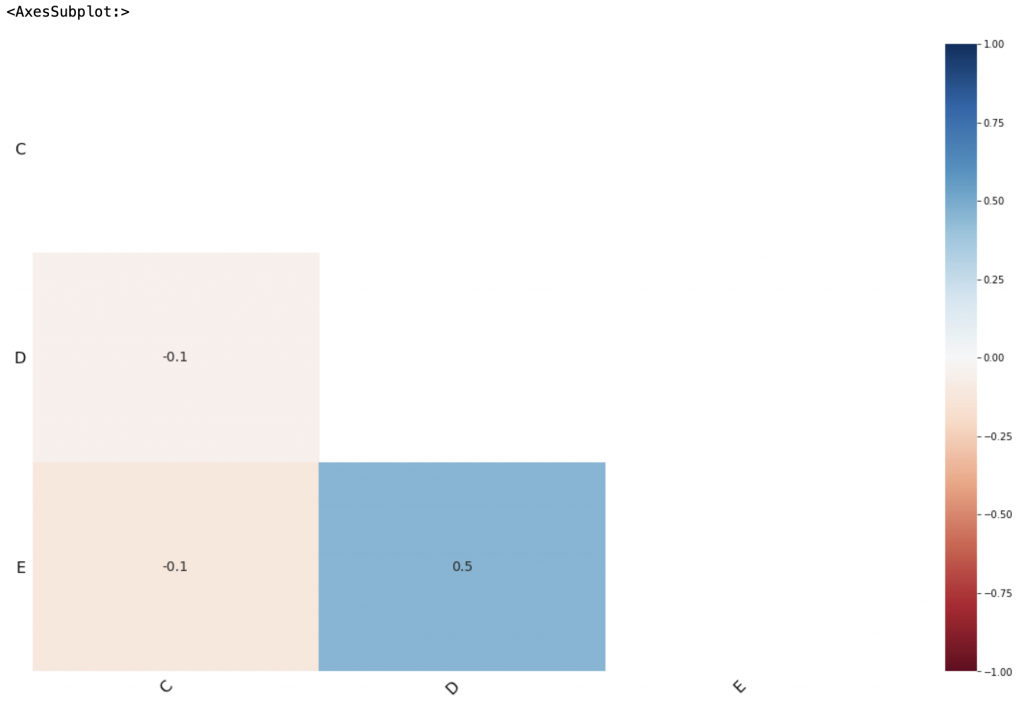
---
以上是今天的筆記
## 機器學習Day10(有關於資料,你所需要知道的事)
在載入資料後,我們在資料前處理的時候,時常需要去分辨每個變數的資料型態。
基本上分為以下兩種:
### Numerical Data(數值型)
**這個資料型態的範疇包含連續資料及離散資料,共通點是都以數字組成**
數值如果是整數型態的,則屬於離散資料
如果是屬於連續不斷的,則是屬於連續資料,其中還能劃分成等距資料及等比資料。
### Categorical Data(類別型)
**包括名目資料以及次序資料,其中的共通點為組成皆為文字(也有數字的,但是數字代表的意思是標籤而非數值)**
如果資料間有大小順序則屬於次序資料,如果是沒有順序的則為名目資料。
當資料前處理時,必須把數值資料與類別資料劃分開來,以免模型誤把類別資料的數字看作是數值,這樣一來會導致預測的效果降低。
當我們歸類好資料後,接著我們要來學習資料該如何處理。
### 訓練及測試資料
對於Supervised Learning來說,我們必須使用標註資料(Labeled Data)來做訓練。
因此我們需要訓練資料(Training Data)
當然我們不可能把所有搜集到的資料都拿去做訓練,還得保留一些資料當作測試資料(Testing Data),幫我們測試訓練出來的模型到底準不準確。
這些資料必須是不同的,否則會有作弊嫌疑,想像如果在考試前拿到考題,那麼理應(如果有認真學習的話)會得到很高的成績,雖然成績高,但不能代表學生理解學到的知識,機器也是一樣。
所以最簡單的方式就是將資料分割成兩部分,一部份當訓練資料,另外一部分當作測試資料。通常訓練資料會佔大約60~80%,剩下的當作測試資料。
---
以上是今天的筆記
## 機器學習Day11(機器學習數學 -- 資料相似度)
在進入真正的機器學習領域之前,我們先來看一下一些相關的數學知識。
### 資料相似度
資料相似度,顧名思義指的是用數值衡量資料之間的相似程度,以最常見的距離算法來看的話,如果兩個特徵的相似度低,距離算出來就會比較大;反而言之,相似度高,距離就小。
接下來讓我們來介紹常見的距離相似度算法
### 歐幾里德距離(歐式距離)
歐式距離是最常見的距離計算方式,歐式距離也被叫做簡單距離,如果今天資料較密集或是資料是連續性的,那麼就適合用歐式距離算資料間的相似性。
公式如下:

### 曼哈頓距離
曼哈頓距離是將矩陣中兩個點的x軸差跟y軸差相加,也被叫做L1 distance 或是 L1 norm

### Cosine 相似度
cosine相似度常用於文字探勘(text mining)中的文件比較,通過測量兩個向量的夾角之間的餘弦值來比較相似度。
0度角餘弦值是1,而其他任何角度的餘弦值都不大於1;並且其最小值是-1。

---
以上是今天的筆記
### Refference
[FIVE MOST POPULAR SIMILARITY MEASURES IMPLEMENTATION IN PYTHON](https://dataaspirant.com/five-most-popular-similarity-measures-implementation-in-python/)
[餘弦相似性](https://zh.wikipedia.org/wiki/余弦相似性)
## 機器學習Day12 (機器學習數學 -- 資訊熵)
今天要來探討一下什麼是資訊熵,原本熵是起源於物理,用來度量一個熱力學系統的無序程度,
後來克勞德·艾爾伍德·夏農將熱力學的熵,引入到資訊理論,用來測量資訊的不確定性。
說了那麼多,我們還是來舉個例子讓大家比較容易理解Entropy到底有啥用

