:::spoiler UPDATE 2026-05-17 — v5 Dense Qwen3.6-27B vs MoE+MTP same-hardware A/B
The MTP recommendation from v3/v4 above held up against a new comparator: the dense sibling **Qwen3.6-27B**, which fits TP=1 on a single 24 GB 3090 and was hypothesised as a possible cheaper-to-serve alternative for a voice agent.
**Falsified.** On the same s1 (2× RTX 3090 PCIe, vLLM 0.19.1, AWQ-Marlin), 10 prompts × 3 trials × 2 models = 60 streaming SSE samples:
| metric | MoE 35B-A3B + MTP k=3 + TP=2 (production) | Dense 27B no-spec TP=1 | MoE win |
|---|---:|---:|---:|
| TTFT mean (ms) | **178** | 771 | **4.34×** |
| e2e mean (ms) | **274** | 1684 | **6.13×** |
| tok/s mean | **88.0** | 16.2 | **5.42×** |
| tool accuracy | **30/30 (100 %)** | 23/30 (77 %) | +23.3 pp |
No production swap. The dense sibling is not a free upgrade on this hardware for this workload.
**Same-day ERRATA on the v5 release** (transparency): an audit pass after publication surfaced (1) a zh-TW classifier bug that collapsed SIMP into shared — corrected MoE chat-reply counts are 6 TRAD / 3 SIMP (all c1 "你好" trials) / 3 MIX, Dense 5/5 TRAD on its 5 chat replies; (2) the bench SYSTEM_PROMPT is a 4-line stub, not the actual production `robot_brain.py:1292` SYSTEM_PROMPT (60 lines, 8 tools, JSON schema, explicit "你好 → speech only, use greet animation" guidance) — so the 77 % vs 100 % tool-accuracy gap is partly a bench-prompt-under-specification artifact; (3) additional vLLM-config confounds (prefix-caching, `--enforce-eager` / CUDA-graphs differential, `max-num-seqs` 4 vs 1) were not originally disclosed. **Latency findings (TTFT 4.34×, tok/s 5.42×, e2e 6.13×) are compute-bound and remain robust**; tool-accuracy + zh-TW purity need a prompt-matched retest.
Full writeup: [vllm-2x3090 v5_2026_05_17/](https://github.com/thc1006/qwen3.6-vllm-2x3090/tree/master/v5_2026_05_17) · GitHub release with ERRATA: [v5.0](https://github.com/thc1006/qwen3.6-vllm-2x3090/releases/tag/v5.0) · Zenodo DOI: [10.5281/zenodo.20247229](https://doi.org/10.5281/zenodo.20247229)
:::
:::spoiler UPDATE 2026-05-08 — v3 DFlash datapoint + retraction of "hardware-class-independent" framing
Two updates that refine and partly correct the 2026-04-26 banner immediately below.
**1. DFlash via llama.cpp PR #22105 — first public RTX 3090 + DFlash + Q4 datapoint.** Same hardware/model/quant as v2.3, drafter `z-lab/Qwen3.6-35B-A3B-DFlash` (BF16 safetensors → GGUF via the PR's modified `convert_hf_to_gguf.py` with `--target-model-dir`). 5 prompts × 1 trial × 3 draft-max configs.
| method | mean tok/s | vs baseline (138.9) |
|---|---:|---:|
| no spec (baseline) | 138.9 | reference |
| **DFlash `--draft-max=8`** ⭐ | **77.0** | **−44.6 %** ❌ (best DFlash) |
| DFlash `--draft-max=16` | 65.8 | −52.6 % |
| DFlash `--draft-max=4` | 74.9 | −46.1 % |
| (v2.3 reference) Oleg `--draft-min 2 --draft-max 32` | 65.5 | −52.8 % |
DFlash on consumer Ampere with Q4 target is **NET LOSS −44.6 %** at best — slightly less bad than Oleg draft-spec but still net negative. Likely root cause: the BF16-trained drafter conditions on FP16/BF16 target hidden states, which shift subtly under Q4 quantization, breaking drafter–verifier alignment. PR #22105's author already notes the MoE+hybrid path "is currently not optimal" for Qwen3.5/3.6 — our −44.6 % sits inside that envelope. Confirms: **no llama.cpp speculative-decoding method tested gives a positive yield on consumer Ampere with Q4 quantized target.**
Full data + reproducer: [`v3_dflash_2026_05_07/`](https://github.com/thc1006/qwen3.6-speculative-decoding-rtx3090/tree/master/v3_dflash_2026_05_07).
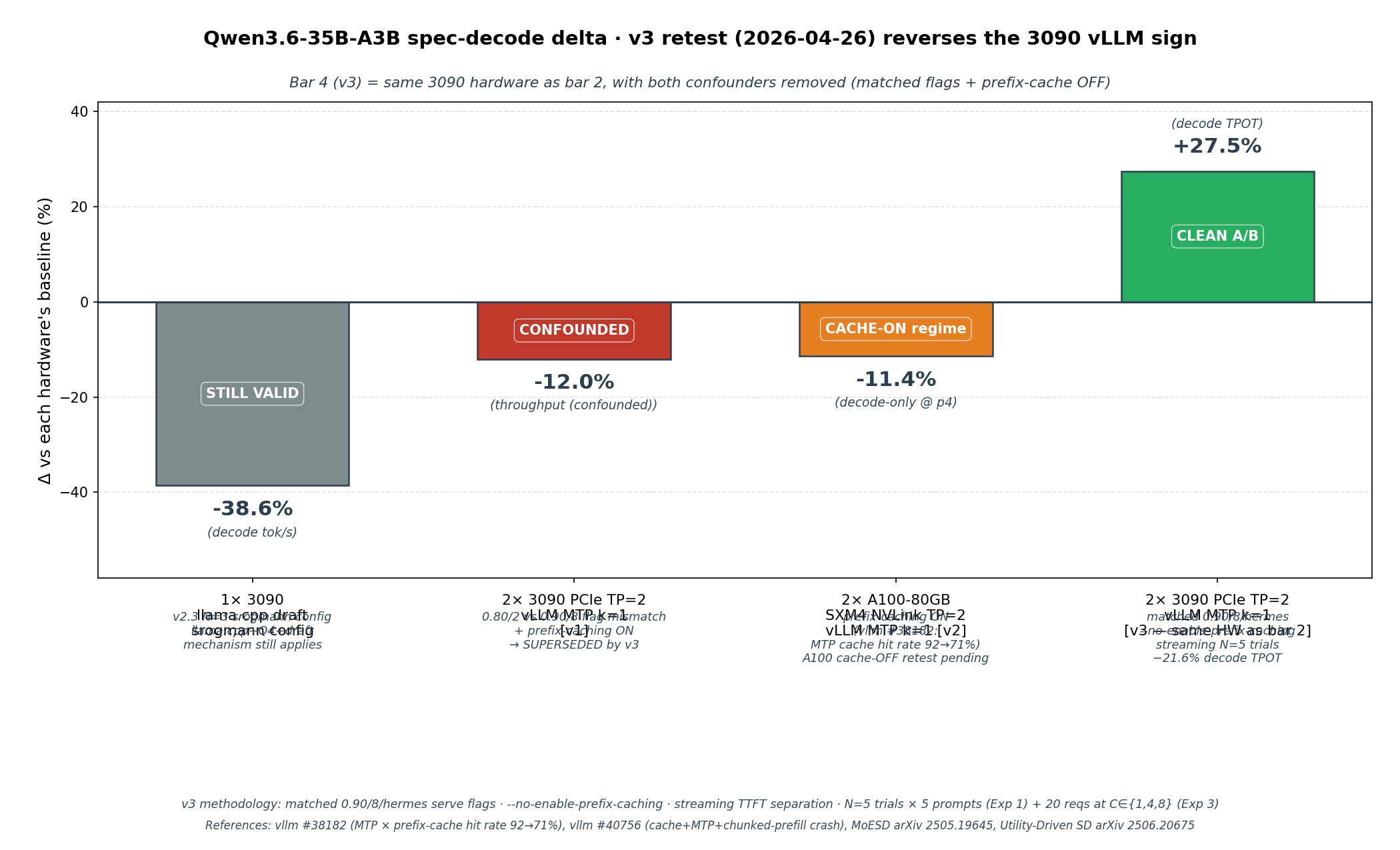
**2. Cross-engine reframe — the regression is NOT "hardware-class-independent".** The 2026-04-26 banner below claims the regression is "hardware-class-independent at single-stream batch=1", based on the A100 NVLink datapoint (−11.4 %) matching the 3090 sign. **That framing is now retracted.** A v3 clean A/B retest on the same 2× RTX 3090 hardware, with matched serve flags AND `--no-enable-prefix-caching` (vLLM 0.19.1 MTP k=1), shows **+27.5 % decode TPOT** vs no-MTP — i.e. MTP *wins* on the same 3090 box once the prefix-cache × MTP interaction ([vllm #38182](https://github.com/vllm-project/vllm/issues/38182), MTP cache hit rate 92 → 71 %) is removed. The original v1 vLLM −12 % was a flag-mismatch confound (`--gpu-memory-utilization 0.80 --max-num-seqs 2` vs `0.90 / 8`); the A100 NVLink −11.4 % is in the cache-ON regime where vllm #38182 still applies. v4 (2026-05-07) confirms +27.5 % holds across k∈{1, 2, 3} and across vLLM 0.19.1 vs 0.20.1 (k=3 is the new TTFT-optimised production setting **on our 2× 3090 PCIe + AWQ + vLLM 0.19.1 stack** — TTFT −33 % / tok/s +8 % vs k=2; [vLLM Recipes](https://docs.vllm.ai/projects/recipes/en/latest/Qwen/Qwen3.5.html)' k=2 default remains the safer cross-hardware starting point, single-card / NVLink / HBM regimes unbenched).
**Corrected framing: the negative finding in this article is engine + spec-method specific to `llama.cpp draft-spec` / `DFlash` on consumer Ampere with Q4 target — NOT hardware-class-independent.