# The DevOps Handbook


* Miro: [[讀書交流] The DevOps Handbook, Online Whiteboard for Visual Collaboration](https://miro.com/app/board/uXjVM0-wmN0=/)
### 進度
PART I 三步工作法 & PART II 從何處開始
```mermaid
gantt
dateFormat YYYY-MM-DD
section Part I
Ch. 01 ~ 02 :done, 2023-08-05, 1w
Ch. 03 ~ 04 :done, 2023-08-12, 1w
section Part II
Ch. 05 ~ 06 :done, 2023-08-19, 1w
Ch. 07 ~ 08 :done, 2023-08-26, 1w
```
PART III 第一步工作法:暢流的技術實踐
```mermaid
gantt
dateFormat YYYY-MM-DD
section Part III
Ch. 09 ~ 11 :done, 2023-09-02, 1w
Ch. 12 ~ 13 :done, 2023-09-09, 2w
```
PART IV 第二步工作法:回饋的技術實踐
```mermaid
gantt
dateFormat YYYY-MM-DD
section Part IV
Ch. 14 ~ 16 :done, 2023-09-30, 1w
Ch. 17 ~ 18 :active, 2023-10-07, 1w
```
PART V 第三步工作法:持續學習與實驗的具體實踐
```mermaid
gantt
dateFormat YYYY-MM-DD
section Part IV
Ch. 19 ~ 21 :active, 2023-10-15, 1w
```
PART VI 整合資訊安全、變更管理和合規性的技術實踐
```mermaid
gantt
dateFormat YYYY-MM-DD
section Part IV
Ch. 22 ~ 23 : 2023-10-22, 1w
```
* 2023-08-05
- Chapter 1|敏捷、持續交付與「三步工作法」
- Chapter 2|第一步:暢流原則
* 2018-08-12
- Chapter 3|第二步:回饋原則
- Chapter 4|第三步:持續學習與實驗原則
* 2023-08-19
- Chapter 5|選擇適當價值流作為切入點
- Chapter 6|理解、可視化和運用價值流
* 2023-08-26
- Chapter 7|參考康威法則設計組織架構
- Chapter 8|將營運融入日常開發工作
* 2023-09-02
- Chapter 9|奠定部署管線的基礎
- Chapter 10|實現快速可靠的自動化測試
- Chapter 11|啟動和實踐持續整合
* 2023-09-09
- Chapter 12|自動化並降低發佈風險
- Chapter 13|降低發佈風險的架構
* 2023-09-30
- Chapter 14|建立能發現並解決問題的遙測系統
- Chapter 15|分析遙測資料以便預測故障和實現目標
- Chapter 16|啟動回饋機制,安全地部署程式碼
* 2023-10-07
- Chapter 17| 將「假設驅動開發」和「A / B 測試」
- Chapter 18|建立評閱和協作流程,提升現有工作品質
* 2023-10-15
- Chapter 19|將學習融入日常工作
- Chapter 20|將局部經驗轉化為全局改善
- Chapter 21|為組織學習和改善活動預留時間
* 2023-10-15
- Chapter 19|將學習融入日常工作
- Chapter 20|將局部經驗轉化為全局改善
- Chapter 21|為組織學習和改善活動預留時間
* 2023-10-22 (待決定是否要拆分)
- Chapter 22|將資訊安全納入每個人的日常工作
- Chapter 23|保護部署管線
---
[TOC]
# 疑問區
## 疑問:標題 (範本)
問題闡述
### 討論
> 討論內容
> [name=發表人]
### 小結
已達成與會者共識的結論簡述
### 討論
> 討論內容
> [name=發表人]
### 小結
已達成與會者共識的結論簡述
> 他們開發了一個儀表板,從三個不同的角度檢視每一次版本發布:系統層面(產品的狀態)、價值流(上下游的依賴性等),以及環境(平台、事件等)。透過這 三個檢視角度,儀表板會給出「發布/不可發布」的明確建議。18
> 在任何東西被發布到生產環境之前,這個檢查已經自動完成。如果一切正常,它 就能進入生產環境。如果不行,這個發布則會停止,負責團隊就會檢查儀表板, 查看問題出在哪裡。問題可能是由於某個特定活動,例如在 Adidas 的主打產品 發布日不允許推出任何變更,也可能是團隊沒有更多的錯誤預算等等。
## 疑問:將生產遙測融入日常生活工作的實踐
這組問題主要是針對第 14 章的內容去深入討論:
> 為了讓所有人都能在日常工作中發現並解決問題,我們需要讓他們在日常工作中可以輕鬆地建立、展示和分析度量指標。建立必要的基礎設施和資料庫,讓任何開發或營運人員都能輕易地針對任何功能建立遙測。理想情況下,建立一個新的指標並顯示在儀表板上,讓價值流中的所有人都可以看到它,應該像編寫一行程式碼那樣簡單。
> StatsD 可以用一行程式碼 (Ruby、Perl、Python、Java 和其他語言) 產生計時器和計數器,經常結合 Graphite 或Grafana,將指標資料呈現在圖形和儀表板上。
>
> 圖 14.3 顯示了用一行程式碼建立的使用者登入事件 (在這個例子中,那一行 PHP程式碼是:StatsD::increment("login.successes"))。圖中顯示了每分 鐘登入成功和失敗的次數,圖上的垂直線表示一次生產部署。
指標會需要資料庫收攏 (通常是時間序列資料庫),如果要讓開發或營運人員能輕易去收攏指標,是否代表會有一組資料庫/服務,是每一個人員都有權限去存取,去塞入他們想要監測的指標?
假設每位人員都可以存取資料庫服務去塞入想要監測的指標,那麼又如何決定指標的合理性?還是只要產品/開發/維運團隊需要瞭解某個功能/應用/元件的狀態,就可以自行進行指標採樣塞入資料庫中?
在個人當前所在的團隊,應用面的指標,是透過 OTel SDK,送到 OTel Collector 做整理處理後,再送到對應的資料庫服務存儲,使用 Grafana 做視覺化的檢索 (如下圖所示)

## 疑問:異常檢測技術
第 15 章異常檢測技術提到:
> 除此之外還有一些更獨特的篩選技法,諸如快速傅立葉轉換和 Kolmogorov-Smirnov 檢驗 (可見於 Graphite 和 Grafana),其中前者廣泛應用於圖像處理,後者常被用來分析週期性/季節性度量資料的相似性或差異性。
然而個人實際翻閱文件,不論是 Graphite、Prometheus 或是 Grafana,根本沒有提供現成的 FFT 或是 K-S Test 方案,個人認為這些實踐都需要透過額外的應用去分析處理。然而也的確如同書中所提到,現實生活中的指標並非呈現常態分佈,不能僅單純用標準差來去設定告警規則,也許團隊中會需要資料工程師?
> Rally 軟體公司的開發和營運 VP Tarun Reddy,積極倡導在營運工積極運用資料統計。他說:
>> 為了提高服務品質,我們將所有生產指標輸入到統計分析軟體 Tableau 中。我們甚至僱用一名受過統計學訓練的營運工程師,請他編寫 R 語言程式碼 (另一個統計軟體包)。這名工程師有大量的待辦事項,大多是來自公司其他團隊的需求,他們希望在影響客戶的大型事故發生之前,儘早找到那些差異。


[Quick Tour of Pivotal Labs HD - YouTube](https://youtu.be/AEBUvTt-zas?si=RoqPfSevjTmhUgPa&t=181)
# 待整理
> 維護者過於懶散,還沒花時間整理
## 疑問:如何實踐 TBD 與 Feature Toggles
不論是在 The DevOps Handbook 或是 The DevOps Days Taipei 2023 的議程中,個人看到 Trunk-Based Development (TBD) 以及 Feature Toogles 這兩項是建議的做法。然而個人好奇在實務上開發團隊又是如何去實踐的?是否有導入相關的框架或制定規則,或者說如果要去實踐你會如何去規劃設計?這個疑問單純想聽聽大家的想法
### 討論
> 參考資料:
> - [SAIKURON 13.Ned: 筆記:TBD是三小?---What is Trunk Based Development?](https://nedwu13.blogspot.com/2014/01/tbd-what-is-trunk-based-development.html)
> - [What is Trunk-Based Development?](https://paulhammant.com/2013/04/05/what-is-trunk-based-development/)
>
> [name=Michael D]
> 引用 [Trunk Based Development](https://trunkbaseddevelopment.com/)
>> Trunk-Based Development needs you to have small stories/tasks. Optimal is you starting work on a change, should only be a matter of hours before completing and pushing it forward for code review. Longer than a couple of days, and there is going to be pressure to group a bunch of developers on a non-trunk branch and merge back later. Or worse, have developers make branches/forks from your in-progress branch. Or worse still, take intermediate merges from your branch, despite your change being incomplete.
>>
>> **Branch by Abstraction**
>>
>> For simplicity’s sake, let us say there is code that is ‘to be replaced’, code ‘to be introduced’.
>>
>>
>> 1. Introduce an abstraction around the code that is to be replaced, and commit that for all to see. If needed, this can take multiple commits. None of those are allowed to break the build, and all of them could be pushed to the shared repository in order, and as done.
>> 2. Write a second implementation of the abstraction for the to-be-introduced code, and commit that, but maybe as ‘turned off’ within the trunk so that other developers are not depending on it yet. If needed, this can take multiple commits as above. The abstraction from #1 may also be occasionally tweaked, but must follow the same rule - do not break the build.
>> 3. Flip the software ‘off’ switch to ‘on’ for the rest of the team, and commit/push that.
>> 4. Remove the to-be-replaced implementation
>> 5. Remove the abstraction
>>
>> Hopefully, your team uses an IDE that can perform complex refactorings on sets on checkouts, in a way that running the build after each is an uneventful validation of the refactorings.
>
> [name=Michael D]
> Atlassian (Jira 母公司) 有一篇 [Trunk-based Development | Atlassian](https://www.atlassian.com/continuous-delivery/continuous-integration/trunk-based-development) 的介紹文章,包含 TBD 最佳實踐的建議做法,個人以自己的理解重寫詮釋:
>#### Trunk-based development best practices
> 1. Develop in small batches: 維持小 PR 提交審查量,降低審查同仁的認知負擔
> 2. Feature flags: 避免長期的 feature branch,鼓勵將新功能小批量提交合併到 main branch 這中,又不會影響應用的部署發佈
> 3. Implement comprehensive automated testing: 於不同階段運行不同類型的自動化測試,譬如 PR 整合階段運行短時間的單元測試、整合測試,部署階段運行長時間的完整 E2E 測試。
> 4. Perform asynchronous code reviews: 在 PR 發起時,觸發自動化測試,除了功能性測試也可以含是否符合規範 (Lint),降低審查同仁的認知負擔,專注檢視程式碼的優化
> 5. Have three or fewer active branches in the application's code repository: 定期檢視 branch 將不需要的移除 (如同 feature toggles 也需要定期檢視)
> 6. Merge branches to the trunk at least once a day: 持續整合、持續部署,維持 main branch 隨時在可部署的狀態
> 7. Reduced number of code freezes and integration phases:週五/連續假日/大型活動前夕禁止部署是否可以視為一種部署凍結? (考量到潛在風險而暫緩部署)
> [Thoughts💡 Deploy on Fridays?關於週五部署這件事 | by Jayden Lin | 程式猿吃香蕉 | Medium](https://medium.com/%E7%A8%8B%E5%BC%8F%E7%8C%BF%E5%90%83%E9%A6%99%E8%95%89/deploy-on-fridays-%E9%97%9C%E6%96%BC%E9%80%B1%E4%BA%94%E9%83%A8%E7%BD%B2%E9%80%99%E4%BB%B6%E4%BA%8B-39c0bec38226)
> 8. Build fast and execute immediately: 優化建置與測試的執行時間,譬如對 package 使用 cache、檢視測試案例移除已不需要的項目
>
> [name=Kehao]
> Feature Branching 似乎通常指的是長生命週期,開發完成後才合併為 main branch 的分支策略。
> 
> 因此 TBD + Feature Flags 追求的就是儘快合併至 main branch
> 
> —— 圖片來源: [Git Branching Strategies vs. Trunk-Based Development - LaunchDarkly | LaunchDarkly](https://launchdarkly.com/blog/git-branching-strategies-vs-trunk-based-development/)
>
> [name=kehao]
### 小結
已達成與會者共識的結論簡述
## 疑問:測試涵蓋率的價值?
### 91 對測試覆蓋率的看法
> 重點在於「相對趨勢 > 絕對數字」,與其去訂一個覆蓋率 > 20 %, 還不如定義,每次 build 之後,coverage 只能比原本的高,這意義是對自己這次簽入的程式碼負責。(無須對前人的 legacy code 負責)
>
> 接著鼓勵大家頻繁簽入,整體程式碼的覆蓋率就會不斷提昇。
這就是 Uncle Bob 所提的童子軍法則:讓離開時的營地比原本更乾淨。
>
> Code Coverage 的比例向來不是重點,有數字時大家就只會迷思在數字,這是 KPI 思維,不是 OKR。
> —— [[Comments] 測試覆蓋率與 TDD 的正確心態 | In 91 - 點部落](https://dotblogs.com.tw/hatelove/2017/05/30/my-opinions-of-code-coverage-and-tdd)
>> 91大對於測試涵蓋率的建議:
>> - 至少要大於 0%,代表該產品存在著相關的自動測試
>> ※ 代表環境都建置好了,就差隨手寫寫 Unit Test
>> - 檢視測試案例是否包含最主要的情境,以及曾經出錯的情境
>> - 檢視是否有不必要的產品程式碼或缺少對應的測試案例
>> - 相對趨勢大於絕對數字
>> ※ 以前的包袱就算了,至少之後要更好吧~!
>
> 專注在**有價值**的測試,而不是為了衝 coverage 而寫了許多低意義的 assert。
>
> —— [[91大的TDD課程心得] 測試覆蓋率的價值 | Mystic Pieces - 點部落](https://dotblogs.com.tw/Mystic_Pieces/2017/06/11/004537)
### Google Blog 上的指引
> We should not be obsessing on how to get from 90% code coverage to 95%. The gains of increasing code coverage beyond a certain point are logarithmic. But we should be taking concrete steps to get from 30% to 70% and always making sure new code meets our desired threshold.
>
> —— [Google Testing Blog: Code Coverage Best Practices](https://testing.googleblog.com/2020/08/code-coverage-best-practices.html)
> 
> 
> 
>
> —— [Test coverage at Google - Google 簡報](https://docs.google.com/presentation/d/1god5fDDd1aP6PwhPodOnAZSPpD80lqYDrHhuhyD7Tvg/edit#slide=id.g3f5c82004_8636)
## 疑問:對於職能型組織的功能團隊,若要減少團隊內穀倉效應只能要求團隊要有學習心態成為通才?
康威定律中的團隊邊界,是否可視為依據溝通成本來劃分?
個人所在的組織為職能型組織,功能團隊採取 component team 架構,而非 cross-functional team,分為前端、後端與維運人員。個人認為通才對於一般公司人才難尋,團隊成員也並不是那麼想要成為通才 (也許是想把心力精通既有的領域加深護城河),要如何要求每一位同仁會需要對所業務邏輯、技術架構有基本的理解嗎 (個人的確也觀察到不是所有同仁都瞭解自己的工作與價值流目標的關聯)?
或者其實應該將單一系統/微服務視為一個整體,所謂的前端、後端、資料庫都是再去切分的,如果同仁專注,單一功能團隊的成員如果僅侷限於某個部分反而是劃地自限?然而要怎麼推動團隊內的成員都有學習心態成為通才?
### 討論
>> 與組織結構相配,每個團隊獨立負責某些服務,獲得更高的生產力
>> —— [微服務架構關鍵要素. 良好的架構讓企業走在數位轉型之旅的正確方向、並且走得輕鬆… | by Kenny Chen | Brobridge - 寬橋微服務](https://medium.brobridge.com/%E5%BE%AE%E6%9C%8D%E5%8B%99%E6%9E%B6%E6%A7%8B%E9%97%9C%E9%8D%B5%E8%A6%81%E7%B4%A0-8e6632fc581c)
>
> [name=Kehao]
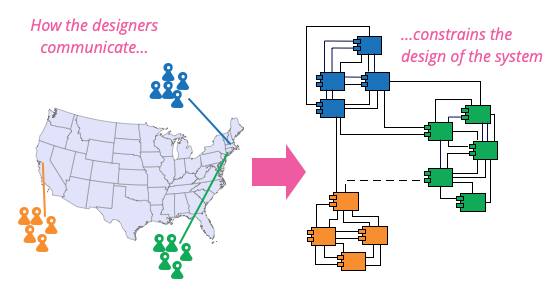
>> The first step in dealing with Conway's Law is know not to fight it. I still remember one sharp technical leader, who was just made the architect of a large new project that consisted of six teams in different cities all over the world.
“I made my first architectural decision” he told me. “There are going to be six major subsystems. I have no idea what they are going to be, but there are going to be six of them.”
>> 
>
>> Domain-Driven Design plays a role with Conway's Law to help define organization structures, since a key part of DDD is to identify **BoundedContexts**.
>> —— [ConwaysLaw - Martin Fowler](https://martinfowler.com/bliki/ConwaysLaw.html)
>
> [name=Kehao]
> 康威定律強調的是組織結構將影響所開發的系統架構,其中的團隊邊界的確可以根據溝通成本來劃分。在你的情況下,將前端、後端和維護人員分為不同團隊可以是有效的,但也可能導致溝通和協同工作的問題。
>
> 關於邁向通才的問題,雖然通才在某些情況下可以提供價值,但並不是每一個團隊或組織都需要或適合通才。要求每一位員工都有基本的業務邏輯和技術架構理解是合理的,這可以幫助他們看到他們工作與整體目標的關聯。
>
> 你提及的將系統或微服務視為一個整體的想法也有其優點,這樣可以讓團隊專注於創建和維護一個聯合的、對終端用戶有價值的產品或服務。
>
> 在推動員工向通才發展方面,這需要創建一個支持和鼓勵學習的文化,提供必要的培訓資源和機會、公認和獎勵學習以及多領域的成就等。這也可以包括提供時間和空間讓人們嘗試新的角色和責任、實驗和學習新的技能。
>
> [name=ChatGPT4]
> 康威定律中的團隊邊界,通常是由團隊成員之間的溝通結構來決定的。在職能型組織中,功能團隊採取 component team 架構,而非 cross-functional team,分為前端、後端與維運人員。這種架構的優點是每個人都可以專注於自己的領域,但缺點是可能會出現溝通成本高的問題。如果您想要讓每位同仁對所業務邏輯、技術架構有基本的理解,您可以考慮以下幾點:
>
> 1. 建立一個知識分享平台,讓每位同仁可以分享自己的知識和經驗。
> 2. 定期舉辦內部培訓課程,讓每位同仁都有機會學習其他領域的知識。
> 3. 鼓勵每位同仁參與跨部門項目,這樣他們就可以更好地了解整個產品開發過程中不同部門之間的關係。
>
> 另外,您也提到了單一系統/微服務視為一個整體的想法。這種想法在實踐中是可行的,因為它可以幫助團隊成員更好地了解整個系統。但是,這種方法也有一些缺點。例如,如果某個功能需要跨多個微服務實現,那麼這種方法可能會導致溝通成本增加。因此,在實踐中需要根據具體情況來決定是否使用這種方法。
>
> 最後,關於如何推動團隊內的成員都有學習心態成為通才,我認為最重要的是建立一個開放、支持學習和分享的文化。只有在這種文化下,每位同仁才會願意學習新知識和技能。
>
> [name=Bing Chat]
> 是的,康威定律中的團隊邊界,可視為依據溝通成本來劃分。在職能型組織中,團隊邊界通常會依據技術或職能領域來劃分,例如前端、後端、維運等。這種劃分方式會導致團隊成員之間的溝通成本較高,因為他們需要跨越不同的技術領域或職能領域來溝通,這會增加溝通的複雜性和誤解的可能性。
>
> 為了降低團隊之間的溝通成本,組織可以採用跨職能團隊的架構。在跨職能團隊中,團隊成員來自不同的技術或職能領域,他們需要在團隊中共同合作來完成工作。這種劃分方式可以有效地降低團隊之間的溝通成本,並提高團隊的協作效率。
>
> 對於您的問題,要如何要求每一位同仁會需要對所業務邏輯、技術架構有基本的理解,可以從以下幾個方面來考慮:
> * 提供員工培訓和教育機會,幫助他們了解業務邏輯和技術架構。
> * 建立團隊文化,鼓勵員工分享知識和經驗。
> * 創造機會讓員工參與跨團隊合作,了解不同團隊的工作。
>
> 如果單一系統/微服務視為一個整體,所謂的前端、後端、資料庫都是再去切分的,這將有助於減少團隊之間的溝通成本。因為團隊成員都需要對整個系統/微服務有基本的了解,才能有效地溝通和協作。
>
> 要推動團隊內的成員都有學習心態成為通才,可以從以下幾個方面來考慮:
> * 建立團隊目標和激勵機制,讓員工了解他們的貢獻對團隊的重要性。
> * 提供員工成長和發展的機會,幫助他們提升技能和能力。
> * 營造良好的工作環境,讓員工感到被重視和認可。
>
> 總而言之,康威定律指出,組織的溝通結構會影響系統的設計。因此,組織需要根據具體情況來選擇合適的團隊架構,以降低團隊之間的溝通成本,提高團隊的協作效率。
>
> [name=Google Bard]
> 是否團隊主管需要瞭解各個成員的職涯規劃,來協助他們達成目標累積「職涯資本」,進而讓同仁有動力建立學習心態?
>
> [name=Kehao]
> 是否為公司沒有明確的獎勵制度或是績效改善計畫 (Performance Improvement Plan, PIP),導致團隊成員沒有動力追求卓越,即使躺平也不好導致薪水獎金大幅減少
>
> [name=]
> 沒有適當「人才汰換機制」導致員工沒有動力去學習,目前所在的臺灣分公司建立近兩年,公司內採取扁平化組織 (無中階主管)。不過在任何組織形態,要求每一個人能自組織,能做好向上管理本就是難事
>
> [name=]
> 是否 HR 在審核人才的時候,就需要先做好把關角色,確認其是否具備學習心態?譬如使用 MBTI 16 人格測試?
>
> [name=Kehao]
### 小結
N/A
## 疑問:要如何在身處的團隊,去推動 DevOps?
> 當團隊踏入DevOps的領域,我們需要開始觀察周遭的團隊是否也在實行DevOps,或者他們是否具有相同水準的知識來討論DevOps。而在這個時候,我們也可能陷入「這份工作是我的職責」或「這是我的績效指標」的思維模式中,尤其是在大型企業中,這樣的情況十分普遍。
>
> 總之,穀倉效應和Function Team的執著可能威脅到DevOps實踐的成功。建立跨功能的多技能團隊,以及強調組織的Top-Down支援,都是克服這些障礙的關鍵。所以,集中化的權責劃分勢必將要轉型,這也將衝擊到原有組織內的工作型態
>
> —— [[淺談]DevOps 開始到崩壞? - EK.Technology Learn](https://blog.edwardkuo.dev/%E6%B7%BA%E8%AB%87-devops-%E9%96%8B%E5%A7%8B%E5%88%B0%E5%B4%A9%E5%A3%9E-5697dbc3c596)
>

### 討論
> 在 The DevOps Handbook 中提到,「不需要花費太多時間在改變保守意見的群體」,先找有意願的團隊進行導入。然而在敝公司的 DevOps 是上頭指示全體開發團隊皆需導入,然而各團隊甚至是團隊內的成員,對於 DevOps 都會有各自的理解,導致你執行的 DevOps 不是 DevOps,一個 DevOps 各自解釋。
> 由於在敝公司開發團隊與維運團隊,實際是隸屬於不同的兩個專職單位,因此績效指標各自不同,那麼在導入 DevOps 的時候,可能就會發生利益衝突,對於開發團隊來說我原本不需要去碰任何應用部署、維運相關的工作,怎麼現在要去撰寫 CD pipeline?對於維運團隊來說為了配合實踐 DevOps,需要導入自動化部署工具,需要監控的內容增加了,這些與既有的績效指標不直接相關。
>
> [name=Kehao]
> 就如同書中提到的《跨越鴻溝》,先找到能迅速接受新想法的是創新者或是早期採用者 (2.5% + 13.5%),與其花費太多時間在改變保守意見的群體,不如找到有意願和能力對現有流程進行創新改善的團隊,來建立工程師文化創造成功,在以此為基礎逐漸擴大範圍。
>
> [name=]
### 《超級思維》
> 人們與組織擁有被壓抑的能量,這是等待被釋放的能量。在尋求改變時,隱藏的位能是另一個你可以尋找的東西。想想在你的組織中,那些有動力讓改變發生的人,他們可能願意幫助你。與一群不同的潛在利害關係人交談,可以幫助你找出這些隱藏的位能。
> 就像有技巧地應用在造成變革一樣,如果你能找出一個想法、市場、流程,或任何事物的重心所在,就可以針對這一點採取行動,更快促成改變。舉例來說,你可以說服一個有影響力的中心人物,也就是其他人或組織負責指引方向的人,讓他相信某個想法是有價值的。
>
>
> 企業常常利用這個概念,尋求名人、有影響力的人、媒體或名氣響亮的客戶背書代言。一個背書就可以引發連鎖效應,因為你說服了正確的人,促成你的想法得以傳播。在這種情境下,它就是一種壓力點,只要按下它,你就可以移動整個系統。
>
> Excerpt From
> 超級思維
>
> [name=Michael D]
尋找同樣對現狀不滿的人,這些少數人是隱性的動能。
### 《溝通的方法》
> [博客來-溝通的方法](https://www.books.com.tw/products/0010903813)
>
> 第五章:目標感
>
> [name=Michael D]
### 小結
N/A
## 疑問:如果定義「類生產環境」?該如何去實踐發佈前需運行在類生產環境?
> ### 運行在類生產環境裡才算「完成」
> 現在我們已經可以按需佈建環境,而且一切變更都處於版本控制之下。接下来的「目標,是確保開發團隊在日常工作中使用這些環境。在專案結束還有很長一段時間時,或是首次向生產環境部署前,就確認應用程式能在類生產環境中正常運行。
>
> 大多數現代軟體開發方法論都指定採用較短的迭代期,而非大爆炸方法(如瀑布式開發)。一般來說,部署的間隔時間越長,軟體品質越差。例如在 Scrum 的方法論中,「衝刺」(sprint) 是一個固定時間的開發週期 (通常不多於一個月) 我們必須在這段時間內完成任務,也就是要產出「可運作且可交付的程式碼」。
>
> 我們的目標是在整個專案中確保開發和 QA 能頻繁且常應地整合程式碼與類生產環境。透過擴大解釋「完成」的定義來實現這一點:「完成」的意思不只是實現了功能正確的程式碼,還包括在每個迭代期結束時 (甚至更頻繁地) 在類生產環境中整合且測試了可運作和可交付的程式碼。
>
> 換句話說,「完成」不是指開發人員所認為的「已經完工」,而是指可以成功佈建和部署應用程式,並且確定它在類生產環境中按照預期運行 —— 最好早在迭代結束之前就處理過與生產環境類似的 **負載和資料集**。這麼一來,就能防止應用程式只能運行在開發人員的電腦上,而無法在其他地方運行。
>
> 讓開發人員在類生產環境中編寫、測試和運行自己的程式碼,就能在日常工作中完成程式碼與環境整合的大部分工作,而不需要等到軟體發布時才做。在第一個開發週期結束時,程式碼和環境已經被多次整合,應用程式已被證明能在類生產環境正確運行。在理想情況下,所有步驟都是自動化的 (而不需要手動微調)。
>
> 更棒的是,到專案結束時,我們應該已經在類生產環境中部署和運行程式碼超過上百次,甚至上千次了,因此能確信我們已經發現並解決大部分生產環境部署中的問題。
>
> 理想情況下,應該在預生產環境中使用與生產環境相同的工具,如監控工具、日誌記錄工具和部署工具等。這樣做能夠累積經驗,熟悉如何在生產環境中順利部署和運行程式碼,以及診斷和解決問題。
>
> 藉由開發團隊和營運團隊共同掌握程式碼與環境的互動情形,儘早且頻繁地實施程式碼部署,能夠讓生產環境的部署風險顯著降低。同時也解決總是在專案的最後一刻才發現架構問題的困境,並完全消除這類安全隱患。
>
> —— 《The DevOps Hanbook:Chapter 9|奠定部署管線的基礎》
如何定義「類生產環境」?即使使用的運算資源與生產環境相同規格,個人蠻常遇到的議題是資料庫裡面的資料量級與內容,也希望能與生產環境相近,因此往往的做法就是直接使用資料庫,在某些情境才會從現有的資料庫時例複製一份來使用,直接使用讓類生產環境與生產環境使用同一組資料庫 (也就是讓類生產環境直接使用生產環境的資料庫) 是否為好的實踐?還是需要維運團隊定期從生產環境資料庫實例,完整複製一組供給開發/測試團隊使用?
想討論的議題:
1. 瞭解參與夥伴在團隊內當前的「類生產環境」如何實踐?
2. 對於當前的「類生產環境」,在進行整合運行測試時,有遇到什麼障礙,或是缺乏什麼資源,導致難以在「類生產環境」去驗證某塊功能?
- 延伸議題: 針對上述問題,你覺得該如何改進才能對團隊帶來實質上的幫助?
### 討論
>> [軟體測試的鬼故事]
>> 最近這段時間, 很多公司邀請去分享測試入門知識
>> 都是國內蠻大的公司, 像是友達, 特力屋, 和神坊
>> 他們都不是純軟體公司
>> 但是從些舉動代表國內軟體有越來越重視品質的趨勢
>>
>> 在和他們交流的過程中, 觀察到一些有趣的現象
>> (1) RD 常用"寫測試"這個說法, 因為很多人認為測試就是在寫自動化測試
>> (2) 常常抱怨測試資源不夠, 但是不會找更多測試人員, 然後 RD 也不會去分擔測試工作
>> (3) 開發人員覺得寫完程式就做不完, 測試這件事情真的無法負擔.
>> (4) 測試沒有空做, 所以用戶就是他們的測試人員
>> (5) 每次迭代新功能寫完後, 大多只能測試新功能, 回歸測試就再說
>> (6) 每次都問有沒有辦法測完整一點, 但是都希望不要加時間, 也不要學測試相關知識
>> (7) 常常問到有沒有好用的測試自動化工具, 但是回去後還是沒有在做測試自動化
>> (8) RD 很愛學習或是了解測試自動化的作法, 但是回去後還是沒有在做測試自動化
(9) 只有寫程式是技術, 測試相關的知識不是技術
>>
>> —— [軟體測試的鬼故事 - Facebook](https://www.facebook.com/photo.php?fbid=789545659845901)
>
> [name=Kehao]
>> ### 烽火下的 Scrum
>> 思考一下以下兩句話:「我們這個 Sprint 先做功能,下個Sprint 再補測試。」、「RD 這個 Sprint 先做功能,QA 下個Sprint 再幫忙測試。」是否耳熟?是否是你自己也會考慮,甚至是經常做的事?
>>
>> 很多人號稱自己在 Scrum,卻忽略了一件很重要的事:Scrum 的 Sprint 產出物,要是「潛藏性可交付的產品增量」(Potentially Shippable Product Increment)。什麼意思?意思就是它不只要有增加新功能或修復,它還要是「潛藏性可交付」。也就是說,一個 Sprint 結束後,你的產品要保持在一個「不上線也行,要上線的話也隨時可以」的狀態。也就是說,每個 Sprint 對產品產生的變化,都要「可以交付」,這才是 Scrum 要的產品增量。
>>
>> 試想,如果你這個 Sprint 做的功能,下個 Sprint 才要測,不論那是自動還是手動,那你或你老闆敢「隨時上線」嗎?如果不敢,那你有迭代跟沒迭代又有什麼差別?你還是要等人家測完你再修,修完才能上線,不是嗎?等你好不容易上線,市場的最佳時機早就過了,那還敏捷個 P 啊?
>>
>> 「啊~ Scrum 沒用啦~用了 Scrum 反而慢!」是不是很容易推導出這種結論?
>>
>> 哪有這種事?明明是你自己沒有照人家 Scrum 規範,做出可交付的產品增量,哪能怪人家 Scrum 沒有用呢?
>>
>> 發現了嗎?問題就是出在你「寫完程式無法馬上確定對不對」啊!
>>
>> —— 《你就是不寫測試才會沒時間:Kuma的單元測試實戰 - Java 篇》
>
> [name=Kehao]
> 在 2014 年的技術分享,Google 建議的測試涵蓋率為 85% 以上
>> What do we say to coverage? 85%
>>
>> —— [Test coverage at Google - Google Slides](https://docs.google.com/presentation/d/1god5fDDd1aP6PwhPodOnAZSPpD80lqYDrHhuhyD7Tvg/htmlpresent)
>
>> 
>> The chart above is the histogram of average values of measured absolute coverage across Google. The median (50th percentile) code coverage is 78%, the 75th percentile 85% and 90th percentile 90%. We believe that these numbers represent a very healthy codebase.
>>
>> —— [Google Testing Blog: Measuring Coverage at Google](https://testing.googleblog.com/2014/07/measuring-coverage-at-google.html)
>
> 在 2020 年的技術 Blog,Google 認為卓越的測試涵蓋率為 90% 以上
>> In general code coverage of a lot of products is below the bar; we should aim at significantly improving code coverage across the board. Although there is no “ideal code coverage number,” at Google we offer the general guidelines of 60% as “acceptable”, 75% as “commendable” and 90% as “exemplary.” However we like to stay away from broad top-down mandates and encourage every team to select the value that makes sense for their business needs.
>>
>> —— [Google Testing Blog: Code Coverage Best Practices](https://testing.googleblog.com/2020/08/code-coverage-best-practices.html)
## 組織內部的 registry,如何確保所有專案使用最新的版本
提問自本書 p.327
> 公司使用 [GitHub Apps - Renovate · GitHub](https://github.com/apps/renovate)
>
> [name=michael]
> Dependabot 也可以了:
>
>> Dependabot can now access dependencies from authenticated private registries, such as GitHub Packages, Azure Artifacts, and Artifactory.
>> —— [Dependabot private registry support public beta - The GitHub Blog](https://github.blog/changelog/2021-03-15-dependabot-private-registry-support-public-beta/)
>
>> Now, you can also update dependencies from private GitHub repositories. This feature is available for most package managers supported by Dependabot version updates, except bundler, hex, and pip.
> —— [Dependabot: version updates from private GitHub repositories - The GitHub Blog](https://github.blog/changelog/2020-12-02-dependabot-version-updates-from-private-github-repositories/)
比較:[Bot comparison - Renovate Docs | Renovate Docs](https://docs.renovatebot.com/bot-comparison/)
功能包含第 22 章的「軟體組成分析 Software composition analysis (SCA)」
軟體物料清單 (Software Bill of Materials, SBOM)?
---
# 疑問封存
## 疑問:MDTP 採行了「意見平台」的概念,具體來說是如何實踐的?
> 對三個關鍵因素的持續關注,是讓這個平台獲得成功的關鍵 —— 文化、工具和實踐。MDTP 的目標是讓增加團隊、建立服務和快速交付價值變得更容易。平台秉持這一目標不斷發展改進,讓跨職能團隊能夠快速到位,使用通用工具來設計,開發和營運一個面向公眾的全新服務。
>
> 在實踐方面,MDPT 為數位團隊的程式碼提供了生存空間,並為程式碼的構建和部署提供了自動化管線,連接至各種環境和實際生產環境,讓團隊可以快速獲得使用者回饋。通用的遙測工具配置,幫助團隊以自動儀表板和警報機制來監控其服務,讓他們始終知道發生了什麼。平台也為團隊提供協作工具,幫助他們在內部和彼此之間進行溝通,無論是遠距或進辦公室,都能高效工作。這一切只需要最小的配置或手動步驟,也幾乎即時提供給團隊的。這是為了讓數位團隊能夠完全專注於解決業務問題。
>
> 如果同時有兩千多人在做變更,而且可能是一天好幾次,系統會變得非常混亂。為了避免這種情況,**MDTP 採行了「意見平台」的概念 (也被稱為「鋪路平台」 或「護欄」)**。比方說,如果你建立一個微服務,它必須用 Scala 編寫,並使用 Play 框架。如果你的服務需要持久性,它還必須使用 Mongo。如果使用者需要執行一個共同的動作,比如:上傳文件,那麼團隊必須使用一個共同的平台服務加以實現。從本質上講,一點點的治理結構被内建到平台本身了。對團隊來說,遵守一些規則的好處是,他們可以非常迅速地提供服務。
>
> 但好處還不止於此。限制平台上可以使用的技術,讓支援變得簡單許多。此外,數位團隊可以避免為已經在其他地方解決的問題裡浪費時間苦思冥想。
>
> 「我們可以提供共用服務和可重複使用的組件,這些組件可以與所有的服務一起使用。它還允許人們在服務之間移動> 事實上> 它允許服務轉移到新的團隊> 而不必擔心我們的人是否具備完成這項工作的技能」Hyatt說。
>
> 另一個關鍵是,MDTP 將照料基礎設施這項工作從數位團隊中抽離出來,讓他們只需將心力放在各自的應用程式上。「他們仍然可以透過 Kibana 和 Grafana 等工具觀察基礎設施,但不會有任何服務團隊可以自行存取 AWS 帳戶」Hyatt 指出。
>
> 重要的是,這個「意見平台」採行自助式服務模式,可以確實根據使用者的需求和要求而改變。Hyatt 說:「一項服務可以在我們的平台上建立、開發和部署。
>
> —— 《The DevOps Hanbook:Chapter 5|選擇適當價值流作為切入點》
MDTP 採行了「意見平台」的概念,具體來說是如何實踐的?
### 討論
> 原文可以參考 [Saving the Economy From Ruin (With a Hyperscale PaaS) at HMRC - IT Revolution](https://itrevolution.com/articles/saving-the-economy-from-ruin-with-a-hyperscale-paas-at-hmrc/)
>
> [name=Kehao]
> 
> 
> [09:50](https://youtu.be/HK1IweTsRUM?si=c7Ks0gjWOXoH8Peu&t=644) MDTP 是一組專責團隊,負責應用運行與遙測技術的平臺建置 (Platform Engineering) 的共享平臺。使用 DevOps 原則,MDTP 實現了公有雲中的自動化,建立了可信賴和高可用的數位服務平台。
>
> 
> [23:04](https://youtu.be/HK1IweTsRUM?si=I1beMIJPw7wwWZ46) 雖然 MDTP 上已運行了 95 組服務,並非所有的 HMRC 部門都將應用運行在 MDTP 上,但有時會傾向於自行設置環境,而未使用共享平台。
>
> 
> [31:04]() 一個有趣的 Q&A,對於 JVM 語言的支援,目前 MDTP 平台主要支持 Scala 語言,但未來可能會考慮擴展支持其他 JVM 語言。
>
> —— [Tech Series: Adoption of DevOps HMRC - YouTube](https://www.youtube.com/watch?v=HK1IweTsRUM)
> [name=Kehao]
> 若論企業內部的平臺工程,個人認為值得借鏡的案例為 Line 的 Verda (基於 Kubernetes/Rancher,遙測使用 Elasticsearch + Grafana)
>
> —— [8大關鍵服務維運監控得靠它,Line臺灣百億筆遙測數據的可觀察性平臺架構大公開 | iThome](https://www.ithome.com.tw/news/149317)
> [Verda Cloud Family -English version- - YouTube](https://www.youtube.com/watch?v=S465BmGABdU)
>
> [name=Kehao]
### 小結
已達成與會者共識的結論簡述
## 疑問: 追求安燈繩拉動率是否有意義?
P.40 中提到每當團隊看到安燈繩拉動率下降,他們就會尋找新的方法來刺激拉動率。然而如果拉動次數頻繁,不就代表團隊的思緒也頻繁的打斷,頻繁的 context switch 嗎?這樣反而會增加心力上的憔悴?或者說如何預防安燈繩被濫用?
### 討論
> 安燈繩(Andon cord)的拉動是為了提醒團隊出現問題,需要及時回應。你的擔心是有道理的,頻繁的安燈繩拉動可能會導致思緒頻繁打斷和所謂的 context switch,進而增加團隊的壓力。適度的使用安燈繩是一種平衡。太頻繁的使用會導致中斷和疲勞,太少的使用則可能會忽視問題。因此,制定明確的安燈繩拉動規則和門檻,以及定期審查和調整這些規則,是防止過度或不足使用安燈繩的一種有效方法。
>
> [name=ChatGPT 4]
> [1]: https://www.amazon.com/DevOps-Handbook-Second-World-Class-Organizations/dp/B09L56CT6N ""
> [2]: https://www.oreilly.com/library/view/the-devops-handbook/9781457191381/ ""
> [3]: https://www.amazon.com/DevOps-Handbook-World-Class-Reliability-Organizations/dp/1942788002 ""
>
> 您好,這是 Bing。感謝您對 The DevOps Handbook 的興趣。安燈繩是一種讓團隊能夠快速解決問題的工具,它可以幫助團隊提高生產力和品質[^1^][1]。安燈繩的使用原則是,當團隊遇到任何阻礙或困難時,就可以拉動安燈繩,並立即得到其他團隊成員的協助[^2^][2]。這樣可以避免問題的累積和擴散,並促進團隊的協作和學習[^3^][3]。
>
> 您提出了一個很好的問題,安燈繩的拉動率是否會影響團隊的思緒和效率。根據書中的例子,安燈繩的拉動率並不是越高越好,而是要達到一個適當的平衡點。如果拉動率太低,表示團隊可能沒有及時發現和解決問題,或者沒有充分利用安燈繩的優勢。如果拉動率太高,表示團隊可能遇到了太多的問題,或者安燈繩被濫用或誤用。因此,團隊需要根據自己的實際情況,找出一個合適的安燈繩拉動率,並定期檢視和調整。
>
> 預防安燈繩被濫用的方法有幾個,例如:
> - 建立一個清晰和明確的安燈繩拉動規則,讓團隊知道什麼情況下可以或應該拉動安燈繩。
> - 設定一個合理和可接受的安燈繩拉動時間限制,避免安燈繩被長時間佔用。
> - 對每次安燈繩拉動進行記錄和分析,找出問題的根源和改善措施。
> - 鼓勵團隊成員在不影響工作質量和效率的前提下,嘗試自己解決問題,而不是依賴安燈繩。
>
> 希望這些資訊對您有幫助。如果您還有其他關於 The DevOps Handbook 的問題,歡迎再次詢問。😊
>
> [name=Bing Chat]
> 是的,安燈繩的拉動率應該要適當,不應該過度頻繁。如果拉動率過高,會造成團隊的思緒被頻繁打斷,導致工作效率下降,甚至會增加心力上的憔悴。
>
> 以下是一些如何預防安燈繩被濫用的建議:
>
> * 設定拉動率的目標。
> * 定期檢視拉動率,並採取必要的措施來改善。
> * 避免過度頻繁地拉動。
> * 在拉動之前,先確定是否有必要拉動。
> * 在拉動之後,記錄拉動的原因和結果。
> * 與團隊溝通,讓他們了解安燈繩的目的和使用方式。
>
> 通過這些措施,可以有效地預防安燈繩被濫用,並確保安燈繩能夠被有效地使用。
>
> [name=Google Bard]
### 小結
即使安燈繩拉動頻繁,只要每一次的安燈繩拉動都是有實質意義,是需要改善解決的議題,那麼就應該鼓勵團隊同仁去拉下安燈繩。安燈繩不同於定期的 Retrospective 活動,是能當下作出分析反饋,避免發生時間過久 context 難以追溯。因此組織/團隊內部應建立安燈繩文化,讓同仁能立即作出問題/阻礙的反饋。即使不能當下解決,也能記錄當前的 context 置入於 backlog 中,在定期的改善活動中去解決問題。
如果安燈繩拉動率下降,需要確認是否團隊同仁不敢發表問題,分析什麼因素導致秘而不宣,消除員工的恐懼打造誠實回報的發表環境。
## 疑問:Reasearch 與 Reaftor 是否視為任務納入 WIP 計算範圍
會把 research 跟 refactor 算入 WIP 嗎?各位在現實開發上如何實踐?
