Korpusy, jazykové modely. Automatické morfologické a syntaktické značkování. Klasifikace textů, extrakce informací. Rekurentní neuronové sítě pro jazykové modelování, zpracování sekvencí, transformery. Odpovídání na otázky, strojový překlad. (PA153)
## Korpusy, (klasické) jazykové modely.
**korpus** = *je (většinou rozsáhlý) soubor textů určitého jazyka. Jedná se o vnitřně strukturovaný, unifikovaný a obvykle i o indexovaný a ucelený rozsáhlý soubor elektronicky uložených a zpracovaných jazykových dat většinou v textové podobě, organizovaný se zřetelem k využití pro určitý cíl. (wikipedia)*
**jazykovy model** = pravděpodobnostní distribuce přes všechny možné sekvence slov.
- používá se ke zjistění pravděpodobnostní distribuce následujícího slova
=> generování textu, doplňování chybějících slov do kontextu - skrz to, pak může řešit další úkoly
**Zipf's law**
$$\text{word frequency} \, \propto \, \frac{1}{\text{word rank}}$$
- word rank: kolikáté nejčastější slovo v korpusu
- word frequency: počet výskytů slova v korpusu
**n-gram** = **N-gramy jsou souvislé části textu sestávající z n slov.** 1-gramy neboli unigramy jsou jednotlivá slova, 2-gramy neboli bigramy jsou dvojslovné fráze, 3-gramy (trigramy) trojslovné fráze atd. Ve větě *Skákal pes přes oves* jsou tedy:
- unigramy: [skákal, pes, přes, oves]
- bigramy: [skákal pes, pes přes, přes oves]
- trigramy: [skákal pes přes, pes přes oves]


**!! pravděpodobnosti při násobení typicky rychle vypadnou z přesnosti floatů => převedeme na součet logprobů**

### Nevýhody
- když n-gram není v datech, ale objeví se při inferenci $p(w)=0$ -> potřeba **smoothing** (Add-one, Add-α, Good–Turing smoothing - nijak dál se ve slidech nerozebírá)
- pokud je **malé** $n$, máme nedostatečný kontext pro kvalitní predikci následujícího slova
- pokud je **velké** $n$ počet poteciálních n-gramů ($|slovník|^n$) naroste a pravděpodobnosti z dat budou extrémně řídký
### Porovnání jazykových modelů (obecně aplikovatelné)



---------------------------------------------------------------------------------------
## Automatické morfologické a syntaktické značkování.
Toto s náma Pary na PA153 na podzim 2023 ani 2022 neprobíral.. Velmi stručně, kdyby na tom chtěl někdo vyloženě trvat
ZKOPIROVANE ze stareho HackMD: https://hackmd.io/MYIa_15bSvmjt0JAYxs8tw
### Automatická morfologická analýza
Jedním z prvních kroků v automatickém zpracování textu někdy bývá morfologická analýza a lemmatizace.
#### Morfologická analýza
https://is.muni.cz/auth/el/fi/podzim2020/PA153/index.qwarp?prejit=5714569
https://nlp.fi.muni.cz/poc_lingv/slajdy-2019/pl04-2.pdf
Pro každý slovní tvar vrací:
- základní slovní tvar (lemma - položka slovníku)
- možné gramatické významy (značky)
- kombinace hodnot relevantních gramatických kategorií jako např. slovní druh (sloveso, zájmeno..), pád, číslo, osoba, jmenný rod (mužský životný, mužský neživotný, ženský...), atd.
- příkladem užití jsou morfologický analyzátory Ajka a Majka.
Příklad:
- Morfologická analýza věty 'Sním je místo něho'
- sloupce: analyzovaný tvar:lemma:značky kategorií (V-verb,S-singular...)

- Problém:
- Jakou informaci chceme / potřebujeme zachytit a popsat?
- Jak si tuto informaci / tato data budeme organizovat?
- Jak implementovat analýzu či syntézu nad těmito daty?
#### Značky
Gramatické informace reprezentujeme jako řetězec znaků, existuje na to více systémů:
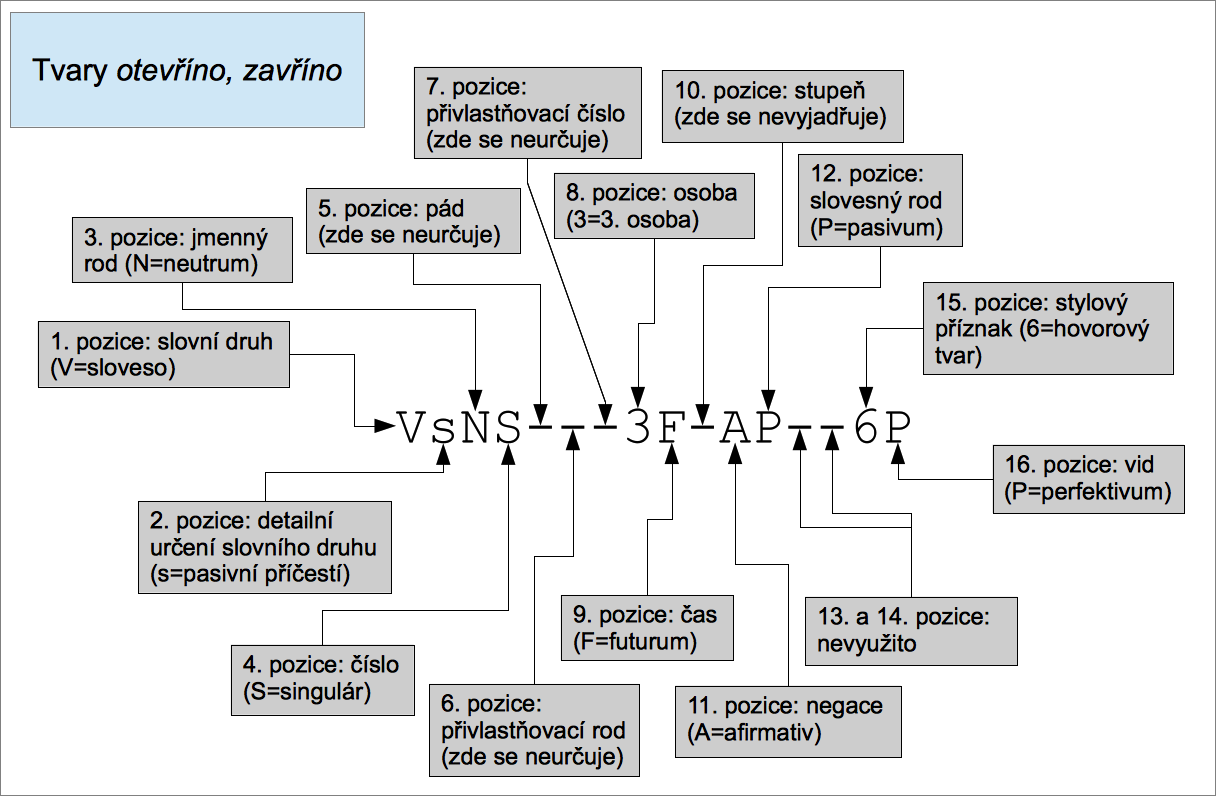
- Poziční systém (z Prahy):
- kategorie je určena pozicí ve značce (15 pozicí)
- 
- Atributový systém (z Brna, **takže lepší**):
- dvojice atribut-hodnota
- nezáleží na pořadí
- přehlednější, lehce rozšiřitelný, úspornější?why, čitelný regulárními výrazy
https://nlp.fi.muni.cz/projekty/ajka/tags.pdf
- *k1gInSc4*
- k1 - substantivum
- gI - mužský neživotný rod
- nS - singulár
- c4 - akuzativ
- nezachycuje specifikaci a afirmaci ??
- Heterogenní systém (Bratislava...):
- jako poziční, ale prázdné pozice jsou vynechané
- BNC tagset (english):
- pevná množina značek (AJO, AJC, AJS)
- problém: které všechny gramatické kategorie popisovat?
- které slovní druhy: zkratky, interpunkce, čísla, speciality
- které gramatické kategorie: *druhy zájmen*, *číslovek*, *příslovcí*, ...
- duál
### Sémantická analýza
#### Kolokace jako slovníkové heslo, MWE
- pevné kolokace: zakopaný pes, New York, křížem krážem
- porušují princip kompozicionality (význam složeného výrazu lze složit z významů jeho složek)
- v NLP se používá termín *multiword expression (MWE)*
- důležité MWE identifikovat, např. pro strojový překlad
- zamrzlé MWE: ad hoc
- pevné MWE: zakopaný pes, zakopaného psa
- syntaktické anomálie: cobydup, coby dup, co by dup
- MWE s možnou přetržkou: více méně, více či méně
- MWE jako vzory (patterns): vzít někoho na hůl (někoho ojebat finančně)
#### Nalezení významu v kontextu, WSD
- *lexikální desambiguace* (Word Sense Disambiguation)
- $F: (w, c) \rightarrow s$
- $w \in W$ - množina slov
- $c \in C$ - množina kontextů
- $s \in S$ - množina významů
- Algoritmy: hledáme význam slova použitého v kontextu
- Naivní Leskův algoritmus
- rozloží kontext na lemmy
- definice hledaného slova jsou taktéž množiny lem
- vytvoří průnik, definice, jejíž průnik má největší mohutnost je vybraná
- porovnávají se shody slov z kontextu se slovy ve významu ze slovníku => výstup, kde je největší shoda
- nevýhoda: nutnost slovníkových definicí
- WSD založené na ML
- stanovit význam u pevných kolokací (ručně nebo ze slovníku)
- iterativně zjistit další kolokace
kopie => kopie oddacího listu
- opakovat, dokud desambiguované množiny nepřestanou narůstat
- nevýhoda: Algoritmy závisejí na inventáři a popisu významů
- Kolik významů ma slovo *list*?
- SSJČ: 8
- SSČ: 6
- Word Sense Discrimination / Induction
- nepočítají s pevným inventářem významů, jen s kontextem (clustering?)
#### kontext
- verbální (slova vyskytující se před/za slovem/větou)
- situační (místo, čas, počet a vědomosti komunikačních partnerů)
- sociální (vzdělání publika, sociální status skupiny)
------------------------------------------------------------------------------------------------------------------------------
## Klasifikace textů, extrakce informací.
Ok, tak zase něco normálního.
- detekce spamu
- identifikace autora
- identifikace věku, genderu pisatele
- rozpoznání jazyka
- anaýza sentimentu
**vstup**: dokument; **výstup**: třída (předem definovaná)
* ručně vykraftěný pravidla - drahý na vytvoření a údrždu
* supervised strojový učení
* naive bayes
* logisticka regrese
* SVM
* KNN
* ...
Ve slajdech je zmíněná konkrétně akorát klasifikace pomocí naive bayesu
### Naive bayes klasifikace
- bag-of-words pohled na dokumenty (nezajímá nás pořadí, dokument je pro nás množina slov s počty výskytů)
- chceme odhadnout maximal a posteriory pravděpodobnost přes třídy $c$: $c_{MAP} = argmax_{c \in C}P(c|w_1, w_2, w_3, ...)$
- jinak funguje úplně stejně, jako klasickej naive bayes (podrobněji viz https://hackmd.io/WuUsIBmRQKaCMh6LGinfxg)