** The MoE expert-saturation argument (MoESD / Utility-Driven SD) still explains why llama.cpp's K=5–64 draft-then-verify path loses on consumer Ampere, but does **not** generalise to vLLM MTP k=1 which uses structurally smaller K + a lighter verify path that reuses target hidden states.
Full v3 / v4 vLLM data: [thc1006/qwen3.6-vllm-2x3090](https://github.com/thc1006/qwen3.6-vllm-2x3090).
**Attribution note (2026-05-10 audit)**: the `--no-enable-prefix-caching` recommendation for latency-focused MTP serving was already documented by [vLLM Recipes](https://docs.vllm.ai/projects/recipes/en/latest/Qwen/Qwen3.5.html) in its 2026-04-24 revision — two days before our v3 publication — citing a KV-capacity argument ("speculative tokens consume KV cache capacity, reducing effective batch size"). Our v3 contribution is **quantification** (+27.5 % decode rate vs cache-ON baseline on dual 3090 PCIe + AWQ + Qwen3.6-35B-A3B), **confound decomposition** (matched-flag fix ≈ 30 pp + cache-OFF ≈ 10 pp), and **mechanism link** to vllm #38182's `single_type_kv_cache_manager.py:L457` force-drop bug (a different mechanism than the KV-capacity one Recipes cites; not addressed by Recipes). The cache-OFF preference appears A3B-class specific — Qwen3.6-27B dense + cache-ON + MTP k=3 has been [independently reported working at 97/95/91 % per-position acceptance](https://medium.com/@fzbcwvv/an-overnight-stack-for-qwen3-6-27b-85-tps-125k-context-vision-on-one-rtx-3090-0d95c6291914), so #38182 is best read as a Qwen3.5/3.6 A3B issue, not a Qwen3-family-wide rule.
:::
:::spoiler UPDATE 2026-04-26 — cross-hardware A100 NVLink clean A/B + N=3 replication
Two follow-ups today:
**1. A100 NVLink clean A/B (Modal)** — `vllm/vllm-openai:v0.19.1`, identical serve flags between no-MTP and MTP runs (`--gpu-memory-utilization 0.90 --max-num-seqs 8 --tool-call-parser hermes`). Same 5-prompt set, max_tokens=200, temperature=0.5, seed=42. Prompt-4 decode-only delta **−11.4 %** (TTFT-adjusted; varies <0.2 pp across TTFT ∈ [0, 200 ms] because both arms share the same TTFT for the same prompt content). This rules out two natural-sounding hypotheses:
- ❌ "GDDR6X memory bandwidth is the bottleneck" — HBM2e 2 TB/s shows the same magnitude regression
- ❌ "PCIe Gen4 x8 allreduce is the bottleneck" — NVLink ~600 GB/s shows the same magnitude regression
The mechanism is therefore **hardware-class-independent at single-stream batch=1**, consistent across consumer Ampere + datacenter Ampere (and Hopper H20-3e per [vllm #38182](https://github.com/vllm-project/vllm/issues/38182), Qwen3.5-35B-A3B-FP8 + MTP drops prefix-cache hit rate ~92 % → ~71 %).
**2. N=3 trial replication on a fresh standalone 3090** — addresses the N=1 caveat from v2 limitations. Numbers:
| Config | mean tok/s | run-to-run stdev | v2 published | match |
|---|---:|---:|---:|---|
| baseline | 139.19 | 0.105 | 139.9 | <0.5 pp |
| Oleg `--draft-min 2 --draft-max 32` | 65.24 | 0.057 | 65.0 | <0.3 pp |
| srogmann `--draft-min 48 --draft-max 64` | 85.50 | 0.086 | 85.6 | <0.2 pp |
→ v2 numbers are **N=3 reproducible**, not single-trial flukes.
**Cross-engine corroboration on DGX Spark GB10 forum threads** (April 2026, multiple users on `developer.nvidia.com`): same negative direction reported across vLLM FP8 + MTP-2, SGLang EAGLE3 (−48 % to −58 %), and DFlash spec-decode. The exceptions where spec-decode wins on Spark are batched serving (multi-user concurrency) or structured workloads (code/JSON/Q&A) where prompt entropy is low enough for high acceptance + small expert union — both of which are outside this bench's single-stream voice-dialog scope.
Full data: [thc1006/qwen3.6-vllm-2x3090](https://github.com/thc1006/qwen3.6-vllm-2x3090) (`results/modal_2x_a100_v2.json`, `analysis/plot_cross_hardware.png`).
The v1/v2 conclusions stand and now span more hardware than originally claimed: **single-stream spec-decode for ~3 B-active MoE is a net loss across hardware classes (consumer Ampere, datacenter Ampere with NVLink, Hopper, datacenter Blackwell on Spark per cross-engine forum reports), engines (llama.cpp, vLLM, SGLang), and quantisations (Q4_K_M, AWQ-Marlin Q4, FP8, NVFP4) tested**. The mechanism tracks MoE-Spec / Utility-Driven SD theory: K (1–32) ≪ T_thres ≈ 94, so verify pass loads expert-union with no amortization vs autoregressive — independent of memory bandwidth class.
:::
:::spoiler UPDATE 2026-04-22 — v2 follow-up bench
In response to [Oleg-dM's comment on the HF discussion](https://huggingface.co/unsloth/Qwen3.6-35B-A3B-GGUF/discussions/14), I re-ran the draft-model sweep on a fresh single-3090 box, plus a cross-check on current llama.cpp master `bcb5eeb64`. Short version:
- Oleg's `--draft-min 2 --draft-max 32` does beat the `--draft-min=5` defaults (65 vs 55 tok/s) but is still **−54 %** vs baseline 139.9.
- Aggressive `--draft-min 48 --draft-max 64` is the **least bad** recipe at **−39 %** — counter-intuitively the "wasteful" config amortises overhead better.
- 100 % acceptance is genuine (source read + `--verbose` confirm).
- Master gives same results ±0.3 % — not a stale-commit issue.
- Bottom line of the original post holds: **no spec-decode configuration on consumer 3090 beats baseline for this model+quant.**
Full v2 data + logs + master cross-check: [[Link](https://github.com/thc1006/qwen3.6-speculative-decoding-rtx3090/tree/master/v2_3090_followup)]
Read on for the original writeup; the v2 appendix at the bottom has the full result table.
:::
# Tested every llama.cpp speculative-decode mode on Qwen3.6-35B-A3B + RTX 3090 — none of them are faster than baseline
**TL;DR** — I ran a 19-configuration matrix of speculative decoding on Qwen3.6-35B-A3B (UD-Q4_K_XL, via llama.cpp commit 9789512, post PR #19493 merge) on a single RTX 3090. **None of the spec-decode modes — ngram-cache, ngram-mod (including srogmann's recommended n=24 --draft-min 48 --draft-max 64), or classic `--model-draft` with the vocab-matched Qwen3.5-0.8B — achieves net speedup over baseline.** Mean decode drops 3–12 %, with a bimodal tail of 59–67 tok/s on reasoning / code prompts *despite 100 % draft acceptance*.
### Numbers (single 3090, 24 GB, SM 8.6, Q8_0 KV, greedy, batch=1)
| config | mean | min | std | draft_accept |
|--------------------------|--------|--------|-------|------------------|
| **baseline** | 135.7 | 135.3 | 0.3 | — |
| ngmod-n32 | 133.7 | 133.5 | 0.1 | 0 %(never hits) |
| ngmod-n{8,12,16,20,24} | 129–131| 120–130| 2–5 | 100 % |
| **ngcache-kv-fp16** | 121.3 | 67.3 | 27.6 | 100 % |
| **draft-q35-08b-max{8,16,32}** | 120–121 | **59–65** | **~30** | 100 % |
| draft-q35-08b-1000tok | 120.2 | 64.8 | 28.3 | 100 % |
| ngram-cache | 119.1 | 65.3 | 27.8 | 100 % |
| ngcache-1000tok | 115.9 | 60.0 | 28.7 | 100 % |
### Controls (ruled out)
- Reproduction: baseline-rerun 135.5, ngcache-rerun 118.8 — std within a config ≤ 0.4, so the regression isn't jitter.
- **KV quant is not the cause** — switching `-ctk q8_0 -ctv q8_0` → fp16 KV leaves `ngram-cache` at 121.3 tok/s mean.
- **Output length is not the cause** — 300 → 1000 tokens keeps every ratio.
- **Draft-model vocab** — I initially tried `qwen3:0.6b` (vocab 151936) which silently failed (`failed to create draft context`). The correct draft is **Qwen3.5-0.8B** (vocab 248320, matching the target). That one *loads* and drafts and still loses.
### Why
The pattern matches [MoESD (arXiv 2505.19645)](https://arxiv.org/html/2505.19645) and [Utility-Driven SD for MoE (arXiv 2506.20675)](https://arxiv.org/pdf/2506.20675). With A3B (3 B active, 8-of-256 routed, sparsity 0.031), the expert-saturation threshold `T_thres ≈ 94` is well above any realistic draft K. Each drafted token pulls a fresh expert slice through the memory hierarchy, and on a bandwidth-bound 3090 the verification pass pays for the union. 100 % acceptance cannot rescue it.
**Counter-evidence**: srogmann's own benchmark on Qwen3.5-**122B-A10B** (10 B active) in PR #20075 gets +15–45 % from the same machinery. The issue is class-specific to A3B / small-active MoE, not a general regression of PR #19493.
### Practical takeaway
If you run Qwen3.6-35B-A3B on a consumer 3090 today: **don't enable spec-decode**. Just `llama-server -m Qwen3.6-35B-A3B-UD-Q4_K_XL.gguf -ngl 999 -c 16384 -fa on -ctk q8_0 -ctv q8_0` gives you 135.7 tok/s, which is already +27 % vs Ollama 0.20.7 (107 tok/s) on the same hardware.
### Reproducibility
Full raw JSON per request, 3 plots, aggregated CSV, `BENCHMARK_ENV.md` (hardware / driver / CUDA / commit / model SHA256), and the exact `run_*_matrix.sh` — everything at:
**https://github.com/thc1006/qwen3.6-speculative-decoding-rtx3090**
PR #19493 comment with the same data: https://github.com/ggml-org/llama.cpp/pull/19493#issuecomment-4285150166
If you're on a different Ampere card (3060 Ti / 3080 / A4000 / A5000) — would love a replication, happy to merge your JSON into the repo.
---
# v2 Appendix · Follow-up bench (2026-04-22)
Context: two days after the original writeup, Oleg-dM raised three critiques in [HF discussion #14](https://huggingface.co/unsloth/Qwen3.6-35B-A3B-GGUF/discussions/14):
1. `n_acc_tokens / n_gen_tokens` = 100 % looks off
2. `--draft-min 48` is too aggressive, try `--draft-min 2 --draft-max 32`
3. "failed to create draft context" is probably OOM
Instead of arguing, I re-ran on a fresh single-3090 box.
## Setup
- llama.cpp `97895129e` (original) AND cross-check on master `bcb5eeb64` (post PR #22227 speculative-simple checkpoint)
- RTX 3090 24 GB, single GPU, driver 580.126, CUDA 12.0
- **Stock clocks**, no OC (graphics 1965 MHz current / 2100 max; memory 9751 MHz; power limit 350 W)
- `-ngl 999 -c 16384 -fa on -ctk q8_0 -ctv q8_0 -n 200 --temp 0.5 --seed 42 -no-cnv -st`
- 5 prompts, `/no_think` appended
- Draft model: `unsloth/Qwen3.5-0.8B-Q4_K_M.gguf` (vocab-matched)
## Result chart

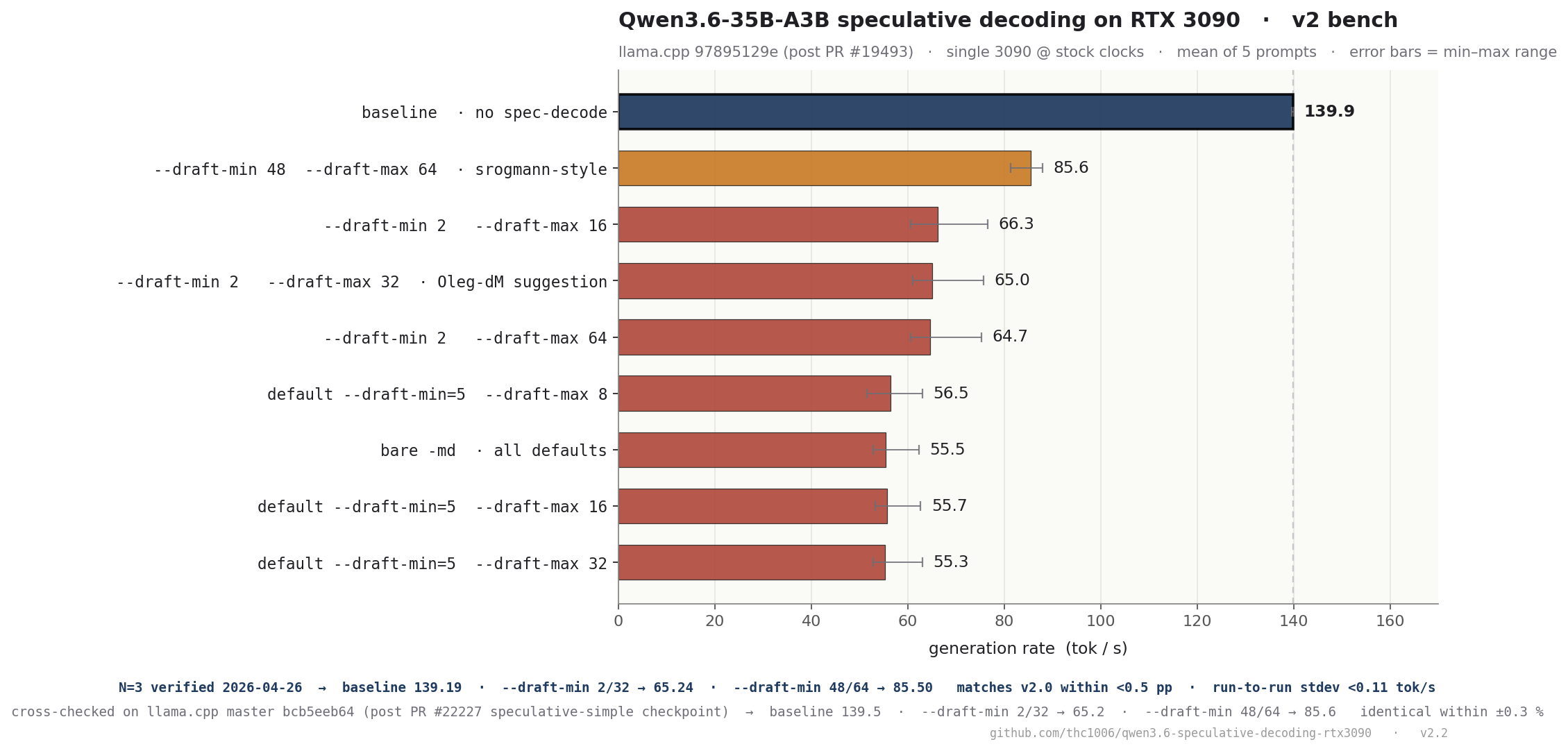
## Results on `97895129e` (tok/s, N=5)
| Config | mean | min | max | Δ baseline |
|---|---:|---:|---:|---:|
| **baseline** | **139.9** | 139.7 | 140.0 | — |
| `-md --draft-max 8` (default min=5) | 56.5 | 51.5 | 63.0 | −60 % |
| `-md --draft-max 16` (default min=5) | 55.7 | 53.3 | 62.7 | −60 % |
| `-md --draft-max 32` (default min=5) | 55.3 | 52.9 | 63.1 | −60 % |
| `-md` (full defaults) | 55.5 | 52.8 | 62.3 | −60 % |
| **`--draft-min 2 --draft-max 32` (Oleg)** | **65.0** | 61.0 | 75.8 | **−54 %** |
| `--draft-min 2 --draft-max 16` | 66.3 | 60.6 | 76.6 | −53 % |
| `--draft-min 2 --draft-max 64` | 64.7 | 60.6 | 75.3 | −54 % |
| `--draft-min 48 --draft-max 64` (srogmann) | **85.6** | 81.3 | 88.0 | **−39 %** |
## Cross-check on master `bcb5eeb64`
| Config | `97895129e` | master | Δ |
|---|---:|---:|---:|
| baseline | 139.9 | 139.5 | −0.3 % (noise) |
| Oleg 2/32 | 65.0 | 65.2 | +0.3 % (noise) |
| srogmann 48/64 | 85.6 | 85.6 | 0 % |
## Key findings
### 1. 100 % acceptance is real
`common/speculative.cpp` line ~1194: `impl->n_acc_tokens += n_accepted;` — counter is post-verify. `--verbose` run emits `draft acceptance rate = 1.00000 (115 accepted / 115 generated)`. The 0.8B vocab-matched draft genuinely matches the 35B target on low-entropy prompts.
### 2. Oleg's suggestion beats defaults, still loses to baseline
`--draft-min 2 --draft-max 32` at 65 tok/s is +18 % over the default `--draft-min=5` at 55 tok/s. But -54 % vs no-spec-decode 139.9.
### 3. Counter-intuitive: aggressive wins
`--draft-min 48 --draft-max 64` is the LEAST bad at 85.6 tok/s (-39 %). The large draft window amortises per-verify overhead enough to hide part of the cost.
### 4. Why v1 showed mean 120 and v2 shows mean 55-85
v1's 12-prompt set included chat prompts that exhausted the draft cache quickly, falling back to normal decode (~140 tok/s) — the observed tail at 59-67 is the always-active regime, the baseline-like numbers come from the skipped-spec-decode regime. v1's mean 120 is the mixture.
v2's 5 structured prompts keep spec-decode active throughout, isolating the always-on regime.
### 5. Not a stale-commit artefact
Master `bcb5eeb64` includes PR #22227 speculative-simple checkpoint support — gives same numbers. The regression is architectural.
## Conclusion (v1 + v2 combined)
**Consumer RTX 3090 + Qwen3.6-35B-A3B Q4_K_M: no speculative decoding configuration is a net win**, regardless of commit, regardless of draft-min/max settings, regardless of which regime you measure. The memory-bandwidth × MoE expert-loading math doesn't work on this hardware tier.
H100 / H200 / NVLinked pairs may flip the sign; dual-3090 with PCIe crossing between main-GPU and draft-GPU makes it worse (per Oleg's 80 → 25 tok/s observation in the same discussion).
Full artefacts (per-prompt llama-cli logs, GPU state, verbose dump, master cross-check):
→ https://github.com/thc1006/qwen3.6-speculative-decoding-rtx3090/tree/master/v2_3090_followup