---
tags: Specializace
---
# ML 3. Zpracování přirozeného jazyka
Zpracování přirozeného jazyka: Automatická morfologická analýza. Rozpoznávání a generování větné struktury, gramatiky, základní typy syntaktické analýzy. Sémantická analýza věty, logická analýza přirozeného jazyka. Pragmatická rovina, komunikační situace. Zpracování řeči, dialogové systémy. Korpusy, statistické a pravidlové značkování. (PA153, IA161, PA156, PA154, IV029, PA164)
# 90% hotovo
zdroje:
- https://drive.google.com/file/d/1MCmc4wQ0jqZvxZ_tet85L0NY1I0Nk2eJ/view?usp=sharing
- slajdy
- https://drive.google.com/drive/folders/1TxF1pfvjAhw4hc5BsA0CJyJ9bAMvXmf3?usp=sharing
- https://hackmd.io/@ovn3qcMfQGCB9SyG0QWrTg/ByZGV81kd/edit
## Obecně
- NLP použití
- strojový překlad (google translate)
- oprava překlepů (grammarly)
- analyzátory (sentiment analysis)
- strojově čitelné slovníky
- Roviny jazyka
- Fonetická (vztahy mezi zvuky v jazyku)
- Morfologická (skládání slov z menších jednotek)
- Syntaktická (gramaticky správná věta)
- Sémantická (význam věty)
- Pragmatická (vztahy mezi výrazem a kontextem)
## Automatická morfologická analýza
Jedním z prvních kroků v automatickém zpracování textu je morfologická analýza a lemmatizace.
### Morfologická analýza
https://is.muni.cz/auth/el/fi/podzim2020/PA153/index.qwarp?prejit=5714569
https://nlp.fi.muni.cz/poc_lingv/slajdy-2019/pl04-2.pdf
Pro každý slovní tvar vrací:
- základní slovní tvar (lemma - položka slovníku)
- možné gramatické významy (značky)
- kombinace hodnot relevantních gramatických kategorií jako např. slovní druh (sloveso, zájmeno..), pád, číslo, osoba, jmenný rod (mužský životný, mužský neživotný, ženský...), atd.
- příkladem užití jsou morfologický analyzátory Ajka a Majka.
Příklad:
- Morfologická analýza věty 'Sním je místo něho'
- sloupce: analyzovaný tvar:lemma:značky kategorií (V-verb,S-singular...)

- Problém:
- Jakou informaci chceme / potřebujeme zachytit a popsat?
- Jak si tuto informaci / tato data budeme organizovat?
- Jak implementovat analýzu či syntézu nad těmito daty?
### Značky
Gramatické informace reprezentujeme jako řetězec znaků, existuje na to více systémů:
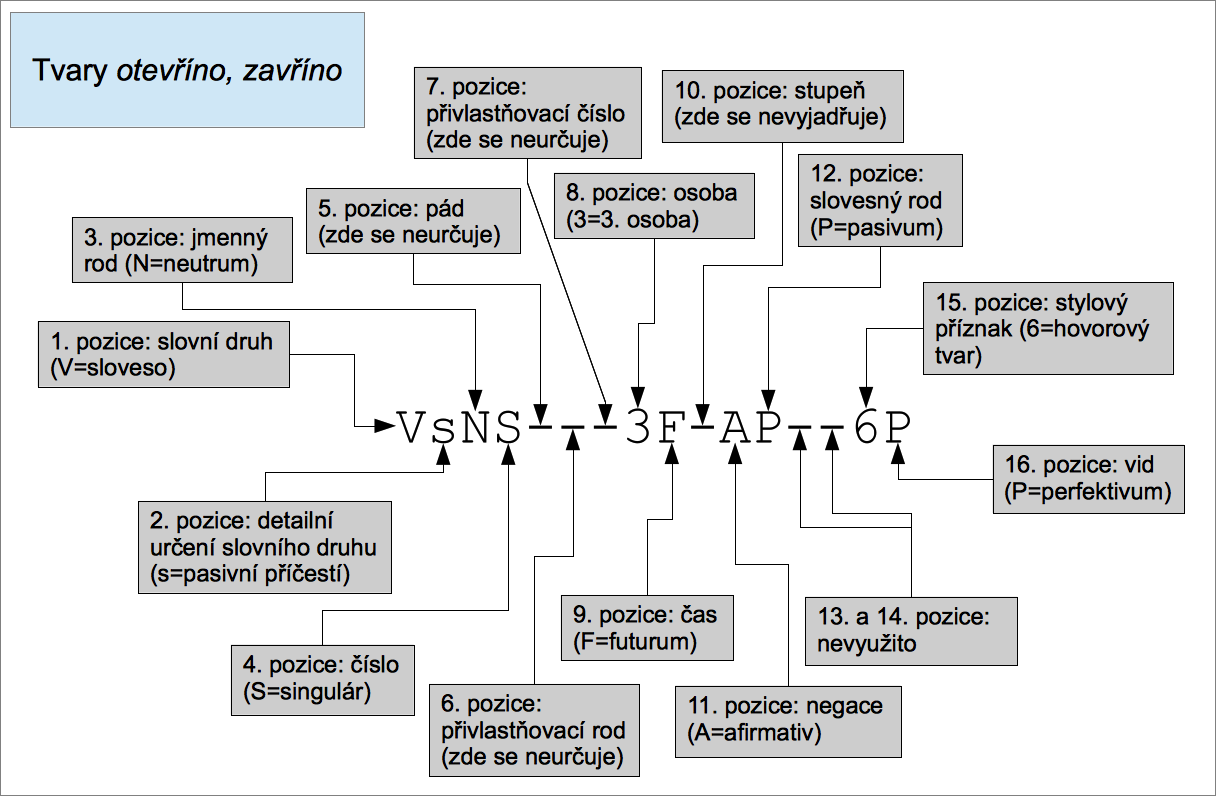
- Poziční systém (z Prahy):
- kategorie je určena pozicí ve značce (15 pozicí)
- 
- Atributový systém (z Brna, **takže lepší**):
- dvojice atribut-hodnota
- nezáleží na pořadí
- přehlednější, lehce rozšiřitelný, úspornější?why, čitelný regulárními výrazy
https://nlp.fi.muni.cz/projekty/ajka/tags.pdf
- *k1gInSc4*
- k1 - substantivum
- gI - mužský neživotný rod
- nS - singulár
- c4 - akuzativ
- nezachycuje specifikaci a afirmaci ??