NEBOLI


#### Problém
- co když se nějaké slovo ze zkoumaného dokumentu nevyskytuje v trénovacích datech (případně jen v některých třídách)?
- to by vynulovalo pravděpodobnosti všech tříd (kde neylo) a nevěděli bychom nic
=> **add-1 smoothing** - při počítání frekvence přidáme k výskytu všech zkoumaných slov 1, kompenzujeme i ve jmenovateli
+ můžeme přidat i +1 za neznámé slovo

## Rekurentní neuronové sítě pro jazykové modelování, zpracování sekvencí, transformery.
zdroj: https://is.muni.cz/auth/el/fi/podzim2023/PA153/um/07-lec0506-rnn.pdf
* jiný pohled na jazykové modelování - model nám dává pravděpodobnost následujícího slova na základě kontextu
* vychází z:

### Rekurentní sítě
* neuronové sítě ve kterých informační proud není striktně dopředný, což dovoluje vstupům ovlivňovat výpočet sítě i nad vstupy procházející sítí v budoucnu
* budují si určitý typ vnitří paměti
* pro snazší vizualizaci a pochopení je lze rozvinout a vytvořit tak kvazi dopřednou síť
* loss je cross-entropy
* model vrací distribuci pravděpodonosti následujícího slova přes slovník
* label je one-hot-encoded správné následující slovo


* text se obvykle nařeže na menší kusy => častější updaty nejsou tolik náročné na paměť => SGD
* **teacher forcing** = pokud architektura RNN obsahuje zpětnou cestu z výstupního neuronu, můžeme modelu při tréninku vyměňovat jeho (pravděpodobně chybné) odhady následujícího slova za pravdivý label. Tím pádem ho jeho vlastní průběžné chyby nebudou plést
* autoregresivní generování textu (výstup z modelu cpeme zpět jako následující vstup)


#### Vanishing gradient problem


- Opacne taky exploding gradient - ten se da clipovat, ale co vanishing gradient?
=>
#### LSTM
soucasti otazky https://hackmd.io/Dd7PryIlSjSiTSusk0kHlg


### Další využití RNN (zpracování sekvencí)
* part-of-speech tagging
* named entity recognition
* zakódování celé věty (encoder) => klasifikace věty
* zakódování a následné dekódování (encoder-decoder)
* sumarizace
* question answering
* strojový překlad
* transkripce audia
### Transformery
součástí otázky: https://hackmd.io/FSCQMYT7TLS6opVxqK_0EQ
## Odpovídání na otázky, strojový překlad.
### Strojový překlad (Neural machine translation, NMT)
- standardně architektura encoder-decoder
- ale decoder-only transformery to zvladají taky supr
- stejné jako obyčejný language modelling, ale generujeme na základě vstupu a navíc už vygenerovaného prefixu
- potřeba velkých paralelních korpusů
- ke klasickým RNN a bidirectional RNN přibyla Attention
- pak už rychlá cesta k transformerům


#### Metody generování
- greedy decoding
- beam search
- sampling
- top-k
- top-p
- sampled beam search
- temperature parameter
### Odpovídání na otázky (Question answering, QA)
- velice komplexní problém
- různé typy otázek
- faktické/nefaktické
- uzavřená/otevřená doména
- výběr z možností/otevřená otázka
- porozumění textu (SQuAD dataset)
- různé typy odpovědí
- krátký kus textu (abstraktivní/extraktivní)
- seznam
- výběr z možností
- ...
#### Deep learning QA systémy
##### Porozumění textu (nejlehčí typ QA)
- obvykle end-to-end modely (na rozdíl od dřívějších systémů typu IBM Watson)
- SQuAD dataset
- **vstup**: úryvek z Wikipedie, otázka
- **výstup**: odpověď na otázku, která lze najít v úryvku
- kolem roku 2021 začaly neuronky porážet lidi
- Stanford attentive reader
- 2 bidirectional LSTM s attention
- predikuje začátek a konec části úruvku, která je odpovědí
- BERT based modely
- překonaly lidské skóre na SQuAD
- **vstup**: [CLS]<otázka>[SEP]<úryvek>
- pro každý token "nad úryvkem" spočítáme pravděpodobnost, že je start/end
- pravděpodobnost se určí tak, že se výstupní hidden state z BERTa (pro každý token jeden vektor) vynásobí s trénovanými START a END tokeny a strčí se to do softmaxu
##### Otevřené otázky
- nemáme k dospozici žádný úryvek -> buď si ho systém musí najít sám, nebo musí odpověď znát
- **document retriever** + **document reader** kombinace
- i retriever se dá trénovat
- reader si přečte nabídnutý text a buď ohraničí nebo vygeneruje odpověď
- obecné LLM
- buďto si odpovědi pamatují z tréninku
- nebo můžou vyhledávat na webu
### Metriky pro evaluaci generativních modelů
Vyhodnocovat automaticky generativní modely je těžké, a existuje řada metrik. Jejich kvalita se obvykle posuzuje podle toho jak korelují s lidským posouzením. Při počítání evaluačních metrik se předpokládá znalost nějakých referenčních výstupů (překladů).
#### WER (Word Error Rate)
- založené na edit distance (Lehvenstein) na úrovni slov
$$
\text{WER} = \frac{S + D + I}{N}
$$
kde:
- $N$ je počet slov v referenci
- $S$ je počet substitucí
- $D$ počet smazání (Delete)
- $I$ je počet vložení (Insert)
#### BLEU, SacreBLEU
- BLEU je rodina metrik založená na precision n-gramů
- Přes rozdílné $n$ (jako n-gramů) se dělá vážený geometrický průměr. geometrický průměr zvýhodňuje predikce, které mají **naráz** dobré přesnosti na úrovni 1-gramů, 2-gramů, ...,
- BLEU penalizuje příliš krátké výstupy protože ty mají obvykle vysokou přesnost (na úkor recallu)
- SacreBLEU je konkrétní konfigurace (vhodný default)
#### Rouge-N, Rouge-L
- Rouge-N:
- $n=2$ počítá bigramy, $n=3$ trigramy...
- za Rouge se bere recall na n-gramech
- některé zdroje ale uvádí, že Rouge je F1 skóre (harmonický průměr recallu a precision)
- Rouge-L
- založena na LCS - longest common subsequence
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet