---
tags: Kubernete
---
# Kubernetes初階
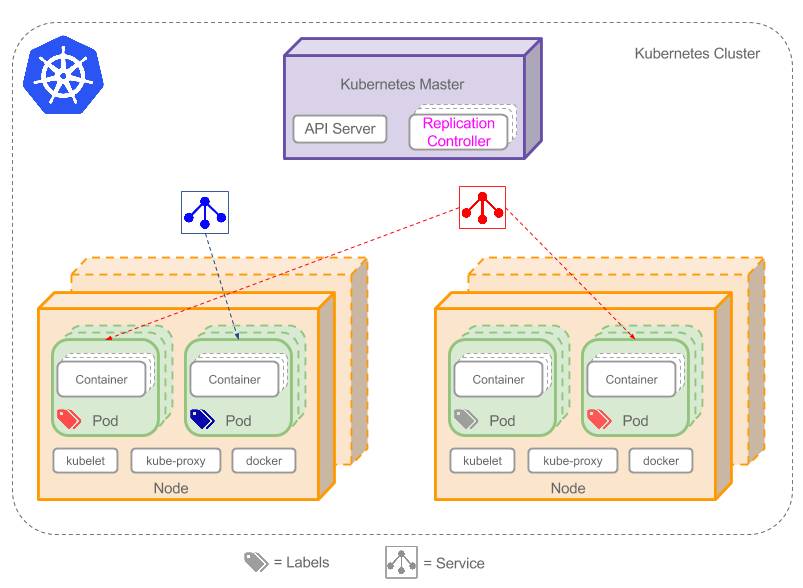
上圖可以看到如下組件,使用特別的圖標表示Service和Label:
* Pod
* Container
* Label
* Replication Controller
* Deployment
* Service
* Node
* Kubernetes Master
---
### Pod
Pod是在Kubernetes集群中運行部署應用或服務的最小單元,它是可以支持多容器的。Pod的設計理念是支持多個容器在一個Pod中共享網絡地址(Docker Bridge)和文件系統(Volume),可以通過進程間通信和文件共享這種簡單高效的方式組合完成服務。
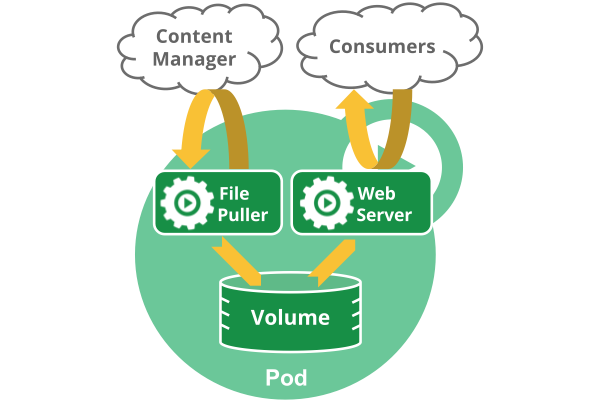
Pod是短暫的,不是持續性實體。可能會有這些問題:
* 如果Pod是短暫的,那麼我怎麼才能持久化容器數據使其能夠跨重啟而存在呢? Kubernetes支持Volume的概念,因此可以使用持久化的Volume類型。
* 是否手動創建Pod,如果想要創建同一個容器的多份拷貝,需要一個個分別創建出來麼?可以手動創建單個Pod,但是也可以使用Replication Controller使用Pod模板創建出多份拷貝。
* 如果Pod是短暫的,那麼重啟時IP地址可能會改變,那麼怎麼才能從前端容器正確可靠地指向後台容器呢?這時可以使用Service。
---
### Label
正如圖所示,一些Pod有Label。一個Label是attach到Pod的一對Key-Value,用來傳遞用戶定義的屬性。比如,你可能創建了一個"tier"和“app”標簽,通過Label(tier=frontend, app=myapp)來標記前端Pod容器,使用Label(tier=backend, app=myapp)標記後台Pod。然後可以使用Selectors選擇帶有特定Label的Pod,並且將Service或者Replication Controller應用到上面。
---
### Replication Controller(ReplicaSet)
是否手動創建Pod,如果想要創建同一個容器的多份拷貝,需要一個個分別創建出來麼,能否將Pods劃到邏輯組裡?
RC是Kubernetes集群中最早的保證Pod高可用的API對像。通過監控(Health Check)運行中的Pod來保證集群中運行指定數目的Pod副本。指定的數目可以是多個也可以是1個;少於指定數目,RC就會啟動運行新的Pod副本;多於指定數目,RC就會殺死多余的Pod副本。即使在指定數目為1的情況下,通過RC運行Pod也比直接運行Pod更明智,因為RC也可以發揮它高可用的能力,保證永遠有1個Pod在運行。RC是Kubernetes較早期的技術概念,只適用於長期伺服型的業務類型,比如控制小機器人提供高可用的Web服務。
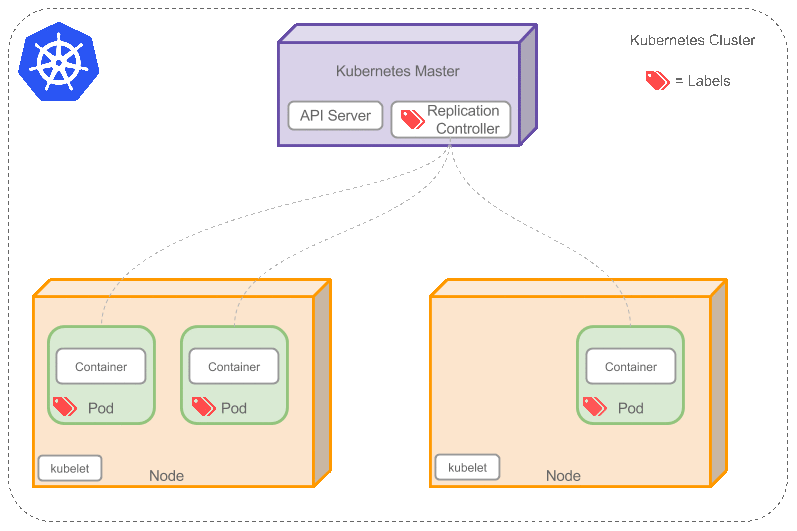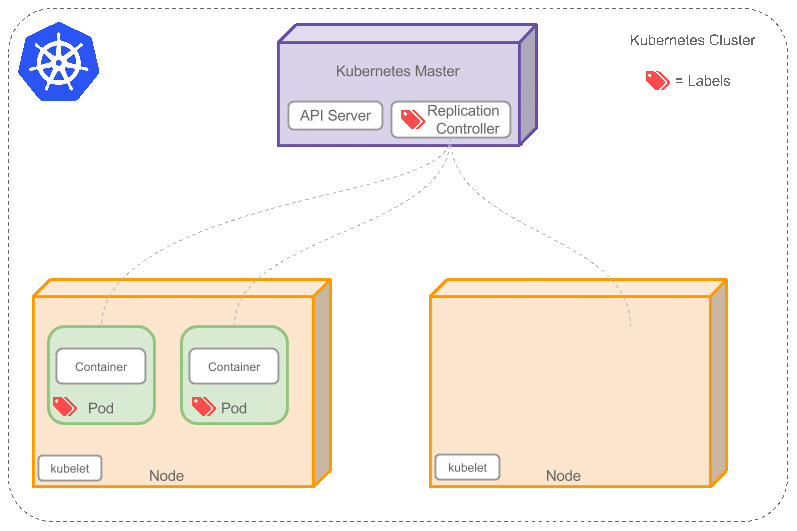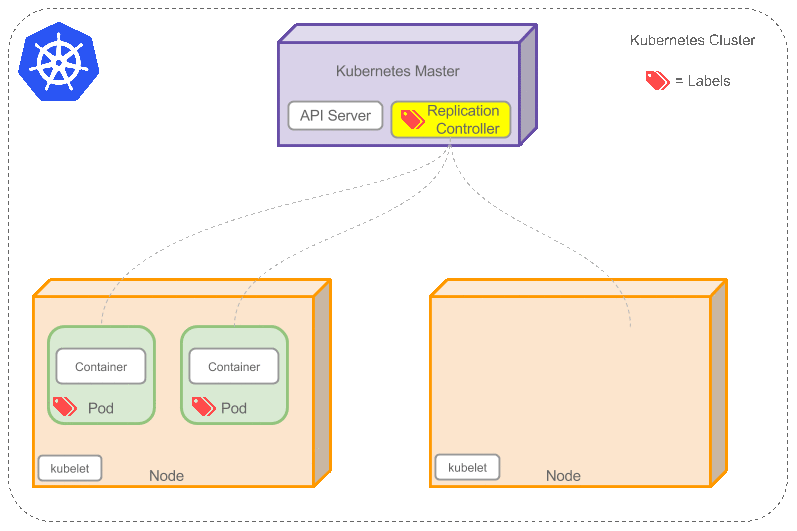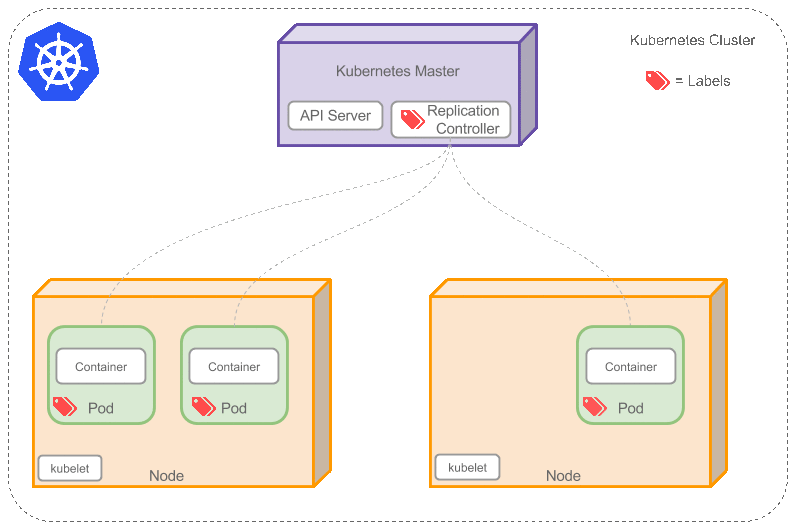
如果之前不響應的Pod恢復了,現在就有4個Pod了,那麼Replication Controller會將其中一個終止保持總數為3。如果在運行中將副本總數改為5,Replication Controller會立刻啟動2個新Pod(Auto Scaling),保證總數為5。還可以按照這樣的方式縮小Pod,這個特性在執行滾動升級(Rolling Update)或者是Blue-Green Deployment時很有用。
當創建Replication Controller時,需要指定兩個東西:
1. Pod模板:用來創建Pod副本的模板
2. Label:Replication Controller需要監控的Pod的標簽。
現在已經創建了Pod的一些副本,那麼在這些副本上如何均衡負載呢?我們需要的是Service。
在新版本的Kubernetes中建議使用ReplicaSet來取代ReplicationController。ReplicaSet跟ReplicationController沒有本質的不同,只是名字不一樣,並且ReplicaSet支持集合式的selector。
雖然ReplicaSet可以獨立使用,但一般還是建議使用 Deployment 來自動管理ReplicaSet,這樣就無需擔心跟其他機制的不兼容問題(比如ReplicaSet不支持rolling-update但Deployment支持)。
----
### Deployment
Deployment 為 Pod 和 ReplicaSet 提供了一個聲明式定義(declarative)方法,用來替代以前的ReplicationController 來方便的管理應用。典型的應用場景包括:
* 定義Deployment來創建Pod和ReplicaSet
* 滾動升級和回滾應用
* 擴容和縮容
* 暫停和繼續Deployment
Deployment表示用戶對Kubernetes集群的一次更新操作。Deployment是一個比RS應用模式更廣的API對像,可以是創建一個新的服務,更新一個新的服務,也可以是滾動升級一個服務。滾動升級一個服務,實際是創建一個新的RS,然後逐漸將新RS中副本數增加到理想狀態,將舊RS中的副本數減小到0的復合操作;這樣一個復合操作用一個RS是不太好描述的,所以用一個更通用的Deployment來描述。以Kubernetes的發展方向,未來對所有長期伺服型的的業務的管理,都會通過Deployment來管理。
---
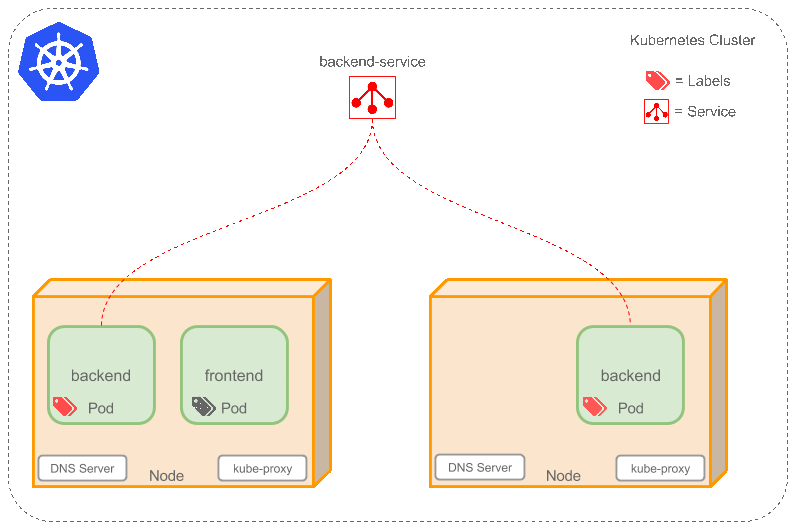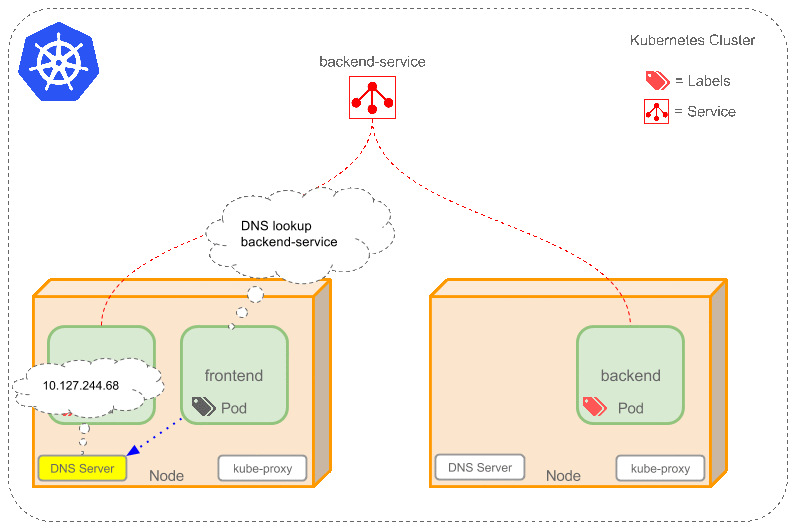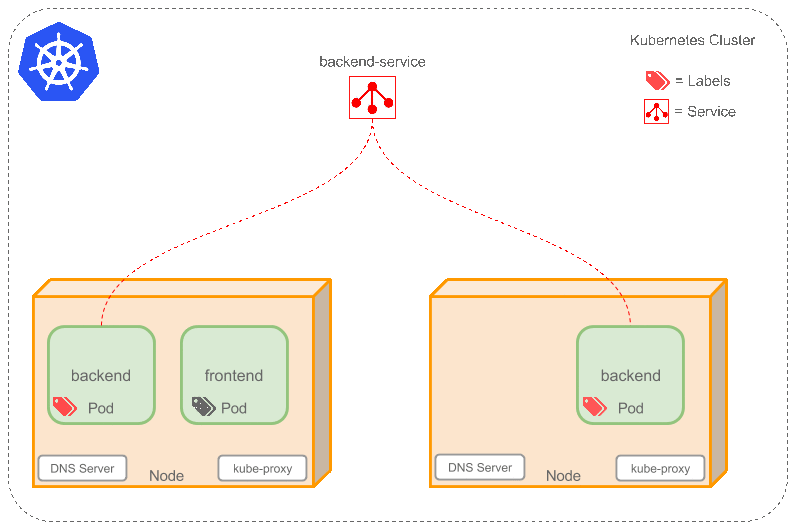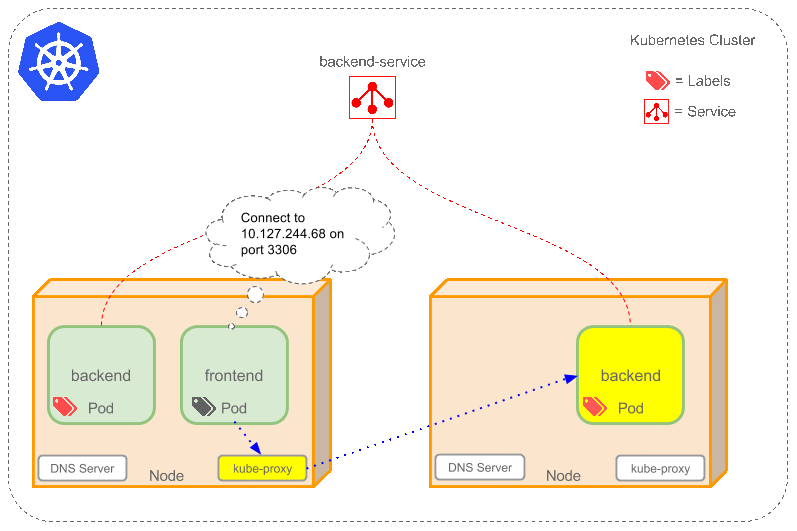
### Service
如果Pods是短暫的,那麼重啟時IP地址可能會改變,怎麼才能從前端容器正確可靠地指向後台容器呢?
Service是定義一系列Pod以及訪問這些Pod的一層抽像。Service通過Label找到Pod。因為Service是抽像的,所以在圖表裡通常看不到它們的存在,這也就讓這一概念更難以理解。
現在,假定有2個後台Pod,並且定義後台Service的名稱為‘backend-service’,lable選擇器為(tier=backend, app=myapp)。backend-service 的Service會完成如下兩件重要的事情:
* 會為Service創建一個本地集群的DNS入口,因此前端Pod只需要DNS查找主機名為 ‘backend-service’,就能夠解析出前端應用程序可用的IP地址。
* 現在前端已經得到了後台服務的IP地址,但是它應該訪問2個後台Pod的哪一個呢?Service在這2個後台Pod之間提供透明的負載均衡,會將請求分發給其中的任意一個(如下面的動畫所示)。通過每個Node上運行的代理(kube-proxy)完成。這裡有更多技術細節。
下述動畫展示了Service的功能。注意該圖作了很多簡化。如果不進入網絡配置,那麼達到透明的負載均衡目標所涉及的底層網絡和路由相對先進。
---
### Node
節點(上圖橘色方框)是物理或者虛擬機器,作為Kubernetes worker。每個節點都運行如下Kubernetes關鍵組件:
* Kubelet:是主節點代理。
* Kube-proxy:Service使用其將鏈接路由到Pod,如上文所述。
* Docker:Kubernetes使用的容器技術來創建容器。
----
### Master
集群擁有一個Kubernetes Master(紫色方框)。Kubernetes Master提供集群的獨特視角,並且擁有一系列組件,比如Kubernetes API Server。API Server提供可以用來和集群交互的REST端點。master節點包括用來創建和複製Pod的Replication Controller(RC)。
---
## Service Expose
* hostNetwork
* hostPort
* proxy-ClusterIP
* NodePort
* LoadBalancer
* Ingress
### hostNetwork: true
這是一種直接定義Pod網絡的方式。
如果在Pod中使用hostNotwork:true配置的話,在這種pod中運行的應用程序可以直接看到pod啟動的主機的網絡接口。在主機的所有網絡接口上都可以訪問到該應用程序。以下是使用主機網絡的pod的示例定義:
``` yaml
apiVersion: v1
kind: Pod
metadata:
name: influxdb
spec:
hostNetwork: true
containers:
name: influxdb
image: influxdb
```
注意每次啟動這個Pod的時候都可能被調度到不同的節點上,所有外部訪問Pod的IP也是變化的,而且調度Pod的時候還需要考慮是否與宿主機上的端口衝突,因此一般情況下除非您知道需要某個特定應用占用特定宿主機上的特定端口時才使用hostNetwork: true的方式。
這種Pod的網絡模式有一個用處就是可以將網絡插件包裝在Pod中然後部署在每個宿主機上,這樣該Pod就可以控制該宿主機上的所有網絡。
---
### hostPort
這是一種直接定義Pod網絡的方式。
hostPort是直接將容器的端口與所調度的節點上的端口路由,這樣用戶就可以通過宿主機的IP加上來訪問Pod了,如:
``` yaml
apiVersion: v1
kind: Pod
metadata:
name: influxdb
spec:
containers:
- name: influxdb
image: influxdb
ports:
- containerPort: 8086
hostPort: 8086
```
這樣做有個缺點,因為Pod重新調度的時候該Pod被調度到的宿主機可能會變動,這樣就變化了,用戶必須自己維護一個Pod與所在宿主機的對應關系。
這種網絡方式可以用來做 nginx ingress controller。外部流量都需要通過kubenretes node節點的80和443端口。
---
### ServiceType
通過外部(Kubernetes 集群外部)IP 地址暴露 `Service`。
Kubernetes `ServiceTypes` 允許指定一個需要的類型的 Service,默認是 `ClusterIP` 類型。
Type 的取值以及行為如下:
* `ClusterIP`:通過集群的內部 IP 暴露服務,選擇該值,服務只能夠在集群內部可以訪問,這也是默認的 `ServiceType`。
* `NodePort`:通過每個 Node 上的 IP 和靜態端口(`NodePort`)暴露服務。NodePort 服務會路由到 `ClusterIP` 服務,這個 `ClusterIP` 服務會自動創建。通過請求 ``<NodeIP>:<NodePort>``,可以從集群的外部訪問一個 `NodePort` 服務。
* `LoadBalancer`:使用雲提供商的負載均衡器,可以向外部暴露服務。外部的負載均衡器可以路由到 `NodePort` 服務和 `ClusterIP` 服務。
* `ExternalName`:通過返回 `CNAME` 和它的值,可以將服務映射到 `externalName` 字段的內容(例如, `foo.bar.example.com`)。 沒有任何類型代理被創建,這只有 Kubernetes 1.7 或更高版本的 `kube-dns` 才支持。
### ClusterIP
ClusterIP 服務是 Kubernetes 的默認服務。它給你一個集群內的服務,集群內的其它應用都可以訪問該服務。集群外部無法訪問它。
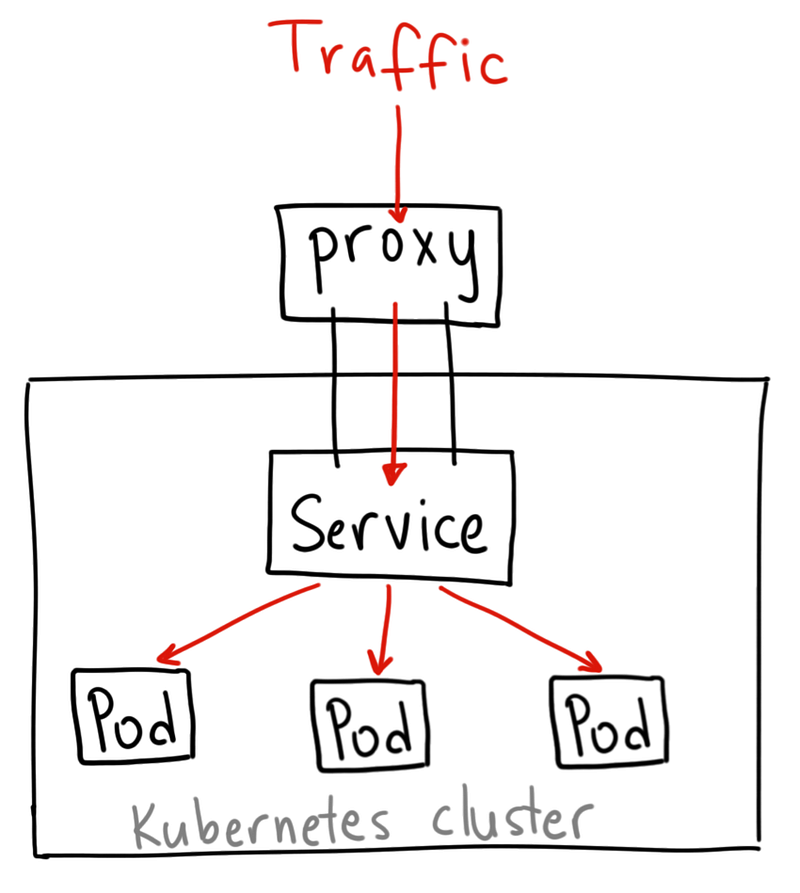
如果 從Internet 沒法訪問 ClusterIP 服務,那麼我們為什麼要討論它呢?那是因為我們可以通過 Kubernetes 的 proxy(Kube-proxy) 模式來訪問該服務!
有一些場景下,你得使用 Kubernetes 的 proxy 模式來訪問你的服務:
由於某些原因,你需要調試你的服務,或者需要直接通過筆記本電腦去訪問它們。
容許內部通信,展示內部儀表盤等。
這種方式要求我們運行 kubectl 作為一個未認證的用戶,因此我們不能用這種方式把服務暴露到 internet 或者在生產環境使用。
----
### NodePort
NodePort 服務是引導外部流量到你的服務的最原始方式。NodePort,正如這個名字所示,在所有節點(虛擬機)上開放一個特定端口,任何發送到該端口的流量都被轉發到對應服務
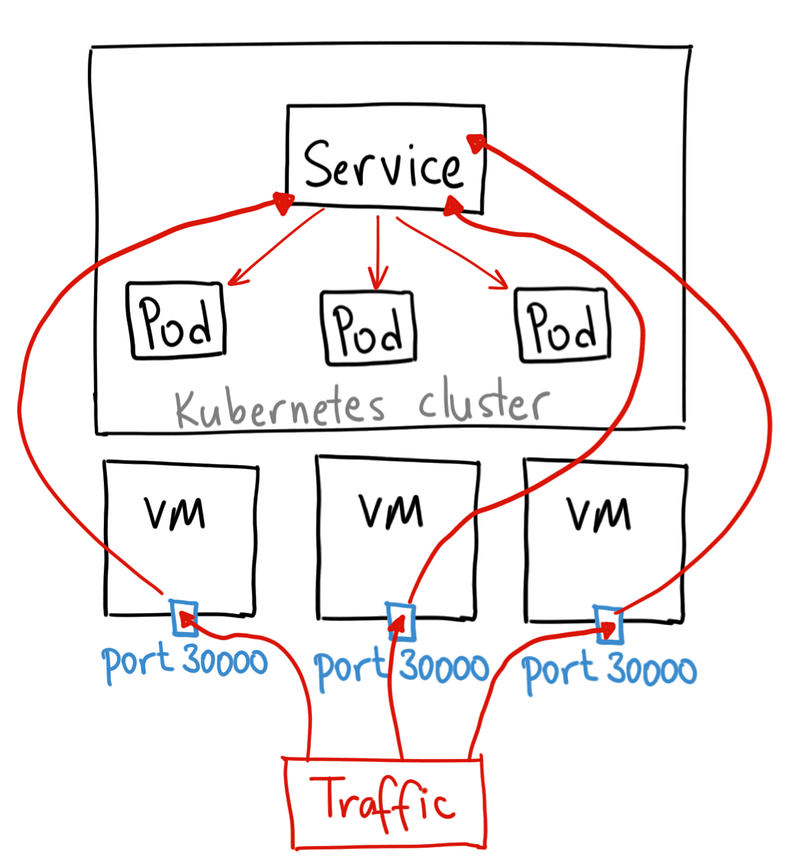
NodePort 服務主要有兩點區別於普通的“ClusterIP”服務。第一,它的類型是“NodePort”。有一個額外的端口,稱為 nodePort,它指定節點上開放的端口值。如果你不指定這個端口,系統將選擇一個隨機端口。大多數時候我們應該讓 Kubernetes 來選擇端口,用戶自己來選擇可用端口代價太大。
這種方法有許多缺點:
* 每個端口只能是一種服務
* 端口範圍只能是 30000-32767
* 如果節點/VM 的 IP 地址發生變化,你需要能處理這種情況。
基於以上原因,我不建議在生產環境上用這種方式暴露服務。如果你運行的服務不要求一直可用,或者對成本比較敏感,你可以使用這種方法。
---
### LoadBalancer
LoadBalancer 服務是暴露服務到 internet 的標准方式。在 GKE 上,這種方式會啟動一個 Network Load Balancer,它將給你一個單獨的IP 地址,轉發所有流量到你的服務。需搭配雲端平台提供商的服務才可使用。
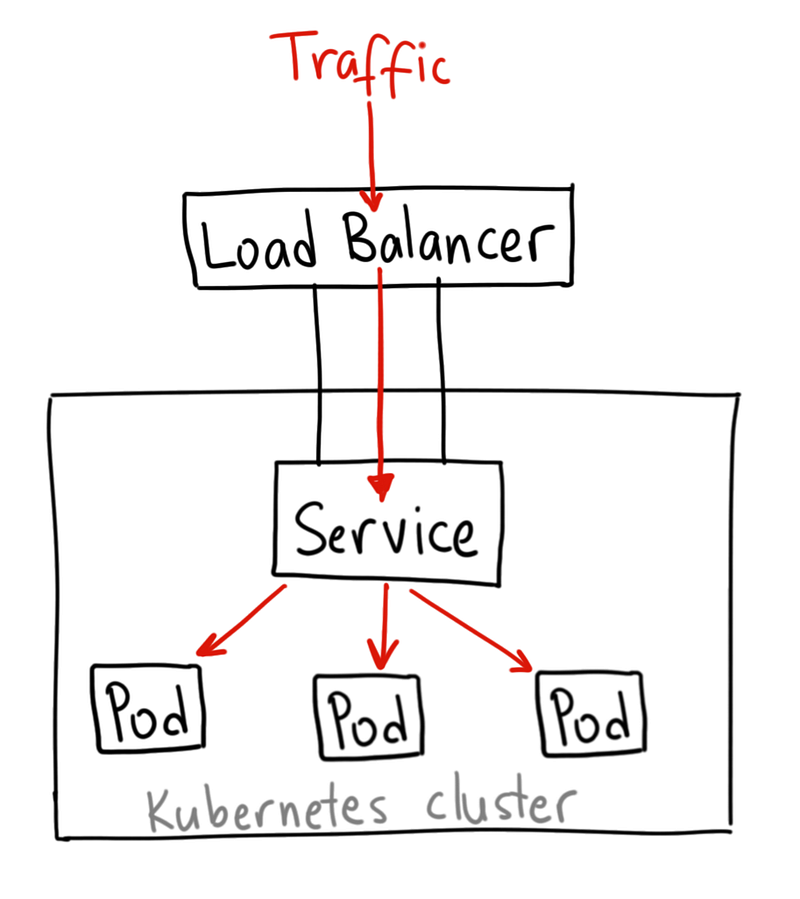
如果你想要直接暴露服務,這就是默認方式。所有通往你指定的端口的流量都會被轉發到對應的服務。它沒有過濾條件,沒有路由等。這意味著你幾乎可以發送任何種類的流量到該服務,像 HTTP,TCP,UDP,Websocket,gRPC 或其它任意種類。
這個方式的最大缺點是每一個用 LoadBalancer 暴露的服務都會有它自己的 IP 地址,每個用到的 LoadBalancer 都需要付費,這將是非常昂貴的。
----
### Ingress
有別於以上所有例子,Ingress 事實上不是一種服務類型。相反,它處於多個服務的前端,扮演著“API GateWay”或者集群入口的角色。
你可以用 Ingress 來做許多不同的事情,各種不同類型的 Ingress 控制器也有不同的能力。
GKE 上的默認 ingress 控制器是啟動一個 HTTP(S) Load Balancer。它允許你基於路徑或者子域名來路由流量到後端服務。例如,你可以將任何發往域名 foo.yourdomain.com 的流量轉到 foo 服務,將路徑 yourdomain.com/bar/path 的流量轉到 bar 服務。
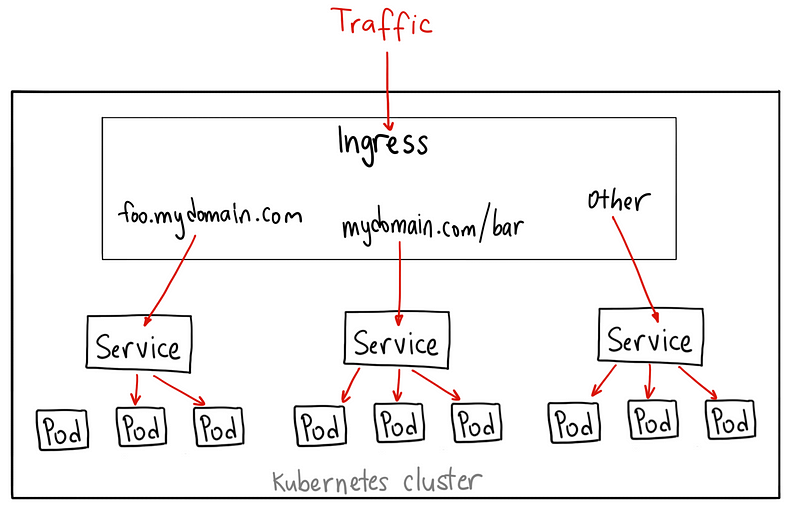
Ingress 可能是暴露服務的最強大方式,但同時也是最復雜的。Ingress 控制器有各種類型,包括 Google Cloud Load Balancer,Nginx,Contour,Istio,等等。它還有各種插件,比如 cert-manager,它可以為你的服務自動提供 SSL 證書。
如果你想要使用同一個 IP 暴露多個服務,這些服務都是使用相同的七層協議(典型如 HTTP),那麼Ingress 就是最有用的。如果你使用本地的 GCP 集成,你只需要為一個負載均衡器付費,且由於 Ingress是“智能”的,你還可以獲取各種開箱即用的特性(比如 SSL,認證,路由,等等)。
---
### Volume (Kubernetes Volume != Docker Volume)
Docker 中也有一個 volume 的概念,盡管它稍微寬松一些,管理也很少。在 Docker 中,卷就像是磁盤或是另一個容器中的一個目錄。它的生命周期不受管理,直到最近才有了 local-disk-backed 卷。Docker 現在提供了卷驅動程序,但是功能還非常有限(例如Docker1.7只允許每個容器使用一個卷驅動,並且無法給卷傳遞參數)。
另一方面,Kubernetes 中的卷有明確的壽命——與封裝它的 Pod 相同。所以,卷的生命比 Pod 中的所有容器都長,當這個容器重啟時數據仍然得以保存。當然,當 Pod 不再存在時,卷也將不復存在。也許更重要的是,Kubernetes 支持多種類型的卷,Pod 可以同時使用任意數量的卷。
卷的核心是目錄,可能還包含了一些數據,可以通過 pod 中的容器來訪問。該目錄是如何形成的、支持該目錄的介質以及其內容取決於所使用的特定卷類型。
要使用卷,需要為 pod 指定為卷(spec.volumes 字段)以及將它掛載到容器的位置(spec.containers.volumeMounts 字段)。
容器中的進程看到的是由其 Docker 鏡像和卷組成的文件系統視圖。Docker 鏡像位於文件系統層次結構的根目錄,任何卷都被掛載在鏡像的指定路徑中。卷無法掛載到其他卷上或與其他卷有硬連接。Pod 中的每個容器都必須獨立指定每個卷的掛載位置。
Kubernetes 支持以下類型Volume:
* awsElasticBlockStore
* azureDisk
* azureFile
* cephfs
* csi
* downwardAPI
* emptyDir
* fc (fibre channel)
* flocker
* gcePersistentDisk
* gitRepo
* glusterfs
* hostPath
* iscsi
* local
* nfs
* persistentVolumeClaim
* projected
* portworxVolume
* quobyte
* rbd
* scaleIO
* secret
* storageos
* vsphereVolume
---
### emptyDir
當 Pod 被分配給節點時,首先創建 emptyDir Volume,並且只要該 Pod 在該節點上運行,該Volume就會存在。正如Volume的名字所述,它最初是空的。Pod 中的容器可以讀取和寫入 emptyDir 中的相同文件,盡管該Volume可以掛載到每個容器中的相同或不同路徑上。當出於任何原因從節點中刪除 Pod 時,emptyDir 中的數據將被永久刪除。
注意:容器崩潰不會從節點中移除 pod,因此 emptyDir 中的數據在容器崩潰時是安全的。
emptyDir 的用法有:
* 暫存空間,例如用於基於磁盤的合並排序
* 用作長時間計算崩潰恢復時的檢查點
* Web服務器容器提供數據時,保存內容管理器容器提取的文件
---
### hostPath
hostPath 將主機節點(Node)的文件系統中的文件或目錄掛載到集群中。該功能大多數 Pod 都用不到,但它為某些應用程序提供了一個強大的解決方法。
例如,hostPath 的用途如下:
* 運行需要訪問 Docker 內部的容器;使用 /var/lib/docker 的 hostPath
* 在容器中運行 cAdvisor;使用 /dev/cgroups 的 hostPath
* 允許 pod 指定給定的 hostPath 是否應該在 pod 運行之前存在,是否應該創建,以及它應該以什麼形式存在
除了所需的 path 屬性之外,用戶還可以為 hostPath 指定 type。
使用這種類型是請注意,因為:
* 由於每個節點上的文件都不同,具有相同配置(例如從 podTemplate 創建的)的 pod 在不同節點上的行為可能會有所不同
* 當 Kubernetes 按照計劃添加資源感知調度時,將無法考慮 hostPath 使用的資源
* 在底層主機上創建的文件或目錄只能由 root 寫入。您需要在特權容器中以 root 身份運行進程,或修改主機上的文件權限以便寫入 hostPath
---
### nfs
nfs 允許將現有的 NFS(網絡文件系統)共享掛載到您的容器中。不像 emptyDir,當刪除 Pod 時,nfs 的內容被保留,nfs僅僅是被卸載。這意味著 NFS 可以預填充數據,並且可以在 pod 之間“切換”數據。 NFS可以被多個寫入者同時掛載。
重要提示:您必須先擁有自己的 NFS 服務器才能使用它,然後才能使用它。