- Heterogenní systém (Bratislava...):
- jako poziční, ale prázdné pozice jsou vynechané
- BNC tagset (english):
- pevná množina značek (AJO, AJC, AJS)
- problém: které všechny gramatické kategorie popisovat?
- které slovní druhy: zkratky, interpunkce, čísla, speciality
- které gramatické kategorie: *druhy zájmen*, *číslovek*, *příslovcí*, ...
- duál
### Různé míry lemmatizace
- problém do jaké míry zohlednit slovotvorbu/flexi při určení základního tvaru
- jaký je správný základní tvar?
- nebral => brát/nebrát
- učený => učený/učit
- nejstaršího => starý/nejstarší
- dublety (oba tvary jsou spisovné)
- kapitaliSmus/kapitaliZmus
- myslet/myslit
- negace
- nebral => nebrát/brát
- diachronie (změna/vývojové tendence určitého slova v dějinách/čase)
- všechen/všecken
### Morfologický analyzátor
#### Ajka
- shrnuje více možných lemmat pod jeden záznam??
- slovní tvary lemmatu se rozdělí na společný základ + intersegment (kmenotvorná přípona) + množina koncovek
- 
- https://kb.upol.cz/fileadmin/userdata/FF/katedry/kbh/studium/materialy/e-knihovna/Bednarikova_cvicebnice_z_morfologie.pdf
- lemmata mající shodné množiny koncovek patří k témuž vzoru (tyto vzory nutně neodpovídají klasickým vzorům jako pán, muž, hrad, stroj..)
- 
#### Jak vypadá slovník
- formát
- $<lemma>: <vzor><! - lze\,\, negovat><\% - reflexivita\,\, tantum??><poznamky>$
- hanbit: barvit!%|793.1, 167.1
- zelený: nový!|148.1
- $<vzor>$ je definován takto
- lemma vzoru + $<intersegmenty>$ + seznam koncovkových množin
- $*$ +barvit
- $<i>$ NEWES717, NEWES744
- $<en>$ NEWES710
- tyto koncovkové množiny jsou definovány takto
- NEWES717 = {t, k5aImF}
- NEWES705 = {y, k5aImAgFnP},{i,k5aImAgMnP},...
### Postup analýzy
Analyzované slovo - $w_{1}w_{2}..w_{k} = Z+I+K$
$Z$ - základ, $I$ - intersegment, $K$ - koncovka (mohou byt nulové, $\epsilon$)
- pre každý základ $Z=w_{1} \ldots w_{n}$ nájdený v zozname základov sa v jeho vzore skúsia dohladat kandidáti na $w_{n+1} \ldots w_{i}=I+K$
1. Z lemmy odtrhneme první intersegment a koncovku vzoru -> vznikne slovní základ -> připojím k němu intersegment a koncovky (z existujících záznamů??)
Hanbit -> hanb + -i + -t
2. hanb-i-t k5aImF, hanb-il-i k5aInAgMnP
3. pro každý základ (Z) se zkusí podle jeho vzoru dohledat kandidáti na I+K
4. Výstup: značky příslušné trojicím $Z+I+K$
- Nevýhody formátu
- stav:
- slovník základů + soubor vzorů a množin koncovek se značkami
- pro každý základ jsou specifikovány vzory, připojením jejich koncovek se získají tvary se značkami
- základy i koncovky jsou řetězce, které se jen skládají k sobě
- ze stavu plyne zásadní nevýhoda: redundance popisu/zápisu
- Luděk/Luďka, Staněk/Staňka, vrah/vraha, medvídek/medvídka atp. se skloňují stejně či podobně, ale kvůli drobným odlišnostem vyžadují vlastní řešení
- redundance vede k nekonzistenci při doplňování či opravách
> doplnění hovorového 2. pádu j.č. $-e \rightarrow -a: muža$
> •217 vzorů, tedy nutno automaticky -e→-a
> •ovšem u cca 10 vzorů je -ě místo -e
- řešení příliš drahé
- Nový formát
- slovník základů + soubor vzorů (a v něm i koncovky)
- 
- výhody
- redukce redundance
- možnost zachytit hláskové změny
- rozlišení pravidelných od okrajových případů
<!--  -->
#### Majka
- využívá minimializovaný acyklický konečně statový automat
- 
## Rozpoznávání a generování větné struktury, gramatiky, základní typy syntaktické analýzy
Syntaktická analýza
- odhalení povrchové struktury dat (věty)
- základ pro analýzu jazyka na vyšších úrovních
- vztahy mezi slovy, identifikace frází...
- https://nlp.fi.muni.cz/trac/research/raw-attachment/wiki/en/AdvancedNlpCourse/anlp-03-ParsingCzech.pdf
Nějaké pojmy:
- syntax : uspořádání slov (vztahy mezi slovy) a frází za účelem vytvoření dobře vytvořených vět v jazyce
- syntaktická jednotka : nositel významu, individuální slova někdy nestačí (in, the VS in the city (where)) - aplikace pro extrahovaní faktů, question answering, logická analýza, kontrola gramatiky atd...
Formalizmy (notace syntaxe) TODO příklady stromu??
- závislostní strom
- strukturní vztahy kódovány závislostmi mezi slovy na vstupu
- Grafické znázornění syntaktické (příp. sémantické) závislostní struktury věty.
- pražský korpus závislostních stromů PDT
- Závislostní přístup studuje syntax věty jako systém vztahů mezi dvojicemi slov, přičemž tyto vztahy jsou asymetrické – jsou‑li dvě slova v syntaktickém vztahu, je jedno z nich považováno za slovo řídící(/rozvíjené/dominující) a druhé za slovo podřízené(/rozvíjející/dominované).
- Ve stromu: vztah uzlů rodič-syn odpovídá vztahu slov řídící-podřízené.
- 
- Tabulka pro ilustraci
- 
- https://www.czechency.org/slovnik/Z%C3%81VISLOSTN%C3%8D%20STROM
- složkový (frázový) strom
- strukturní vztahy kódovány stromem odvození z gramatiky
- např. syntakticky anotovaný korpus současné češtiny SYNT
- [TODO je to správný příklad?] 