搭配上面的公式,我們來簡單的舉個例子
假設今天我們的容器中有四顆球,球的顏色有紅的跟藍的

第一個容器裡我們有四顆紅球,也就是說,不關今天我們怎麼拿,拿到的一定是紅球,所以今天第一個容器的知識量較高,不確定性較低,而資訊熵也就比較低。
再來看第二個容器裡,我們有三顆紅球、一顆藍球,所以今天我們有機會拿到藍球,知識量中等,不確定性也中等,資訊熵也中等。
最後我們看到第三個容器中,有兩顆紅球跟兩顆藍球,今天拿到紅球跟藍球的機率一樣,所以我們隨便拿的話不確定會拿到紅球還是藍球,這樣一來第三個容器的知識量就很低,不確定性非常高,相對的資訊熵也就很高。
透過計算樣本的資訊熵,我們可以知道怎樣的分配會讓資訊量傳遞達到最大效益,同時資訊熵衍伸出的東西有像是Information Gain(資訊獲利),是在決策樹中常會用到的分類依據。所以今天把熵學起來,在之後的機器學習道路上,一定有機會用得到~
---
以上是今天的筆記
### Reference
[Shannon Entropy, Information Gain, and Picking Balls from Buckets](https://medium.com/udacity/shannon-entropy-information-gain-and-picking-balls-from-buckets-5810d35d54b4)
## 機器學習Day13(決策樹演算法)
在開始分析資料之前,我們來稍微介紹一下之後會用到的演算法,今天會先介紹決策樹,後面會做實作演練。
### 什麼是決策樹
決策樹是一種分類問題的算法,這種算法的過程直覺且單純,是個執行效率高的監督式學習模型。
他可以做分類也可以做迴歸分析,優點在於比其他機器學習的模型要快。
此外,在每個決策階段,做的決定都非常明確,不是yes就是no,相較於其他模型,我們更容易理解及解釋它內部的運作細節。
舉個例子解釋,假如下圖是我們要分類三個主題類型的照片:火山、海洋、森林,這三種主題的照片有著不同類型的主色,火山偏紅、海洋偏藍、森林偏綠,那我們可以將決策樹設計成下圖

看起來很容易,但回歸現實層面,當我們要設計此機器學習的架構時,要怎麼知道分幾個節點,把哪個解點擺在起始根部,結點判斷的依據為何?這時候我們會用到決策樹演算法。著名的有Cart, ID3, C4.5...等。他們的特色是可以將特徵量化,自動建構並決定出決策樹的各個節點。
我們可以看到上圖從第一個節點依據給定的條件,將資料分割到不同邊,分割的條件是:**這樣的分割要能得到最大的資訊增益(Information Gain)**
而明天我們會針對資訊增益的部分,再另做詳細解說。
---
以上是今天的筆記
### Reference
[決策樹 Decision trees](https://chtseng.wordpress.com/2017/02/10/決策樹-decision-trees/)
[[資料分析&機器學習] 第3.5講 : 決策樹(Decision Tree)以及隨機森林(Random Forest)介紹](https://medium.com/jameslearningnote/資料分析-機器學習-第3-5講-決策樹-decision-tree-以及隨機森林-random-forest-介紹-7079b0ddfbda)
## 機器學習Day14(決策樹演算法2)
延續我們昨天講到的資訊增益(Information Gain),我們今天要來主要重點講什麼是資訊增益,以及決策樹演算法的基礎數學理論有哪些。
### 資訊增益
資訊增益用到的概念是我們之前有提到的資訊熵,用資訊增益來計算節點的演算法包括ID3, C4.5, C5.0,其中C4.5跟C5.0是ID3的改進版本,待會舉個例子更加暸解資訊增益是什麼,首先來複習一下Entropy,公式如下:
`
Entropy = -p * log2 p – q * log2q
`
p:成功的機率(或true的機率) q:失敗的機率(或false的機率)
Infromation Gain的算法就是將母節點的Entropy減去子節點加權過後的Entropy
我們再用一張圖來解釋Entropy,請看下圖:

圖中可以看到,資料C屬於同一屬性,不用多做說明;資料B需要稍作解釋,才能說明其中三個不同資料點的意義;資料A需要做的解釋更多。因此可以得出一個結論,越純淨的資料需要的資訊量越少,反之雜亂的資料需要的資訊量越多。
而以Entropy來表示,如果資料都一樣那麼entropy就是0,如果資料各有一半不同,那麼entropy就是1。
所以如果我們用決策樹使用Information Gain,那麼我們就會用到entropy來計算我們的節點,例子如下:

我們想要利用上圖的資料預測喜歡打板球的學生,已知有兩種分類方法,我們要試著來比較看看哪一個分法較佳。
我們用Information Gain來做做看:
1. 首先我們計算一下母節點的Entropy,打板球跟不打板球的學生各佔一半,因此Entropy為1

2. 以性別作為區分的話:
Female節點:十位女性,其中2位打板球10位不打,因此Entropy為
-(2/10) log2 (2/10) – (8/10) log2 (8/10) = 0.72
Male節點:20位男性,其中13位打板球7位不打,因此其Entropy為
-(13/20) log2 (13/20) – (7/20) log2 (7/20) = 0.93
故,以性別分類的Entropy加權後為:
(10/30)*0.72 + (20/30)*0.93 = 0.86
Information Gain為 `母節點Entropy - 子節點加權過的Entropy`
**1 - 0.86 = 0.14**

3. 以班級作為區分的話:
Class IX節點:此班14位同學,其中6位打板球8位不打,因此Entropy為:
-(6/14) log2 (6/14) – (8/14) log2 (8/14) = 0.99
Class X節點:此班16位同學,其中9位打板球7位不打,因此Entropy為:
-(9/16) log2 (9/16) – (7/16) log2 (7/16) = 0.99
故,以班級分類分類的決策樹其Entropy加權後為:
(14/30)*0.99 + (16/30)*0.99 = 0.99
所以Information Gain為:
**1 - 0.99 = 0.01**

`因此結論為以性別作為區分的方法較佳,原因是因為用這個方法能獲得的資訊增益最高`
明天我們要來講決策樹很常使用的演算法CART中,用到的數學模型Gini Index(吉尼係數)
---
以上是今天的筆記
### Reference
[決策樹 Decision trees](https://chtseng.wordpress.com/2017/02/10/決策樹-decision-trees/)
## 機器學習Day15(決策樹演算法3)
今天我們要來介紹決策樹演算法中,最常被使用的其中一個演算法CART中,使用的數學模型Gini Index.
首先先簡單介紹一下CART,CART是Classification跟Regression Tree的縮寫,字面意思就是CART兼具分類及回歸分析,能夠做數字預測也可以做分類預測,由於不限制自變數與應變數的型態,因此在使用上較有彈性。
介紹完CART後,接下來我們要講一下Gini Index
### Gini Index(基尼係數)
Gini係數與Information Gain 有著一個很大的不同,就是Information Gain可以一次產生多個不同的節點,
但是Gini Index一次只能產生兩個節點,即Ture或False的二元分類。Gini係數代表的意思為不平均程度,如果今天分配的結果非常不平均,則Gini係數為1;如果結果很平均,則Gini係數為0。
公式如下:

看完上面的式子可能不知道Gini Index到底怎麼算,下面舉個跟昨天一樣的例子。

用性別來分:

Female節點:十位女性,其中有2位打板球10位不打,Gini係數為
1 - (0.2)^2 + (0.8)^2 = `0.32`
Male節點:20位男性,其中有13位打板球7位不打,Gini係數為
1 - (0.65)^2 + (0.35)^2 = `0.45`
加權後的Gini係數為: (10/30) * `0.32` + (20/30) * `0.45` = `0.41`
用班級來分:

Class IX節點:此班14位同學,其中6位打板球8位不打,因此Gini係數為
1 - (0.43)^2 + (0.57)^2 = `0.49`
Class X節點:此班16位同學,其中9位打板球7位不打,因此Gini係數為
1 - (0.56)^2 + (0.44)^2 = `0.49`
加權後的Gini係數為:(14/30) * `0.49` + (16/30) * `0.49` = `0.49`
因為Gini係數越小代表分配的結果越平均,所以比較兩種分類方法的Gini係數後,顯示以性別做區分比較好。
---
以上是今天的筆記
### Reference
[資料分析系列-探討決策樹(1)](https://medium.com/企鵝也懂程式設計/資料分析系列-探討決策樹-1-1cc354484559)
[決策樹 Decision trees](https://chtseng.wordpress.com/2017/02/10/決策樹-decision-trees/)
[基尼係數-維基百科](https://zh.wikipedia.org/wiki/基尼系数)
## 機器學習Day16(決策樹演算法4)
今天我們要正式開始實作的部分
我們今天要用到的資料集是scikit-learn裡頭的Iris鳶尾花資料集(因為有超多人用的,所以我也拿來用看看)
首先我們先將我們會用到的數據庫載入程式碼
```python
from sklearn import tree
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
```
然後我們載完數據庫後先讀入我們要的鳶尾花資料
```python
iris = load_iris()
iris_X = iris.data
iris_Y = iris.target
```
接下來我們來將資料分割成訓練資料70%跟測試資料30%
```python
train_x, test_x, train_y, test_y = train_test_split(iris_X, iris_Y, test_size = 0.3)
```
然後接下來建立分類器
scikit learn裡分類樹有一個叫criterion的參數是可以選擇要用Gini還是Entropy,預設是Gini,而我們今天想要先用CART做為我們的模型演算法,所以就不用調整參數
建完分類器後,我們要把訓練資料`fit`進去,讓他去學習
```python
clf = tree.DecisionTreeClassifier()
iris_clf = clf.fit(train_x, train_y)
```
最後我們要去看看他預測的結果怎麼樣
```python
predict = iris_clf.predict(test_x)
# 預測結果
print(predict)
# 標準答案
print(test_y)
```

結果顯示他全中啊!!
為了證明沒有出錯,我們把測試資料改成40%試試看
```python
train_x, test_x, train_y, test_y = train_test_split(iris_X, iris_Y, test_size = 0.4)
```

眼尖的話還是可以發現,預測出來有一些些錯誤,所以模型應該是沒有出錯的
為了我們的眼睛著想,我們可以用confusion matrix(混淆矩陣)去看看實際上命中的有幾個,出錯的有幾個
首先我們要使用`sklean.metrics`中所含有的`confusion_matrix`
```python
from sklearn.metrics import confusion_matrix
print(confusion_matrix(test_y, predict))
```

這樣我們就可以知道有哪些是命中0,1,2的哪些是誤判的啦~
另外我們還可以計算準確率(Accuracy)來看看預測的成效如何
```python
from sklearn.metrics import accuracy_score
accuracy_score(test_y, predict)
```
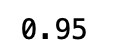
看來準確率頗高的
那麼決策樹就介紹到這邊,接下來將介紹其他不同的演算法
---
以上是今天的筆記
### Reference
[[第 23 天] 機器學習(3)決策樹與 k-NN 分類器](https://ithelp.ithome.com.tw/articles/10187191)
[sklearn.tree.DecisionTreeClassifier](https://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html)
[Decision Trees in Python with Scikit-Learn](https://stackabuse.com/decision-trees-in-python-with-scikit-learn/)
## 機器學習Day 17(Random Forest演算法)
今天我們要簡單的來介紹一下什麼事隨機森林演算法
隨機森林,字面意思就是從眾多的樹裡頭挑選一個出來,而他原本的概念是利用很多顆的CART決策樹(使用Gini算法的),並且加入隨機分配的訓練資料,以大幅增近最終的運算結果。
這個演算法就是結合很多個**弱學習器**來建立一個**強學習器**,而這種方法也被稱作「Ensemble Method」。
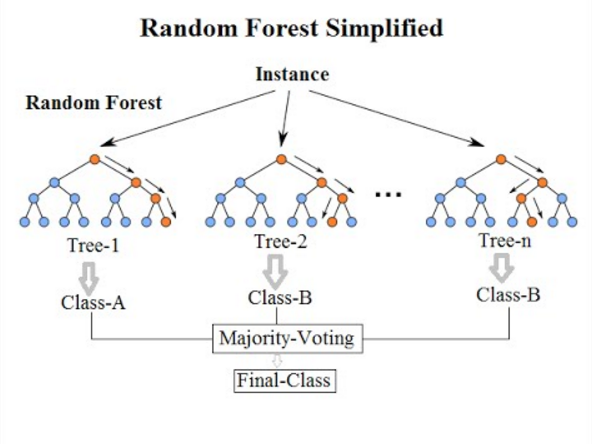
但是我們只有一個數據集,如果要形成很多顆具有差異性的樹以進行Ensemble learning,必須得產生不同的數據集才能形成多顆具差異性的CART樹,做法有下面兩種:
### Bagging(Boostrap Aggretion)
Bootstrap指的是從原有的Data中重新取樣產生出另一個新的Data,取樣的過程是均勻且可重複的,
利用Bootstrap,我們就可以從原本的一組Data產生出更多新的Data。
此方法會從原本的Training Data取出K個樣本,再從這K個樣本中訓練出K個不同的分類器(這裡為tree)。
每次取出的樣本皆會再放回原本的資料中,因此K個樣本中可能會有部分資料重複,但是由於每棵樹的樣本還是不同,所以訓練出的分類器還是會有差異,而每個分類器的權重一致,最後採投票的方式(Majority Vote)得到最後的結果。
### Boosting
Boosting的做法跟Bootstrap類似,只不過他更加強調對錯誤的部分加強學習以提升整體的效率。透過將舊有的分類器錯誤資料權重提高,加重對錯誤資料的學習,這樣一來新的分類器就可以學到分類錯誤資料(Misclassified Data)的特性,進而提升分類正確率。就像做完題目時會回頭針對答錯的題目做加強一樣。
而Random Forest則是利用 Bagging + Decision Tree
今天的介紹到這裡,明天試著用Random Forest實作看看。
---
以上是今天的筆記
### Reference
[ML入門(十七)隨機森林(Random Forest)](https://medium.com/chung-yi/ml入門-十七-隨機森林-random-forest-6afc24871857)
## 機器學習Day 18(Random Forest演算法2)
今天我們一樣用鳶尾花的資料集當作訓練資料,然後演算法改成用Random Forest實際操作一次
一開始一樣先引入鳶尾花的資料
```python
from sklearn.datasets import load_iris
iris = load_iris()
```
看一下裡面有哪些變數
```python
print(iris.target_names)
print(iris.feature_names)
```