### 討論
> 對於個人所在團隊,Research 會是一組 User Story 的子任務/必要步驟,故也會被列入到 WIP 的計算中
>
> [name=Kehao]
> 然而 Refactor 是知道有 Technical Debt,也知道 "改天” 要去改善。然而實際情況往往看到業務需求優先,重構改善並未安排時間人力定期改善
>
> [name=Kehao]
> 以個人的理想,Techniacl Debt 應是團隊定期回顧審視 (e.g. 可以是 Scrum 的 Retrospective 活動),提出需要重構改善的任務化為 Backlog Task。
> PO/PM 需要定期抽出固定的時間人力,來去消化 Backlog 中屬於 Technical Debt 的 Backlog Tasks。
>
> [name=Kehao]
> 書中 p.89 亦提到〈未非功能性需求預留 20% 改善週期,減少技術債〉
> 
>
> [name=Kehao]
### 小結
不論是 Research 或是 Refactor 都應納入 WIP 計算,由於 Research 很可能是難以評估所需工時的未知領域,需要定時做資訊上的同步回報,並由 Product Owner 或是 Stakeholder 協助建立停損點,避免 Feature Team 陷入無止盡的在文獻/資料裡打轉,像個無頭蒼蠅的瞎忙窘境。
Refactor 是需要團隊定期花人力時間去改善,並且團隊成員應隨時能提出所看到的問題 (Technical Debt),將其納入至 Backlog 中。於下一次的迭代/規劃中,依據其重要度與價值挑選出來進行重構。
## 疑問:使用 WIP 限制執行中任務數量,是否需要加上點數衡量
限制 WIP 數量時,把每個 task 加上點數衡量會不會更好? (我會) 無事可做 (等待) 的時候該怎麼辦?
### 討論
> 任務可以使用點數來衡量複雜度/工時,然而這會是在工作規劃階段,用於評估一組需求完成的所需時間,或是固定時間內能產出的任務。
> 限制 WIP 數量的目的,在於避免人腦頻繁的 Context Switch,限制手頭上進行中的任務數量,不論這些任務的大小/複雜度
> [name=Kehao]
> 如果指派的任務與團隊其他夥伴手頭上的任務相依,需要先等待該夥伴完成導致無事可做,可以先確認該位夥伴是否在執行任務中遇到阻礙需要協助。
> 如同書中提到的安燈繩子文化 (P.39),團隊是朝向共同的目標為客戶交付價值,為了能讓價值流能順暢流動,團隊夥伴可以先協助將阻礙打通,讓流程能順利進行下去,如同書中提到的 “Stop starting. Stop finishing." (書中 P.22 「聚焦完成,謹慎開始」的原文)
> [name=Kehao]
### 小結
WIP 限制的用意是在於避免手頭上任務多工並行,點數評估則是用於評估任務的複雜度與所需時間,各自適用的場景不同,WIP 是用於迭代衝刺階段,點數評估則是用於迭代規劃階段。
## 疑問:Reasearch 陷入像無頭蒼蠅的瞎忙窘境,心態該如何調試?
技術 research 花了過多的時間撞牆,數個月仍沒有太大進展,面對未知要如何評估損益點。
心態如何調試?
### 討論
> 由於 Research 很可能是難以評估所需工時的未知領域,需要定時做資訊上的同步回報,並由 Product Owner 或是 Stakeholder 協助建立停損點,避免 Feature Team 陷入無止盡的在文獻/資料裡打轉,像個無頭蒼蠅的瞎忙窘境。
>
> [name=Rick]
> 面對陷入頭緒不清的窘境,我們的確會感到困惑和無力。但請不要氣餒,以下是我建議的幾種調整心態的方式:
>
> 1. **重新評估目標**:我們常常會在混亂中忘記最初的目標。記得定期地回看你的目標,看看是否有需要做出調整的地方。
>
> 2. **確定小步驟**:當大目標看起來難以達成時,設立一些小目標。這樣不僅可以讓工作進度更具可見性,還可以增加你的成就感。
>
> 3. **休息與反思**:當我們沈浸在工作中時,往往會忽視其他需要注意的事物。定期的休息和思考可以讓我們保持頭腦清晰,有助於找到新的想法和解決方案。
>
> 4. **尋求協助**:如果你覺得困難重重,不妨尋求他人的幫助或建議。無論是領導、同事,還是朋友,他們可能會給你帶來新的視角,幫助你突破困境。
>
> 5. **保持學習並接受失敗**:未知往往帶來恐懼,但同時也是學習和成長的機會。接受你不可能一切都知道,並從失敗中找到教訓,這是向前邁進的重要步驟。
>
> 請記住,有時候調整我們的工作方式和思維方式,比持續在困境中努力更有效。
>
> [name=ChatGPT4]
> 您好,這是 Bing。我很高興您對技術研究有興趣。😊
>
> 技術研究是一個充滿挑戰和創新的領域,但也可能會遇到困難和挫折。如果您覺得自己陷入了無頭蒼蠅的瞎忙窘境,心態該如何調試呢?我有一些建議可以分享給您:
>
> - **確定您的研究目標和問題**。有時候,我們可能會在研究過程中迷失方向,不知道自己想要解決什麼問題,或者為什麼要解決這個問題。這時候,我們需要回到起點,重新思考我們的研究目標和問題,並且明確地定義它們。這樣可以幫助我們聚焦在最重要的事情上,避免做無用功。
> - **制定一個合理的研究計劃**。在確定了研究目標和問題之後,我們需要制定一個合理的研究計劃,包括研究方法、資料來源、時間安排、預期結果等。這樣可以幫助我們有條理地進行研究,並且可以隨時檢查我們的進度和成果,及時發現和解決問題。
> - **尋求指導和支持**。技術研究並不是一個孤立的活動,我們需要與其他人交流和合作,尤其是在遇到困難的時候。我們可以尋求指導老師、同事、同學、朋友等人的幫助和建議,或者參加一些相關的研討會、論壇、社群等活動,與其他研究者分享和討論我們的想法和成果。這樣可以幫助我們拓寬視野、增加知識、提高技能、建立關係、增加信心。
> - **保持開放和好奇的心態**。技術研究是一個不斷探索和創新的領域,我們需要保持開放和好奇的心態,不要害怕失敗和錯誤,而是把它們當作學習和成長的機會。我們也需要不斷地閱讀和學習最新的技術發展和趨勢,並且嘗試運用到我們的研究中。這樣可以幫助我們保持熱情和動力,並且發現更多的可能性。
>
> 希望我的建議對您有所幫助。祝您技術研究順利!😊
>
> [name=Bing Chart]
> 技術研究是一項艱鉅的任務,常常需要花費大量的時間和精力才能取得成果。當陷入撞牆的窘境時,很容易會感到挫折和無助。以下是一些調節心態的方法:
> * **首先,要接受自己會撞牆的事實**:技術研究中充滿了未知,不可能事事順利。當撞牆時,不要太過沮喪,而是要調整自己的心態,做好迎接挑戰的準備。
> * **其次,要找出撞牆的原因**:只有找出原因,才能找到解決方案。可以和同事或朋友討論,也可以自己回顧自己的研究過程,找出可能存在的問題。
> * **再次,要調整自己的研究方法**:如果之前的研究方法沒有效果,可以嘗試新的思路或方法。可以參考其他人的研究成果,也可以多參加相關的學術會議或研討會,吸收新知。
> * **最後,要給自己足夠的時間和空間**:技術研究需要時間和積累,不要指望一蹴而就。要給自己足夠的時間和空間,去探索和發現。
>
> 在評估損益點時,可以從以下幾個方面考慮:
>
> * **研究的目標和價值**:研究的目標是什麼?研究的成果對現有技術有什麼改進?研究的價值是否值得投入大量的時間和精力?
> * **研究的進展情況**:目前的研究進展到什麼程度?是否還有繼續研究的必要?
> * **研究的成本和風險**:繼續研究需要投入多少成本?是否存在什麼風險?
>
> 如果研究的目標和價值很高,而且研究進展順利,則可以繼續研究。如果研究的目標和價值不高,或者研究進展不順利,則可以考慮放棄。
>
> 以下是一些具體的調節心態的方法:
>
> * **給自己定一個目標**:一個明確的目標可以幫助你保持專注和動力。可以將研究目標分解為更小的階段性目標,這樣更容易達成。
> * **制定一個計劃**:制定一個研究計劃可以幫助你理清思路,避免盲目地進行研究。計劃中應該包括研究的目標、方法、步驟和預期成果。
> * **定期回顧自己的進展**:定期回顧自己的進展可以幫助你發現問題,並做出相應的調整。
> * **與他人交流**:與同事或朋友交流可以幫助你獲得新的思路和反饋。
> * **給自己放鬆的時間**:研究工作很辛苦,要學會給自己放鬆的時間。可以參加一些興趣愛好活動,或者和朋友家人在一起度過愉快的時間。
>
> 希望這些建議能幫助你調節心態,克服困難,取得研究成果。
>
> [name=Google Bard]
> 
> [EP387 你人生的 #快樂 取決於你思想的品質!加入「目標與代價」的視角,你會更瀟灑!|大人的Small Talk - YouTube](https://www.youtube.com/watch?v=FyW48RP4ODc)
>> 一件事的代價,是以犧牲多少生活來衡量的。
The cost of something is measured by how much life you have to give for it.
>> —— 梭羅 Henry David Thoreau
>
>> 每件事都有它的代價。
>> —— 歐陽盆栽
>
> [name=Kehao]
### 小結
N/A
## 疑問:當 DevOps 遇上 Security 所帶來的價值衝突
在 DevOps Handbook 書中 P.117 提到
> 在理想情況下,所有平台和服務應該是全自動化的,並且能按需提供,不需要開發人員提交工單,等待營運團隊手動處理。如此,可以確保產品或服務不會卡在營運階段 (例如「我們已收到您的工單請求,手動配置這些測試環境需要 6 週」)。
> 自動化的平台和服務,使得產品團隊能夠及時取得所需資源,同時降低了溝通和協作成本。正如 Damon Edwards 所說:「如果沒有這些自助式服務營運平台, 雲端就只是昂貴的 2.0 版主機託管服務。」
由於國家的資通安全管理法規,使得系統需要符合 ISO 27001,即使採用像公雲的自助式服務營運平臺,也會為了存取控制有對應的職責角色,為了資產關聯而有申請審核流程,這一切要求看起來對於價值流交付增加了阻礙,當 DevOps 遇上資安 (具體來說是 ISO 27001) 又應該如何進行調試?
### 討論
> 合資訊安全規範(如 ISO 27001)與實踐 DevOps 之間的確存在挑戰。要遵守 ISO 27001 的規定,您可能需要加入一些額外的步驟或程序,這可能在某種程度上會對價值流的交付產生阻礙。然而,遵守資訊安全規範並實踐 DevOps 並非不可能的事。
>
> 對於這種問題,一種可能的策略就是儘可能將這些額外的步驟和程序「自動化」。例如,對於需要進行的存取控制和與資產相關的審核流程,您可以考慮使用自動化的工具或寫程式腳本來完成這些工作,並將它們整合到你的 DevOps 流程中。
>
> 另一個策略是將安全性的考量「向前移」(shifting security left),也就是將安全性問題的處理提前到開發生命週期的較早階段。這將使安全性成為開發流程的一部分,而不是在所有事都做完之後才去處理,導致不必要的浪費和重新工作。
>
> 最後,開始跨部門間的溝通與協作也是一個被證實有效的策略。與資訊安全團隊合作,理解他們的需求和擔憂,以找到一套既能提高效率又能夠確保安全的解決方案。此外,進行教育來提升組織內部對資訊安全的認識也是重要的一環。
>
> [name=ChatGPT 4]
> 在 DevOps Handbook 書中 P.117 提到,所有平台和服務應該是全自動化的,並且能按需提供,不需要開發人員提交工單,等待營運團隊手動處理。然而,由於國家的資通安全管理法規,系統需要符合 ISO 27001 的要求。即使採用像公雲的自助式服務營運平臺,也會為了存取控制有對應的職責角色,為了資產關聯而有申請審核流程。這些要求看起來對於價值流交付增加了阻礙。當 DevOps 遇上資安 (具體來說是 ISO 27001) 時,可以考慮以下幾點:
>
> 1. 建立一個符合 ISO 27001 要求的自動化平台和服務。
> 2. 確保所有的自動化平台和服務都符合國家的資通安全管理法規。
> 3. 建立一個開放、支持學習和分享的文化,讓每位同仁都能夠學習新知識和技能。
>
> 這些方法可以幫助您在符合國家的資通安全管理法規的前提下實現全自動化的平台和服務。此外,您也可以考慮與相關部門進行溝通,以確保您的自動化平台和服務符合國家的資通安全管理法規。
>
> [name=Bing Chat]
> 當 DevOps 遇上資安,尤其是 ISO 27001 這類嚴格的法規時,確實會面臨一些挑戰。以下是一些調試的建議:
>
> * **將 DevOps 和資安視為同一個價值流**
> DevOps 和資安都是為了確保系統安全和可靠而存在的。因此,在調試時,應將兩者視為同一個價值流,而不是兩個獨立的流程。這樣才能避免重複工作或產生矛盾。
> * **從安全需求出發**
> 在設計 DevOps 流程時,應從安全需求出發。例如,如果 ISO 27001 要求對所有資產進行定期評估,則 DevOps 流程應包含對資產的自動化評估。這樣才能確保安全需求得到滿足,而不會影響 DevOps 的敏捷性。
> * **使用自動化工具**
> 自動化是 DevOps 的核心理念。在資安方面,自動化工具也可以幫助提高效率和降低成本。例如,可以使用自動化工具來執行資安掃描、管理安全配置、以及進行安全事件響應。
> * **建立跨職能團隊**
> DevOps 和資安需要不同職能團隊的合作。在調試時,應建立跨職能團隊,包括 DevOps 工程師、資安工程師、開發人員、運營人員等。這樣才能充分溝通和協作,共同解決問題。
>
> 以下是一些具體的調試措施:
> * **在 DevOps 流程中加入資安審核流程**
> DevOps 流程通常是快速迭代和持續更新的。因此,需要在流程中加入資安審核流程,以確保安全需求得到滿足。審核流程可以是人工審核,也可以是自動化審核。
> * **使用安全工具來自動化安全控制**
> 安全工具可以幫助企業實施和管理安全控制。在 DevOps 流程中使用安全工具,可以提高效率和降低成本。例如,可以使用安全工具來自動化資產管理、配置管理、以及安全事件響應。
> * **建立安全文化**
> 安全文化是企業安全管理的基礎。在 DevOps 團隊中建立安全文化,可以提高團隊的安全意識和責任感。例如,可以通過安全教育、安全宣傳、以及安全激勵等措施來建立安全文化。
>
> 總之,DevOps 和資安是可以兼顧的。通過有效的調試,可以確保 DevOps 的敏捷性和效率,同時滿足資安需求。
>
> [name=Google Bard]
### 小結
對於 Security 的優先度必大於價值流的順暢流動,在設計 DevOps 流程仍需考量 Security 需求,不過仍可以力求審核流程的自動化來降低流動的阻礙,譬如將紙本簽核改為電子簽核,將簽核整合至 CD 的 Pipeline 中
## 疑問:打破穀倉效應該如何起步?
在 The DevOps Handbook 中提到一個案例做了成本測算,是為了解決財務審查過程的繁瑣冗長。個人當前唯一會與財務相關的是公雲費用支出,但申請新資源倒也沒有經過財務部門的批轉,好奇其他公司的狀況。如果需要僅準評估成本,是否包含機房的水電、設備汰換、人月這些都必須一項項盤點?然而由於財務部門、開放部門、維運部門各自的績效不同,因此會有各自為政,資訊不透明的現象。雖然說希望各組織要當責,建立掛部門溝通朝向共同目標邁進,打破組織的穀倉效應,然而在實踐上該如何起步?
> 原問題:
> P.017 提到成本測算,是為了解決財務審查過程的繁瑣冗長。個人當前唯一會與財務相關的是公雲費用支出,但申請新資源倒也沒有經過財務部門的批轉,好奇其他公司的狀況。
如果需要僅準評估成本,是否包含機房的水電、設備汰換、人月這些都必須一項項盤點?
### 討論
> 曾經有經歷 IDE 採購,跑了 3 個月以上行政流程,仍尚未採購完成。
>
> [name=Michael D]
> 個人所在的公司,軟體/服務的採購是會需要在今年編列預算並進行招標,如果是臨時購買則會是用雜支購買,但如果費用較高則無法使用雜支
>
> [name=Kehao]
> 從當責角度,就算不上雲端,財務部門平時就該檢視現有資源投入的效益 (地端機房)。如果沒有的話,那就是他的失職 (沒有負起部門當責:替公司精算成本效益),害組織發生浪費 (如果上雲真的更便宜)。
>
> [name=Michael D]
> 我讀當責這本書時也感覺這本傳達的概念也太不 DevOps 了吧,不過並非無可取之處,我認為當責可以放在改變組織文化的過度階段。總歸來說達成 DevOps 的前提是,組織要有足夠高的集體意識。
>
> [name=Michael D]
> 打破組織的穀倉效應並建立跨部門的溝通和協作是一個綜合性的變革過程,它可能需要以下的一些步驟。首先,確認共享的目標並讓所有相關的部門理解並接受。其次,試著建立一些跨部門的團隊或工作小組,他們的工作是解決指定的問題或完成某項工作,並確保他們的績效評估與此相關。再來,定期舉辦跨部門會議,公開討論問題、提供更新、並尋求解決方案。最後,通過在公司內部分享成功的案例,來推動相關的變革過程。在財務方面,執行完全的成本計算可能需要包括所有的相關費用如水電、設備更新、工時等。若欲採取更為實質性的評估方式,則需要釐清各部門的費用衡量方法以便於準確計算全面成本。
>
> [name=ChatGPT 4]
> 您好,這是 Bing。感謝您的提問,我會盡力為您提供一些有用的資訊和建議。😊
>
> 組織的穀倉效應(silo effect)是指不同部門或團隊之間缺乏有效的溝通和協作,導致資訊孤島、效率低下、創新受阻和利益衝突等問題。打破組織的穀倉效應是一個挑戰,但也是一個機會,可以提高組織的績效和競爭力。
>
> 在實踐上,打破組織的穀倉效應需要從多個方面著手,例如:
>
> - 建立一個清晰的組織願景和目標,並讓所有部門和團隊都了解和認同。這樣可以幫助各方對齊自己的工作和責任,並促進跨部門的合作和協調。
> - 建立一個開放和透明的組織文化,鼓勵資訊的共享和流動,減少資訊的壟斷和隱藏。這樣可以增加各方的信任和理解,並提高決策的品質和速度。
> - 建立一個有效的溝通和反饋機制,讓各方可以及時地交流意見和建議,並及時地解決問題和衝突。這樣可以增加各方的參與和貢獻,並提高工作的滿意度和忠誠度。
> - 建立一個靈活和創新的組織結構,減少層級和障礙,增加協作和學習。這樣可以提高組織的適應能力和創造力,並應對外部環境的變化。
>
> 以上是我對打破組織的穀倉效應的一些看法,希望對您有所幫助。如果您還有其他問題或想法,歡迎再次與我聯繫。😊
>
> [name=Bing Chat]
> 1. 在 The DevOps Handbook 中提到的案例,是為了解決財務審查過程的繁瑣冗長。在傳統的 IT 組織中,財務審查過程通常非常複雜,需要經過多個部門的審批,這會導致審查時間延長,效率低下。DevOps 通過對 IT 基礎設施和運營流程進行自動化,可以簡化財務審查過程,提高效率。
> 2. 在你所在的公司,目前只有公雲費用支出需要經過財務部門的批轉。如果需要準確評估成本,則需要將機房的水電、設備汰換、人月等所有成本一項項盤點。由於財務部門、開發部門、運維部門各自的績效不同,因此會有各自為政,資訊不透明的現象。為了打破這種現象,需要建立跨部門溝通的機制,讓各部門能夠分享資訊,共同努力降低成本。
> 3. 在實踐上,可以從以下幾點入手:
> * 建立跨部門的成本管理小組,由各部門的代表參與其中。
> * 使用財務管理軟體,收集和分析各部門的成本數據。
> * 定期召開成本會議,匯報各部門的成本情況,並進行討論和分析。
> * 制定成本降低計劃,並落實到各部門。
> * 定期檢查成本管理小組的工作,並進行調整。
>
> 通過這些措施,可以有效降低 IT 成本,提高 IT 運營效率。
>
> [name=Google Bard]
> 也許是組織間無法 **將心比心**,由於沒有共同的目標/KPI,尤其是離客戶越遠的組織,越無法將客戶的滿意度/忠誠度視為責任,導致資訊在組織間的不透明
> 
>
> [name=Kehao]
> 時刻改善日常流程,持續改進和優化日常工作流程,以提高效率和生產力。鼓勵不同部門之間的合作和溝通,從而促進知識共享和創新。
>
> [name=Michael D]
> 是否如同 Amazon 一般,要求各部門/團隊接都需要實作並開放 API 來做資訊交換,就能減少彼此間的資訊落差?
> [亚马逊如何变成 SOA(面向服务的架构)? - 阮一峰的网络日志](http://www.ruanyifeng.com/blog/2016/09/how_amazon_take_soa.html)
> >(1)从今天起,所有的团队都要以服务接口的方式,提供数据和各种功能。
> >(2)团队之间必须通过接口来通信。
> >(3)不允许任何其他形式的互操作:不允许直接链接,不允许直接读其他团队的数据,不允许共享内存,不允许任何形式的后门。唯一许可的通信方式,就是通过网络调用服务。
> >(4)具体的实现技术不做规定,HTTP、Corba、PubSub、自定义协议皆可。
> >(5)所有的服务接口,必须从一开始就以可以公开作为设计导向,没有例外。这就是说,在设计接口的时候,就默认这个接口可以对外部人员开放,没有讨价还价的余地。
> >(6)不遵守上面规定,就开除。
>
> [name= Kehao]
>> 沒想到阿肥做不到一個月就辭職,房子退一退,直接跑去加拿大了,大家都覺得錯愕,跑去問阿肥怎麼了,不知道是 mac 鏡頭的問題還是怎樣,只見 zoom 裡的阿肥臉色蒼白像是看到鬼,跟我們說,「靠北喔,裡面不准用 GitHub,pip install 要開單申請,版本控制用檔名,最扯的是我說請幫我把 xx db schema 拉出來我看看,對方處長說這樣有資安疑慮不開權限給我,我說好那你拉出來我用看的就好,結果他們部門加班把資料拉出來塞進 excel 再印出來給我」
>>
>> 我聽到這邊就嚇醒了,還好只是夢不是真的,翻翻 LinkedIn ,阿肥人好好的回去美國 AWS 爽缺了,呼~嚇死😦
>>
>> —— [脾氣不好的中年工程師 on X: "上班太累剛剛不小心睡著做了一個夢" / X](https://twitter.com/al6wul4wul4/status/1696538961597071782?s=20)
>
> [name=Kehao]
> - 打破穀倉,未來會是一種能力指標
> - 看透局,先活下去,讓自己更強壯,然後影響其他人
> - 改變不了整個公司,但是不要被影響
>
> [Rick Hwang - 兩場 (0819, 0826)書友見面會 的心得 . - 這些朋友未來就是下一代的 SRE Lead /... | Facebook](https://www.facebook.com/rick.kyhwang/posts/pfbid02yKaE9t8tvvW3jYghnyrnr1AKEukF9c3s4t8hus5TDmkPxGWrqwzr6UT7AZduVx81l)
> 傳統開發模式常是各自獨立作業,直到整合階段才發覺一堆問題。分工應以功能為單位進行,協同 end-to-end 的進行開發,避免累積庫存 (work in process, WIP) 與進度不同步。Teddy 老師最後也提到 team leader 應關注分工模式,而不是僅是分配工作就完事,避免分工不合作影響團隊效能。
>
> [分工不合作 - 搞笑談軟工](https://www.youtube.com/watch?v=TZS6N9Wqllk)
> 也許 Developer 以及 Operator 在實務上並不同屬於一個單位,各自關注的業務目標也不相同,或許 DevOps 走到後面透過 Platform Engineering 解耦合會是更好的做法 (相當於將應用層的維運工作轉嫁到開發團隊身上,而開發團隊也是最瞭解運用如何運行的同仁)
>
> [name=Kehao]
### 小結
- 持續改進和優化日常工作流程,鼓勵不同部門之間的合作和溝通,從而促進知識共享和創新
- 建立資訊庫 (Knowledge Base) 收攏資訊或是將資料 API 化,讓資訊透明並易於取得
- 導入平臺工程 (Platform Engineering) 以自助式方式,讓每一個單位都可以自行獲取所需資源
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet