解釋 Soperator:Nebius 推出的 Slurm Kubernetes Operator 開源專案
===
###### tags: `K8s / app / Slurm Operator`
###### tags: `Kubernetes`, `k8s`, `app`, `Slurm`, `Operator`, `Nebius`, `Soperator`, `Open Source`, `Github`, `GPU`, `shared filesystem`, `health checks`, `scaling`, `shared root`, `Cilium`, `Ceph`, `NFS`, `OpenEBS`, `GlusterFS`, `Terraform`, `V100`, `A100`, `H100`, `NCCL`, `InfiniBand`, `spool`
<br>
[TOC]
<br>
:::info
**原始出處**:[Explaining Soperator, Nebius’ open-source Kubernetes operator for Slurm](https://medium.com/nebius/e7a41f307d14)
**翻譯語言**:臺灣繁體中文(zh-rTW)
**翻譯人員**:gpt-4o (2025/06/03)
:::
---
# 解釋 Soperator:Nebius 推出的 Slurm Kubernetes Operator 開源專案
> 我們打造了一個開源的 Kubernetes Operator,能夠在 K8s 中執行並管理 Slurm 叢集。在這篇文章中,你將了解過去社群如何處理這項任務,以及我們解決方案的架構細節,我們將它命名為 Soperator。
**作者**:Mikhail Mokrushin
**發佈時間**:2024 年 9 月 24 日
**閱讀時間**:14 分鐘
**GitHub**:[https://github.com/nebius/soperator](https://github.com/nebius/soperator)
---
## 內容目錄
- [結合 Slurm 與 Kubernetes](#結合-Slurm-與-Kubernetes)
- 以 Kubernetes 為主
- 以 Slurm 為主
- 對等整合(Peering)
- [我們的解決方案](#我們的解決方案)
- 功能與設計理念
- 共用根檔案系統
- GPU 健康檢查
- 簡易擴展
- 高可用性
- 使用者操作隔離
- 快速啟動
- 可觀察性
- 目前限制
- 未來規劃
- 嘗試方式
- GitHub 原始碼庫
- 部署到任何 Kubernetes 叢集
- 部署到 Nebius 雲端
---
## 結合 Slurm 與 Kubernetes
Slurm 與 Kubernetes 都可用於分散式模型訓練與高效能運算(HPC)。兩者各有優劣,而在實務中,這些取捨其實相當明顯。
很可惜,目前還沒有簡單的方法能夠兼顧兩者優勢:Slurm 提供高效的排程與硬體掌控,Kubernetes 則有普遍性、自動擴展與自我修復能力。許多在大公司工作的 ML 工程師甚至沒有選擇權——公司預設就是使用 Kubernetes,無法支援獨立的模型訓練系統。那些堅持架設 Slurm 叢集的人,又會遇到資源無法共享的問題:昂貴的運算資源無法在兩個排程系統間互通。這也是為什麼許多公司都在努力讓兩者和平共存。
我們先來看看幾種理論上可行的整合方式,嘗試取得兩者優點。
### 以 Kubernetes 為主
最直接的方式是直接在 Kubernetes 叢集內執行 Slurm 節點(透過 Kubernetes Operator 實作)。過去已經有人試過好幾次,但沒有一個在開源圈真正成功。
這些方案的問題是:會強迫使用者改變他們使用 Slurm 的方式。Kubernetes 是為「雲原生」容器應用設計的,而 Slurm 並非這種類型。在一般 Slurm 環境中,節點的檔案系統通常是持久的:使用者會安裝軟體、建立 Linux 使用者與群組、儲存設定檔、批次腳本、作業輸出與其他資料。然而,在 Kubernetes 中,容器檔案系統是暫態的。很多變更都需要重建映像檔並重新啟動整個 HPC 叢集(因為 Slurm 節點是 Pod),這對模型訓練來說是災難。此外,這些方案也經常強迫使用者將作業包成容器執行,但不是所有 HPC 使用者都熟悉容器或雲原生哲學。
### 以 Slurm 為主
第二種方式是將 Kubernetes 節點當作 Slurm 作業來執行。這聽起來就很奇怪,實際上也的確如此。這方法不太可行(至少不太理想),因為 Slurm 作業最大執行時間為一年。
從工程角度來看,這不是一個好辦法:讓短時程作業跑在設計給長時程任務的系統中可能沒問題,但反過來就不妙了。
此外,這種方式也不太適用於各種託管型 Kubernetes 解決方案——不是每個人都願意自己維運一套內部部署系統。
### 對等整合(Peering)
這是理論上最乾淨的方法,所需變通最少。
與其將一個系統嵌入另一個系統,不如讓它們彼此整合,進而共享運算資源。Slurm 採模組化設計,因此可以開發一個排程外掛,讓 Slurm 可以將作業派送到 Kubernetes 上,轉為 Pod 執行。這樣的方式不需修改 Slurm 本體。
Slurm 開發團隊 SchedMD 正在開發這樣的解決方案,稱為 [Slinky](https://slurm.schedmd.com/slinky.html)。截至目前撰寫時間,還未釋出正式版本(細節可能會改變),但我們非常期待。
這種方式優雅又通用,不過還是會要求 Slurm 使用者改變互動方式,對某些使用者而言不太理想。
---
## 我們的解決方案
在 Nebius,我們選擇了「以 Kubernetes 為主」的方式。同時,我們設計的系統保留了使用者熟悉的操作體驗,又能符合雲原生的限制條件。這讓我們能夠加入許多傳統 Slurm 安裝缺乏的功能。
以下是我們解決方案的高階架構圖,說明如何用 Kubernetes 資源來表示 Slurm 叢集:
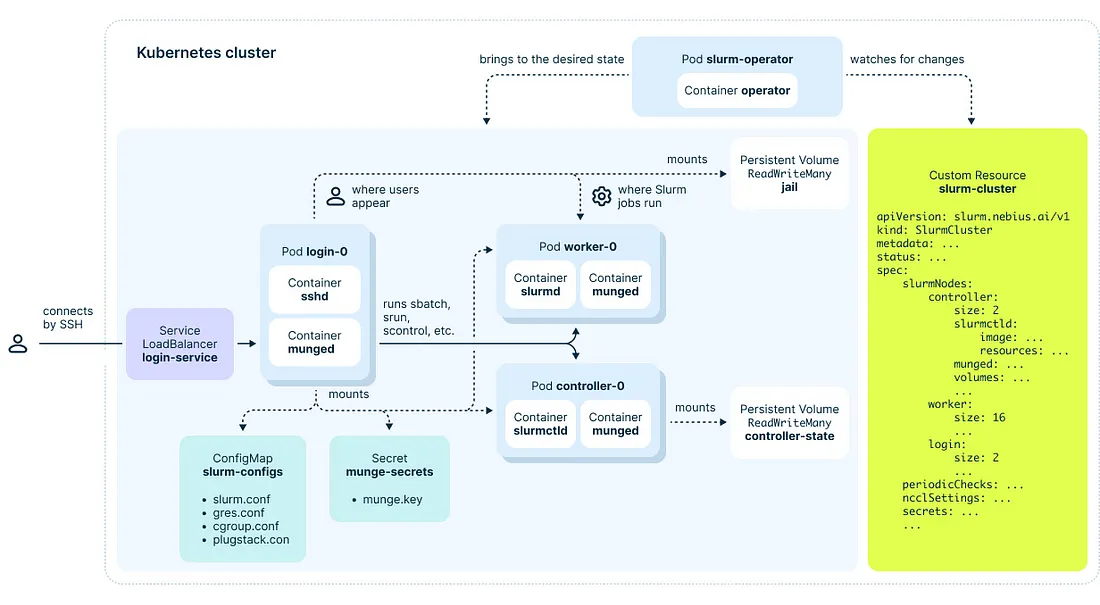
圖 1. Soperator 的頂層架構
乍看之下,我們的 Operator 運作原理很直觀:它接收你在 YAML 中定義的 Slurm 叢集目標狀態,並使實際的 Kubernetes 資源與之同步。在這個過程中,它會初始化新的 Slurm 節點、變更映像檔、更新設定檔、掛載新磁碟等等。
我們建立的 Slurm 叢集有三種類型的節點:Login、Controller 和 Worker(又稱 Compute),這些都是以 Kubernetes 的 [Pod](https://kubernetes.io/docs/concepts/workloads/pods/) 表示。
Login 節點有負載平衡機制——每次使用者透過 SSH 連線時,會被導向一個隨機的節點。
雖然所有容器的檔案系統都是暫態的(重啟後變更即消失),但我們透過 Kubernetes 的 [Persistent Volumes](https://kubernetes.io/docs/concepts/storage/persistent-volumes/) 來保留資料。
Soperator 的核心魔法在於我們如何使用「jail」這個 Persistent Volume。這個共用檔案系統會掛載到所有 Worker 與 Login 節點,並被視為另一個根目錄,可能來自不同的 Linux 發行版。
當使用者操作 Slurm 叢集(例如透過 SSH 存取檔案系統或執行 Slurm 作業)時,他們所見到的其實是這個共用檔案系統的根目錄(即 `/`)。這個技巧讓使用者保有熟悉的 Slurm 體驗,且更方便:他們不需要確保每個節點的檔案系統完全一致。他們可以在一個節點安裝軟體、建立使用者、寫入作業輸出或模型 checkpoint,其他節點馬上也能看到這些變更。
---
## 功能與設計理念
以下是我們透過與 Kubernetes 整合,為 Slurm 帶來的詳細功能介紹。
### 共用根檔案系統
如前所述,所有 Login 與 Worker 節點從使用者角度來看,都共用同一個根目錄。這與 K8s 容器搭配後,省去了節點同步的麻煩。我們將使用者操作的環境稱為「**jail**」。
「**host**」環境是各 Slurm 節點的原始容器環境,若出現問題可直接重新啟動回復原狀。
若你對遞迴有興趣,仍然可以在 jail 環境中使用容器再封裝你的作業。我們目前支援 [Pyxis 插件](https://github.com/NVIDIA/pyxis)。
#### 我們是如何實作的
對熟悉 Linux 的人來說,這種方法可能聽起來很瘋狂。Linux 並不設計來讓多個節點共用 rootfs。這是事實,因此我們的 rootfs 並非完全共用——部分目錄仍為本地,例如 `/dev`(裝置)、`/tmp`(暫存)、`/proc`(程序資訊)、`/run`(執行時資料)等。一些低層函式庫、裝置驅動與系統設定也非共用,而是從 host 環境 bind-mount 過來。
以下是示意圖,說明這個概念:
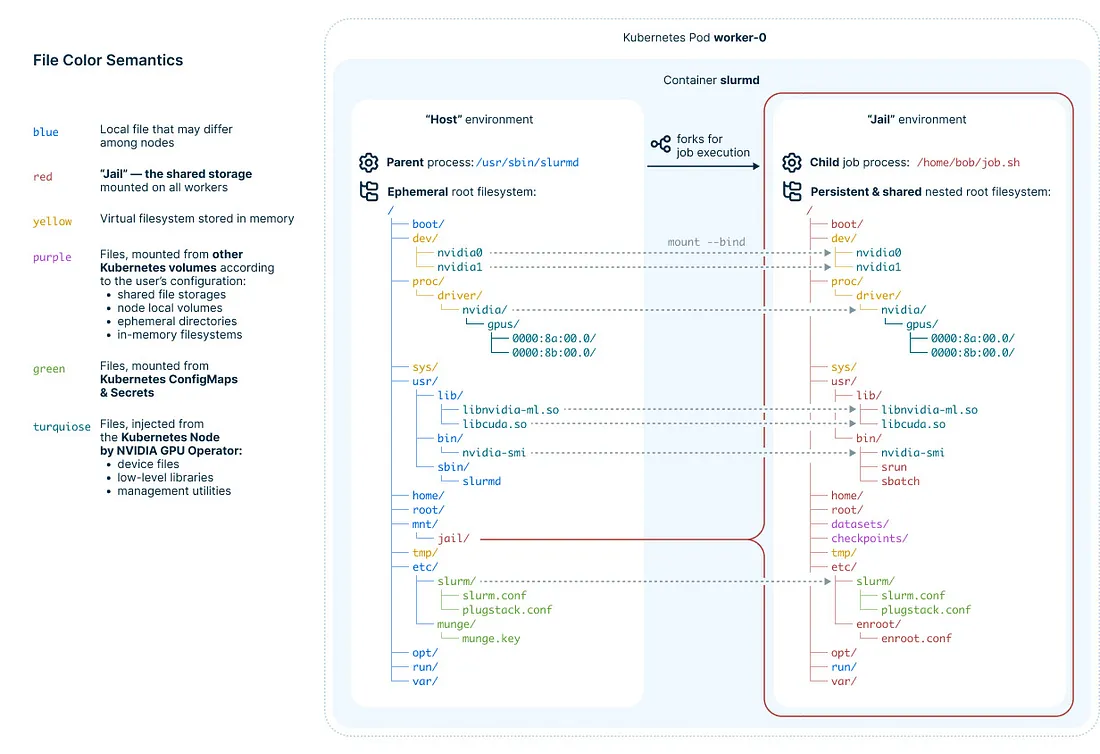
圖 2. 共用根檔案系統的實作方式
雖然這種方法不適用於任意 Linux 系統的 rootfs 共享,但對 Slurm 使用者來說已經足夠。Slurm 使用者通常不會在提交作業之間安裝驅動或啟用 daemon。我們的 Operator 可以額外支援這些功能,但大多數常見需求都能滿足。
共用檔案系統效能通常較差,這點也在我們考量之中。我們支援在 jail root 內部掛載本地(甚至記憶體)檔案系統,用以儲存效能敏感的資料,其餘則放在共用儲存上。
為了讓 Slurm 作業在 jail 環境中執行,我們撰寫了一個 [SPANK plugin](https://slurm.schedmd.com/spank.html),它會在 slurmd fork 出來之後、執行作業命令之前被呼叫。我們的程序會切換進新建的 Linux namespaces,並使用 [pivot_root](https://man7.org/linux/man-pages/man2/pivot_root.2.html) 呼叫來切換根目錄。所有容器技術如 Docker、containerd 都採取類似但更複雜的隔離方式。
這個插件不綁定於 Kubernetes,也可套用於傳統 Slurm 部署。
對於使用者 SSH 登入 Login 節點的情況,我們用的是 OpenSSH 的 ChrootDirectory 功能來切換根目錄。
出乎意料地(連我們都驚訝),它真的運作良好。
理論上,jail 環境也可以是各節點獨立的 Persistent Volume,只要搭配相同機制(Slurm plugin + ChrootDirectory)就能運作。雖然要維持節點一致性,但檔案系統效能會更好。若未來有需求,我們會加入此功能支援。
---
### GPU 健康檢查
這個功能是針對現代 ML 專用 GPU 的運算特性設計的。因為這些裝置在長時間重負載下的可靠性並不高。
尤其在大型叢集中更為明顯。請參考 [Meta 的經驗分享](https://youtu.be/ELIcy6flgQI?si=XXQmzhiq2uPuKoQF&t=1700),當時只因一張 GPU 出了點小狀況,整個 16,000 GPU 的叢集效能下降了 50%,持續了好幾個小時。可想而知損失有多慘重。因此,及早偵測硬體異常並快速將可疑節點下線是至關重要的。
我們的作法是定期執行 GPU 健康檢查。若某節點未通過檢查,Operator 就會將該節點「drain」,也就是從可分配作業的節點池中移除。
未來,我們還計畫與 Nebius 雲端整合,不只是 drain 節點,還要自動建立替代節點。我們也會預留介面,以便整合其他雲平台。
#### 我們是如何實作的
我們的解法有兩種類型的健康檢查:
1. **快速檢查**:執行時間不超過 10 秒,且可與使用者作業併行,不互相干擾。我們透過 Slurm 的 [HealthCheckProgram](https://slurm.schedmd.com/slurm.conf.html#OPT_HealthCheckProgram) 實作。檢查重點包括 GPU 是否正確辨識,以及是否存在重大硬體或軟體錯誤。
2. **長時間檢查**:需數分鐘完成,會以一般 Slurm 作業執行。目前我們使用 [NCCL 測試工具](https://github.com/NVIDIA/nccl-tests),執行 all_reduce_perf 測試,並將總線頻寬結果與預設門檻值比較,若未達標則自動將該節點設為 [DRAINED](https://slurm.schedmd.com/sinfo.html#OPT_DRAINED)。
以下是示意圖:
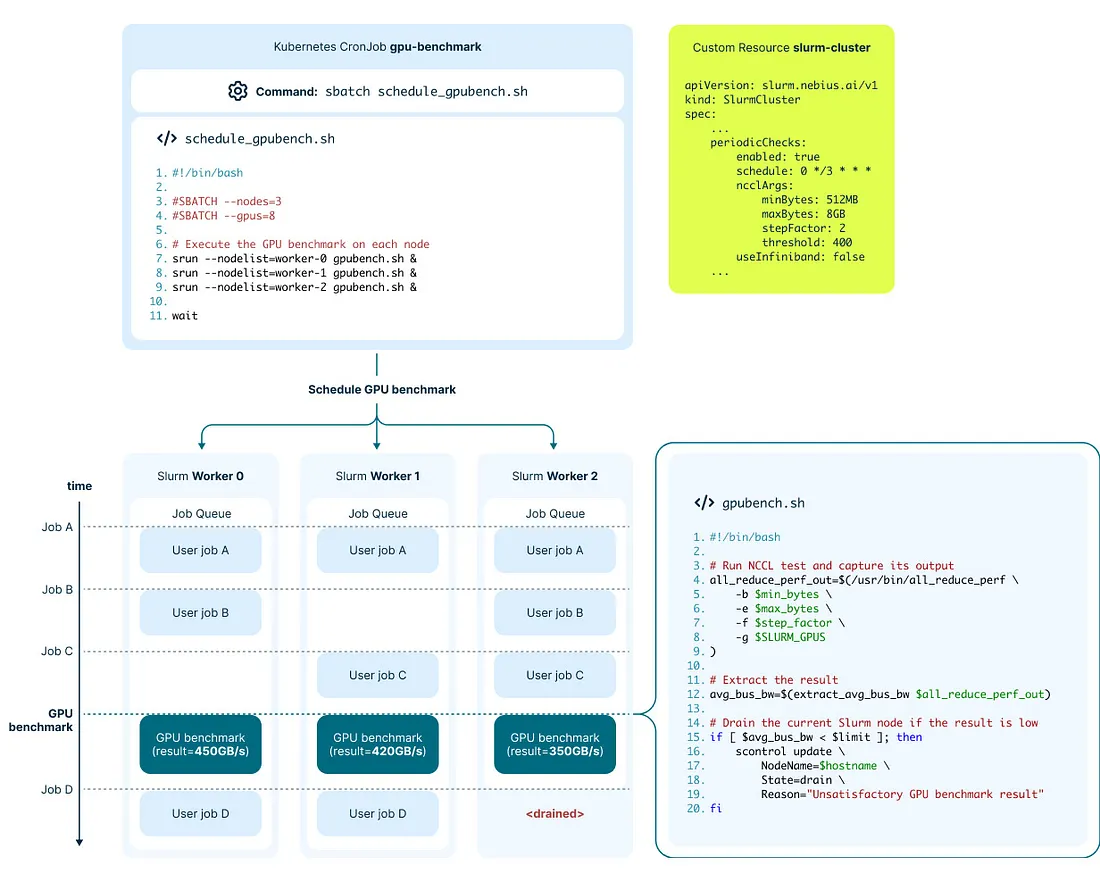
圖 3. 長時間 GPU 健康檢查流程
我們的 Operator 會建立一個 Kubernetes [CronJob](https://kubernetes.io/docs/concepts/workloads/controllers/cron-jobs/),定期在每個節點上執行上述 benchmark。
---
### 簡易擴展
機器學習產品開發往往會經歷資源需求變動的階段。有時需要大量運算資源進行訓練,有時只需少量實驗。若一直保留最大資源規模,將造成不必要的成本浪費。更進一步說,閒置資源也會排擠其他人使用,這在全球 GPU 供應緊張下尤其明顯。
因此,給使用者提供簡單的叢集擴縮功能非常重要。同時,這也讓我們得以「過度銷售」(oversell)硬體資源,提升效能與彈性。
我們不需特別開發此功能——只要 Slurm 跑在 Kubernetes 上就能自動支援。然而,共用根檔案系統的設計,讓擴展節點變得更加容易,因為不必逐一設置新節點環境。
以下是示意圖:
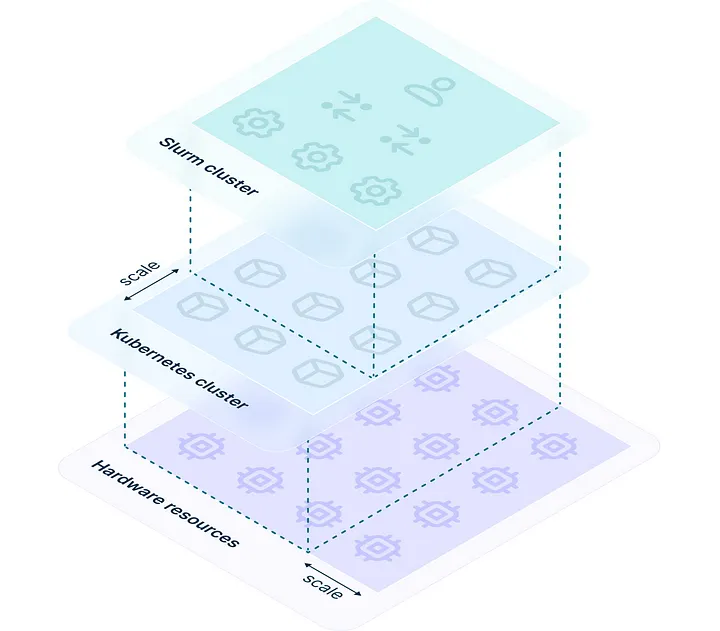
首先,我們利用大多數雲平台原生支援的 Kubernetes 自動擴展能力。
其次,我們將 Slurm 節點(Pod)分組為 [StatefulSets](https://kubernetes.io/docs/concepts/workloads/controllers/statefulset/),並允許使用者透過 SlurmCluster 定義直接調整節點數量。
只要修改 YAML 中的一個數值,你的叢集就能擴展或收縮。
---
### 其他功能
#### 高可用性(HA)
Kubernetes 天生支援某些 HA 機制。例如當某個 Pod 或容器異常(如 Slurm controller 掛掉),Kubernetes 會自動重新建立它。這對大型叢集管理者來說可謂安心不少。
我們的 Operator 更進一步,會持續將整個叢集維持在期望狀態。
#### 使用者操作隔離
使用者位於 [「jail」環境](https://nebius.atlassian.net/wiki/spaces/MSP/pages/edit-v2/254281930#Shared-Root-Filesystem),不會對 Slurm 主系統造成影響。即使他們擁有 jail 內部的 root 權限,也無法觸及 host 層級的設定。
這明確區隔了管理員(或雲服務商)與使用者的責任。
目前,若使用者刻意破壞仍可能影響系統,因此我們未來會強化安全隔離。目前只建立了 mount namespace,我們計畫日後加入更多 [Linux namespace](https://man7.org/linux/man-pages/man7/namespaces.7.html) 類型。
#### 快速啟動(Bootstrapping)
Soperator 能快速建立新的 Slurm 叢集且具一致性,步驟如下:
1. 建立共用儲存(NFS、GlusterFS、OpenEBS 等皆可)。Operator 只需要一個 PVC 名稱。
2. 使用我們提供的 Helm chart 安裝 Operator。
3. 再套用另一個 Helm chart 建立 SlurmCluster Custom Resource。如需多個叢集,只要重複這個步驟。
我們也提供 [Terraform 部署範本](https://preview.nebius.ai/services/soperator),在我們的雲端環境中 20~30 分鐘內即可完成整個部署(含 Kubernetes、網路、儲存等)。
#### 可觀察性(Observability)
我們的 Operator 可與獨立的監控堆疊整合(也提供 Helm chart),收集 Slurm 狀態與硬體使用情況,使用者可透過預設儀表板檢視這些資訊。
---
## 目前限制
Soperator 還很新,開發過程中我們必須設定優先順序,先滿足雲端客戶的需求。
若你需要的功能尚未支援,歡迎貢獻原始碼;或成為我們的客戶,我們將盡力優先實作你需要的功能。
以下是目前已知限制:
- **需配備 GPU。** 雖然支援純 CPU 的叢集看似簡單,我們尚未實作。
- **僅提供 Nebius 的 Terraform 範本。** 其他雲平台尚未支援。
- **縮減叢集規模會殘留節點。** 雖然可輕鬆擴展節點數,縮減後刪除的節點仍會在 Slurm controller 記憶體中殘留(例如 sinfo 輸出中),需要手動使用 `scontrol` 移除。
- **軟體版本受限。** 目前僅支援 Ubuntu 20.04 / 22.04,Slurm 23.11.6 / 24.05.3,CUDA 12.2.2。也依賴 Kubernetes 1.28 引入的某些功能。我們預設的 jail 環境內軟體版本也是固定的。
---
## 未來規劃
我們僅花三個月就完成了上述版本的 Soperator,但我們的規劃遠不止於此。
以下是一些正在開發或規劃中的功能,優先順序會依社群與雲端使用者需求而定:
- **Slurm 帳務系統(Accounting)**
你或許已注意到架構圖中沒有出現帳務資料庫或 daemon。我們目前尚未支援這部分,因此使用者會錯失 Slurm 的許多帳務功能。我們正在積極開發中。
- **更完善的安全性與隔離**
雖然理論上可以完全隔離 jail 與 host 環境,但目前尚未採用所有 Linux namespace 技術。尤其是我們目前建立的容器大多屬於 [「特權模式(privileged)」](https://slurm.schedmd.com/topology.html),這是安全性上的一個缺口。
- **按需節點(On-demand nodes)**
雖然目前可手動擴展叢集,我們未來將支援依佇列中等待作業數自動建立新的計算節點(在已設定上限內)。
- **支援網路拓樸感知排程**
Slurm 提供的 [拓樸功能(topology)](https://slurm.schedmd.com/topology.html) 能細緻配置網路結構,有助於強化分散式訓練或其他高效能用途(甚至是加密貨幣挖礦)。
- **自動替換異常節點**
現在若節點健康檢查失敗,我們只會將其 drain,仍需使用者手動處理。我們計畫加入全自動的節點替換功能。
- **jail 環境備份**
共用根目錄雖然便利,卻增加單點故障風險。因此我們規劃定期備份 jail,以提升整體叢集的可靠性。
- **自動 GPU 程序外部 checkpoint**
NVIDIA 正在研發的 [cuda-checkpoint](https://github.com/NVIDIA/cuda-checkpoint) 專案允許對 GPU 程序進行外部儲存 checkpoint。若能整合至 Slurm,就能避免開發者自行實作複雜的應用層檢查點邏輯。
---
## 嘗試方式
### GitHub 原始碼庫
我們將 Soperator 的原始碼分散於三個 GitHub 儲存庫中:
- [nebius/soperator](https://github.com/nebius/soperator) — 主儲存庫,包含 Operator 原始碼與 Helm charts。
- [nebius/slurm-deb-packages](https://github.com/nebius/slurm-deb-packages) — 用於建置 Slurm 與 NCCL 等開源套件,並發佈為 .deb 套件。有興趣者可獨立使用。
- [nebius/soperator-terraform](https://github.com/nebius/soperator-terraform) — 提供部署 Soperator 至 Nebius 雲端的 Terraform 配方。
若你發現 bug 或有功能需求但無法自行實作,請在相應儲存庫開 issue,我們會審閱!
---
### 部署至任意 Kubernetes 叢集
你可以將 Soperator 安裝到任何 Kubernetes 叢集,不論是自建或雲端。但請先確認以下條件:
1. 該 Kubernetes 叢集需使用 [Cilium](https://github.com/cilium/cilium) 為網路層。
2. 你需要一套共用儲存方案。Operator 僅需一個 PVC 名稱,但該 PVC 必須支援 ReadWriteMany 模式。最簡單的是 [NFS](https://kubernetes.io/docs/concepts/storage/volumes/#nfs),如需效能則可考慮 [OpenEBS](https://openebs.io/)、[GlusterFS](https://kubedemy.io/kubernetes-storage-part-2-glusterfs-complete-tutorial) 等。雲平台通常也提供共用儲存。
3. 目前仍需具備 GPU。雖然多數型號應可支援,但我們僅在 V100、A100、H100 上測試過。
4. 若叢集內部使用 Ethernet 通訊,可能需要額外調整以讓 NCCL 正常運作。使用 InfiniBand 則應可開箱即用。
詳細安裝說明請參考 [官方文件](https://github.com/nebius/soperator?tab=readme-ov-file#-installation)。
---
### 部署至 Nebius 雲端
我們保證 Soperator 能在 Nebius 雲端順利運作,並提供完整的 [Terraform 部署配方](https://preview.nebius.ai/services/soperator)。
只需依需求調整參數(也可使用預設值),執行 `terraform apply` 即可。此流程會自動建立 Kubernetes 叢集、虛擬網路、靜態 IP 與一個適用於多主機並行讀寫的 [分散式檔案系統](https://nebius.ai/docs/compute/concepts/filesystem)。
> 關鍵字:Kubernetes、K8s、開源、GitHub、Slurm、Operator、Nebius、Soperator、GPU、共用檔案系統、健康檢查、自動擴展、共用根目錄、Cilium、Ceph、NFS、OpenEBS、GlusterFS、Terraform、V100、A100、H100、NCCL、InfiniBand
<br>
---
---
<br>
# Soperator 是什麼?給 K8s 入門者的淺顯解釋
> by gpt-4o (2025/06/03)
## 🎯 這篇文章到底在講什麼?
這篇文章是在介紹一個叫 **Soperator** 的工具。它的功能是:
👉 **讓你可以在 Kubernetes 上,直接使用 Slurm 這套做高效能運算(HPC)的工具**。
它由 Nebius 公司開發,是一個開源專案(免費使用),專門給做 **機器學習、GPU 大量運算** 的人使用。
---
## ❓為什麼要把 Slurm 跑在 Kubernetes 上?
原本大家在跑模型訓練時,有兩種主流選擇:
| 系統 | 優點 | 缺點 |
|------|------|------|
| **Slurm** | 控制硬體很強、適合 HPC | 舊、難維護、不適合雲端 |
| **Kubernetes (K8s)** | 自動擴展、雲端友好 | 排程對 HPC 來說太弱 |
很多公司希望能**把這兩個結合**,既有 Slurm 的控制力,又有 Kubernetes 的靈活性。
---
## 🚧 有哪些整合方式?為什麼以前都不太成功?
1. **用 K8s 管 Slurm**(Kubernetes-first)
把 Slurm 節點當 Pod 跑。結果使用者要改很多操作方式,常常會「整個重來」才能更新,大家用不習慣。
2. **反過來,用 Slurm 管 K8s**(Slurm-first)
太奇怪、不實用,還得改 Slurm 的程式。
3. **讓兩者「和平共處」**(Peering)
最乾淨,但還是會逼你改操作方式(比如改寫 batch script),不夠貼近使用者習慣。
---
## ✅ Soperator 是怎麼做的?解法簡單說:
> **Soperator 就是一個 Kubernetes 的「Slurm 專用管理員(Operator)」**
它會讀你給的 YAML 設定(就像你描述你要什麼叢集),然後:
- 幫你建立 Slurm 的 Login、Controller、Worker 節點(用 Pod 形式)
- 掛載一個共用的磁碟區(jail),讓每個使用者看到的根目錄 `/` 是一樣的
- 使用者登入之後可以像在一般 Slurm 一樣跑作業
- 所有節點的檔案都同步,不用每次安裝東西都重來
- 這一切都用 **Kubernetes 的資源與方式來實現**
---
## 💡Soperator 有哪些優點?
| 功能 | 說明 |
|------|------|
| ✅ **共用根目錄(jail)** | 使用者看起來就像在一台 Linux 機器上用 Slurm,不用學習 Kubernetes。 |
| ✅ **GPU 健康檢查** | 會定期檢查 GPU 狀態,有問題的節點會自動下線(不再排程新作業)。 |
| ✅ **自動擴展** | 只要改一個 YAML 設定,就能讓叢集擴展或縮減。 |
| ✅ **高可用** | 節點掛掉,K8s 自己會重新啟動;Operator 會持續維護整體狀態。 |
| ✅ **使用者操作隔離** | 使用者的行為不會破壞整個叢集;可設 superuser 權限但只限 jail 裡。 |
| ✅ **快速建立新叢集** | 幾個步驟就能部署一個 Slurm 叢集。還有 Terraform 模板能一鍵安裝。 |
| ✅ **可觀察性** | 可搭配監控儀表板,看到作業狀態與 GPU 使用率等資料。 |
---
## ⚠️ 目前的限制是什麼?
- 目前只能支援有 GPU 的叢集
- 只支援 Ubuntu(20.04、22.04)、Slurm(23.11.6 和 24.05.3)
- CPU-only 或其他 OS 尚未支援
- 降低節點數時,Slurm 不會自動忘記舊節點(要手動清除)
---
## 🔮 未來會有哪些新功能?
- Slurm 帳務系統
- 更安全的隔離
- 作業多、節點不夠時自動加節點(on-demand)
- 自動替換壞掉的節點
- jail 根目錄自動備份
- 支援 GPU 程式的外部 checkpoint(例如 CUDA-checkpoint)
---
## 🚀 我要怎麼試試看?
### 方式一:用 Nebius 雲端(最簡單)
Nebius 提供一鍵部署的 Terraform 配方,幾十分鐘內就能建好整套叢集。
### 方式二:用自己的 K8s
你也可以在自己的 Kubernetes 叢集部署,只需要:
- 使用 Cilium 網路
- 提供一個 ReadWriteMany 的共用儲存(例如 NFS)
- 節點需要有 GPU(目前僅測過 V100、A100、H100)
---
## 📦 最後總結一句話
> **Soperator = Slurm 的 Kubernetes 管理員(Operator)**
> 讓你可以像以前一樣用 Slurm,但其實是在雲端 K8s 上跑,而且更容易、更安全、更能擴展。
<br>
---
<br>
# 各元件的解釋
## ✅ 圖片與簡化解釋的對應核對說明:
> by gpt-4o (2025/06/03)
### 🧠 Figure 1:整個 Slurm 叢集在 K8s 上長什麼樣子?

#### ✅ 白話解釋:
這張圖是「Soperator 背後整個系統在 Kubernetes 中的實際組成」。
1. **右邊黃色區塊是 YAML 設定檔(SlurmCluster CRD)**
- 你在這裡定義要幾個 login/controller/worker 節點
- 也可以開啟 GPU 健康檢查等設定
2. **中間藍色方塊是 Kubernetes 中跑的 Pod**
- login pod:讓使用者 SSH 登入、送作業
- controller pod:Slurm 的主控系統
- worker pod:實際跑作業的地方
- operator pod:負責監控與維持整體狀態
3. **底下是 Secret/ConfigMap/PersistentVolume 等 Kubernetes 元件**
- 用來提供設定檔與儲存空間(jail 就是用 ReadWriteMany 的 volume)
➡️ **結論:整個 Slurm 系統已經被拆成 Kubernetes 中的多個 Pod,但你看起來還是在用 Slurm。魔法來自那份 YAML 設定與 operator 的管理邏輯。**
---
### 🧱 Figure 2:為什麼叫 jail?原來是「共用根目錄」的魔法

#### ✅ 白話解釋:
這張圖在講「為什麼 Slurm 裡每個節點看起來都像是同一台機器」。
1. **左邊是 host 的環境**:每個 Slurm worker 的原始容器檔案系統,會隨重啟而變動。
2. **右邊是 jail(監獄)**:是掛載在每個 worker 上的共用資料夾,使用者看到的根目錄 `/` 就是從這裡來的。
3. **底層原理是 bind mount(資料夾疊起來)**:只把需要的目錄掛過來,例如 GPU 驅動、設定檔等。
➡️ **結論:jail 就是讓你覺得自己在一台完整 Linux 主機上寫程式、跑作業、存資料,但實際上這是由共享空間 + 綁定掛載完成的假象。**
---
### ⚙️ Figure 3:自動健康檢查 GPU,爛掉就下線!

#### ✅ 白話解釋:
這張圖講的是「Slurm 叢集怎麼自動檢查 GPU 是否正常」,流程如下:
1. **Kubernetes 幫你定期排程一個 CronJob(排程任務)**
2. **這個任務會發一個 Slurm 作業**,裡面是 benchmark 指令(例如測 bus 傳輸速度)
3. **每個 Slurm worker 節點會執行一次 GPU 測試**
4. **如果結果太差(例如 350GB/s 低於門檻 400)→ 這個節點會自動被設為 DRAINED,不再排作業**
➡️ **結論:你不用人工去監控哪顆 GPU 壞掉,Soperator 幫你定期跑 benchmark,自動下線壞節點。**
---
### 🧩 Figure 4:Slurm 是怎麼跑在 Kubernetes 上的?

#### ✅ 白話解釋:
這張圖就像是「三明治剖面圖」,從下到上分三層:
1. **最下面:硬體資源**
就是你買的 GPU、CPU、記憶體,這些實體機器。
2. **中間:Kubernetes 叢集**
像是「虛擬機器管理員」,負責幫你分配和啟動工作。這層可以自動擴充。
3. **最上面:Slurm 叢集**
使用者其實只看得到這層。你用 Slurm 提交作業,背後是由 Kubernetes 幫你完成的。
➡️ **結論:你還是像平常一樣用 Slurm,但實際運算是跑在 K8s 上,由它幫你控管資源。**
---
### 🎉 總結一下
| 圖片 | 重點 | 白話理解 |
|------|------|----------|
| Figure 1 | 整體架構 | 所有組件都變成 K8s 的 Pod,用一份 YAML 管理一切 |
| Figure 2 | jail 架構 | 看起來每台機器一樣,是因為用了共享 root 檔案系統 |
| Figure 3 | GPU 健康檢查 | 自動用 Slurm 作業檢查 GPU 壞沒,壞的自動退役 |
| Figure 4 | Slurm 跑在 K8s 上 | 三層疊起來,Slurm → K8s → 實體硬體 |
<br>
---
<br>
## 🔐 `munge` 在 Soperator 中的角色與用途
> by gpt-4o (2025/06/03)
在 **Soperator(Nebius 的 Slurm Operator)** 中,`munge` 是 Slurm 各節點間 **身分驗證與通信信任的基礎機制**,它是 Slurm 安全模型中不可或缺的一環。
---
### 🔐 `munge` 的角色與用途
#### ✅ 在 Slurm/Soperator 中的任務:
| 功能 | 說明 |
|------|------|
| ✅ 驗證 | 提供 **Slurm 各節點之間(`slurmctld`, `slurmd`)的身分驗證**,保證來自合法來源的訊息才被接受。 |
| ✅ 加密 | 對傳遞的訊息進行 **對稱加密(shared key)與簽章**,保證資料完整性與來源可信。 |
| ✅ 單一信任來源 | 所有 Slurm 節點必須使用相同的 `munge.key`,否則無法加入 Slurm cluster。 |
---
### 📦 在 Soperator 中如何運作
在 `SlurmCluster` CR YAML 中,你會看到 `munge` 相關設定出現在:
#### ✅ Controller:
```
controller:
munge:
image: quay.io/munge/munge:0.5.14
```
### ✅ Worker:
```
worker:
munge:
image: ghcr.io/nebius/soperator/munge:1.19.0-jammy-slurm24.05.5
```
這表示每個控制器與 worker pod 都會:
1. 使用這個 `munge` image 啟動一個 container 或 sidecar
2. 持有 **相同的 `munge.key`**(由 Operator 自動在 secret 中分發,或你也可自建)
3. 在啟動 `slurmd` / `slurmctld` 前先啟動 munge,確保通信過程中可進行認證
---
### 🔑 `munge.key` 的由來與管理
- Soperator 會自動產生一份 `munge.key` 並儲存在 `secret/soperator-munge` 裡。
- 所有節點都會 mount 此 secret 至 `/etc/munge/munge.key`
- 若你有自己生成的 key,可將其放入 Kubernetes secret 中:
```
kubectl create secret generic soperator-munge --from-file=munge.key --namespace=soperator
```
---
### 🔄 Slurm 節點之間通信流程(簡略)
1. `slurmctld` 發送 job 啟動指令 → 使用 munge 加簽並加密
2. `slurmd` 收到指令,驗證 munge token 是否有效
3. 任務啟動,job log 上傳,所有階段的 request 都通過 `munge` 做驗證
---
### 🧠 總結:為何 `munge` 是必須的?
| 原因 | 說明 |
|------|------|
| 安全 | 防止任意節點冒充發送命令 |
| 一致性 | 所有節點必須共享相同的 key |
| 整合性 | 沒有 munge,Slurm job 將無法派送,也無法認可回傳的任務結果 |
---
如果你使用的 image 是自己 build 的,記得也要有 `munge` daemon 在 container 裡正確啟動,並指定 `--munge-socket` 給 Slurm。
是否需要我幫你畫出這整個通信與驗證流程?或者給你 sample `munge` 初始化腳本?

<br>
---
<br>
## 📁 spool & jail 在 Soperator 中的角色與功能說明
> by gpt-4o (2025/06/03)
在 **Nebius Soperator** 的 Slurm 架構中,`spool` 和 `jail` 是 Slurm Worker 的兩個主要 PersistentVolume 掛載點,各自扮演不同但關鍵的角色:
---
### 📁 `spool`: Slurm 的核心資料交換與狀態維護區
#### ✅ 角色與功能:
- 用於 **Slurm 工作節點 (`slurmd`) 的核心暫存與通信資料**
- 常用來存放:
- `slurmd` 的 state 資料夾(例如 `/var/spool/slurmd`)
- 工作派發、完成的中繼檔(如 job 退出碼、任務狀態)
- 如果開啟 `Prolog`, `Epilog` script,可能也會用到這個目錄
#### ✅ 舉例掛載:
```
volumes:
spool:
volumeSourceName: spool
```
在 pod 內掛載到 `/var/spool/slurmd` 或 `/mnt/spool`。
---
### 📁 `jail`: 用來 sandbox Job 的工作目錄(Job 執行區)
#### ✅ 角色與功能:
- 為每個 job 提供 **隔離的工作目錄空間**,類似 container 的「根目錄分區」
- 通常對應 Slurm `TaskPluginParam=Cray_PrologSlurmctld` 或 jail-like 管理方式
- 多個 jailSubMount 可以設置對應不同 job 目錄或使用者資料
- 如果使用 `Slurmrestd` 或 `JobContainerPlugin=contain`,這個也可能做為容器內部的根目錄掛載點
#### ✅ 舉例設定:
```yaml
volumes:
jail:
volumeSourceName: jail
jailSubMounts:
- name: jail
mountPath: "/"
volumeSourceName: jail
```
- `jail` 是一個 PersistentVolume,`jailSubMounts` 是針對此 volume 的細分掛載
- 每個 Worker pod 都會有 `/mnt/jail` 或 `/mnt/data` 之類的子掛載點,對應 job 執行空間
---
### 🔁 二者比較
| Volume | 主要用途 | 資料性質 | 掛載路徑(常見) | 是否 Job 專屬 |
|--------|-----------------------------|---------------------|-----------------------------|----------------|
| `spool` | `slurmd` 工作管理暫存區 | 系統暫存、狀態資料 | `/var/spool/slurmd` | ❌ 共用 |
| `jail` | Job 執行目錄、隔離區(sandbox) | 使用者資料、job輸出 | `/mnt/job`, `/` (jail root) | ✅ 每 job 可獨立 |
---
### ✅ 延伸:為何要 `jailSubMounts`?
你可以讓 Slurm 在啟動 job 時,把 jail volume 的某個 `subPath` 當作該 job 的 root FS,例如:
```
jailSubMounts:
- name: job-data
mountPath: /job
volumeSourceName: jail
subPath: jobs/${SLURM_JOB_ID}
```
這樣每個 job 都有隔離、持久、可回溯的執行目錄,特別適合多 GPU 任務或 AI 訓練任務(如 checkpoint 儲存)。
<br>
{%hackmd vaaMgNRPS4KGJDSFG0ZE0w %}