# [論文筆記] The Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation
###### tags: `FCN` `Segmentation`
DenseNet普遍被用於影像分類的任務中,選用DenseNet而不是ResNet有以下三個優點:
1. 模型參數的使用上更有效率
2. 拜short paths所賜,DenseNet可實現深層監督
3. 特徵重複使用: 所有的layer可以獲取先前layer的資訊,從而增進先前feature maps的再利用
因此,DenseNet的架構被修改來用於**語意切割**(Semantice Segmentation)的領域中,在2017發表於CVPRW並有超過1000次的引用。
那些經典的、被用於語意切割的模型通常具備:
1. 可以提取粗略特徵的downsampling path
2. 可將輸入影像分辨率復原至輸出圖片大小的upsampling path
3. 後處理的模組: 可用以強化切割的邊緣,提高模型預測準確率 ex: CRF
## DenseNet Connection的review

- **Standard Convolution**: 對前一層的輸出$x_l-1$做非線性變換$H_l$計算出$x_l$

- **Residual Learning**: ResNet引用了residual block,可將輸入的恆等映射和輸出相加求和,從而提升先前feature maps的再利用。

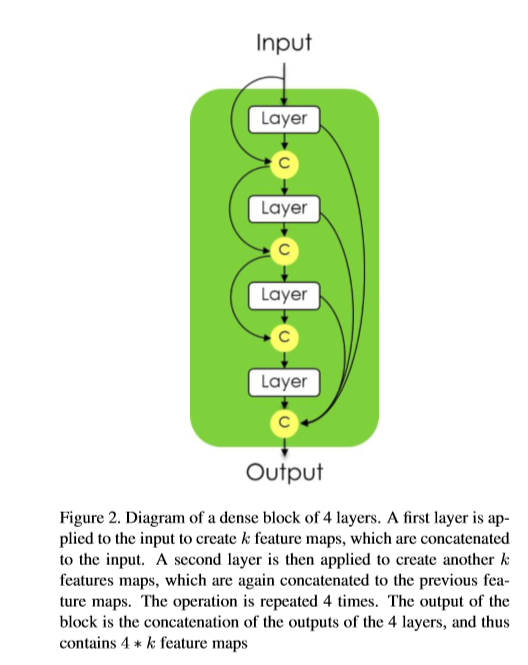
- **DenseNet**: 將前饋連接網路中所有的特徵輸出拼接起來,使得每層都能直接訓練。
(附圖為Dense Block)
## FC-DenseNet 架構


- 在FC-DenseNet中,只對先前dence block生成的feature map 進行上採樣,否則會耗費大量的計算資源。(並不是對每層layer所生成的feature map都做上採樣)
- 如同UNet、FCN等類似架構般,跳躍連接(Skip connection)被使用於下採樣和上採樣之間
- 無須任何預訓練(per-training),即可重頭開始訓練模型

- 上圖為FC-DenseNet103的網路細節
- $m$: 在block輸出後的featuren map總數
- $c$: 類別數
## 實驗結果
※**CamVid**

- FC-DenseNets使用224X224的切割和batch size = 3進行訓練。在最後,用全尺寸的圖像微調模型,且並沒有做任何平滑或後處理。
- 從結果得知,與經典的模型相比,本文提出的上採樣路徑得出明顯的優勢。特別是像路標、圍牆、騎單車者,都獲得15%-25%的效能提升。
- FC-DenseNet受益於更深的網路深度和更多的模型參數。

## 參考資料
https://towardsdatascience.com/review-fc-densenet-one-hundred-layer-tiramisu-semantic-segmentation-22ee3be434d5
https://www.cnblogs.com/fourmi/p/9881741.html