然後製作一個DataFrame包含鳶尾花的資料
```python
import pandas as pd
data = pd.DataFrame({
'sepal length':iris.data[:,0],
'sepal width':iris.data[:,1],
'petal length':iris.data[:,2],
'petal width':iris.data[:,3],
'species':iris.target
})
data.head()
```
分訓練資料跟測試資料
```python
from sklearn.model_selection import train_test_split
X=data[['sepal length', 'sepal width', 'petal length', 'petal width']]
y=data['species']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
```
建立分類器
```python
from sklearn.ensemble import RandomForestClassifier
#設定有100個不同的樹
clf=RandomForestClassifier(n_estimators=100)
clf.fit(X_train,y_train)
y_pred=clf.predict(X_test)
```
顯示正確率
```python
from sklearn import metrics
print("Accuracy:",metrics.accuracy_score(y_test, y_pred))
```
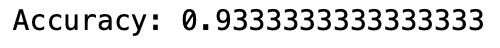
這樣就是隨機森林的實作code啦
---
以上是今天的筆記
### Reference
[Simple Random Forest - Iris Dataset](https://www.kaggle.com/tcvieira/simple-random-forest-iris-dataset)
## 機器學習Day19(KNN演算法)
今天同樣的要來介紹演算法了~
很常聽到KNN但是到底KNN是什麼意思?
KNN 是 K Nearest Neighbor 的縮寫,其字面意思就是K個最近的鄰居
到底找K個最近的鄰居要幹嘛呢,下面將為您介紹
### 簡介
開始正式探討什麼事KNN之前,我們先用一個例子讓大家可以更明白KNN的運作
在Movie Category 這個表格中,記錄著電影的名稱、電影有幾次踢腳的動作、電影有幾次親吻的畫面、電影的分類,而這些電影資料被歸類為愛情電影(Romance)和動作電影(Action)這兩類,但有一筆資料「?」沒有被分類到。

下面用二維平面來顯示「kicks」跟「kisses」跟電影的關係

那麼「?」這部電影的電影類型應該是什麼呢?
KNN就是找在他附近的電影是什麼類型,發現Beautiful Woman、California Man的type都是Romace
所以合理推測「?」應該也是Romace類型的電影。
統整來說,KNN做的事情就是
> **假設欲預測點是 i
找出離 i最近的 k 筆資料多數是哪一類,預測 i 的類型**
Given a test instance i, find the k closest neighbors and their labels
Predict i’s label as the majority of the labels of the k nearest neighbors
那麼接下來我們來看看KNN的核心知識吧
### KNN距離與相似度的衡量
在KNN的演算法中,最常用到來計算距離的方法有之前提過的歐式距離(Euclidean distance), 曼哈頓距離(Manhattan distance)跟餘弦相似度(Cosine similarity)。具體要用哪種方法必須視資料的情況而定,對於關係型資料,最常用歐式距離;對於文字分類來說,使用餘弦相似度比歐式距離更合適。
### K值怎麼選
選擇一個好的K值可以讓訓練出來的model有好的彈性,避免發生Overfitting 或是 Underfitting。
**K值是基數偶數?**
如果K值是偶數的話,有可能碰到無法直接做分類的情況,需要額外針對該情況做exception handling
例如K=4,如果剛好找到附近有兩個A type的資料跟兩個B type的資料,則會導致無法判斷結果
**K值的選擇**
如果K = 1的話會導致Overfitting
> Overfitting,因為參數過多導致過度符合Training set的資料特性,使得其無法預測較為普遍的資料集
如果K = n的話會導致Underfitting,預測結果一定是資料佔多數的那一類別,有分跟沒分一樣。
**結論就是**
K=1的時候容易導致Overfitting
K很大的話會導致Underfitting
因此選擇K值的方式一般來說都是從小的值選到大的值,藉由不斷調整K值的大小來使得樣本分類最優,不過有一個經驗規則:*k一般低於訓練樣本數的平方根。 *
---
以上是今天的筆記
### Reference
[[Machine Learning] kNN分類演算法](https://medium.com/@NorthBei/machine-learning-knn分類演算法-b3e9b5aea8df)
[KNN演算法(有監督學習演算法)](https://www.itread01.com/content/1546211528.html)
## 機器學習Day20(KNN演算法2)
今天要來做KNN的實作
首先先引入模組,今天我們會用到scikit learn的knn模組
```python
from sklearn.neighbors import KNeighborsClassifier
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn import metrics
```
今天一如往常的使用鳶尾花資料集當作我們的訓練資料
```python
iris=datasets.load_iris()
X=iris.data
y=iris.target
```
把資料分成訓練資料70%跟測試資料30%
```python
X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.3,random_state=123)
```
再來就是建立模型了
scikit-learn的KNeighborsClassifier有幾個參數先了解一下
- Parameter:
- **n_neighbors**: 簡單來說就是設定K的值,預測為5
- **weights**: 權重,有兩種可選,第一種是'uniform',意思是每個點的權重都一樣;第二種是'distance',顧名思義是以距離來分配權重,離目標點的距離越近,所分配到的權重越大
- **p**: 衡量距離的方法,有1跟2。1就是Minkowski distance(L1),2就是Minkowski distance(L2),預測是2。之前講資料相似度的地方有介紹到,不懂的可以去看一下,
接著建模
```python
clf = KNeighborsClassifier(n_neighbors = 3, weights='distance')
clf.fit(X_train,y_train)
clf.predict(X_test)
```

最後我們要來看準確度評估
```python
clf.score(X_test,y_test)
```
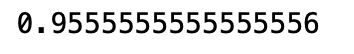
那麼如何要找尋適合的K值
```python
accuracy = []
for k in range(1, 100):
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(X_train, y_train)
y_pred = knn.predict(X_test)
accuracy.append(metrics.accuracy_score(y_test, y_pred))
k_range = range(1,100)
plt.plot(k_range, accuracy)
plt.show()
```
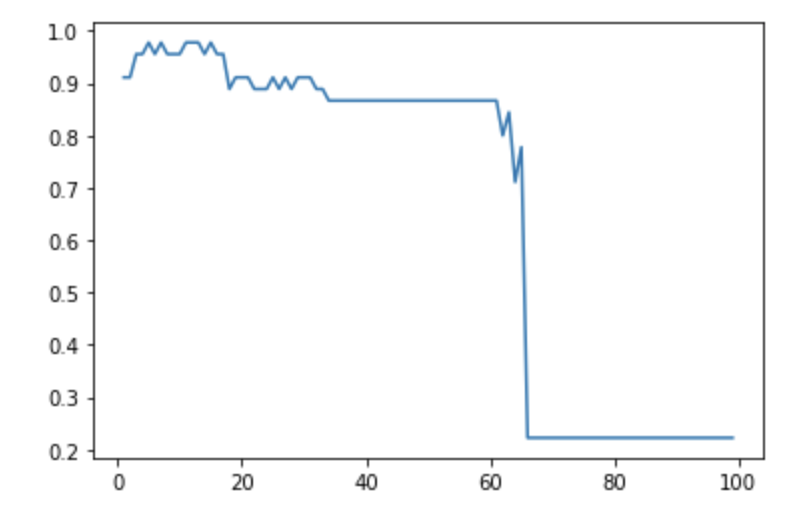
可以看到當K值越大,準確度越來越差
那麼今天的介紹就到這
---
以上是今天的筆記
### Reference
[[Python實作] K-近鄰演算法 KNN](https://pyecontech.com/2020/05/03/python實作-k-近鄰演算法-knn/)
## 機器學習Day21(Classification v.s Regression)
今天要回頭來講分類問題跟迴歸問題的差別,為什麼兩個方法的問題不能用對方的方法去解決。
前面的文章只有提到離散資料適合使用分類方法解決,連續資料適合用迴歸方法解決,但是到底是為什麼呢?
首先先用簡單的數學說明一下兩者的差異
假設今天有一個方程式y=wx+b可以用來表達我們資料及的資料分布狀況,y是我們要預測模擬的結果(Label);x是我們拿來預測模擬的屬性(Feature)。而監督式學習的目標是找到適合的w(weight,權重)跟b(bias)讓我們再匯入資料時(x1,x2,x3...)可以模擬出結果y。
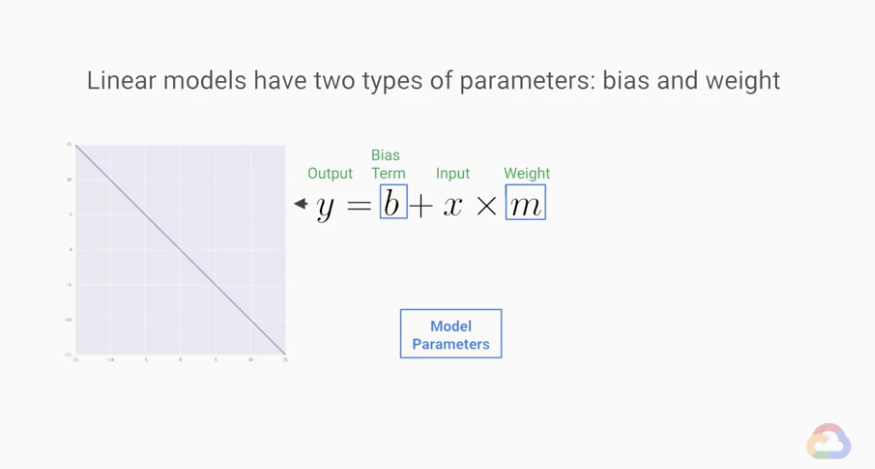
### 迴歸
> 盡量畫出一條可以通過所有資料點的線
在迴歸問題裡,就是要去畫出一條能夠預測y值的線(或是超平面)
假設今天你經營一家公司,迴歸能夠處理的問題如:銷售量的預測、原物料價格變化對消費的影響...等等
只要你輸入features,就可以預測出相對應的值
常用到的演算法有:線性迴歸、多項式迴歸
### 分類
> 把資料分到我指定的幾個類別中
在分類問題裡,y值則為某個類別的機率,藉由這個值去判定資料屬於哪一個類別。
假設你經營某個社群網站,分類處理的問題像是:藉由會員性別年齡、好友數、使用頻率等變數,預測用戶是否會流失,每筆訓練資料標記了「已流失與否」,模型則可能產出每筆資料「流失的機率」,假設這個機率值大於 50% 我們就視為「會流失」,藉此處理分類的問題。
常用到的演算法有:決策樹、邏輯迴歸、SVM、KNN
經過今天的介紹,應該會對於什麼是迴歸什麼是分類更有了解一點
之前的文章是針對分類方法做演算法的介紹跟實作,後面的文章則是會針對迴歸分析做相關演算法的介紹跟實作
---
以上是今天的筆記
### Reference
[監督式學習:「分類」和「迴歸」的介紹與比較 – 機器學習兩大學習方法 (一)](https://blog.gcp.expert/supervised-learning-classification-regression/)
[【Day 18】 Google ML - Lesson 4 - 什麼是ML模型?訓練的目標? 回歸模型(Regression model), 分類模型(Classification model)的運算](https://ithelp.ithome.com.tw/articles/10217431)
## 機器學習Day22(Simple Linear Regression介紹)
今天我們要來介紹迴歸分析中最常用到的演算法Linear Regression(線性迴歸)
線性迴歸如果只有一個自變數和一個依變數的情形稱為**簡單線性回歸**;反之若有多個自變數則稱作為**多元線性回歸**
跟分類演算法不同,線性回歸不是在分類物件是0或1,所以在圖上不一定會以直線方式呈現,也有可能以曲線呈現。
### 簡單線性回歸(Simple Linear Regression)
舉個例子,假設年齡與得到癌症的機率可以用直線的關係來描述,這裡的年齡是自變數x,得癌症機率是依變數y
簡單線性回歸: y=β0+β1x
β0:截距(Intercept),β1:斜率(Slope)為 x變動一個單位y變動的量,如下圖:

> **回歸分析就只是在找β0和β1**
但是要怎麼找?
首先先收集一組資料(xi, yi), i=1, …,n,將每個點都帶到回歸公式內:
ŷi =β0+β1xi,i=1, …,n
ŷi :為預估出來的得病機率,和真實資料還是會有誤差(error)或稱為殘差(Residual):
εi = yi — ŷi

所以回歸分析的損失函數(loss function)就是希望找到的模型最終的殘差能夠越小越好
統計上會用**最小平方法(Least Square)**來找參數(β0和β1)。
為什麼叫最小平方法,就是希望誤差的平方越小越好,為什麼是平方,因為誤差值有正有負,取平方後皆為正值,所以我們會很希望所有訓練樣本的誤差平方和(Sum Square error, SSE)接近0。
今天我們只介紹簡單線性回歸,明天要來實作
---
以上是今天的筆記
### Reference
[線性回歸(Linear Regression)](https://chih-sheng-huang821.medium.com/線性回歸-linear-regression-3a271a7453e)
[machine learning 下的 Linear Regression 實作(使用python)](https://medium.com/jackys-blog/machine-learning-下的-linear-regression-實作-使用python-7e1dd03a4d46)
## 機器學習Day23(Simple Linear Regression實作)
今天要進入Linear Regression 的實作部分啦
一樣我們會用Scikit-Learn作為我們今天實作的套件
在進入演算法之前,我們先將資料做好
首先我們先將會用到的套件載入
```python
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
import numpy as np
```
我們舉簡單線性回歸來說,y=ax+b,a為斜率、b為截距
考慮到使用的數據,下面舉斜率為3、截距為-5
```python
rng = np.random.RandomState(1)
x = 10 * rng.rand(50)
y = 3 * x - 5 + rng.randn(50)
plt.scatter(x, y);
```
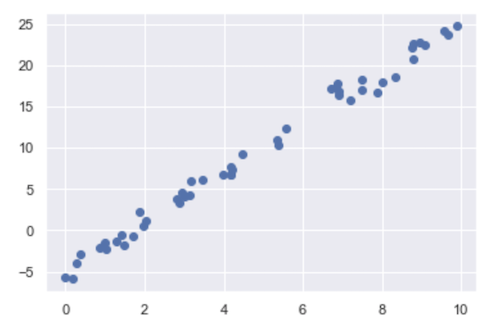
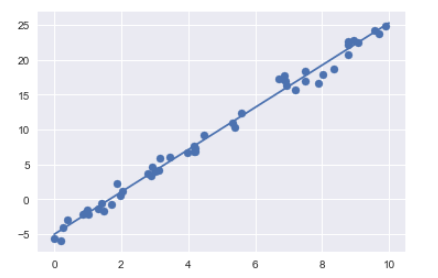
接著使用Scikit-Learn的Linear Regression來擬合數據,並利用plt.plot()建構出圖表
```python
from sklearn.linear_model import LinearRegression
model = LinearRegression(fit_intercept=True)
model.fit(x[:, np.newaxis], y)
xfit = np.linspace(0, 10, 1000)
yfit = model.predict(xfit[:, np.newaxis])
plt.scatter(x, y)
plt.plot(xfit, yfit);
```
模型的斜率及截距,分別儲存在model.coef_[0] 和 model.intercept_中。
```python
print("Model slope: ", model.coef_[0])
print("Model intercept:", model.intercept_)
```
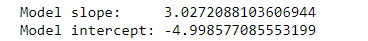
這樣就找出來啦~
今天是做簡單線性回歸的實作,明天我們來探討多元線性回歸
---
以上是今天的筆記
### Reference
[Day13-Scikit-learn介紹(5)_ Linear-Regression](https://ithelp.ithome.com.tw/articles/10206114)
## 機器學習Day24(Multiple Linear Regression介紹)
繼昨天跟前天講的Simple Linear Regression,今天我們要講多元線性回歸(Multiple Linear Regression)
上次有提過簡單線性回歸跟多元線性回歸的差別點就在於自變數的數量,簡單線性回歸的字變數只有一個,多元線性回歸的自變數可以有好幾個。
那麼廢話不多說,就直接進入主題吧
### Multiple Linear Regression
這邊我們假設有一組n個資料,d個自變數和一個依變數
這邊有點特殊,X的向量會多一個純量(1)在向量的最前面,這個部分就是在算前面的截距(Intercept)用的。

此時的回歸公式為


Loss Function 被定義為

和簡單線性回歸一樣,為了推估β,對Loss(β)做β偏微分等於0

所以多元回歸線的係數跟簡單線性回歸一樣可以求得close form。
但因為這種算法程式計算複雜度很大(算反矩陣),因此可以用隨機梯度下降(Stochastic gradient descent,SGD)來找答案,大家一定很好奇為什麼吧。
我們將一個樣本的多元回歸公式寫出來:


這樣的結構不就等於只有一個只有輸入和輸出層的神經網路,所以可以用SGD去找β的最佳解
---
以上是今天的筆記
### Reference
[線性回歸(Linear Regression)](https://chih-sheng-huang821.medium.com/線性回歸-linear-regression-3a271a7453e)
## 機器學習Day25(Multiple Linear Regression實作)
今天我們要來用Multiple Linear Regression的實作啦
跟Simple Linear Regression一樣,我們先來處理Data
先將會用到的套件載入
```python
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
import numpy as np
```
多維回歸的線性模型,,可以在y上建立多維的陣列。
```python
rng = np.random.RandomState(1)
X = 10 * rng.rand(100, 3)
y = 0.5 + np.dot(X, [1.5, -1., 2.])
plt.scatter(x, y);
```
一樣載入Sklean的Linear Regression套件
```python
from sklearn.linear_model import LinearRegression
model = LinearRegression(fit_intercept=True)
model.fit(X, y)
print(model.intercept_)
print(model.coef_)
```
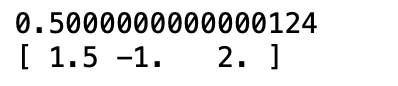
這樣一來截距跟係數就找出來了
### Polynomial basis functions
利用SKlearn中匯入 PolynomialFeatures,來做多項式函數處理。
```python
from sklearn.preprocessing import PolynomialFeatures
x = np.array([2, 3, 4])
poly = PolynomialFeatures(3, include_bias=False)
poly.fit_transform(x[:, None])
```
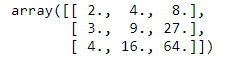
並且利用make_pipeline,一維陣列轉換為三維陣列,加入線性回歸中。
```python
from sklearn.pipeline import make_pipeline
poly_model = make_pipeline(PolynomialFeatures(7), LinearRegression())
```
轉換完成後,可以看到(x,y)的關係為正弦sin圖形
```python
rng = np.random.RandomState(1)
x = 10 * rng.rand(50)
y = np.sin(x) + 0.1 * rng.randn(50)
poly_model.fit(x[:, np.newaxis], y)
yfit = poly_model.predict(xfit[:, np.newaxis])
plt.scatter(x, y)
plt.plot(xfit, yfit);
```
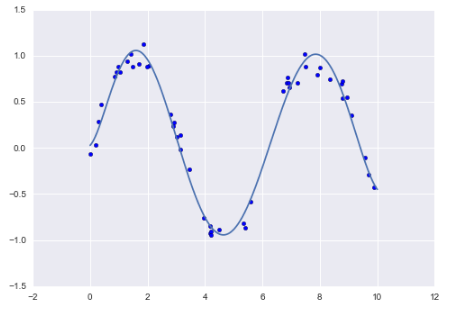
---
以上是今天的筆記
### Reference
[Day13-Scikit-learn介紹(5)_ Linear-Regression](https://ithelp.ithome.com.tw/articles/10206114)
## 機器學習Day26(K-means演算法介紹)前幾天都是在用監督式學習,今天我們要來嘗試看看非監督式學習的演算法K-means
K-means跟Knn都一樣有個k,那麼他們應該道理很像吧?
我們先來介紹什麼是K-means這樣大家就比較能夠作比較了
### K-means概念
其實K-means的全名是K-means clustering,從字面意思看就能知道,他是集群演算法(Clustering)
K-means的概念舉個例子就好比,大家到新學校上學的時候,第一天大家基本上都不熟,都是有一兩個人聚一群,然後慢慢的會有越多人聚在一起,沒幾天就會分成兩三群,過了幾個月,班上的小群體大部分都分好了。
每個團體裡都有一個Key-man,基本上大家會聚在一起都是因為有這個Key-man,我們可以把Key-man當作是群心。
這個Key-man從開學到分好之前,基本上有可能會一直換來換去的,甚至多出一個key-man或是少一個key-man(演算法:ISODATA),或是這個團體的key-man會因為別人的強勢而換掉,這就是**會動=換掉**的群心。
### K-means 運作步驟
1. 首先我們先設定好要分成多少群
2. 然後在feature space(x軸身高和y軸體重組出來的2維空間,假設資料是d維,則會組出d維空間)隨機給k個群心
3. 每個資料都會所有k個群心算歐式距離
4. 將每筆資料分類判給距離最近的那個群心
5. 每個群心內都會有被分類過來的資料,用這些資料更新一次新的群心。
6. 一直重複3–5,直到所有群心不在有太大的變動(收斂),結束。
### 概念圖解
繼續剛剛的例子,將身高和體重分成兩類,兩類也比較好圖解

基本上就是先做initial群心(圖2),然後一直重複做圖3–5,直到群心不太變動(收斂)。
---
以上是今天的筆記
### Reference
[機器學習: 集群分析 K-means Clustering](https://chih-sheng-huang821.medium.com/機器學習-集群分析-k-means-clustering-e608a7fe1b43)
## 機器學習Day27(K-means演算法實作)
今天我們要來實作K-means
同樣的,我們要用scikit-learn的cluster套件裡頭的kmeans方法,然後我今天一樣拿鳶尾花當作訓練資料
首先載入套件
```python
from sklearn import cluster
from sklearn.datasets import load_iris
```
接著將資料載入,套用kmeans演算法
```python
df = load_iris()
iris_X = df.data
# Kmeans演算法, 分三群
clf = cluster.KMeans(n_clusters = 3).fit(iris_X)
# 印出分群結果
cluster_labels = clf.labels_
print("分群結果:")
print(cluster_labels)
print("---")
# 印出品種看看
iris_y = iris.target
print("真實品種:")
print(iris_y)
```

看起來 setosa 這個品種跟另外兩個品種在花瓣(Petal)的長和寬跟花萼(Sepal)的長和寬有比較大的差異。
接著我們可以來看一下績效的衡量,分群演算法的績效可以使用 Silhouette 係數或 WSS
這次我們使用 sklearn.metrics 的 silhouette_score() 方法,這個數值愈接近 1 表示績效愈好,反之愈接近 -1 表示績效愈差。
```python
from sklearn import cluster, datasets, metrics
# 讀入鳶尾花資料
iris = datasets.load_iris()
iris_X = iris.data
# KMeans 演算法
kmeans_fit = cluster.KMeans(n_clusters = 3).fit(iris_X)
cluster_labels = kmeans_fit.labels_
# 印出績效
silhouette_avg = metrics.silhouette_score(iris_X, cluster_labels)
print(silhouette_avg)
```
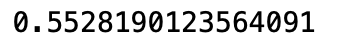
看起來績效還算ok
---
以上是今天的筆記
### Reference
[[第 24 天] 機器學習(4)分群演算法](https://ithelp.ithome.com.tw/articles/10187314)
## 機器學習Day28(介紹類神經網路)
類神經網路是以電腦(軟體或硬體)來模擬大腦神經的人工智慧系統,並將此應用於辨識、決策、控制、預測等工作。在神經網路的階層上,一般包括輸入層、隱藏層與輸出層,而中間的隱藏層可以有一層以上。其中,兩層以上隱藏層的神經網路,通常會被泛稱為深度神經網路

如果要談類神經網路的細部原理,類神經網路所模擬人類神經元中,常會設定一個個的激發函數(activation function),也就是上圖中的各個隱藏層裡面的節點,轉換成數學式,就是我們時常看到的迴歸模型

當我們對神經元進行輸入(Xi)後,經過激發函數與內部迴歸模型對輸入的權重(Wi)加乘,再加入偏誤(b)後,便完成了該節點的輸出。該輸出會再傳給下一個神經元,作為該神經元的輸入值,如此一層層傳遞下去,直到最後一層的輸出層,產生預測結果。在學術上,這就是著名的**前向傳播法**
此外,類神經網路會由預測結果和真實結果之間的差距,對整個神經網路進行更新。由於這是一種由後面神經元至前層神經元的更新,學術上又稱為**反向傳播法**
透過訓練類神經網路的這幾個基本步驟,達到如人類神經元一般的活動進行學習,逐步讓預測結果愈來愈準確。同時,過程中隨著隱藏層的加深,也讓預測能力更好,意味賦予類神經網路更多的神經元進行訓練,這也是類神經網路,為何常被稱為「人工智慧」與「深度學習」的原因。
如今類神經網路對各大產業已經產生了深遠的影響與應用,從瑕疵檢測、醫學影像辨識、信用卡詐欺偵測、精準校務就學穩定率預測、離職預測到精準行銷等,幾乎全都奠基在類神經網路模型的架構與技術上發展。
---
以上是今天的筆記
### Reference
[快速反應機制─類神經網路](https://medium.com/marketingdatascience/快速反應機制-類神經網路-a3bbdee4a6f6)
## 機器學習Day29(介紹好用套件Pycaret)
之前我們都用Scikit-learn來做演算法處理,現在我們要來介紹一個非常好用的套件,這個套件可以從前處理的地方就幫你包好包滿,讓你可以簡單透過套件的方法去完成,並且可以自己選擇要用到的演算法。
PyCaret說白了,有點像一個機器學習庫的煉丹爐。
以下是它「熔」進來的部分庫:數據處理—pandas、numpy、數據可視化—matplotlib、seaborn、各種模型—sklearn、xgboost、catboost、lightgbm。
然後,PyCaret 這個煉丹爐,自帶功能「按鍵」(定義了一些函數),包括數據預處理、模型訓練、模型集成、模型分析、模型測試等。只需要寫上幾行 Python 程式碼,這些功能「按鍵」就會被按下,PyCaret 自動幫你實現。
那麼說了那麼多,我們先做一些示範
### 下載pycaret
在使用前,我們要先下載這個套件,他可以透過PiP 下載,只要在terminal打上
```bash
pip install pycaret[full]
```
就會自動幫你安裝這個套件
### Pycaret分析流程
載完套件後,可以開始資料分析
首先先一樣引入data
然後我們可以將5%的資料屏蔽,當作最後測試的資料

接著可以準備建立前處理的參數
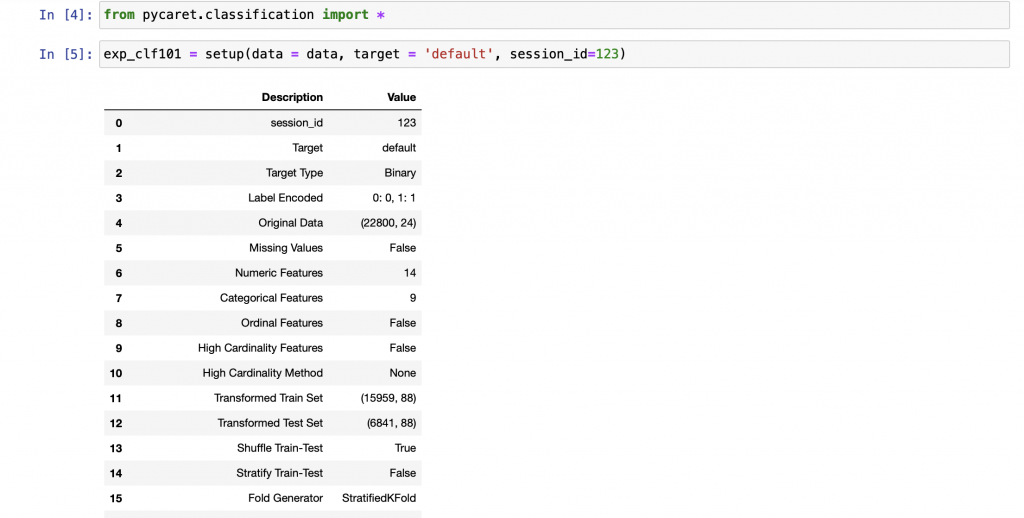
確認完資料無誤以後,選擇要建立的演算法
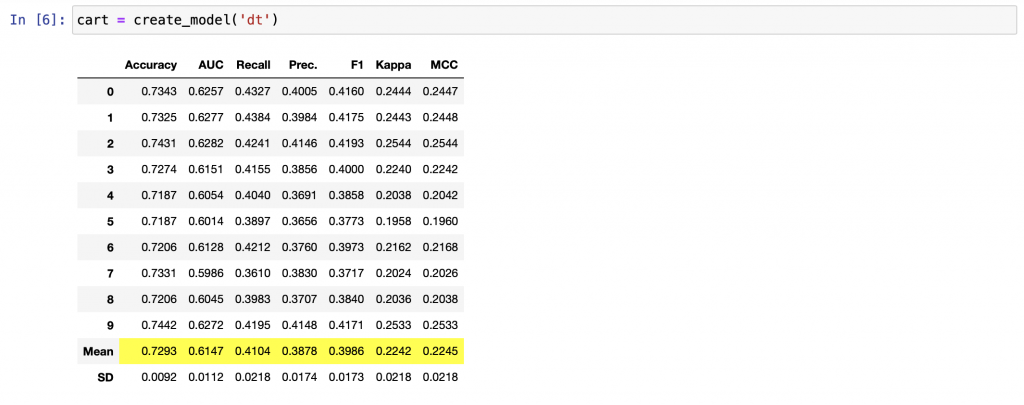
可以印出來看一下模型的超參數

也可以直接透過一行程式碼,自動修正模型,pycaret將會用設定的超參數值去做貪婪搜尋法找到最好的結果
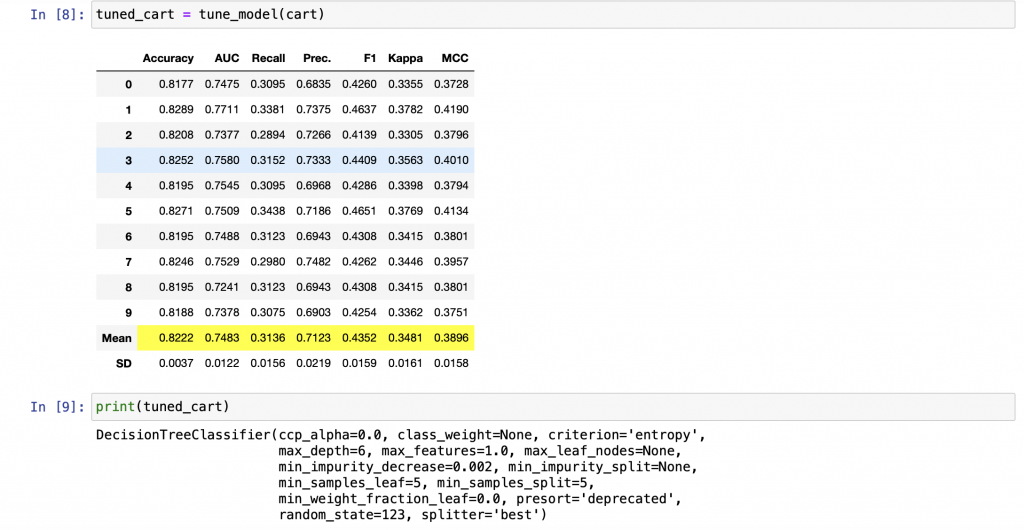
最後我們可以直接預測資料,pycaret在前處理時會自動將資料分成70%訓練資料跟30%測試資料
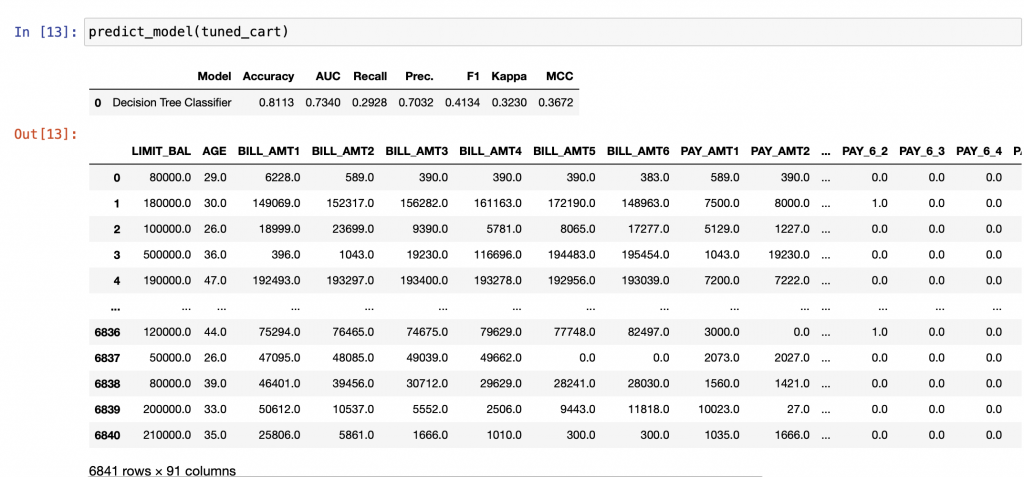
然後對模型的預測做績效的評估

---
以上是今天的筆記
## 機器學習Day30(PyCaret在Mac的IO錯誤)
如題這次會針對Pycaret會在Mac上發生的IO錯誤做處理
在我安裝pycaret以後,跑引進分類器時會遇到IO error
而我去stack overflow上查了下資料發現
問題出在lightbgm的安裝路徑問題
之後看了些資料,解決方法如下
### 安裝HomeBrew
HomeBrew 是一個安裝輔助軟體,可以幫你單獨下載缺少的套件
透過在terminal打上下面的程式碼
```bash
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
```
就可以安裝HomeBrew了
### 透過HomeBrew安裝libomp
在terminal上打上下面的程式碼
```bash
brew install libomp
```
安裝完後基本上就可以跑了
### 結語
這次的30天學習讓我從一開始對於機器學習一竅不通,到最後可以運用套件去分析資料
非常感謝有這一堂課可以讓我30天督促自己學習,讓自己成長
希望之後可以繼續對這塊領域做更多的學習,這次比較多時間花在琢磨機器學習演算法,之後可以考慮學習深度學習的實作跟演算法
###### tags: `鐵人賽`