- parciální syntaktická analýza
- nezajímá nás kompletní strom, jen nějaké vztahy
- např. "word sketch"
Automatická syntaktická analýza
- detekce slovních druhů (podst. jméno, sloveso...), frází, vět (klauzule) + hledá vztahy mezi těmito jednotkami
- potřebujeme morfologickou analýzu (slovní druh, rod, číslo), rozpoznávání jmenných entit, lexikální sémantické informace (např. "těhotná" může být jen žena)
- Metody parsování
- Statistické metody
- vyžaduje označkovaný korpus (drahé, časově náročné, většinou malé korpusy)
- jazykový korpus je soubor textů určitého jazyka, který slouží
- pro lingvistický výzkum jazykové praxe
- jako datová základna pro tvorbu slovníků, korektorů, překladačů
- statistické metody se z korpusu naučí pravidla
- metoda se dá do jisté míry aplikovat na různé jazyky
- Pravidlové metody
- expert vytvoří množinu pravidel - gramatiku (těžko udržovatelné)
- metoda není univerzální, záleží od experta
- Hybridní metody
- Syntaktické analyzátory: SYNY, SET, BOTH, WORK SKETCH
Syntaktická analýza
- popis pomocí gramatik
- kategoriální gramatiky
- lexikální kategorie slov tvoří funkce, které určují jak se slova vážou s jinými (princip kompozicionality)
- 
- N - noun, NP - noun phrase (jmenná fráze)
- https://cs.wikipedia.org/wiki/Fr%C3%A1ze_(syntax)
- závislostní gramatiky
- aplikace algoritmu hledání nejmenší kostry na statisticky naučené vazby
- Tree-adjoining grammar (TAG)
- práce se stromy, ne řetězci
- počáteční a pomocné stromy
- operace: substituce a připojení
- Definite clause grammar (DCG)
- prolog
- lexikálně funkční gramatiky (LFG)
- head-driven phase structure grammar
### CZPJ centrum FI ??
#### Synt
- složkový analyzátor
- základ = bezkontextová gramatika + chart parser (tabulkový analyzátor)
- koncept metagramatiky, kontextové akce
#### SET
- hybridní analyzátor
- založen na detekci konečných vzorků v textu
#### Dis/VaDis
- založen na DCG
- použití při morfologiké desambiguaci
#### IOBBER
- statistický rozpoznávač frází (chunker)
## Sémantická analýza věty, logická analýza přirozeného jazyka
### Sémantická analýza
#### Lexikální význam
- izolovaný význam slova
- bez ohledu na význam věty, ve které se slovo nachází
- bez ohledu na kontext
- bez ohledu na gramatické kategorie
#### Lexikální jednotka (lexical unit, LU)
- reprezentována **lexikální formou** (slovo)
- asociována s určitým **lexikálním významem** (myšlenka)
- má určité **gramatické vlastnosti** (např. tranzitivní sloveso)
- může mít určité **pragmatické vlastnosti** (např. *já* je pokaždé někdo jiný)
- LU se stejným významem, ale jinou formou = **synonymie**
- LU se stejnou formou, ale jiným významem = **homonymie**
- druhy:
- autosémantické = plnovýznamové (podst. jména, přídavná jména, slovesa)
- synsémantické = význam jen v kombinaci s plnovýznamovými
#### Slovník
- je soubor lexikálních jednotek (lexikální databáze, lexikon)
- Typy: jednojazyčné výkladové, překladové, současného jazyka (synonyma, zkratky, rýmy), terminologické, historické, etymologické, speciální (frekvenční, valenční), strojově čitatelné
#### Slovníkové heslo
- lexikální forma
- gramatické vlastnosti
- definice
- kolokace (spojení více slov, která spolu souvisí a vytváří lexikální jednotku)
- příklady užití
- odvozené lexikální formy (hnízdování)
*[hnízdování]: V lexikografické praxi sdružování slov do souborné heslové stati s cílem prezentovat jejich vztahy (a zároveň uspořit místo).
#### Sémantická analýza
##### Kolokace jako slovníkové heslo, MWE
- pevné kolokace: zakopaný pes, New York, křížem krážem
- porušují princip kompozicionality (význam složeného výrazu lze složit z významů jeho složek)
- v NLP se používá termín *multiword expression (MWE)*
- důležité MWE identifikovat, např. pro strojový překlad
- zamrzlé MWE: ad hoc
- pevné MWE: zakopaný pes, zakopaného psa
- syntaktické anomálie: cobydup, coby dup, co by dup
- MWE s možnou přetržkou: více méně, více či méně
- MWE jako vzory (patterns): vzít někoho na hůl (někoho ojebat finančně)
##### Nalezení významu v kontextu, WSD
- *lexikální desambiguace* (Word Sense Disambiguation)
- $F: (w, c) \rightarrow s$
- $w \in W$ - množina slov
- $c \in C$ - množina kontextů
- $s \in S$ - množina významů
- Algoritmy: hledáme význam slova použitého v kontextu
- Naivní Leskův algoritmus
- rozloží kontext na lemmy
- definice hledaného slova jsou taktéž množiny lem
- vytvoří průnik, definice, jejíž průnik má největší mohutnost je vybraná
- porovnávají se shody slov z kontextu se slovy ve významu ze slovníku => výstup, kde je největší shoda
- nevýhoda: nutnost slovníkových definicí
- WSD založené na ML
- stanovit význam u pevných kolokací (ručně nebo ze slovníku)
- iterativně zjistit další kolokace
kopie => kopie oddacího listu
- opakovat, dokud desambiguované množiny nepřestanou narůstat
- nevýhoda: Algoritmy závisejí na inventáři a popisu významů
- Kolik významů ma slovo *list*?
- SSJČ: 8
- SSČ: 6
- Word Sense Discrimination / Induction
- nepočítají s pevným inventářem významů, jen s kontextem (clustering?)
#### kontext
- verbální (slova vyskytující se před/za slovem/větou)
- situační (místo, čas, počet a vědomosti komunikačních partnerů)
- sociální (vzdělání publika, sociální status skupiny)
### Komponentová analýza
- popis významů slov pomocí množiny **sémantických rysů (primitiv)**
- přítomný, nepřítomný, irelevantní
> muž = +HUMAN +ADULT +MALE
>
> žena = +HUMAN +ADULT -MALE
- **sémantické třídy** = skupiny slov, která sdílejí určitý sémantický rys
- obratlovec - savec - šelma - psovitá šelma - pes - pudl - trpasličí pudl
- vytváří určitou taxonomii/hiearchii slov
- Sémantické sítě
- např. *WordNet*
- počítačově dobře zpracovatelný zdroj informací
- obsahuje významy slov a vztahy mezi významy
- jednotkou je synonymická řada (synset)
- synsety jsou spojeny relacemi
- hyperonymie/hyponymie: vůz, automobil - dodávka
- holonymie/meronymie (part of, member of): vůz, automobil - tlumič
- near-antonym: den - noc
- odvození: velikost - velký
> - Synset: (n) mind, head, brain, psyche, nous
> - Direct hypernym:
> - Synset: (n) cognition, knowledge, noesis
- ontologie = souhrn pravidel tříd a vztahů mezi synsety (SUMO, MILO, ConceptNet)
- ontologické jazyky - predikátová logika prvního řádu (FOPL), knowledge interchange format (KIF), rodina resource descriptiom framework jazyku (RDF, RDFS, OWL, DAML)
- Sémantické vektory
- vektor popisující kontext (n-gram v okolí slova)
- vektor popisující slovo
- TODO?
### Logická analýza
- převod jazyka (lexikálních jednotek?) do formální logiky
- mezijazyk pro strojový překlad
- přesné vyjádření faktů, odvozování
- Predikátová logika 1. řádu, Modální logika, TIL (Transparentní intenzionální logika)
- Fregeho model sémantiky TODO?
### Predikátová logika
- predikáty => True/False
- ”Those who do not know statistics, will be classified F” →
∀x : ¬knows(x, statistics) ⇒ classif(x, F)
- výhody:
- jednoduchost
- prozkoumaná
- existují inferenční stroje
- nevýhody:
- ne všechno je možné vyjádřit pomocí výroků (dobrý den, děkuji)
- na některé výroky je FOPL nedostatečná (All people have some common features)
- nedostatek kvantifikátorů (somebody, big part of, many people)
- různý význam pravdy (Miloš Zeman je prezident ČR = pravda teď, ale ne za 20 let)
### Transparentní intenzionální logika
- Možný svět
- množina bezesporných výroků o univerzu
- aktuální svět je jeden z možných světů
- aktuální svět + **aktuální čas** = object
- empirická pravda - pravdivost formule závisí od světa, její význam však nezavisí na světu
- intenzionální logika
- intensions (nezávislé na světě)
- extensions (označuje objekt v konkrétním světě)
- báze
- o (True/False)
- ι (množina individuí)
- τ (množina reálných čísel - časových okamžiků)
- ω (množina světů)
- $(((\omicron \iota)\tau)\omega)$ - vlastnost $((\omicron \tau)_{\tau \omega})$
- výhody:
- poskytuje korektní a velmi precizní analýzu
- nevýhody:
- velmi abstraktní a komplexní
- není rozšiřitelná?
- experti se neshodnou na správné analýze
Valence?? TODO
## Pragmatická rovina, komunikační situace
- Pragmatická rovina
- části jazyka, které nesouvisí se strukturou jazyka, ale se situačním kontextem
- Externí pragmatika
- komunikační situace
- hovořící, posluchači, čas, místo, objekty související s konverzací, diektické výrazy (já, ty, tady)
- Interní pragmatika
- Vztahy mezi uživateli jazyka a významem
- deklarativní, interogativní, imperativní, tázací..?
- Implikatury
- závěry, kterých chce hovořící dosáhnout
- Griceho konverzační principy (maxims)
- hovořící jedná podle nějakých pravidel, od posluchačů se očekává že budou jednat podle stejných pravidel
- maxim of quality (říkej pravdu)
- maxim of quantity (říkej jen to, co je podstatné)
- maxim of relevance (mluv k věci)
- maxim of manner (vyhni se nejasnostem, dvousmyslům...)
- speech acts
- jazyk neslouží jen na výměnu informací
- každá věta má informační aspekt (význam) a výkonostní aspekt (mění stav světa)
- locutionary act – význam věty (”Is there some salt?”)
- illocutionary act – pochopený význam (”Bring me some salt.”)
- perlocutionary act – vykonaná akce (Akt podání soli)
## Zpracování řeči, dialogové systémy
- https://nlp.fi.muni.cz/poc_lingv/pl03-print.pdf
- https://is.muni.cz/auth/el/fi/jaro2020/PA156/um/slidy/02-uvod_ds.pdf
## Korpusy, statistické a pravidlové značkování
- Korpus je soubor textů v přirozeném jazyce (knihy, časopisy, noviny, internet, titulky, eseje...)
- synchronní/diachronní
- jednojazyčné/vícejazyčné
- paralelní/paralelní srovnatelné
- plné texty/vzorky
- audio/video (multimodální)
- problémy:
- autorská práva
- vysoké náklady
- nedostatečná velikost
- obtížné získávání dat
- příklady:
- brown corpus
- british national corpus
- corpus of temporary american english
- český narodní korpus
- de-sam
- web jako korpus
- výhody:
- obrovský
- různé druhy dokumentů
- aktuální podoba jazyka
- lehká dostupnost
- nízké náklady
- nevýhody:
- neuspořádaný
- nežádoucí obsah
- duplicity
- chyby
- korpusový manažer
- příprava textu
- převod formátů
- metadata
- tokenizace
- anotace
- konkordance
- výpočet statistik
- uchování korpusu
*[konkordance]: vyhledávání
- anotace
- přidávání lingvistických informací do korpusu
- informace o zpracování dat (tokenizace)
- metadata textu (autor, téma, žánr, datum)
- struktury (dokument, odstavec, věta, hovořící)
- značkování (POS tag)
- typy anotace
- morfologická - slovní druh a gramatické kategorie
- syntaktická - závislostní nebo složkový syntaktický strom
- sémantická - WSD, named entity recognition
- koreference - určení anafory
- pragmatická - označení hovořícího, komunikační situace
- ruční anotace je nákladná a zdlouhavá
- automatická anotace je nedokonalá
---------------------------------------
---------------------------------------
---------------------------------------
# PA153 Počítačové zpracování přirozeného jazyka
## Úvod
...
## Morfologická analýza
- Nejnižší rovina zpracování jazyka v textové podobě
- Morfologická analýza pro každý slovní tvar vrací:
- základní slovní tvar (**lemma**, položka slovníku)
- možné gramatické významy ("značky")
- tj. gramatické kategorie jako např. slovní druh, pád, číslo, osoba atd.
- příklad
> Pro slovní tvar _stroj_
>
> - stroj - podst. jm., mužský neživotný rod, singulár, nominativ/akusativ
> - _strojit_ - sloveso, 2. os. j. č., rozkazovací způsob, nedokonavé
- Problém:
- Jakou informaci chceme / potřebujeme zachytit a popsat
- Jak si tuto informaci / tato data budeme organizovat
- Jak implementovat analýzu či syntézu nad těmito daty
### Značky
- reprezentují gramatické informace
#### Poziční systém
- kategorie jednoznačně určena pozicí ve značče
- **pražský systém**
- 
#### Atributový systém
- dvojice _atribut-hodnota_ bez ohledu na pořadí
- **brněnský systém**
- *k1gInSc4*
- k1 - substantivum
- gI - mužský neživotný rod
- nS - singulár
- c4 - akuzativ
- výhody: přehlednější, úspornější, snadno rozšířitelný, čitelné regularními výrazy
### Co chceme popisovat
- různé možnosti *lemmatizace*
- do jaké míry zohlednit slovotvorbu/flexi při určení základního tvaru
> - otcova => otcův/otec, učený => učený/učit, učení => učení/učit
> - nejstarší => starý/nejstarší
> - nebral => brát/nebrat
- jak naložit s *dubletami*
> - mysli => myslet/myslit
- *diachronie*
> - všechen / všecken
- různé možnosti volby gramatických kategorií a jejich hodnot
- které slovní druhy: zkratky, interpunkce, čísla, speciality
- které gramatické kategorie: *druhy zájmen*, *číslovek*, *příslovcí*, ...
- duál
- stanovení pravidel pro určení slovního varu v konkrétním větném kontextu
### Jak budeme informace organizovat
#### Morfologický analyzátor $ajka$
- předem dané, které slovní druhy patří k sobě
- slovní tvary lemmatu se rozdělí na společný základ a _koncovky_
- lemmata mající shodné množiny koncovek patří k témuž vzoru

##### Slovník
- formát
- `lemma: <vzor>, <! - lze negovat>, <% - reflexiva tantum> + poznámky`
> `hanbit: barvit!%|793.1, 167.1`
>
> `zelený: nový!|148.1`
- příklad definice vzoru
- lemma vzoru + <intersegmenty\> + seznam koncovkových množin

- příklady koncovkových množin
- jména jsou arbitrární, generovaná nějakým programem
- množina dvojic *koncovka* + *jí* odpovídající značka

- interpretace
- z lemmatu odtrhnu první intersegment a koncovku vzoru => slovní základ
- ke slovnímu základu připojuju intersegmenty a koncovky
> `hanbit => hanb + -i-t`
>
> `=> hanb-i-t k5aImF,...,hanb-il-i k5aImAgMnP, ...`
##### Princip analýzy nad uvedenými daty
- analyzované slovo $w_1w_2...w_i = Z + I + K$
- $Z$ - základ, $I$ - intersegment, $K$ - koncovka
- mohou být nulové
> např. `slon-0-0, 0-člověk-0`
- pro každý základ $Z = w_1...w_n$ nalezený v seznamu základů se v jeho vzoru zkusí dohledat kandidáti na $w_{n+1}...w_i = I + K$
- výstupem jsou příslušné k nalezeným trojicím $Z + I + K$
##### Nevýhody formátu
- stav:
- slovník základů + soubor vzorů, množin koncovek se značkami
- pro každý základ jsou specifikovány vzory, připojením jejich koncovek se získají tvary se značkami
- základy i koncovky jsou řetězce, které se jen skládají k sobě
- plyne z toho zásadní nevýhoda: redundance popisu
- Luděk/Luďka, Staněk/Staňka, vrah/vraha, medvídek/medvídka atp. se skloňují stejně či podobně, ale kvůli drobným odlišnostem vyžadují vlastní řešení
- redundance vede k nekonzistenci při doplňování či opravách
> doplnění hovorového 2. pádu j.č. $-e \rightarrow -a: muža$
- řešení příliš drahé
#### Nový formát dat
- zůstává slovník a soubor vzorů
- snaha oddělit pravidelné (vzory, program) a nepravidelné (slovník)
- slovník: specifické pro jednotlivá lemmata, co si musím pamatovat
- vzory: vlastnosti koncovek, program: pravidla pro skládání
- základy `slon: pán` ve slovníku, koncovky uspořádané do vzorů

##### Vlastnosti a přínos nového formátu
- redukce redundance
- vyšší "lingvistická přijatelnost"
- slova lze řadit k tradičním vzorům
- hranice mezi kmenem a koncovkou může odpovídat mluvnicím
- lze zachytit pravidelné hláskové změny (alternace)
- formát umožňuje slovotvorné vztahy a morfematickou analýzu
- umožňuje rozlišit pravidelné, typické jevy od okrajových, u kterých navíc stačí popsat jen odchylku od většinového chování
## Sémantika
### Lexikální význam
- izolovaný význam slova
- bez ohledu na význam věty, ve které se slovo nachází
- bez ohledu na gramatické kategorie
### Lexikální jednotka (lexical unit, LU)
- reprezentována **lexikální formou**
- asociována s určitým **lexikálním významem**
- má určité **gramatické vlastnosti**
- může mít určité **pragmatické vlastnosti** (např. *já* je pokaždé někdo jiný)
- LU se stejným významem, ale jinou formou = **synonymie**
- LU se stejnou formou, ale jiným významem = **homonymie**
### Slovníkové heslo
- lexikální forma
- gramatické vlastnosti
- definice
- kolokace
- příklady užití
- odvozené lexikální formy (hnízdování)
#### Kolokace jako slovníkové heslo
- pevné kolokace: zakopaný pes, New York, křížem krážem
- porušují princip kompozicionality (význam složeného výrazu lze složit z významů jeho složek)
- v NLP se používá termín *multiword expression (MWE)*
- důležité MWE identifikova, např. pro stojový překlad
- zamrzlé MWE: ad hoc
- pevné MWE: zakopaný pes, zakopaného psa
- syntaktické anomálie: cobydup, coby dup, co by dup
- MWE s možnou přetržkou: více méně, více či méně
- MWE jako vzory (patterns): vzít někoho na hůl (někoho ojebat finančně)
### Nalezení významu v kontextu
- *lexikální desambiguace* (Word Sense Disambiguation)
- $F: (w, c) \rightarrow s$
$w \in W$ - množina slov
$c \in C$ - množina kontextů
$s \in S$ - množina významů
#### Naivní Leskův algoritmus
- porovnávají se shody slov z kontextu se slovy ve významu ze slovníku => výstup, kde je největší shoda
#### WSD založené na ML
- stanovit význam u pevných kolokací (ručně nebo ze slovníku)
- iterativně zjistit další kolokace
kopie => kopie oddacího listu
- opakovat, dokud desambiguované množiny nepřestanou narůstat
#### Slabiny WSD
- Algoritmy závisejí na inventáři a popisu významů
- Kolik významů ma slovo *list*?
- SSJČ: 8
- SSČ: 6
#### Word Sense Discrimination / Induction
- nepočítají s pevným inventářem významů, jen s kontextem (clustering?)
### Komponentová analýza
- popis významů slov pomocí množiny **sémantických rysů (primitiv)**
- přítomný, nepřítomný, irelevantní
> muž = +HUMAN +ADULT +MALE
>
> žena = +HUMAN +ADULT -MALE
- **sémantické třídy** = skupiny slov, která sdílejí určitý sémantický rys
obratlovec - savec - šelma - psovitá šelma - pes - pudl - trpasličí pudl
### Sémantické sítě
#### WordNet
- lexikální síť
- zdroj informací o významech slov a vztazích mezi významy (slovník + thesaurus)
- jednotkou je **synset** (synonymická řada)
- synsety jsou spojeny relacemi:
- hyperonymie/hyponimie: vůz, automobil - dodávka
- holonymie/meronymie (part of, member of): vůz, automobil - tlumič
- near-antonym: den - noc
- odvození: velikost - velký
> - Synset: (n) mind, head, brain, psyche, nous
> - Direct hypernym:
> - Synset: (n) cognition, knowledge, noesis
### Sémantické vektory
- vektor popisující kontext (n-gram v okolí slova)
- vektor popisující slovo

- **problém**: příliš mnoho dimenzí a přílis prázdný prostor (řídké matice)
- **řešení:** redukce dimenzí, vnoření slov (word embeddings)
- word2vec - předtrénovaný model, který transformuje slovo na vektor fixní délky
### Kontext
- **verbální kontext** - co bylo řečeno, co bude následovat
- **situační kontext** - místo, čas, počet komunikačních partnerů, jejich vzájemný vztah, presupozice mluvčího
- **sociální kontext** - vzdělání, zkušenost, životní podmínky, status sociální skupiny
#### Verbální kontext
- slovní profily (**word sketches**)

- **word sketch grammar** - gramatika pro dotazy
### Větná sémantika
- význam věty: význam slov + syntaktické vztahy mezi větnými složkami (princip kompozicionality)
### Logická sémantika
- redukuje LU na logický typ (individum, čas, ...)
#### Limity predikátové logika
- ne všechny konstrukce v přirozeném jazyce jsou propozice
- dobrý den, děkuji vám, ...
- ne všechny propozice jsou 1. řádu
- $\exists V \forall x: V(x)$ - Všichni lidé mají společné vlastnosti. (Logika druhého řádu umožňuje kvantifikaci přes relace)
- v přirozeném jazyce je mnohem více kvantifikátorů
- většina, velká část, kdekdo, ...
- implicitní existence
### Valence
- schopnost slova vázat na sebe další větné členy
- nevalenční - Prší.
- jednovalenční - Dítě spí.
- dvouvalenční - Pachatel se bojí trestu.
##### VerbaLex
- valenční rámec

#### Semantic Role Labeling
- vstup **věta** => výstup **predikát(argumenty)**
- Jon told Pat to cut off the tree.
ask(v=ask, arg0=John, arg1=to cut off the tree, arg2=Pat)
### Sémantika diskurzu
- seznam objektů promluvy (promluvový objekt, PO; discourse entity)
- množina prvků znalostní báze, které byly zmíněny a mohou být odkazovány pomocí zájmen
- pokud prvek nebyl zmíněn, a přesto může být odkazován, byl evokován
## Korpusy, nástroje, anotace
### Korpusy
- korpus je soubor dat (textů) v přirozeném jazyce
#### Použití
- obecně - data ke studiu přirozeného jazyka
- lexikografie - slovníky
- lingvistika - jazykové analýzy, změny jazyka
- sociologie - jak a o čem píšeme, která témata jsou aktuální
- marketing - hodnocení značek a výrobků v textech
- statistické nástroje NLP - jazykové modely pro značkovače, analyzátory, překladové systémy, prediktivní psaní, ...
#### Zdroje dat
- tištěná média - knihy, časopisy, noviny, básně
- řeč - přepis záznamů řeči, filmové titulky
- ostatní - osobní korespondence, školní eseje
- internet - články, prezentace, blogy, diskuze, tweety
#### Vlastnosti korpusů
- podle data vzniku obsahu - **synchronní** x **diachronní**
- diachronní - zkoumání trendů v používání slov
- jednojazyčné x vícejazyčné
- paralelní x paralelní srovnatelné
- podle zkrácení dokumentů - plné texty x zkrácené vzorky
#### Tradiční korpusy
- **Český národní korpus SYN**
- Ústav ČNK na FF UK v Praze
- texty od 1990 - vydání SYN2000, SYN2005, SYN2010
- 1,3 mld. slov (2010)
- **Korpus DESAM**
- CZPJ FI MU
- morfologicky označkovaný korpus českých textů
- desamgibuované značkování
- 1 mil. slov
#### Korpusový manažer
- příprava textu - převod z různých formátů
- zahrnutí metadat
- tokenizace
- anotace
- efektivní uchování korpusu
- konkordance
- výpočet statistik
##### Word Sketch Engine
- **Manatee**
- korpusový manažer
- akceptuje XML vertikální formát dat
- podporuje metadata a anotace
- Word Sketches
- **Corpus Query Language (CQL)**
- dotazovací jazyk
- slouží k vyhledání tokenů v korpuse
- využívá regulárních výrazů
- příklad
`[lemma="červený"|lemma="černý"] [tag="k1.*nP.*"]`
- dvě bezprostředně následující slova
- první má základní tvar *červený* nebo *černý*
- druhé je podstatné jméno v množném čísle
- tedy např. *červenými domky* je platný výraz
- **Bonito**
- UI a API nad Manatee
### Anotace
- přidávání informací (o slovech, větách, dokumentech) do textového korpusu
- slouží k označení a následnému zkoumání vlastností slov, vět nebo celých textů
- informace o zpracování dat (např. rozdělení na tokeny)
- metadata textů (zdroj, autor, téma, žánr, datum)
- struktury (dokument, odstavec, věta, zarovnání, mluvčí)
- značkování - přiřazení značky (např slovního druhu) k tokenu
#### Druhy anotace
- morfologická (slovní druh a jiné gramatické kategorie)
- Majka
- syntaktická (parsing - závislostní nebo složkové stromy, chunking - rozdělení na fráze jmennou /NP/, slovesnou /VP/, předložkovou /PP/)
- Synt, DIS/VADIS
- sémantická (word sense tagging/desambiguation, rozlišení významu slova, named entitity recognition)
- DESAMB, WordNet
- koreference (určení anafory)
- SARA
- pragmatická (označení mluvčího, komunikační situace)
#### Prague Dependency Treebank
- anotace v morfologické, syntaktické, tektogramatické
*[tektogramatické]: Tektogramatické reprezentace (dále TR) vět jsou explicitně, formálně zachycené zápisy jazykového významu, jsou to zápisy vět na rovině (podkladové) syntaktické stavby. TR je disambiguovaným (zjednoznačněným) zápisem významu věty. Synonymní věty sdílejí jednu TR; věty víceznačné mají více TR.
## Lexikografie
- tvoření a úprava slovníků
### XML
- **DTD** - Document Type Definition
- **XML Schema** - description of XML document structure and content
- **XSLT** - eXtensible Stylesheet Language; for transformations, converting XML to another format
- XML documents are stored into XML database
- **XPath, XQuery** - for searching
### Text Encoding Initiative (TEI)
- guidelines for semantic description of documents
### Lexical Markup Framework (LMF)
- common model for lexical resources
### Dictionary Writing Systems
- software application for dictionary creation
- connected to other resources
- **DEB** (Dictionary Editor and Browser)
### Lexical database
- detailed structured database of language
- usage examples from corpus
- grammar
- valences, patterns
- language style, usage, region
- word relations
## Syntaktická analýza přirozeného jazyka
- odhalení povrchové struktury věty
- základy pro analýzu jazyka na vyšších úrovních
- proč?
- pokročilejší zpracování jazyka
- např. vztahy mezi slovy => logické konstrukce
- identifikace frází v textu
### Notace syntaxe
- **závislostní formalismus**
- strukturní vztahy kódovány závislostmi mezi slovy na vstupu
- pražský korpus závislostních stromů PDT
- **složkový formalismus**
- strukturní vztahy kódovány stromem odvození z gramatiky
- brněnský analyzátor *synt*
- **parciální syntaktická analýza**
- nezajímá nás kompletní strom, jen některé vztahy
- VaDis, Word Sketches
### Jak analyzovat
- manuálně vytvořené gramatiky (bezkontextové, závislostní)
- statisticky naučené gramatiky
- statistické odhadování podoby stromu
### Gramatické formalismy
- **Bezkontextová gramatika**
- CKY, chart parser (tabulkový analyzátor) - vhodný pro analýzu nejednoznačných gramatik
- **Závislostní snytax**
- aplikace algoritmu hledání nejmenší kostry na statisticky naučené vazby
- Definite clause grammar (Prolog)
- Head-driven phrase structure grammar
- Combinatory categorical grammar
- Tree adjoining grammar
### CZPJ centrum FI
#### Synt
- složkový analyzátor
- základ = bezkontextová gramatika + chart parser
- koncept metagramatiky, kontextové akce
#### SET
- hybridní analyzátor
- založen na detekci konečných vzorků v textu
#### Dis/VaDis
- založen na DCG
- použití při morfologiké desambiguaci
#### IOBBER
- statistický rozpoznávač frází (chunker)
## Logická analýza přirozeného jazyka
- převod jazyka do formální logiky
- formální odvozování
- interlingua pro strojový překlad
- přesné vyjádření faktů
- jaký formalismus?
- predikátová logika
- modální logiky
- transparentní intenzionální logika
### Význam výrazu

### Koncepce možných světů
#### Možný svět
- množina bezesporných výroků o univerzu
- aktuální svět je jeden z možných světů
#### Empirická pravdivost
- pravdivost výpovědi závisí na světě
- význam je na světě nezávislý
#### Intenzionální logiky
- intenze (nezávisí na světě)
- extenze (denotáty v nějakém světě)
### Transparentní intenzionální logika
- **procedurální logika**
- zavádí kromě aktuálního světa ještě aktuální čas
- význam je **konstrukce** tj. abstraktní procedura (algoritmus), který dosadí aktuální svět a čas, a tím vytvoří objekt (extenzi)
- notace jako lambda funkce
- **typovaná logika**
- $\omicron$ - pravda, nepravda
- $\iota$ - množina individuí
- $\tau$ - množina reálných čísel (časových okamžiků)
- $\omega$ - množina možných světů
- $((\omicron \tau)\omega)$ - propozice
- $(((\omicron \iota)\tau)\omega)$ - vlastnost $((\omicron \tau)_{\tau \omega})$
- **pro**
- korektní a velmi jemná analýza jazyka
- umožnuje korektní obecné vyvozování
- **proti**
- vysoký stupeň složitosti
- málo rozšířená
- často není shoda expertů na tom, co je správně
## Pragmatika
- principy jazyka, které nesouvisí s jazykovou strukturou
- situační a obecný kontext
- interakce jazykové struktury s kontextem
- **externí pragmatika - komunikační situace**
- $\{\{o_1, ..., o_n\}, m, p, t, l \}$
- promluvové objekty, mluvčí, posluchač, čas, místo
- deiktické výrazy - proměnné, které nabývají hodnot až v určité komunikační situaci
- **interní pragmatika**
- vztah mezi uživateli jazyka a obsahem výpovědi
- oznamovací, tázací, rozkazovací, přací
- **implikatury**
- inference zamýšlené mluvčím
- mluvčí má komunikační záměr
- cílem je přenést záměr na příjemce
### Griceův kooperační princip
- Kooperuj s komunikačními partnery
- mluvčí dodržuje určitá pravidla
- posluchač předpoklád, že je mluvčí dodržuje
- konverzační maximy
- maxim kvality - říkej pravdu
- maxim kvantity - říkej jen to, co je nutné
- maxim relevance - drž se tématu
- maxim způsobu - mluv zřetelně a jednoznačně
- konverzační implikatury
- plynou z dodržení nebo nedodržení principů
## Znalosti, parafráze, odvozování
### Znalosti
- znalosti o jazyce (lexikon, gramatické kategorie, syntax)
- znalosti o světě
- **znalostní báze**
- obsahuje fakta, která jsou premisami v deduktivním odvozování
- lidmi čitelné KB: how-to, FAQ, recepty, návody, diagramy
- strojově čitelné KB: ontologie (SUMO-MILO), sémantické sítě (WordNet), dbPedia
#### Reprezentace znalosti
##### Deklarativní
- znalosti zaznamenané v určitém jazyce
- uložené v určitém zdroji (databáza)
- jednoduché odvozován
- explicitná
- formálně verifikovatelná
- obecně platná
##### Procedurální
- vyjádření pomocí procedury
- hodnota se zjistí provedením procedury
- implicitní
>Příklad (pohyb robota po místnosti)
>
>Deklarativní: pohyb robota + mapa
>
>Procedurální: běž na pozici (X, Y)
##### Rámcové
- kombinace deklarativního a procedurálního přístupu
- rámce samotné jsou deklarativní
- sloty v rámcích jsou procedurální
#### Odvozování
- reprezentace znalostí: znalostní báze + odvozovací pravidla
##### Deduktivní odvozování
- monotonicita
- pokud přidáme další předpoklad, již odvozené závěry stále platí
$\Gamma \vdash C$ $\Gamma, A \vdash C$
- nemonotónní
- např. Default logic
#### Znalosti o světě
- encyklopedické - Jaké je hlavní město ČR?
- common-sense - Jak je vhodné se obléci 5. 12.?
- počítačově zpracovatelné zdroje encyklopedických znalostí:
- encyklopedie
- znalostní hry
- dbPedia - strojově zpracovaná Wikipedie
#### Common sense
- sdílená znalost, ne vždy v souladu s věděckými fakty (V noci nesvítí slunce.)
- deduktivní odvozování není možné použít vždy (ve skutečnosti skoro nikdy)
Cheap apartments are rare., Rare things are expensive. $\vdash$ Cheap apartments are expensive.
- projekty:
- **Never-ending Language Learning (NELL)**
- prochází web a odvozuje (hledá spojení mezi věcmi, keré zná a věcmi, které najde prostřednictvím vyhledávání)
- občas nutný lidský zásah (delete cookies, delete files => soubor stejná kategorie jako sušenky)
- **CyC**
- reprezentace pomocí vlastního jazyka CyCL
- pokus o zavedení obsáhle ontologie a znalostní báze
- cíl - expresivní jazyk, ontologie v rozumné úrovní detailu, znalostní báze, rychlý inferenční systém
- inferenční systém - dedukce, indukce, machine learning
- **ConceptNet**
- syntaktická analýza OpenMind, propojení s Wiktionary
#### Parafráze
- promluva $x$ je parafrází promluvy $y$, pokud $x$ a $y$ mají stejný nebo podobný význam
Tento most postavila Nejlepší firma s.r.o.
Nejlepší firma s.r.o. postavila tento most.
- hledání podobností
- na řetězcích (Levenshteinova vzdálenost)
- na slovech
- na slovech s použitím znalostní báze
- na syntaktických stromech
- kombinace předchozích
- využití:
- odpovídání na otázky
- chatbots
- detekce plagiátů
- výka
- automatická sumarizace textu
- doplnění implicitní znalosti
- logická analýza textu
- znalostní modely v umělé inteligenci
- korpusy parafrází
- Microsoft Research Paraphrase Corpus
- The Boeing-Princeton-ISI (BPI) Textual Entailment Test Suite
- Multiple Translation Chinese Corpus
- The SEMILAR Corpus: The SEMantic SimILARity Corpus
- Paraphrase Discovery
#### Generování parafrází
- základní způsoby parafrázování
- **aktivní-pasivní větná konstrukce** - Tento most byl postaven Nejlepší firmou s.r.o.
- **synonyma** - Tuto lávku postavila Nejlepší firma s.r.o.
- **hyperonyma** - Tuto stavbu postavila Nejlepší firma s.r.o.
- **substantivizace, deverbalizace** - Stavitelem tohoto mostu je Nejlepší firma s.r.o.
- **kombinace** - Tento most byl vytvořen Nejlepší firmou s.r.o.
#### Přirozená logika
- nástrojem je přirozený jazyk
- **monotonicita**
- **obsažení/omezení (containment)**
- **exkluze**
#### Belief-desire-intention
##### Záměr - Intention
- aktivní agent ví co chce, agent si tvoří nějáký plán
Najdi si cestu z domu X na FI.
##### Přání - Desire
- agentova motivace, motivovaný agent má cíle, cíle by neměly být v rozporu
Najdi nejkratší cestu z domu X na FI.
##### Belief - Domněnka
- báze znalostí, informace mohou být pravdivé, agent v ně v daný okamžik věří a chápe je jako nedokonalé přiblížení obrazu okolního světa.
Najdi nejkratší cestu z domu na FI. Mostecká je neprůjezdná.
## Machine translation
### Classification of MT based on approach
- **Rule-based, knowledge-based (RBMT, KBMT)**
- transfer
- with interlingua
- **Statistical machine translation (SMT)**
- **hybrid machine translation (HMT, HyTran)**
- **neural networks**
### Vauquiois's triangle

### Rule-based Machine Translation (RBMT)
- linguistic knowledge in form of rules
- rules for:
- analysis of **source language (SL)**
- transfer between languages
- generation/rendering/synthesis of **target language (TL)**
#### Knowledge-based Machine Translation
- systems using linguistic knowledge about languages
- older types, more general notion
- **analysis of meaning of SL** **is crucial**
- no total meaning (connotation - meaning dívka x děvucha, common sense)
- able to translate *vrána na stromě* => it is not necessary to know that *vrána* is a bird and can fly
##### KBMT classification
- direct translation
- systems with interlingua
- transfer systems
The only types of MT until 90s.
###### Direct translation
- the oldest systems
- one step process - transfer
- all components are bount to a language pair
- typically consists of
- translation dicitonary
- monolithic program dealing with analysis and generation
###### With interlingua
- we supposite it is possible to convert SL to a language-independent repesentation
- interlingua (IL) must be unambiguos (jednoznačný)
- two steps:
- analysis
- synthesis (generation) from IL
- analysis is SL-dependent but TL-independent
###### Transfer translation
- analysis up to a certain levels
- transfer rules S forms => T forms
- usually on syntactic levels => context constraints
- three step translation
##### Source language analysis
###### Tokenization
- first level in Vauqois $\triangle$
- input text to tokens (words, numbers, punctuation)
- problems:
- don't: do n't, do n't, don't?
- červeno-černý, červeno - černý, červeno- černý
###### Sentence segmentation
- Zeleninu jako rajče, mrkev atd. Petr nemá rád.
- Složil zkoušku a získal titul Mgr. Petr mu dost záviděl.
- related to named entity recognition
###### Morphological analysis
- second level of Vauquois $\triangle$
- reducing the immense amount of wordforms
- conversion from wordforms to lemma
- morphological disambiguation
- statistical (Desamb)
- rule-based (VerbaLex)
###### Lexical level analysis
- dictionaries - connection between languages
- transfer systems - syntactic levelse
### Statistical Machine Translation (SMT)
- inspired by information theory and statistics
- **Translation model**
- **Decoding algorithm**
- **Language model**