# Thesis work session 2
## Kiến thức chung về sound signal [^1]
- Âm thanh là một dạng tín hiệu được sinh ra từ việc thay đổi **áp suất không khí**. Cường độ của **sự thay đổi áp suất** này có thể đo được, nó chính là Applitude (biên độ).
- Sound signal là một dạng tín hiệu tương tự(**analog signal**)bọn em xin phép không tìm hiểu sâu hơn về dạng này.
- Để chuyển sang dạng số (**digital**) để lưu trữ và xử lý trên máy tính, ta sẽ rời rạc hoá dữ liệu âm thanh thành các phần tử (sample) rồi rạc. Mỗi sample biểu diễn biên độ âm thanh tại 1 thời điểm.

- **Sample rate** là mật độ sample trong **một giây**. Ví dụ : file âm thành dài 10s với mật độ 16000hz thì số sample là : 10*16000.
## Biểu diễn sound signal [^2]
Một tín hiệu âm thanh chính là sự kết hợp của các dao động với tần số khác nhau. Để mạng neural có thể trích xuất các đặc trưng tốt hơn, ta sẽ biểu diễn âm thanh dưới dạng một **tổ hợp ** của **các hàm biểu diễn dao động với các tần số khác nhau**.
**Sự dao động** được biểu diễn dưới dạng hàm $sin$.
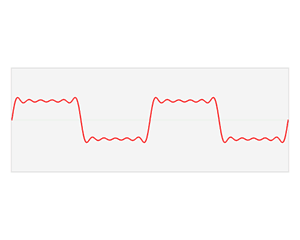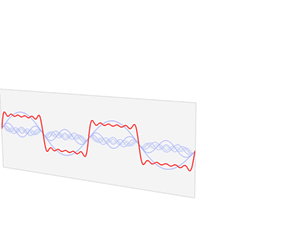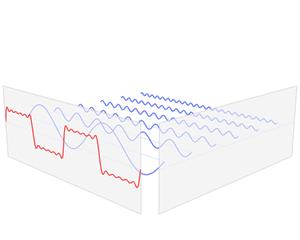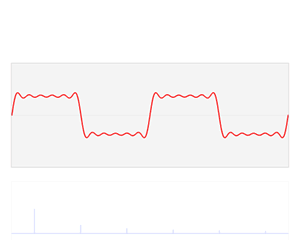
Để có thể hồi quy các samples về tổ hợp các hàm dưới dạng $\sum_{i}(n_i\sin(it)) (sin(\omega_it)$ tương ứng với tần số $f = \frac{\omega}{2\pi}$*(khúc này không nhớ kĩ)*).
Ta sử dụng phương pháp **tích phân fourier**. Có 2 loại là Discrete Fourier Transform và Fast Fourier Transform. Lựa chọn pp nào sẽ nghiên cứu sau.
Tuy nhiên, cách biểu diễn này **không có thông tin về thời gian**.
Như vậy, sau khi thực hiện phép tích phân fourier, ta được vector sau :
$[n_1,n_2,...,n_i]$ với $n_i$ là hệ số của âm thanh có tần số $f_i$ trong hàm hồi quy. Việc chọn lựa các tần số để biểu diễn sao cho hợp lý sẽ được nghiên cứu sau.
### Sử dụng khung cửa sổ
- Chia chuỗi âm thanh đang phân tích **thành các chuỗi âm thanh con nhỏ hơn**(còn được gọi là khung cửa sổ).
- Để tránh mất thông tin về một vài tần số (bọn em chưa nghiên cứu mất cái gì, tại sao mất?), chúng ta thường dữ cho các khung cửa sổ này **chồng lên nhau - overlap**.
- Đối với tác vụ **liên quan đến giọng nói** thì độ dài khung cửa sổ nên là 20-30ms. Thường thì đây là khoảng thời gian tối thiểu của 1 âm tiết.

Với mỗi windows, ta được một vector. Như vậy, một đoạn âm thanh sẽ được phân tách thành một ma trận 2D với mỗi dòng là một vector biểu diễn cho một cửa sổ.
## Tần số của các âm thành phần.
- Con người không phân biệt được tần số trên thang đo tuyến tính. VD : phân biệt được 100Hz và 200Hz nhưng không phân biệt được 2000Hz và 2100Hz. => phải log scale tần số.

## Mel frequency Cepstral Coefficients (MFCC) [^3][^4]
MFCC là một phương pháp dùng để trích xuất đặc trưng đại diện cho digital signal như là âm thanh, giọng nói.
**Idea:** MFCC dựa trên khả năng nghe của đôi tai con người, tai người thường không thể cảm nhận được âm thanh có tần số trên 1 KHz. MFCC có 2 loại bộ lọc chính: spaced linearly ở tần số thấp (dưới 1000 Hz), logarithmic spacing ở tầng số cao (trên 1000 Hz).
MFCC bao gồm 7 bước:

Speech signal sẽ được biểu diễn dưới dạng hai chiều (x,y) với x là thời gian và y là biên độ (hay nói cách khác giọng nói sẽ được biểu diễn bằng biên độ âm thanh theo thời gian)
- **Bước 1 Pre-emphasis**:
- Các âm ở tần số thấp sẽ có mức năng lượng cao và các âm ở tần số cao sẽ có mức năng lượng thấp. Tuy nhiên, hầu như các âm ở tần số cao chứa nhiều thông tin về âm vị hơn các âm ở tần số thấp -> cần phải nâng giá trị âm tần số cao
- Vấn đề về số trong lúc thực hiện phép tích phân fourier -> cần phải có filter đưa về dạng "không có vấn đề về số".
$$y(n)=x(n)-\alpha x(n-1)$$
Với :
$\alpha\in[0.9,1]$
$y(n)$ là tín hiệu sau khi được emphasis tại thời điểm $n$
$x(n)$ là tín hiệu trước khi được emphasis tại thời điểm $n$
Ngoài trừ việc giải quyết vấn đề số khi tích phân Fourier thì các mục khác của pre-emphasis đều là mục đích phụ (các bước sau cũng sẽ thực hiện các mục đích này).
- **Bước 2 Framing**: Tín hiệu âm thanh (sau khi chuyển về dạng digital) ở dạng liên tục theo thời gian, do đó cần phải chia thành các khung (frame). Mỗi khung có kích thước khoảng 20-40 ms và chồng lên nhau (tức là từ đầu frame sau tới cuối frame trước) khoảng 10-15 ms.
- **Bước 3 Hamming windowing**: Việc chia tín hiệu âm thanh thành các khung dẫn đến việc chúng sẽ rời rạc với nhau, nghĩa là các giá trị ở 2 biên của mỗi khung sẽ bị giảm đột ngột về 0 dẫn tới khi tới bước FFT chuyển sang miền tần số sẽ xuất hiện rất nhiều nhiễu ở các tần số cao. Để khắc phục được vấn đề trên, ta sẽ dùng một hàm Hamming Window để làm mượt các khung:

Sau đó nhân chập khung với window (W) vừa tính được:
$$Y(n)=X(n)*W(n)$$
N: số mẫu trong mỗi khung
Y(n): tín hiệu output
X(n): tin hiệu input
W(n): hamming window
- **Bước 4 Fast Fourier Tranform + power spectrum**: Chuyển đổi các khung từ biểu diễn theo miền thời gian sang biểu diễn theo tần số.

Trong đó $N_{FFT}$ bằng 256 hoặc 512, $x_{i}$ là frame thứ $i$ của tín hiệu âm thanh $x$
- **Bước 5 Mel filter Bank Processing**: Dải tần số trong phổ FFT (FFT spectrum) rất rộng và phi tuyến, do đó ta cần sử dụng một 1 tập các bộ lọc Mel-scale (Mel-scale filter) trên từng khoảng tần số (mỗi filter áp dụng trên 1 dải tần xác định). Giá trị output của từng filter là năng lượng dải tần số mà filter đó bao phủ được (tổng của các thành phần quang phổ đã lọc).


- **Bước 6 Discrete Cosine Transform**: là quá trình biến đổi log Mel spectrum(*) về miền thời gian (**). Phép biến đổi DCT là một phép biến đổi trực giao. Về mặt toán học, phép biến đổi này tạo ra các **uncorrelated features**, có thể hiểu là các feature độc lập hoặc có độ tương quan kém với nhau. Trong các thuật toán Machine learning, uncorrelated features thường cho hiểu quả tốt hơn.
>(*) lý do ta dùng **log** Mel spectrum bởi vì con người kém nhạy cảm trong sự thay đổi năng lượng ở các tần số cao, nhạy cảm hơn ở tần số thấp. Vì vậy ta sẽ tính log trên Mel-scale power spectrum. Điều này còn giúp giảm các biến thể âm thanh không đáng kể để nhận dạng giọng nói.
(**) ở đây ta sẽ dùng phép biến đổi Fourier ngược (IFFT) để biến đổi ngược về miền thời gian, ta sẽ thu được các Cepstrum (ngược lại của Spectrum).
**Lý giải thêm việc tại sao phải dùng phép IFFT để biến đổi ngược về miền thời gian**: Tín hiệu giọng nói đầu vào là spectrum (phổ) chứa rất nhiều thông tin nhiễu và các thông tin không cần thiết. Việc biến đổi ngược nhằm mục đích tạo ra Cepstrum, với các Cepstrum thu được các phần thông tin quan trọng sẽ nằm tách biệt với các thông tin không cần thiết khác. Cụ thể là phần thông tin quan trọng sẽ nằm ở đoạn đầu của Cepstrum nên ta chỉ cần lấy 12 giá trị đầu để tính MFCC (12 cepstral).




- **Bước 7 Delta Energy + Delta spectrum**: mỗi khung ta đã trích xuất ra được 12 Cepstral features làm 12 feature đầu tiên của MFCC. Feature thứ 13 là năng lượng của khung đó, tính theo công thức:

13 hệ số tiếp theo tương ứng với 13 delta features thể hiện sự thay đổi giữa các khung, chính là đạo hàm bậc 1 của 13 feature đầu tiên. Hay nói cách khác, chúng chứa thông tin về sự thay đổi từ khung t đến khung t+1 theo công thức:

Tương tự như vậy, 13 hệ số tiếp theo (cũng là 13 hệ số cuối của MFCC) là đạo hàm bậc 1 của d(t), hoặc đạo hàm bậc 2 của c(t):

Tóm tại, từ 12 cepstral + 1 cepstral năng lượng, đạo hàm hai lần ta thu được MFCC feature (gồm 39 feature).
# Speech Enhancement
https://ieeexplore.ieee.org/document/8462593
Speech Enhancement(SE) là một tác vụ chuyển âm thanh tiếng nói người có lẫn tạp âm thành âm thanh tiếng nói sạch (làm rõ tiếng nói, loại bỏ tạp âm).
## Thang đo (metric) đùng để đánh giá mô hình SE
Các công trình nghiên cứu cho ra những mô hình SE khác nhau. Để đánh giá độ hiệu quả của từng mô hình thì phải có một thang đo chuẩn, thể hiện mức độ hiệu quả trong tác vụ SE.
Các đơn giản nhất là sử dụng MSE giữa chuỗi âm thanh kết quả cho ra bởi mô hình(output) và âm thanh tiếng nói gốc từ tập dữ liệu được đem đi huấn luyện (ground truth). Viết dưới dạng toán học :
$$MSE(\hat{y},y)$$
Tuy nhiên, cách này chỉ đánh giá sự giống nhau giữa output và ground truth chứ không đánh giá được độ rõ ràng của âm thanh (mục đích chính của model).
Sau đây là một số cách khác được dùng :
- Subject testing : đánh giá bằng con người, cho một nhóm người nghe âm thanh lọc bởi các model và đánh giá xem âm thanh từ model nào tốt hơn. Cách này khá tốn kém thời gian và chi phí.
- Intrusive metrics : dùng âm thanh ground truth để đối chiếu. i.e : NCM,STOI,PESQ, HASQI,HASPI, PEMO-Q.
- Non - intrusive : không dùng âm thanh ground truth để đối chiếu.
Vì khi huấn luyện, ta thường đã có dữ liệu âm thanh tiếng nói rõ ràng (clean), và tạo ra âm thanh tiếng nói nhiễu bằng cách thêm vào những âm thanh clean các âm thanh nhiễu nên phương pháp intrusive metrics sẽ phù hợp hơn.
## Short-time objective intelligibility(STOI)
STOI là một thang đo dựa trên correlation coefficient giữa output và ground-truth.
Tín hiệu được giải mã bởi 1/3-octave filterbank (lọc tần số giống với mel-filterbank nhưng cách thực hiện khác).
# SEGAN : Speech Enhancement Generative ADversarial Network
## mô hình GAN
mô hình GAN là mô hình sản sinh ra dữ liệu bằng cách học để ánh xạ một sample $x$ được lấy từ phân phối $X$ từ một mẫu $z$ được lấy từ phân phối $Z$. Ví dụ :Cho $z$ là một hình ảnh chú chó, hình ảnh có cấu trúc được lấy mẫu từ phân phối $Z$ ; Từ một số ngẫu nhiên $x$ lấy mẫu từ phân phối $\mathcal{N}(0,1)$, mô hình đã được huấn luyện $f$ sẽ cho ra ánh xạ là một hình ảnh chú chó $z$.
... giải thích về 2 module của GAN là Generator (mạng G) và Discriminator (mạng D).
## LSGAN
https://arxiv.org/pdf/1611.04076v3.pdf
Một vấn đề của mạng GAN là loss function bị hiện tượng vanishing gradient khi huấn luyện Generator.
LSGAN đề suất loss function như sau :

## Kiến trúc autoencoder
Autoencoder bao gồm 3 phần chính
Encoder: Module có nhiệm vụ nén dữ liệu đầu vòa thành một biễu diễn được mã hóa (coding), thường nhỏ hơn một vài bậc so với dữ liệu đầu vào
Bottleneck: Module chứa các biểu diễn tri thức được nén (chính là output của Encoder), đây là phần quan trọng nhất của mạng bới nó mang đặc trưng của đầu vào, có thể dùng để tái tạo ảnh, lấy đặc trưng của ảnh, ….
Decoder: Module giúp mạng giải nén các biểu diễn tri thức và tái cấu trúc lại dữ liệu từ dạng mã hóa của nó, mô hình học dựa trên việc so sánh đầu ra của Decoder với đầu vào ban đầu (Input của Encoder)

## SEGAN
SEGAN là một mô hình GAN với input là $\hat{x}$ và output là âm thanh rõ ràng $\tilde{x}$. Trong trường này, mạng G sẽ thực hiện tác vụ SE. Input của mạng G là $\hat{x}$ với vector khởi tạo ngẫu nhiên $z$ và output là $\tilde{x} = G(\hat{x})$.
Mạng G sẽ được thiết kế theo kiến trúc autoencoder. Ở phần encode, tín hiệu đầu vào sẽ được quy hoạch và nén qua những lớp convolution với PRreLU (biến thể của reLU). Tác giả chọn kiến trúc strided CNN vì nó được chứng minh là hiệu quả với mạng GAN qua một nghiên cứu trước đó. Tri thức được nén dưới dạng vector $c$, ta sẽ cộng $c$ với vector khởi tạo ngẫu nhiên $z$, sau đó tiến hành tác vụ ngược lại với strided CNN là fraction-strided CNN.
Mỗi tầng ở phần decoder sẽ có chức năng tương ứng với một tầng encoder đối xứng với nó.
Tác giả thực hiện phương pháp skip connections, kết nối các tầng encoder và decoder tương ứng với nhau. Sở dĩ làm được điều này là vì input và output của mạng G có cấu trúc ẩn giống nhau (đều có tính chất của chuỗi âm thanh). Khi thực hiện skip connection sẽ tránh được hiện tượng vanishing gradient và nghẽn cổ chai.


Loss function của mạng G tuân theo loss function của mô hình LSGAN. Tuy nhiên, dựa vào những nghiên cứu trước, tác giả đã cộng thêm vào hàm loss giá trị L1 norm giữa $G(z,\tilde{x})$ và $x$, giá trị L1 norm này được nhân với hệ số $\alpha$ tuỳ chọn.

## Reference
[^1]:[Sound signal cơ bản](https://tiensu.github.io/blog/67_audio_deep_learning_part_1/)
[^2]:[Biểu diển sound signal](https://viblo.asia/p/xu-ly-du-lieu-am-thanh-Qpmlezg95rd)
[^3]:[Voice Recognition Algorithms using Mel
Frequency Cepstral Coefficient (MFCC)](https://arxiv.org/ftp/arxiv/papers/1003/1003.4083.pdf)
[^4]:[Sơ lược về Mel Frequency Cepstral Coefficients (MFCCs)](https://viblo.asia/p/so-luoc-ve-mel-frequency-cepstral-coefficients-mfccs-1VgZv1m2KAw?fbclid=IwAR1eDXv3uQ6N0cx07oTS0QJEtL2_ItdopLQt1Bmddpk89-F2M2mIi9W8-iI)
[1,2,1,2]
A = k*sin(ax) + (h*sin(bx) + pi) +(j*sin(cx))
mfcc = [k,h,j]
real = [k,h,j]
imagine = [0,1,0]
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet